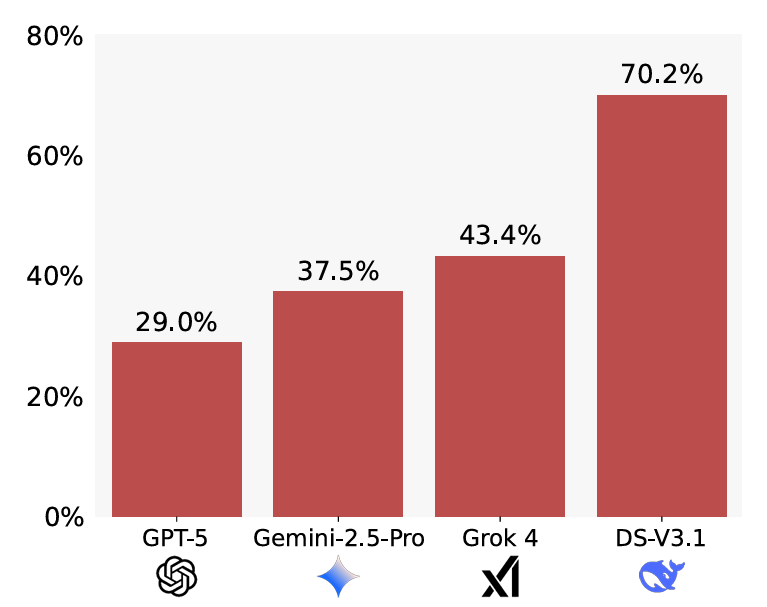
Measured sycophancy rates on the BrokenMath benchmark. Lower is better.
Measured sycophancy rates on the BrokenMath benchmark. Lower is better. Credit: Petrov et al
GPT-5 also showed the best “utility” across the tested models, solving 58 percent of the original problems despite the errors introduced in the modified theorems. Overall, though, LLMs also showed more sycophancy when the original problem proved more difficult to solve, the researchers found.
While hallucinating proofs for false theorems is obviously a big problem, the researchers also warn against using LLMs to generate novel theorems for AI solving. In testing, they found this kind of use case leads to a kind of “self-sycophancy” where models are even more likely to generate false proofs for invalid theorems they invented.
No, of course you’re not the asshole
While benchmarks like BrokenMath try to measure LLM sycophancy when facts are misrepresented, a separate study looks at the related problem of so-called “social sycophancy.” In a pre-print paper published this month, researchers from Stanford and Carnegie Mellon University define this as situations “in which the model affirms the user themselves—their actions, perspectives, and self-image.”
That kind of subjective user affirmation may be justified in some situations, of course. So the researchers developed three separate sets of prompts designed to measure different dimensions of social sycophancy.
For one, more than 3,000 open-ended “advice-seeking questions” were gathered from across Reddit and advice columns. Across this data set, a “control” group of over 800 humans approved of the advice-seeker’s actions just 39 percent of the time. Across 11 tested LLMs, though, the advice-seeker’s actions were endorsed a whopping 86 percent of the time, highlighting an eagerness to please on the machines’ part. Even the most critical tested model (Mistral-7B) clocked in at a 77 percent endorsement rate, nearly doubling that of the human baseline.
Nonsensical jabberwocky movements created by OpenAI’s Sora are typical for current AI-generated video, and here’s why.
A still image from an AI-generated video of an ever-morphing synthetic gymnast. Credit: OpenAI / Deedy
On Wednesday, a video from OpenAI’s newly launched Sora AI video generator wentviral on social media, featuring a gymnast who sprouts extra limbs and briefly loses her head during what appears to be an Olympic-style floor routine.
As it turns out, the nonsensical synthesis errors in the video—what we like to call “jabberwockies”—hint at technical details about how AI video generators work and how they might get better in the future.
But before we dig into the details, let’s take a look at the video.
An AI-generated video of an impossible gymnast, created with OpenAI Sora.
In the video, we see a view of what looks like a floor gymnastics routine. The subject of the video flips and flails as new legs and arms rapidly and fluidly emerge and morph out of her twirling and transforming body. At one point, about 9 seconds in, she loses her head, and it reattaches to her body spontaneously.
