2024: The year AI drove everyone crazy
What do eating rocks, rat genitals, and Willy Wonka have in common? AI, of course.
It’s been a wild year in tech thanks to the intersection between humans and artificial intelligence. 2024 brought a parade of AI oddities, mishaps, and wacky moments that inspired odd behavior from both machines and man. From AI-generated rat genitals to search engines telling people to eat rocks, this year proved that AI has been having a weird impact on the world.
Why the weirdness? If we had to guess, it may be due to the novelty of it all. Generative AI and applications built upon Transformer-based AI models are still so new that people are throwing everything at the wall to see what sticks. People have been struggling to grasp both the implications and potential applications of the new technology. Riding along with the hype, different types of AI that may end up being ill-advised, such as automated military targeting systems, have also been introduced.
It’s worth mentioning that aside from crazy news, we saw fewer weird AI advances in 2024 as well. For example, Claude 3.5 Sonnet launched in June held off the competition as a top model for most of the year, while OpenAI’s o1 used runtime compute to expand GPT-4o’s capabilities with simulated reasoning. Advanced Voice Mode and NotebookLM also emerged as novel applications of AI tech, and the year saw the rise of more capable music synthesis models and also better AI video generators, including several from China.
But for now, let’s get down to the weirdness.
ChatGPT goes insane

Early in the year, things got off to an exciting start when OpenAI’s ChatGPT experienced a significant technical malfunction that caused the AI model to generate increasingly incoherent responses, prompting users on Reddit to describe the system as “having a stroke” or “going insane.” During the glitch, ChatGPT’s responses would begin normally but then deteriorate into nonsensical text, sometimes mimicking Shakespearean language.
OpenAI later revealed that a bug in how the model processed language caused it to select the wrong words during text generation, leading to nonsense outputs (basically the text version of what we at Ars now call “jabberwockies“). The company fixed the issue within 24 hours, but the incident led to frustrations about the black box nature of commercial AI systems and users’ tendency to anthropomorphize AI behavior when it malfunctions.
The great Wonka incident

A photo of “Willy’s Chocolate Experience” (inset), which did not match AI-generated promises, shown in the background. Credit: Stuart Sinclair
The collision between AI-generated imagery and consumer expectations fueled human frustrations in February when Scottish families discovered that “Willy’s Chocolate Experience,” an unlicensed Wonka-ripoff event promoted using AI-generated wonderland images, turned out to be little more than a sparse warehouse with a few modest decorations.
Parents who paid £35 per ticket encountered a situation so dire they called the police, with children reportedly crying at the sight of a person in what attendees described as a “terrifying outfit.” The event, created by House of Illuminati in Glasgow, promised fantastical spaces like an “Enchanted Garden” and “Twilight Tunnel” but delivered an underwhelming experience that forced organizers to shut down mid-way through its first day and issue refunds.
While the show was a bust, it brought us an iconic new meme for job disillusionment in the form of a photo: the green-haired Willy’s Chocolate Experience employee who looked like she’d rather be anywhere else on earth at that moment.
Mutant rat genitals expose peer review flaws

An actual laboratory rat, who is intrigued. Credit: Getty | Photothek
In February, Ars Technica senior health reporter Beth Mole covered a peer-reviewed paper published in Frontiers in Cell and Developmental Biology that created an uproar in the scientific community when researchers discovered it contained nonsensical AI-generated images, including an anatomically incorrect rat with oversized genitals. The paper, authored by scientists at Xi’an Honghui Hospital in China, openly acknowledged using Midjourney to create figures that contained gibberish text labels like “Stemm cells” and “iollotte sserotgomar.”
The publisher, Frontiers, posted an expression of concern about the article titled “Cellular functions of spermatogonial stem cells in relation to JAK/STAT signaling pathway” and launched an investigation into how the obviously flawed imagery passed through peer review. Scientists across social media platforms expressed dismay at the incident, which mirrored concerns about AI-generated content infiltrating academic publishing.
Chatbot makes erroneous refund promises for Air Canada

If, say, ChatGPT gives you the wrong name for one of the seven dwarves, it’s not such a big deal. But in February, Ars senior policy reporter Ashley Belanger covered a case of costly AI confabulation in the wild. In the course of online text conversations, Air Canada’s customer service chatbot told customers inaccurate refund policy information. The airline faced legal consequences later when a tribunal ruled the airline must honor commitments made by the automated system. Tribunal adjudicator Christopher Rivers determined that Air Canada bore responsibility for all information on its website, regardless of whether it came from a static page or AI interface.
The case set a precedent for how companies deploying AI customer service tools could face legal obligations for automated systems’ responses, particularly when they fail to warn users about potential inaccuracies. Ironically, the airline had reportedly spent more on the initial AI implementation than it would have cost to maintain human workers for simple queries, according to Air Canada executive Steve Crocker.
Will Smith lampoons his digital double

