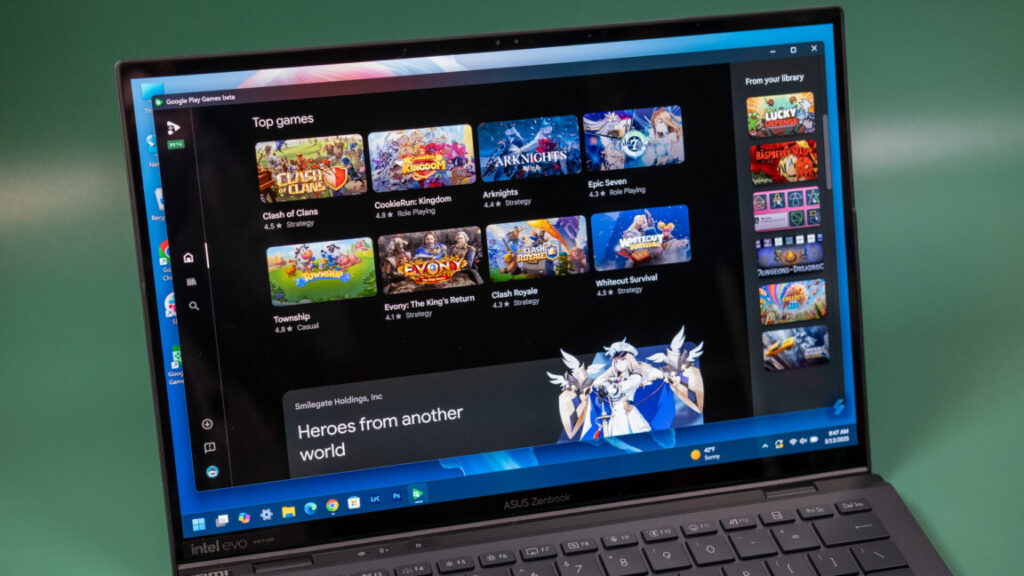
Google Play Games for PC is getting more premium titles and cross-buy with Android
Buy once (or more) to play anywhere
While Google announced last year it was opening the door to all Android games on Windows, things haven’t exactly worked out like that. It should have been easy, though. None of these “Windows” games is actually built for Windows—Play Games uses virtualization to run a lightweight Android OS in a container for the games. Hypothetically, all Android games should work, but there are still some big gaps.
For example, Play Games for Windows has thus far not supported paid games outside of those on Play Pass, and even some Play Pass content has been absent. In the latter case, that may be because developers have opted out. Google now says developers can choose to have Play Pass content available on both platforms. Regardless, the selection of free-to-play microtransaction factories in Play Games for PC hasn’t exactly screamed “premium experience.”
We should start seeing more paid games for Windows pop up, but Google’s going about it in an odd way. While these are still Android games at their core, Google is treating Windows as a separate platform. Thus, it has announced, “Buy once, play anywhere.” The idea is that developers can offer premium games in Google Play that include both Android and Windows access.
On mobile devices, anything you buy is always available on all other Android phones and tablets, but it’s apparently not the same for Windows. Developers have to join this program to offer cross-buy functionality, and it does not work for games you’ve previously purchased on Android. In addition, premium upgrades purchased on Android don’t necessarily carry over. Google says that depend son developer support and is unrelated to the new cross-buy program.
Google is making strides as it builds its desktop gaming catalog, but it still has a long way to go before it can attract any new players. In the distant past, Google might have just mirrored all mobile games on PC and called it a day, but Play Games on PC isn’t shaping up to be a Wild West. Google today is more deliberative and interested in controlling how apps are distributed. This is just another example of that mentality.
Updated 3/11 at 9PM ET with additional comment from Google.
Google Play Games for PC is getting more premium titles and cross-buy with Android Read More »











{kind=link}