Enlarge/ The real Will Smith eating spaghetti, parodying an AI-generated video from 2023.
On Monday, Will Smith posted a video on his official Instagram feed that parodied an AI-generated video of the actor eating spaghetti that went viral last year. With the recent announcement of OpenAI’s Sora video synthesis model, many people have noted the dramatic jump in AI-video quality over the past year compared to the infamous spaghetti video. Smith’s new video plays on that comparison by showing the actual actor eating spaghetti in a comical fashion and claiming that it is AI-generated.
Captioned “This is getting out of hand!”, the Instagram video uses a split screen layout to show the original AI-generated spaghetti video created by a Reddit user named “chaindrop” in March 2023 on the top, labeled with the subtitle “AI Video 1 year ago.” Below that, in a box titled “AI Video Now,” the real Smith shows 11 video segments of himself actually eating spaghetti by slurping it up while shaking his head, pouring it into his mouth with his fingers, and even nibbling on a friend’s hair. 2006’s Snap Yo Fingers by Lil Jon plays in the background.
In the Instagram comments section, some people expressed confusion about the new (non-AI) video, saying, “I’m still in doubt if second video was also made by AI or not.” In a reply, someone else wrote, “Boomers are gonna loose [sic] this one. Second one is clearly him making a joke but I wouldn’t doubt it in a couple months time it will get like that.”
We have not yet seen a model with the capability of Sora attempt to create a new Will-Smith-eating-spaghetti AI video, but the result would likely be far better than what we saw last year, even if it contained obvious glitches. Given how things are progressing, we wouldn’t be surprised if by 2025, video synthesis AI models can replicate the parody video created by Smith himself.
It’s worth noting for history’s sake that despite the comparison, the video of Will Smith eating spaghetti did not represent the state of the art in text-to-video synthesis at the time of its creation in March 2023 (that title would likely apply to Runway’s Gen-2, which was then in closed testing). However, the spaghetti video was reasonably advanced for open weights models at the time, having used the ModelScope AI model. More capable video synthesis models had already been released at that time, but due to the humorous cultural reference, it’s arguably more fun to compare today’s AI video synthesis to Will Smith grotesquely eating spaghetti than to teddy bears washing dishes.
On Friday, Bloomberg reported that Reddit has signed a contract allowing an unnamed AI company to train its models on the site’s content, according to people familiar with the matter. The move comes as the social media platform nears the introduction of its initial public offering (IPO), which could happen as soon as next month.
Reddit initially revealed the deal, which is reported to be worth $60 million a year, earlier in 2024 to potential investors of an anticipated IPO, Bloomberg said. The Bloomberg source speculates that the contract could serve as a model for future agreements with other AI companies.
After an era where AI companies utilized AI training data without expressly seeking any rightsholder permission, some tech firms have more recently begun entering deals where some content used for training AI models similar to GPT-4 (which runs the paid version of ChatGPT) comes under license. In December, for example, OpenAI signed an agreement with German publisher Axel Springer (publisher of Politico and Business Insider) for access to its articles. Previously, OpenAI has struck deals with other organizations, including the Associated Press. Reportedly, OpenAI is also in licensing talks with CNN, Fox, and Time, among others.
In April 2023, Reddit founder and CEO Steve Huffman told The New York Times that it planned to charge AI companies for access to its almost two decades’ worth of human-generated content.
If the reported $60 million/year deal goes through, it’s quite possible that if you’ve ever posted on Reddit, some of that material may be used to train the next generation of AI models that create text, still pictures, and video. Even without the deal, experts have discovered in the past that Reddit has been a key source of training data for large language models and AI image generators.
While we don’t know if OpenAI is the company that signed the deal with Reddit, Bloomberg speculates that Reddit’s ability to tap into AI hype for additional revenue may boost the value of its IPO, which might be worth $5 billion. Despite drama last year, Bloomberg states that Reddit pulled in more than $800 million in revenue in 2023, growing about 20 percent over its 2022 numbers.
Advance Publications, which owns Ars Technica parent Condé Nast, is the largest shareholder of Reddit.
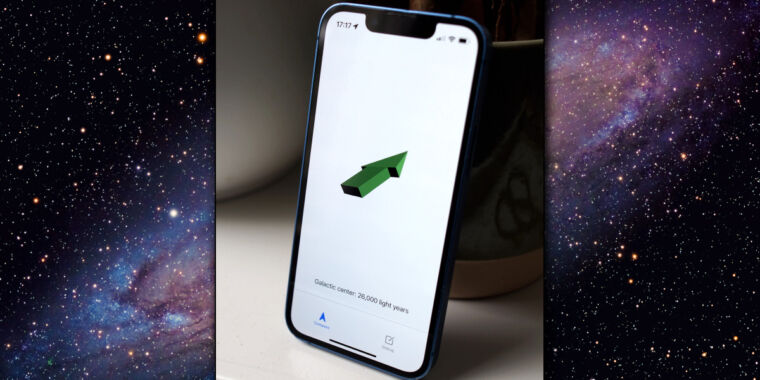
Enlarge/ A photo of Galactic Compass running on an iPhone.
Matt Webb / Getty Images
On Thursday, designer Matt Webb unveiled a new iPhone app called Galactic Compass, which always points to the center of the Milky Way galaxy—no matter where Earth is positioned on our journey through the stars. The app is free and available now on the App Store.
While using Galactic Compass, you set your iPhone on a level surface, and a big green arrow on the screen points the way to the Galactic Center, which is the rotational core of the spiral galaxy all of us live in. In that center is a supermassive black hole known as Sagittarius A*, a celestial body from which no matter or light can escape. (So, in a way, the app is telling us what we should avoid.)
But truthfully, the location of the galactic core at any given time isn’t exactly useful, practical knowledge—at least for people who aren’t James Tiberius Kirk in Star Trek V. But it may inspire a sense of awe about our place in the cosmos.
