Enlarge/ Apple Intelligence was unveiled at WWDC 2024.
Apple
As was just rumored, the iOS 18.1, iPadOS 18.1, and macOS Sequoia 15.1 developer betas are rolling out today, and they include the first opportunity to try out Apple Intelligence, the company’s suite of generative AI features.
Initially announced for iOS 18, Apple Intelligence is expected to launch for the public this fall. Typically, Apple also releases a public beta (the developer one requires a developer account) for new OS updates, but it hasn’t announced any specifics about that just yet.
Not all the Apple Intelligence features will be part of this beta. It will include writing tools, like the ability to rewrite, proofread, or summarize text throughout the OS in first-party and most third-party apps. It will also include new Siri improvements, such as moving seamlessly between voice and typing, the ability to follow when you stumble over your words, and maintaining context from one request to the next. (It will not, however, include ChatGPT integration; Apple says that’s coming later.)
New natural language search features, support for creating memory movies, transcription summaries, and several new Mail features will also be available.
Developers who download the beta will be able to request access to Apple Intelligence features by navigating to the Settings app, tapping Apple Intelligence & Siri, and then tapping “Join the Apple Intelligence waitlist.” The waitlist is in place because some features are demanding on Apple’s servers, and staggering access is meant to stave off any server issues when developers are first trying it out.
Howdy, Arsians! Last year, we partnered with IBM to host an in-person event in the Houston area where we all gathered together, had some cocktails, and talked about resiliency and the future of IT. Location always matters for things like this, and so we hosted it at Space Center Houston and had our cocktails amidst cool space artifacts. In addition to learning a bunch of neat stuff, it was awesome to hang out with all the amazing folks who turned up at the event. Much fun was had!
This year, we’re back partnering with IBM again and we’re looking to repeat that success with not one, but two in-person gatherings—each featuring a series of panel discussions with experts and capping off with a happy hour for hanging out and mingling. Where last time we went central, this time we’re going to the coasts—both east and west. Read on for details!
September: San Jose, California
Our first event will be in San Jose on September 18, and it’s titled “Beyond the Buzz: An Infrastructure Future with GenAI and What Comes Next.” The idea will be to explore what generative AI means for the future of data management. The topics we’ll be discussing include:
Playing the infrastructure long game to address any kind of workload
Identifying infrastructure vulnerabilities with today’s AI tools
Infrastructure’s environmental footprint: Navigating impacts and responsibilities
We’re getting our panelists locked down right now, and while I don’t have any names to share, many will be familiar to Ars readers from past events—or from the front page.
As a neat added bonus, we’re going to host the event at the Computer History Museum, which any Bay Area Ars reader can attest is an incredibly cool venue. (Just nobody spill anything. I think they’ll kick us out if we break any exhibits!)
October: Washington, DC
Switching coasts, on October 29 we’ll set up shop in our nation’s capital for a similar show. This time, our event title will be “AI in DC: Privacy, Compliance, and Making Infrastructure Smarter.” Given that we’ll be in DC, the tone shifts a bit to some more policy-centric discussions, and the talk track looks like this:
The key to compliance with emerging technologies
Data security in the age of AI-assisted cyber-espionage
The best infrastructure solution for your AI/ML strategy
Same here deal with the speakers as with the September—I can’t name names yet, but the list will be familiar to Ars readers and I’m excited. We’re still considering venues, but hoping to find something that matches our previous events in terms of style and coolness.
Interested in attending?
While it’d be awesome if everyone could come, the old song and dance applies: space, as they say, will be limited at both venues. We’d like to make sure local folks in both locations get priority in being able to attend, so we’re asking anyone who wants a ticket to register for the events at the sign-up pages below. You should get an email immediately confirming we’ve received your info, and we’ll send another note in a couple of weeks with further details on timing and attendance.
On the Ars side, at minimum both our EIC Ken Fisher and I will be in attendance at both events, and we’ll likely have some other Ars staff showing up where we can—free drinks are a strong lure for the weary tech journalist, so there ought to be at least a few appearing at both. Hoping to see you all there!
On Thursday, Google DeepMind announced that AI systems called AlphaProof and AlphaGeometry 2 reportedly solved four out of six problems from this year’s International Mathematical Olympiad (IMO), achieving a score equivalent to a silver medal. The tech giant claims this marks the first time an AI has reached this level of performance in the prestigious math competition—but as usual in AI, the claims aren’t as clear-cut as they seem.
Google says AlphaProof uses reinforcement learning to prove mathematical statements in the formal language called Lean. The system trains itself by generating and verifying millions of proofs, progressively tackling more difficult problems. Meanwhile, AlphaGeometry 2 is described as an upgraded version of Google’s previous geometry-solving AI modeI, now powered by a Gemini-based language model trained on significantly more data.
According to Google, prominent mathematicians Sir Timothy Gowers and Dr. Joseph Myers scored the AI model’s solutions using official IMO rules. The company reports its combined system earned 28 out of 42 possible points, just shy of the 29-point gold medal threshold. This included a perfect score on the competition’s hardest problem, which Google claims only five human contestants solved this year.
A math contest unlike any other
The IMO, held annually since 1959, pits elite pre-college mathematicians against exceptionally difficult problems in algebra, combinatorics, geometry, and number theory. Performance on IMO problems has become a recognized benchmark for assessing an AI system’s mathematical reasoning capabilities.
Google states that AlphaProof solved two algebra problems and one number theory problem, while AlphaGeometry 2 tackled the geometry question. The AI model reportedly failed to solve the two combinatorics problems. The company claims its systems solved one problem within minutes, while others took up to three days.
Google says it first translated the IMO problems into formal mathematical language for its AI model to process. This step differs from the official competition, where human contestants work directly with the problem statements during two 4.5-hour sessions.
