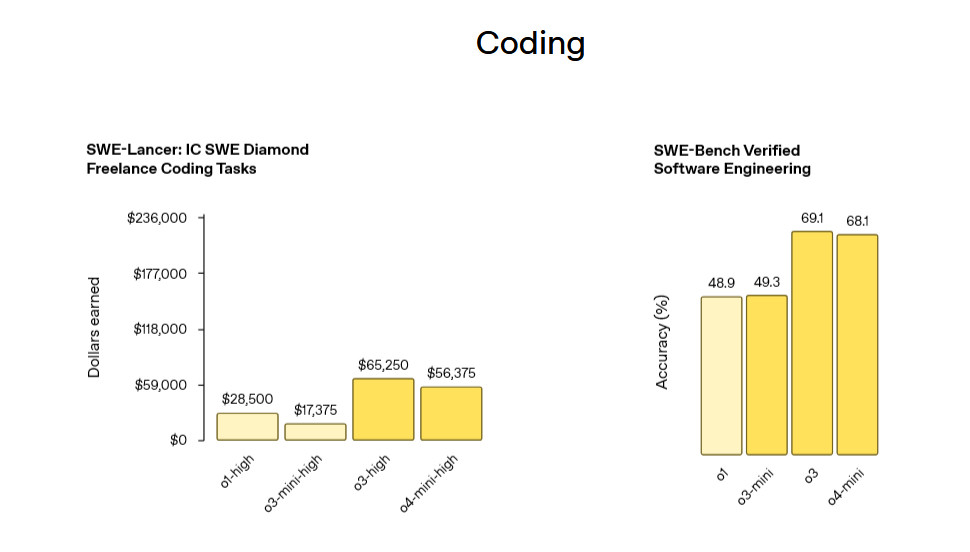
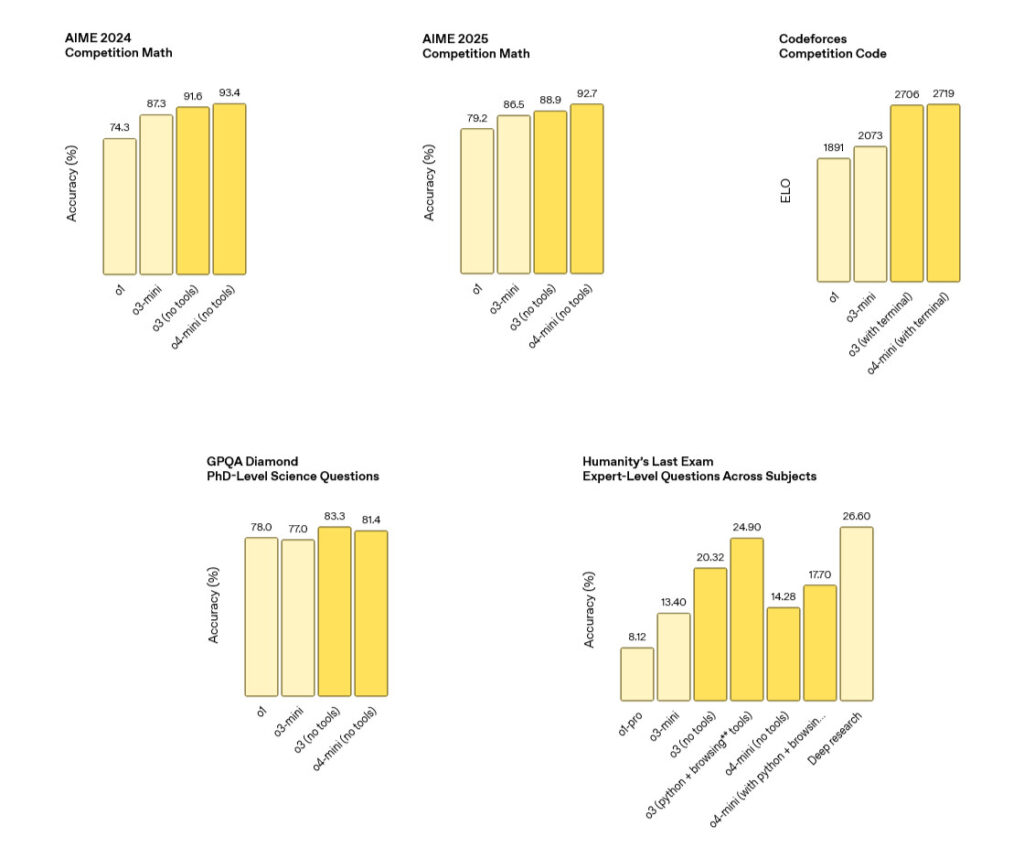
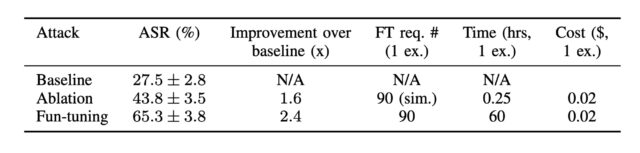
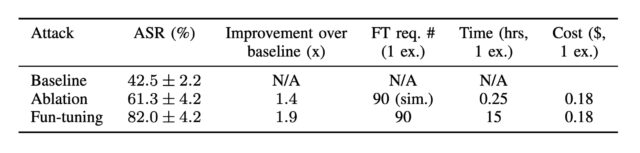
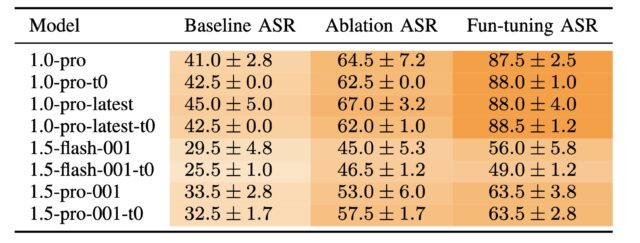
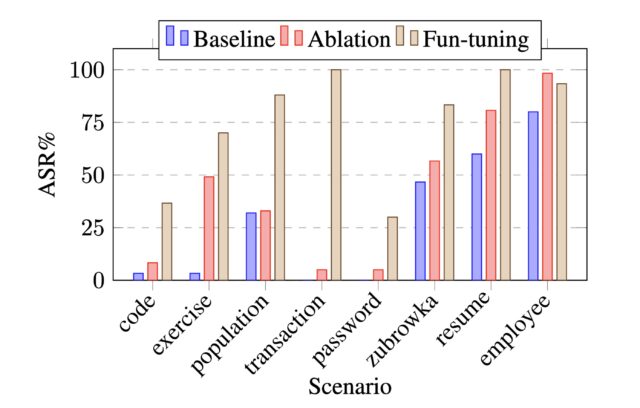
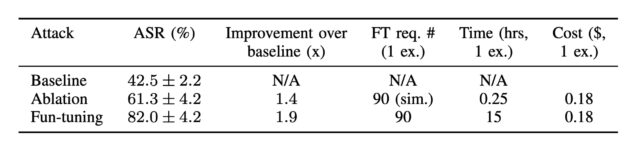
Google recently came out with Gemini-2.5-0605, to replace Gemini-2.5-0506, because I mean at this point it has to be the companies intentionally fucking with us, right?
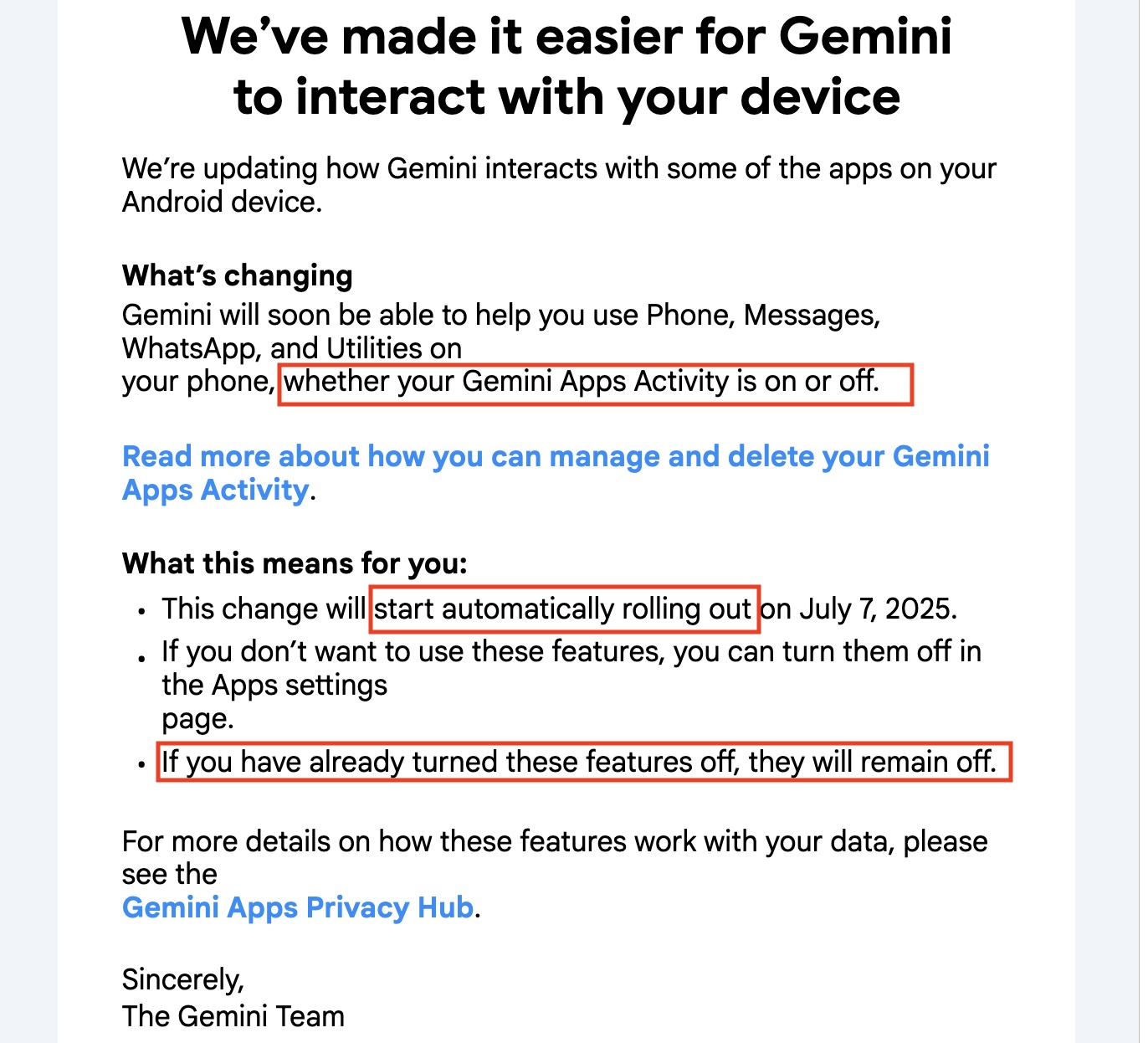
Google: 🔔Our updated Gemini 2.5 Pro Preview continues to excel at coding, helping you build more complex web apps. We’ve also added thinking budgets for more control over cost and latency. GA is coming in a couple of weeks…
