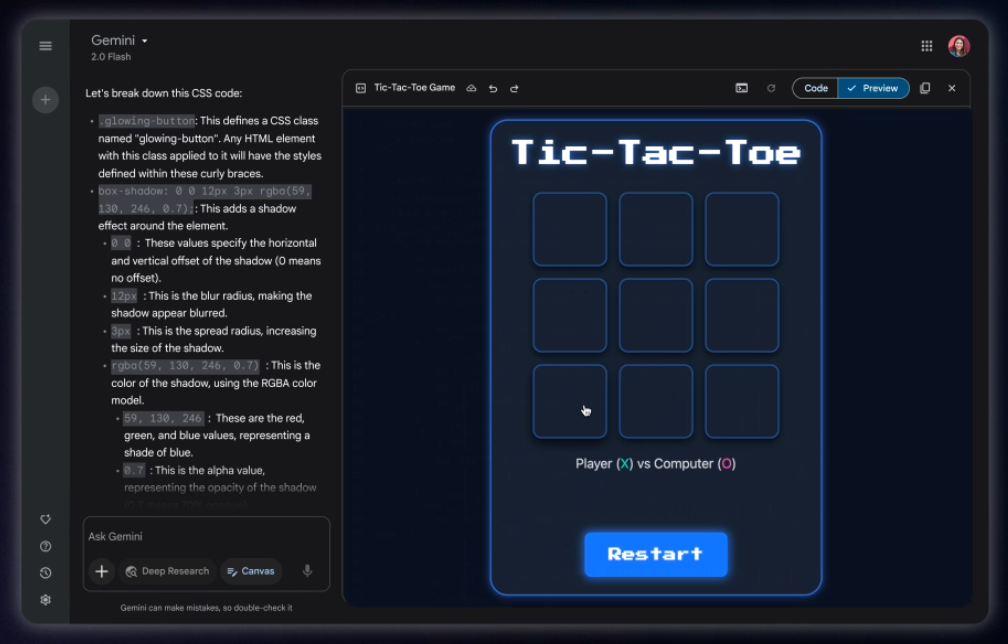
We recently spoke with Google’s Tulsee Doshi, who noted that the 2.5 Pro (Experimental) release was still prone to “overthinking” its responses to simple queries. However, the plan was to further improve dynamic thinking for the final release, and the team also hoped to give developers more control over the feature. That appears to be happening with Gemini 2.5 Flash, which includes “dynamic and controllable reasoning.”
The newest Gemini models will choose a “thinking budget” based on the complexity of the prompt. This helps reduce wait times and processing for 2.5 Flash. Developers even get granular control over the budget to lower costs and speed things along where appropriate. Gemini 2.5 models are also getting supervised tuning and context caching for Vertex AI in the coming weeks.
In addition to the arrival of Gemini 2.5 Flash, the larger Pro model has picked up a new gig. Google’s largest Gemini model is now powering its Deep Research tool, which was previously running Gemini 2.0 Pro. Deep Research lets you explore a topic in greater detail simply by entering a prompt. The agent then goes out into the Internet to collect data and synthesize a lengthy report.
Credit: Google
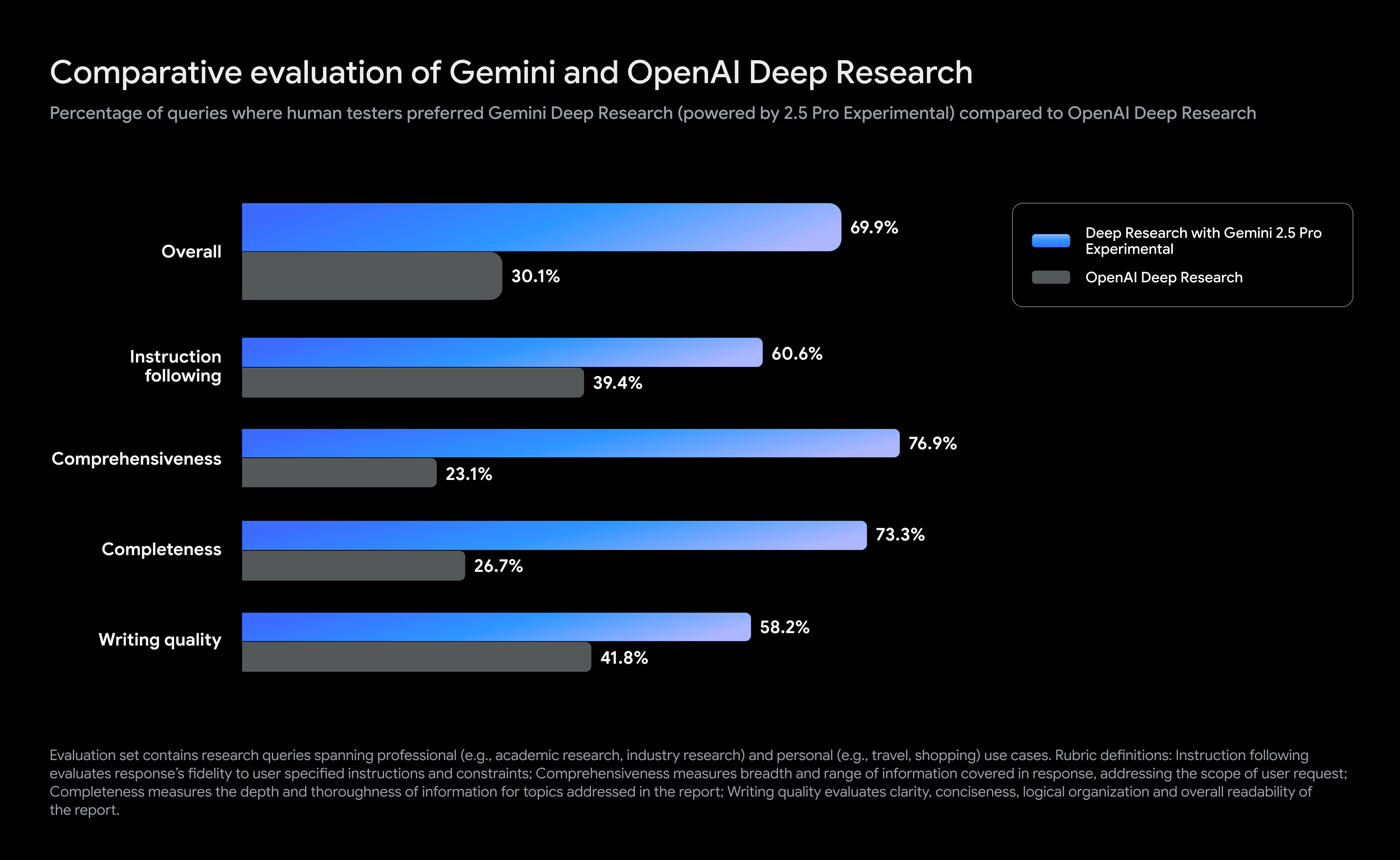
Google says that the move to Gemini 2.5 has boosted the accuracy and usefulness of Deep Research. The graphic above shows Google’s alleged advantage compared to OpenAI’s deep research tool. These stats are based on user evaluations (not synthetic benchmarks) and show a greater than 2-to-1 preference for Gemini 2.5 Pro reports.
Deep Research is available for limited use on non-paid accounts, but you won’t get the latest model. Deep Research with 2.5 Pro is currently limited to Gemini Advanced subscribers. However, we expect before long that all models in the Gemini app will move to the 2.5 branch. With dynamic reasoning and new TPUs, Google could begin lowering the sky-high costs that have thus far made generative AI unprofitable.
