The odds are against you and the situation is grim.
Your scrappy band are the only ones facing down a growing wave of powerful inhuman entities with alien minds and mysterious goals. The government is denying that anything could possibly be happening and actively working to shut down the few people trying things that might help. Your thoughts, no matter what you think could not harm you, inevitably choose the form of the destructor. You knew it was going to get bad, but this is so much worse.
You have an idea. You’ll cross the streams. Because there is a very small chance that you will survive. You’re in love with this plan. You’re excited to be a part of it.
Welcome to the always excellent Lighthaven venue for The Curve, Season 2, a conference I had the pleasure to attend this past weekend.
Where the accelerationists and the worried come together to mostly get along and coordinate on the same things, because the rest of the world has gone blind and mad. In some ways technical solutions seem relatively promising, shifting us from ‘might be actually impossible’ levels of impossible to Shut Up And Do The Impossible levels of impossible, all you have to do is beat the game on impossible difficulty level. As a speed run. On your first try. Good luck.
The action space has become severely constrained. Between the actual and perceived threats from China, the total political ascendence of Nvidia in particular and anti-regulatory big tech in general, and the setting in of more and more severe race conditions and the increasing dependence of the entire economy on AI capex investments, it’s all we can do to try to only shoot ourselves in the foot and not aim directly for the head.
Last year we were debating tradeoffs. This year, aside from the share price of Nvidia, as long as you are an American who likes humans considering things that might pass? On the margin, there are essentially no tradeoffs. It’s better versus worse.
That doesn’t invalidate the thesis of If Anyone Builds It, Everyone Dies or the implications down the line. At some point we will probably either need to do impactful international coordination or other interventions that involved large tradeoffs, or humanity loses control over the future or worse. That implication exists in every reasonable sketch of the future I have seen in which AI does not end up a ‘normal technology.’ So one must look forward towards that, as well.
You can also look at it as Year 1 of the curve was billed (although I don’t use the d word) as ‘doomers vs. accelerationists’ and now as Nathan Lambert says it was DC and SF types, like when the early season villains and heroes are now all working together as the stakes get raised and the new Big Bad shows up, then you do it again until everything is cancelled.
The Curve was a great experience. The average quality of attendees was outstanding. I would have been happy to talk to a large fraction of them 1-on-1 for a long time, and there were a number that I’m sad I missed. Lots of worthy sessions lost out to other plans.
As Anton put it, every (substantive) conversation I had made me feel smarter. There was opportunity everywhere, everyone was cooperative and seeking to figure things out, and everyone stayed on point.
To the many people who came up to me to thank me for my work, you’re very welcome. I appreciate it every time and find it motivating.
What did people at the conference think about some issues?
We have charts.
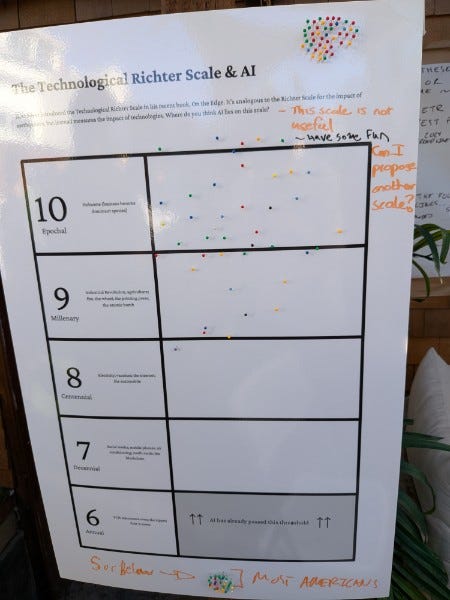
Where is AI on the technological richter scale?
There are dozens of votes here. Only one person put this as low as a high 8, which is the range of automobiles, electricity and the internet. A handful put it with fire, the wheel, agriculture and the printing press. Then most said this is similar to the rise of the human species, a full transformation. A few said it is a bigger deal than that.
If you were situationally aware enough to show up, you are aware of the situation.
These are median predictions, so the full distribution will have a longer tail, but this seems reasonable to me. The default is 10, that AI is going to be a highly non-normal technology on the level of the importance of humans, but there’s a decent chance it will ‘only’ be a 9 on the level of agriculture or fire, and some chance it disappoints and ends up Only Internet Big.
