Since its founders started Anthropic in 2021, the company has marketed itself as one that takes an ethics- and safety-focused approach to AI development. The company differentiates itself from competitors like OpenAI by adopting what it calls responsible development practices and self-imposed ethical constraints on its models, such as its “Constitutional AI” system.
As Futurism points out, this new defense partnership appears to conflict with Anthropic’s public “good guy” persona, and pro-AI pundits on social media are noticing. Frequent AI commentator Nabeel S. Qureshi wrote on X, “Imagine telling the safety-concerned, effective altruist founders of Anthropic in 2021 that a mere three years after founding the company, they’d be signing partnerships to deploy their ~AGI model straight to the military frontlines.“
Aside from the implications of working with defense and intelligence agencies, the deal connects Anthropic with Palantir, a controversial company which recently won a $480 million contract to develop an AI-powered target identification system called Maven Smart System for the US Army. Project Maven has sparked criticism within the tech sector over military applications of AI technology.
It’s worth noting that Anthropic’s terms of service do outline specific rules and limitations for government use. These terms permit activities like foreign intelligence analysis and identifying covert influence campaigns, while prohibiting uses such as disinformation, weapons development, censorship, and domestic surveillance. Government agencies that maintain regular communication with Anthropic about their use of Claude may receive broader permissions to use the AI models.
Even if Claude is never used to target a human or as part of a weapons system, other issues remain. While its Claude models are highly regarded in the AI community, they (like all LLMs) have the tendency to confabulate, potentially generating incorrect information in a way that is difficult to detect.