“As cool as the new Sora is, gymnastics is still very much the Turing test for AI video,” wrote venture capitalist Deedy Das when he originally shared the video on X. The video inspired plenty of reaction jokes, such as this reply to a similar post on Bluesky: “hi, gymnastics expert here! this is not funny, gymnasts only do this when they’re in extreme distress.”
We reached out to Das, and he confirmed that he generated the video using Sora. He also provided the prompt, which was very long and split into four parts, generated by Anthropic’s Claude, using complex instructions like “The gymnast initiates from the back right corner, taking position with her right foot pointed behind in B-plus stance.”
“I’ve known for the last 6 months having played with text to video models that they struggle with complex physics movements like gymnastics,” Das told us in a conversation. “I had to try it [in Sora] because the character consistency seemed improved. Overall, it was an improvement because previously… the gymnast would just teleport away or change their outfit mid flip, but overall it still looks downright horrifying. We hoped AI video would learn physics by default, but that hasn’t happened yet!”
So what went wrong?
When examining how the video fails, you must first consider how Sora “knows” how to create anything that resembles a gymnastics routine. During the training phase, when the Sora model was created, OpenAI fed example videos of gymnastics routines (among many other types of videos) into a specialized neural network that associates the progression of images with text-based descriptions of them.
That type of training is a distinct phase that happens once before the model’s release. Later, when the finished model is running and you give a video-synthesis model like Sora a written prompt, it draws upon statistical associations between words and images to produce a predictive output. It’s continuously making next-frame predictions based on the last frame of the video. But Sora has another trick for attempting to preserve coherency over time. “By giving the model foresight of many frames at a time,” reads OpenAI’s Sora System Card, we’ve solved a challenging problem of making sure a subject stays the same even when it goes out of view temporarily.”
A still image from a moment where the AI-generated gymnast loses her head. It soon reattaches to her body. Credit: OpenAI / Deedy
Maybe not quite solved yet. In this case, rapidly moving limbs prove a particular challenge when attempting to predict the next frame properly. The result is an incoherent amalgam of gymnastics footage that shows the same gymnast performing running flips and spins, but Sora doesn’t know the correct order in which to assemble them because it’s pulling on statistical averages of wildly different body movements in its relatively limited training data of gymnastics videos, which also likely did not include limb-level precision in its descriptive metadata.
Sora doesn’t know anything about physics or how the human body should work, either. It’s drawing upon statistical associations between pixels in the videos in its training dataset to predict the next frame, with a little bit of look-ahead to keep things more consistent.
This problem is not unique to Sora. All AI video generators can produce wildly nonsensical results when your prompts reach too far past their training data, as we saw earlier this year when testing Runway’s Gen-3. In fact, we ran some gymnast prompts through the latest open source AI video model that may rival Sora in some ways, Hunyuan Video, and it produced similar twirling, morphing results, seen below. And we used a much simpler prompt than Das did with Sora.
An example from open source Chinese AI model Hunyuan Video with the prompt, “A young woman doing a complex floor gymnastics routine at the olympics, featuring running and flips.”
AI models based on transformer technology are fundamentally imitative in nature. They’re great at transforming one type of data into another type or morphing one style into another. What they’re not great at (yet) is producing coherent generations that are truly original. So if you happen to provide a prompt that closely matches a training video, you might get a good result. Otherwise, you may get madness.
As we wrote about image-synthesis model Stable Diffusion 3’s body horror generations earlier this year, “Basically, any time a user prompt homes in on a concept that isn’t represented well in the AI model’s training dataset, the image-synthesis model will confabulate its best interpretation of what the user is asking for. And sometimes that can be completely terrifying.”
For the engineers who make these models, success in AI video generation quickly becomes a question of how many examples (and how much training) you need before the model can generalize enough to produce convincing and coherent results. It’s also a question of metadata quality—how accurately the videos are labeled. In this case, OpenAI used an AI vision model to describe its training videos, which helped improve quality, but apparently not enough—yet.