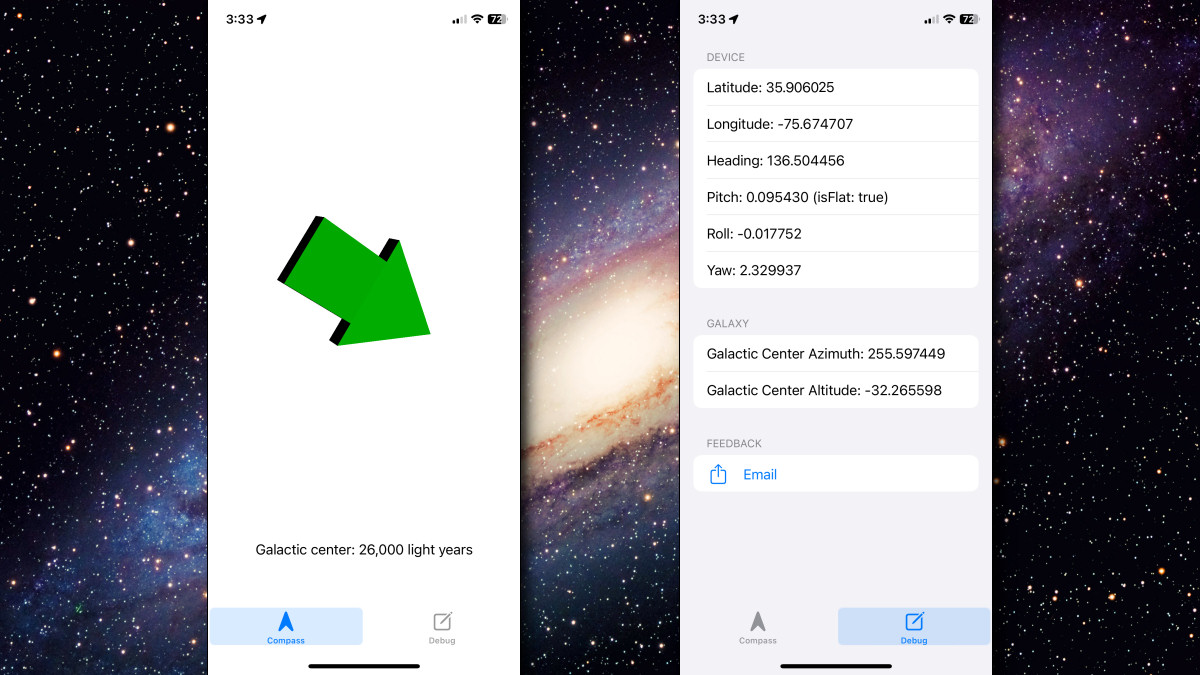
Enlarge/ Screenshots of Galactic Compass in action, captured by Ars Technica in a secret location.
Benj Edwards / Getty Images
“It is astoundingly grounding to always have a feeling of the direction of the center of the galaxy,” Webb told Ars Technica. “Your perspective flips. To begin with, it feels arbitrary. The middle of the Milky Way seems to fly all over the sky, as the Earth turns and moves in its orbit.”
Webb’s journey to creating Galactic Compass began a decade ago as an offshoot of his love for casual astronomy. “About 10 years ago, I taught myself how to point to the center of the galaxy,” Webb said. “I lived in an apartment where I had a great view of the stars, so I was using augmented reality apps to identify them, and I gradually learned my way around the sky.”
While Webb initially used an astronomy app to help locate the Galactic Center, he eventually taught himself how to always find it. He described visualizing himself on the surface of the Earth as it spins and tilts, understanding the ecliptic as a line across the sky and recognizing the center of the galaxy as an invisible point moving predictably through the constellation Sagittarius, which lies on the ecliptic line. By visualizing Earth’s orbit over the year and determining his orientation in space, he was able to point in the right direction, refining his ability through daily practice and comparison with an augmented reality app.
With a little help from AI
Enlarge/ Our galaxy, the Milky Way, is thought to look similar to Andromeda (seen here) if you could see it from a distance. But since we’re inside the galaxy, all we can see is the edge of the galactic plane.
Getty Images
In 2021, Webb imagined turning his ability into an app that would help take everyone on the same journey, showing a compass that points toward the galactic center instead of Earth’s magnetic north. “But I can’t write apps,” he said. “I’m a decent enough engineer, and an amateur designer, but I’ve never figured out native apps.”
That’s where ChatGPT comes in, transforming Webb’s vision into reality. With the AI assistant as his coding partner, Webb progressed step by step, crafting a simple app interface and integrating complex calculations for locating the galactic center (which involves calculating the user’s azimuth and altitude).
Still, coding with ChatGPT has its limitations. “ChatGPT is super smart, but it’s not embodied like a human, so it falls down on doing the 3D calculations,” he says. “I had to learn a lot about quaternions, which are a technique for combining 3D rotations, and even then, it’s not perfect. The app needs to be held flat to work simply because my math breaks down when the phone is upright! I’ll fix this in future versions,” Webb said.
Webb is no stranger to ChatGPT-powered creations that are more fun than practical. Last month, he launched a Kickstarter for an AI-rhyming poetry clock called the Poem/1. With his design studio, Acts Not Facts, Webb says he uses “whimsy and play to discover the possibilities in new technology.”
Whimsical or not, Webb insists that Galactic Compass can help us ponder our place in the vast universe, and he’s proud that it recently peaked at #87 in the Travel chart for the US App Store. In this case, though, it’s spaceship Earth that is traveling the galaxy while every living human comes along for the ride.
“Once you can follow it, you start to see the galactic center as the true fixed point, and we’re the ones whizzing and spinning. There it remains, the supermassive black hole at the center of our galaxy, Sagittarius A*, steady as a rock, eternal. We go about our days; it’s always there.”
More than 1,000 Ubiquiti routers in homes and small businesses were infected with malware used by Russian-backed agents to coordinate them into a botnet for crime and spy operations, according to the Justice Department.
That malware, which worked as a botnet for the Russian hacking group Fancy Bear, was removed in January 2024 under a secret court order as part of “Operation Dying Ember,” according to the FBI’s director. It affected routers running Ubiquiti’s EdgeOS, but only those that had not changed their default administrative password. Access to the routers allowed the hacking group to “conceal and otherwise enable a variety of crimes,” the DOJ claims, including spearphishing and credential harvesting in the US and abroad.
Unlike previous attacks by Fancy Bear—that the DOJ ties to GRU Military Unit 26165, which is also known as APT 28, Sofacy Group, and Sednit, among other monikers—the Ubiquiti intrusion relied on a known malware, Moobot. Once infected by “Non-GRU cybercriminals,” GRU agents installed “bespoke scripts and files” to connect and repurpose the devices, according to the DOJ.
The DOJ also used the Moobot malware to copy and delete the botnet files and data, according to the DOJ, and then changed the routers’ firewall rules to block remote management access. During the court-sanctioned intrusion, the DOJ “enabled temporary collection of non-content routing information” that would “expose GRU attempts to thwart the operation.” This did not “impact the routers’ normal functionality or collect legitimate user content information,” the DOJ claims.