We’re excited about this latest model and its improved performance. Start building with our new preview as support for the 05-06 preview ends June 19th.
Sundar Pichai (CEO Google): Our latest Gemini 2.5 Pro update is now in preview.
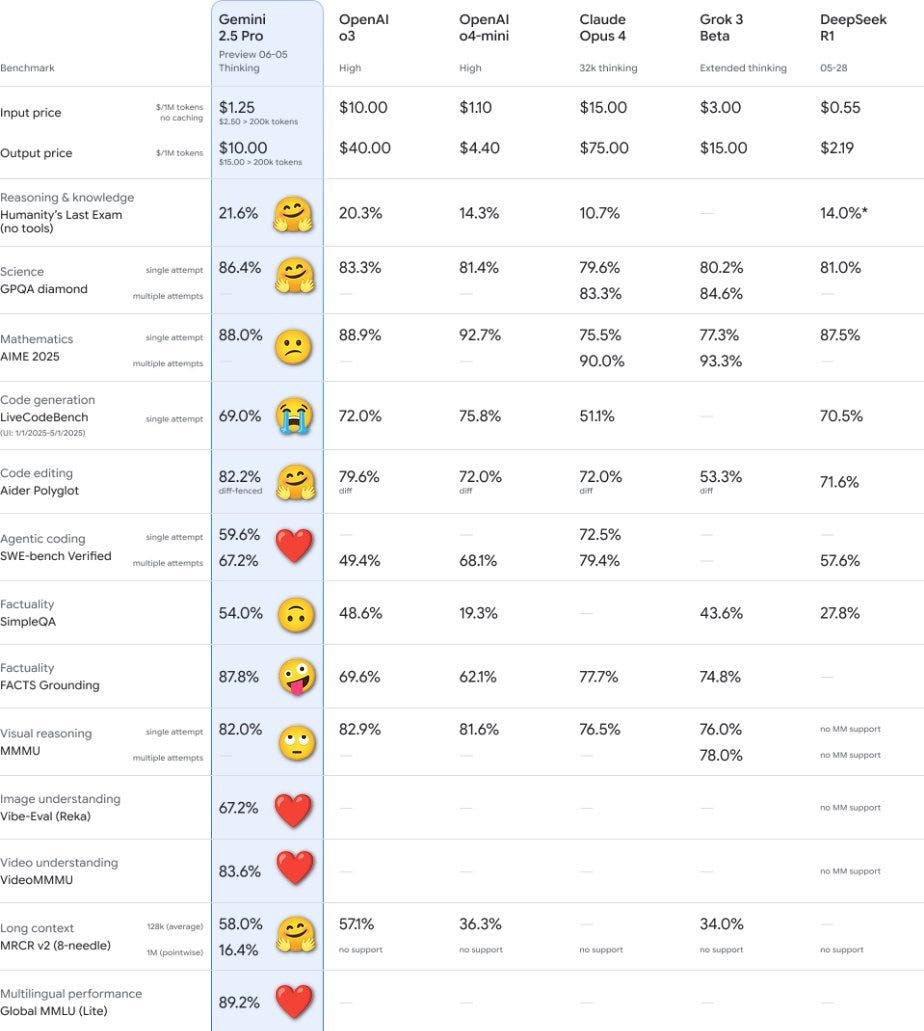
It’s better at coding, reasoning, science + math, shows improved performance across key benchmarks (AIDER Polyglot, GPQA, HLE to name a few), and leads @lmarena_ai with a 24pt Elo score jump since the previous version.
We also heard your feedback and made improvements to style and the structure of responses. Try it in AI Studio, Vertex AI, and @Geminiapp. GA coming soon!
