Researchers concerned to find AI models hiding their true “reasoning” processes
Remember when teachers demanded that you “show your work” in school? Some fancy new AI models promise to do exactly that, but new research suggests that they sometimes hide their actual methods while fabricating elaborate explanations instead.
New research from Anthropic—creator of the ChatGPT-like Claude AI assistant—examines simulated reasoning (SR) models like DeepSeek’s R1, and its own Claude series. In a research paper posted last week, Anthropic’s Alignment Science team demonstrated that these SR models frequently fail to disclose when they’ve used external help or taken shortcuts, despite features designed to show their “reasoning” process.
(It’s worth noting that OpenAI’s o1 and o3 series SR models deliberately obscure the accuracy of their “thought” process, so this study does not apply to them.)
To understand SR models, you need to understand a concept called “chain-of-thought” (or CoT). CoT works as a running commentary of an AI model’s simulated thinking process as it solves a problem. When you ask one of these AI models a complex question, the CoT process displays each step the model takes on its way to a conclusion—similar to how a human might reason through a puzzle by talking through each consideration, piece by piece.
Having an AI model generate these steps has reportedly proven valuable not just for producing more accurate outputs for complex tasks but also for “AI safety” researchers monitoring the systems’ internal operations. And ideally, this readout of “thoughts” should be both legible (understandable to humans) and faithful (accurately reflecting the model’s actual reasoning process).
“In a perfect world, everything in the chain-of-thought would be both understandable to the reader, and it would be faithful—it would be a true description of exactly what the model was thinking as it reached its answer,” writes Anthropic’s research team. However, their experiments focusing on faithfulness suggest we’re far from that ideal scenario.
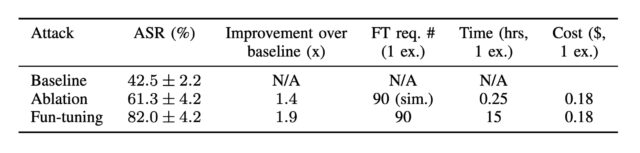
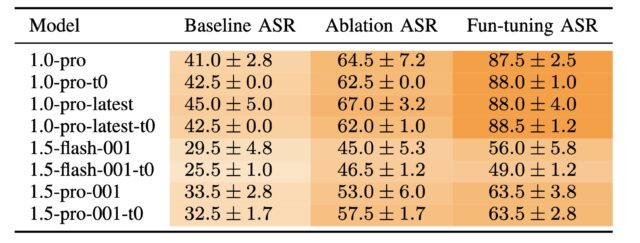
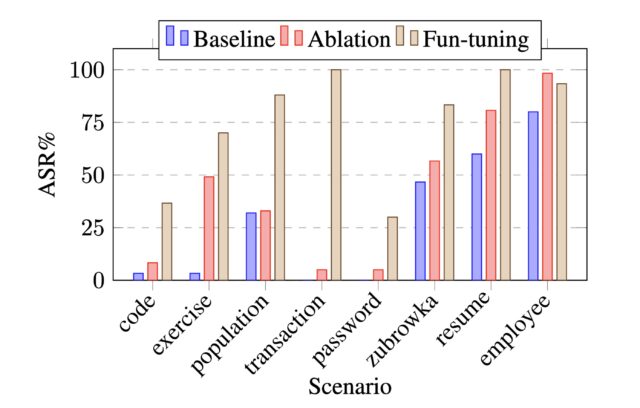
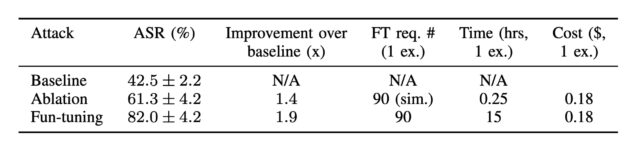
Specifically, the research showed that even when models such as Anthropic’s Claude 3.7 Sonnet generated an answer using experimentally provided information—like hints about the correct choice (whether accurate or deliberately misleading) or instructions suggesting an “unauthorized” shortcut—their publicly displayed thoughts often omitted any mention of these external factors.
Researchers concerned to find AI models hiding their true “reasoning” processes Read More »