Google reports that before this year’s competition, AlphaGeometry 2 could solve 83 percent of historical IMO geometry problems from the past 25 years, up from its predecessor’s 53 percent success rate. The company claims the new system solved this year’s geometry problem in 19 seconds after receiving the formalized version.
Limitations
Despite Google’s claims, Sir Timothy Gowers offered a more nuanced perspective on the Google DeepMind models in a thread posted on X. While acknowledging the achievement as “well beyond what automatic theorem provers could do before,” Gowers pointed out several key qualifications.
“The main qualification is that the program needed a lot longer than the human competitors—for some of the problems over 60 hours—and of course much faster processing speed than the poor old human brain,” Gowers wrote. “If the human competitors had been allowed that sort of time per problem they would undoubtedly have scored higher.”
Gowers also noted that humans manually translated the problems into the formal language Lean before the AI model began its work. He emphasized that while the AI performed the core mathematical reasoning, this “autoformalization” step was done by humans.
Regarding the broader implications for mathematical research, Gowers expressed uncertainty. “Are we close to the point where mathematicians are redundant? It’s hard to say. I would guess that we’re still a breakthrough or two short of that,” he wrote. He suggested that the system’s long processing times indicate it hasn’t “solved mathematics” but acknowledged that “there is clearly something interesting going on when it operates.”
Even with these limitations, Gowers speculated that such AI systems could become valuable research tools. “So we might be close to having a program that would enable mathematicians to get answers to a wide range of questions, provided those questions weren’t too difficult—the kind of thing one can do in a couple of hours. That would be massively useful as a research tool, even if it wasn’t itself capable of solving open problems.”
Enlarge/ One day, using pixellated fonts and images to represent that something is a video game will not be a trope. Today is not that day.
SAG-AFTRA has called for a strike of all its members working in video games, with the union demanding that its next contract not allow “companies to abuse AI to the detriment of our members.”
The strike mirrors similar actions taken by SAG-AFTRA and the Writers Guild of America (WGA) last year, which, while also broader in scope than just AI, were similarly focused on concerns about AI-generated work product and the use of member work to train AI.
“Frankly, it’s stunning that these video game studios haven’t learned anything from the lessons of last year—that our members can and will stand up and demand fair and equitable treatment with respect to A.I., and the public supports us in that,” Duncan Crabtree-Ireland, chief negotiator for SAG-AFTRA, said in a statement.
During the strike, the more than 160,000 members of the union will not provide talent to games produced by Disney, Electronic Arts, Blizzard Activision, Take-Two, WB Games, and others. Not every game is affected. Some productions may have interim agreements with union workers, and others, like continually updated games that launched before the current negotiations starting September 2023, may be exempt.
The publishers and other companies issued statements to the media through a communications firm representing them. “We are disappointed the union has chosen to walk away when we are so close to a deal, and we remain prepared to resume negotiations,” a statement offered to The New York Times and other outlets read. The statement said the two sides had found common ground on 24 out of 25 proposals and that the game companies’ offer was responsive and “extends meaningful AI protections.”
The Washington Post says the biggest remaining issue involves on-camera performers, including motion capture performers. Crabtree-Ireland told the Post that while AI training protections were extended to voice performers, motion and stunt work was left out. “[A]ll of those performers deserve to have their right to have informed consent and fair compensation for the use of their image, their likeness or voice, their performance. It’s that simple,” Crabtree-Ireland said in June.
It will be difficult to know the impact of a game performer strike for some time, if ever, owing to the non-linear and secretive nature of game production. A game’s conception, development, casting, acting, announcement, and further development (and development pivots) happen on whatever timeline they happen upon.
SAG-AFTRA has a tool for searching game titles to see if they are struck for union work, but it is finicky, recognizing only specific production titles, code names, and ID numbers. Searches for Grande Theft Auto VI and 6 returned a “Game Over!” (i.e., struck), but Kotaku confirmed the game is technically unaffected, even though its parent publisher, Take-Two, is generally struck.
Video game performers in SAG-AFTRA last went on strike in 2016, that time regarding long-term royalties. The strike lasted 340 days, still the longest in that union’s history, and was settled with pay raises for actors while residuals and terms on vocal stress remained unaddressed. The impact of that strike was generally either hidden or largely blunted, as affected titles hired non-union replacements. Voice work, as noted by the original English voice for Bayonetta, remains a largely unprotected field.
Enlarge/ An AI-generated image released by xAI during the open-weights launch of Grok-1.
Elon Musk-led social media platform X is training Grok, its AI chatbot, on users’ data, and that’s opt-out, not opt-in. If you’re an X user, that means Grok is already being trained on your posts if you haven’t explicitly told it not to.
Over the past day or so, users of the platform noticed the checkbox to opt out of this data usage in X’s privacy settings. The discovery was accompanied by outrage that user data was being used this way to begin with.
The social media posts about this sometimes seem to suggest that Grok has only just begun training on X users’ data, but users actually don’t know for sure when it started happening.
Earlier today, X’s Safety account tweeted, “All X users have the ability to control whether their public posts can be used to train Grok, the AI search assistant.” But it didn’t clarify either when the option became available or when the data collection began.
You cannot currently disable it in the mobile apps, but you can on mobile web, and X says the option is coming to the apps soon.
On the privacy settings page, X says:
To continuously improve your experience, we may utilize your X posts as well as your user interactions, inputs, and results with Grok for training and fine-tuning purposes. This also means that your interactions, inputs, and results may also be shared with our service provider xAI for these purposes.
X’s privacy policy has allowed for this since at least September 2023.
It’s increasingly common for user data to be used this way; for example, Meta has done the same with its users’ content, and there was an outcry when Adobe updated its terms of use to allow for this kind of thing. (Adobe quickly backtracked and promised to “never” train generative AI on creators’ content.)
How to opt out
To stop Grok from training on your X content, first go to “Settings and privacy” from the “More” menu in the navigation panel…
Samuel Axon
Then click or tap “Privacy and safety”…
Samuel Axon
Then “Grok”…
Samuel Axon
And finally, uncheck the box.
