Beyond qubits: Meet the qutrit (and ququart)
The world of computers is dominated by binary. Silicon transistors are either conducting or they’re not, and so we’ve developed a whole world of math and logical operations around those binary capabilities. And, for the most part, quantum computing has been developing along similar lines, using qubits that, when measured, will be found in one of two states.
In some cases, the use of binary values is a feature of the object being used to hold the qubit. For example, a technology called dual-rail qubits takes its value from which of two linked resonators holds a photon. But there are many other quantum objects that have access to far more than two states—think of something like all the possible energy states an electron could occupy when orbiting an atom. We can use things like this as qubits by only relying on the lowest two energy levels. But there’s nothing stopping us from using more than two.
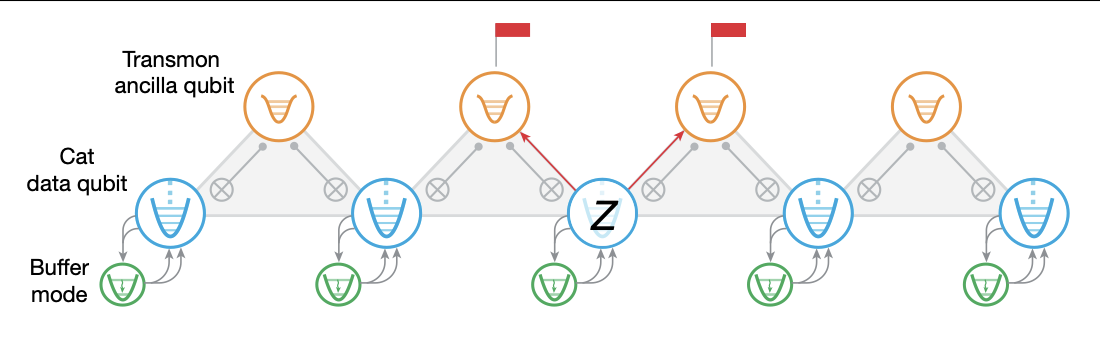
In Wednesday’s issue of Nature, researchers describe creating qudits, the generic term for systems that hold quantum information—it’s short for quantum digits. Using a system that can be in three or four possible states (qutrits and ququarts, respectively), they demonstrate the first error correction of higher-order quantum memory.
Making ququarts
More complex qudits haven’t been as popular with the people who are developing quantum computing hardware for a number of reasons; one of them is simply that some hardware only has access to two possible states. In other cases, the energy differences between additional states become small and difficult to distinguish. Finally, some operations can be challenging to execute when you’re working with qudits that can hold multiple values—a completely different programming model than qubit operations might be required.
Still, there’s a strong case to be made that moving beyond qubits could be valuable: it lets us do a lot more with less hardware. Right now, all the major quantum computing efforts are hardware-constrained—we can’t build enough qubits and link them together for error correction to let us do useful calculations. But if we could fit more information in less hardware, it should, in theory, let us get to useful calculations sooner.
Beyond qubits: Meet the qutrit (and ququart) Read More »