“For the second time in two months, we’ve disrupted state-sponsored hackers from launching cyber-attacks behind the cover of compromised US routers,” said Deputy Attorney General Lisa Monaco in a press release.
The DOJ states it will notify affected customers to ask them to perform a factory reset, install the latest firmware, and change their default administrative password.
Christopher A. Wray, director of the FBI, expanded on the Fancy Bear operation and international hacking threats generally at the ongoing Munich Security Conference. Russia has recently targeted underwater cables and industrial control systems worldwide, Wray said, according to a New York Times report. And since its invasion of Ukraine, Russia has focused on the US energy sector, Wray said.
The past year has been an active time for attacks on routers and other network infrastructure. TP-Link routers were found infected in May 2023 with malware from a reportedly Chinese-backed group. In September, modified firmware in Cisco routers was discovered as part of a Chinese-backed intrusion into multinational companies, according to US and Japanese authorities. Malware said by the DOJ to be tied to the Chinese government was removed from SOHO routers by the FBI last month in similar fashion to the most recently revealed operation, targeting Cisco and Netgear devices that had mostly reached their end of life and were no longer receiving security patches.
In each case, the routers provided a highly valuable service to the groups; that service was secondary to whatever primary aims later attacks might have. By nesting inside the routers, hackers could send commands from their overseas locations but have the traffic appear to be coming from a far more safe-looking location inside the target country or even inside a company.
Similar inside-the-house access has been sought by international attackers through VPN products, as in the three different Ivanti vulnerabilities discovered recently.
Enlarge/ All shall tremble before your fully functional forward and reverse lookups!
Aurich Lawson | Getty Images
Here’s a short summary of the next 7,000-ish words for folks who hate the thing recipe sites do where the authors babble about their personal lives for pages and pages before getting to the cooking: This article is about how to install bind and dhcpd and tie them together into a functional dynamic DNS setup for your LAN so that DHCP clients self-register with DNS, and you always have working forward and reverse DNS lookups. This article is intended to be part one of a two-part series, and in part two, we’ll combine our bind DNS instance with an ACME-enabled LAN certificate authority and set up LetsEncrypt-style auto-renewing certificates for LAN services.
If that sounds like a fun couple of weekend projects, you’re in the right place! If you want to fast-forward to where we start installing stuff, skip down a couple of subheds to the tutorial-y bits. Now, excuse me while I babble about my personal life.
My name is Lee, and I have a problem
(Hi, Lee.)
I am a tinkering homelab sysadmin forever chasing the enterprise dragon. My understanding of what “normal” means, in terms of the things I should be able to do in any minimally functioning networking environment, was formed in the days just before and just after 9/11, when I was a fledgling admin fresh out of college, working at an enormous company that made planes starting with the number “7.” I tutored at the knees of a whole bunch of different mentor sysadmins, who ranged on the graybeard scale from “fairly normal, just writes his own custom GURPS campaigns” to “lives in a Unabomber cabin in the woods and will only communicate via GPG.” If there was one consistent refrain throughout my formative years marinating in that enterprise IT soup, it was that forward and reverse DNS should always work. Why? Because just like a clean bathroom is generally a sign of a nice restaurant, having good, functional DNS (forward and reverse) is a sign that your IT team knows what it’s doing.
Just look at what the masses have to contend with outside of the datacenter, where madness reigns. Look at the state of the average user’s LAN—is there even a search domain configured? Do reverse queries on dynamic hosts work? Do forward queries on dynamic hosts even work? How can anyone live like this?!
I decided long ago that I didn’t have to, so I’ve maintained a linked bind and dhcpd setup on my LAN for more than ten years. Also, I have control issues, and I like my home LAN to function like the well-run enterprise LANs I used to spend my days administering. It’s kind of like how car people think: If you’re not driving a stick shift, you’re not really driving. I have the same kind of dumb hang-up, but for network services.
Honestly, though, running your LAN with bind and dhcpd isn’t even that much work—those two applications underpin a huge part of the modern Internet. The packaged versions that come with most modern Linux distros are ready to go out of the box. They certainly beat the pants off of the minimal DNS/DHCP services offered by most SOHO NAT routers. Once you have bind and dhcpd configured, they’re bulletproof. The only time I interact with my setup is if I need to add a new static DHCP mapping for a host I want to always grab the same IP address.
So, hey, if the idea of having perfect forward and reverse DNS lookups on your LAN sounds exciting—and, come on, who doesn’t want that?!—then pull up your terminal and strap in because we’re going make it happen.
(Note that I’m relying a bit on Past Lee and this old blog entry for some of the explanations in this piece, so if any of the three people who read my blog notice any similarities in some of the text, it’s because Past Lee wrote it first and I am absolutely stealing from him.)
But wait, there’s more!
This piece is intended to be part one of two. If the idea of having one’s own bind and dhcpd servers sounds a little silly (and it’s not—it’s awesome), it’s actually a prerequisite for an additional future project with serious practical implications: our own fully functioning local ACME-enabled certificate authority capable of answering DNS-01 challenges so we can issue our own certificates to LAN services and not have to deal with TLS warnings like plebes.
(“But Lee,” you say, “why not just use actual-for-real LetsEncrypt with a real domain on my LAN?” Because that’s considerably more complicated to implement if one does it the right way, and it means potentially dealing with split-horizon DNS and hairpinning if you also need to use that domain for any Internet-accessible stuff. Split-horizon DNS is handy and useful if you have requirements that demand it, but if you’re a home user, you probably don’t. We’ll keep this as simple as possible and use LAN-specific DNS zones rather than real public domain names.)
We’ll tackle all the certificate stuff in part two—because we have a ways to go before we can get there.
Enlarge/ Snapshots from three videos generated using OpenAI’s Sora.
On Thursday, OpenAI announced Sora, a text-to-video AI model that can generate 60-second-long photorealistic HD video from written descriptions. While it’s only a research preview that we have not tested, it reportedly creates synthetic video (but not audio yet) at a fidelity and consistency greater than any text-to-video model available at the moment. It’s also freaking people out.
“It was nice knowing you all. Please tell your grandchildren about my videos and the lengths we went to to actually record them,” wrote Wall Street Journal tech reporter Joanna Stern on X.
“This could be the ‘holy shit’ moment of AI,” wrote Tom Warren of The Verge.
“Every single one of these videos is AI-generated, and if this doesn’t concern you at least a little bit, nothing will,” tweeted YouTube tech journalist Marques Brownlee.