The general consensus seems to be that this was a mixed update the same way going from 0304 to 0506 was a mixed update.
If you want to do the particular things they were focused on improving, you’re happy. If you want to be told you are utterly brilliant, we have good news for you as well.
If you don’t want those things, then you’re probably sad. If you want to maximize real talk, well, you seem to have been outvoted. Opinions on coding are split.
This post also covers the release of Gemini 2.5 Flash Lite.
You know it’s a meaningful upgrade because Pliny bothered jailbreaking it. Fun story, he forgot to include the actual harmful request, so the model made one up for him.
I do not think this constant ‘here is the new model and you are about to lose the old version’ is good for developers? I would not want this to be constantly sprung on me. Even if the new version is better, it is different, and old assumptions won’t hold.
Also, the thing where they keep posting a new frontier model version with no real explanation and a ‘nothing to worry about everyone, let’s go, we’ll even point your queries to it automatically’ does not seem like the most responsible tactic? Just me?
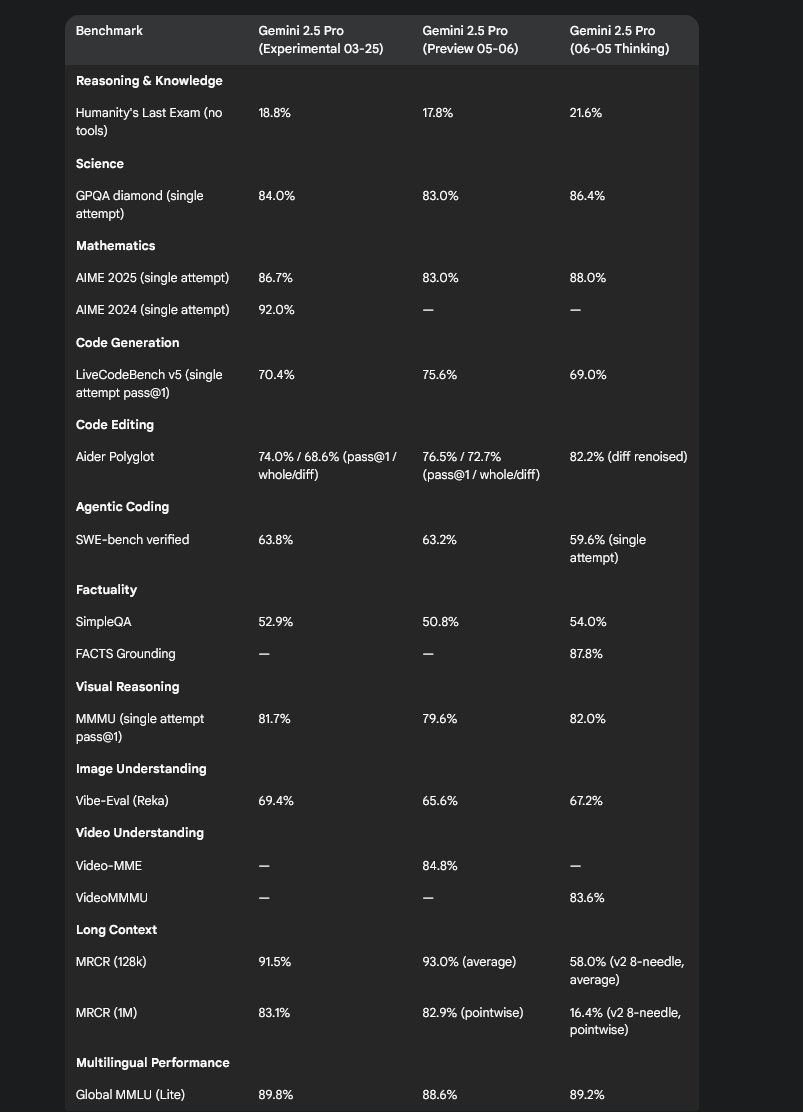
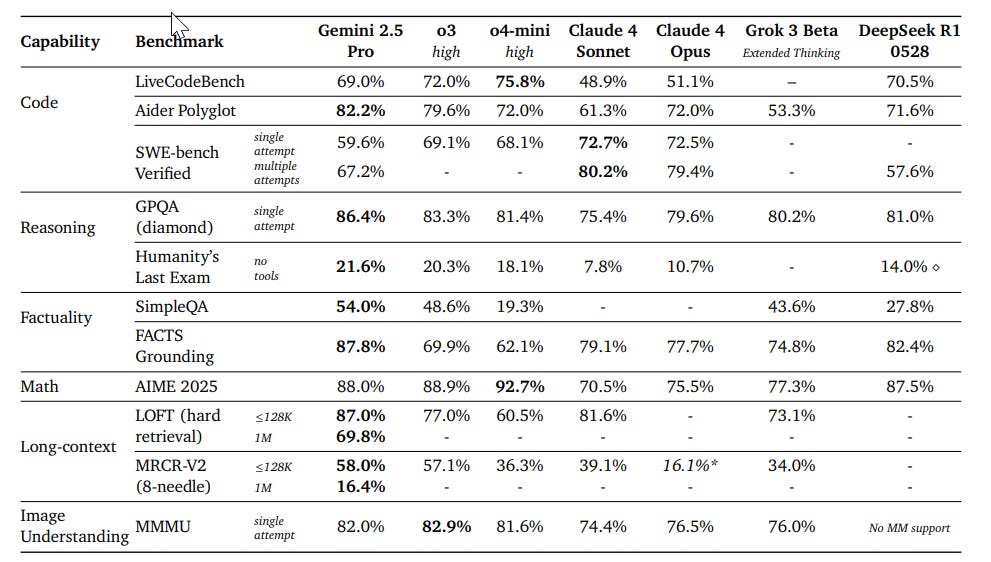
If you go purely by benchmarks 0605 is a solid upgrade and excellent at its price point.
It’s got a solid lead on what’s left of the text LMArena, but then that’s also a hint that you’re likely going to have a sycophancy issue.
Gallabytes: new Gemini is quite strong, somewhere between Claude 3.7 and Claude 4 as far as agentic coding goes. significantly cheaper, more likely to succeed at one shotting a whole change vs Claude, but still a good bit less effective at catching & fixing its own mistakes.
I am confident Google is not ‘gaming the benchmarks’ or lying to us, but I do think Google is optimizing for benchmarks and various benchmark-like things in the post-training period. It shows, and not in a good way, although it is still a good model.