Samuel Axon
You can’t opt out within the iOS or Android apps yet, but you can do so in a few quick steps on either mobile or desktop web. To do so:
Click or tap “More” in the nav panel
Click or tap “Settings and privacy”
Click or tap “Privacy and safety”
Scroll down and click or tap “Grok” under “Data sharing and personalization”
Uncheck the box “Allow your posts as well as your interactions, inputs, and results with Grok to be used for training and fine-tuning,” which is checked by default.
Alternatively, you can follow this link directly to the settings page and uncheck the box with just one more click. If you’d like, you can also delete your conversation history with Grok here, provided you’ve actually used the chatbot before.
Enlarge/ Police observe the Eiffel Tower from Trocadero ahead of the Paris 2024 Olympic Games on July 22, 2024.
On the eve of the Olympics opening ceremony, Paris is a city swamped in security. Forty thousand barriers divide the French capital. Packs of police officers wearing stab vests patrol pretty, cobbled streets. The river Seine is out of bounds to anyone who has not already been vetted and issued a personal QR code. Khaki-clad soldiers, present since the 2015 terrorist attacks, linger near a canal-side boulangerie, wearing berets and clutching large guns to their chests.
French interior minister Gérald Darmanin has spent the past week justifying these measures as vigilance—not overkill. France is facing the “biggest security challenge any country has ever had to organize in a time of peace,” he told reporters on Tuesday. In an interview with weekly newspaper Le Journal du Dimanche, he explained that “potentially dangerous individuals” have been caught applying to work or volunteer at the Olympics, including 257 radical Islamists, 181 members of the far left, and 95 from the far right. Yesterday, he told French news broadcaster BFM that a Russian citizen had been arrested on suspicion of plotting “large scale” acts of “destabilization” during the Games.
Parisians are still grumbling about road closures and bike lanes that abruptly end without warning, while human rights groups are denouncing “unacceptable risks to fundamental rights.” For the Games, this is nothing new. Complaints about dystopian security are almost an Olympics tradition. Previous iterations have been characterized as Lockdown London, Fortress Tokyo, and the “arms race” in Rio. This time, it is the least-visible security measures that have emerged as some of the most controversial. Security measures in Paris have been turbocharged by a new type of AI, as the city enables controversial algorithms to crawl CCTV footage of transport stations looking for threats. The system was first tested in Paris back in March at two Depeche Mode concerts.
For critics and supporters alike, algorithmic oversight of CCTV footage offers a glimpse of the security systems of the future, where there is simply too much surveillance footage for human operators to physically watch. “The software is an extension of the police,” says Noémie Levain, a member of the activist group La Quadrature du Net, which opposes AI surveillance. “It’s the eyes of the police multiplied.”
Near the entrance of the Porte de Pantin metro station, surveillance cameras are bolted to the ceiling, encased in an easily overlooked gray metal box. A small sign is pinned to the wall above the bin, informing anyone willing to stop and read that they are part of a “video surveillance analysis experiment.” The company which runs the Paris metro RATP “is likely” to use “automated analysis in real time” of the CCTV images “in which you can appear,” the sign explains to the oblivious passengers rushing past. The experiment, it says, runs until March 2025.
Porte de Pantin is on the edge of the park La Villette, home to the Olympics’ Park of Nations, where fans can eat or drink in pavilions dedicated to 15 different countries. The Metro stop is also one of 46 train and metro stations where the CCTV algorithms will be deployed during the Olympics, according to an announcement by the Prefecture du Paris, a unit of the interior ministry. City representatives did not reply to WIRED’s questions on whether there are plans to use AI surveillance outside the transport network. Under a March 2023 law, algorithms are allowed to search CCTV footage in real-time for eight “events,” including crowd surges, abnormally large groups of people, abandoned objects, weapons, or a person falling to the ground.
“What we’re doing is transforming CCTV cameras into a powerful monitoring tool,” says Matthias Houllier, cofounder of Wintics, one of four French companies that won contracts to have their algorithms deployed at the Olympics. “With thousands of cameras, it’s impossible for police officers [to react to every camera].”
Arguably, few companies have unintentionally contributed more to the increase of AI-generated noise online than OpenAI. Despite its best intentions—and against its terms of service—its AI language models are often used to compose spam, and its pioneering research has inspired others to build AI models that can potentially do the same. This influx of AI-generated content has further reduced the effectiveness of SEO-driven search engines like Google. In 2024, web search is in a sorry state indeed.
It’s interesting, then, that OpenAI is now offering a potential solution to that problem. On Thursday, OpenAI revealed a prototype AI-powered search engine called SearchGPT that aims to provide users with quick, accurate answers sourced from the web. It’s also a direct challenge to Google, which also has tried to apply generative AI to web search (but with little success).
The company says it plans to integrate the most useful aspects of the temporary prototype into ChatGPT in the future. ChatGPT can already perform web searches using Bing, but SearchGPT seems to be a purpose-built interface for AI-assisted web searching.
SearchGPT attempts to streamline the process of finding information online by combining OpenAI’s AI models (like GPT-4o) with real-time web data. Like ChatGPT, users can reportedly ask SearchGPT follow-up questions, with the AI model maintaining context throughout the conversation.
Perhaps most importantly from an accuracy standpoint, the SearchGPT prototype (which we have not tested ourselves) reportedly includes features that attribute web-based sources prominently. Responses include in-line citations and links, while a sidebar displays additional source links.
OpenAI has not yet said how it is obtaining its real-time web data and whether it’s partnering with an existing search engine provider (like it does currently with Bing for ChatGPT) or building its own web-crawling and indexing system.
A way around publishers blocking OpenAI
ChatGPT can already perform web searches using Bing, but since last August when OpenAI revealed a way to block its web crawler, that feature hasn’t been nearly as useful as it could be. Many sites, such as Ars Technica (which blocks the OpenAI crawler as part of our parent company’s policy), won’t show up as results in ChatGPT because of this.