For future reference—since this type of panic will some day appear ridiculous—there’s a generation of people who grew up believing that photorealistic video must be created by cameras. When video was faked (say, for Hollywood films), it took a lot of time, money, and effort to do so, and the results weren’t perfect. That gave people a baseline level of comfort that what they were seeing remotely was likely to be true, or at least representative of some kind of underlying truth. Even when the kid jumped over the lava, there was at least a kid and a room.
The prompt that generated the video above: “A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.“
Technology like Sora pulls the rug out from under that kind of media frame of reference. Very soon, every photorealistic video you see online could be 100 percent false in every way. Moreover, every historical video you see could also be false. How we confront that as a society and work around it while maintaining trust in remote communications is far beyond the scope of this article, but I tried my hand at offering some solutions back in 2020, when all of the tech we’re seeing now seemed like a distant fantasy to most people.
In that piece, I called the moment that truth and fiction in media become indistinguishable the “cultural singularity.” It appears that OpenAI is on track to bring that prediction to pass a bit sooner than we expected.
Prompt: Reflections in the window of a train traveling through the Tokyo suburbs.
OpenAI has found that, like other AI models that use the transformer architecture, Sora scales with available compute. Given far more powerful computers behind the scenes, AI video fidelity could improve considerably over time. In other words, this is the “worst” AI-generated video is ever going to look. There’s no synchronized sound yet, but that might be solved in future models.
How (we think) they pulled it off
AI video synthesis has progressed by leaps and bounds over the past two years. We first covered text-to-video models in September 2022 with Meta’s Make-A-Video. A month later, Google showed off Imagen Video. And just 11 months ago, an AI-generated version of Will Smith eating spaghetti went viral. In May of last year, what was previously considered to be the front-runner in the text-to-video space, Runway Gen-2, helped craft a fake beer commercial full of twisted monstrosities, generated in two-second increments. In earlier video-generation models, people pop in and out of reality with ease, limbs flow together like pasta, and physics doesn’t seem to matter.
Sora (which means “sky” in Japanese) appears to be something altogether different. It’s high-resolution (1920×1080), can generate video with temporal consistency (maintaining the same subject over time) that lasts up to 60 seconds, and appears to follow text prompts with a great deal of fidelity. So, how did OpenAI pull it off?
OpenAI doesn’t usually share insider technical details with the press, so we’re left to speculate based on theories from experts and information given to the public.
OpenAI says that Sora is a diffusion model, much like DALL-E 3 and Stable Diffusion. It generates a video by starting off with noise and “gradually transforms it by removing the noise over many steps,” the company explains. It “recognizes” objects and concepts listed in the written prompt and pulls them out of the noise, so to speak, until a coherent series of video frames emerge.
Sora is capable of generating videos all at once from a text prompt, extending existing videos, or generating videos from still images. It achieves temporal consistency by giving the model “foresight” of many frames at once, as OpenAI calls it, solving the problem of ensuring a generated subject remains the same even if it falls out of view temporarily.
OpenAI represents video as collections of smaller groups of data called “patches,” which the company says are similar to tokens (fragments of a word) in GPT-4. “By unifying how we represent data, we can train diffusion transformers on a wider range of visual data than was possible before, spanning different durations, resolutions, and aspect ratios,” the company writes.
An important tool in OpenAI’s bag of tricks is that its use of AI models is compounding. Earlier models are helping to create more complex ones. Sora follows prompts well because, like DALL-E 3, it utilizes synthetic captions that describe scenes in the training data generated by another AI model like GPT-4V. And the company is not stopping here. “Sora serves as a foundation for models that can understand and simulate the real world,” OpenAI writes, “a capability we believe will be an important milestone for achieving AGI.”
One question on many people’s minds is what data OpenAI used to train Sora. OpenAI has not revealed its dataset, but based on what people are seeing in the results, it’s possible OpenAI is using synthetic video data generated in a video game engine in addition to sources of real video (say, scraped from YouTube or licensed from stock video libraries). Nvidia’s Dr. Jim Fan, who is a specialist in training AI with synthetic data, wrote on X, “I won’t be surprised if Sora is trained on lots of synthetic data using Unreal Engine 5. It has to be!” Until confirmed by OpenAI, however, that’s just speculation.
Broadcom has made a lot of changes to VMware since closing its acquisition of the company in November. On Wednesday, VMware admitted that these changes are worrying customers. With customers mulling alternatives and partners complaining, VMware is trying to do damage control and convince people that change is good.
Not surprisingly, the plea comes from a VMware marketing executive: Prashanth Shenoy, VP of product and technical marketing for the Cloud, Infrastructure, Platforms, and Solutions group at VMware. In Wednesday’s announcement, Shenoy admitted that VMware “has been all about change” since being swooped up for $61 billion. This has resulted in “many questions and concerns” as customers “evaluate how to maximize value from” VMware products.
Among these changes is VMware ending perpetual license sales in favor of a subscription-based business model. VMware had a history of relying on perpetual licensing; VMware called the model its “most renowned” a year ago.
Shenoy’s blog sought to provide reasoning for the change, with the executive writing that “all major enterprise software providers are on [subscription models] today.”
However, the idea that ‘”everyone’s doing it” has done little to ameliorate impacted customers who prefer paying for something once and owning it indefinitely (while paying for associated support costs). Customers are also dealing with budget concerns with already paid-for licenses set to lose support and the only alternative being a monthly fee.
Shenoy’s blog, though, focused on license portability. “This means you will be able to deploy on-premises and then take your subscription at any time to a supported Hyperscaler or VMware Cloud Services Provider environment as desired. You retain your license subscription as you move,” Shenoy wrote, noting new Google Cloud VMware Engine license portability support for VMware Cloud Foundation.
Further, Shenoy claimed the discontinuation of VMware products so that Broadcom could focus on VMware Cloud Foundation and vSphere Foundation would be beneficial, because “offering a few offerings that are lower in price on the high end and are packed with more value for the same or less cost on the lower end makes business sense for customers, partners, and VMware.”
This week, Broadcom axed the free version of vSphere Hypervisor, ESXi. As reported by my colleague Andrew Cunningham, the offering was useful for enthusiasts “who wanted to run multipurpose home servers or to split a system’s time between Windows and one or more Linux distributions without the headaches of dual booting” or who wanted to familiarize themselves with vSphere Hypervisor without having to pay for licensing. The removal of ESXi could contribute to an eventual VMware skills gap, ServeTheHome suggested.
