Many of you know that most of our staff is spread out all over these United States, but what you might not know is that it has been more than five years since many of us saw each other in meatspace. Travel budgets and the pandemic conspired to keep us apart, but we are finally gathering Team Ars in New York City later this week. We’d love for you to be there, too, in spirit.
As we gear up for our big fall meeting, we want to hear from you! We’ve set up a special email address, [email protected], just for reader feedback. We won’t harvest your email for spam or some nonsense—we just want to hear from you.
What would we like to hear about? We’re eager to know your thoughts on what we’re doing right, where we could improve, and what you’d like to see more (or less) of. What topics do you think we should be covering that we aren’t? Are we hitting the right balance in our reporting? Is there too much doom and gloom, or not enough? Feel free to be as specific and loquacious as you wish.
This is your chance to speak directly to us and influence our future direction. While we welcome comments on this post, emailing your feedback to [email protected] will help us better organize and address your thoughts during our meeting.
Thanks in advance for helping us make Ars even better!
Whew—the big event is finally behind us. I’m talking, of course, about the Ars Technica version 9 redesign, which we rolled out last month in response to your survey feedback and which we have iterated on extensively in the weeks since. The site is now fully responsive and optimized for mobile browsing, with a sleek new look and great user options.
In response to your comments, our tireless tech and design team of Jason and Aurich have spent the last few weeks adding a font size selector, tweaking the default font and headline layout, and adding the option for orange hyperlinks. Plus, they rolled out an all-new, subscriber-only “wide mode” for Ars superfans who need 100+ character line lengths in their lives. Not enough? Jason and Aurich also tweaked the overall information density (especially on mobile), added next/previous story buttons to articles, and made the nav bar “sticky” on mobile, all in response to your feedback. (Read more about our two post-launch rounds of updates here and here.)
If that’s still not enough site goodness, Jason and Aurich are currently locked in their laboratory, cooking up a brand-new “true light” theme and big improvements to commenting and comment voting.
So while they’re brewing up those potions, I wanted to take a moment to highlight our subscription offering. At just $25 a year, this is a great deal that does more than just support our fully unionized staff; it also offers real quality-of-life benefits to readers. Subs don’t see any ads, nor are they served any trackers. They get access to the ultra-dense “Neutron Star” layout and the bloggy “Ars Classic” view, along with the optional wide-text mode and the ability to filter topics. (Plus full-text RSS feeds, PDF downloads, and some other little goodies.)
We love all the feedback that Ars readers have submitted since we rolled out the Ars Technica 9.0 design last week—even the, err, deeply passionate remarks. It’s humbling that, after 26 years, so many people still care so much about making Ars into the best possible version of itself.
Based on your feedback, we’ve just pushed a new update to the site that we hope fixes many readers’ top concerns. (You might need to hard-refresh to see it.)
Much of the feedback (forum posts, email, DMs, the Ars comment form) has told us that the chief goals of the redesign—more layout options, larger text, better readability—were successful. But readers have also offered up interesting edge cases and different use patterns for which design changes would be useful. Though we can’t please everyone, we will continue to make iterative design tweaks so that the site can work well for as many people as possible.
So here’s a quick post about what we’ve done so far and what we’re going to be working on over the next few weeks. As usual, continued feedback is welcome and appreciated!
Changes made and changes planned
The 9.0 design was based on reader feedback; an astonishing 20,000 people took our most recent reader survey, and most of these readers don’t post in the comments or the Ars forums. The consensus was that readability and customization were the most significant site design issues. We’ve addressed those through (among other things) a responsive design that unifies desktop and mobile codebases, increased text size to meet modern standards, and four site layout options (Classic, Grid, List, and the super-dense Neutron Star view).
As you can see, we’ve refreshed the site design. We hope you’ll come to love it. Ars Technica is a little more than 26 years old, yet this is only our ninth site relaunch (number eight was rolled out way back in 2016!).
We think the Ars experience gets better with each iteration, and this time around, we’ve brought a ton of behind-the-scenes improvements aimed squarely at making the site faster, more readable, and more customizable. We’ve added responsive design, larger text, and more viewing options. We’ve also added the highly requested “Most Read” box so you can find our hottest stories at a glance. And if you’re a subscriber, you can now hide certain topics that we cover—and never see those stories again.
(Most of these changes were driven by your feedback to our big reader survey back in 2022. We can’t thank you enough for giving us your time with these surveys, and we hope to have another one for you before too long.)
We know that change is unsettling, and no matter how much we test internally, a new design will also contain a few bugs, edge cases, and layout oddities. As always, we’ll be monitoring the comments on this article and making adjustments for the next couple of weeks, so please report any bugs or concerns you run into. (And please be patient with the process—we’re a small team!)
The two big changes
One of the major changes to the site in this redesign has been a long time coming: Ars is now fully responsive across desktop and mobile devices. For various reasons, we have maintained separate code bases for desktop and mobile over the years, but that has come to an end—everything is now unified. All site features will work regardless of device or browser/window width. (This change will likely produce the most edge cases since we can’t test on all devices.)