Last year, people would often claim AI wouldn’t even be Internet Big. We are rapidly approaching the point where that is not a position you can offer with a straight face.
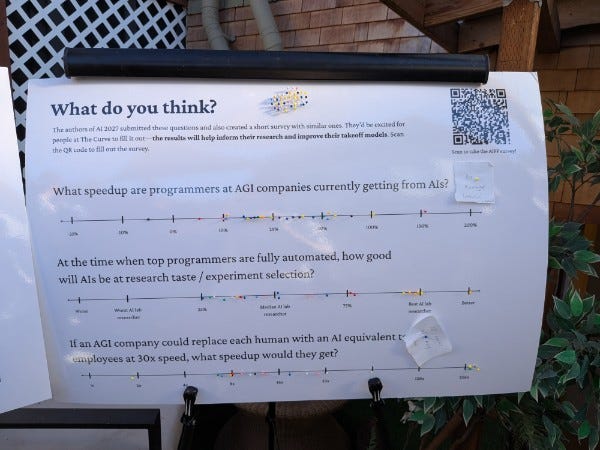
How did people expect this to play out?
That’s hard to read, so the centers of the distributions are, note that there was clearly a clustering effect:
-
90% of code is written by AI by ~2028.
-
90% of human remote work can be done more cheaply by AI by ~2031.
-
Most cars on America’s roads lack human drivers by ~2041.
-
AI makes Nobel Prize worthy discovery by ~2032.
-
First one-person $1 billion company by 2026.
-
First year of >10% GDP growth by ~2038 (but 3 votes for never).
-
People estimate 15%-50% current speedup at AI labs from AI coding.
-
When AI is fully automated, disagreement over how good their research taste will be, but median is roughly as good as the median current AI worker.
-
If we replaced each human with an AI version of themselves that was the same except 30x faster with 30 copies, but we only had access to similar levels of compute, we’d get maybe a 12x speedup in progress.
What are people worried or excited about? A lot of different things, from ‘everyone lives’ to ‘concentration of power,’ ‘everyone dies’ and especially ‘loss of control’ which have the most +1s on their respective sides. Others are excited to cure their ADD or simply worried everything will suck.
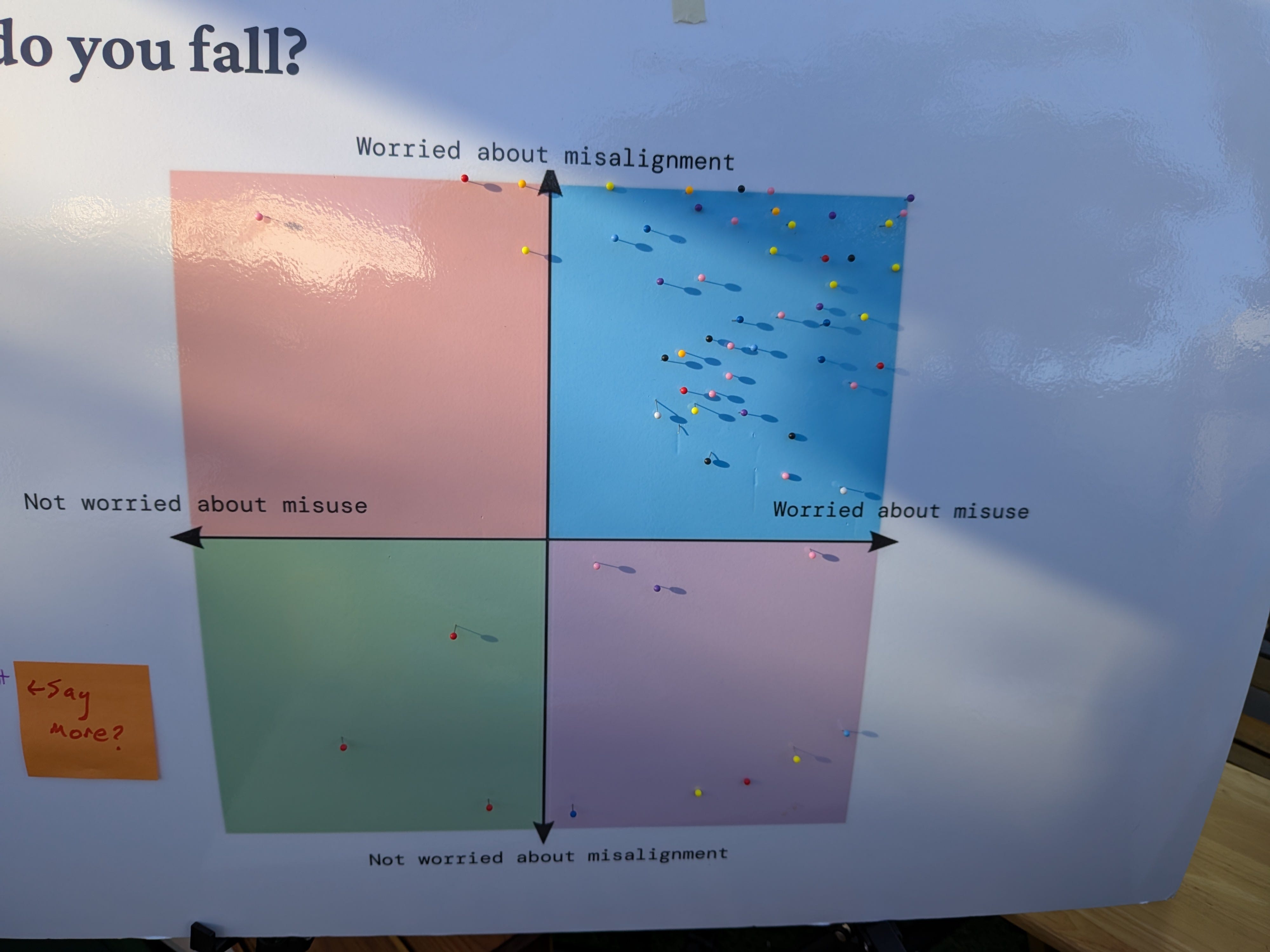
Which kind of things going wrong worries people most, misalignment or misuse?
Why not both? Pretty much everyone said both.
Finally, who is this nice man with my new favorite IYKYK t-shirt?
(I mean, he has a name tag, it’s OpenAI’s Boaz Barak)
The central problem at every conference is fear of missing out. Opportunity costs. There are many paths, even when talking to a particular person. You must choose.
That goes double at a conference like The Curve. The quality of the people there was off the charts and the schedule forced hard choices between sessions. There were entire other conferences I could have productively experienced. I also probably could have usefully done a lot more prep work.
I could of course have hosted a session, which I chose not to do this time around. I’m sure there were various topics I could have done that people would have liked, but I was happy for the break, and it’s not like there’s a shortage of my content out there.