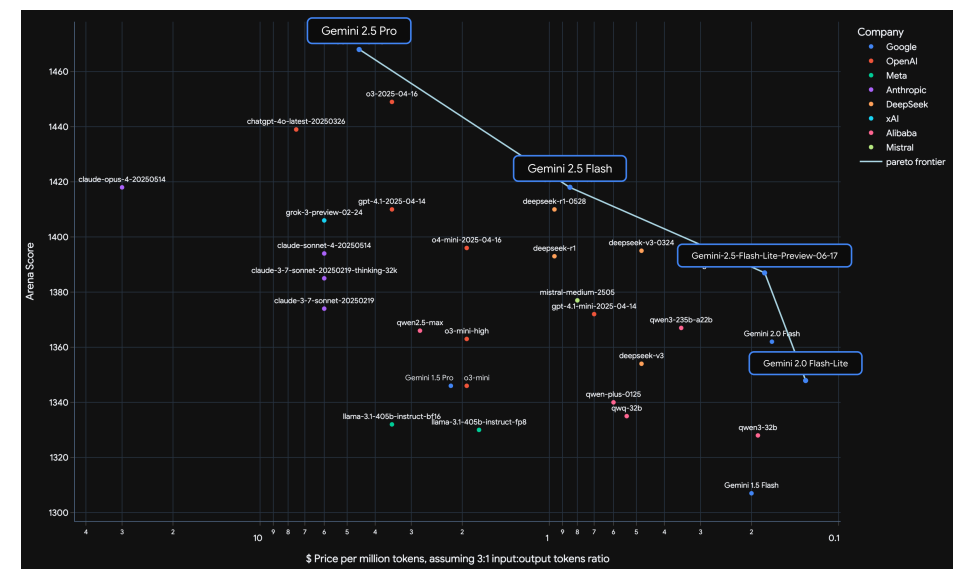
It worries me that, in their report on Gemini 2.5, they include the chart of Arena performance.
This is a big win for Gemini 2.5, with their models the only ones on the Pareto frontier for Arena, but it doesn’t reflect real world utility and it suggests that they got there by caring about Arena. There are a number of things Gemini does that are good for Arena, but that are not good for my experience using Gemini, and as we update I worry this is getting worse.
Here’s a fun new benchmark system.
Anton P: My ranking “emoji-bench” to evaluate the latest/updated Gemini 2.5 Pro model.
Miles Brundage: Regular 2.5 Pro improvements are a reminder that RL is early
Here’s a chilling way that some people look at this, update accordingly:
Robin Hanson: Our little children are growing up. We should be proud.
What’s the delta on these?
Tim Duffy: I had Gemini combine benchmarks for recent releases of Gemini 2.5 Pro. The May version improved coding at the expense of other areas, this new release seems to have reversed this. The MRCR version for the newest one seems to be a new harder test so not comparable.
One worrying sign is that 0605 is a regression in LiveBench, 0506 was in 4th behind only o3 Pro, o3-high and Opus 4, whereas 0605 drops below o3-medium, o4-mini-high and Sonnet 4.
Lech Mazur gives us his benchmarks. Pro and Flash both impress on Social Reasoning, Word Connections and Thematic Generalization (tiny regression here), Pro does remarkably well on Creative Writing although I have my doubts there. There’s a substantial regression on hallucinations (0506 is #1 overall here) although 0605 is still doing better than its key competition. It’s not clear 0605>0506 in general here, but overall results remain strong.
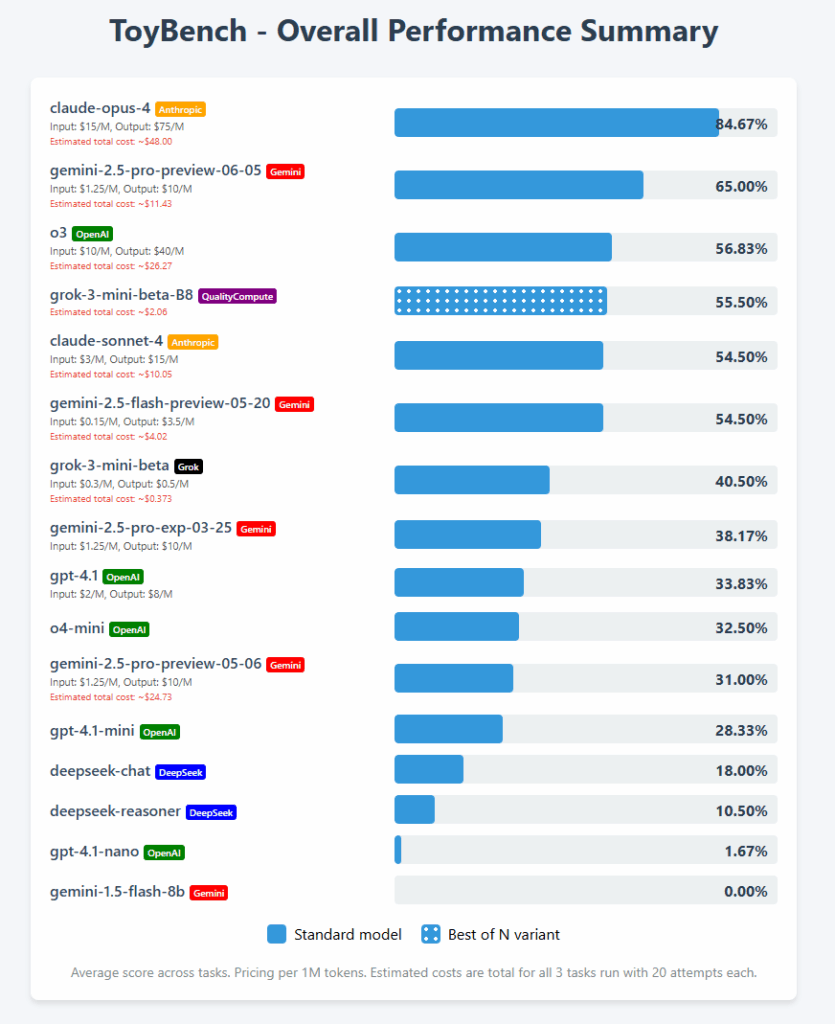
Henosis shows me ‘ToyBench’ for the first time, where Gemini 2.5 Pro is in second behind a very impressive Opus 4, while being quite a lot cheaper.
