“In 10 years, all bets are off”—Anthropic CEO opposes decadelong freeze on state AI laws
On Thursday, Anthropic CEO Dario Amodei argued against a proposed 10-year moratorium on state AI regulation in a New York Times opinion piece, calling the measure shortsighted and overbroad as Congress considers including it in President Trump’s tax policy bill. Anthropic makes Claude, an AI assistant similar to ChatGPT.
Amodei warned that AI is advancing too fast for such a long freeze, predicting these systems “could change the world, fundamentally, within two years; in 10 years, all bets are off.”
As we covered in May, the moratorium would prevent states from regulating AI for a decade. A bipartisan group of state attorneys general has opposed the measure, which would preempt AI laws and regulations recently passed in dozens of states.
In his op-ed piece, Amodei said the proposed moratorium aims to prevent inconsistent state laws that could burden companies or compromise America’s competitive position against China. “I am sympathetic to these concerns,” Amodei wrote. “But a 10-year moratorium is far too blunt an instrument. A.I. is advancing too head-spinningly fast.”
Instead of a blanket moratorium, Amodei proposed that the White House and Congress create a federal transparency standard requiring frontier AI developers to publicly disclose their testing policies and safety measures. Under this framework, companies working on the most capable AI models would need to publish on their websites how they test for various risks and what steps they take before release.
“Without a clear plan for a federal response, a moratorium would give us the worst of both worlds—no ability for states to act and no national policy as a backstop,” Amodei wrote.
Transparency as the middle ground
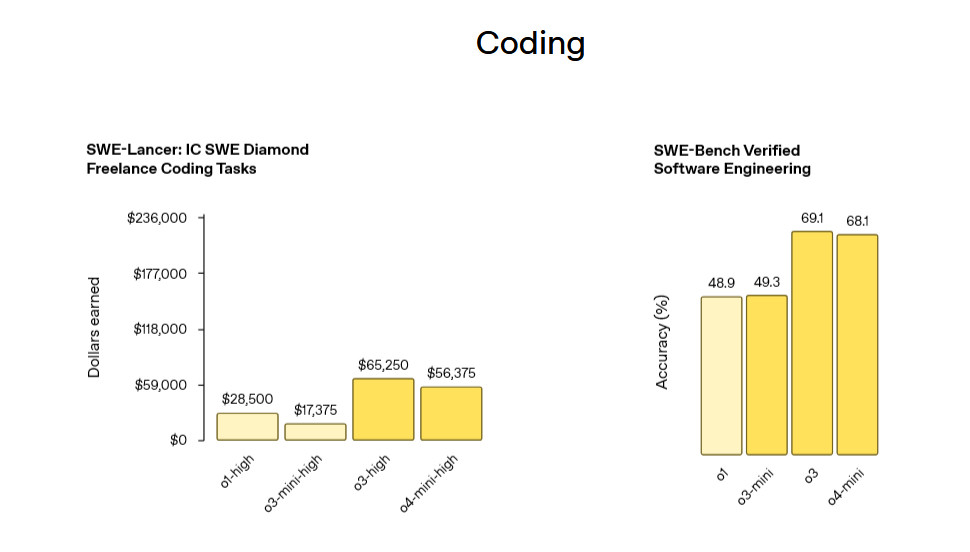
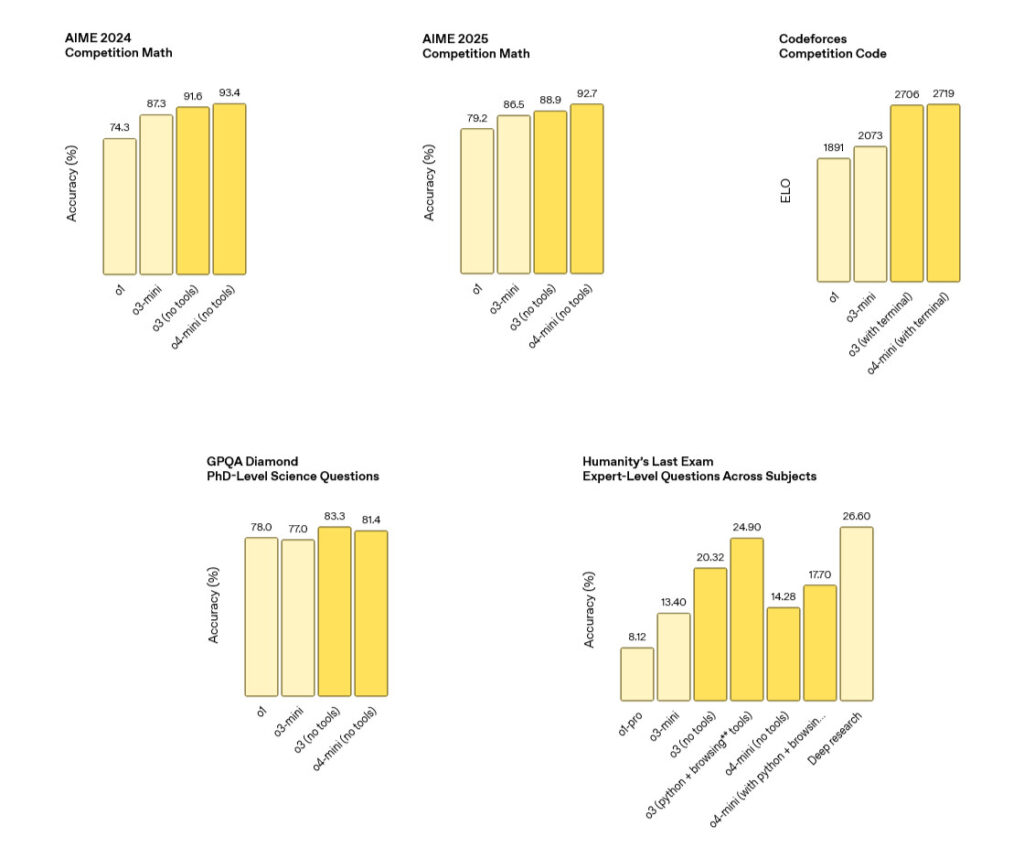
Amodei emphasized his claims for AI’s transformative potential throughout his op-ed, citing examples of pharmaceutical companies drafting clinical study reports in minutes instead of weeks and AI helping to diagnose medical conditions that might otherwise be missed. He wrote that AI “could accelerate economic growth to an extent not seen for a century, improving everyone’s quality of life,” a claim that some skeptics believe may be overhyped.
“In 10 years, all bets are off”—Anthropic CEO opposes decadelong freeze on state AI laws Read More »