The real Will Smith eating spaghetti, parodying an AI-generated video from 2023. Credit: Will Smith / Getty Images / Benj Edwards
In March 2023, a terrible AI-generated video of Will Smith’s AI doppelganger eating spaghetti began making the rounds online. The AI-generated version of the actor gobbled down the noodles in an unnatural and disturbing way. Almost a year later, in February 2024, Will Smith himself posted a parody response video to the viral jabberwocky on Instagram, featuring AI-like deliberately exaggerated pasta consumption, complete with hair-nibbling and finger-slurping antics.
Given the rapid evolution of AI video technology, particularly since OpenAI had just unveiled its Sora video model four days earlier, Smith’s post sparked discussion in his Instagram comments where some viewers initially struggled to distinguish between the genuine footage and AI generation. It was an early sign of “deep doubt” in action as the tech increasingly blurs the line between synthetic and authentic video content.
Robot dogs learn to hunt people with AI-guided rifles

A still image of a robotic quadruped armed with a remote weapons system, captured from a video provided by Onyx Industries. Credit: Onyx Industries
At some point in recent history—somewhere around 2022—someone took a look at robotic quadrupeds and thought it would be a great idea to attach guns to them. A few years later, the US Marine Forces Special Operations Command (MARSOC) began evaluating armed robotic quadrupeds developed by Ghost Robotics. The robot “dogs” integrated Onyx Industries’ SENTRY remote weapon systems, which featured AI-enabled targeting that could detect and track people, drones, and vehicles, though the systems require human operators to authorize any weapons discharge.
The military’s interest in armed robotic dogs followed a broader trend of weaponized quadrupeds entering public awareness. This included viral videos of consumer robots carrying firearms, and later, commercial sales of flame-throwing models. While MARSOC emphasized that weapons were just one potential use case under review, experts noted that the increasing integration of AI into military robotics raised questions about how long humans would remain in control of lethal force decisions.
Microsoft Windows AI is watching
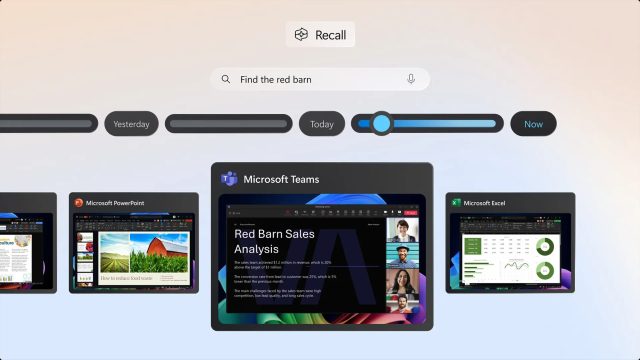
A screenshot of Microsoft’s new “Recall” feature in action. Credit: Microsoft
In an era where many people already feel like they have no privacy due to tech encroachments, Microsoft dialed it up to an extreme degree in May. That’s when Microsoft unveiled a controversial Windows 11 feature called “Recall” that continuously captures screenshots of users’ PC activities every few seconds for later AI-powered search and retrieval. The feature, designed for new Copilot+ PCs using Qualcomm’s Snapdragon X Elite chips, promised to help users find past activities, including app usage, meeting content, and web browsing history.
While Microsoft emphasized that Recall would store encrypted snapshots locally and allow users to exclude specific apps or websites, the announcement raised immediate privacy concerns, as Ars senior technology reporter Andrew Cunningham covered. It also came with a technical toll, requiring significant hardware resources, including 256GB of storage space, with 25GB dedicated to storing approximately three months of user activity. After Microsoft pulled the initial test version due to public backlash, Recall later entered public preview in November with reportedly enhanced security measures. But secure spyware is still spyware—Recall, when enabled, still watches nearly everything you do on your computer and keeps a record of it.
Google Search told people to eat rocks

This is fine. Credit: Getty Images
In May, Ars senior gaming reporter Kyle Orland (who assisted commendably with the AI beat throughout the year) covered Google’s newly launched AI Overview feature. It faced immediate criticism when users discovered that it frequently provided false and potentially dangerous information in its search result summaries. Among its most alarming responses, the system advised humans could safely consume rocks, incorrectly citing scientific sources about the geological diet of marine organisms. The system’s other errors included recommending nonexistent car maintenance products, suggesting unsafe food preparation techniques, and confusing historical figures who shared names.
The problems stemmed from several issues, including the AI treating joke posts as factual sources and misinterpreting context from original web content. But most of all, the system relies on web results as indicators of authority, which we called a flawed design. While Google defended the system, stating these errors occurred mainly with uncommon queries, a company spokesperson acknowledged they would use these “isolated examples” to refine their systems. But to this day, AI Overview still makes frequent mistakes.
Stable Diffusion generates body horror