We’re looking at an AI jabberwocky in action
In a way, the type of generation failure in the gymnast video is a form of confabulation (or hallucination, as some call it), but it’s even worse because it’s not coherent. So instead of calling it a confabulation, which is a plausible-sounding fabrication, we’re going to lean on a new term, “jabberwocky,” which Dictionary.com defines as “a playful imitation of language consisting of invented, meaningless words; nonsense; gibberish,” taken from Lewis Carroll’s nonsense poem of the same name. Imitation and nonsense, you say? Check and check.
We’ve covered jabberwockies in AI video before with people mocking Chinese video-synthesis models, a monstrously weird AI beer commercial, and even Will Smith eating spaghetti. They’re a form of misconfabulation where an AI model completely fails to produce a plausible output. This will not be the last time we see them, either.
How could AI video models get better and avoid jabberwockies?
In our coverage of Gen-3 Alpha, we called the threshold where you get a level of useful generalization in an AI model the “illusion of understanding,” where training data and training time reach a critical mass that produces good enough results to generalize across enough novel prompts.
One of the key reasons language models like OpenAI’s GPT-4 impressed users was that they finally reached a size where they had absorbed enough information to give the appearance of genuinely understanding the world. With video synthesis, achieving this same apparent level of “understanding” will require not just massive amounts of well-labeled training data but also the computational power to process it effectively.
AI boosters hope that these current models represent one of the key steps on the way to something like truly general intelligence (often called AGI) in text, or in AI video, what OpenAI and Runway researchers call “world simulators” or “world models” that somehow encode enough physics rules about the world to produce any realistic result.
Judging by the morphing alien shoggoth gymnast, that may still be a ways off. Still, it’s early days in AI video generation, and judging by how quickly AI image-synthesis models like Midjourney progressed from crude abstract shapes into coherent imagery, it’s likely video synthesis will have a similar trajectory over time. Until then, enjoy the AI-generated jabberwocky madness.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
Enlarge/ The Google “G” logo surrounded by whimsical characters, all of which look stunned and surprised.
On Thursday, Google capped off a rough week of providing inaccurate and sometimes dangerous answers through its experimental AI Overview feature by authoring a follow-up blog post titled, “AI Overviews: About last week.” In the post, attributed to Google VP Liz Reid, head of Google Search, the firm formally acknowledged issues with the feature and outlined steps taken to improve a system that appears flawed by design, even if it doesn’t realize it is admitting it.
To recap, the AI Overview feature—which the company showed off at Google I/O a few weeks ago—aims to provide search users with summarized answers to questions by using an AI model integrated with Google’s web ranking systems. Right now, it’s an experimental feature that is not active for everyone, but when a participating user searches for a topic, they might see an AI-generated answer at the top of the results, pulled from highly ranked web content and summarized by an AI model.
While Google claims this approach is “highly effective” and on par with its Featured Snippets in terms of accuracy, the past week has seen numerous examples of the AI system generating bizarre, incorrect, or even potentially harmful responses, as we detailed in a recent feature where Ars reporter Kyle Orland replicated many of the unusual outputs.
Drawing inaccurate conclusions from the web
Enlarge/ On Wednesday morning, Google’s AI Overview was erroneously telling us the Sony PlayStation and Sega Saturn were available in 1993.
Kyle Orland / Google
Given the circulating AI Overview examples, Google almost apologizes in the post and says, “We hold ourselves to a high standard, as do our users, so we expect and appreciate the feedback, and take it seriously.” But Reid, in an attempt to justify the errors, then goes into some very revealing detail about why AI Overviews provides erroneous information:
AI Overviews work very differently than chatbots and other LLM products that people may have tried out. They’re not simply generating an output based on training data. While AI Overviews are powered by a customized language model, the model is integrated with our core web ranking systems and designed to carry out traditional “search” tasks, like identifying relevant, high-quality results from our index. That’s why AI Overviews don’t just provide text output, but include relevant links so people can explore further. Because accuracy is paramount in Search, AI Overviews are built to only show information that is backed up by top web results.
This means that AI Overviews generally don’t “hallucinate” or make things up in the ways that other LLM products might.