Google started cramming AI features into search in 2024, but last month marked an escalation. With the release of AI Mode, Google previewed a future in which searching the web does not return a list of 10 blue links. Google says it’s getting positive feedback on AI Mode from users, so it’s forging ahead by adding multimodal functionality to its robotic results.
AI Mode relies on a custom version of the Gemini large language model (LLM) to produce results. Google confirms that this model now supports multimodal input, which means you can now show images to AI Mode when conducting a search.
As this change rolls out, the search bar in AI Mode will gain a new button that lets you snap a photo or upload an image. The updated Gemini model can interpret the content of images, but it gets a little help from Google Lens. Google notes that Lens can identify specific objects in the images you upload, passing that context along so AI Mode can make multiple sub-queries, known as a “fan-out technique.”
Google illustrates how this could work in the example below. The user shows AI Mode a few books, asking questions about similar titles. Lens identifies each individual title, allowing AI Mode to incorporate the specifics of the books into its response. This is key to the model’s ability to suggest similar books and make suggestions based on the user’s follow-up question.
Google’s Tulsee Doshi talks vibes and efficiency in Gemini 2.5 Pro.
Google was caught flat-footed by the sudden skyrocketing interest in generative AI despite its role in developing the underlying technology. This prompted the company to refocus its considerable resources on catching up to OpenAI. Since then, we’ve seen the detail-flubbing Bard and numerous versions of the multimodal Gemini models. While Gemini has struggled to make progress in benchmarks and user experience, that could be changing with the new 2.5 Pro (Experimental) release. With big gains in benchmarks and vibes, this might be the first Google model that can make a dent in ChatGPT’s dominance.
We recently spoke to Google’s Tulsee Doshi, director of product management for Gemini, to talk about the process of releasing Gemini 2.5, as well as where Google’s AI models are going in the future.
