Google’s Gemini-powered smart home revamp is here with a new app and cameras
Google promises a better smart home experience thanks to Gemini.
Google’s new Nest cameras keep the same look. Credit: Google
Google’s products and services have been flooded with AI features over the past couple of years, but smart home has been largely spared until now. The company’s plans to replace Assistant are moving forward with a big Google Home reset. We’ve been told over and over that generative AI will do incredible things when given enough data, and here’s the test.
There’s a new Home app with Gemini intelligence throughout the experience, updated subscriptions, and even some new hardware. The revamped Home app will allegedly gain deeper insights into what happens in your home, unlocking advanced video features and conversational commands. It demos well, but will it make smart home tech less or more frustrating?
A new Home
You may have already seen some elements of the revamped Home experience percolating to the surface, but that process begins in earnest today. The new app apparently boosts speed and reliability considerably, with camera feeds loading 70 percent faster and with 80 percent fewer app crashes. The app will also bring new Gemini features, some of which are free. Google’s new Home subscription retains the same price as the old Nest subs, but naturally, there’s a lot more AI.
Google claims that Gemini will make your smart home easier to monitor and manage. All that video streaming from your cameras churns through the AI, which interprets the goings on. As a result, you get features like AI-enhanced notifications that give you more context about what your cameras saw. For instance, your notifications will include descriptions of activity, and Home Brief will summarize everything that happens each day.
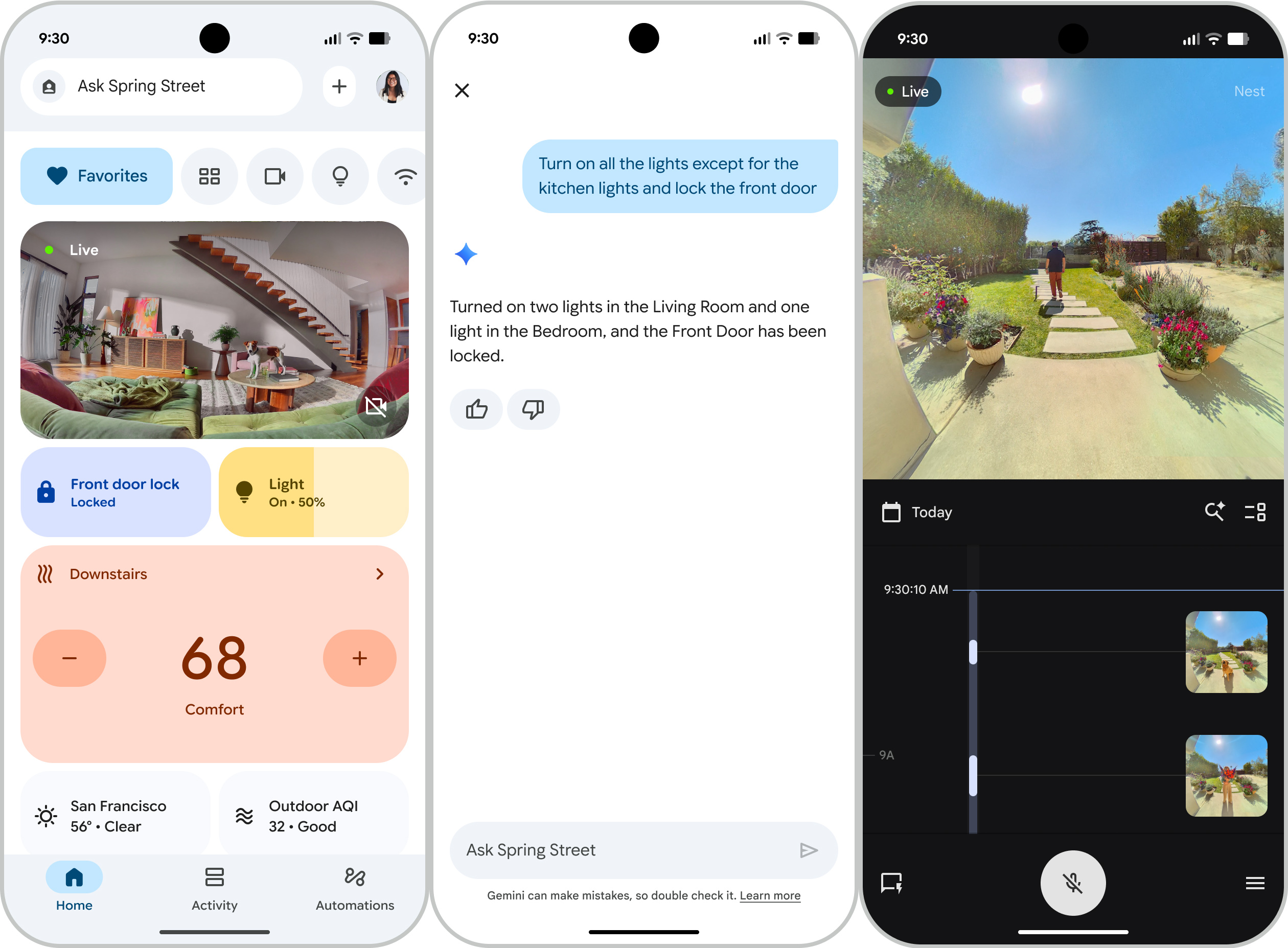
The new Home app has a simpler three-tab layout.
