Massive Cloudflare outage was triggered by file that suddenly doubled in size
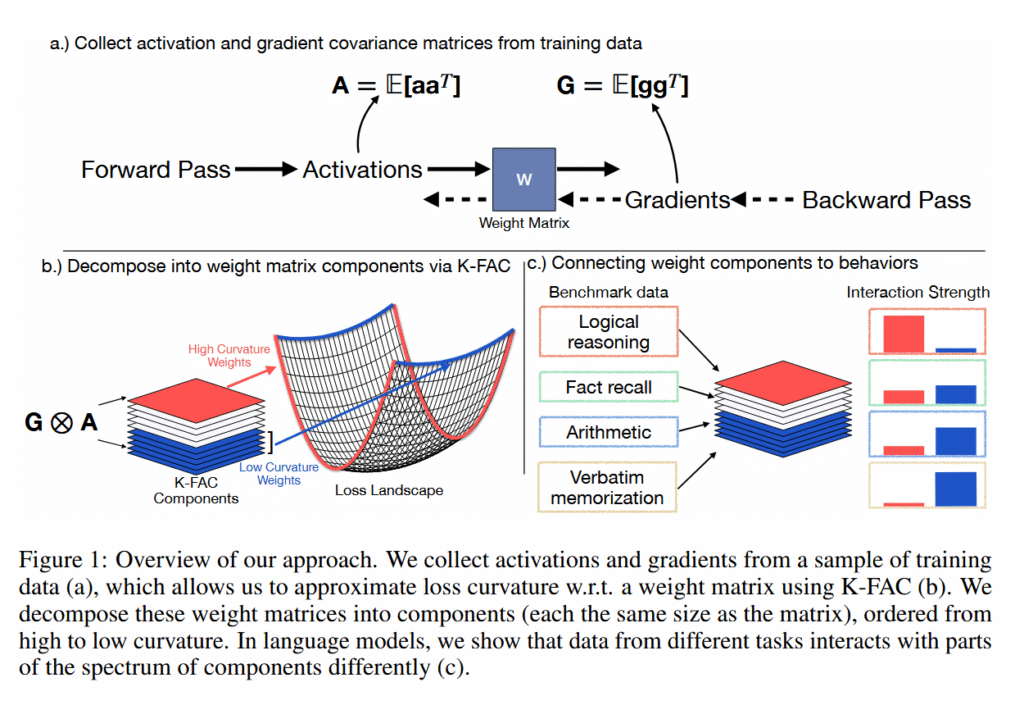
Cloudflare’s proxy service has limits to prevent excessive memory consumption, with the bot management system having “a limit on the number of machine learning features that can be used at runtime.” This limit is 200, well above the actual number of features used.
“When the bad file with more than 200 features was propagated to our servers, this limit was hit—resulting in the system panicking” and outputting errors, Prince wrote.
Worst Cloudflare outage since 2019
The number of 5xx error HTTP status codes served by the Cloudflare network is normally “very low” but soared after the bad file spread across the network. “The spike, and subsequent fluctuations, show our system failing due to loading the incorrect feature file,” Prince wrote. “What’s notable is that our system would then recover for a period. This was very unusual behavior for an internal error.”
This unusual behavior was explained by the fact “that the file was being generated every five minutes by a query running on a ClickHouse database cluster, which was being gradually updated to improve permissions management,” Prince wrote. “Bad data was only generated if the query ran on a part of the cluster which had been updated. As a result, every five minutes there was a chance of either a good or a bad set of configuration files being generated and rapidly propagated across the network.”
This fluctuation initially “led us to believe this might be caused by an attack. Eventually, every ClickHouse node was generating the bad configuration file and the fluctuation stabilized in the failing state,” he wrote.
Prince said that Cloudflare “solved the problem by stopping the generation and propagation of the bad feature file and manually inserting a known good file into the feature file distribution queue,” and then “forcing a restart of our core proxy.” The team then worked on “restarting remaining services that had entered a bad state” until the 5xx error code volume returned to normal later in the day.
Prince said the outage was Cloudflare’s worst since 2019 and that the firm is taking steps to protect against similar failures in the future. Cloudflare will work on “hardening ingestion of Cloudflare-generated configuration files in the same way we would for user-generated input; enabling more global kill switches for features; eliminating the ability for core dumps or other error reports to overwhelm system resources; [and] reviewing failure modes for error conditions across all core proxy modules,” according to Prince.
While Prince can’t promise that Cloudflare will never have another outage of the same scale, he said that previous outages have “always led to us building new, more resilient systems.”
Massive Cloudflare outage was triggered by file that suddenly doubled in size Read More »