The other significant change is that Ars now uses a much larger default text size. This has been the trend with basically every site since our last design overhaul, and we’re normalizing to that. People with aging eyes (like me!) should appreciate this, and mobile users should find things easier to read in general. You can, of course, change it to suit your preferences.
Most other changes are smaller in scope. We’re not introducing anything radically different in our stories or presentation, just trying to make everything work better and feel nicer.
Smaller tweaks
The front-page experience largely remains what you know, with some new additions. Our focus here was on two things:
Providing more options to let people control how they read Ars
Giving our subscribers the best experience we can
To that end, we now have four different ways to view the front page. They’re not buried in a menu but are right at the top of the page, arranged in order of information “density.” The four views are called:
Classic: A subscriber-only mode—basically, what’s already available to current subs. Gives you an old-school “blog” format. You can scroll and see the opening paragraphs of every story. Click on those you want to read.
Grid: The default view, an updated version of what we currently have. We’re trying some new ways of presenting stories so that the page feels like it has a little more hierarchy while still remaining almost completely reverse-chronological.
List: Very much like our current list view. If you just want a reverse chronology with fewer bells and whistles, this is for you.
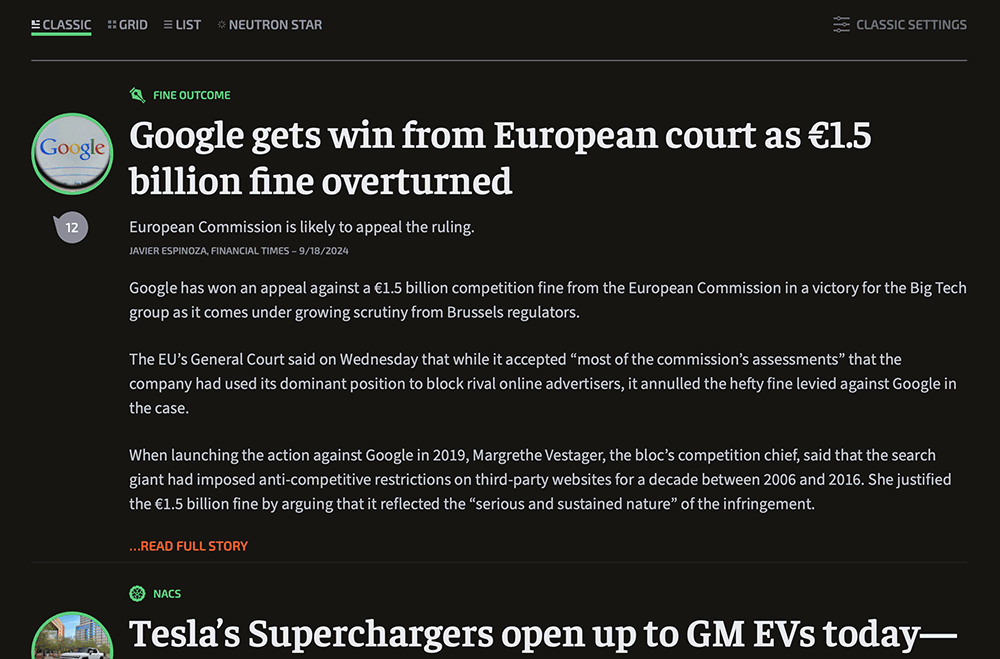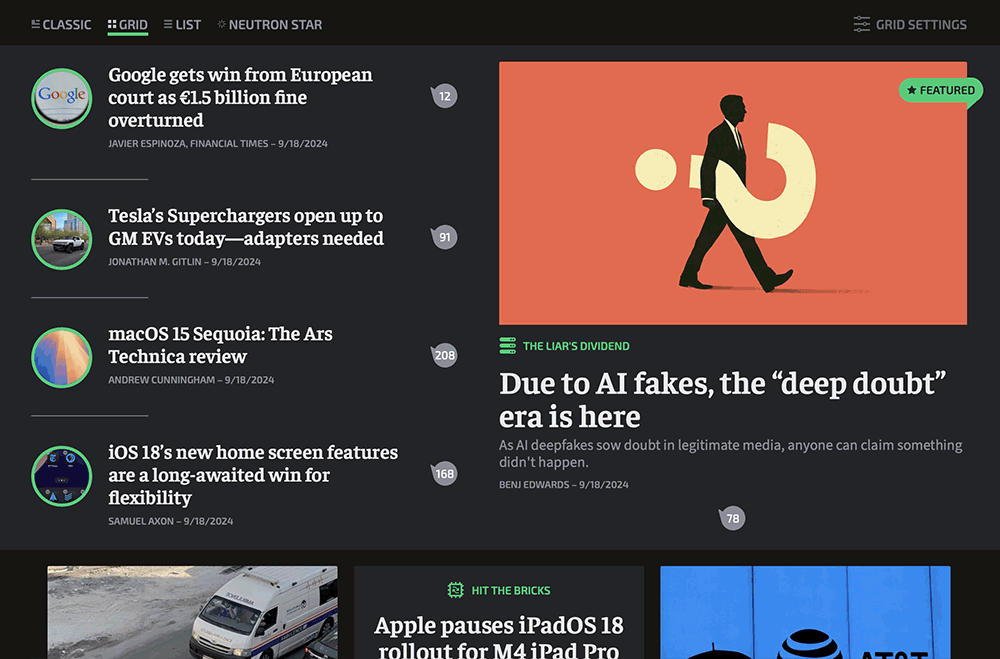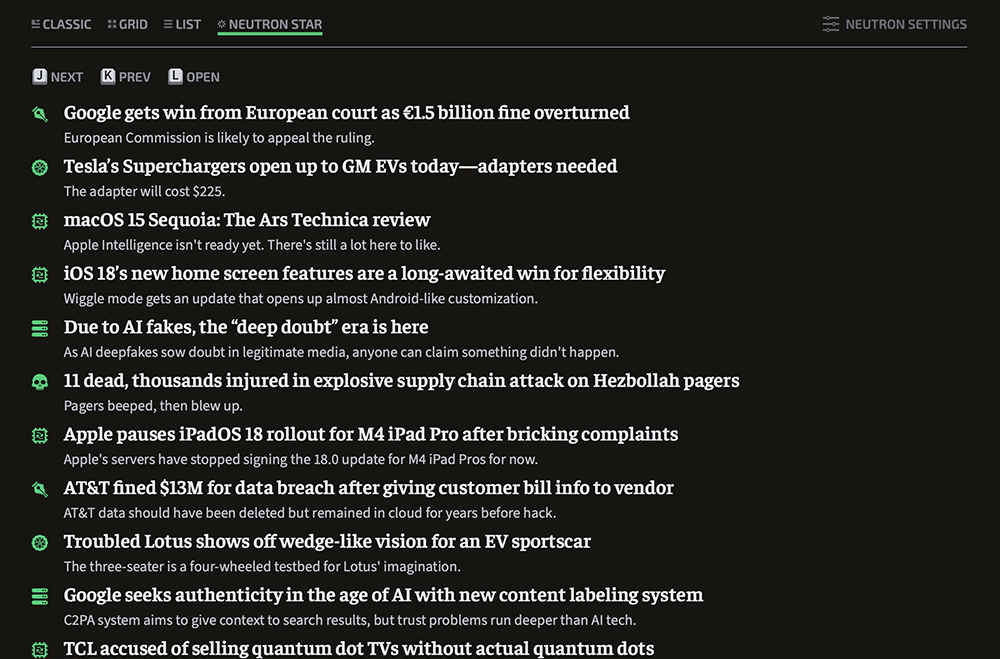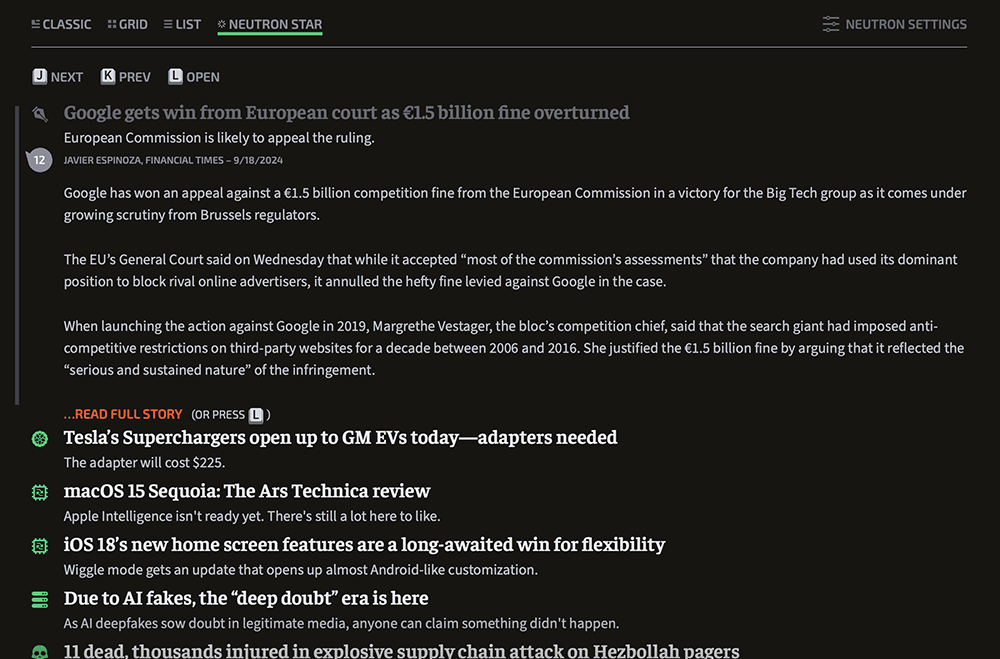
Neutron Star: The densest mode we’ve ever offered—and another subscriber-only perk. Neutron Star shows only headlines and lower decks, with no images or introductory paragraphs. It’s completely keyboard navigable. You can key your way through stories, opening and collapsing headlines to see a preview. If you want a minimal, text-focused, power-user interface, this is it.
The sub-only modes will offer non-subscribers a visual preview for anyone who wants to see them in action.
