Samsung drops Android 16 beta for Galaxy S25 with more AI you probably don’t want
The next version of Android is expected to hit Pixel phones in June, but it’ll take longer for devices from other manufacturers to see the new OS. However, Samsung is making unusually good time this cycle. Owners of the company’s Galaxy S25 phones can get an early look at One UI 8 (based on Android 16) in the new open beta program. Samsung promises a lot of upgrades, but it may not feel that way.
Signing up for the beta is a snap—just open the Samsung Members app, and the beta signup should be right on the main landing page. From there, the OTA update should appear on your device within a few minutes. It’s pretty hefty at 3.4GB, but the installation is quick, and none of your data should be affected. That said, backups are always advisable when using beta software.
You must be in the US, Germany, Korea, or the UK to join the beta, and US phones must be unlocked or the T-Mobile variants. The software is compatible with the Galaxy S25, S25+, and S25 Ultra—the new S25 Edge need not apply (for now).
Samsung’s big pitch here might not resonate with everyone: more AI. It’s a bit vague about what exactly that means, though. The company claims One UI 8 brings “multimodal capabilities, UX tailored to different device form factors, and personalized, proactive suggestions.” Having used the new OS for a few hours, it doesn’t seem like much has changed with Samsung’s AI implementation.
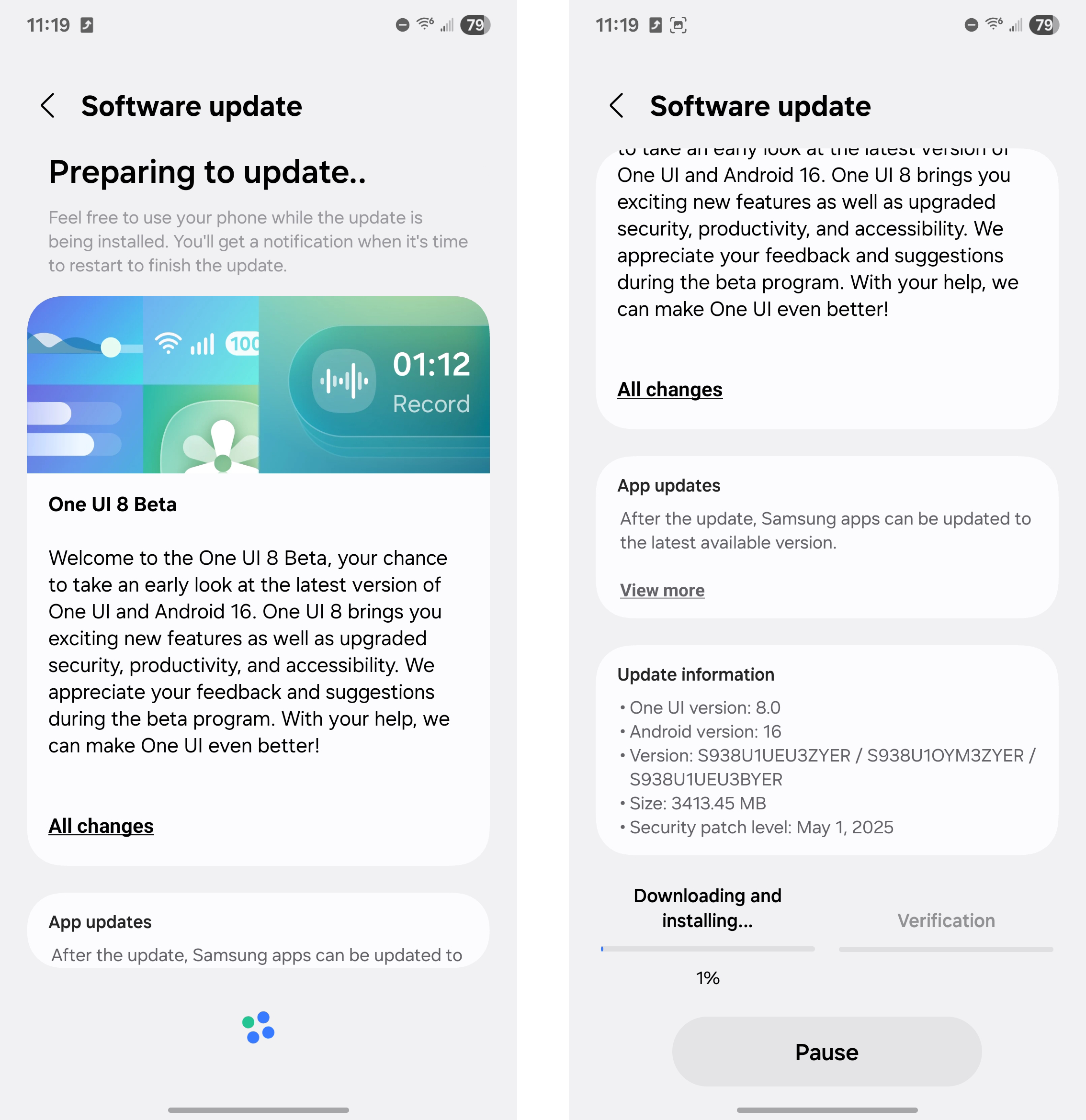
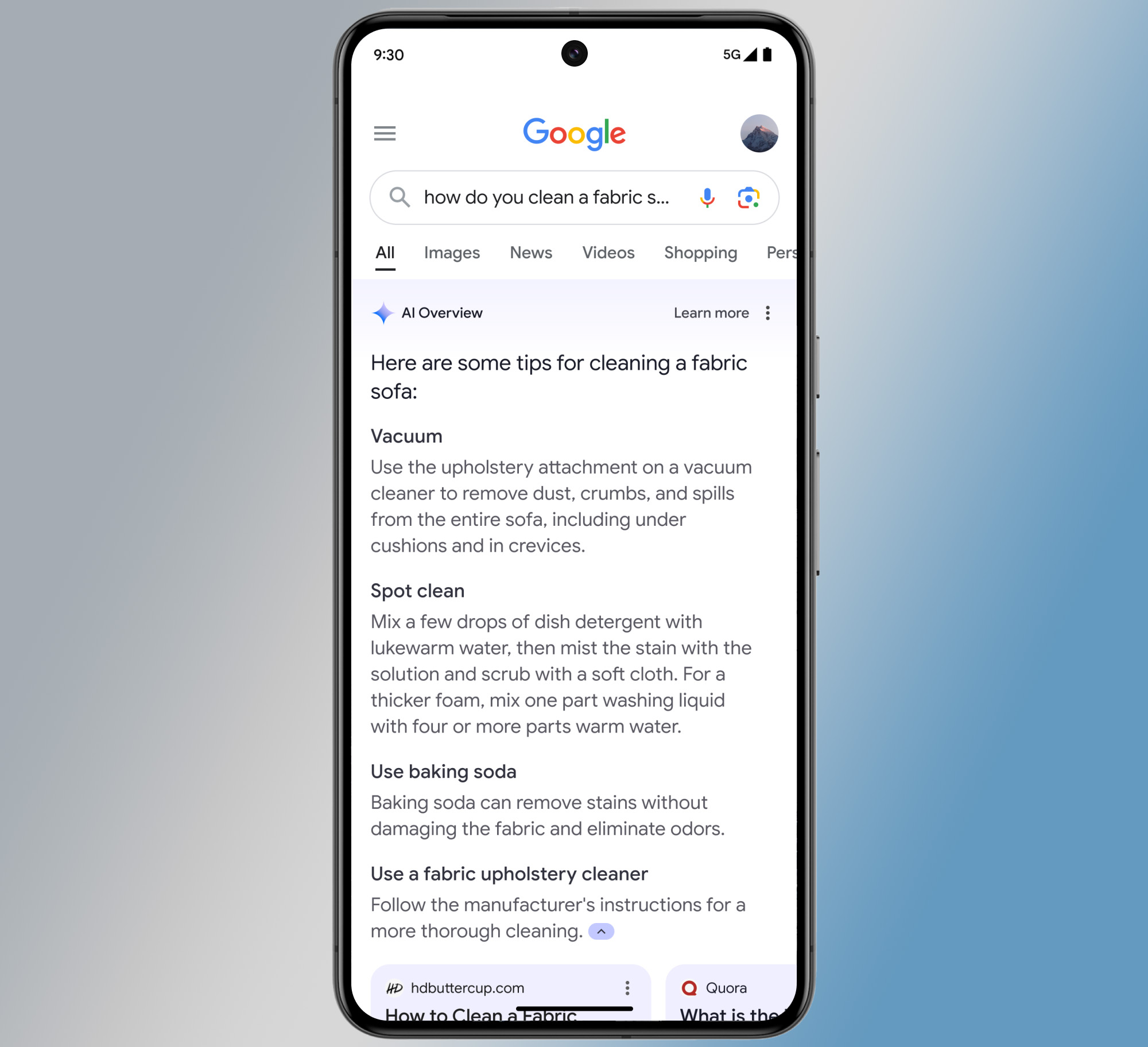
The One UI 8 beta is large, but installation doesn’t take very long.
Credit: Ryan Whitwam
The One UI 8 beta is large, but installation doesn’t take very long. Credit: Ryan Whitwam
The Galaxy S25 series launched with a feature called Now Brief, along with a companion widget called Now Bar. The idea is that this interface will assimilate your data, process it privately inside the Samsung Knox enclave, and spit out useful suggestions. For the most part, it doesn’t. While Samsung says One UI 8 will allow Now Brief to deliver more personal, customized insights, it seems to do the same handful of things it did before. It’s plugged into a lot of Samsung apps and data sources, but mostly just shows weather information, calendar events, and news articles you probably won’t care about. There were some hints of an upcoming audio version of Now Brief, but that’s not included in the beta.
Samsung drops Android 16 beta for Galaxy S25 with more AI you probably don’t want Read More »