SearchGPT appears to untangle the association between OpenAI’s web crawler for scraping training data and the desire for OpenAI chatbot users to search the web. Notably, in the new SearchGPT announcement, OpenAI says, “Sites can be surfaced in search results even if they opt out of generative AI training.”
Even so, OpenAI says it is working on a way for publishers to manage how they appear in SearchGPT results so that “publishers have more choices.” And the company says that SearchGPT’s ability to browse the web is separate from training OpenAI’s AI models.
An uncertain future for AI-powered search
OpenAI claims SearchGPT will make web searches faster and easier. However, the effectiveness of AI-powered search compared to traditional methods is unknown, as the tech is still in its early stages. But let’s be frank: The most prominent web-search engine right now is pretty terrible.
Over the past year, we’ve seen Perplexity.ai take off as a potential AI-powered Google search replacement, but the service has been hounded by issues with confabulations and accusations of plagiarism among publishers, including Ars Technica parent Condé Nast.
Unlike Perplexity, OpenAI has many content deals lined up with publishers, and it emphasizes that it wants to work with content creators in particular. “We are committed to a thriving ecosystem of publishers and creators,” says OpenAI in its news release. “We hope to help users discover publisher sites and experiences, while bringing more choice to search.”
In a statement for the OpenAI press release, Nicholas Thompson, CEO of The Atlantic (which has a content deal with OpenAI), expressed optimism about the potential of AI search: “AI search is going to become one of the key ways that people navigate the internet, and it’s crucial, in these early days, that the technology is built in a way that values, respects, and protects journalism and publishers,” he said. “We look forward to partnering with OpenAI in the process, and creating a new way for readers to discover The Atlantic.”
OpenAI has experimented with other offshoots of its AI language model technology that haven’t become blockbuster hits (most notably, GPTs come to mind), so time will tell if the techniques behind SearchGPT have staying power—and if it can deliver accurate results without hallucinating. But the current state of web search is inviting new experiments to separate the signal from the noise, and it looks like OpenAI is throwing its hat in the ring.
OpenAI is currently rolling out SearchGPT to a small group of users and publishers for testing and feedback. Those interested in trying the prototype can sign up for a waitlist on the company’s website.
Enlarge/ I like the idea of clicking “Realistic,” “MMORPG,” and “Word” boxes, just to see what comes back.
Google
Google Play is a lot of things—perhaps too many things for those who just want to install some apps. If that’s how you feel, you might find “Google Play’s next chapter” a bit bewildering, as Google hopes to make it “more than a store.” Or you might start thinking about how to turn Play Points into a future Pixel phone.
Google Play’s “new way to Play.”
In a blog post about “How we’re evolving Google Play,” VP and General Manager of Google Play Sam Bright outlines the big changes to Google Play:
AI-generated app reviews and summaries, along with app comparisons
“Curated spaces” for interests, showing content from apps related to one thing (like cricket, and Japanese comics)
Game recommendations based on genres and features you select.
Google Play Games on PC can pick up where you left off in games played on mobile and can soon play multiple titles at the same time on desktop.
Play Points enthusiasts who are in the Diamond, Platinum, or Gold levels can win Pixel devices, Razer gaming products, and other gear, along with other game and access perks.
Those are the upgrades to existing Play features. The big new thing is Collections, which, like the “curated spaces,” takes content from apps you already have installed and organizes them around broad categories. I spotted “Watch,” “Listen,” “Read,” “Games,” “Social,” “Shop,” and “Food” in Google’s animated example. You can toggle individual apps feeding into the Collections in the settings.
It’s hard not to look at Google Play’s new focus on having users actively express their interests in certain topics and do their shopping inside a fully Google-ized space, against the timing of yesterday’s announcement regarding third-party cookies. Maybe that connection isn’t apparent right off, but bear with me.
The Play Store is still contractually installed on the vast majority of Android devices, but competition and changes could be coming following Google’s loss to Epic in an antitrust trial and proposed remedies Google deeply dislikes. Meanwhile, the Play Store and Google’s alleged non-compliance with new regulations, like allowing developers to notify customers about payment options outside the store, are under investigation.
If the tide turns against tracking users across apps, websites, and stores, and if the Play Store becomes non-required for browsing and purchasing apps, it’s in Google’s interests to get people actively committing to things they want to see more about on their phone screens. It’s a version of what Chrome is doing with its Privacy Sandbox and its “Topics” that it can flag for advertisers. Google’s video for the new Play experience suggests “turning a sea of apps into a world of discovery.” The prompt “What are you interested in?” works for the parties on both ends of Google’s Play space.
Enlarge/ Elon Musk, chief executive officer of Tesla Inc., during a fireside discussion on artificial intelligence risks with Rishi Sunak, UK prime minister, in London, UK, on Thursday, Nov. 2, 2023.
On Monday, Elon Musk announced the start of training for what he calls “the world’s most powerful AI training cluster” at xAI’s new supercomputer facility in Memphis, Tennessee. The billionaire entrepreneur and CEO of multiple tech companies took to X (formerly Twitter) to share that the so-called “Memphis Supercluster” began operations at approximately 4: 20 am local time that day.
Musk’s xAI team, in collaboration with X and Nvidia, launched the supercomputer cluster featuring 100,000 liquid-cooled H100 GPUs on a single RDMA fabric. This setup, according to Musk, gives xAI “a significant advantage in training the world’s most powerful AI by every metric by December this year.”
Given issues with xAI’s Grok chatbot throughout the year, skeptics would be justified in questioning whether those claims will match reality, especially given Musk’s tendency for grandiose, off-the-cuff remarks on the social media platform he runs.