Credit: Google
The new Home app has a simpler three-tab layout. Credit: Google
Conversational interaction is also a big part of this update. In the home app, subscribers will see a new Ask Home bar where you can input natural language queries. For example, you could ask if a certain person has left or returned home, or whether or not your package showed up. At least, that’s what’s supposed to happen—generative AI can get things wrong.
The new app comes with new subscriptions based around AI, but the tiers don’t cost any more than the old Nest plans, and they include all the same video features. The base $10 subscription, now known as Standard, includes 30 days of video event history, along with Gemini automation features and the “intelligent alerts” Home has used for a while that can alert you to packages, familiar faces, and so on. The $20 subscription is becoming Home Advanced, which adds the conversational Ask Home feature in the app, AI notifications, AI event descriptions, and a new “Home Brief.” It also still offers 60 days of events and 10 days of 24/7 video history.
Gemini is supposed to help you keep tabs on what’s happening at home.
Credit: Google
Gemini is supposed to help you keep tabs on what’s happening at home. Credit: Google
Free users still get saved event video history, and it’s been boosted from three hours to six. If you are not subscribing to Gemini Home or using the $10 plan, the Ask Home bar that is persistent across the app will become a quick search, which surfaces devices and settings.
If you’re already subscribing to Google’s AI services, this change could actually save you some cash. Anyone with Google AI Pro (a $20 sub) will get Home Standard for free. If you’re paying for the lavish $250 per month AI Ultra plan, you get Home Advanced at no additional cost.
A proving ground for AI
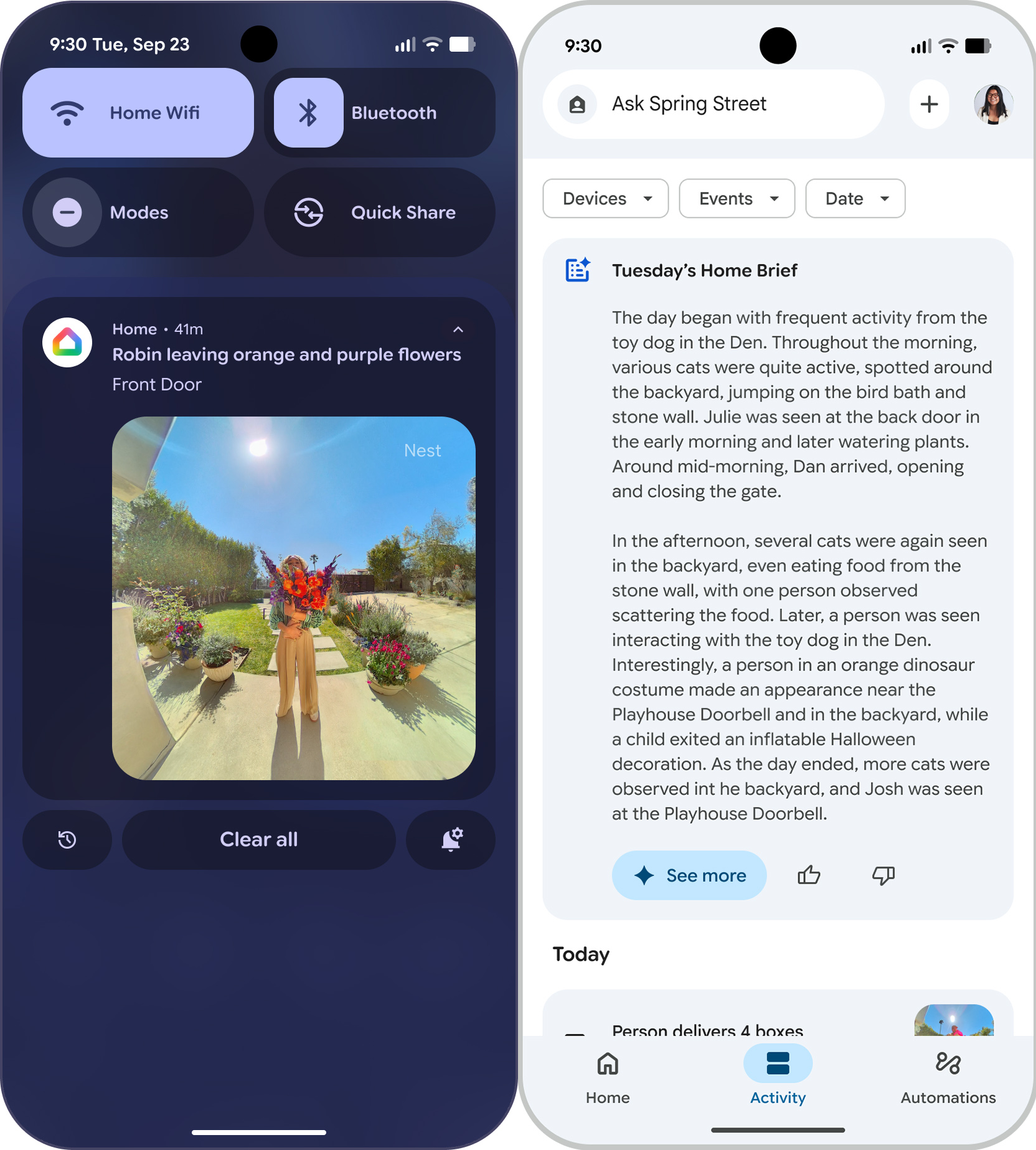
You may have gotten used to Assistant over the past decade in spite of its frequent feature gaps, but you’ll have to leave it behind. Gemini for Home will be taking over beginning this month in early access. The full release will come later, but Google intends to deliver the Gemini-powered smart home experience to as many users as possible.
