Porsche’s best daily driver 911? The 2025 Carrera GTS T-Hybrid review.
An electric turbocharger means almost instant throttle response from the T-Hybrid.

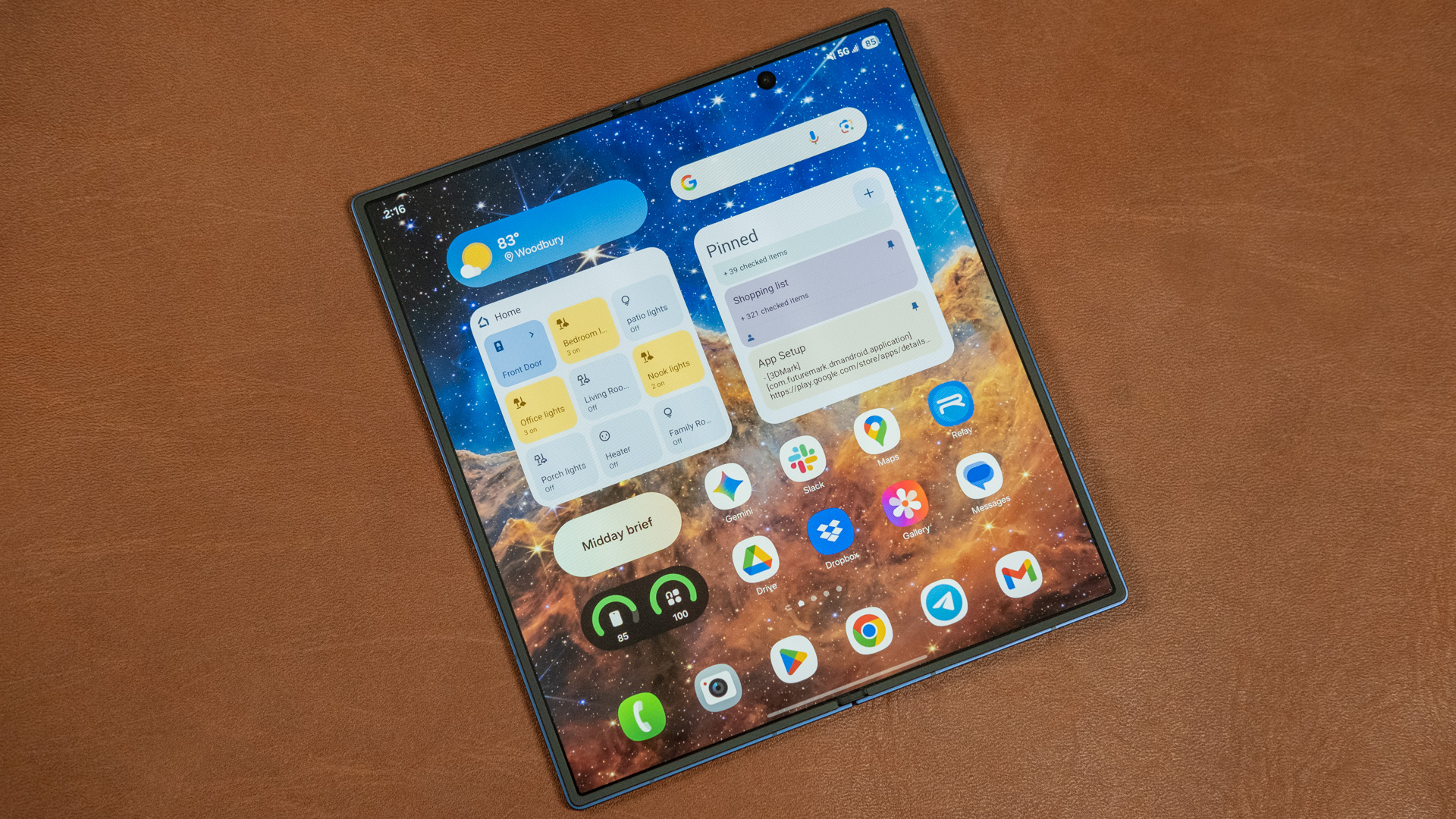
Porsche developed a new T-Hybrid system for the 911, and it did a heck of a job. Credit: Jonathan Gitlin
Porsche developed a new T-Hybrid system for the 911, and it did a heck of a job. Credit: Jonathan Gitlin
Porsche 911 enthusiasts tend to be obsessive about their engines. Some won’t touch anything that isn’t air-cooled, convinced that everything went wrong when emissions and efficiency finally forced radiators into the car. Others love the “Mezger” engines; designed by engineer Hans Mezger, they trace their roots to the 1998 Le Mans-winning car, and no Porschephile can resist the added shine of a motorsports halo.
I’m quite sure none of them will feel the same way about the powertrain in the new 911 Carrera GTS T-Hybrid (MSRP: $175,900), and I think that’s a crying shame. Because not only is the car’s technology rather cutting-edge—you won’t find this stuff outside an F1 car—but having spent several days behind the wheel, I can report it might just be one of the best-driving, too.
T-Hybrid
This is not just one of Porsche’s existing flat-six engines with an electric motor bolted on; it’s an all-new 3.6 L engine designed to comply with new European legislation that no longer lets automakers rich out a fuel mixture under high load to improve engine cooling. Instead, the engine has to maintain the same 14.7:1 stoichiometric air-to-fuel ratio (also known as lambda = 1) across the entire operating range, thus allowing the car’s catalytic converters to work most efficiently.
The 911 Carrera GTS T-Hybrid at dawn patrol. Jonathan Gitlin
Because the car uses a hybrid powertrain, Porsche moved some of the ancillaries. There’s no belt drive; the 400 V hybrid system powers the air conditioning electrically now via its 1.9 kWh lithium-ion battery, and the water pump is integrated into the engine block. That rearrangement means the horizontally opposed engine is now 4.3 inches (110 mm) lower than it was before, which meant Porsche could use that extra space in the engine bay to fit the power electronics, like the car’s pulse inverters and DC-DC converters.
And instead of tappets, Porsche has switched to using roller cam followers to control the engine’s valves, as in motorsport. These solid cam followers don’t need manual adjustment at service time, and they reduce friction losses compared to bucket tappets.
The added displacement—0.6 L larger than the engine you’ll find in the regular 911—is to compensate for not being able to alter the fuel ratio. And for the first time in several decades, there’s now only a single turbocharger. Normally, a larger-capacity engine and a single big turbo should be a recipe for plenty of lag, versus a smaller displacement and a turbocharger for each cylinder bank, as the former has larger components with more mass that needs to be moved.
The GTS engine grows in capacity by 20 percent. Porsche
That’s where one of the two electric motors comes in. This one is found between the compressor and the turbine wheel, and it’s only capable of 15 hp (11 kW), but it uses that to spin the turbine up to 120,000 rpm, hitting peak boost in 0.8 seconds. For comparison, the twin turbos you find in the current 3.0 L 911s take three times as long. Since the turbine is electrically controlled and the electric motor can regulate boost pressure, there’s no need for a wastegate.
The electrically powered turbocharger is essentially the same as the MGU-H used in Formula 1, as it can drive the turbine and also regenerate energy to the car’s traction battery. (The mighty 919 Hybrid race car, which took Porsche to three Le Mans wins last decade, was able to capture waste energy from its turbocharger, but unlike the 911 GTS or an F1 car, it didn’t use that same motor to spin the turbo up to speed.)
On its own, the turbocharged engine generates 478 hp (357 kW) and 420 lb-ft (570 Nm). However, there’s another electric motor, this one a permanent synchronous motor built into the eight-speed dual-clutch (PDK) transmission casing. This traction motor provides up to 53 hp (40 kW) and 110 lb-ft (150 Nm) of torque to the wheels, supplementing the internal combustion engine when needed. The total power and torque output are 532 hp (397 kW) and 449 lb-ft (609 Nm).

