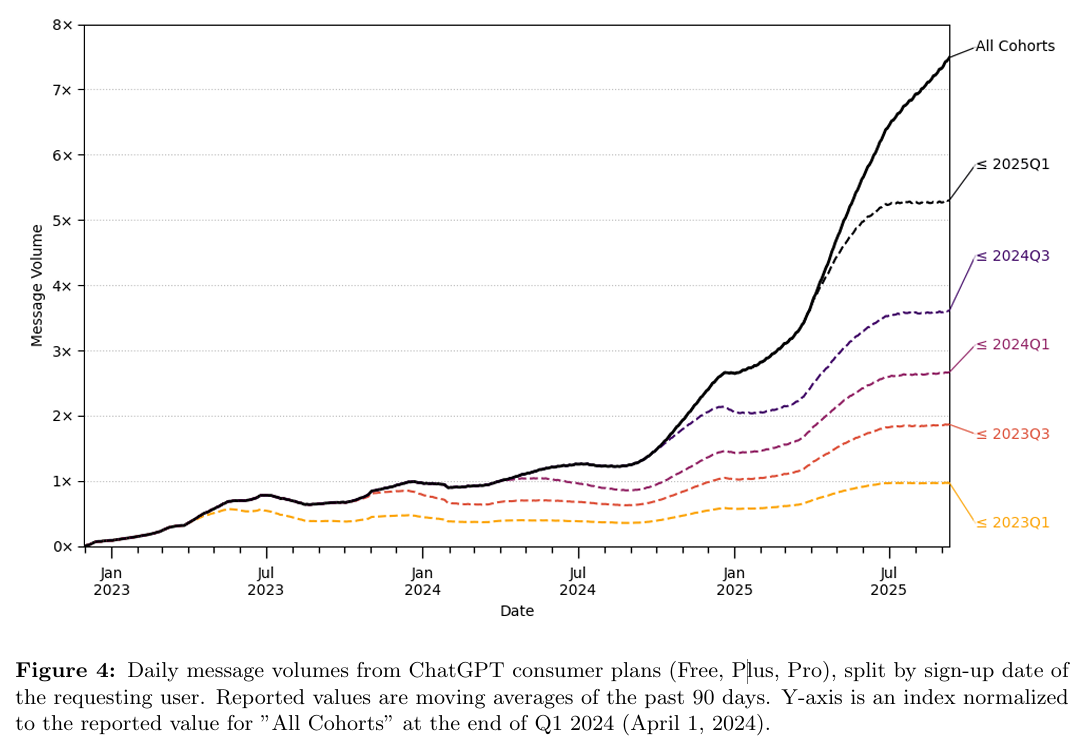
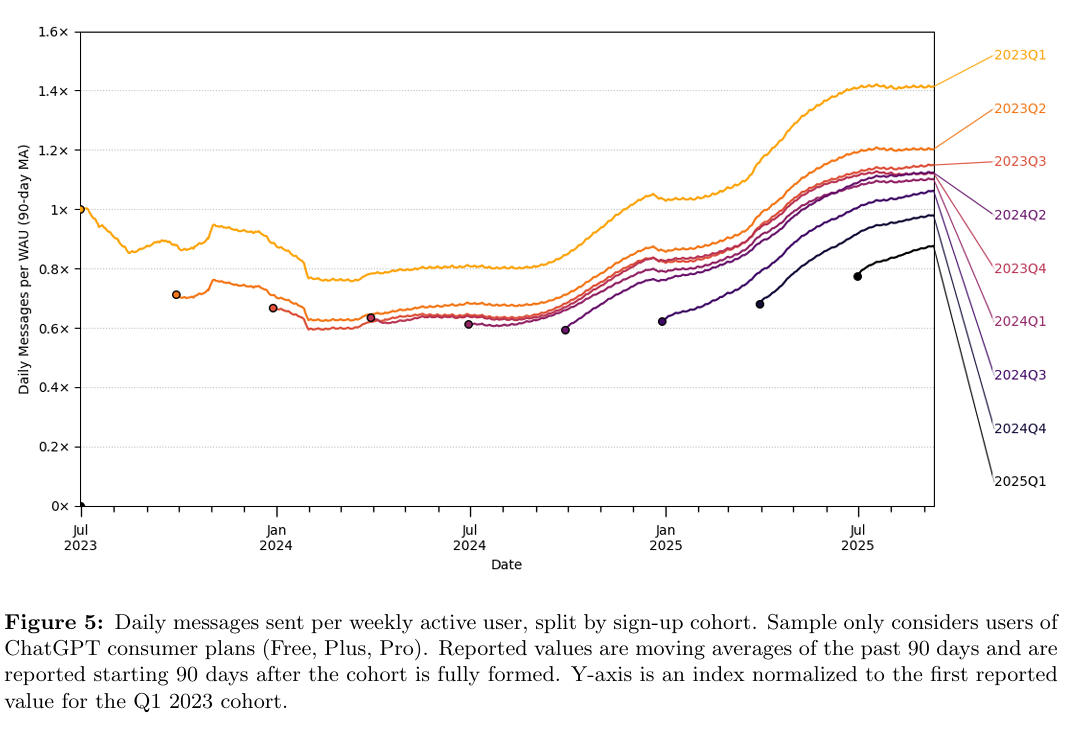
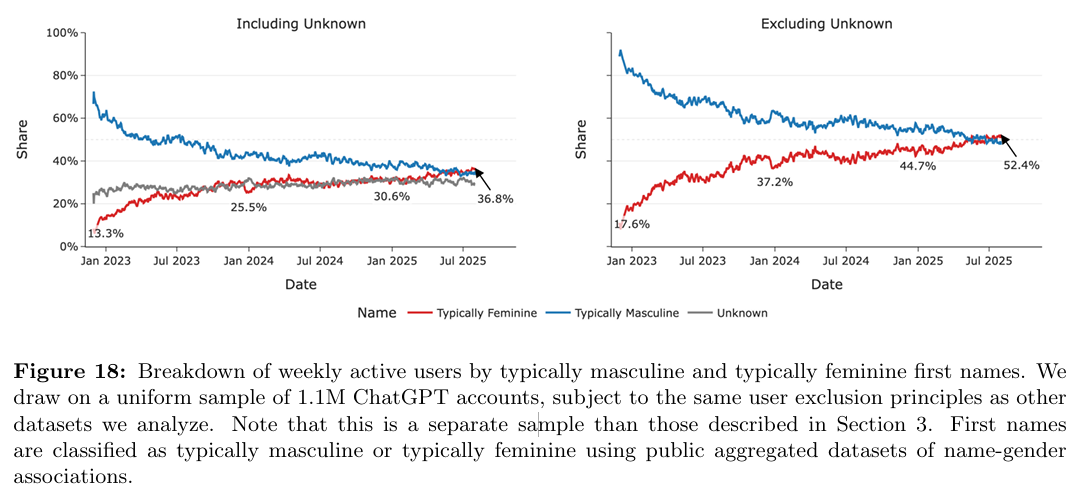
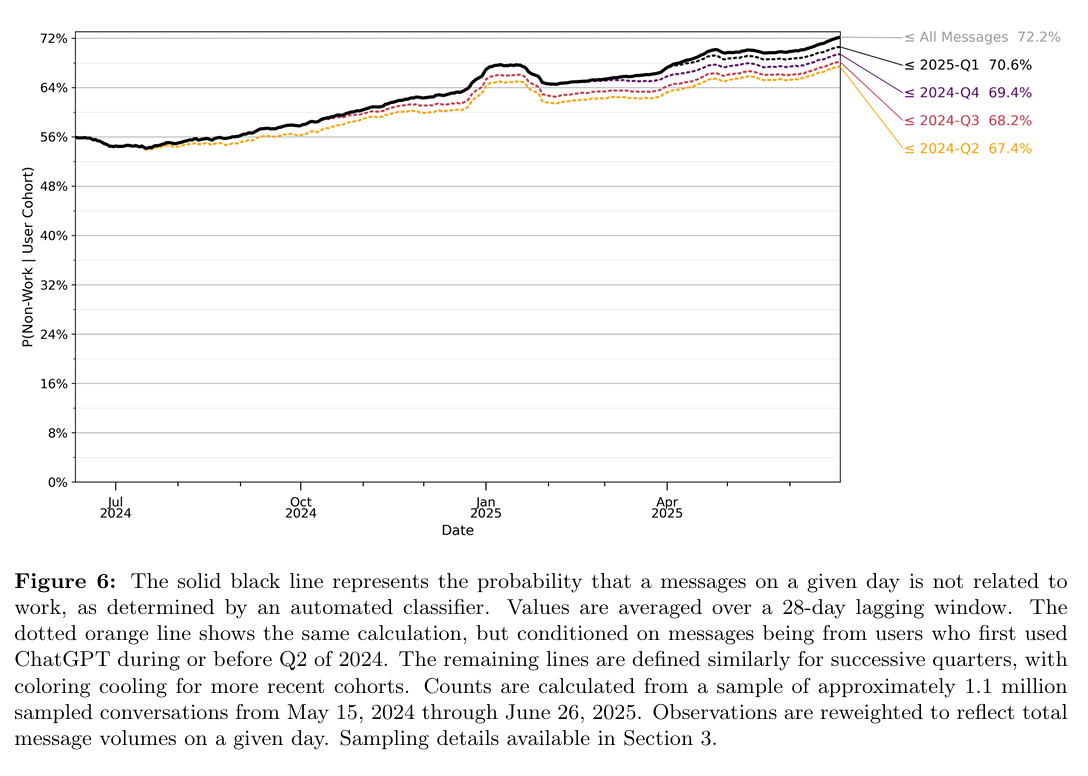
I am a little late to the party on several key developments at OpenAI:
-
OpenAI’s Chief Global Affairs Officer Chris Lehane was central to the creation of the new $100 million PAC where they will partner with a16z to oppose any and all attempts of states to regulate AI in any way for any reason.
