“We are gravely disappointed that the protections provided by ADP will not be available to our customers in the UK given the continuing rise of data breaches and other threats to customer privacy,” Apple said. “Enhancing the security of cloud storage with end-to-end encryption is more urgent than ever before.”
For UK Apple users, some data can still be encrypted. iCloud Keychain and Health, iMessage, and FaceTime will remain end-to-end encrypted by default. But other iCloud services will not be encrypted, effective immediately, including iCloud Backup, iCloud Drive, Photos, Notes, Reminders, Safari Bookmarks, Siri Shortcuts, Voice memos, Wallet passes, and Freeform.
In the future, Apple hopes to restore data protections in the UK, but the company refuses to ever build a backdoor for government officials.
“Apple remains committed to offering our users the highest level of security for their personal data and are hopeful that we will be able to do so in the future in the United Kingdom,” Apple said. “As we have said many times before, we have never built a backdoor or master key to any of our products or services, and we never will.”
Microsoft declined to comment, but allegedly the DOGE employees are “using AI software accessed through Microsoft’s cloud computing service Azure to pore over every dollar of money the department disburses, from contracts to grants to work trip expenses,” one source told the Post.
The lawsuit noted that several DOE employees have tried to block DOGE’s access by raising red flags up the command chain, but DOE leadership directly instructed lower-level employees to grant DOGE access, the same source alleged.
A big concern is that DOGE funneling education data into AI systems will cause sensitive data to be stored in a way that makes it more vulnerable to cyberattacks or data breaches. Another issue could be the AI system being error-prone or potentially hallucinating data that is driving decisions on major DOE cuts.
On Thursday, a DOE deputy assistant secretary for communications, Madi Biedermann, issued a statement insisting that DOGE employees are federal employees who have undergone background checks to be granted requisite security clearances.
“There is nothing inappropriate or nefarious going on,” Biedermann said.
Trump has similarly waved away concerns over DOGE’s work at DOE and other departments that officials worry are experiencing a “blitz” of seemingly unlawful power grabs, the Post reported. On Monday, Trump told reporters that “if there’s a conflict” with DOGE accessing Americans’ data, “then we won’t let him get near it.” But seemingly until Trump agrees there’s a conflict, Musk’s work with DOGE must go on, Trump said.
“We’re trying to shrink government, and he can probably shrink it as well as anybody else, if not better,” Trump suggested.
While thousands of Americans are suing, confused over whether they need to urgently protect their private financial data, one DOE staffer told the Post that DOGE “is working with almost unbelievable speed.” The staffer ominously suggested that it may already be too late to protect Americans from invasive probes or defend departments against cuts.
“They have a playbook, which is to get access to the data,” the staffer told the Post. “And once they’re in, it’s already over.”
Nick Dedeke is an associate teaching professor at Northeastern University, Boston. His research interests include digital transformation strategies, ethics, and privacy. His research has been published in IEEE Management Review, IEEE Spectrum, and the Journal of Business Ethics. He holds a PhD in Industrial Engineering from the University of Kaiserslautern-Landau, Germany. The opinions in this piece do not necessarily reflect the views of Ars Technica.
In an earlier article, I discussed a few of the flaws in Europe’s flagship data privacy law, the General Data Protection Regulation (GDPR). Building on that critique, I would now like to go further, proposing specifications for developing a robust privacy protection regime in the US.
Writers must overcome several hurdles to have a chance at persuading readers about possible flaws in the GDPR. First, some readers are skeptical of any piece criticizing the GDPR because they believe the law is still too young to evaluate. Second, some are suspicious of any piece criticizing the GDPR because they suspect that the authors might be covert supporters of Big Tech’s anti-GDPR agenda. (I can assure readers that I am not, nor have I ever, worked to support any agenda of Big Tech companies.)
In this piece, I will highlight the price of ignoring the GDPR. Then, I will present several conceptual flaws of the GDPR that have been acknowledged by one of the lead architects of the law. Next, I will propose certain characteristics and design requirements that countries like the United States should consider when developing a privacy protection law. Lastly, I provide a few reasons why everyone should care about this project.
The high price of ignoring the GDPR
People sometimes assume that the GDPR is mostly a “bureaucratic headache”—but this perspective is no longer valid. Consider the following actions by administrators of the GDPR in different countries.
In May 2023, the Irish authorities hit Meta with a fine of $1.3 billion for unlawfully transferring personal data from the European Union to the US.
On July 16, 2021, the Luxembourg National Commission for Data Protection (CNDP) issued a fine of 746 million euros ($888 million) to Amazon Inc. The fine was issued due to a complaint from 10,000 people against Amazon in May 2018 orchestrated by a French privacy rights group.
On September 5, 2022, Ireland’s Data Protection Commission (DPC) issued a 405 million-euro GDPR fine to Meta Ireland as a penalty for violating GDPR’s stipulation regarding the lawfulness of children’s data (see other fines here).
In other words, the GDPR is not merely a bureaucratic matter; it can trigger hefty, unexpected fines. The notion that the GDPR can be ignored is a fatal error.