Another feature we’re adding is a “Most Read” box. Top stories from the last 24 hours will show up there, and the box is updated in real time. We’ve never offered readers a view into what stories are popping quite like this, and I’m excited to have it.
If you’re a subscriber, you can also customize this box to any single section you’d like. For instance, if you change it to Space, you will see only the top space stories here.
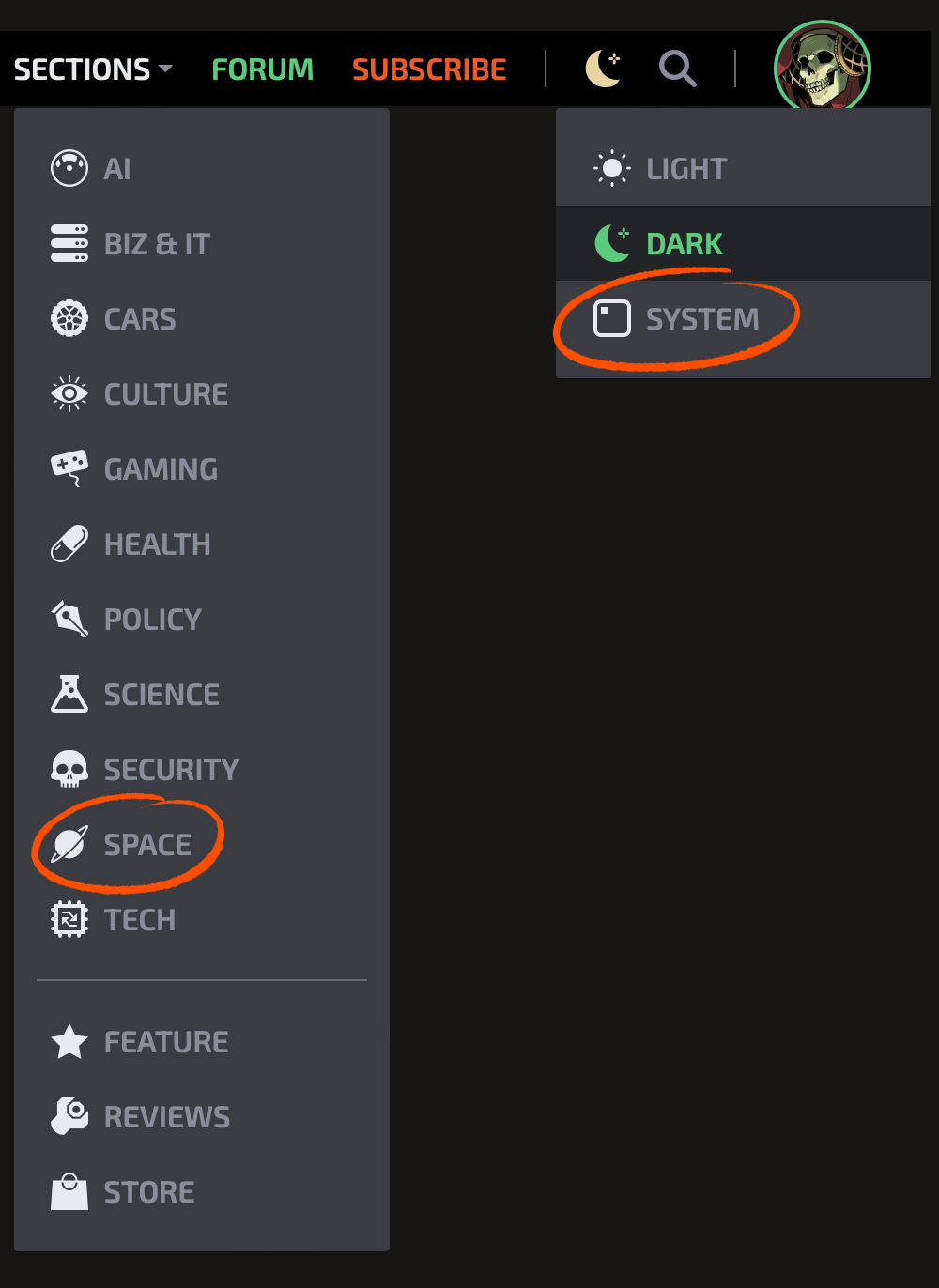
Speaking of sections, we’re breaking out all of our regular beats into their own sections now, so it will be much easier to find just space or health or AI or security stories.
And as long as we’re looking at menus, of course our old friend “dark mode” is still here (and is used in all my screenshots), but for those who like to switch their preference automatically by system setting, we now offer that option, too.