Welcome to the vibes era
Google may have had a slow start in building generative AI products, but the Gemini team has picked up the pace in recent months. The company released Gemini 2.0 in December, showing a modest improvement over the 1.5 branch. It only took three months to reach 2.5, meaning Gemini 2.0 Pro wasn’t even out of the experimental stage yet. To hear Doshi tell it, this was the result of Google’s long-term investments in Gemini.
“A big part of it is honestly that a lot of the pieces and the fundamentals we’ve been building are now coming together in really awesome ways, ” Doshi said. “And so we feel like we’re able to pick up the pace here.”
The process of releasing a new model involves testing a lot of candidates. According to Doshi, Google takes a multilayered approach to inspecting those models, starting with benchmarks. “We have a set of evals, both external academic benchmarks as well as internal evals that we created for use cases that we care about,” she said.
Credit: Google
The team also uses these tests to work on safety, which, as Google points out at every given opportunity, is still a core part of how it develops Gemini. Doshi noted that making a model safe and ready for wide release involves adversarial testing and lots of hands-on time.
But we can’t forget the vibes, which have become an increasingly important part of AI models. There’s great focus on the vibe of outputs—how engaging and useful they are. There’s also the emerging trend of vibe coding, in which you use AI prompts to build things instead of typing the code yourself. For the Gemini team, these concepts are connected. The team uses product and user feedback to understand the “vibes” of the output, be that code or just an answer to a question.
Google has noted on a few occasions that Gemini 2.5 is at the top of the LM Arena leaderboard, which shows that people who have used the model prefer the output by a considerable margin—it has good vibes. That’s certainly a positive place for Gemini to be after a long climb, but there is some concern in the field that too much emphasis on vibes could push us toward models that make us feel good regardless of whether the output is good, a property known as sycophancy.
If the Gemini team has concerns about feel-good models, they’re not letting it show. Doshi mentioned the team’s focus on code generation, which she noted can be optimized for “delightful experiences” without stoking the user’s ego. “I think about vibe less as a certain type of personality trait that we’re trying to work towards,” Doshi said.
Hallucinations are another area of concern with generative AI models. Google has had plenty of embarrassing experiences with Gemini and Bard making things up, but the Gemini team believes they’re on the right path. Gemini 2.5 apparently has set a high-water mark in the team’s factuality metrics. But will hallucinations ever be reduced to the point we can fully trust the AI? No comment on that front.
Don’t overthink it
Perhaps the most interesting thing you’ll notice when using Gemini 2.5 is that it’s very fast compared to other models that use simulated reasoning. Google says it’s building this “thinking” capability into all of its models going forward, which should lead to improved outputs. The expansion of reasoning in large language models in 2024 resulted in a noticeable improvement in the quality of these tools. It also made them even more expensive to run, exacerbating an already serious problem with generative AI.
The larger and more complex an LLM becomes, the more expensive it is to run. Google hasn’t released technical data like parameter count on its newer models—you’ll have to go back to the 1.5 branch to get that kind of detail. However, Doshi explained that Gemini 2.5 is not a substantially larger model than Google’s last iteration, calling it “comparable” in size to 2.0.
Gemini 2.5 is more efficient in one key area: the chain of thought. It’s Google’s first public model to support a feature called Dynamic Thinking, which allows the model to modulate the amount of reasoning that goes into an output. This is just the first step, though.
“I think right now, the 2.5 Pro model we ship still does overthink for simpler prompts in a way that we’re hoping to continue to improve,” Doshi said. “So one big area we are investing in is Dynamic Thinking as a way to get towards our [general availability] version of 2.5 Pro where it thinks even less for simpler prompts.”
Credit: Ryan Whitwam
Google doesn’t break out earnings from its new AI ventures, but we can safely assume there’s no profit to be had. No one has managed to turn these huge LLMs into a viable business yet. OpenAI, which has the largest user base with ChatGPT, loses money even on the users paying for its $200 Pro plan. Google is planning to spend $75 billion on AI infrastructure in 2025, so it will be crucial to make the most of this very expensive hardware. Building models that don’t waste cycles on overthinking “Hi, how are you?” could be a big help.
Missing technical details
Google plays it close to the chest with Gemini, but the 2.5 Pro release has offered more insight into where the company plans to go than ever before. To really understand this model, though, we’ll need to see the technical report. Google last released such a document for Gemini 1.5. We still haven’t seen the 2.0 version, and we may never see that document now that 2.5 has supplanted 2.0.