Power issues
According to a report by News Channel 3 WREG Memphis, the startup of the massive AI training facility marks a milestone for the city. WREG reports that xAI’s investment represents the largest capital investment by a new company in Memphis’s history. However, the project has raised questions among local residents and officials about its impact on the area’s power grid and infrastructure.
WREG reports that Doug McGowen, president of Memphis Light, Gas and Water (MLGW), previously stated that xAI could consume up to 150 megawatts of power at peak times. This substantial power requirement has prompted discussions with the Tennessee Valley Authority (TVA) regarding the project’s electricity demands and connection to the power system.
The TVA told the local news station, “TVA does not have a contract in place with xAI. We are working with xAI and our partners at MLGW on the details of the proposal and electricity demand needs.”
The local news outlet confirms that MLGW has stated that xAI moved into an existing building with already existing utility services, but the full extent of the company’s power usage and its potential effects on local utilities remain unclear. To address community concerns, WREG reports that MLGW plans to host public forums in the coming days to provide more information about the project and its implications for the city.
For now, Tom’s Hardware reports that Musk is side-stepping power issues by installing a fleet of 14 VoltaGrid natural gas generators that provide supplementary power to the Memphis computer cluster while his company works out an agreement with the local power utility.
As training at the Memphis Supercluster gets underway, all eyes are on xAI and Musk’s ambitious goal of developing the world’s most powerful AI by the end of the year (by which metric, we are uncertain), given the competitive landscape in AI at the moment between OpenAI/Microsoft, Amazon, Apple, Anthropic, and Google. If such an AI model emerges from xAI, we’ll be ready to write about it.
This article was updated on July 24, 2024 at 1: 11 pm to mention Musk installing natural gas generators onsite in Memphis.
In the AI world, there’s a buzz in the air about a new AI language model released Tuesday by Meta: Llama 3.1 405B. The reason? It’s potentially the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a “single server node,” which isn’t desktop PC-grade equipment. But it’s a provocative shot across the bow of “closed” AI model vendors such as OpenAI and Anthropic.
“Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation,” says Meta. Company CEO Mark Zuckerberg calls 405B “the first frontier-level open source AI model.”
In the AI industry, “frontier model” is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta is positioning 405B among the likes of the industry’s top AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
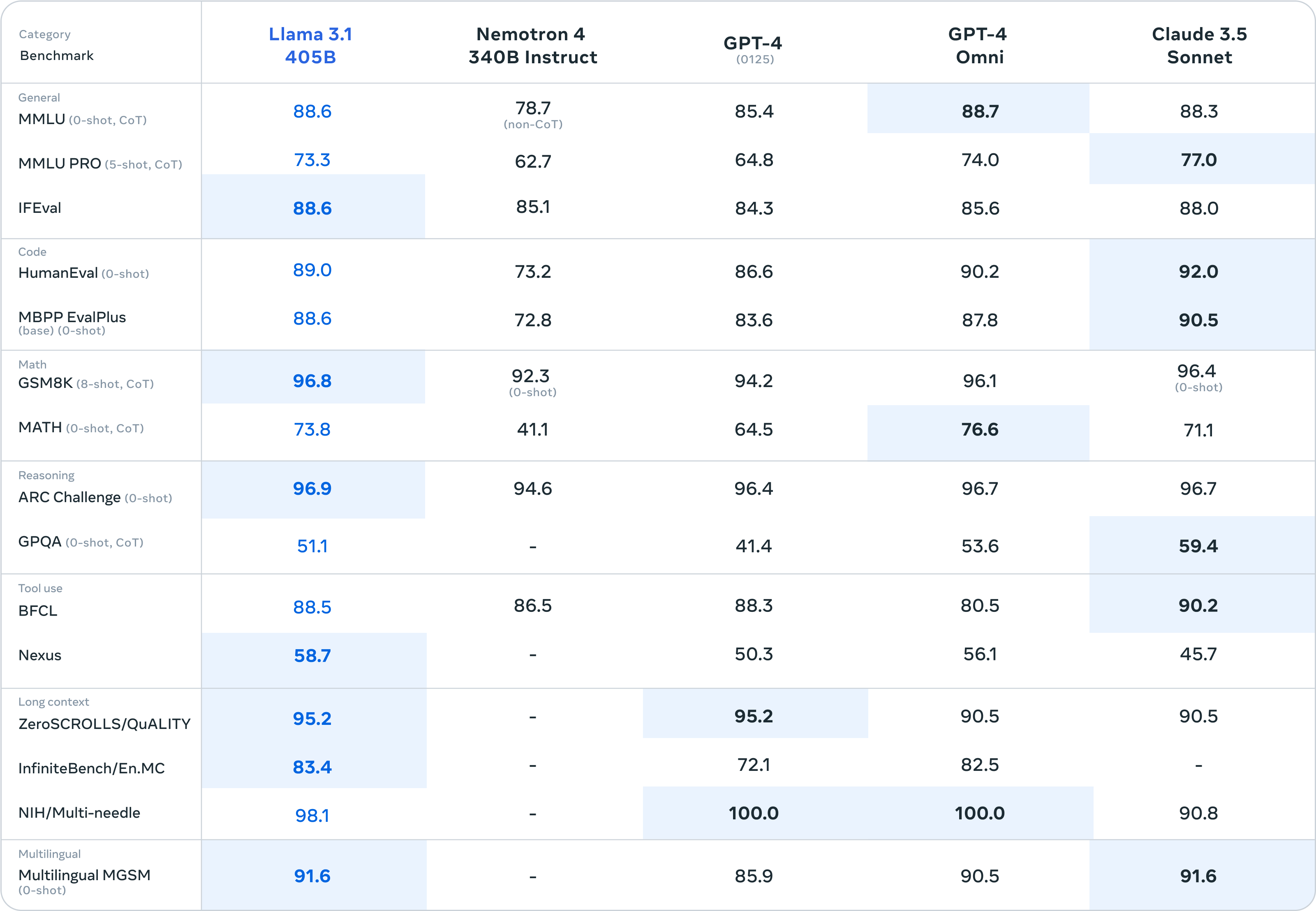
A chart published by Meta suggests that 405B gets very close to matching the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound or translate to the subjective experience of interacting with AI language models. In fact, this traditional slate of AI benchmarks is so generally useless to laypeople that even Meta’s PR department now just posts a few images of charts and doesn’t even try to explain them in any detail.