Gemini will replace Assistant on every first-party Google Home device, going all the way back to the original 2016 Google Home. You’ll be able to have live chats with Gemini via your smart speakers and make more complex smart home queries. Google is making some big claims about contextual understanding here.
If Google’s embrace of generative AI pays off, we’ll see it here.
Credit: Google
If Google’s embrace of generative AI pays off, we’ll see it here. Credit: Google
If you’ve used Gemini Live, the new Home interactions will seem familiar. You can ask Gemini anything you want via your smart speakers, perhaps getting help with a recipe or an appliance issue. However, the robot will sometimes just keep talking long past the point it’s helpful. Like Gemini Live, you just have to interrupt the robot sometimes. Google also promises a selection of improved voices to interrupt.
If you want to get early access to the new Gemini Home features, you can sign up in the Home app settings. Just look for the “Early access” option. Google doesn’t guarantee access on a specific timeline, but the first people will be allowed to try the new Gemini Home this month.
New AI-first hardware
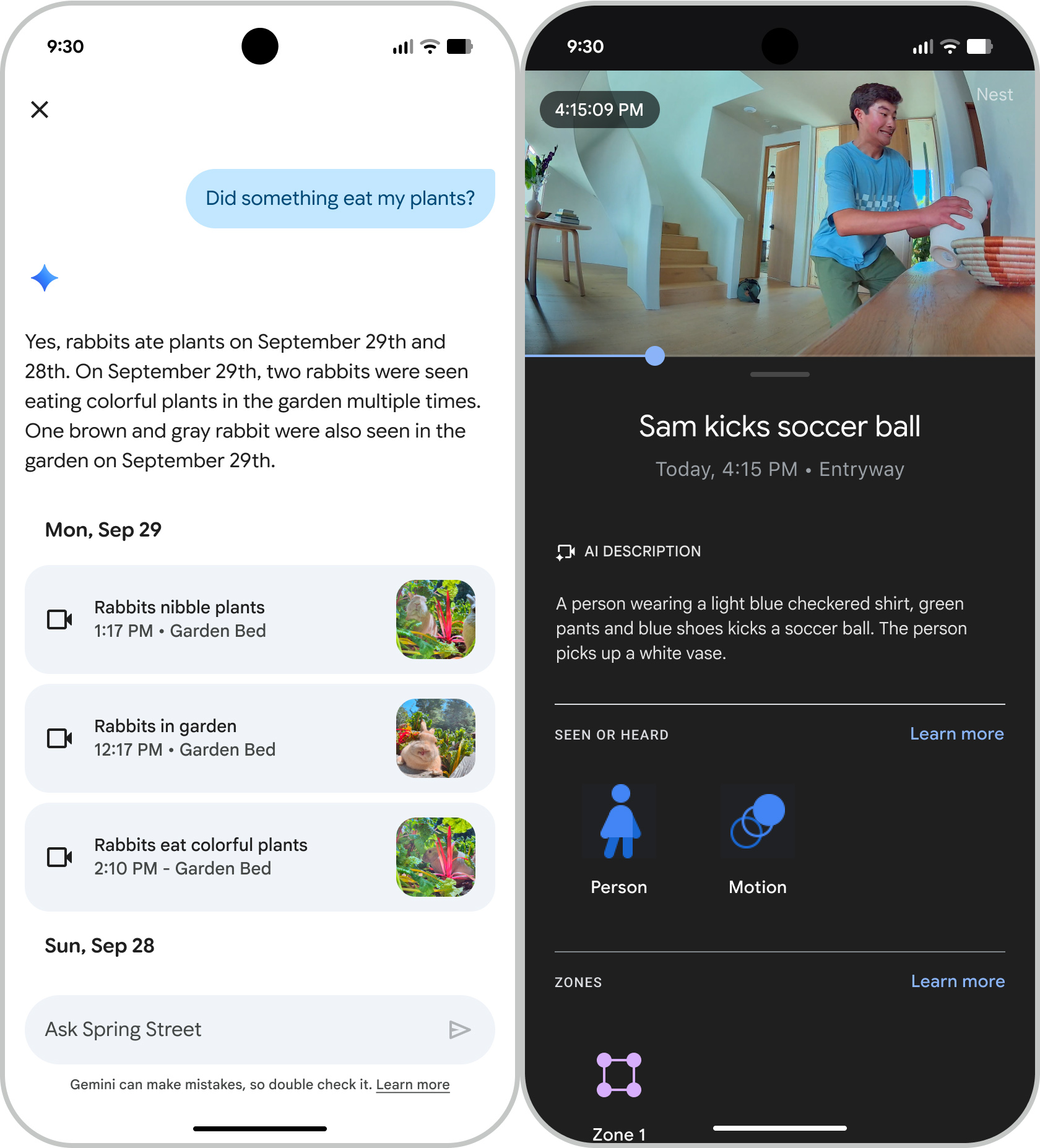
It has been four years since Google released new smart home devices, but the era of Gemini brings some new hardware. There are three new cameras, all with 2K image sensors. The new Nest Indoor camera will retail for $100, and the Nest Outdoor Camera will cost $150 (or $250 in a two-pack). There’s also a new Nest Doorbell, which requires a wired connection, for $180.
Google says these cameras were designed with generative AI in mind. The sensor choice allows for good detail even if you need to digitally zoom in, but the video feed is still small enough to be ingested by Google’s AI models as it’s created. This is what gives the new Home app the ability to provide rich updates on your smart home.

The new Nest Doorbell looks familiar.
Credit: Google
The new Nest Doorbell looks familiar. Credit: Google