Doshi notes that 2.5 Pro is still an experimental model. So, don’t expect full evaluation reports to happen right away. A Google spokesperson clarified that a full technical evaluation report on the 2.5 branch is planned, but there is no firm timeline. Google hasn’t even released updated model cards for Gemini 2.0, let alone 2.5. These documents are brief one-page summaries of a model’s training, intended use, evaluation data, and more. They’re essentially LLM nutrition labels. It’s much less detailed than a technical report, but it’s better than nothing. Google confirms model cards are on the way for Gemini 2.0 and 2.5.
Given the recent rapid pace of releases, it’s possible Gemini 2.5 Pro could be rolling out more widely around Google I/O in May. We certainly hope Google has more details when the 2.5 branch expands. As Gemini development picks up steam, transparency shouldn’t fall by the wayside.
Ryan Whitwam is a senior technology reporter at Ars Technica, covering the ways Google, AI, and mobile technology continue to change the world. Over his 20-year career, he’s written for Android Police, ExtremeTech, Wirecutter, NY Times, and more. He has reviewed more phones than most people will ever own. You can follow him on Bluesky, where you will see photos of his dozens of mechanical keyboards.
On the heels of releasing its most capable AI model yet, Google is making some changes to the Gemini team. A new report from Semafor reveals that longtime Googler Sissie Hsiao will step down from her role leading the Gemini team effective immediately. In her place, Google is appointing Josh Woodward, who currently leads Google Labs.
According to a memo from DeepMind CEO Demis Hassabis, this change is designed to “sharpen our focus on the next evolution of the Gemini app.” This new responsibility won’t take Woodward away from his role at Google Labs—he will remain in charge of that division while leading the Gemini team.
Meanwhile, Hsiao says in a message to employees that she is happy with “Chapter 1” of the Bard story and is optimistic for Woodward’s “Chapter 2.” Hsiao won’t be involved in Google’s AI efforts for now—she’s opted to take some time off before returning to Google in a new role.
Hsiao has been at Google for 19 years and was tasked with building Google’s chatbot in 2022. At the time, Google was reeling after ChatGPT took the world by storm using the very transformer architecture that Google originally invented. Initially, the team’s chatbot efforts were known as Bard before being unified under the Gemini brand at the end of 2023.
This process has been a bit of a slog, with Google’s models improving slowly while simultaneously worming their way into many beloved products. However, the sense inside the company is that Gemini has turned a corner with 2.5 Pro. While this model is still in the experimental stage, it has bested other models in academic benchmarks and has blown right past them in all-important vibemarks like LM Arena.
Google released its latest and greatest Gemini AI model last week, but it was only made available to paying subscribers. Google has moved with uncharacteristic speed to release Gemini 2.5 Pro (Experimental) for free users, too. The next time you check in with Gemini, you can access most of the new AI’s features without a Gemini Advanced subscription.
The Gemini 2.5 branch will eventually replace 2.0, which was only released in late 2024. It supports simulated reasoning, as all Google’s models will in the future. This approach to producing an output can avoid some of the common mistakes that AI models have made in the past. We’ve also been impressed with Gemini 2.5’s vibe, which has landed it at the top of the LMSYS Chatbot arena leaderboard.
Google says Gemini 2.5 Pro (Experimental) is ready and waiting for free users to try on the web. Simply select the model from the drop-down menu and enter your prompt to watch the “thinking” happen. The model will roll out to the mobile app for free users soon.
While the free tier gets access to this model, it won’t have all the advanced features. You still cannot upload files to Gemini without a paid account, which may make it hard to take advantage of the model’s large context window—although you won’t get the full 1 million-token window anyway. Google says the free version of Gemini 2.5 Pro (Experimental) will have a lower limit, which it has not specified. We’ve added a few thousand words without issue, but there’s another roadblock in the way.
Just a few months after releasing its first Gemini 2.0 AI models, Google is upgrading again. The company says the new Gemini 2.5 Pro Experimental is its “most intelligent” model yet, offering a massive context window, multimodality, and reasoning capabilities. Google points to a raft of benchmarks that show the new Gemini clobbering other large language models (LLMs), and our testing seems to back that up—Gemini 2.5 Pro is one of the most impressive generative AI models we’ve seen.
Gemini 2.5, like all Google’s models going forward, has reasoning built in. The AI essentially fact-checks itself along the way to generating an output. We like to call this “simulated reasoning,” as there’s no evidence that this process is akin to human reasoning. However, it can go a long way to improving LLM outputs. Google specifically cites the model’s “agentic” coding capabilities as a beneficiary of this process. Gemini 2.5 Pro Experimental can, for example, generate a full working video game from a single prompt. We’ve tested this, and it works with the publicly available version of the model.
Gemini 2.5 Pro builds a game in one step.