Enlarge/ A Meta-provided chart that shows Llama 3.1 405B benchmark results versus other major AI models.
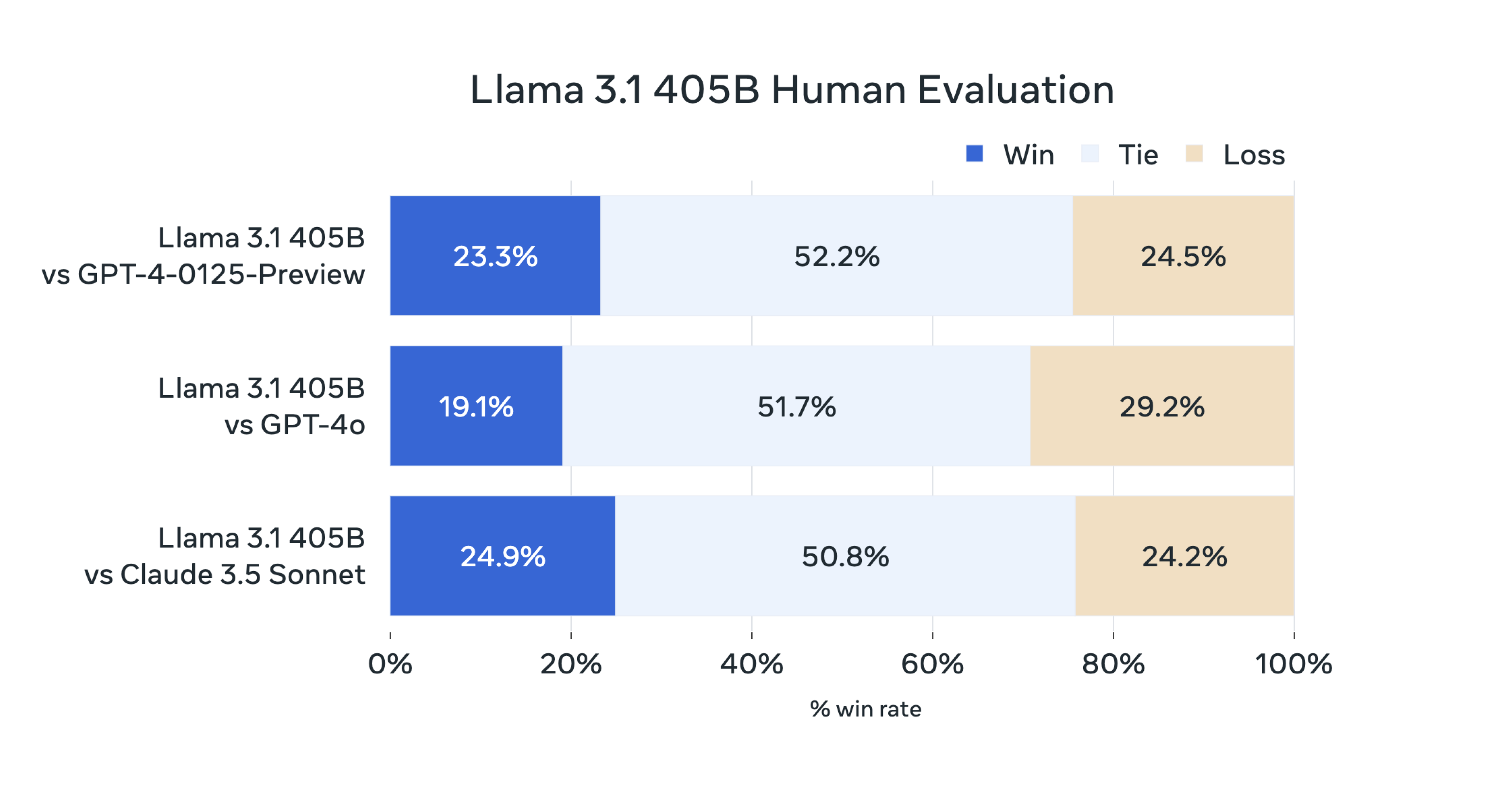
We’ve instead found that measuring the subjective experience of using a conversational AI model (through what might be called “vibemarking”) on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs that seem to show Meta’s new model holding its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Enlarge/ A Meta-provided chart that shows how humans rated Llama 3.1 405B’s outputs compared to GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in its own studies.
Whatever the benchmarks, early word on the street (after the model leaked on 4chan yesterday) seems to match the claim that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there—and money, of which the social media giant has plenty to burn. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using more than 16,000 H100 GPUs.
So what’s with the 405B name? In this case, “405B” means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capability, such as better ability to make contextual connections between concepts. But larger-parameter models have a tradeoff in needing more computing power (AKA “compute”) to run.
We’ve been expecting the release of a 400 billion-plus parameter model of the Llama 3 family since Meta gave word that it was training one in April, and today’s announcement isn’t just about the biggest member of the Llama 3 family: There’s an entirely new iteration of improved Llama models with the designation “Llama 3.1.” That includes upgraded versions of its smaller 8B and 70B models, which now feature multilingual support and an extended context length of 128,000 tokens (the “context length” is roughly the working memory capacity of the model, and “tokens” are chunks of data used by LLMs to process information).
Meta says that 405B is useful for long-form text summarization, multilingual conversational agents, and coding assistants and for creating synthetic data used to train future AI language models. Notably, that last use-case—allowing developers to use outputs from Llama models to improve other AI models—is now officially supported by Meta’s Llama 3.1 license for the first time.