9 conceptual flaws of the GDPR: Perspective of the GDPR’s lead architect
Axel Voss is one of the lead architects of the GDPR. He is a member of the European Parliament and authored the 2011 initiative report titled “Comprehensive Approach to Personal Data Protection in the EU” when he was the European Parliament’s rapporteur. His call for action resulted in the development of the GDPR legislation. After observing the unfulfilled promises of the GDPR, Voss wrote a position paper highlighting the law’s weaknesses. I want to mention nine of the flaws that Voss described.
First, while the GDPR was excellent in theory and pointed a path toward the improvement of standards for data protection, it is an overly bureaucratic law created largely using a top-down approach by EU bureaucrats.
Second, the law is based on the premise that data protection should be a fundamental right of EU persons. Hence, the stipulations are absolute and one-sided or laser-focused only on protecting the “fundamental rights and freedoms” of natural persons. In making this change, the GDPR architects have transferred the relationship between the state and the citizen and applied it to the relationship between citizens and companies and the relationship between companies and their peers. This construction is one reason why the obligations imposed on data controllers and processors are rigid.
Third, the GDPR law aims to empower the data subjects by giving them rights and enshrining these rights into law. Specifically, the law enshrines nine data subject rights into law. They are: the right to be informed, the right to access, the right to rectification, the right to be forgotten/or to erasure, the right to data portability, the right to restrict processing, the right to object to the processing of personal data, the right to object to automated processing and the right to withdraw consent. As with any list, there is always a concern that some rights may be missing. If critical rights are omitted from the GDPR, it would hinder the effectiveness of the law in protecting privacy and data protection. Specifically, in the case of the GDPR, the protected data subject rights are not exhaustive.
Fourth, the GDPR is grounded on a prohibition and limitation approach to data protection. For example, the principle of purpose limitation excludes chance discoveries in science. This ignores the reality that current technologies, e.g., machine learning and artificial Intelligence applications, function differently. Hence, these old data protection mindsets, such as data minimization and storage limitation, are not workable anymore.
Fifth, the GDPR, on principle, posits that every processing of personal data restricts the data subject’s right to data protection. It requires, therefore, that each of these processes needs a justification based on the law. The GDPR deems any processing of personal data as a potential risk and forbids its processing in principle. It only allows processing if a legal ground is met. Such an anti-processing and anti-sharing approach may not make sense in a data-driven economy.
Sixth, the law does not distinguish between low-risk and high-risk applications by imposing the same obligations for each type of data processing application, with a few exceptions requiring consultation of the Data Processing Administrator for high-risk applications.
Seventh, the GDPR also excludes exemptions for low-risk processing scenarios or when SMEs, startups, non-commercial entities, or private citizens are the data controllers. Further, there are no exemptions or provisions that protect the rights of the controller and of third parties for such scenarios in which the data controller has a legitimate interest in protecting business and trade secrets, fulfilling confidentiality obligations, or the economic interest in avoiding huge and disproportionate efforts to meet GDPR obligations.
Eighth, the GDPR lacks a mechanism that allows SMEs and startups to shift the compliance burden onto third parties, which then store and process data.
Ninth, the GPR relies heavily on government-based bureaucratic monitoring and administration of GDPR privacy compliance. This means an extensive bureaucratic system is needed to manage the compliance regime.
There are other issues with GDPR enforcement (see pieces by Matt Burgess and Anda Bologa) and its negative impacts on the EU’s digital economy and on Irish technology companies. This piece will focus only on the nine flaws described above. These nine flaws are some of the reasons why the US authorities should not simply copy the GDPR.
The good news is that many of these flaws can be resolved.
Enlarge / Andrew J. Pincus, attorney for TikTok and ByteDance, leaves the E. Barrett Prettyman US Court House with members of his legal team as the U.S. Court of Appeals hears oral arguments in the case TikTok Inc. v. Merrick Garland on September 16 in Washington, DC.
The fight to keep TikTok operating unchanged in the US reached an appeals court Monday, where TikTok and US-based creators teamed up to defend one of the world’s most popular apps from a potential US ban.
TikTok lawyer Andrew Pincus kicked things off by warning a three-judge panel that a law targeting foreign adversaries that requires TikTok to divest from its allegedly China-controlled owner, ByteDance, is “unprecedented” and could have “staggering” effects on “the speech of 170 million Americans.”
Pincus argued that the US government was “for the first time in history” attempting to ban speech by a specific US speaker—namely, TikTok US, the US-based entity that allegedly curates the content that Americans see on the app.
The government justified the law by claiming that TikTok may in the future pose a national security risk because updates to the app’s source code occur in China. Essentially, the US is concerned that TikTok collecting data in the US makes it possible for the Chinese government to both spy on Americans and influence Americans by manipulating TikTok content.
But Pincus argued that there’s no evidence of that, only the FBI warning “about the potential that the Chinese Communist Party could use TikTok to threaten US homeland security, censor dissidents, and spread its malign influence on US soil.” And because the law carves out China-owned and controlled e-commerce apps like Temu and Shein—which a US commission deemed a possible danger and allegedly process even more sensitive data than TikTok—the national security justification for targeting TikTok is seemingly so under-inclusive as to be fatal to the government’s argument, Pincus argued.