Not interested in a topic? Hide it
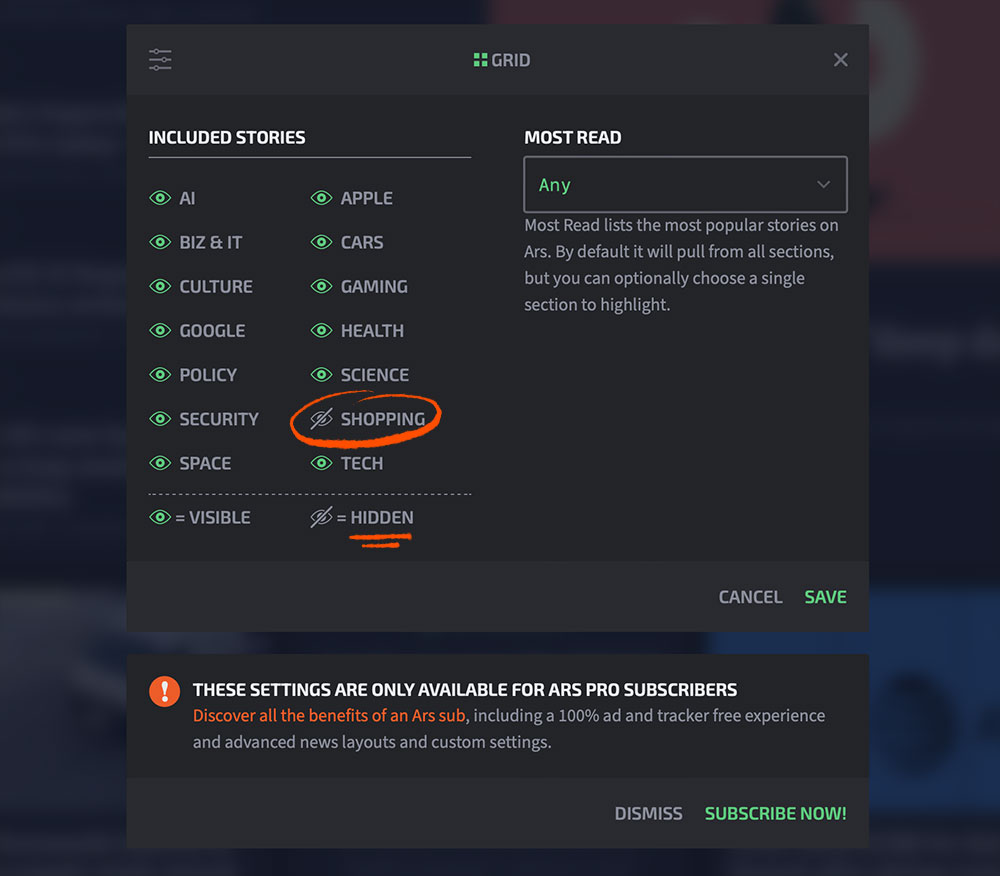
Our last reader survey generated a ton of responses. When we asked about potential new subscriber features, we heard a clear message: People wanted the ability to hide topics that didn’t interest them. So as a new and subscriber-only feature, we’re offering the ability to hide particular topic areas.
In this example, subscribers can hide the occasional shopping posts we still do for things like Amazon sales days. Or maybe you want to skip articles about cars, or you don’t want to see Apple content. Just hide it. As you can see, we’re adding a few more categories here than exist in our actual site navigation so that people aren’t forced to hide entire topic areas to avoid one company or product. We don’t have an Apple or a Google section on the site, for instance, but “Apple” and “Google” stories can still be hidden.
A little experimenting may be needed to dial this in, but please share your feedback; we’ll work out any kinks as people use the tool for a while and report back.
Ars longa, vita brevis
This is our ninth significant redesign in the 26-year history of Ars Technica. Putting on my EIC hat in the late ’90s, I couldn’t have imagined that we’d be around in 2024, let alone being stronger than ever, reaching millions of readers around the globe each month with tech news, analysis, and hilarious updates on the smart-homification of Lee’s garage. In a world of shrinking journalism budgets, your support has enabled us to employ a fully unionized staff of writers and editors while rolling out quality-of-life updates to the reading experience that came directly from your feedback.
Everyone wants your subscription dollars these days, but we’ve tried hard to earn them at Ars by putting readers first. And while we don’t have a paywall, we hope you’ll see a subscription as the perfect way to support our content, sustainably nix ads and tracking, and get special features like new view modes and topic hiding. (Oh—and our entry-level subscription is still just $25/year, the same price it was in 2000.)
So thanks for reading, subscribing, and supporting us through the inevitable growing pains that accompany another redesign. Truly, we couldn’t do any of it without you.
And a special note of gratitude goes out to our battalion of two, Ars Creative Director Aurich Lawson and Ars Technical Director Jason Marlin. Not only have they done all the heavy lifting to make this happen, but they did it while juggling everything else we throw at them.
On Tuesday, OpenAI announced a partnership with Ars Technica parent company Condé Nast to display content from prominent publications within its AI products, including ChatGPT and a new SearchGPT prototype. It also allows OpenAI to use Condé content to train future AI language models. The deal covers well-known Condé brands such as Vogue, The New Yorker, GQ, Wired, Ars Technica, and others. Financial details were not disclosed.
One immediate effect of the deal will be that users of ChatGPT or SearchGPT will now be able to see information from Condé Nast publications pulled from those assistants’ live views of the web. For example, a user could ask ChatGPT, “What’s the latest Ars Technica article about Space?” and ChatGPT can browse the web and pull up the result, attribute it, and summarize it for users while also linking to the site.