Broadcom addresses VMware partner changes
Broadcom has also announced that it’s ending the VMware partner program. Broadcom initially said it would invite a select number of VMware channel partners to the Broadcom partner program but didn’t say how many, causing concerns about how smaller businesses would get access to VMware products.
Broadcom said it ultimately invited 18,000 VMware resellers to its partner program and said this included “all active” partners, as defined by partners who had active contracts within the last two years. However, 18,000 is fewer than the 28,000 partners VMware told ChannelE2E it had in March 2023. Broadcom didn’t respond to CRN’s questions asking about the discrepancy in numbers and hasn’t responded to questions that Ars Technica previously sent about how it was deciding which VMware partners it would invite to its program.
There are still concerns that channel partners won’t be able to meet Broadcom’s new requirements for being a VMware reseller, meaning that smaller companies may have to consider notable infrastructure changes and moving off VMware. Broadcom’s layoffs of thousands of VMware employees has reportedly hurt communication and contributed to confusion, too.
VMware’s Wednesday post also addressed Broadcom taking VMware’s biggest customers direct, removing channel partners from the equation:
It makes business sense for Broadcom to have close relationships with its most strategic VMware customers to make sure VMware Cloud Foundation is being adopted, used, and providing customer value. However, we expect there will be a role change in accounts that will have to be worked through so that both Broadcom and our partners are providing the most value and greatest impact to strategic customers. And, partners will play a critical role in adding value beyond what Broadcom may be able.
But while taking over VMware’s biggest accounts (CRN estimated in January that this affects about 2,000 accounts) may make business sense for Broadcom, it’s hard to imagine how it would make business sense for the IT businesses managing those accounts previously.
While Broadcom has made headlines with its dramatic changes to VMware, Shenoy argued that “Broadcom identified things that needed to change and, as a responsible company, made the changes quickly and decisively.”
“The changes that have taken place over the past 60+ days were absolutely necessary,” he added.
The implications of these changes will continue to be debated over the coming months as the impact of Broadcom’s strategy is realized. But in the meantime, it looks like Broadcom is sticking to its guns, even with rivals looking to capitalize on related uncertainty.
One week after its last major AI announcement, Google appears to have upstaged itself. Last Thursday, Google launched Gemini Ultra 1.0, which supposedly represented the best AI language model Google could muster—available as part of the renamed “Gemini” AI assistant (formerly Bard). Today, Google announced Gemini Pro 1.5, which it says “achieves comparable quality to 1.0 Ultra, while using less compute.”
Congratulations, Google, you’ve done it. You’ve undercut your own premiere AI product. While Ultra 1.0 is possibly still better than Pro 1.5 (what even are we saying here), Ultra was presented as a key selling point of its “Gemini Advanced” tier of its Google One subscription service. And now it’s looking a lot less advanced than seven days ago. All this is on top of the confusing name-shuffling Google has been doing recently. (Just to be clear—although it’s not really clarifying at all—the free version of Bard/Gemini currently uses the Pro 1.0 model. Got it?)
Google claims that Gemini 1.5 represents a new generation of LLMs that “delivers a breakthrough in long-context understanding,” and that it can process up to 1 million tokens, “achieving the longest context window of any large-scale foundation model yet.” Tokens are fragments of a word. The first part of the claim about “understanding” is contentious and subjective, but the second part is probably correct. OpenAI’s GPT-4 Turbo can reportedly handle 128,000 tokens in some circumstances, and 1 million is quite a bit more—about 700,000 words. A larger context window allows for processing longer documents and having longer conversations. (The Gemini 1.0 model family handles 32,000 tokens max.)
But any technical breakthroughs are almost beside the point. What should we make of a company that just trumpeted to the world about its AI supremacy last week, only to partially supersede that a week later? Is it a testament to the rapid rate of AI technical progress in Google’s labs, a sign that red tape was holding back Ultra 1.0 for too long, or merely a sign of poor coordination between research and marketing? We honestly don’t know.
So back to Gemini 1.5. What is it, really, and how will it be available? Google implies that like 1.0 (which had Nano, Pro, and Ultra flavors), it will be available in multiple sizes. Right now, Pro 1.5 is the only model Google is unveiling. Google says that 1.5 uses a new mixture-of-experts (MoE) architecture, which means the system selectively activates different “experts” or specialized sub-models within a larger neural network for specific tasks based on the input data.
Google says that Gemini 1.5 can perform “complex reasoning about vast amounts of information,” and gives an example of analyzing a 402-page transcript of Apollo 11’s mission to the Moon. It’s impressive to process documents that large, but the model, like every large language model, is highly likely to confabulate interpretations across large contexts. We wouldn’t trust it to soundly analyze 1 million tokens without mistakes, so that’s putting a lot of faith into poorly understood LLM hands.
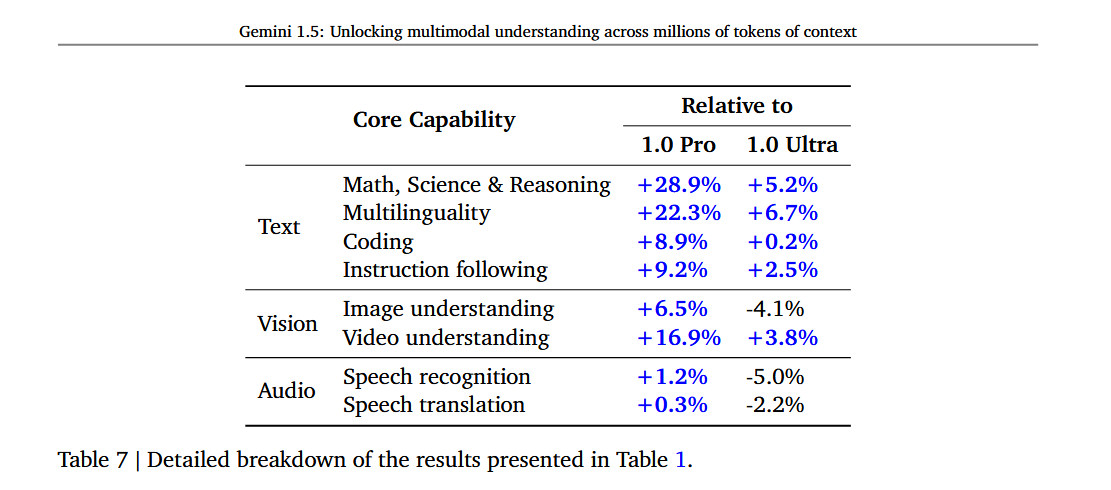
For those interested in diving into technical details, Google has released a technical report on Gemini 1.5 that appears to show Gemini performing favorably versus GPT-4 Turbo on various tasks, but it’s also important to note that the selection and interpretation of those benchmarks can be subjective. The report does give some numbers on how much better 1.5 is compared to 1.0, saying it’s 28.9 percent better than 1.0 Pro at “Math, Science & Reasoning” and 5.2 percent better at those subjects than 1.0 Ultra.