No Porsches were harmed during the making of this review, but one did get a little dusty. Credit: Jonathan Gitlin
Now that’s what I call throttle response
Conceptually, the T-Hybrid in the 911 GTS is quite different from the E-Hybrid system we’ve tested in various plug-in Porsches. Those allow for purely electric driving thanks to a clutch between transmission and electric traction motor—that’s not present in the T-Hybrid, where weight saving, performance, and emissions compliance were the goal rather than an increase in fuel efficiency.
Regardless of the intent, Porsche’s engineers have created a 911 with the best throttle response of any of them. Yes, even better than the naturally aspirated GT3, with its engine packed full of motorsports mods.
I realize this is a bold claim. But I’ve been saying for a while now that I prefer driving the all-electric Taycan to the 911 because the immediacy of an electric motor beats even the silkiest internal combustion engine in terms of that first few millimeters of throttle travel. The 3.0 L twin-turbo flat-six in most 911s doesn’t suffer from throttle lag like it might have in the 1980s, but there’s still an appreciable delay between initial tip-in and everything coming on song.
Initially, I suspected that the electric motor in the PDK case was responsible for the instantaneous way the GTS responds from idle, but according to Porsche’s engineers, all credit for that belongs to the electric turbocharger. However the engineers did it, this is a car that still provides 911 drivers the things they like about internal combustion engines—the sound, the fast refueling, using gears—but with the snappiness of a fast Taycan or Macan.