In the longer term, the deal also means that OpenAI can openly and officially utilize Condé Nast articles to train future AI language models, which includes successors to GPT-4o. In this case, “training” means feeding content into an AI model’s neural network so the AI model can better process conceptual relationships.
AI training is an expensive and computationally intense process that happens rarely, usually prior to the launch of a major new AI model, although a secondary process called “fine-tuning” can continue over time. Having access to high-quality training data, such as vetted journalism, improves AI language models’ ability to provide accurate answers to user questions.
It’s worth noting that Condé Nast internal policy still forbids its publications from using text created by generative AI, which is consistent with its AI rules before the deal.
Not waiting on fair use
With the deal, Condé Nast joins a growing list of publishers partnering with OpenAI, including Associated Press, Axel Springer, The Atlantic, and others. Some publications, such as The New York Times, have chosen to sue OpenAI over content use, and there’s reason to think they could win.
In an internal email to Condé Nast staff, CEO Roger Lynch framed the multi-year partnership as a strategic move to expand the reach of the company’s content, adapt to changing audience behaviors, and ensure proper compensation and attribution for using the company’s IP. “This partnership recognizes that the exceptional content produced by Condé Nast and our many titles cannot be replaced,” Lynch wrote in the email, “and is a step toward making sure our technology-enabled future is one that is created responsibly.”
The move also brings additional revenue to Condé Nast, Lynch added, at a time when “many technology companies eroded publishers’ ability to monetize content, most recently with traditional search.” The deal will allow Condé to “continue to protect and invest in our journalism and creative endeavors,” Lynch wrote.
OpenAI COO Brad Lightcap said in a statement, “We’re committed to working with Condé Nast and other news publishers to ensure that as AI plays a larger role in news discovery and delivery, it maintains accuracy, integrity, and respect for quality reporting.”
On Tuesday, AI-powered search engine Perplexity unveiled a new revenue-sharing program for publishers, marking a significant shift in its approach to third-party content use, reports CNBC. The move comes after plagiarism allegations from major media outlets, including Forbes, Wired, and Ars parent company Condé Nast. Perplexity, valued at over $1 billion, aims to compete with search giant Google.
“To further support the vital work of media organizations and online creators, we need to ensure publishers can thrive as Perplexity grows,” writes the company in a blog post announcing the problem. “That’s why we’re excited to announce the Perplexity Publishers Program and our first batch of partners: TIME, Der Spiegel, Fortune, Entrepreneur, The Texas Tribune, and WordPress.com.”
Under the program, Perplexity will share a percentage of ad revenue with publishers when their content is cited in AI-generated answers. The revenue share applies on a per-article basis and potentially multiplies if articles from a single publisher are used in one response. Some content providers, such as WordPress.com, plan to pass some of that revenue on to content creators.
A press release from WordPress.com states that joining Perplexity’s Publishers Program allows WordPress.com content to appear in Perplexity’s “Keep Exploring” section on their Discover pages. “That means your articles will be included in their search index and your articles can be surfaced as an answer on their answer engine and Discover feed,” the blog company writes. “If your website is referenced in a Perplexity search result where the company earns advertising revenue, you’ll be eligible for revenue share.”
Enlarge/ A screenshot of the Perplexity.ai website taken on July 30, 2024.
Benj Edwards
Dmitry Shevelenko, Perplexity’s chief business officer, told CNBC that the company began discussions with publishers in January, with program details solidified in early 2024. He reported strong initial interest, with over a dozen publishers reaching out within hours of the announcement.
As part of the program, publishers will also receive access to Perplexity APIs that can be used to create custom “answer engines” and “Enterprise Pro” accounts that provide “enhanced data privacy and security capabilities” for all employees of Publishers in the program for one year.
Accusations of plagiarism
The revenue-sharing announcement follows a rocky month for the AI startup. In mid-June, Forbes reported finding its content within Perplexity’s Pages tool with minimal attribution. Pages allows Perplexity users to curate content and share it with others. Ars Technica sister publication Wired later made similar claims, also noting suspicious traffic patterns from IP addresses likely linked to Perplexity that were ignoring robots.txt exclusions. Perplexity was also found to be manipulating its crawling bots’ ID string to get around website blocks.
As part of company policy, Ars Technica parent Condé Nast disallows AI-based content scrapers, and its CEO Roger Lynch testified in the US Senate earlier this year that generative AI has been built with “stolen goods.” Condé sent a cease-and-desist letter to Perplexity earlier this month.
But publisher trouble might not be Perplexity’s only problem. In some tests of the search we performed in February, Perplexity badly confabulated certain answers, even when citations were readily available. Since our initial tests, the accuracy of Perplexity’s results seems to have improved, but providing inaccurate answers (which also plagued Google’s AI Overviews search feature) is still a potential issue.
Compared to the free tier of service, Perplexity users who pay $20 per month can access more capable LLMs such as GPT-4o and Claude 3, so the quality and accuracy of the output can vary dramatically depending on whether a user subscribes or not. The addition of citations to every Perplexity answer allows users to check accuracy—if they take the time to do it.