Enlarge/ A table from the Gemini 1.5 technical document showing comparisons to Gemini 1.0.
Google
But for now, we’re still kind of shocked that Google would launch this particular model at this particular moment in time. Is it trying to get ahead of something that it knows might be just around the corner, like OpenAI’s unreleased GPT-5, for instance? We’ll keep digging and let you know what we find.
Google says that a limited preview of 1.5 Pro is available now for developers via AI Studio and Vertex AI with a 128,000 token context window, scaling up to 1 million tokens later. Gemini 1.5 apparently has not come to the Gemini chatbot (formerly Bard) yet.
On Tuesday, the United States Patent and Trademark Office (USPTO) published guidance on inventorship for AI-assisted inventions, clarifying that while AI systems can play a role in the creative process, only natural persons (human beings) who make significant contributions to the conception of an invention can be named as inventors. It also rules out using AI models to churn out patent ideas without significant human input.
The USPTO says this position is supported by “the statutes, court decisions, and numerous policy considerations,” including the Executive Order on AI issued by President Biden. We’ve previously covered attempts, which have been repeatedly rejected by US courts, by Dr. Stephen Thaler to have an AI program called “DABUS” named as the inventor on a US patent (a process begun in 2019).
Even though an AI model itself cannot be named an inventor or joint inventor on a patent, using AI assistance to create an invention does not necessarily disqualify a human from holding a patent, as the USPTO explains:
“While AI systems and other non-natural persons cannot be listed as inventors on patent applications or patents, the use of an AI system by a natural person(s) does not preclude a natural person(s) from qualifying as an inventor (or joint inventors) if the natural person(s) significantly contributed to the claimed invention.”
However, the USPTO says that significant human input is required for an invention to be patentable: “Maintaining ‘intellectual domination’ over an AI system does not, on its own, make a person an inventor of any inventions created through the use of the AI system.” So a person simply overseeing an AI system isn’t suddenly an inventor. The person must make a significant contribution to the conception of the invention.
If someone does use an AI model to help create patents, the guidance describes how the application process would work. First, patent applications for AI-assisted inventions must name “the natural person(s) who significantly contributed to the invention as the inventor,” and additionally, applications must not list “any entity that is not a natural person as an inventor or joint inventor, even if an AI system may have been instrumental in the creation of the claimed invention.”
Reading between the lines, it seems the contributions made by AI systems are akin to contributions made by other tools that assist in the invention process. The document does not explicitly say that the use of AI is required to be disclosed during the application process.
Even with the published guidance, the USPTO is seeking public comment on the newly released guidelines and issues related to AI inventorship on its website.
This week, Broadcom is making a change that is smaller in scale but possibly more relevant for home users of its products: The free version of VMware’s vSphere Hypervisor, also known as ESXi, is being discontinued.
ESXi is what is known as a “bare-metal hypervisor,” lightweight software that runs directly on hardware without requiring a separate operating system layer in between. ESXi allows you to split a PC’s physical resources (CPUs and CPU cores, RAM, storage, networking components, and so on) among multiple virtual machines. ESXi also supports passthrough for PCI, SATA, and USB accessories, allowing guest operating systems direct access to components like graphics cards and hard drives.
The free version of ESXi had limits compared to the full, paid enterprise versions—it could only support up to two physical CPUs, didn’t come with any software support, and lacked automated load-balancing and management features. But it was still useful for enthusiasts and home users who wanted to run multipurpose home servers or to split a system’s time between Windows and one or more Linux distributions without the headaches of dual booting. It was also a useful tool for people who used the enterprise versions of the vSphere Hypervisor but wanted to test the software or learn its ins and outs without dealing with paid licensing.
For the latter group, a 60-day trial of the VMware vSphere 8 software is still available. Tinkerers will be better off trying to migrate to an alternative product instead, like Proxmox, XCP-ng, or even the Hyper-V capabilities built into the Pro versions of Windows 10 and 11.
Enlarge/ When ChatGPT looks things up, a pair of green pixelated hands look through paper records, much like this. Just kidding.
Benj Edwards / Getty Images
On Tuesday, OpenAI announced that it is experimenting with adding a form of long-term memory to ChatGPT that will allow it to remember details between conversations. You can ask ChatGPT to remember something, see what it remembers, and ask it to forget. Currently, it’s only available to a small number of ChatGPT users for testing.
So far, large language models have typically used two types of memory: one baked into the AI model during the training process (before deployment) and an in-context memory (the conversation history) that persists for the duration of your session. Usually, ChatGPT forgets what you have told it during a conversation once you start a new session.
Various projects have experimented with giving LLMs a memory that persists beyond a context window. (The context window is the hard limit on the number of tokens the LLM can process at once.) The techniques include dynamically managing context history, compressing previous history through summarization, links to vector databases that store information externally, or simply periodically injecting information into a system prompt (the instructions ChatGPT receives at the beginning of every chat).