-
Effectively as part of that effort, OpenAI sent a deeply bad faith letter to Governor Newsom opposing SB 53.
-
OpenAI seemingly has embraced descending fully into paranoia around various nonprofit organizations and also Effective Altruism in general, or at least is engaging in rhetoric and legal action to that effect, joining the style of Obvious Nonsense rhetoric about this previously mostly used by a16z.
This is deeply troubling news. It is substantially worse than I was expecting of them. Which is presumably my mistake.
This post covers those events, along with further developments around two recent tragic suicides where ChatGPT was plausibly at fault for what went down, including harsh words from multiple attorneys general who can veto OpenAI’s conversion to a for-profit company.
In OpenAI #11: America Action Plan, I documented that OpenAI:
-
Submitted an American AI Action Plan proposal that went full jingoist, framing AI as a race against the CCP in which we must prevail, with intentionally toxic vibes throughout.
-
Requested immunity from all AI regulations.
-
Attempted to ban DeepSeek using bad faith arguments.
-
Demanded absolute fair use, for free, for all AI training, or else.
-
Also included some reasonable technocratic proposals, such as a National Transmission Highway Act, AI Opportunity Zones, along with some I think are worse on the merits such as their ‘national AI readiness strategy.’
Also worth remembering:
-
This article claims both OpenAI and Microsoft were central in lobbying to take any meaningful requirements for foundation models out of the EU’s AI Act. If I was a board member, I would see this as incompatible with the OpenAI charter. This was then fleshed out further in the OpenAI Files and in this article from Corporate Europe Observatory.
-
OpenAI lobbied against SB 1047, both reasonably and unreasonably.
-
OpenAI’s CEO Sam Altman has over time used increasingly jingoistic language throughout his talks, has used steadily less talk about
OpenAI’s Chief Global Affairs Officer, Christopher Lehane, sent a letter to Governor Newsom urging him to gut SB 53 (or see Miles’s in-line responses included here), which is already very much a compromise bill that got compromised further by pushing its ‘large AI companies’ threshold and eliminating the third-party audit requirement. That already eliminated almost all of what little burden could be claimed was being imposed by the bill.
OpenAI’s previous lobbying efforts were in bad faith. This is substantially worse.
Here is the key ask from OpenAI, bold in original:
In order to make California a leader in global, national and state-level AI policy, we encourage the state to consider frontier model developers compliant with its state requirements when they sign onto a parallel regulatory framework like the CoP or enter into a safety-oriented agreement with a relevant US federal government agency.
As in, California should abdicate its responsibilities entirely, and treat giving lip service to the EU’s Code of Practice (not even actually complying with it!) as sufficient to satisfy California on all fronts. It also says that if a company makes any voluntary agreement with the Federal Government on anything safety related, then that too should satisfy all requirements.
This is very close to saying California should have no AI safety regulations at all.
The rhetoric behind this request is what you would expect. You’ve got:
-
The jingoism.
-
The talk about ‘innovation.’
-
The Obvious Nonsense threats about this slowing down progress or causing people to withdraw from California.
-
The talk about Federal leadership on regulation without any talk of what that would look like while the only Federal proposal that ever got traction was ‘ban the states from acting and still don’t do anything on the Federal level.’
-
The talk about burden on ‘small developers’ when to be covered by SB 53 at all you now have to spend a full $500 million in training compute, and the only substantive expense (the outside audits) are entirely gone.
-
The false claim that California lacks state capacity to handle this, and the false assurance us the EU and Federal Government have totally have what they need.
-
The talk of a ‘California approach’ which here means ‘do nothing.’
They even try to equate SB 53 to CEQA, which is a non-sequitur.