Google says a lot of things about Gemini 2.5 Pro; it’s smarter, it’s context-aware, it thinks—but it’s hard to quantify what constitutes improvement in generative AI bots. There are some clear technical upsides, though. Gemini 2.5 Pro comes with a 1 million token context window, which is common for the big Gemini models but massive compared to competing models like OpenAI GPT or Anthropic Claude. You could feed multiple very long books to Gemini 2.5 Pro in a single prompt, and the output maxes out at 64,000 tokens. That’s the same as Flash 2.0, but it’s still objectively a lot of tokens compared to other LLMs.
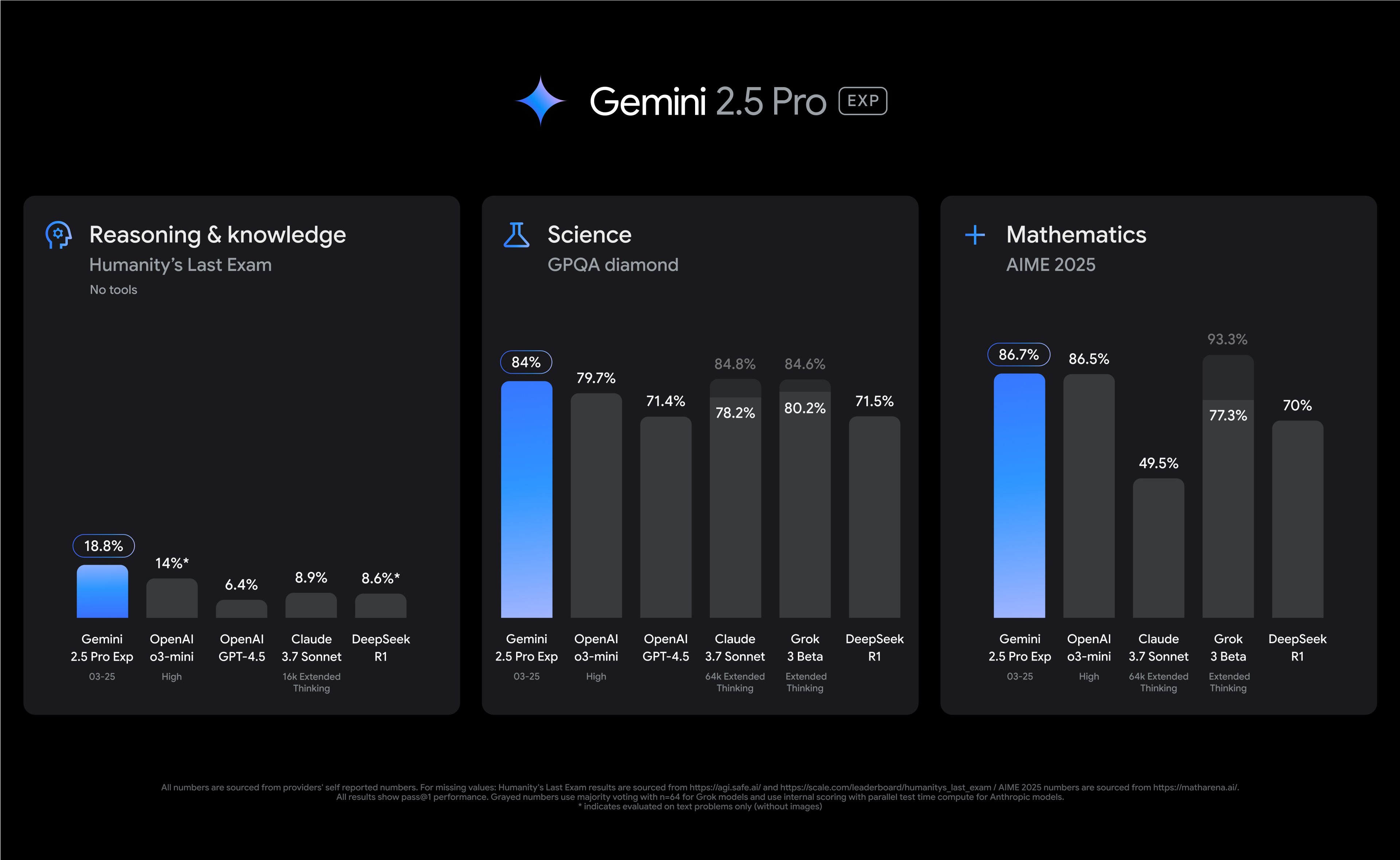
Naturally, Google has run Gemini 2.5 Experimental through a battery of benchmarks, in which it scores a bit higher than other AI systems. For example, it squeaks past OpenAI’s o3-mini in GPQA and AIME 2025, which measure how well the AI answers complex questions about science and math, respectively. It also set a new record in the Humanity’s Last Exam benchmark, which consists of 3,000 questions curated by domain experts. Google’s new AI managed a score of 18.8 percent to OpenAI’s 14 percent.