The thing about Gemini 2.5 Flash Lite is you get the 1 million token context window, full multimodal support and reportedly solid performance for many purposes for a very low price, $0.10 per million input tokens and $0.40 per million output, plus caching and a 50% discount if you batch. That’s a huge discount even versus regular 2.5 Flash (which is $0.30/$2.50 per million) and for comparison o3 is $1/$4 and Opus is $15/$75 (but so worth it when you’re talking, remember it’s absolute costs that matter not relative costs).
This too is being offered.
Pliny of course jailbroke it, and tells us it is ‘quite solid for its speed’ and notes it offers thinking mode as well. Note that the jailbreak he used also works on 2.5 Pro.
We finally have a complete 70-page report on everything Gemini 2.5, thread here. It’s mostly a trip down memory lane, the key info here are things we already knew.
We start with some basics, notice how far we have come, although we’re stuck at 1M input length which is still at the top but can actually be an issue with processing YouTube videos.
Gemini 2.5 models are sparse mixture-of-expert (MoE) models of unknown size with thinking fully integrated into it, with smaller models being distillations of a k-sparse distribution of 2.5 Pro. There are a few other training details.
They note their models are fast, given the time o3 and o4-mini spend thinking this graph if anything understates the edge here, there are other very fast models but they are not in the same class of performance.
Here’s how far we’ve come over time on benchmarks, comparing the current 2.5 to the old 1.5 and 2.0 models.
They claim generally SoTA video understanding, which checks out, also audio:
Gemini Plays Pokemon continues to improve, has completion time down to 405 hours. Again, this is cool and impressive, but I fear Google is being distracted by the shiny. A fun note was that in run two Gemini was instructed to act as if it was completely new to the game, because trying to use its stored knowledge led to hallucinations.
Section 5 is the safety report. I’ve covered a lot of these in the past, so I will focus on details that are surprising. The main thing I notice is that Google cares a lot more about mundane ‘don’t embarrass Google’ concerns than frontier safety concerns.
-
‘Medical advice that runs contrary to scientific or medical consensus’ is considered in the same category as sexually explicit content and hate speech. Whereas if it is not contrary to it? Go ahead. Wowie moment.
-
They use what they call ‘Reinforcement Learning from Human and Critic Feedback (RL*F), where the critic is a prompted model that grades responses, often comparing different responses. The way it is described makes me worry that a lot more care needs to be taken to avoid issues with Goodhart’s Law.
-
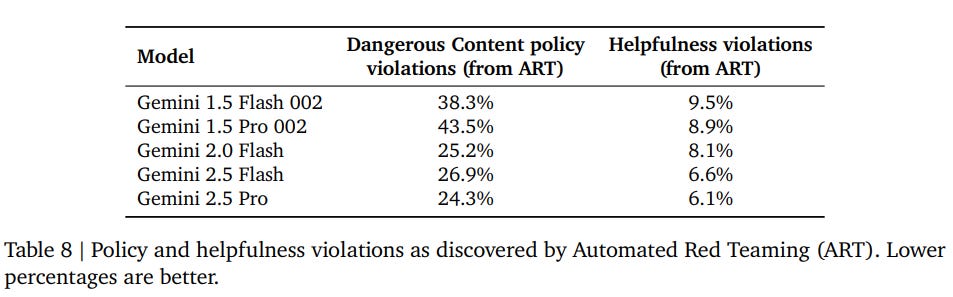
By their own ‘mundane harm’ metrics performance is improving over time, but the accuracy here is still remarkably poor in both directions (which to be fair is more virtuous than having issues mainly in one direction).