They equate OpenAI’s ‘commitment to work with’ the US federal government in ways that likely amount to running some bespoke tests focused on national security concerns as equivalent to being under a comprehensive regulatory regime, and as a substitute for SB 53 including its transparency requirements.
They emphasize that they are a non-profit, while trying to transform themselves into a for-profit and expropriate most of the non-profit’s wealth for private gain.
Plus we have again the important misstatement of OpenAI’s mission.
OpenAI’s actual mission: Ensure that AGI benefits all of humanity.
OpenAI says its mission is: Building AI that benefits all of humanity.
That is very importantly not the same thing. The best way to ensure AGI benefits all of humanity could importantly be to not build it.
Also as you would expect, the letter does not, anywhere, explain why the even fully complying with Code of Practice, let alone any future unspecified voluntary safety-oriented agreement, would satisfy the policy goals behind SB 53.
Because very obviously, if you read the Code of Practice and SB 53, they wouldn’t.
Miles Brundage responds to the letter in-line (which I recommend if you want to go into the details at that level) and also offers this Twitter thread:
Miles Brundage (September 1): TIL OpenAI sent a letter to Governor Newsom filled with misleading garbage about SB 53 and AI policy generally.
Unsurprising if you follow this stuff, but worth noting for those who work there and don’t know what’s being done in their name.
I don’t think it’s worth dignifying it with a line-by-line response but I’ll just say that it was clearly not written by people who know what they’re talking about (e.g., what’s in the Code of Practice + what’s in SB 53).
It also boils my blood every time that team comes up with new and creative ways to misstate OpenAI’s mission.
Today it’s “the AI Act is so strong, you should just assume that we’re following everything else” [even though the AI Act has a bunch of issues].
Tomorrow it’s “the AI Act is being enforced too stringently — it needs to be relaxed in ways A, B, and C.”
-
The context here is OpenAI trying to water down SB 53 (which is not that strict to begin with – e.g. initially third parties would verify companies’ safety claims in *2030and now there is just *nosuch requirement)
-
The letter treats the Code of Practice for the AI Act, one the one hand – imperfect but real regulation – and a voluntary agreement to do some tests sometimes with a friendly government agency, on the other – as if they’re the same. They’re not, and neither is SB 53…
-
It’s very disingenuous to act as if OpenAI is super interested in harmonious US-EU integration + federal leadership over states when they have literally never laid out a set of coherent principles for US federal AI legislation.
-
Vague implied threats to slow down shipping products or pull out of CA/the US etc. if SB 53 went through, as if it is super burdensome… that’s just nonsense. No one who knows anything about this stuff thinks any of that is even remotely plausible.
-
The “California solution” is basically “pretend different things are the same,” which is funny because it’d take two braincells for OpenAI to articulate an actually-distinctively-Californian or actually-distinctively-American approach to AI policy. But there’s no such effort.
-
For example, talk about how SB 53 is stronger on actual transparency (and how the Code of Practice has a “transparency” section that basically says “tell stuff to regulators/customers, and it’d sure be real nice if you sometimes published it”). Woulda been trivial. The fact that none of that comes up suggests the real strategy is “make number of bills go down.”
-
OpenAI’s mission is to ensure that AGI benefits all of humanity. Seems like something you’d want to get right when you have court cases about mission creep.
We also have this essay response from Nomads Vagabonds. He is if anything even less kind than Miles. He reminds us that OpenAI through Greg Brockman has teamed up with a16z to dedicate $100 million to ensuring no regulation of AI, anywhere in any state, for any reason, in a PAC that was the brainchild of OpenAI vice president of global affairs Chris Lehane.
He also goes into detail about the various bad faith provisions.
These four things can be true at once.
-
OpenAI has several competitors that strongly dislike OpenAI and Sam Altman, for a combination of reasons with varying amounts of merit.
-
Elon Musk’s lawsuits against OpenAI are often without legal merit, although the objections to OpenAI’s conversion to for-profit were ruled by the judge to absolutely have merit, with the question mainly being if Musk had standing.
-
There are many other complaints about OpenAI that have a lot or merit.
-
AI might kill everyone and you might want to work to prevent this without having it out for OpenAI in particular or being funded by OpenAI’s competitors.
OpenAI seems, by Shugerman’s reporting, to have responded to this situation by becoming paranoid that there is some sort of vast conspiracy Out To Get Them, funded and motivated by commercial rivalry, as opposed to people who care about AI not killing everyone and also this Musk guy who is Big Mad.
Of course a lot of us, as the primary example, are going to take issue with OpenAI’s attempt to convert from a non-profit to a for-profit while engaging in one of the biggest thefts in human history by expropriating most of the nonprofit’s financial assets, worth hundreds of billions, for private gain. That opposition has very little to do with Elon Musk.