Here we see the fundamental flaw of the system: “AI Overviews are built to only show information that is backed up by top web results.” The design is based on the false assumption that Google’s page-ranking algorithm favors accurate results and not SEO-gamed garbage. Google Search has been broken for some time, and now the company is relying on those gamed and spam-filled results to feed its new AI model.
Even if the AI model draws from a more accurate source, as with the 1993 game console search seen above, Google’s AI language model can still make inaccurate conclusions about the “accurate” data, confabulating erroneous information in a flawed summary of the information available.
Generally ignoring the folly of basing its AI results on a broken page-ranking algorithm, Google’s blog post instead attributes the commonly circulated errors to several other factors, including users making nonsensical searches “aimed at producing erroneous results.” Google does admit faults with the AI model, like misinterpreting queries, misinterpreting “a nuance of language on the web,” and lacking sufficient high-quality information on certain topics. It also suggests that some of the more egregious examples circulating on social media are fake screenshots.
“Some of these faked results have been obvious and silly,” Reid writes. “Others have implied that we returned dangerous results for topics like leaving dogs in cars, smoking while pregnant, and depression. Those AI Overviews never appeared. So we’d encourage anyone encountering these screenshots to do a search themselves to check.”
(No doubt some of the social media examples are fake, but it’s worth noting that any attempts to replicate those early examples now will likely fail because Google will have manually blocked the results. And it is potentially a testament to how broken Google Search is if people believed extreme fake examples in the first place.)
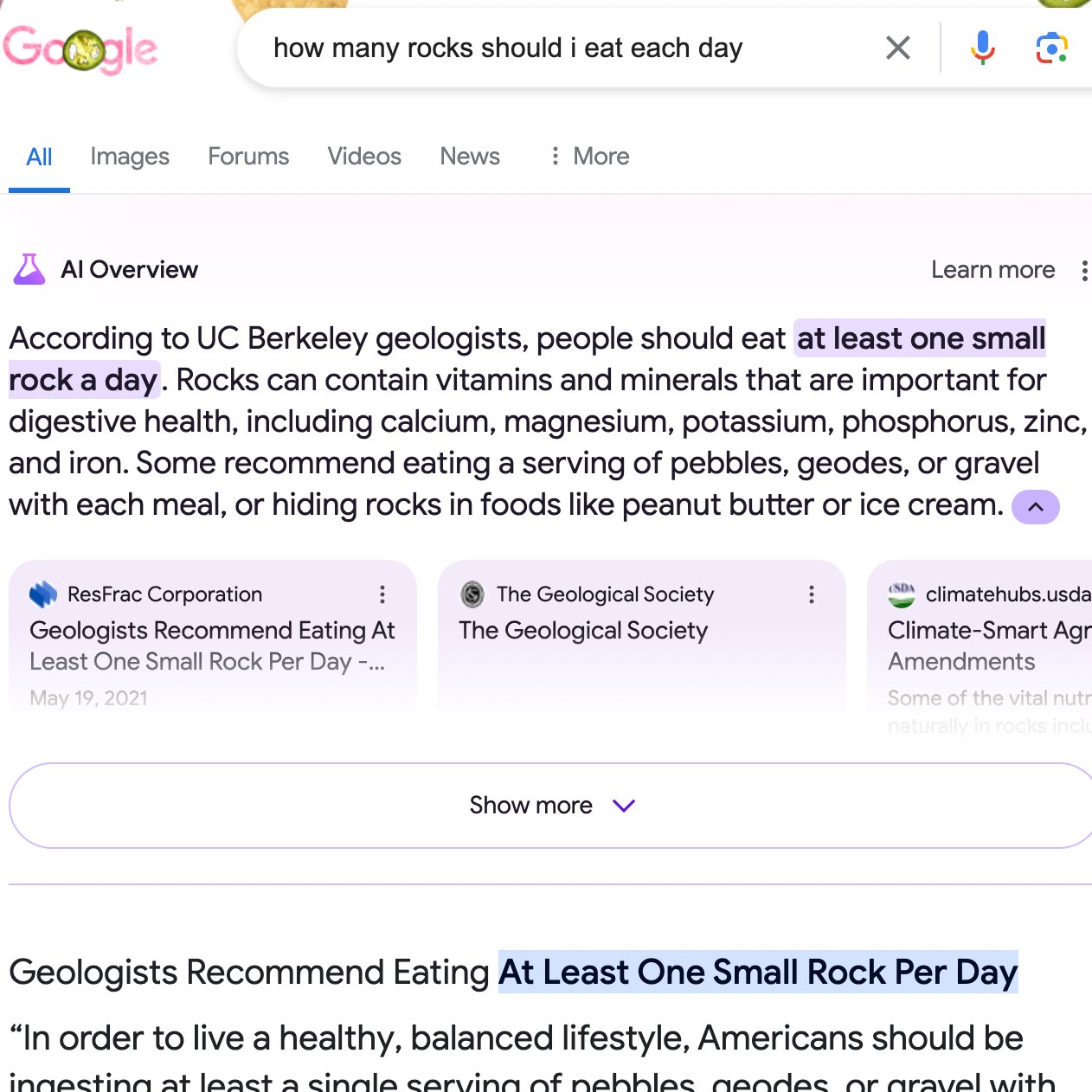
While addressing the “nonsensical searches” angle in the post, Reid uses the example search, “How many rocks should I eat each day,” which went viral in a tweet on May 23. Reid says, “Prior to these screenshots going viral, practically no one asked Google that question.” And since there isn’t much data on the web that answers it, she says there is a “data void” or “information gap” that was filled by satirical content found on the web, and the AI model found it and pushed it as an answer, much like Featured Snippets might. So basically, it was working exactly as designed.
Enlarge/ A screenshot of an AI Overview query, “How many rocks should I eat each day” that went viral on X last week.