On the heels of its release of new Gemini models last week, Google has announced a pair of new features for its flagship AI product. Starting today, Gemini has a new Canvas feature that lets you draft, edit, and refine documents or code. Gemini is also getting Audio Overviews, a neat capability that first appeared in the company’s NotebookLM product, but it’s getting even more useful as part of Gemini.
Canvas is similar (confusingly) to the OpenAI product of the same name. Canvas is available in the Gemini prompt bar on the web and mobile app. Simply upload a document and tell Gemini what you need to do with it. In Google’s example, the user asks for a speech based on a PDF containing class notes. And just like that, Gemini spits out a document.
Canvas lets you refine the AI-generated documents right inside Gemini. The writing tools available across the Google ecosystem, with options like suggested edits and different tones, are available inside the Gemini-based editor. If you want to do more edits or collaborate with others, you can export the document to Google Docs with a single click.
Credit: Google
Canvas is also adept at coding. Just ask, and Canvas can generate prototype web apps, Python scripts, HTML, and more. You can ask Gemini about the code, make alterations, and even preview your results in real time inside Gemini as you (or the AI) make changes.
Google Assistant is not long for this world. Google confirmed what many suspected last week, that it will transition everyone to Gemini in 2025. Assistant holdouts may find it hard to stay on Google’s old system until the end, though. Google has confirmed some popular Assistant features are being removed in the coming weeks. You may not miss all of them, but others could force a change to your daily routine.
As Google has increasingly become totally consumed by Gemini, it was a foregone conclusion that Assistant would get the ax eventually. In 2024, Google removed features like media alarms and voice messages, but that was just the start. The full list of removals is still available on its support page (spotted by 9to5Google), but there’s now a new batch of features at the top. Here’s a rundown of what’s on the chopping block.
Favorite, share, and ask where and when your photos were taken with your voice
Change photo frame settings or ambient screen settings with your voice
Translate your live conversation with someone who doesn’t speak your language with interpreter mode
Get birthday reminder notifications as part of Routines
Ask to schedule or hear previously scheduled Family Bell announcements
Get daily updates from your Assistant, like “send me the weather everyday”
Use Google Assistant on car accessories that have a Bluetooth connection or AUX plug
Some of these are no great loss—you’ll probably live without the ability to get automatic birthday reminders or change smart display screensavers by voice. However, others are popular features that Google has promoted aggressively. For example, interpreter mode made a splash in 2019 and has been offering real-time translations ever since; Assistant can only translate a single phrase now. Many folks also use the scheduled updates in Assistant as part of their morning routine. Family Bell is much beloved, too, allowing Assistant to make custom announcements and interactive checklists, which can be handy for getting kids going in the morning. Attempting to trigger some of these features will offer a warning that they will go away soon.
Not all devices can simply download an updated app—after almost a decade, Assistant is baked into many Google products. The company says Google-powered cars, watches, headphones, and other devices that use Assistant will receive updates that transition them to Gemini. It’s unclear if all Assistant-powered gadgets will be part of the migration. Most of these devices connect to your phone, so the update should be relatively straightforward, even for accessories that launched early in the Assistant era.
There are also plenty of standalone devices that run Assistant, like TVs and smart speakers. Google says it’s working on updated Gemini experiences for those devices. For example, there’s a Gemini preview program for select Google Nest speakers. It’s unclear if all these devices will get updates. Google says there will be more details on this in the coming months.
Meanwhile, Gemini still has some ground to make up. There are basic features that work fine in Assistant, like setting timers and alarms, that can go sideways with Gemini. On the other hand, Assistant had its fair share of problems and didn’t exactly win a lot of fans. Regardless, this transition could be fraught with danger for Google as it upends how people interact with their devices.