Emily Dreyfuss: Inside OpenAI, there’s a growing paranoia that some of its loudest critics are being funded by Elon Musk and other billionaire competitors. Now, they are going after these nonprofit groups, but their evidence of a vast conspiracy is often extremely thin.
Emily Shugerman (SF Standard): Nathan Calvin, who joined Encode in 2024, two years after graduating from Stanford Law School, was being subpoenaed by OpenAI. “I was just thinking, ‘Wow, they’re really doing this,’” he said. “‘This is really happening.’”
The subpoena was filed as part of the ongoing lawsuits between Elon Musk and OpenAI CEO Sam Altman, in which Encode had filed an amicus brief supporting some of Musk’s arguments. It asked for any documents relating to Musk’s involvement in the founding of Encode, as well as any communications between Musk, Encode, and Meta CEO Mark Zuckerberg, whom Musk reportedly tried to involve in his OpenAI takeover bid in February.
Calvin said the answer to these questions was easy: The requested documents didn’t exist.
…
In media interviews, representatives for an OpenAI-affiliated super PAC have described a “vast force” working to slow down AI progress and steal American jobs.
This has long been the Obvious Nonsense a16z line, but now OpenAI is joining them via being part of the ‘Leading the Future’ super PAC. If this was merely Brockman contributing it would be one thing, but no, it’s far beyond that:
According to the Wall Street Journal, the PAC is in part the brainchild of Chris Lehane, OpenAI’s vice president of global affairs.
Meanwhile, OpenAI is treating everyone who opposes their transition to a for-profit as if they have to be part of this kind of vast conspiracy.
Around the time Musk mounted his legal fight [against OpenAI’s conversion to a for-profit], advocacy groups began to voice their opposition to the transition plan, too. Earlier this year, groups like the San Francisco Foundation, Latino Prosperity, and Encode organized open letters to the California attorney general, demanding further questioning about OpenAI’s move to a for-profit. One group, the Coalition for AI Nonprofit Integrity (CANI), helped write a California bill introduced in March that would have blocked the transition. (The assemblymember who introduced the bill suddenly gutted it less than a month later, saying the issue required further study.)
In the ensuing months, OpenAI leadership seems to have decided that these groups and Musk were working in concert.
Catherine Bracy: Based on my interaction with the company, it seems they’re very paranoid about Elon Musk and his role in all of this, and it’s become clear to me that that’s driving their strategy
No, these groups were not (as far as I or anyone else can tell) funded by or working in concert with Musk.
The suspicions that Meta was involved, including in Encode which is attempting to push forward SB 53, are not simply paranoid, they flat out don’t make any sense. Nor does the claim about Musk, either, given how he handles opposition:
Both LASST and Encode have spoken out against Musk and Meta — the entities OpenAI is accusing them of being aligned with — and advocated against their aims: Encode recently filed a complaint with the FTC about Musk’s AI company producing nonconsensual nude images; LASST has criticized the company for abandoning its structure as a public benefit corporation. Both say they have not taken money from Musk nor talked to him. “If anything, I’m more concerned about xAi from a safety perspective than OpenAI,” Whitmer said, referring to Musk’s AI product.
I’m more concerned about OpenAI because I think they matter far more than xAI, but pound for pound xAI is by far the bigger menace acting far less responsibly, and most safety organizations in this supposed conspiracy will tell you that if you ask them, and act accordingly when the questions come up.
Miles Brundage: First it was the EAs out to get them, now it’s Elon.
The reality is just that most people think we should be careful about AI
(Elon himself is ofc actually out to get them, but most people who sometimes disagree with OpenAI have nothing to do with Elon, including Encode, the org discussed at the beginning of the article. And ironically, many effective altruists are more worried about Elon than OAI now)
OpenAI’s paranoia started with CANI, and then extended to Encode, and then to LASST.
Nathan Calvin: They seem to have a hard time believing that we are an organization of people who just, like, actually care about this.
…
Emily Shugerman: Lehane, who joined the company last year, is perhaps best known for coining the term “vast right-wing conspiracy” to dismiss the allegations against Bill Clinton during the Monica Lewinsky scandal — a line that seems to have seeped into Leading the Future’s messaging, too.
…
In a statement to the Journal, representatives from the PAC decried a “vast force out there that’s looking to slow down AI deployment, prevent the American worker from benefiting from the U.S. leading in global innovation and job creation, and erect a patchwork of regulation.””