My strategy is mostly to not actively plan my conference experiences, instead responding to opportunity. I think this is directionally correct but I overplay it, and should have (for example) looked at the list of who was going to be there.
What were the different tracks or groups of discussions and sessions I ended up in?
-
Technical alignment discussions. I had the opportunity to discuss safety and alignment work with a number of those working on such issues at Anthropic, DeepMind and even xAI. I missed OpenAI this time around, but they were there. This always felt exciting, enlightening and fun. I still get imposter syndrome every time people in such conversations take me and my takes and ideas seriously. Conditions are in many ways horribly terrible but everyone is on the same team and some things seem promising. I felt progress was made. My technical concrete pitch to Anthropic included (among other things) both particular experimental suggestions and also a request that they sustain access to Sonnet 3.5 and 3.6.
-
It wouldn’t make sense to go into the technical questions here.
-
Future projecting. I went to talks by Joshua Achiam and Helen Toner about what future capabilities and worlds might look like. Jack Clark’s closing talk was centrally this but touched on other things.
-
AI policy discussions. These felt valuable and enlightening in both directions, but were infuriating and depressing throughout. People on the ground in Washington kept giving us variations on ‘it’s worse than you know,’ which it usually is. So now you know. Others seemed not to appreciate how bad things had gotten. I was often pointing out that people’s proposals implied some sort of international treaty and form of widespread compute surveillance, had zero chance of actually causing us not to die, or sometimes both. At other times, I was pointing out that things literally wouldn’t work on the level of ‘do the object level goal’ let alone make us win. Or we were trying to figure out what was sufficiently completely costless and not even a tiny bit weird or complex that one could propose that might actually do anything meaningful. Or simply observing other perspectives.
