NASA test flight seeks to help bring commercial supersonic travel back
The X-59 has successfully completed its inaugural flight.
Credit: Lockheed Martin/Michael Jackson
About an hour after sunrise over the Mojave Desert of Southern California, NASA’s newest experimental supersonic jet took to the skies for the first time on Tuesday. The X-59 Quesst (Quiet SuperSonic Technology) is designed to decrease the noise of a sonic boom when an aircraft breaks the sound barrier, paving the way for future commercial jets to fly at supersonic speeds over land.
The jet, built by Lockheed Martin’s Skunk Works, took off from US Air Force Plant 42 in Palmdale, California. Flown by Nils Larson, NASA’s lead test pilot for the X-59, the inaugural flight validated the jet’s airworthiness and safety before landing about an hour after takeoff near NASA’s Armstrong Flight Research Center in Edwards, California.
“X-59 is a symbol of American ingenuity,” acting NASA Administrator Sean Duffy said in a statement. “It’s part of our DNA—the desire to go farther, faster, and even quieter than anyone has ever gone before.”
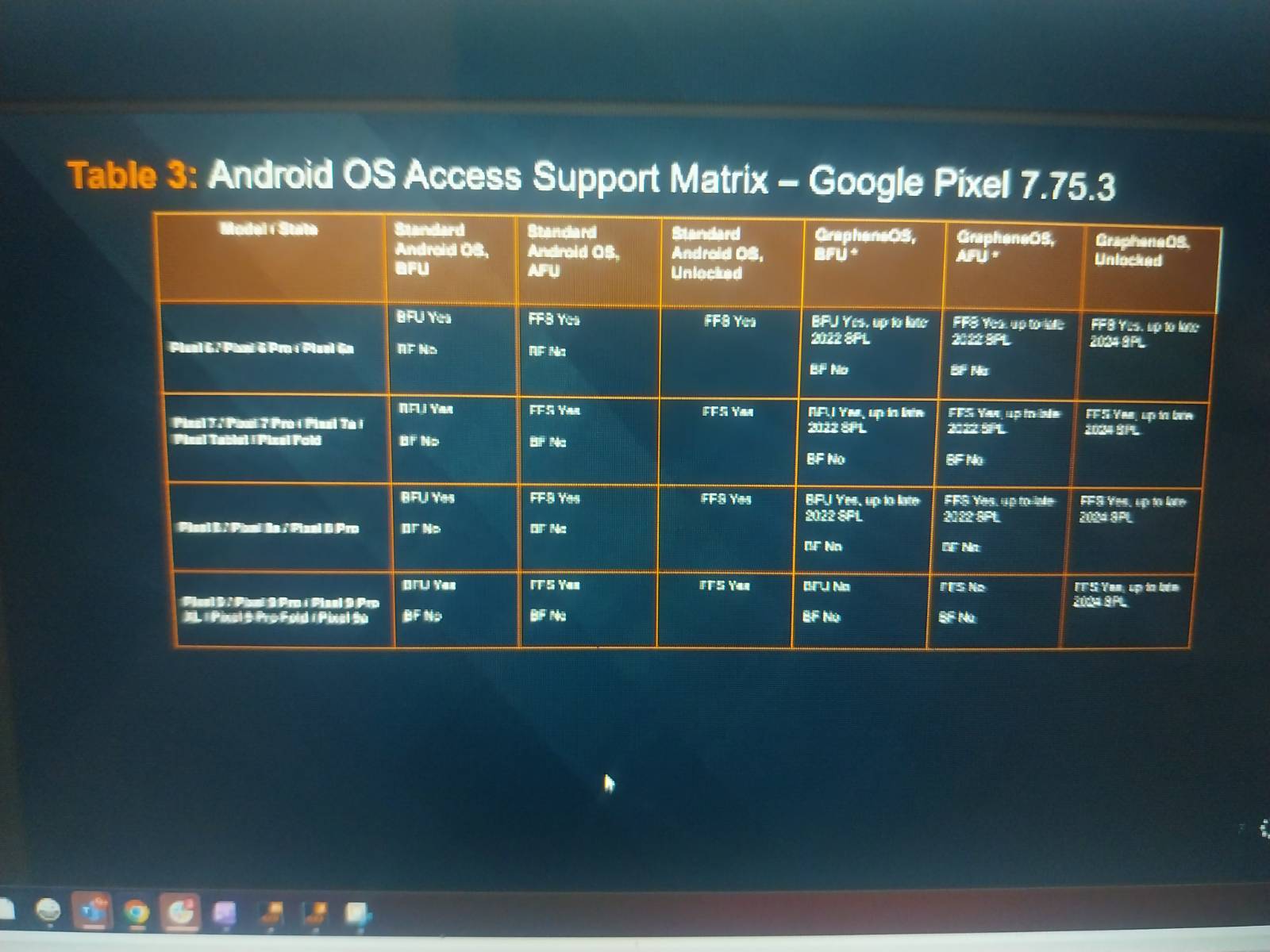
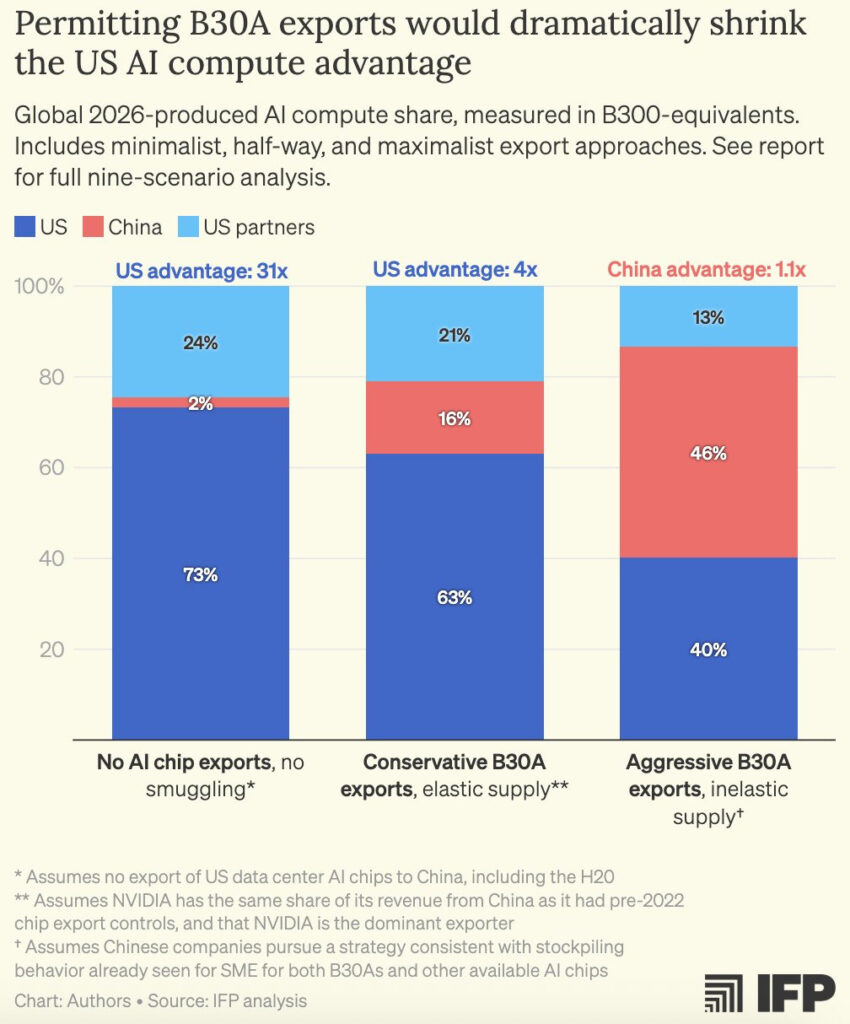
Commercial planes are prohibited from flying at supersonic speeds over land in the US due to the disruption that breaking the sound barrier causes on the ground, releasing a loud sonic boom that can rattle windows and trigger alarms. The Concorde, which was the only successful commercial supersonic jet, was limited to flying at supersonic speeds only over the oceans.
When a plane approaches the speed of sound, pressure waves build up on the surface of the aircraft. These areas of high pressure coalesce into large shock waves when the plane goes supersonic, producing the double thunderclap of a sonic boom.

The X-59 is capable of reaching supersonic speeds, without the supersonic boom.
Credit: Lockheed Martin/Gary Tice
The X-59 is capable of reaching supersonic speeds, without the supersonic boom. Credit: Lockheed Martin/Gary Tice
The X-59 will generate a lower “sonic thump” thanks to its unique design. It was given a long, slender nose that accounts for about a third of the total length and breaks up pressure waves that would otherwise merge on other parts of the airplane. The engine was mounted on top of the X-59’s fuselage, rather than underneath as on a fighter jet, to keep a smooth underside that limits shock waves and also to direct sound waves up into the sky rather than down toward the ground. NASA aims to provide key data to aircraft manufacturers so they can build less noisy supersonic planes.