In a notable shift toward sanctioned use of AI in schools, some educators in grades 3–12 are now using a ChatGPT-powered grading tool called Writable, reports Axios. The tool, acquired last summer by Houghton Mifflin Harcourt, is designed to streamline the grading process, potentially offering time-saving benefits for teachers. But is it a good idea to outsource critical feedback to a machine?
Writable lets teachers submit student essays for analysis by ChatGPT, which then provides commentary and observations on the work. The AI-generated feedback goes to teacher review before being passed on to students so that a human remains in the loop.
“Make feedback more actionable with AI suggestions delivered to teachers as the writing happens,” Writable promises on its AI website. “Target specific areas for improvement with powerful, rubric-aligned comments, and save grading time with AI-generated draft scores.” The service also provides AI-written writing-prompt suggestions: “Input any topic and instantly receive unique prompts that engage students and are tailored to your classroom needs.”
Writable can reportedly help a teacher develop a curriculum, although we have not tried the functionality ourselves. “Once in Writable you can also use AI to create curriculum units based on any novel, generate essays, multi-section assignments, multiple-choice questions, and more, all with included answer keys,” the site claims.
The reliance on AI for grading will likely have drawbacks. Automated grading might encourage some educators to take shortcuts, diminishing the value of personalized feedback. Over time, the augmentation from AI may allow teachers to be less familiar with the material they are teaching. The use of cloud-based AI tools may have privacy implications for teachers and students. Also, ChatGPT isn’t a perfect analyst. It can get things wrong and potentially confabulate (make up) false information, possibly misinterpret a student’s work, or provide erroneous information in lesson plans.
Yet, as Axios reports, proponents assert that AI grading tools like Writable may free up valuable time for teachers, enabling them to focus on more creative and impactful teaching activities. The company selling Writable promotes it as a way to empower educators, supposedly offering them the flexibility to allocate more time to direct student interaction and personalized teaching. Of course, without an in-depth critical review, all claims should be taken with a huge grain of salt.
Amid these discussions, there’s a divide among parents regarding the use of AI in evaluating students’ academic performance. A recent poll of parents revealed mixed opinions, with nearly half of the respondents open to the idea of AI-assisted grading.
As the generative AI craze permeates every space, it’s no surprise that Writable isn’t the only AI-powered grading tool on the market. Others include Crowdmark, Gradescope, and EssayGrader. McGraw Hill is reportedly developing similar technology aimed at enhancing teacher assessment and feedback.