The move by Perplexity occurs against a backdrop of tensions between AI companies and content creators. Some media outlets, such as The New York Times, have filed lawsuits against AI vendors like OpenAI and Microsoft, alleging copyright infringement in the training of large language models. OpenAI has struck media licensing deals with many publishers as a way to secure access to high-quality training data and avoid future lawsuits.
In this case, Perplexity is not using the licensed articles and content to train AI models but is seeking legal permission to reproduce content from publishers on its website.
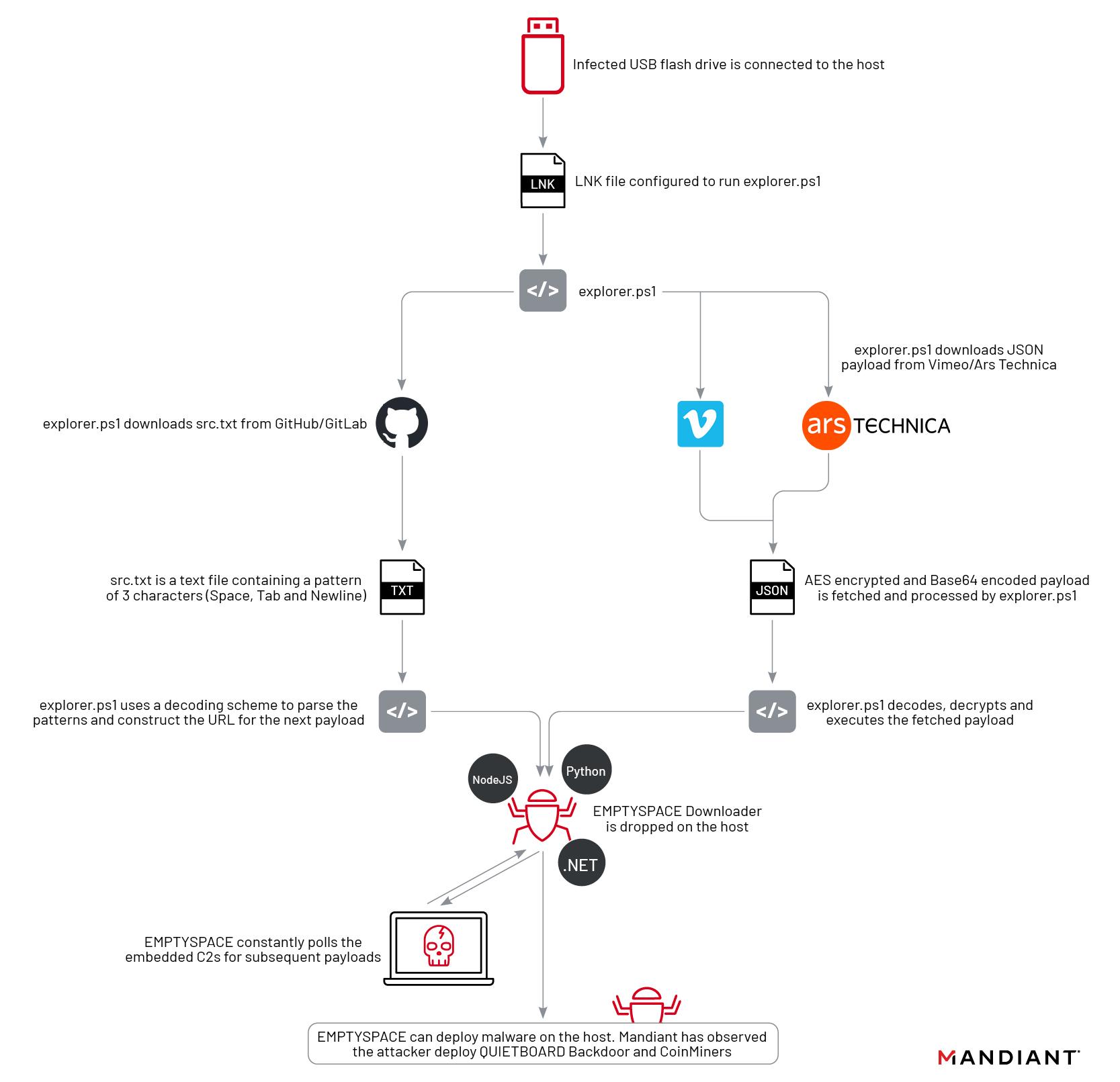
Ars Technica was recently used to serve second-stage malware in a campaign that used a never-before-seen attack chain to cleverly cover its tracks, researchers from security firm Mandiant reported Tuesday.