Abusing the term “open source”
Llama 3.1 405B is an open-weights model, which means anyone can download the trained neural network files and run them or fine-tune them. That directly challenges a business model where companies like OpenAI keep the weights to themselves and instead monetize the model through subscription wrappers like ChatGPT or charge for access by the token through an API.
Fighting the “closed” AI model is a big deal to Mark Zuckerberg, who simultaneously released a 2,300-word manifesto today on why the company believes in open releases of AI models, titled, “Open Source AI Is the Path Forward.” More on the terminology in a minute. But briefly, he writes about the need for customizable AI models that offer user control and encourage better data security, higher cost-efficiency, and better future-proofing, as opposed to vendor-locked solutions.
All that sounds reasonable, but undermining your competitors using a model subsidized by a social media war chest is also an efficient way to play spoiler in a market where you might not always win with the most cutting-edge tech. That benefits Meta, Zuckerberg says, because he doesn’t want to get locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to “taxes” Apple levies on developers through its App Store.
Enlarge/ A screenshot of Mark Zuckerberg’s essay, “Open Source AI Is the Path Forward,” published on July 23, 2024.
So, about that “open source” term. As we first wrote in an update to our Llama 2 launch article a year ago, “open source” has a very particular meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (such as Llama 3.1) or that ship without providing training data. We’ve been calling these releases “open weights” instead.
Unfortunately for terminology sticklers, Zuckerberg has now baked the erroneous “open source” label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the correct term in AI may be a losing battle. Still, his usage annoys people like independent AI researcher Simon Willison, who likes Zuckerberg’s essay otherwise.
“I see Zuck’s prominent misuse of ‘open source’ as a small-scale act of cultural vandalism,” Willison told Ars Technica. “Open source should have an agreed meaning. Abusing the term weakens that meaning which makes the term less generally useful, because if someone says ‘it’s open source,’ that no longer tells me anything useful. I have to then dig in and figure out what they’re actually talking about.”
The Llama 3.1 models are available for download through Meta’s own website and on Hugging Face. They both require providing contact information and agreeing to a license and an acceptable use policy, which means that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.
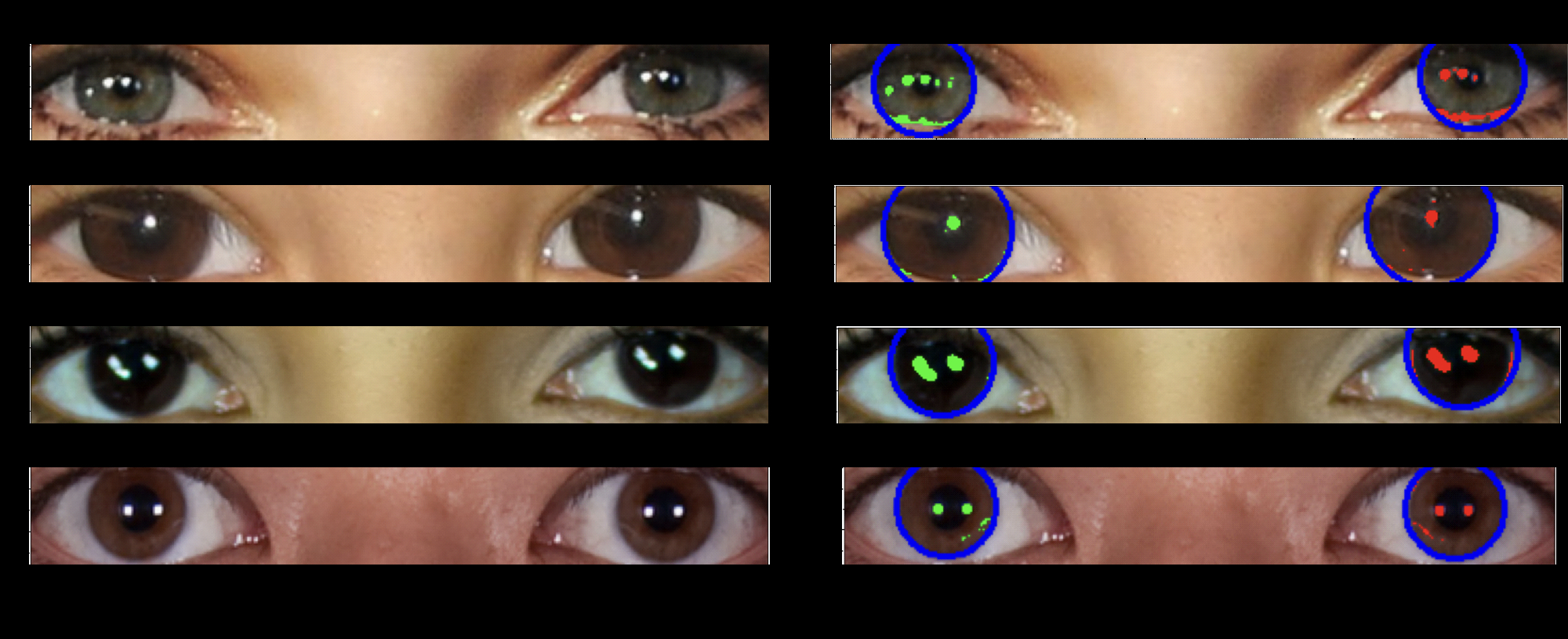
Enlarge/ Researchers write, “In this image, the person on the left (Scarlett Johansson) is real, while the person on the right is AI-generated. Their eyeballs are depicted underneath their faces. The reflections in the eyeballs are consistent for the real person, but incorrect (from a physics point of view) for the fake person.”
In 2024, it’s almost trivial to create realistic AI-generated images of people, which has led to fears about how these deceptive images might be detected. Researchers at the University of Hull recently unveiled a novel method for detecting AI-generated deepfake images by analyzing reflections in human eyes. The technique, presented at the Royal Astronomical Society’s National Astronomy Meeting last week, adapts tools used by astronomers to study galaxies for scrutinizing the consistency of light reflections in eyeballs.