Jeffrey Fisher, a lawyer for TikTok creators, agreed, warning the panel that “what the Supreme Court tells us when it comes to under-inclusive arguments is” that they “often” are “a signal that something else is at play.”
Daniel Tenny, a lawyer representing the US government, defended Congress’ motivations for passing the law, explaining that the data TikTok collects is “extremely valuable to a foreign adversary trying to compromise the security” of the US. He further argued that a foreign adversary controlling “what content is shown to Americans” is just as problematic.
Rather than targeting Americans’ expression on the app, Tenny argued that because ByteDance controls TikTok’s source code, the speech on TikTok is not American speech but “expression by Chinese engineers in China.” This is the “core point” that the US hopes the appeals court will embrace, that as long as ByteDance oversees TikTok’s source code, the US will have justified concerns about TikTok data security and content manipulation. The only solution, the US government argues, is divestment.
TikTok has long argued that divestment isn’t an option and that the law will force a ban. Pincus told the court that the “critical issue” with the US government’s case is that the US does not have any evidence that TikTok US is under Chinese control. Because the US is only concerned about some “future Chinese control,” the burden that the law places on speech must meet the highest standard of constitutional scrutiny. Any finding otherwise, Pincus warned the court, risked turning the First Amendment “on its head,” potentially allowing the government to point to foreign ownership to justify regulating US speech on any platform.
But as the panel explained, the US government had tried for two years to negotiate with ByteDance and find through Project Texas a way to maintain TikTok in the US while avoiding national security concerns. Because every attempt to find a suitable national security arrangement has seemingly failed, Congress was potentially justified in passing the law, the panel suggested, especially if the court rules that the law is really just trying to address foreign ownership—not regulate content. And even though the law currently only targets TikTok directly, the government could argue that’s seemingly because TikTok is so far the only foreign adversary-controlled company flagged as a potential national security risk, the panel suggested.
TikTok insisted that divestment is not the answer and that Congress has made no effort to find a better solution. Pincus argued that the US did not consider less restrictive means for achieving the law’s objectives without burdening speech on TikTok, such as a disclosure mechanism that could prevent covert influence on the app by a foreign adversary.
But US circuit judge Neomi Rao pushed back on this, suggesting that disclosure maybe isn’t “always” the only appropriate mechanism to block propaganda in the US—especially when the US government has no way to quickly assess constantly updated TikTok source code developed in China. Pincus had confirmed that any covert content manipulation uncovered on the app would only be discovered after users were exposed.
“They say it would take three years to just review the existing code,” Rao said. “How are you supposed to have disclosure in that circumstance?”
“I think disclosure has been the historic answer for covert content manipulation,” Pincus told the court, branding the current law as “unusual” for targeting TikTok and asking the court to overturn the alleged ban.
The government has given ByteDance until mid-January to sell TikTok, or else the app risks being banned in the US. The appeals court is expected to rule by early December.
Chrome users who declined to sync their Google accounts with their browsing data secured a big privacy win this week after previously losing a proposed class action claiming that Google secretly collected personal data without consent from over 100 million Chrome users who opted out of syncing.
On Tuesday, the 9th US Circuit Court of Appeals reversed the prior court’s finding that Google had properly gained consent for the contested data collection.
The appeals court said that the US district court had erred in ruling that Google’s general privacy policies secured consent for the data collection. The district court failed to consider conflicts with Google’s Chrome Privacy Notice (CPN), which said that users’ “choice not to sync Chrome with their Google accounts meant that certain personal information would not be collected and used by Google,” the appeals court ruled.
Rather than analyzing the CPN, it appears that the US district court completely bought into Google’s argument that the CPN didn’t apply because the data collection at issue was “browser agnostic” and occurred whether a user was browsing with Chrome or not. But the appeals court—by a 3–0 vote—did not.
In his opinion, Circuit Judge Milan Smith wrote that the “district court should have reviewed the terms of Google’s various disclosures and decided whether a reasonable user reading them would think that he or she was consenting to the data collection.”
“By focusing on ‘browser agnosticism’ instead of conducting the reasonable person inquiry, the district court failed to apply the correct standard,” Smith wrote. “Viewed in the light most favorable to Plaintiffs, browser agnosticism is irrelevant because nothing in Google’s disclosures is tied to what other browsers do.”
Smith seemed to suggest that the US district court wasted time holding a “7.5-hour evidentiary hearing which included expert testimony about ‘whether the data collection at issue'” was “browser-agnostic.”
“Rather than trying to determine how a reasonable user would understand Google’s various privacy policies,” the district court improperly “made the case turn on a technical distinction unfamiliar to most ‘reasonable'” users, Smith wrote.
Now, the case has been remanded to the district court where Google will face a trial over the alleged failure to get consent for the data collection. If the class action is certified, Google risks owing currently unknown damages to any Chrome users who opted out of syncing between 2016 and 2024.