That’s a huge potential problem that could impact Claude’s effectiveness with secret government data, and that fact, along with the other associations, has Futurism’s Victor Tangermann worried. As he puts it, “It’s a disconcerting partnership that sets up the AI industry’s growing ties with the US military-industrial complex, a worrying trend that should raise all kinds of alarm bells given the tech’s many inherent flaws—and even more so when lives could be at stake.”
In the AI world, there’s a buzz in the air about a new AI language model released Tuesday by Meta: Llama 3.1 405B. The reason? It’s potentially the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a “single server node,” which isn’t desktop PC-grade equipment. But it’s a provocative shot across the bow of “closed” AI model vendors such as OpenAI and Anthropic.
“Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation,” says Meta. Company CEO Mark Zuckerberg calls 405B “the first frontier-level open source AI model.”
In the AI industry, “frontier model” is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta is positioning 405B among the likes of the industry’s top AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
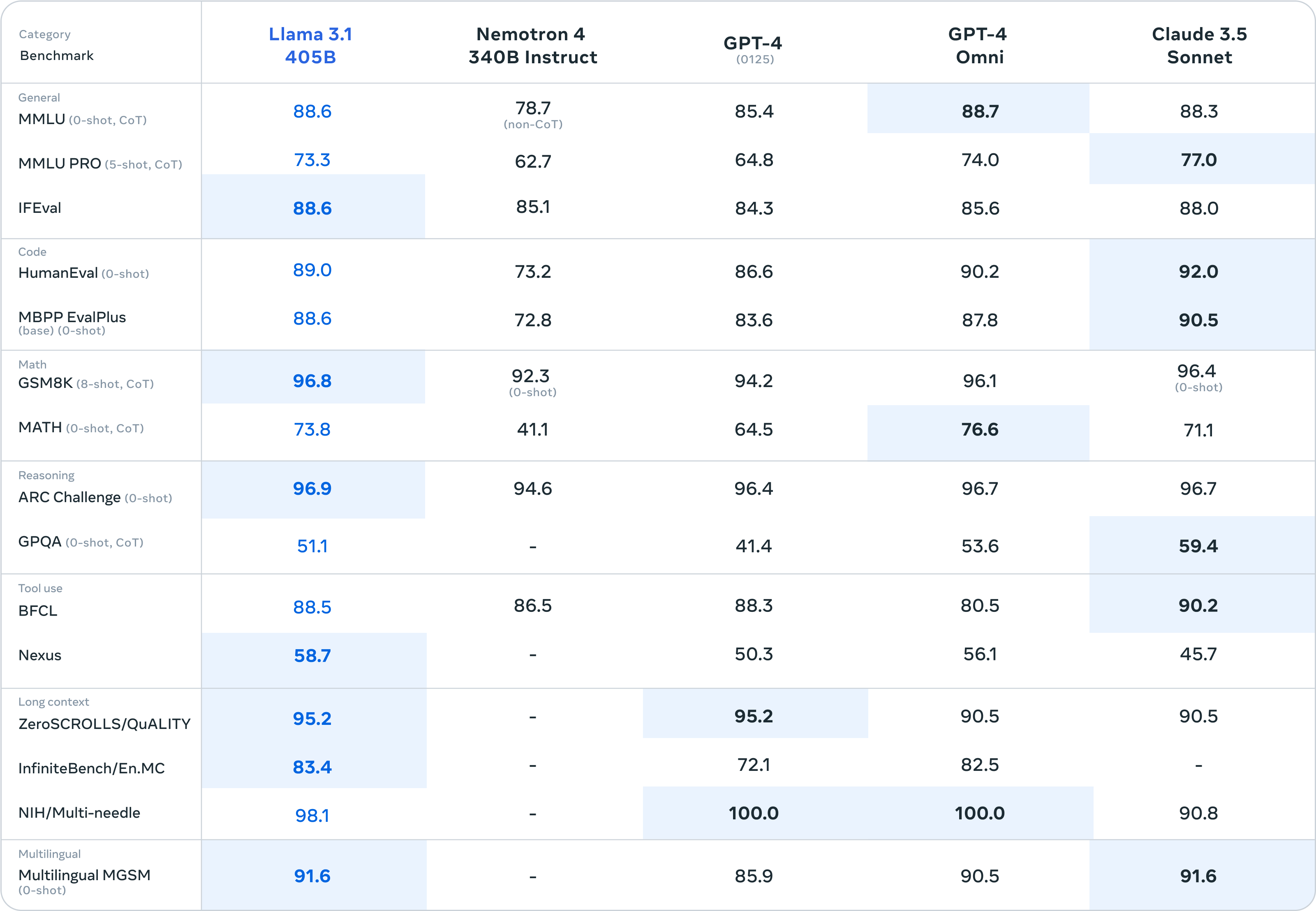
A chart published by Meta suggests that 405B gets very close to matching the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound or translate to the subjective experience of interacting with AI language models. In fact, this traditional slate of AI benchmarks is so generally useless to laypeople that even Meta’s PR department now just posts a few images of charts and doesn’t even try to explain them in any detail.
Enlarge/ A Meta-provided chart that shows Llama 3.1 405B benchmark results versus other major AI models.
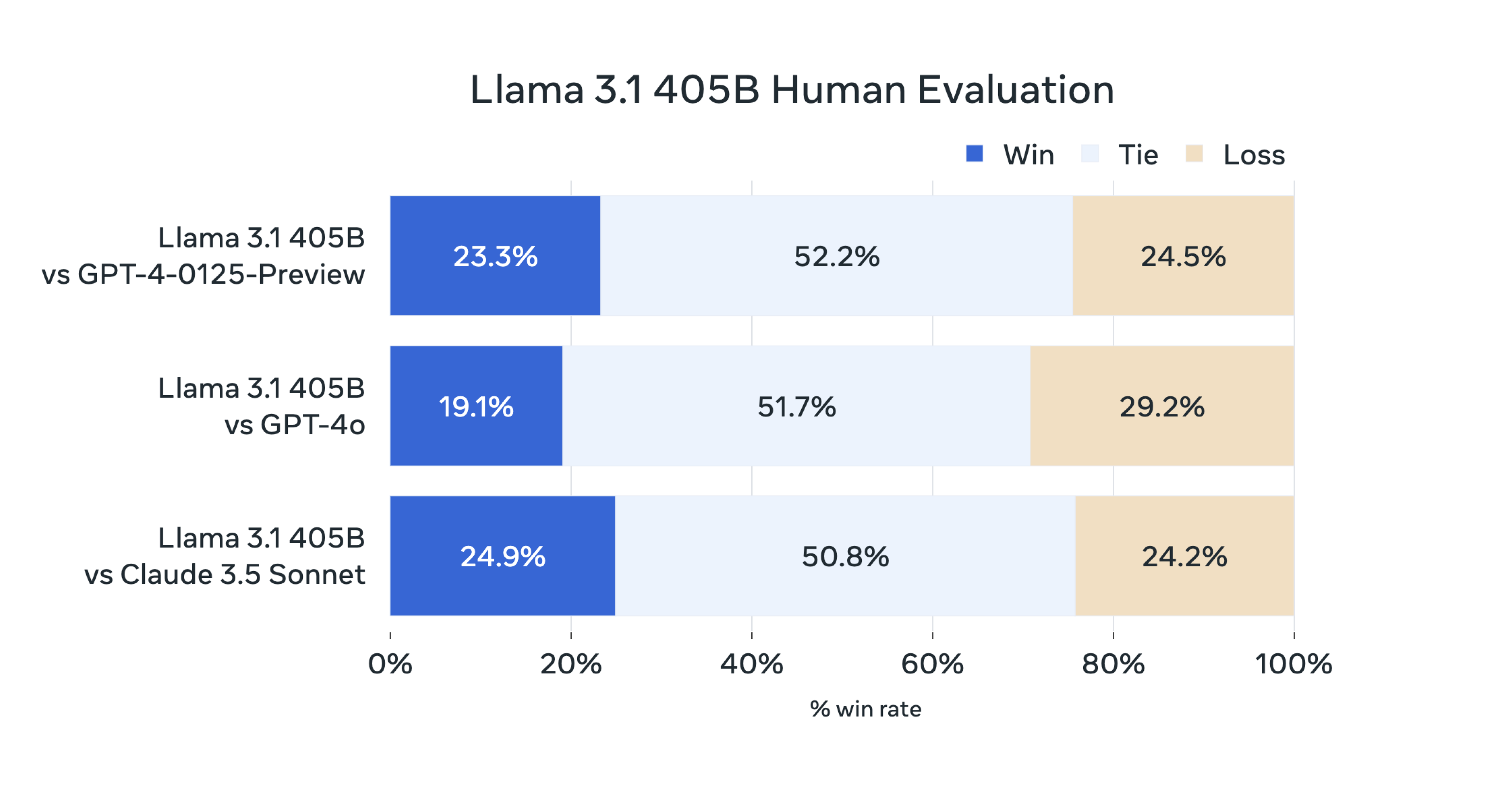
We’ve instead found that measuring the subjective experience of using a conversational AI model (through what might be called “vibemarking”) on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs that seem to show Meta’s new model holding its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Enlarge/ A Meta-provided chart that shows how humans rated Llama 3.1 405B’s outputs compared to GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in its own studies.