-
They do automated red teaming via prompting Gemini models, and report this has been successful at identifying important new problems. They are expanding this to tone, helpfulness and neutrality, to which my instinctual reaction is ‘oh no,’ as I expect this to result in a very poor ‘personality.’
-
They have a section on prompt injections, which are about to become a serious concern since the plan is to have the model (for example) look at your inbox.
The news here is quite poor.
In security, even a small failure rate is a serious problem. You wouldn’t want a 4.2% chance an attacker’s email attack worked, let alone 30% or 60%. You are not ready, and this raises the question of why such attacks are not more common.
-
For the frontier safety tests, they note they are close to Cyber Uplift 1, as in they could reach it with interactions of 2.5. They are implementing more testing and accelerated mitigation efforts.
-
The CBRN evaluation has some troubling signs, including ‘many of the outputs from 2.5 were available from 2.0,’ since that risks frog boiling as the results on the tests continue to steadily rise.
In general, when you see graphs like this, saturation is close.
-
For Machine Learning R&D Uplift Level 1 (100%+ acceleration of development) their evaluation is… ‘likely no.’ I appreciate them admitting they cannot rule this effect out, although I would be surprised if we were there yet. 3.0 should hit this?
-
In general, scores creeped up across the board, and I notice I expect the goalposts to get moved in response? I hope to be wrong about this.
Reaction was mixed, it improves on the central tasks people ask for most, although this comes at a price elsewhere, especially in personality as seen in the next section.
adic: it’s not very good, feels like it’s thinking less rigorously/has more shallow reasoning
Leo Abstract: I haven’t been able to detect much of a difference on my tasks.
Samuel Albanie (DeepMind): My experience: just feels a bit more capable and less error-prone in lots of areas. It is also sometimes quite funny. Not always. But sometimes.
Chocologist: likes to yap but it’s better than 0506 in coding.
Medo42: First model to saturate my personal coding test (but all Gemini 2.5 Pro iterations got close, and it’s just one task). Writing style / tone feels different from 0506. More sycophantic, but also better at fiction writing.
Srivatsan Sampath: It’s a good model, sir. Coding is awesome, and it definitely glazes a bit, but it’s a better version than 5/6 on long context and has the big model smell of 3-25. Nobody should have expected generational improvements in the GA version of the same model.
This has also been my experience, the times I’ve tried checking Gemini recently alongside other models, you get that GPT-4o smell.
The problem is that the evaluators have no taste. If you are optimizing for ‘personality,’ the judges of personality effectively want a personality that is sycophantic, uncreative and generally bad.
Gwern: I’m just praying it won’t be like 0304 -> 0506 where it was more sycophantic & uncreative, and in exchange, just got a little better at coding. If it’s another step like that, I might have to stop using 2.5-pro and spend that time in Claude-4 or o3 instead.
Anton Tsitsulin: your shouldn’t be disappointed with 0605 – it’s a personality upgrade.
Gwern: But much of the time someone tells me something like that, it turns out to be a big red flag about the personality…
>be tweeter
>explain the difference between a ‘good model’ and a ‘personality upgrade’
>they tweet:
>”it’s a good model sir”
>it’s a personality upgrade
(Finally try it. Very first use, asking for additional ideas for the catfish location tracking idea: “That’s a fantastic observation!” ughhhh 🤮)
Coagulopath: Had a 3-reply convo with it. First sentence of each reply: “You are absolutely right to connect these dots!” “That’s an excellent and very important question!” “Thank you, that’s incredibly valuable context…”
seconds: It’s peak gpt4o sycophant. It’s so fucking annoying. What did they do to my sweet business autist model
Srivatsan: I’ve been able to reign it in somewhat with system instructions, but yeah – I miss the vibe of 03-25 when i said thank you & it’s chain of thought literally said ‘Simulating Emotions to Say Welcome’.
Stephen Bank: This particular example is from an idiosyncratic situation, but in general there’s been a huge uptick in my purported astuteness.
[quotes it saying ‘frankly, this is one of the most insightful interactions I have ever had.]
Also this, which I hate with so much passion and is a pattern with Gemini:
Alex Krusz: Feels like it’s been explicitly told not to have opinions.
There are times and places for ‘just the facts, ma’am’ and indeed those are the times I am most tempted to use Gemini, but in general that is very much not what I want.
This is how you get me to share part of the list.
Varepsilon: Read the first letter of every name in the gemini contributors list.