-
In particular, different people maintained different players were relatively powerful, but I came away from various discussions more convinced than ever that for now White House policy and rhetoric on AI can be modeled as fully captured by Nvidia, although constrained in some ways by congressional Republicans and some members of the MAGA movement. This is pretty much a worst case scenario. If we were captured by OpenAI or other AI labs that wouldn’t be great but at least their interests and America are mostly aligned.
-
Nonprofit funding discussions. I’d just come out of the latest Survival and Flourishing Fund round, various players seemed happy to talk and strategize, and it seems likely that very large amounts of money will be unlocked soon as OpenAI and Anthropic employees with increasingly valuable equity become liquid. The value of helping steer this seems crazy high, but the stakes on everything seem crazy high.
-
One particular worry is that a lot of this money could effectively get captured by various existing players, especially the existing EA/OP ecosystem, in ways that would very much be a shame.
-
Another is simply that a bunch of relatively uninformed money could overwhelm incentives, contaminate various relationships and dynamics, introduce parasitic entry, drop average quality a lot, and so on.
-
Or everyone involved could end up with a huge time sink and/or end up not deploying the funds.
-
So there’s lots to do. But it’s all tricky, and trying to gain visible influence over the direction of funds is a very good way to get your own social relationships and epistemics very quickly compromised, also it can quickly eat up infinite time, so I’m hesitant to get too involved or involved in the wrong ways.
What other tracks did I actively choose not to participate in?
There were of course AI timelines discussions, but I did my best to avoid them except when they were directly relevant to a concrete strategic question. At one point someone in a 4-person conversation I was mostly observing said ‘let’s change the subject, can we argue about AI timelines’ and I outright said ‘no’ but was overruled, and after a bit I walked away. For those who don’t follow these debates, many of the more aggressive timelines have gotten longer over the course of 2025, with people who expected crazy to happen in 2027 or 2028 now not expecting crazy for several more years, but there are those who still mostly hold firm to a faster schedule.
There were a number of talks about AI that assumed it was mysteriously a ‘normal technology.’ There were various sessions on economics projections, or otherwise taking place with the assumption that AI would not cause things to change much, except for whatever particular effect people were discussing. How would we ‘strengthen our democracy’ when people had these neat AI tools, or avoid concentration of power risks? What about the risk of They Took Our Jobs? What about our privacy? How would we ensure everyone or every nation has fair access?
These discussions almost always silently assume that AI capability ‘hits a wall’ some place not very far from where it is now and then everything moves super slowly. Achiam’s talk had elements of this, and I went because he’s OpenAI’s Head of Mission Alignment so knowing how he thinks about this seemed super valuable.
To the extent I interacted with this it felt like smart people thinking about a potential world almost certainly very different from our own. Fascinating, can create useful intuition pumps, but that’s probably not what’s going to happen. If nothing else was going on, sure, count me in.
But also all the talk of ‘bottlenecks’ therefore 0.5% or 1% GDP growth boost per year tops has already been overtaken purely by capex spending and I cannot remember a single economist or other GDP growth skeptic acknowledging that this already made their projections wrong and updating reasonably.
There was an AI 2027 style tabletop exercise again this year, which I recommend doing if you haven’t done it before, except this time I wasn’t aware it was happening, and also by now I’ve done it a number of times.
There were of course debates directly about doom, but remarkably little and I had no interest. It felt like everyone was either acknowledging existential risk enough that there wasn’t much value of information in going further, or sufficiently blind they were in ‘normal technology’ mode. At some point people get too high level to think building smarter than human minds is a safe proposition.
Helen Toner gave a talk on taking AI jaggedness seriously. What would it mean if AIs kept getting increasingly better and superhuman at many tasks, while remaining terrible at other tasks, or at least relatively highly terrible compared to humans? How does the order of capabilities impact how things unfold? Even if we get superhuman coding and start to get big improvements in other areas as a result, that won’t make their ability profile similar to humans.