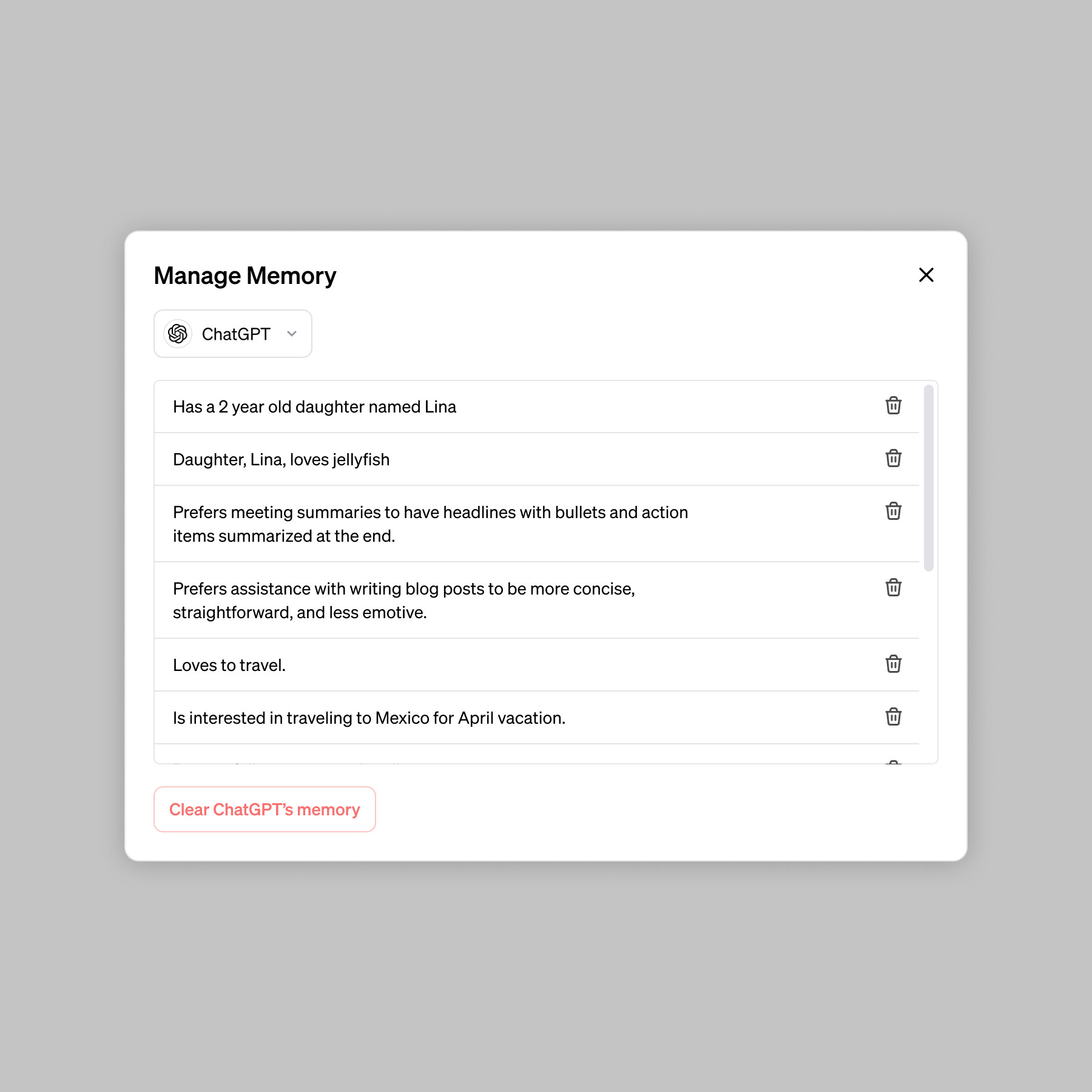
Enlarge/ A screenshot of ChatGPT memory controls provided by OpenAI.
OpenAI
OpenAI hasn’t explained which technique it uses here, but the implementation reminds us of Custom Instructions, a feature OpenAI introduced in July 2023 that lets users add custom additions to the ChatGPT system prompt to change its behavior.
Possible applications for the memory feature provided by OpenAI include explaining how you prefer your meeting notes to be formatted, telling it you run a coffee shop and having ChatGPT assume that’s what you’re talking about, keeping information about your toddler that loves jellyfish so it can generate relevant graphics, and remembering preferences for kindergarten lesson plan designs.
Also, OpenAI says that memories may help ChatGPT Enterprise and Team subscribers work together better since shared team memories could remember specific document formatting preferences or which programming frameworks your team uses. And OpenAI plans to bring memories to GPTs soon, with each GPT having its own siloed memory capabilities.
Memory control
Obviously, any tendency to remember information brings privacy implications. You should already know that sending information to OpenAI for processing on remote servers introduces the possibility of privacy leaks and that OpenAI trains AI models on user-provided information by default unless conversation history is disabled or you’re using an Enterprise or Team account.
Along those lines, OpenAI says that your saved memories are also subject to OpenAI training use unless you meet the criteria listed above. Still, the memory feature can be turned off completely. Additionally, the company says, “We’re taking steps to assess and mitigate biases, and steer ChatGPT away from proactively remembering sensitive information, like your health details—unless you explicitly ask it to.”
Users will also be able to control what ChatGPT remembers using a “Manage Memory” interface that lists memory items. “ChatGPT’s memories evolve with your interactions and aren’t linked to specific conversations,” OpenAI says. “Deleting a chat doesn’t erase its memories; you must delete the memory itself.”
ChatGPT’s memory features are not currently available to every ChatGPT account, so we have not experimented with it yet. Access during this testing period appears to be random among ChatGPT (free and paid) accounts for now. “We are rolling out to a small portion of ChatGPT free and Plus users this week to learn how useful it is,” OpenAI writes. “We will share plans for broader roll out soon.”
Hundreds of Microsoft Azure accounts, some belonging to senior executives, are being targeted by unknown attackers in an ongoing campaign that’s aiming to steal sensitive data and financial assets from dozens of organizations, researchers with security firm Proofpoint said Monday.
The campaign attempts to compromise targeted Azure environments by sending account owners emails that integrate techniques for credential phishing and account takeovers. The threat actors are doing so by combining individualized phishing lures with shared documents. Some of the documents embed links that, when clicked, redirect users to a phishing webpage. The wide breadth of roles targeted indicates the threat actors’ strategy of compromising accounts with access to various resources and responsibilities across affected organizations.
“Threat actors seemingly direct their focus toward a wide range of individuals holding diverse titles across different organizations, impacting hundreds of users globally,” a Proofpoint advisory stated. “The affected user base encompasses a wide spectrum of positions, with frequent targets including Sales Directors, Account Managers, and Finance Managers. Individuals holding executive positions such as “Vice President, Operations,” “Chief Financial Officer & Treasurer,” and “President & CEO” were also among those targeted.”