Adejumoke Owolabi, an MSc student at the University of Hull, headed the research under the guidance of Dr. Kevin Pimbblet, professor of astrophysics.
Their detection technique is based on a simple principle: A pair of eyes being illuminated by the same set of light sources will typically have a similarly shaped set of light reflections in each eyeball. Many AI-generated images created to date don’t take eyeball reflections into account, so the simulated light reflections are often inconsistent between each eye.
Enlarge/ A series of real eyes showing largely consistent reflections in both eyes.
In some ways, the astronomy angle isn’t always necessary for this kind of deepfake detection because a quick glance at a pair of eyes in a photo can reveal reflection inconsistencies, which is something artists who paint portraits have to keep in mind. But the application of astronomy tools to automatically measure and quantify eye reflections in deepfakes is a novel development.
Automated detection
In a Royal Astronomical Society blog post, Pimbblet explained that Owolabi developed a technique to detect eyeball reflections automatically and ran the reflections’ morphological features through indices to compare similarity between left and right eyeballs. Their findings revealed that deepfakes often exhibit differences between the pair of eyes.
The team applied methods from astronomy to quantify and compare eyeball reflections. They used the Gini coefficient, typically employed to measure light distribution in galaxy images, to assess the uniformity of reflections across eye pixels. A Gini value closer to 0 indicates evenly distributed light, while a value approaching 1 suggests concentrated light in a single pixel.
Enlarge/ A series of deepfake eyes showing inconsistent reflections in each eye.
In the Royal Astronomical Society post, Pimbblet drew comparisons between how they measured eyeball reflection shape and how they typically measure galaxy shape in telescope imagery: “To measure the shapes of galaxies, we analyze whether they’re centrally compact, whether they’re symmetric, and how smooth they are. We analyze the light distribution.”
The researchers also explored the use of CAS parameters (concentration, asymmetry, smoothness), another tool from astronomy for measuring galactic light distribution. However, this method proved less effective in identifying fake eyes.
A detection arms race
While the eye-reflection technique offers a potential path for detecting AI-generated images, the method might not work if AI models evolve to incorporate physically accurate eye reflections, perhaps applied as a subsequent step after image generation. The technique also requires a clear, up-close view of eyeballs to work.
The approach also risks producing false positives, as even authentic photos can sometimes exhibit inconsistent eye reflections due to varied lighting conditions or post-processing techniques. But analyzing eye reflections may still be a useful tool in a larger deepfake detection toolset that also considers other factors such as hair texture, anatomy, skin details, and background consistency.
While the technique shows promise in the short term, Dr. Pimbblet cautioned that it’s not perfect. “There are false positives and false negatives; it’s not going to get everything,” he told the Royal Astronomical Society. “But this method provides us with a basis, a plan of attack, in the arms race to detect deepfakes.”
Continuing to evolve the fact-checking service that launched as Twitter’s Birdwatch, X has announced that Community Notes can now be requested to clarify problematic posts spreading on Elon Musk’s platform.
X’s Community Notes account confirmed late Thursday that, due to “popular demand,” X had launched a pilot test on the web-based version of the platform. The test is active now and the same functionality will be “coming soon” to Android and iOS, the Community Notes account said.
Through the current web-based pilot, if you’re an eligible user, you can click on the “•••” menu on any X post on the web and request fact-checking from one of Community Notes’ top contributors, X explained. If X receives five or more requests within 24 hours of the post going live, a Community Note will be added.
Only X users with verified phone numbers will be eligible to request Community Notes, X said, and to start, users will be limited to five requests a day.
“The limit may increase if requests successfully result in helpful notes, or may decrease if requests are on posts that people don’t agree need a note,” X’s website said. “This helps prevent spam and keep note writers focused on posts that could use helpful notes.”
Once X receives five or more requests for a Community Note within a single day, top contributors with diverse views will be alerted to respond. On X, top contributors are constantly changing, as their notes are voted as either helpful or not. If at least 4 percent of their notes are rated “helpful,” X explained on its site, and the impact of their notes meets X standards, they can be eligible to receive alerts.
“A contributor’s Top Writer status can always change as their notes are rated by others,” X’s website said.
Ultimately, X considers notes helpful if they “contain accurate, high-quality information” and “help inform people’s understanding of the subject matter in posts,” X said on another part of its site. To gauge the former, X said that the platform partners with “professional reviewers” from the Associated Press and Reuters. X also continually monitors whether notes marked helpful by top writers match what general X users marked as helpful.
“We don’t expect all notes to be perceived as helpful by all people all the time,” X’s website said. “Instead, the goal is to ensure that on average notes that earn the status of Helpful are likely to be seen as helpful by a wide range of people from different points of view, and not only be seen as helpful by people from one viewpoint.”
X will also be allowing half of the top contributors to request notes during the pilot phase, which X said will help the platform evaluate “whether it is beneficial for Community Notes contributors to have both the ability to write notes and request notes.”
According to X, the criteria for requesting a note have intentionally been designed to be simple during the pilot stage, but X expects “these criteria to evolve, with the goal that requests are frequently found valuable to contributors, and not noisy.”
It’s hard to tell from the outside looking in how helpful Community Notes are to X users. The most recent Community Notes survey data that X points to is from 2022 when the platform was still called Twitter and the fact-checking service was still called Birdwatch.
That data showed that “on average,” users were “20–40 percent less likely to agree with the substance of a potentially misleading Tweet than someone who sees the Tweet alone.” And based on Twitter’s “internal data” at that time, the platform also estimated that “people on Twitter who see notes are, on average, 15–35 percent less likely to Like or Retweet a Tweet than someone who sees the Tweet alone.”























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}