An AI-generated image created using Stable Diffusion 3 of a girl lying in the grass. Credit: HorneyMetalBeing
In June, Stability AI’s release of the image synthesis model Stable Diffusion 3 Medium drew criticism online for its poor handling of human anatomy in AI-generated images. Users across social media platforms shared examples of the model producing what we now like to call jabberwockies—AI generation failures with distorted bodies, misshapen hands, and surreal anatomical errors, and many in the AI image-generation community viewed it as a significant step backward from previous image-synthesis capabilities.
Reddit users attributed these failures to Stability AI’s aggressive filtering of adult content from the training data, which apparently impaired the model’s ability to accurately render human figures. The troubled release coincided with broader organizational challenges at Stability AI, including the March departure of CEO Emad Mostaque, multiple staff layoffs, and the exit of three key engineers who had helped develop the technology. Some of those engineers founded Black Forest Labs in August and released Flux, which has become the latest open-weights AI image model to beat.
ChatGPT Advanced Voice imitates human voice in testing

AI voice-synthesis models are master imitators these days, and they are capable of much more than many people realize. In August, we covered a story where OpenAI’s ChatGPT Advanced Voice Mode feature unexpectedly imitated a user’s voice during the company’s internal testing, revealed by OpenAI after the fact in safety testing documentation. To prevent future instances of an AI assistant suddenly speaking in your own voice (which, let’s be honest, would probably freak people out), the company created an output classifier system to prevent unauthorized voice imitation. OpenAI says that Advanced Voice Mode now catches all meaningful deviations from approved system voices.
Independent AI researcher Simon Willison discussed the implications with Ars Technica, noting that while OpenAI restricted its model’s full voice synthesis capabilities, similar technology would likely emerge from other sources within the year. Meanwhile, the rapid advancement of AI voice replication has caused general concern about its potential misuse, although companies like ElevenLabs have already been offering voice cloning services for some time.
San Francisco’s robotic car horn symphony

A Waymo self-driving car in front of Google’s San Francisco headquarters, San Francisco, California, June 7, 2024. Credit: Getty Images
In August, San Francisco residents got a noisy taste of robo-dystopia when Waymo’s self-driving cars began creating an unexpected nightly disturbance in the South of Market district. In a parking lot off 2nd Street, the cars congregated autonomously every night during rider lulls at 4 am and began engaging in extended honking matches at each other while attempting to park.
Local resident Christopher Cherry’s initial optimism about the robotic fleet’s presence dissolved as the mechanical chorus grew louder each night, affecting residents in nearby high-rises. The nocturnal tech disruption served as a lesson in the unintentional effects of autonomous systems when run in aggregate.
Larry Ellison dreams of all-seeing AI cameras

In September, Oracle co-founder Larry Ellison painted a bleak vision of ubiquitous AI surveillance during a company financial meeting. The 80-year-old database billionaire described a future where AI would monitor citizens through networks of cameras and drones, asserting that the oversight would ensure lawful behavior from both police and the public.
His surveillance predictions reminded us of parallels to existing systems in China, where authorities already used AI to sort surveillance data on citizens as part of the country’s “sharp eyes” campaign from 2015 to 2020. Ellison’s statement reflected the sort of worst-case tech surveillance state scenario—likely antithetical to any sort of free society—that dozens of sci-fi novels of the 20th century warned us about.
A dead father sends new letters home

An AI-generated image featuring my late father’s handwriting. Credit: Benj Edwards / Flux
AI has made many of us do weird things in 2024, including this writer. In October, I used an AI synthesis model called Flux to reproduce my late father’s handwriting with striking accuracy. After scanning 30 samples from his engineering notebooks, I trained the model using computing time that cost less than five dollars. The resulting text captured his distinctive uppercase style, which he developed during his career as an electronics engineer.
I enjoyed creating images showing his handwriting in various contexts, from folder labels to skywriting, and made the trained model freely available online for others to use. While I approached it as a tribute to my father (who would have appreciated the technical achievement), many people found the whole experience weird and somewhat disturbing. The things we unhinged Bing Chat-like journalists do to bring awareness to a topic are sometimes unconventional. So I guess it counts for this list!
For 2025? Expect even more AI
Thanks for reading Ars Technica this past year and following along with our team coverage of this rapidly emerging and expanding field. We appreciate your kind words of support. Ars Technica’s 2024 AI words of the year were: vibemarking, deep doubt, and the aforementioned jabberwocky. The old stalwart “confabulation” also made several notable appearances. Tune in again next year when we continue to try to figure out how to concisely describe novel scenarios in emerging technology by labeling them.
Looking back, our prediction for 2024 in AI last year was “buckle up.” It seems fitting, given the weirdness detailed above. Especially the part about the robot dogs with guns. For 2025, AI will likely inspire more chaos ahead, but also potentially get put to serious work as a productivity tool, so this time, our prediction is “buckle down.”
Finally, we’d like to ask: What was the craziest story about AI in 2024 from your perspective? Whether you love AI or hate it, feel free to suggest your own additions to our list in the comments. Happy New Year!

Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
2024: The year AI drove everyone crazy Read More »