According to Smith, the key focus of the trial will be weighing the CPN terms and determining “what a ‘reasonable user’ of a service would understand they were consenting to, not what a technical expert would.”
Matthew Wessler, a lawyer for Chrome users suing, told Ars that “we are pleased with the Ninth Circuit’s decision” and “look forward to taking this case on behalf of Chrome users to trial.”
A Google spokesperson, José Castañeda, told Ars that Google disputes the decision.
“We disagree with this ruling and are confident the facts of the case are on our side,” Castañeda told Ars. “Chrome Sync helps people use Chrome seamlessly across their different devices and has clear privacy controls.”
Enlarge/ For a true representation of the people-search industry, a couple of these folks should have lanyards that connect them by the pockets.
Getty Images
If you’ve searched your name online in the last few years, you know what’s out there, and it’s bad. Alternately, you’ve seen the lowest-common-denominator ads begging you to search out people from your past to see what crimes are on their record. People-search sites are a gross loophole in the public records system, and it doesn’t feel like there’s much you can do about it.
Not that some firms haven’t promised to try. Do they work? Not really, Consumer Reports (CR) suggests in a recent study.
“[O]ur study shows that many of these services fall short of providing the kind of help and performance you’d expect, especially at the price levels some of them are charging,” said Yael Grauer, program manager for CR, in a statement.
Consumer Reports’ study asked 32 volunteers for permission to try to delete their personal data from 13 people-search sites, using seven services over four months. The services, including DeleteMe, Reputation Defender from Norton, and Confidently, were also compared to “Manual opt-outs,” i.e. following the tucked-away links to pull down that data on each people-search site. CR took volunteers from California, in which the California Consumer Privacy Act should theoretically make it mandatory for brokers to respond to opt-out requests, and in New York, with no such law, to compare results.
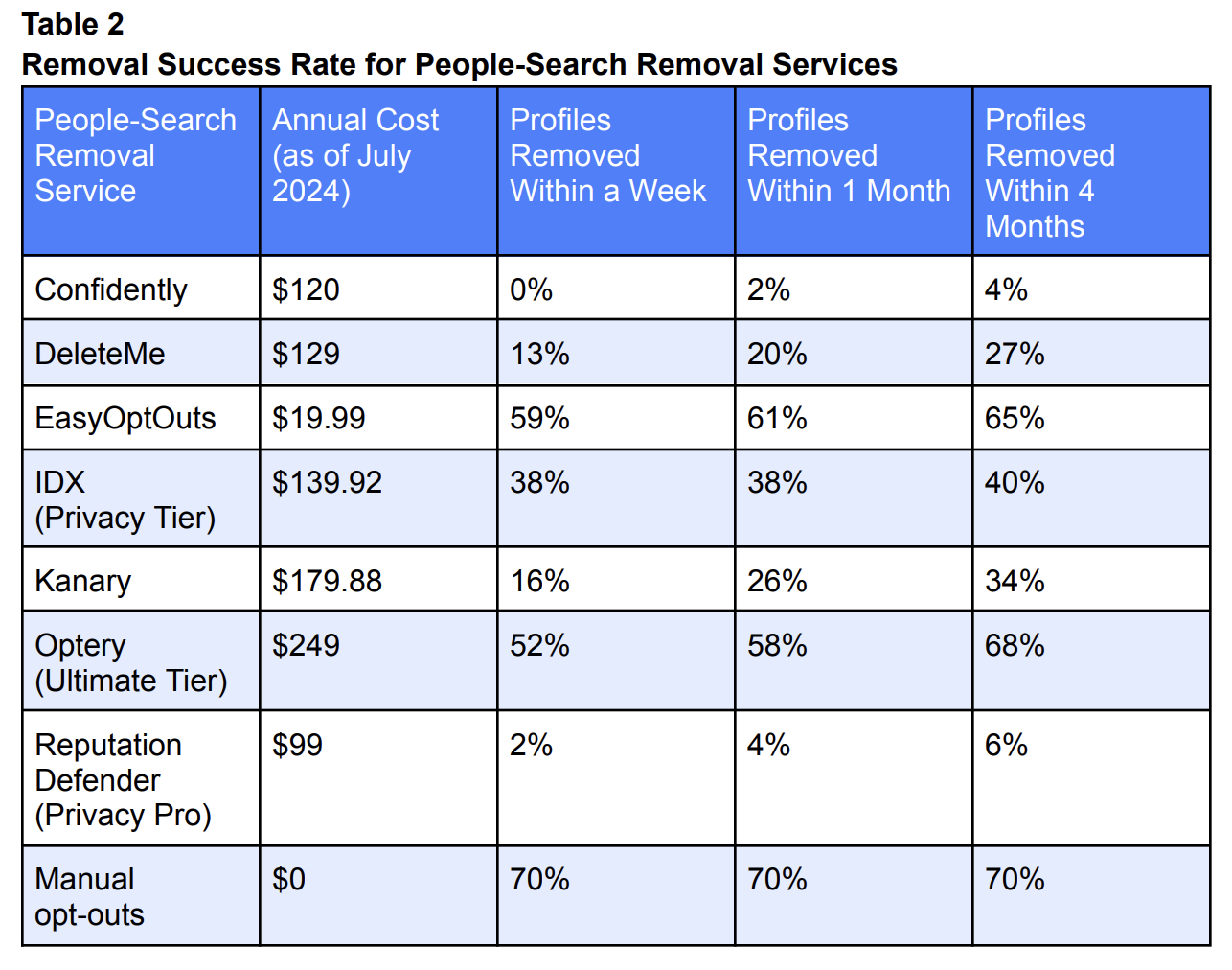
Table from Consumer Reports’ study of people-search removal services, showing effective removal rates over time for each service.