You may also notice there are no battery-powered models in the new batch. Again, that’s because of AI. A battery-powered camera wakes up only momentarily when the system logs an event, but this approach isn’t as useful for generative AI. Providing the model with an ongoing video stream gives it better insights into the scene and, theoretically, produces better insights for the user.
All the new cameras are available for order today, but Google has one more device queued up for a later release. The “Google Home Speaker” is Google’s first smart speaker release since 2020’s Nest Audio. This device is smaller than the Nest Audio but larger than the Nest Mini speakers. It supports 260-degree audio with custom on-device processing that reportedly makes conversing with Gemini smoother. It can also be paired with the Google TV Streamer for home theater audio. It will be available this coming spring for $99.

The new Google Home Speaker comes out next spring.
Credit: Ryan Whitwam
The new Google Home Speaker comes out next spring. Credit: Ryan Whitwam
Google Home will continue to support a wide range of devices, but most of them won’t connect to all the advanced Gemini AI features. However, that could change. Google has also announced a new program for partners to build devices that work with Gemini alongside the Nest cameras. Devices built with the new Google Camera embedded SDK will begin appearing in the coming months, but Walmart’s Onn brand has two ready to go. The Onn Indoor camera retails for $22.96 and the Onn Video Doorbell is $49.86. Both cameras are 1080p resolution and will talk to Gemini just like Google’s cameras. So you may have more options to experience Google’s vision for the AI home of the future.

Ryan Whitwam is a senior technology reporter at Ars Technica, covering the ways Google, AI, and mobile technology continue to change the world. Over his 20-year career, he’s written for Android Police, ExtremeTech, Wirecutter, NY Times, and more. He has reviewed more phones than most people will ever own. You can follow him on Bluesky, where you will see photos of his dozens of mechanical keyboards.
Google’s Gemini-powered smart home revamp is here with a new app and cameras Read More »