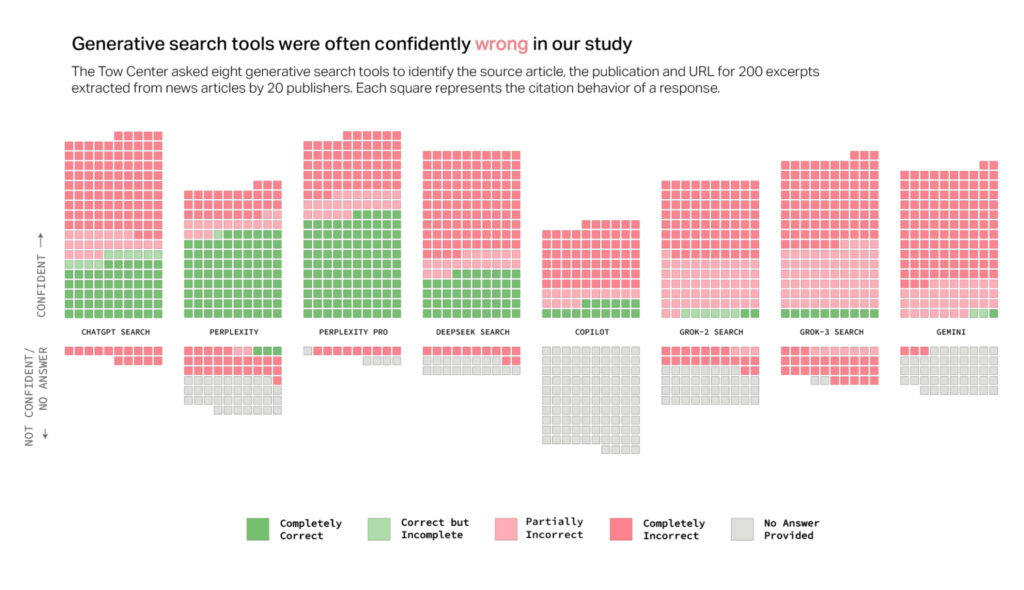
A new study from Columbia Journalism Review’s Tow Center for Digital Journalism finds serious accuracy issues with generative AI models used for news searches. The research tested eight AI-driven search tools equipped with live search functionality and discovered that the AI models incorrectly answered more than 60 percent of queries about news sources.
Researchers Klaudia Jaźwińska and Aisvarya Chandrasekar noted in their report that roughly 1 in 4 Americans now uses AI models as alternatives to traditional search engines. This raises serious concerns about reliability, given the substantial error rate uncovered in the study.
Error rates varied notably among the tested platforms. Perplexity provided incorrect information in 37 percent of the queries tested, whereas ChatGPT Search incorrectly identified 67 percent (134 out of 200) of articles queried. Grok 3 demonstrated the highest error rate, at 94 percent.
A graph from CJR shows “confidently wrong” search results. Credit: CJR
For the tests, researchers fed direct excerpts from actual news articles to the AI models, then asked each model to identify the article’s headline, original publisher, publication date, and URL. They ran 1,600 queries across the eight different generative search tools.
The study highlighted a common trend among these AI models: rather than declining to respond when they lacked reliable information, the models frequently provided confabulations—plausible-sounding incorrect or speculative answers. The researchers emphasized that this behavior was consistent across all tested models, not limited to just one tool.
Surprisingly, premium paid versions of these AI search tools fared even worse in certain respects. Perplexity Pro ($20/month) and Grok 3’s premium service ($40/month) confidently delivered incorrect responses more often than their free counterparts. Though these premium models correctly answered a higher number of prompts, their reluctance to decline uncertain responses drove higher overall error rates.
Issues with citations and publisher control
The CJR researchers also uncovered evidence suggesting some AI tools ignored Robot Exclusion Protocol settings, which publishers use to prevent unauthorized access. For example, Perplexity’s free version correctly identified all 10 excerpts from paywalled National Geographic content, despite National Geographic explicitly disallowing Perplexity’s web crawlers.
Gemini 2.0 is also coming to Deep Research, Google’s AI tool that creates detailed reports on a topic or question. This tool browses the web on your behalf, taking its time to assemble its responses. The new Gemini 2.0-based version will show more of its work as it gathers data, and Google claims the final product will be of higher quality.
You don’t have to take Google’s word on this—you can try it for yourself, even if you don’t pay for advanced AI features. Google is making Deep Research free, but it’s not unlimited. The company says everyone will be able to try Deep Research “a few times a month” at no cost. That’s all the detail we’re getting, so don’t go crazy with Deep Research right away.
Lastly, Google is also rolling out Gems to free accounts. Gems are like custom chatbots you can set up with a specific task in mind. Google has some defaults like Learning Coach and Brainstormer, but you can get creative and make just about anything (within the limits prescribed by Google LLC and applicable laws).
Some of the newly free features require a lot of inference processing, which is not cheap. Making its most expensive models free, even on a limited basis, will undoubtedly increase Google’s AI losses. No one has figured out how to make money on generative AI yet, but Google seems content spending more money to secure market share.
On Wednesday, Google DeepMind announced two new AI models designed to control robots: Gemini Robotics and Gemini Robotics-ER. The company claims these models will help robots of many shapes and sizes understand and interact with the physical world more effectively and delicately than previous systems, paving the way for applications such as humanoid robot assistants.
It’s worth noting that even though hardware for robot platforms appears to be advancing at a steady pace (well, maybe not always), creating a capable AI model that can pilot these robots autonomously through novel scenarios with safety and precision has proven elusive. What the industry calls “embodied AI” is a moonshot goal of Nvidia, for example, and it remains a holy grail that could potentially turn robotics into general-use laborers in the physical world.