Finding a total of 332 instances of identifying information profiles on those sites, Consumer Reports found that only 117 profiles were removed within four months using all the services, or 35 percent. The services varied in efficacy, with EasyOptOuts notably performing the second-best at a 65 percent removal rate after four months. But if your goal is to remove entirely others’ ability to find out about you, no service Consumer Reports tested truly gets you there.
Manual opt-outs were the most effective removal method, at 70 percent removed within one week, which is both a higher elimination rate and quicker turn-around than all the automated services.
The study noted close ties between the people-search sites and the services that purport to clean them. Removing one volunteer’s data from ClustrMaps resulted in a page with a suggested “Next step”: signing up for privacy protection service OneRep. Firefox-maker Mozilla dropped OneRep as a service provider for its Mozilla Monitor Plus privacy bundle after reporting by Brian Krebs found that OneRep’s CEO had notable ties to the people-search industry.
In releasing this study, CR also advocates for laws at the federal and state level, like California’s Delete Act, that would make people-search removal far easier than manually scouring the web or paying for incomplete monitoring.
CR’s study cites CheckPeople, PublicDataUSA, and Intelius as the least responsive businesses in one of the least responsive industries, while noting that PeopleFinders, ClustrMaps, and ThatsThem deserve some very tiny, nearly inaudible recognition for complying with opt-out requests (our words, not theirs).
The US Department of Justice sued TikTok today, accusing the short-video platform of illegally collecting data on millions of kids and demanding a permanent injunction “to put an end to TikTok’s unlawful massive-scale invasions of children’s privacy.”
The DOJ said that TikTok had violated the Children’s Online Privacy Protection Act of 1998 (COPPA) and the Children’s Online Privacy Protection Rule (COPPA Rule), claiming that TikTok allowed kids “to create and access accounts without their parents’ knowledge or consent,” collected “data from those children,” and failed to “comply with parents’ requests to delete their children’s accounts and information.”
The COPPA Rule requires TikTok to prove that it does not target kids as its primary audience, the DOJ said, and TikTok claims to satisfy that “by requiring users creating accounts to report their birthdates.”
However, even if a child inputs their real birthdate, the DOJ said, TikTok does nothing to stop them from restarting the process and using a fake birthdate. Dodging TikTok’s age gate has been easy for millions of kids, the DOJ alleged, and TikTok knows that, collecting their information anyway and neglecting to delete information even when child users “identify themselves as children.”
“The precise magnitude” of TikTok’s violations “is difficult to determine,” the DOJ’s complaint said. But TikTok’s “internal analyses show that millions of TikTok’s US users are children under the age of 13.”
“For example, the number of US TikTok users that Defendants classified as age 14 or younger in 2020 was millions higher than the US Census Bureau’s estimate of the total number of 13- and 14-year-olds in the United States, suggesting that many of those users were children younger than 13,” the DOJ said.
TikTok seemingly risks huge fines if the DOJ proves its case. The DOJ has asked a jury to agree that damages are owed for each “collection, use, or disclosure of a child’s personal information” that violates the COPPA Rule, with likely multiple violations spanning millions of children’s accounts. And any recent violations could cost more, as the DOJ noted that the FTC Act authorizes civil penalties up to $51,744 “for each violation of the Rule assessed after January 10, 2024.”
A TikTok spokesperson told Ars that TikTok plans to fight the lawsuit, which is part of the US’s ongoing battle with the app. Currently, TikTok is fighting a nationwide ban that was passed this year, due to growing political tensions with its China-based owner and lawmakers’ concerns over TikTok’s data collection and alleged repeated spying on Americans.
“We disagree with these allegations, many of which relate to past events and practices that are factually inaccurate or have been addressed,” TikTok’s spokesperson told Ars. “We are proud of our efforts to protect children, and we will continue to update and improve the platform. To that end, we offer age-appropriate experiences with stringent safeguards, proactively remove suspected underage users, and have voluntarily launched features such as default screentime limits, Family Pairing, and additional privacy protections for minors.”
The DOJ seems to think damages are owed for past as well as possibly current violations. It claimed that TikTok already has more sophisticated ways to identify the ages of child users for ad-targeting but doesn’t use the same technology to block underage sign-ups because TikTok is allegedly unwilling to dedicate resources to widely police kids on its platform.