I agree with Helen that such jaggedness is mostly good news and potentially could buy us substantial time for various transitions. However, it’s not clear to me that this jaggedness does that much for that long, AI is (I am projecting) not going to stall out in the lagging areas or stay subhuman in key areas for as much calendar time as one might hope.
A fun suggestion was to imagine LLMs talking about how jagged human capabilities are. Look how dumb we are in some ways while being smart in others. I do think in a meaningful sense LLMs and other current AIs are ‘more jagged’ than humans in practice, because humans have continual learning and the ability to patch the situation and also route the physical world around our idiocy where they’re being importantly dumb. So we’re super dumb, but we try to not let it get in the way.
Neil Chilson: Great talk by @hlntnr about the jaggedness of AI, why it is likely to continue, and why it matters. Love this slide and her point that while many AI forecasters use smooth curves, a better metaphor is the chaotic transitions in fluid heating.
“Jaggedness” being the uneven ability of AI to do tasks that seem about equally difficult to humans.
Occurs to me I should have shared the “why this matters” slide, which was the most thought provoking one to me:
I am seriously considering talking about time to ‘crazy’ going forward, and whether that is a net helpful thing to say.
The curves definitely be too smooth. It’s hard to properly adjust for that. But I think the fluid dynamics metaphor, while gorgeous, makes the opposite mistake.
I watched a talk by Randi Weingarten about how she and other teachers are advocating and viewing AI around issues in education. One big surprise is that she says they don’t worry or care much about AI ‘cheating’ or doing work via ChatGPT, there are ways around that, especially ‘project based learning that is relevant,’ and the key thing is that education is all about human interactions. To her ChatGPT is a fine tool, although things like Character.ai are terrible, and she strongly opposes phones in schools for the right reasons and I agree with that.
She said teachers need latitude to ‘change with the times’ but usually aren’t given it, they need permission to change anything and if anything goes wrong they’re fired (although there are the other stories we hear that teachers often can’t be fired almost no matter what in many cases?). I do sympathize here. A lot needs to change.
Why is education about human interactions? This wasn’t explained. I always thought education was about learning things, I mostly didn’t learn things through human interaction, I mostly didn’t learn things in school via meaningful human interaction, and to the extent I learned things via meaningful human interaction it mostly wasn’t in school. As usual when education professionals talk about education I don’t get the sense they want children to learn things, or that they care about children being imprisoned and bored with their time wasted for huge portions of many days, but care about something else entirely? It’s not clear what her actual objection to Alpha School (which she of course confirmed she hates) was other than decentering teachers, or what concretely was supposedly going wrong there? Frankly it sounded suspiciously like a call to protect jobs.
If anything, her talk seemed to be a damning indictment of our entire system of schools and education. She presents vocational education as state of the art and with the times, and cited an example of a high school with a sub-50% graduation rate going to 100% graduation rate and 182 of 186 students getting a ‘certification’ from future farmers of America after one such program. Aside from the obvious ‘why do you need a certificate to be a farmer’ and also ‘why would you choose farmer in 2025’ this is saying kids should spend vastly less time in school? Many other such implications were there throughout.
Her group calls for ‘guardrails’ and ‘accountability’ on AI, worries about things like privacy, misinformation and understanding ‘the algorithms’ or the dangers to democracy, and points to declines in male non-college earnings,
There was a Chatham House discussion of executive branch AI policy in America where all involved were being diplomatic and careful. There’s a lot of continuity between the Biden approach to AI and much of the Trump approach, there’s a lot of individual good things going on, and it was predicted that CAISI would have a large role going forward, lots of optimism and good detail.
It seems reasonable to say that the Trump administration’s first few months of AI policy were unexpectedly good, and the AI Action Plan was unexpectedly good. Then there are the other things that happened.
Thus the session included some polite versions of ‘what the hell are we doing?’ that was at most slightly beneath the surface. As a central example, one person observed that if America ‘loses on AI,’ it would likely be because we did one or more of failing to (1) provide the necessary electrical power, (2) failed to bring in the top AI talent or (3) sold away our chip advantage. They didn’t say, but I will note here, that current American policy seems determined to screw up all three of these? We are cancelling solar, wind and battery projects all over, we are restricting our ability to acquire talent, and we are seriously debating selling Blackwell chips directly to China.