The hits keep coming as the a16z-level paranoid about EA being a ‘vast conspiracy’ kicks into high gear , such as the idea that Dustin Moskovitz doesn’t care about AI safety, he’s going after them because of his stake in Anthropic, can you possibly be serious right now, why do you think he invested in Anthropic.
Of particular interest to OpenAI is the fact that both Omidyar and Moskovitz are investors in Anthropic — an OpenAI competitor that claims to produce safer, more steerable AI technology.
…
Groups backed by competitors often present themselves as disinterested public voices or ‘advocates’, when in reality their funders hold direct equity stakes in competitors in their sector – in this case worth billions of dollars,” she said. “Regardless of all the rhetoric, their patrons will undoubtedly benefit if competitors are weakened.”
Never mind that Anthropic has not supported Moskovitz on AI regulation, and that the regulatory interventions funded by Moskovitz would constantly (aside from any role in trying to stop OpenAI’s for-profit conversion) be bad for Anthropic’s commercial outlook.
Open Philanthropy (funded by Dustin Moskovitz): Reasonable people can disagree about the best guardrails to set for emerging technologies, but right now we’re seeing an unusually brazen effort by some of the biggest companies in the world to buy their way out of any regulation they don’t like. They’re putting their potential profits ahead of U.S. national security and the interests of everyday people.
Companies do this sort of thing all the time. This case is still very brazen, and very obvious, and OpenAI has now jumped into a16z levels of paranoia and bad faith between the lawfare, the funding of the new PAC and their letter on SB 53.
Suing and attacking nonprofits engaging in advocacy is a new low. Compare that to the situation with Daniel Kokotajlo, where OpenAI to its credit once confronted with its bad behavior backed down rather than going on a legal offensive.
Daniel Kokotajlo: Having a big corporation come after you legally, even if they are just harassing you and not trying to actually get you imprisoned, must be pretty stressful and scary. (I was terrified last year during the nondisparagement stuff, and that was just the fear of what *mighthappen, whereas in fact OpenAI backed down instead of attacking) I’m glad these groups aren’t cowed.
As in, do OpenAI and Sam Altman believe these false paranoid conspiracy theories?
I have long wondered the same thing about Marc Andreessen and a16z, and others who say there is a ‘vast conspiracy’ out there by which they mean Effective Altruism (EA), or when they claim it’s all some plot to make money.
I mean, these people are way too smart and knowledgeable to actually believe that, asks Padme, right? And certainly Sam Altman and OpenAI have to know better.
Wouldn’t the more plausible theory be that these people are simply lying? That Lehane doesn’t believe in a ‘vast EA conspiracy’ any more than he believed in a ‘vast right-wing conspiracy’ when he coined the term ‘vast right-wing conspiracy’ about the (we now know very true) allegations around Monica Lewinsky. It’s an op. It’s rhetoric. It’s people saying what they think will work to get them what they want. It’s not hard to make that story make sense.
Then again, maybe they do really believe it, or at least aren’t sure? People often believe genuinely crazy things that do not in any way map to reality, especially once politics starts to get involved. And I can see how going up against Elon Musk and being engaged in one the biggest heists in human history in broad daylight, while trying to build superintelligence that poses existential risks to humanity that a lot of people are very worried about and that also will have more upside than anything ever, could combine to make anyone paranoid. Highly understandable and sympathetic.
Or, of course, they could have been talking to their own AIs about these questions. I hear there are some major sycophancy issues there. One must be careful.
I sincerely hope that those involved here are lying. It beats the alternatives.
It seems that OpenAI’s failures on sycophancy and dealing with suicidality might endanger its relationship with those who must approve its attempted restructuring into a for-profit, also known as one of the largest attempted thefts in human history?
Maybe they will take OpenAI’s charitable mission seriously after all, at least in this way, despite presumably not understanding the full stakes involved and having the wrong idea about what kind of safety matters?
Garrison Lovely: Scorching new letter from CA and DE AGs to OpenAI, who each have the power to block the company’s restructuring to loosen nonprofit controls.
They are NOT happy about the recent teen suicide and murder-suicide that followed prolonged and concerning interactions with ChatGPT.
Rob Bonta (California Attorney General) and Kathleen Jennings (Delaware Attorney General) in a letter: In our meeting, we conveyed in the strongest terms that safety is a non-negotiable priority, especially when it comes to children. Our teams made additional requests about OpenAI’s current safety precautions and governance. We expect that your responses to these will be prioritized and that immediate remedial measures are being taken where appropriate.
We recognize that OpenAI has sought to position itself as a leader in the AI industry on safety. Indeed, OpenAI has publicly committed itself to build safe AGI to benefit all humanity, including children. And before we get to benefiting, we need to ensure that adequate safety measures are in place to not harm.