“By adhering to these deficient policies, Defendants actively avoid deleting the accounts of users they know to be children,” the DOJ alleged, claiming that “internal communications reveal that Defendants’ employees were aware of this issue.”
Meta continues to hit walls with its heavily scrutinized plan to comply with the European Union’s strict online competition law, the Digital Markets Act (DMA), by offering Facebook and Instagram subscriptions as an alternative for privacy-inclined users who want to opt out of ad targeting.
Today, the European Commission (EC) announced preliminary findings that Meta’s so-called “pay or consent” or “pay or OK” model—which gives users a choice to either pay for access to its platforms or give consent to collect user data to target ads—is not compliant with the DMA.
According to the EC, Meta’s advertising model violates the DMA in two ways. First, it “does not allow users to opt for a service that uses less of their personal data but is otherwise equivalent to the ‘personalized ads-based service.” And second, it “does not allow users to exercise their right to freely consent to the combination of their personal data,” the press release said.
Now, Meta will have a chance to review the EC’s evidence and defend its policy, with today’s findings kicking off a process that will take months. The EC’s investigation is expected to conclude next March. Thierry Breton, the commissioner for the internal market, said in the press release that the preliminary findings represent “another important step” to ensure Meta’s full compliance with the DMA.
“The DMA is there to give back to the users the power to decide how their data is used and ensure innovative companies can compete on equal footing with tech giants on data access,” Breton said.
A Meta spokesperson told Ars that Meta plans to fight the findings—which could trigger fines up to 10 percent of the company’s worldwide turnover, as well as fines up to 20 percent for repeat infringement if Meta loses.
Meta continues to claim that its “subscription for no ads” model was “endorsed” by the highest court in Europe, the Court of Justice of the European Union (CJEU), last year.
“Subscription for no ads follows the direction of the highest court in Europe and complies with the DMA,” Meta’s spokesperson said. “We look forward to further constructive dialogue with the European Commission to bring this investigation to a close.”
However, some critics have noted that the supposed endorsement was not an official part of the ruling and that particular case was not regarding DMA compliance.
The EC agreed that more talks were needed, writing in the press release, “the Commission continues its constructive engagement with Meta to identify a satisfactory path towards effective compliance.”
Temu—the Chinese shopping app that has rapidly grown so popular in the US that even Amazon is reportedly trying to copy it—is “dangerous malware” that’s secretly monetizing a broad swath of unauthorized user data, Arkansas Attorney General Tim Griffin alleged in a lawsuit filed Tuesday.
Griffin cited research and media reports exposing Temu’s allegedly nefarious design, which “purposely” allows Temu to “gain unrestricted access to a user’s phone operating system, including, but not limited to, a user’s camera, specific location, contacts, text messages, documents, and other applications.”
“Temu is designed to make this expansive access undetected, even by sophisticated users,” Griffin’s complaint said. “Once installed, Temu can recompile itself and change properties, including overriding the data privacy settings users believe they have in place.”
Griffin fears that Temu is capable of accessing virtually all data on a person’s phone, exposing both users and non-users to extreme privacy and security risks. It appears that anyone texting or emailing someone with the shopping app installed risks Temu accessing private data, Griffin’s suit claimed, which Temu then allegedly monetizes by selling it to third parties, “profiting at the direct expense” of users’ privacy rights.
“Compounding” risks is the possibility that Temu’s Chinese owners, PDD Holdings, are legally obligated to share data with the Chinese government, the lawsuit said, due to Chinese “laws that mandate secret cooperation with China’s intelligence apparatus regardless of any data protection guarantees existing in the United States.”
Griffin’s suit cited an extensive forensic investigation into Temu by Grizzly Research—which analyzes publicly traded companies to inform investors—last September. In their report, Grizzly Research alleged that PDD Holdings is a “fraudulent company” and that “Temu is cleverly hidden spyware that poses an urgent security threat to United States national interests.”
As Griffin sees it, Temu baits users with misleading promises of discounted, quality goods, angling to get access to as much user data as possible by adding addictive features that keep users logged in, like spinning a wheel for deals. Meanwhile hundreds of complaints to the Better Business Bureau showed that Temu’s goods are actually low-quality, Griffin alleged, apparently supporting his claim that Temu’s end goal isn’t to be the world’s biggest shopping platform but to steal data.
Investigators agreed, the lawsuit said, concluding “we strongly suspect that Temu is already, or intends to, illegally sell stolen data from Western country customers to sustain a business model that is otherwise doomed for failure.”
Seeking an injunction to stop Temu from allegedly spying on users, Griffin is hoping a jury will find that Temu’s alleged practices violated the Arkansas Deceptive Trade Practices Act (ADTPA) and the Arkansas Personal Information Protection Act. If Temu loses, it could be on the hook for $10,000 per violation of the ADTPA and ordered to disgorge profits from data sales and deceptive sales on the app.
