The GPT-5 rollout has been a big mess
It’s been less than a week since the launch of OpenAI’s new GPT-5 AI model, and the rollout hasn’t been a smooth one. So far, the release sparked one of the most intense user revolts in ChatGPT’s history, forcing CEO Sam Altman to make an unusual public apology and reverse key decisions.
At the heart of the controversy has been OpenAI’s decision to automatically remove access to all previous AI models in ChatGPT (approximately nine, depending on how you count them) when GPT-5 rolled out to user accounts. Unlike API users who receive advance notice of model deprecations, consumer ChatGPT users had no warning that their preferred models would disappear overnight, noted independent AI researcher Simon Willison in a blog post.
The problems started immediately after GPT-5’s August 7 debut. A Reddit thread titled “GPT-5 is horrible” quickly amassed over 4,000 comments filled with users expressing frustration over the new release. By August 8, social media platforms were flooded with complaints about performance issues, personality changes, and the forced removal of older models.
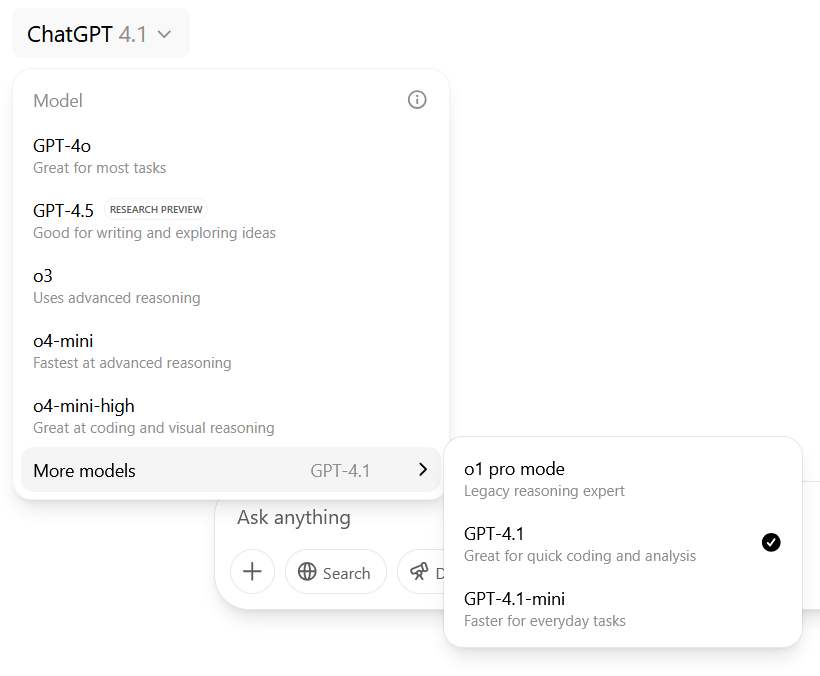
Prior to the launch of GPT-5, ChatGPT Pro users could select between nine different AI models, including Deep Research. (This screenshot is from May 14, 2025, and OpenAI later replaced o1 pro with o3-pro.) Credit: Benj Edwards
Marketing professionals, researchers, and developers all shared examples of broken workflows on social media. “I’ve spent months building a system to work around OpenAI’s ridiculous limitations in prompts and memory issues,” wrote one Reddit user in the r/OpenAI subreddit. “And in less than 24 hours, they’ve made it useless.”
How could different AI language models break a workflow? The answer lies in how each one is trained in a different way and includes its own unique output style: The workflow breaks because users have developed sets of prompts that produce useful results optimized for each AI model.
For example, Willison wrote how different user groups had developed distinct workflows with specific AI models in ChatGPT over time, quoting one Reddit user who explained: “I know GPT-5 is designed to be stronger for complex reasoning, coding, and professional tasks, but not all of us need a pro coding model. Some of us rely on 4o for creative collaboration, emotional nuance, roleplay, and other long-form, high-context interactions.”
The GPT-5 rollout has been a big mess Read More »