It is our shared view that OpenAI and the industry at large are not where they need to be in ensuring safety in AI products’ development and deployment. As Attorneys General, public safety is one of our core missions. As we continue our dialogue related to OpenAI’s recapitalization plan, we must work to accelerate and amplify safety as a governing force in the future of this powerful technology.
The recent deaths are unacceptable. They have rightly shaken the American public’s confidence in OpenAI and this industry. OpenAI – and the AI industry – must proactively and transparently ensure AI’s safe deployment. Doing so is mandated by OpenAI’s charitable mission, and will be required and enforced by our respective offices.
We look forward to hearing from you and working with your team on these important issues.
Some other things said by the AGs:
Bonta: We were looking for a rapid response. They’ll know what that means, if that’s days or weeks. I don’t see how it can be months or years.
All antitrust laws apply, all consumer protection laws apply, all criminal laws apply. We are not without many tools to regulate and prevent AI from hurting the public and the children.
With a lawsuit filed that OpenAI might well lose and the the two attorney generals that can veto its restructuring breathing down OpenAI’s neck, OpenAI is promising various fixes and in particular OpenAI has decided it is time for parental controls as soon as they can, which should be within a month.
Their first announcement on August 26 included these plans:
OpenAI: While our initial mitigations prioritized acute self-harm, some people experience other forms of mental distress. For example, someone might enthusiastically tell the model they believe they can drive 24/7 because they realized they’re invincible after not sleeping for two nights. Today, ChatGPT may not recognize this as dangerous or infer play and—by curiously exploring—could subtly reinforce it.
We are working on an update to GPT‑5 that will cause ChatGPT to de-escalate by grounding the person in reality. In this example, it would explain that sleep deprivation is dangerous and recommend rest before any action.
Better late than never on that one, I suppose. That is indeed why I am relatively not so worried about problems like this, we can adjust after things start to go wrong.
OpenAI: In addition to emergency services, we’re exploring ways to make it easier for people to reach out to those closest to them. This could include one-click messages or calls to saved emergency contacts, friends, or family members with suggested language to make starting the conversation less daunting.
We’re also considering features that would allow people to opt-in for ChatGPT to reach out to a designated contact on their behalf in severe cases.
We will also soon introduce parental controls that give parents options to gain more insight into, and shape, how their teens use ChatGPT. We’re also exploring making it possible for teens (with parental oversight) to designate a trusted emergency contact. That way, in moments of acute distress, ChatGPT can do more than point to resources: it can help connect teens directly to someone who can step in.
On September 2 they followed up with additional information about how they are ‘partnering with experts’ and providing more details.
OpenAI: Earlier this year, we began building more ways for families to use ChatGPT together and decide what works best in their home. Within the next month, parents will be able to:
-
Link their account with their teen’s account (minimum age of 13) through a simple email invitation.
-
Control how ChatGPT responds to their teen with age-appropriate model behavior rules, which are on by default.
-
Manage which features to disable, including memory and chat history.
-
Receive notifications when the system detects their teen is in a moment of acute distress. Expert input will guide this feature to support trust between parents and teens.
These controls add to features we have rolled out for all users including in-app reminders during long sessions to encourage breaks.
Parental controls seem like an excellent idea.
I would consider most of this to effectively be ‘on by default’ already, for everyone, in the sense that AI models have controls against things like NSFW content that largely treat us all like teens. You could certainly tighten them up more for an actual teen, and it seems fine to give parents the option, although mostly I think you’re better off not doing that.
The big new thing is the notification feature. That is a double edged sword. As I’ve discussed previously, an AI or other source of help that can ‘rat you out’ to authorities, even ‘for your own good’ or ‘in moments of acute distress’ is inherently very different from a place where your secrets are safe. There is a reason we have confidentiality for psychologists and lawyers and priests, and balancing when to break that is complicated.
Given an AI’s current level of reliability and its special role as a place free from human judgment or social consequence, I am actually in favor of it outright never altering others without an explicit user request to do so.
Whereas things are moving in the other direction, with predictable results.
As in, OpenAI is already scanning your chats as per their posts I discussed above.
Greg Isenberg: ChatGPT is potentially leaking your private convos to the police.
People use ChatGPT because it feels like talking to a smart friend who won’t judge you. Now, people are realizing it’s more like talking to a smart friend who might snitch.
This is the same arc we saw in social media: early excitement, then paranoia, then demand for smaller, private spaces.
OpenAI (including as quoted by Futurism): When we detect users who are planning to harm others, we route their conversations to specialized pipelines where they are reviewed by a small team trained on our usage policies and who are authorized to take action, including banning accounts.
