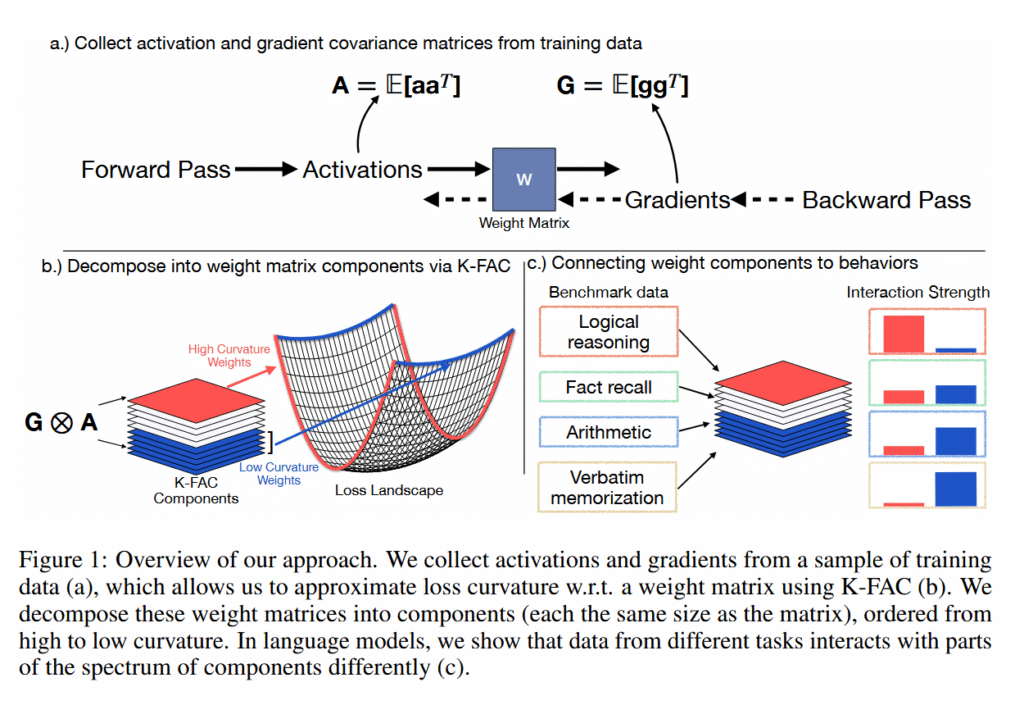
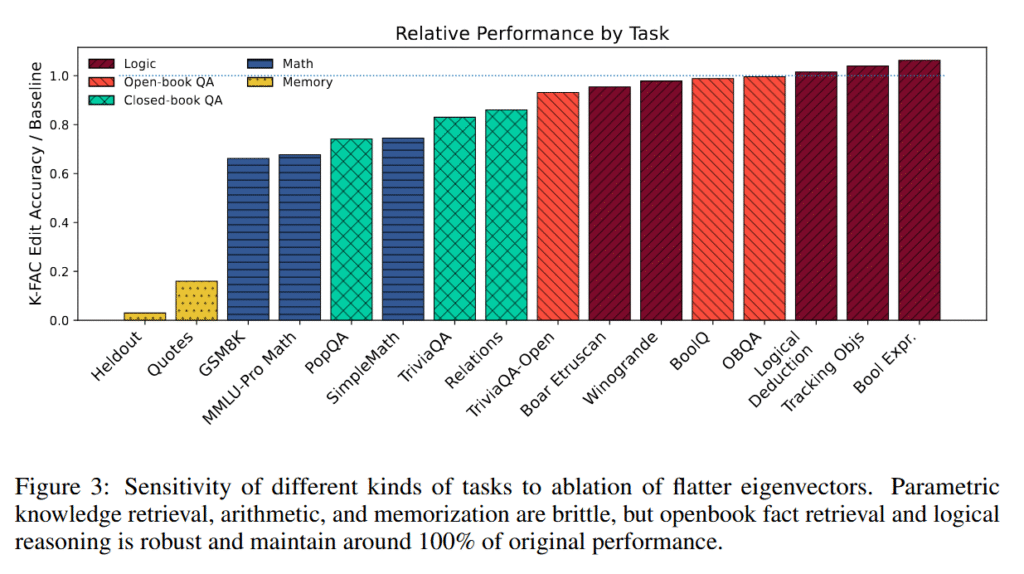
AIs can generate near-verbatim copies of novels from training data
A US court last year found that Anthropic’s training of LLMs on some copyrighted content could be considered fair use as it was deemed “transformative.”
But it determined that storing pirated works was “inherently, irredeemably infringing,” which then led the AI group to pay $1.5 billion to settle the lawsuit.
In Germany, a ruling from November last year found that OpenAI had infringed on copyright because its model had memorized song lyrics. The case, brought by GEMA, an association representing composers, lyricists, and publishers, was considered a landmark ruling in the EU.
Rudy Telscher, a partner at law firm Husch Blackwell, said reproducing an entire book without jailbreaking is “clearly a copyright violation.” But “it’s a matter of whether this is happening enough that [AI models] could be vicariously liable for the infringement,” he added.
Anthropic said the jailbreaking technique used in the Stanford and Yale research was impractical for normal users and would require more effort to extract the text than just purchasing the content.
The company also added that its model does not store copies of specific datasets but learns from patterns and relationships between words and strings in its training data.
xAI, OpenAI, and Google did not respond to requests for comment.
The fact that AI labs have put safeguards in place to prevent training data from being extracted means they are aware of the problem, said Imperial’s de Montjoye.
Ben Zhao, a computer science professor at the University of Chicago, questioned whether AI labs really needed to use copyrighted content in training data to create cutting-edge models in the first place.
“Whether the technical result can be done or not, it’s still a question of should we be doing this?” Zhao said. “The legal side should eventually hold their ground and really be the arbiter in this whole process.”
© 2026 The Financial Times Ltd. All rights reserved. Not to be redistributed, copied, or modified in any way.
AIs can generate near-verbatim copies of novels from training data Read More »