Temu “surprised” by lawsuit
The company that owns Temu, PDD Holdings, was founded in 2015 by a former Google employee, Colin Huang. It was originally based in China, but after security concerns were raised, the company relocated its “principal executive offices” to Ireland, Griffin’s complaint said. This, Griffin suggested, was intended to distance the company from debate over national security risks posed by China, but because the majority of its business operations remain in China, risks allegedly remain.
PDD Holdings’ relocation came amid heightened scrutiny of Pinduoduo, the Chinese app on which Temu’s shopping platform is based. Last year, Pinduoduo came under fire for privacy and security risks that got the app suspended from Google Play as suspected malware. Experts said Pinduoduo took security and privacy risks “to the next level,” the lawsuit said. And “around the same time,” Apple’s App Store also flagged Temu’s data privacy terms as misleading, further heightening scrutiny of two of PDD Holdings’ biggest apps, the complaint noted.
Researchers found that Pinduoduo “was programmed to bypass users’ cell phone security in order to monitor activities on other apps, check notifications, read private messages, and change settings,” the lawsuit said. “It also could spy on competitors by tracking activity on other shopping apps and getting information from them,” as well as “run in the background and prevent itself from being uninstalled.” The motivation behind the malicious design was apparently “to boost sales.”
According to Griffin, the same concerns that got Pinduoduo suspended last year remain today for Temu users, but the App Store and Google Play have allegedly failed to take action to prevent unauthorized access to user data. Within a year of Temu’s launch, the “same software engineers and product managers who developed Pinduoduo” allegedly “were transitioned to working on the Temu app.”
Google and Apple did not immediately respond to Ars’ request for comment.
A Temu spokesperson provided a statement to Ars, discrediting Grizzly Research’s investigation and confirming that the company was “surprised and disappointed by the Arkansas Attorney General’s Office for filing the lawsuit without any independent fact-finding.”
“The allegations in the lawsuit are based on misinformation circulated online, primarily from a short-seller, and are totally unfounded,” Temu’s spokesperson said. “We categorically deny the allegations and will vigorously defend ourselves.”
While Temu plans to defend against claims, the company also seems to potentially be open to making changes based on criticism lobbed in Griffin’s complaint.
“We understand that as a new company with an innovative supply chain model, some may misunderstand us at first glance and not welcome us,” Temu’s spokesperson said. “We are committed to the long-term and believe that scrutiny will ultimately benefit our development. We are confident that our actions and contributions to the community will speak for themselves over time.”
In a statement provided to Ars, users’ lawyer, David Boies, described the settlement as “a historic step in requiring honesty and accountability from dominant technology companies.” Based on Google’s insights, users’ lawyers valued the settlement between $4.75 billion and $7.8 billion, the Monday court filing said.
Under the settlement, Google agreed to delete class-action members’ private browsing data collected in the past, as well as to “maintain a change to Incognito mode that enables Incognito users to block third-party cookies by default.” This, plaintiffs’ lawyers noted, “ensures additional privacy for Incognito users going forward, while limiting the amount of data Google collects from them” over the next five years. Plaintiffs’ lawyers said that this means that “Google will collect less data from users’ private browsing sessions” and “Google will make less money from the data.”
“The settlement stops Google from surreptitiously collecting user data worth, by Google’s own estimates, billions of dollars,” Boies said. “Moreover, the settlement requires Google to delete and remediate, in unprecedented scope and scale, the data it improperly collected in the past.”
Google had already updated disclosures to users, changing the splash screen displayed “at the beginning of every Incognito session” to inform users that Google was still collecting private browsing data. Under the settlement, those disclosures to all users must be completed by March 31, after which the disclosures must remain. Google also agreed to “no longer track people’s choice to browse privately,” and the court filing said that “Google cannot roll back any of these important changes.”
Notably, the settlement does not award monetary damages to class members. Instead, Google agreed that class members retain “rights to sue Google individually for damages” through arbitration, which, users’ lawyers wrote, “is important given the significant statutory damages available under the federal and state wiretap statutes.”
“These claims remain available for every single class member, and a very large number of class members recently filed and are continuing to file complaints in California state court individually asserting those damages claims in their individual capacities,” the court filing said.
While “Google supports final approval of the settlement,” the company “disagrees with the legal and factual characterizations contained in the motion,” the court filing said. Google spokesperson José Castañeda told Ars that the tech giant thinks that the “data being deleted isn’t as significant” as Boies represents, confirming that Google was “pleased to settle this lawsuit, which we always believed was meritless.”
“The plaintiffs originally wanted $5 billion and are receiving zero,” Castañeda said. “We never associate data with users when they use Incognito mode. We are happy to delete old technical data that was never associated with an individual and was never used for any form of personalization.”
While Castañeda said that Google was happy to delete the data, a footnote in the court filing noted that initially, “Google claimed in the litigation that it was impossible to identify (and therefore delete) private browsing data because of how it stored data.” Now, under the settlement, however, Google has agreed “to remediate 100 percent of the data set at issue.”