Centerlock wheels are rather special. Credit: Jonathan Gitlin
Porsche currently makes about 10 different 911 coupe variants, from the base 911 Carrera to the 911 GT3 RS. The GTS (also available with all-wheel drive as a Carrera 4 GTS for an extra $8,100) is marginally less powerful and slightly slower than the current 911 Turbo, and it’s heavier but more powerful than the 911 GT3.
In the past, I’ve thought of GTS-badged Porsches as that company’s take on the ultimate daily driver as opposed to a track day special, and it’s telling that you can also order the GTS with added sunshine, either as a cabriolet (in rear- or all-wheel drive) or as a Targa (with all-wheel drive). You have to remember to tick the box for rear seats now, though—these are a no-cost option rather than being fitted as standard.
The T-Hybrid powertrain adds 103 lbs compared to the previous GTS, so it’s not a lightweight track-day model, even if the non-hybrid GTS was almost nine seconds slower around the Nürburgring. On track, driven back to back with some of the others, you might be able to notice the extra weight, but I doubt it. I didn’t take the GTS on track, but I drove it to one; a trip to Germany to see the Nürburgring 24 race with some friends presented an opportunity to test this and another Porsche that hadn’t made their way to the East Coast press fleet yet.
I’d probably pick that Panamera if most of my driving was on the autobahn. With a top speed of 194 mph (312 km/h) the 911 GTS is capable of holding its own on the derestricted stretches even if its Vmax is a few miles per hour slower than the four-door sedan. But the 911 is a smaller, lighter, and more nimble car that moves around a bit more, and you sit a lot lower to the ground, amplifying the sensation of speed. The combined effect was that the car felt happier with a slightly lower cruising speed of 180 km/h rather than 200 km/h or more in the Panamera. Zero-62 mph (100 km/h) times don’t mean much outside the tollbooth but should take 2.9 seconds with launch control.

Despite the nondescript gray paint, the GTS T-Hybrid still turned plenty of heads. Credit: Jonathan Gitlin
Keep going
For the rest of the time, the 911 GTS evoked far more driving pleasure. Rear-wheel steering aids agility at lower speeds, and there are stiffer springs, newly tuned dampers, and electrohydraulic anti-roll bars (powered by the hybrid’s high-voltage system). Our test car was fitted with the gigantic (420 mm front, 410 mm rear) carbon ceramic brakes, and at the rear, the center lock wheels are 11.5 inches in width.
In the dry, I never got close to finding the front tires’ grip limit. The rear-wheel steering is noticeable, particularly when turning out of junctions, but never to the degree where you start thinking about correcting a slide unless you provoke the tires into breaking traction with the throttle. Even on the smooth tarmac preferred by German municipalities, the steering communicated road conditions from the tires, and the Alcantara-wrapped steering wheel is wonderful to grip in your palms.
So it’s predictably great to drive on mountain roads in Sport or Sport+. However, the instant throttle response means it’s also a better drive in Normal at 30 km/h as you amble your way through a village than the old GTS or any of the 3.0 L cars. That proved handy after Apple Maps sent me down a long dirt road on the way to my rental house, as well as for navigating the Nürburgring campsite, although I think I now appreciate why Porsche made the 911 Dakar (and regret declining that first drive a few years ago).
Happily, my time with the 911 GTS didn’t reveal any software bugs, and I prefer the new, entirely digital main instrument display to the old car’s analog tachometer sandwiched between two multifunction displays. Apple CarPlay worked well enough, and the compact cabin means that ergonomics are good even for those of us with shorter arms. There is a standard suite of advanced driver assistance systems, including traffic sign detection (which handily alerts you when the speed limit changes) and collision warning. Our test car included the optional InnoDrive system that adds adaptive cruise control, as well as a night vision system. On the whole, the ADAS was helpful, although if you don’t remember to disable the lane keep assist at the start of each journey, you might find it intruding mid-corner, should the car think you picked a bad line.
My only real gripe with the 911 GTS T-Hybrid is the fact that, with some options, you’re unlikely to get much change from $200,000. Yes, I know inflation is a thing, and yes, I know that’s still 15 percent less than the starting price of a 911 GT3 Touring, which isn’t really much of a step up from this car in terms of the driving experience on the road. However, a 911 Carrera T costs over $40,000 less than the T-Hybrid, and while it’s slower and less powerful, it’s still available with a six-speed manual. That any of those three would make an excellent daily driver 911 is a credit to Porsche, but I think if I had the means, the sophistication of the T-Hybrid system and its scalpel-sharp responsiveness might just win the day.

Jonathan is the Automotive Editor at Ars Technica. He has a BSc and PhD in Pharmacology. In 2014 he decided to indulge his lifelong passion for the car by leaving the National Human Genome Research Institute and launching Ars Technica’s automotive coverage. He lives in Washington, DC.
Porsche’s best daily driver 911? The 2025 Carrera GTS T-Hybrid review. Read More »