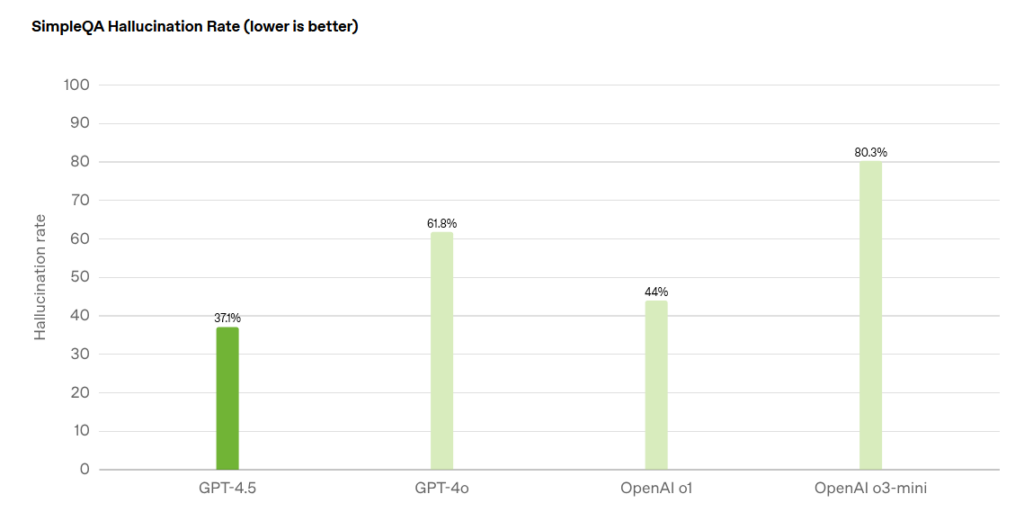
These diffusion models maintain performance faster than or comparable to similarly sized conventional models. LLaDA’s researchers report their 8 billion parameter model performs similarly to LLaMA3 8B across various benchmarks, with competitive results on tasks like MMLU, ARC, and GSM8K.
However, Mercury claims dramatic speed improvements. Their Mercury Coder Mini scores 88.0 percent on HumanEval and 77.1 percent on MBPP—comparable to GPT-4o Mini—while reportedly operating at 1,109 tokens per second compared to GPT-4o Mini’s 59 tokens per second. This represents roughly a 19x speed advantage over GPT-4o Mini while maintaining similar performance on coding benchmarks.
Mercury’s documentation states its models run “at over 1,000 tokens/sec on Nvidia H100s, a speed previously possible only using custom chips” from specialized hardware providers like Groq, Cerebras, and SambaNova. When compared to other speed-optimized models, the claimed advantage remains significant—Mercury Coder Mini is reportedly about 5.5x faster than Gemini 2.0 Flash-Lite (201 tokens/second) and 18x faster than Claude 3.5 Haiku (61 tokens/second).
Opening a potential new frontier in LLMs
Diffusion models do involve some trade-offs. They typically need multiple forward passes through the network to generate a complete response, unlike traditional models that need just one pass per token. However, because diffusion models process all tokens in parallel, they achieve higher throughput despite this overhead.
Inception thinks the speed advantages could impact code completion tools where instant response may affect developer productivity, conversational AI applications, resource-limited environments like mobile applications, and AI agents that need to respond quickly.
If diffusion-based language models maintain quality while improving speed, they might change how AI text generation develops. So far, AI researchers have been open to new approaches.
Independent AI researcher Simon Willison told Ars Technica, “I love that people are experimenting with alternative architectures to transformers, it’s yet another illustration of how much of the space of LLMs we haven’t even started to explore yet.”
On X, former OpenAI researcher Andrej Karpathy wrote about Inception, “This model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!”
Questions remain about whether larger diffusion models can match the performance of models like GPT-4o and Claude 3.7 Sonnet, and if the approach can handle increasingly complex simulated reasoning tasks. For now, these models offer an alternative for smaller AI language models that doesn’t seem to sacrifice capability for speed.
You can try Mercury Coder yourself on Inception’s demo site, and you can download code for LLaDA or try a demo on Hugging Face.