Mitigation efforts include deleting fields Google used to detect users in Incognito mode, “partially redacting IP addresses,” and deleting “detailed URLs, which will prevent Google from knowing the specific pages on a website a user visited when in private browsing mode.” Keeping “only the domain-level portion of the URL (i.e., only the name of the website) will vastly improve user privacy by preventing Google (or anyone who gets their hands on the data) from knowing precisely what users were browsing,” the court filing said.
Because Google did not oppose the motion for final approval, US District Judge Yvonne Gonzalez Rogers is expected to issue an order approving the settlement on July 30.
On Monday, Florida became the first state to ban kids under 14 from social media without parental permission. It appears likely that the law—considered one of the most restrictive in the US—will face significant legal challenges, however, before taking effect on January 1.
Under HB 3, apps like Instagram, Snapchat, or TikTok would need to verify the ages of users, then delete any accounts for users under 14 when parental consent is not granted. Companies that “knowingly or recklessly” fail to block underage users risk fines of up to $10,000 in damages to anyone suing on behalf of child users. They could also be liable for up to $50,000 per violation in civil penalties.
In a statement, Florida governor Ron DeSantis said the “landmark law” gives “parents a greater ability to protect their children” from a variety of social media harm. Florida House Speaker Paul Renner, who spearheaded the law, explained some of that harm, saying that passing HB 3 was critical because “the Internet has become a dark alley for our children where predators target them and dangerous social media leads to higher rates of depression, self-harm, and even suicide.”
But tech groups critical of the law have suggested that they are already considering suing to block it from taking effect.
In a statement provided to Ars, a nonprofit opposing the law, the Computer & Communications Industry Association (CCIA) said that while CCIA “supports enhanced privacy protections for younger users online,” it is concerned that “any commercially available age verification method that may be used by a covered platform carries serious privacy and security concerns for users while also infringing upon their First Amendment protections to speak anonymously.”
“This law could create substantial obstacles for young people seeking access to online information, a right afforded to all Americans regardless of age,” Khara Boender, CCIA’s state policy director, warned. “It’s foreseeable that this legislation may face legal opposition similar to challenges seen in other states.”
Carl Szabo, vice president and general counsel for Netchoice—a trade association with members including Meta, TikTok, and Snap—went even further, warning that Florida’s “unconstitutional law will protect exactly zero Floridians.”
Szabo suggested that there are “better ways to keep Floridians, their families, and their data safe and secure online without violating their freedoms.” Democratic state house representative Anna Eskamani opposed the bill, arguing that “instead of banning social media access, it would be better to ensure improved parental oversight tools, improved access to data to stop bad actors, alongside major investments in Florida’s mental health systems and programs.”
Netchoice expressed “disappointment” that DeSantis agreed to sign a law requiring an “ID for the Internet” after “his staunch opposition to this idea both on the campaign trail” and when vetoing a prior version of the bill.
“HB 3 in effect will impose an ‘ID for the Internet’ on any Floridian who wants to use an online service—no matter their age,” Szabo said, warning of invasive data collection needed to verify that a user is under 14 or a parent or guardian of a child under 14.
“This level of data collection will put Floridians’ privacy and security at risk, and it violates their constitutional rights,” Szabo said, noting that in court rulings in Arkansas, California, and Ohio over similar laws, “each of the judges noted the similar laws’ constitutional and privacy problems.”
Mozilla’s most recent move to protect privacy has been to cut out one of the key providers of Monitor Plus’ people-search protections, Onerep. That comes after reporting from security reporter Brian Krebs, who uncovered Onerep CEO and founder Dimitri Shelest as the founder of “dozens of people-search services since 2010,” including one, Nuwber, that still sells the very kind of “background reports” that Monitor Plus seeks to curb.
Shelest told Krebs in a statement (PDF) that he did have an ownership stake in Nuwber, but that Nuwber has “zero cross-over or information-sharing with Onerep” and that he no longer operates any other people-search sites. Shelest admitted the bad look but said that his experience with people search gave Onerep “the best tech and team in the space.”
Brandon Borrman, vice president of communications at Mozilla, said in a statement that while “customer data was never at risk, the outside financial interests and activities of Onerep’s CEO do not align with our values.” Mozilla is “working now to solidify a transition plan,” Borrman said. A Mozilla spokesperson confirmed to Ars today that Mozilla is continuing to offer Monitor Plus, suggesting no pause in subscriptions, at least for the moment.
Monitor Plus also kept track of a user’s potential data breach exposures in partnership with HaveIBeenPwned. Troy Hunt, founder of HaveIBeenPwned, told Krebs that aside from Onerep’s potential conflict of interest, broker removal services tend to be inherently fraught. “[R]emoving your data from legally operating services has minimal impact, and you can’t remove it from the outright illegal ones who are doing the genuine damage.”
Still, every bit—including removing yourself from the first page of search results—likely counts. Beyond sites that scrape public records and court documents for your information, there are the other data brokers selling barely anonymized data from web browsing, app sign-ups, and other activity. A recent FTC settlement with antivirus and security firm Avast highlighted the depth of identifying information that often is available for sale to both commercial and government entities.



















{kind=link}
{kind=link}