A jet like no other
The X-59 is a single-seat, single-engine jet. It is 99.7 feet long and 29.5 feet wide, making it almost twice as long as an F-16 fighter jet but with a slightly smaller wingspan. The X-59’s cockpit and ejection seat come from the T-38 jet trainer, its landing gear from an F-16, and its control stick from the F-117 stealth attack aircraft. Its engine, a modified General Electric F414 from the F/A-18 fighter jet, will allow the plane to cruise at Mach 1.4, about 925 mph, at an altitude of 55,000 feet. This is nearly twice as high and twice as fast as commercial airliners typically fly.
Perhaps the most striking change on the X-59 is that it does not have a glass cockpit window. Instead, the cockpit is fully enclosed to be as aerodynamic as possible, and the pilot watches a camera feed of the outside world on a 4K monitor known as the eXternal Visibility System.
“You can’t see very clearly through glass when you look at it at a very shallow angle, and so you need to have a certain steepness of the view screen to have good optical qualities, and that would develop a strong shock wave that would really corrupt the low-boom characteristics of the airplane,” says Michael Buonanno, the air vehicle lead for the X-59 at Lockheed Martin.

The X-59 has repurposed components of other NASA aircrafts.
Credit: Lockheed Martin
The X-59 has repurposed components of other NASA aircrafts. Credit: Lockheed Martin
For this first flight, the X-59 flew at a lower altitude and at about 240 mph, according to NASA. During future tests, the jet will gradually increase its speed and altitude until it goes supersonic, NASA said, which occurs at about 659 mph at 55,000 feet, or 761 mph at sea level. The speed of sound varies according to temperature and to a lesser degree pressure, causing it to decrease at higher altitudes.
“The primary objective on a first flight is really just to land,” James Less, a project pilot for the X-59 who will be conducting future flights, tells WIRED. Less flew an F-15 fighter jet in formation with the X-59 as a support aircraft during the flight, observing the new experimental jet for any issues.
“I’m looking for anything external to the airplane that the pilot can’t see,” Less says. Generally the first thing he would check for is that the landing gear retracted successfully, but on this initial flight the X-59 intentionally left the landing gear down. “If the aircraft is leaking any kind of fluids, be it fuel or hydraulics, as a chase pilot, you can usually see that… Also I’m looking for other traffic, air traffic, just to point that out to him.”
Following the X-59’s successful touchdown at Armstrong, NASA and Lockheed Martin engineers will review the flight data to prepare for the jet’s future, faster flights.

The design of the X-59 includes a nose that makes up most of the length of the craft, designed to help reduce noise.
Credit: NASA/Steve Freeman
The design of the X-59 includes a nose that makes up most of the length of the craft, designed to help reduce noise. Credit: NASA/Steve Freeman
The future of supersonic flight
The eXternal Visibility System is just one of the modern technologies needed to build a low-boom airplane like the X-59. Decades of computational fluid dynamics research and wind tunnel testing were also required to arrive at the final design.
“We’ve really had the opportunity to spend a lot of time on the computational fluid dynamics application to these low-boom aircraft,” Lori Ozoroski, the commercial supersonic technology project manager at NASA, tells WIRED. “We’ve gone from this computational domain around an aircraft of something that’s got a couple of million cells as you divide up the space around it to… things with a couple million cells, and now we’re pushing a billion cells.”
Once the X-59 gets up to speed, the next step will be to make sure the quieter sonic thumps really are tolerable for people on the ground.
“We have been planning a test campaign where we will fly over various communities in the US, polling them with a survey and understanding how annoyed people are,” Ozoroski says. The flights will produce both loud and quiet sonic booms to see how people react, she explains.
“Our plan is to gather all this data, doing approximately one-month tests in a couple of locations around the country, and then providing all that data to the FAA and the international regulatory community to try to establish a sound limit, rather than the speed limit.”
If the program is a success, it could pave the way for new commercial supersonic aircraft that would cut travel times in half, something that companies such as Boom Supersonic are trying to achieve.
The jet has joined the ranks of innovative NASA X-planes, dating back almost 80 years to the Bell X-1 that Chuck Yeager piloted on the first faster-than-sound flight in 1947.
“I grew up reading Popular Science and Popular Mechanics and reading about the X-planes out at Edwards, and never imagined that I’d be in a position to do something like this,” says Less, who is eagerly awaiting his turn at the X-59’s stick. “This will be the highlight of my career.”
This story originally appeared on wired.com.

Wired.com is your essential daily guide to what’s next, delivering the most original and complete take you’ll find anywhere on innovation’s impact on technology, science, business and culture.
NASA test flight seeks to help bring commercial supersonic travel back Read More »