If human reviewers determine that a case involves an imminent threat of serious physical harm to others, we may refer it to law enforcement.
We are currently not referring self-harm cases to law enforcement to respect people’s privacy given the uniquely private nature of ChatGPT interactions.
Futurism: When describing its rule against “harm [to] yourself or others,” the company listed off some pretty standard examples of prohibited activity, including using ChatGPT “to promote suicide or self-harm, develop or use weapons, injure others or destroy property, or engage in unauthorized activities that violate the security of any service or system.”
They are not directing self-harm cases to protect privacy, but harm to others is deemed different. That still destroys the privacy of the interaction. And ‘harm to others’ could rapidly morph into any number of places, both with false positives and also with changes in ideas about what constitutes ‘harm.’
They’re not even talking about felonies or imminent physical harm. They’re talking about ‘engage in unauthorized activities that violate the security of any service or system,’ or ‘destroy property,’ so this could potentially extend quite far, and in places that seem far less justified than intervening in response a potentially suicidal user. These are circumstances in which typical privileged communication would hold.
I very much do not like where that is going, and if I heard reports this was happening on the regular it would fundamentally alter my relationship to ChatGPT, even though I ‘have nothing to hide.’
What’s most weird about this is that OpenAI was recently advocating for ‘AI privilege.’
Reid Southern: OpenAI went from warning users that there’s no confidentiality when using ChatGPT, and calling for “AI privilege”, to actively scanning your messages to send to law enforcement, seemingly to protect themselves in the aftermath of the ChatGPT induced murder-suicide
This is partially a case of ‘if I’m not legally forbidden to do [X] then I will get blamed for not doing [X] so please ban me from doing it’ so it’s not as hypocritical as it sounds. It is still rather hypocritical and confusing to escalate like this. Why respond to suicides by warning you will be scanning for harm to others and intent to impact the security of systems, but definitely not acting if someone is suicidal?
If you think AI users deserve privilege, and I think this is a highly reasonable position, then act like it. Set a good example, set a very high bar for ratting, and confine alerting human reviewers let alone the authorities to when you catch someone on the level of trying to make a nuke or a bioweapon, or at minimum things that would force a psychologist to break privilege. It’s even good for business.
Otherwise people are indeed going to get furious, and there will be increasing demand to run models locally or in other ways that better preserve privacy. There’s not zero of that already, but it would escalate quickly.
Steven Byrnes notes the weirdness of seeing Ben’s essay describe OpenAI as an ‘AI safety company’ rather than a company most AI safety folks hate with a passion.
Steven Byrnes: I can’t even describe how weird it is to hear OpenAI, as a whole, today in 2025, being described as an AI safety company. Actual AI safety people HATE OPENAI WITH A PASSION, almost universally. The EA people generally hate it. The Rationalists generally hate it even more.
AI safety people have protested at the OpenAI offices with picket signs & megaphones! When the board fired Sam Altman, everyone immediately blamed EA & AI safety people! OpenAI has churned through AI safety staff b/c they keep quitting in protest! …What universe is this?
Yes, many AI safety people are angry about OpenAI being cavalier & dishonest about harm they might cause in the future, whereas you are angry about OpenAI being cavalier & dishonest about harm they are causing right now. That doesn’t make us enemies. “Why not both?”
I think that’s going too far. It’s not good to hate with a passion.
Even more than that, you could do so, so much worse than OpenAI on all of these questions (e.g. Meta, or xAI, or every major Chinese lab, basically everyone except Anthropic or Google is worse).
Certainly we think OpenAI is on net not helping and deeply inadequate to the task, their political lobbying and rhetoric is harmful, and their efforts have generally made the world a lot less safe. They still are doing a lot of good work, making a lot of good decisions, and I believe that Altman is normative, that he is far more aware of what is coming and the problems we will face than most or than he currently lets on.
I believe he is doing a much better job on these fronts than most (but not all) plausible CEOs of OpenAI would do in his place. For example, if OpenAI’s CEO of Applications Fidji Simo were in charge, or Chairman of the Board Bret Taylor were in charge, or Greg Brockman was in charge, or the CEO of any of the magnificent seven were in charge, I would expect OpenAI to act far less responsibly.
Thus I consider myself relatively well-inclined towards OpenAI among those worried about AI or advocating or AI safety.
I still have an entire series of posts about how terrible things have been at OpenAI and a regular section about them called ‘The Mask Comes Off.’
And I find myself forced to update my view importantly downward, towards being more concerned, in the wake of the recent events described in this post. OpenAI is steadily becoming more of a bad faith actor in the public sphere.