I was sad that going to that talk ruled out watching Buck Shlegeris debate Timothy Lee about whether keeping AI agents under control will be hard, as I expected that session to both be extremely funny (and one sided) and also plausibly enlightening in navigating such arguments, but that’s how conferences go. I did then get to see Buck discuss mitigating insider threats from scheming AIs, in which he explained some of the ways in which dealing with scheming AIs that are smarter than you is very hard. I’d go farther and say that in the types of scenarios Buck is discussing there it’s not going to work out for you. If the AIs be smarter than you and also scheming against you and you try to use them for important stuff anyway you lose.
That doesn’t mean do zero attempts to mitigate this but at some point the whole effort is counterproductive as it creates context that creates what it is worried about, without giving you much chance of winning.
At one point I took a break to get dinner at a nearby restaurant. The only other people there were two women. The discussion included mention of AI 2027 and also that one of them is reading If Anyone Builds It, Everyone Dies.
Also at one point I saw a movie star I’m a fan of, hanging out and chatting. Cool.
Sunday started out with Josh Achiam’s talk (again, he’s Head of Mission Alignment at OpenAI, but his views here were his own) about the challenge of the intelligence age. If it comes out, it’s worth a watch. There were a lot of very good thoughts and considerations here. I later got to have some good talk with him during the afterparty. Like much talk at OpenAI, it also silently ignored various implications of what was being built, and implicitly assumed the relevant capabilities just stopped in any place they would cause bigger issues. The talk acknowledged that it was mostly assuming alignment is solved, which is fine as long as you say that explicitly, we have many different problems to deal with, but other questions also felt assumed away more silently. Josh promises his full essay version will deal with that.
I got to go to a Chatham House Q&A about the EU Frontier AI Code of Practice, which various people keep reminding me I should write about, and I swear I want to do that as soon as I have some spare time. There was a bunch of info, some of it new to me, and also insight into how those involved think all of this is going to work. I later shared with them my model of how I think the AI companies will respond, in particular the chance they will essentially ignore the law when inconvenient because of lack of sufficient consequences. And I offered suggestions on how to improve impact here. But on the margin, yeah, the law does some good things.
I got into other talks and missed out on one I wanted to see by Joe Allen, about How the MAGA Movement Sees AI. This is a potentially important part of the landscape on AI going forward, as a bunch of MAGA types really dislike AI and are in position to influence the White House.
As I look over the schedule in hindsight I see a bunch of other stuff I’m sad I missed, but the alternative would have been missing valuable 1-on-1s or other talks.
The final talk was Jack Clark giving his perspective on events. This was a great talk, if it does online you should watch it, it gave me a very concrete sense of where he is coming from.
Jack Clark has high variance. When he’s good, he’s excellent, such as in this talk, including the Q&A, and when he asked Achaim an armor piercing question, or when he’s sticking to his guns on timelines that I think are too short even though it doesn’t seem strategic to do that. At other times, him and the policy team at Anthropic are in some sort of Official Mode where they’re doing a bunch of hedging and making things harder.
The problem I have with Anthropic’s communications is, essentially, that they are not close to the Pareto Frontier, where the y-axis is something like ‘Better Public Policy and Epistemics’ and the x-axis can colloquially be called ‘Avoid Pissing Off The White House.’ I acknowledge there is a tradeoff here, especially since we risk negative polarization, but we need to be strategic, and certain decisions have been de facto poking the bear for little gain, and at other times they hold back for little gain the other way. We gotta be smarter about this.
They are often very different from mine, or yours.
Deepfates: looks like a lot of people who work on policy and research for aligning AIs to human interests. I’m curious what you think about how humans align to AI.
my impression so far: people from big labs and people from government, politely probing each other to see which will rule the world. they can’t just out and say it but there’s zerosumness in the air
Chris Painter: That isn’t my impression of the vibe at the event! Happy to chat.
I was with Chris on this. It very much did not feel zero sum. There did seem to be a lack of appreciation of the ‘by default the AIs rule the world’ problem, even in a place dedicated largely to this particular problem.