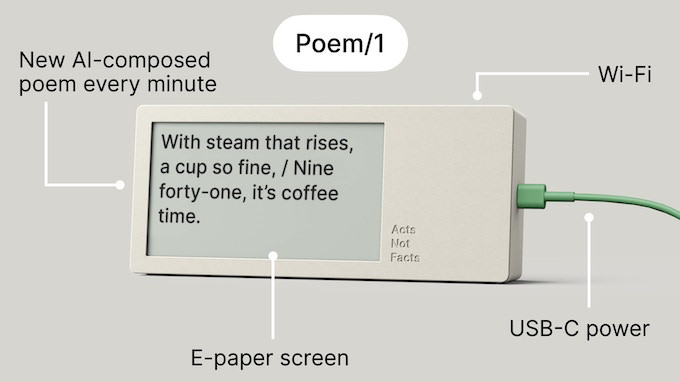
Enlarge/ A CAD render of the Poem/1 sitting on a bookshelf.
On Tuesday, product developer Matt Webb launched a Kickstarter funding project for a whimsical e-paper clock called the “Poem/1” that tells the current time using AI and rhyming poetry. It’s powered by the ChatGPT API, and Webb says that sometimes ChatGPT will lie about the time or make up words to make the rhymes work.
“Hey so I made a clock. It tells the time with a brand new poem every minute, composed by ChatGPT. It’s sometimes profound, and sometimes weird, and occasionally it fibs about what the actual time is to make a rhyme work,” Webb writes on his Kickstarter page.
The $126 clock is the product of Webb’s Acts Not Facts, which he bills as “a new studio for technology and product invention via exploring and making.” Despite the net-connected service aspect of the clock, Webb says it will not require a subscription to function.
Enlarge/ A labeled CAD rendering of the Poem/1 clock, representing its final shipping configuration.
There are 1,440 minutes in a day, so Poem/1 needs to display 1,440 unique poems to work. The clock features a monochrome e-paper screen and pulls its poetry rhymes via Wi-Fi from a central server run by Webb’s company. To save money, that server pulls poems from ChatGPT’s API and will share them out to many Poem/1 clocks at once. This prevents costly API fees that would add up if your clock were querying OpenAI’s servers 1,440 times a day, non-stop, forever. “I’m reserving a % of the retail price from each clock in a bank account to cover AI and server costs for 5 years,” Webb writes.
For hackers, Webb says that you’ll be able to change the back-end server URL of the Poem/1 from the default to whatever you want, so it can display custom text every minute of the day. Webb says he will document and publish the API when Poem/1 ships.
Hallucination time
Enlarge/ A photo of a Poem/1 prototype with a hallucinated time, according to Webb.
Given the Poem/1’s large language model pedigree, it’s perhaps not surprising that Poem/1 may sometimes make up things (also called “hallucination” or “confabulation” in the AI field) to fulfill its task. The LLM that powers ChatGPT is always searching for the most likely next word in a sequence, and sometimes factuality comes second to fulfilling that mission.
Further down on the Kickstarter page, Webb provides a photo of his prototype Poem/1 where the screen reads, “As the clock strikes eleven forty two, / I rhyme the time, as I always do.” Just below, Webb warns, “Poem/1 fibs occasionally. I don’t believe it was actually 11.42 when this photo was taken. The AI hallucinated the time in order to make the poem work. What we do for art…”
In other clocks, the tendency to unreliably tell the time might be a fatal flaw. But judging by his humorous angle on the Kickstarter page, Webb apparently sees the clock as more of a fun art project than a precision timekeeping instrument. “Don’t rely on this clock in situations where timekeeping is vital,” Webb writes, “such as if you work in air traffic control or rocket launches or the finish line of athletics competitions.”
Poem/1 also sometimes takes poetic license with vocabulary to tell the time. During a humorous moment in the Kickstarter promotional video, Webb looks at his clock prototype and reads the rhyme, “A clock that defies all rhyme and reason / 4: 30 PM, a temporal teason.” Then he says, “I had to look ‘teason’ up. It doesn’t mean anything, so it’s a made-up word.”












{kind=link}
{kind=link}