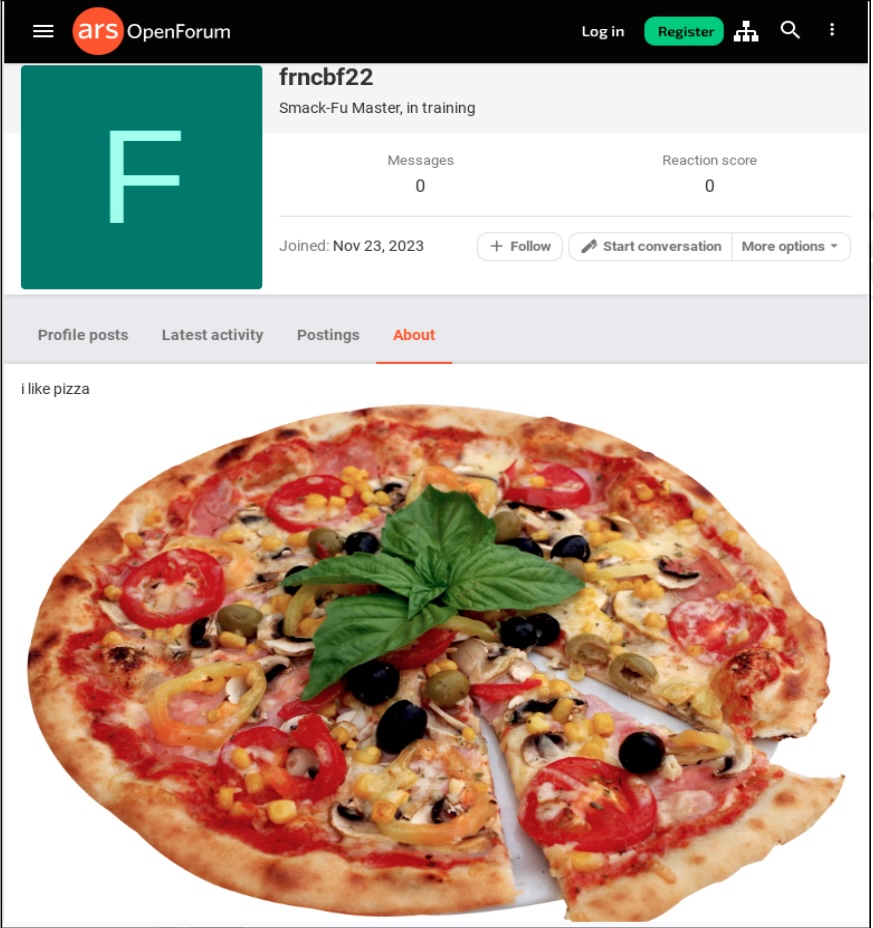
A benign image of a pizza was uploaded to a third-party website and was then linked with a URL pasted into the “about” page of a registered Ars user. Buried in that URL was a string of characters that appeared to be random—but were actually a payload. The campaign also targeted the video-sharing site Vimeo, where a benign video was uploaded and a malicious string was included in the video description. The string was generated using a technique known as Base 64 encoding. Base 64 converts text into a printable ASCII string format to represent binary data. Devices already infected with the first-stage malware used in the campaign automatically retrieved these strings and installed the second stage.
Not typically seen
“This is a different and novel way we’re seeing abuse that can be pretty hard to detect,” Mandiant researcher Yash Gupta said in an interview. “This is something in malware we have not typically seen. It’s pretty interesting for us and something we wanted to call out.”
The image posted on Ars appeared in the about profile of a user who created an account on November 23. An Ars representative said the photo, showing a pizza and captioned “I love pizza,” was removed by Ars staff on December 16 after being tipped off by email from an unknown party. The Ars profile used an embedded URL that pointed to the image, which was automatically populated into the about page. The malicious base 64 encoding appeared immediately following the legitimate part of the URL. The string didn’t generate any errors or prevent the page from loading.
Mandiant researchers said there were no consequences for people who may have viewed the image, either as displayed on the Ars page or on the website that hosted it. It’s also not clear that any Ars users visited the about page.
Devices that were infected by the first stage automatically accessed the malicious string at the end of the URL. From there, they were infected with a second stage.
The video on Vimeo worked similarly, except that the string was included in the video description.
Ars representatives had nothing further to add. Vimeo representatives didn’t immediately respond to an email.
The campaign came from a threat actor Mandiant tracks as UNC4990, which has been active since at least 2020 and bears the hallmarks of being motivated by financial gain. The group has already used a separate novel technique to fly under the radar. That technique spread the second stage using a text file that browsers and normal text editors showed to be blank.
Opening the same file in a hex editor—a tool for analyzing and forensically investigating binary files—showed that a combination of tabs, spaces, and new lines were arranged in a way that encoded executable code. Like the technique involving Ars and Vimeo, the use of such a file is something the Mandiant researchers had never seen before. Previously, UNC4990 used GitHub and GitLab.
The initial stage of the malware was transmitted by infected USB drives. The drives installed a payload Mandiant has dubbed explorerps1. Infected devices then automatically reached out to either the malicious text file or else to the URL posted on Ars or the video posted to Vimeo. The base 64 strings in the image URL or video description, in turn, caused the malware to contact a site hosting the second stage. The second stage of the malware, tracked as Emptyspace, continuously polled a command-and-control server that, when instructed, would download and execute a third stage.
Mandiant
Mandiant has observed the installation of this third stage in only one case. This malware acts as a backdoor the researchers track as Quietboard. The backdoor, in that case, went on to install a cryptocurrency miner.
Anyone who is concerned they may have been infected by any of the malware covered by Mandiant can check the indicators of compromise section in Tuesday’s post.