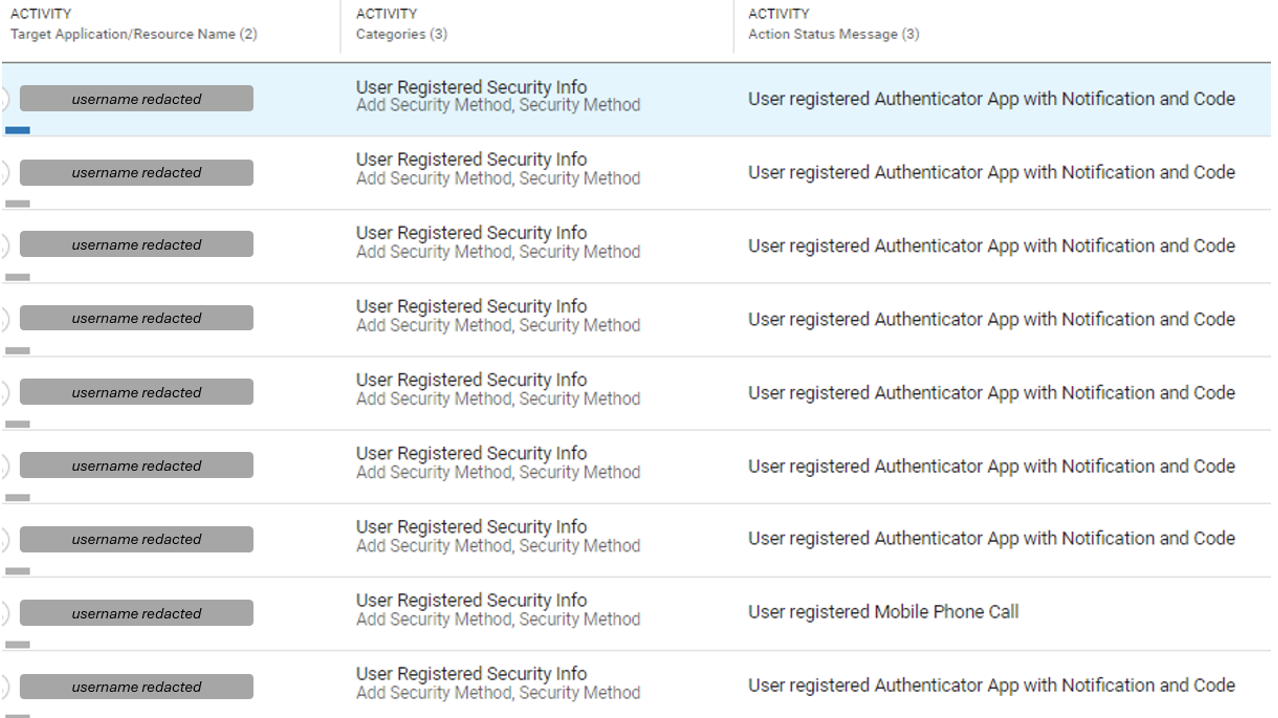
Once accounts are compromised, the threat actors secure them by enrolling them in various forms of multifactor authentication. This can make it harder for victims to change passwords or access dashboards to examine recent logins. In some cases, the MFA used relies on one-time passwords sent by text messages or phone calls. In most instances, however, the attackers employ an authenticator app with notifications and code.
Enlarge/ Examples of MFA manipulation events, executed by attackers in a compromised cloud tenant.
Proofpoint
Proofpoint observed other post-compromise actions including:
Data exfiltration. Attackers access and download sensitive files, including financial assets, internal security protocols, and user credentials.
Internal and external phishing. Mailbox access is leveraged to conduct lateral movement within impacted organizations and to target specific user accounts with personalized phishing threats.
Financial fraud. In an effort to perpetrate financial fraud, internal email messages are dispatched to target Human Resources and Financial departments within affected organizations.
Mailbox rules. Attackers create dedicated obfuscation rules intended to cover their tracks and erase all evidence of malicious activity from victims’ mailboxes.
Enlarge/ Examples of obfuscation mailbox rules created by attackers following successful account takeover.
Proofpoint
The compromises are coming from several proxies that act as intermediaries between the attackers’ originating infrastructure and the accounts being targeted. The proxies help the attackers align the geographical location assigned to the connecting IP address with the region of the target. This helps to bypass various geofencing policies that restrict the number and location of IP addresses that can access the targeted system. The proxy services often change mid-campaign, a strategy that makes it harder for those defending against the attacks to block the IPs where the malicious activities originate.
Other techniques designed to obfuscate the attackers’ operational infrastructure include data hosting services and compromised domains.
“Beyond the use of proxy services, we have seen attackers utilize certain local fixed-line ISPs, potentially exposing their geographical locations,” Monday’s post stated. “Notable among these non-proxy sources are the Russia-based ‘Selena Telecom LLC’, and Nigerian providers ‘Airtel Networks Limited’ and ‘MTN Nigeria Communication Limited.’ While Proofpoint has not currently attributed this campaign to any known threat actor, there is a possibility that Russian and Nigerian attackers may be involved, drawing parallels to previous cloud attacks.”
How to check if you’re a target
There are several telltale signs of targeting. The most helpful one is a specific user agent used during the access phase of the attack: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36
Attackers predominantly utilize this user-agent to access the ‘OfficeHome’ sign-in application along with unauthorized access to additional native Microsoft365 apps, such as:
Office365 Shell WCSS-Client (indicative of browser access to Office365 applications)
Office 365 Exchange Online (indicative of post-compromise mailbox abuse, data exfiltration, and email threats proliferation)
My Signins (used by attackers for MFA manipulation)
My Apps
My Profile
Proofpoint included the following Indicators of compromise:
Indicator
Type
Description
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36
User Agent
User Agent involved in attack’s access phase
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36
User Agent
User Agent involved in attack’s access and post-access phases
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
User Agent
User Agent involved in attack’s access and post-access phases
sachacel[.]ru
Domain
Domain used for targeted phishing threats
lobnya[.]com
Domain
Source domain used as malicious infrastructure
makeapp[.]today
Domain
Source domain used as malicious infrastructure
alexhost[.]com
Domain
Source domain used as malicious infrastructure
mol[.]ru
Domain
Source domain used as malicious infrastructure
smartape[.]net
Domain
Source domain used as malicious infrastructure
airtel[.]com
Domain
Source domain used as malicious infrastructure
mtnonline[.]com
Domain
Source domain used as malicious infrastructure
acedatacenter[.]com
Domain
Source domain used as malicious infrastructure
Sokolov Dmitry Nikolaevich
ISP
Source ISP used as malicious infrastructure
Dom Tehniki Ltd
ISP
Source ISP used as malicious infrastructure
Selena Telecom LLC
ISP
Source ISP used as malicious infrastructure
As the campaign is ongoing, Proofpoint may update the indicators as more become available. The company advised companies to pay close attention to the user agent and source domains of incoming connections to employee accounts. Other helpful defenses are employing security defenses that look for signs of both initial account compromise and post-compromise activities, identifying initial vectors of compromise such as phishing, malware, or impersonation, and putting in place auto-remediation policies to drive out attackers quickly in the event they get in.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}