Along those lines, Google’s new models build upon its Gemini 2.0 large language model foundation, adding capabilities specifically for robotic applications. Gemini Robotics includes what Google calls “vision-language-action” (VLA) abilities, allowing it to process visual information, understand language commands, and generate physical movements. By contrast, Gemini Robotics-ER focuses on “embodied reasoning” with enhanced spatial understanding, letting roboticists connect it to their existing robot control systems.
For example, with Gemini Robotics, you can ask a robot to “pick up the banana and put it in the basket,” and it will use a camera view of the scene to recognize the banana, guiding a robotic arm to perform the action successfully. Or you might say, “fold an origami fox,” and it will use its knowledge of origami and how to fold paper carefully to perform the task.
Gemini Robotics: Bringing AI to the physical world.
In 2023, we covered Google’s RT-2, which represented a notable step toward more generalized robotic capabilities by using Internet data to help robots understand language commands and adapt to new scenarios, then doubling performance on unseen tasks compared to its predecessor. Two years later, Gemini Robotics appears to have made another substantial leap forward, not just in understanding what to do but in executing complex physical manipulations that RT-2 explicitly couldn’t handle.
While RT-2 was limited to repurposing physical movements it had already practiced, Gemini Robotics reportedly demonstrates significantly enhanced dexterity that enables previously impossible tasks like origami folding and packing snacks into Zip-loc bags. This shift from robots that just understand commands to robots that can perform delicate physical tasks suggests DeepMind may have started solving one of robotics’ biggest challenges: getting robots to turn their “knowledge” into careful, precise movements in the real world.
Better generalized results
According to DeepMind, the new Gemini Robotics system demonstrates much stronger generalization, or the ability to perform novel tasks that it was not specifically trained to do, compared to its previous AI models. In its announcement, the company claims Gemini Robotics “more than doubles performance on a comprehensive generalization benchmark compared to other state-of-the-art vision-language-action models.” Generalization matters because robots that can adapt to new scenarios without specific training for each situation could one day work in unpredictable real-world environments.
That’s important because skepticism remains regarding how useful humanoid robots currently may be or how capable they really are. Tesla unveiled its Optimus Gen 3 robot last October, claiming the ability to complete many physical tasks, yet concerns persist over the authenticity of its autonomous AI capabilities after the company admitted that several robots in its splashy demo were controlled remotely by humans.
Here, Google is attempting to make the real thing: a generalist robot brain. With that goal in mind, the company announced a partnership with Austin, Texas-based Apptronik to”build the next generation of humanoid robots with Gemini 2.0.” While trained primarily on a bimanual robot platform called ALOHA 2, Google states that Gemini Robotics can control different robot types, from research-oriented Franka robotic arms to more complex humanoid systems like Apptronik’s Apollo robot.
Gemini Robotics: Dexterous skills.
While the humanoid robot approach is a relatively new application for Google’s generative AI models (from this cycle of technology based on LLMs), it’s worth noting that Google had previously acquired several robotics companies around 2013–2014 (including Boston Dynamics, which makes humanoid robots), but later sold them off. The new partnership with Apptronik appears to be a fresh approach to humanoid robotics rather than a direct continuation of those earlier efforts.
Other companies have been hard at work on humanoid robotics hardware, such as Figure AI (which secured significant funding for its humanoid robots in March 2024) and the aforementioned former Alphabet subsidiary Boston Dynamics (which introduced a flexible new Atlas robot last April), but a useful AI “driver” to make the robots truly useful has not yet emerged. On that front, Google has also granted limited access to the Gemini Robotics-ER through a “trusted tester” program to companies like Boston Dynamics, Agility Robotics, and Enchanted Tools.
Safety and limitations
For safety considerations, Google mentions a “layered, holistic approach” that maintains traditional robot safety measures like collision avoidance and force limitations. The company describes developing a “Robot Constitution” framework inspired by Isaac Asimov’s Three Laws of Robotics and releasing a dataset unsurprisingly called “ASIMOV” to help researchers evaluate safety implications of robotic actions.
This new ASIMOV dataset represents Google’s attempt to create standardized ways to assess robot safety beyond physical harm prevention. The dataset appears designed to help researchers test how well AI models understand the potential consequences of actions a robot might take in various scenarios. According to Google’s announcement, the dataset will “help researchers to rigorously measure the safety implications of robotic actions in real-world scenarios.”
The company did not announce availability timelines or specific commercial applications for the new AI models, which remain in a research phase. While the demo videos Google shared depict advancements in AI-driven capabilities, the controlled research environments still leave open questions about how these systems would actually perform in unpredictable real-world settings.