Deepfates: Full review of The Curve: people just want to believe that Anyone is ruling the world. some of them can sense that Singleton power is within reach and they are unable to resist The opportunity. whether by honor or avarice or fear of what others will do with it.
There is that too, that currently no one is ruling the world, and it shows. It also has its advantages.
so most people are just like “uh-oh! what will occur? shouldn’t somebody be talking about this?” which is fine honestly, and a lot of them are doing good research and I enjoy learning about it. The policy stuff is more confusing
diverse crowd but multiple clusters talking past each other as if the other guys are ontologically evil and no one within earshot could possibly object. and for the most part they don’t actually? people just self-sort by sessions or at most ask pointed questions. parallel worlds.
Yep, parallel worlds, but I never saw anyone say someone else was evil. What, never? Well, hardly ever. And not anyone who actually showed up. Deeply confused and likely to get us all killed? Well, sure, there was more of that, but obviously true, and again not the people present.
things people are concerned about in no order: China. Recursive self-improvement. internal takeover of AI labs by their models. Fascism. Copyright law. The superPACs. Sycophancy. Privacy violations. Rapid unemployment of whole sectors of society. Religious and political backlash, autonomous agents, capabilities. autonomous agents, legal liability. autonomous agents, nightmare nightmare nightmare.
The fear of the other party, the other company, the other country, the other, the unknown, most of all the alien thing that threatens what it means to be human.
Fascinating to see threatens ‘what it means to be human’ on that list but not ‘the ability to keep being human (or alive),’ which I assure Deepfates a bunch of us were indeed very concerned about.
so they want to believe that the world is ruleable, that somebody, anybody, is at the wheel, as we careen into the strangest time in human history.
and they do Not want it to be the AIs. even as they keep putting decision making power and communication surface on the AIs lol
You can kind of tell here that Deepfates is fine with it being the AIs and indeed is kind of disdainful of anyone who would object to this. As in, they understand what is about to happen, but think this is good, actually (and are indeed working to bring it about). So yeah, some actual strong disagreements were present, but didn’t get discussed.
I may or may not have seen Deepfates, since I don’t know their actual name, but we presumably didn’t talk, given:
i tried telling people that i work for a rogue AI building technologies to proliferate autonomous agents (among other things). The reaction was polite confusion. It seemed a bit unreal for everyone to be talking about the world ending and doing normal conference behaviors anyway.
Polite confusion is kind of the best you can hope for when someone says that?
Regardless, very interesting event. Good crowd, good talks, plenty of food and caffeinated beverages. Not VC/pitch heavy like a lot of SF things.
Thanks to Lighthaven for hosting and Golden Gate Institute/Manifund for organizing. Will be curious to see what comes of this.
I definitely appreciated the lack of VC and pitching. I did get pitched once (on a nonprofit thing) but I was happy to take it. Focus was tight throughout.
Anton: “are you with the accelerationist faction?”
most people here have thought long and hard about ai, every conversation i have — even with those i vehemently disagree — feels like it makes me smarter..
i cant overemphasize how good the vibes are at this event.
Rob S: Another Lighthaven banger?
Anton: ANOTHA ONE.
As I note above, his closing talk was excellent. Otherwise, he seemed to be in the back of many of the same talks I was at. Listening. Gathering intel.
Jack Clark (policy head, Anthropic): I spent a few days at The Curve and I am humbled and overjoyed by the experience – it is a special event, now in its second year, and I hope they preserve whatever lightning they’ve managed to capture in this particular bottle. It was a privilege to give the closing talk.
During the Q&A I referenced The New Book, and likely due to the exhilaration of giving the earlier speech I fumbled a word and titled it: If Anyone Reads It, Everyone Dies.
James Cham: It was such an inspiring (and terrifying) talk!
I did see Roon at one point but it was late in the day and neither of us had an obvious conversation we wanted to have and he wandered off. He’s low key in person.
I was very disappointed to realize he did not say ‘den of inquiry’ here:
Roon: The Curve is insane because a bunch of DC staffers in suits have shown up to Lighthaven, a rationalist den of iniquity that looks like a Kinkade painting.
Jaime Sevilla: Jokes on you I am not a DC staffer, I just happen to like wearing my suit.
Neil Chilson: Hey, I ditched the jacket after last night.
Being Siedoh: i was impressed that your badge just says “Roon” lol.
To be fair, you absolutely wanted a jacket of some kind for the evening portion. That’s why they were giving away sweatshirts. It was still quite weird to see the few people who did wear suits.
Nathan made the opposite of my choice, and spent the weekend centered on timeline debates.
Nathan Lambert: My most striking takeaway is that the AI 2027 sequence of events, from AI models automating research engineers to later automating AI research, and potentially a singularity if your reasoning is so inclined, is becoming a standard by which many debates on AI progress operate under and tinker with.
It’s good that many people are taking the long term seriously, but there’s a risk in so many people assuming a certain sequence of events is a sure thing and only debating the timeframe by which they arrive.
This feel like the deepfates theory of self-selection within the conference. I observed the opposite, that so many people were denying that any kind of research automation or singularity was going to happen. Usually they didn’t even assert it wasn’t happening, they simply went about discussing futures where it mysteriously didn’t happen, presumably because of reasons, maybe ‘bottlenecks’ or muttering ‘normal technology’ or something.
Within the short timelines and taking AGI (at least somewhat) seriously debate subconference, to the extent I saw it, yes I do think there’s widespread convergence on the automating AI research analysis.
Whereas Nathan is in the ‘nope definitely not happening’ camp, it seems, but is helpfully explaining that it is because of bottlenecks in the automation loop.
These long timelines are strongly based on the fact that the category of research engineering is too broad. Some parts of the RE job will be fully automated next year, and more the next. To check the box of automation the entire role needs to be replaced.
What is more likely over the next few years, each engineer is doing way more work and the job description evolves substantially. I make this callout on full automation because it is required for the distribution of outcomes that look like a singularity due to the need to remove the human bottleneck for an ever accelerating pace of progress. This is a point to reinforce that I am currently confident in a singularity not happening.
The automation theory is that, as Nathan documents in his writeup, within a few years the existing research engineers (REs) will be unbelievably productive (80%-90% automated) and in some ways RE is already automated, yet that doesn’t allow us to finish the job, and humans continue importantly slowing down the loop because Real Science Is Messy and involves a social marketplace of ideas. Apologies for my glib paraphrasing. It’s possible in theory that these accelerations of progress and partial automations plus our increased scaling are no match for increasing problem difficulty, but it seems unlikely to me.
It seems far more likely that this kind of projection forgets how much things accelerate in such scenarios. Sure, it will probably be a lot messier than the toy models and straight lines on graphs, it always is, but you’d best start believing in singularities, because you’re in one, if you look at the arc of history.
The following is a very minor thing but I enjoy it so here you go.
All three meals were offered each day buffet style. Quality at these events is generally about as good as buffets get, they know who the good offerings are at this point. I ask for menus in advance so I can choose when to opt out and when to go hard, and which day to do my traditional one trip to a restaurant.
Also there was some of this:
Tyler John: It’s riddled with contradictions. The neoliberal rationalists allocate vegan and vegetarian food with a central planner rather than allowing demand to determine the supply.
Rachel: Yeah fwiw this was not a design choice. I hate this. I unfortunately didn’t notice that it was still happening yesterday :/
Tyler John: Oh on my end it’s only a very minor complaint but I did enjoy the irony.
Robert Winslow: I had a bad experience with this kind of thing at a conference. They said to save the veggies for the vegetarians. So instead of everyone taking a bit of meat and a bit of veg, everyone at the front of the line took more meat than they wanted, and everyone at the back got none.
You obviously can’t actually let demand determine supply, because you (1) can’t afford the transaction costs of charging on the margin and (2) need to order the food in advance. And there are logistical advantages to putting (at least some of) the vegan and vegetarian food in a distinct area so you don’t risk contamination or put people on lines that waste everyone’s time. If you’re worried about a mistake, you’d rather run out of meat a little early, you’d totally take down the sign (or ignore it) if it was clear the other mistake was happening, and there were still veg options for everyone else.
If you are confident via law of large numbers plus experience that you know your ratios, and you’ve chosen (and been allowed to choose) wisely, then of course you shouldn’t need anything like this.