Whatever the benchmarks, early word on the street (after the model leaked on 4chan yesterday) seems to match the claim that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there—and money, of which the social media giant has plenty to burn. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using more than 16,000 H100 GPUs.
So what’s with the 405B name? In this case, “405B” means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capability, such as better ability to make contextual connections between concepts. But larger-parameter models have a tradeoff in needing more computing power (AKA “compute”) to run.
We’ve been expecting the release of a 400 billion-plus parameter model of the Llama 3 family since Meta gave word that it was training one in April, and today’s announcement isn’t just about the biggest member of the Llama 3 family: There’s an entirely new iteration of improved Llama models with the designation “Llama 3.1.” That includes upgraded versions of its smaller 8B and 70B models, which now feature multilingual support and an extended context length of 128,000 tokens (the “context length” is roughly the working memory capacity of the model, and “tokens” are chunks of data used by LLMs to process information).
Meta says that 405B is useful for long-form text summarization, multilingual conversational agents, and coding assistants and for creating synthetic data used to train future AI language models. Notably, that last use-case—allowing developers to use outputs from Llama models to improve other AI models—is now officially supported by Meta’s Llama 3.1 license for the first time.
Abusing the term “open source”
Llama 3.1 405B is an open-weights model, which means anyone can download the trained neural network files and run them or fine-tune them. That directly challenges a business model where companies like OpenAI keep the weights to themselves and instead monetize the model through subscription wrappers like ChatGPT or charge for access by the token through an API.
Fighting the “closed” AI model is a big deal to Mark Zuckerberg, who simultaneously released a 2,300-word manifesto today on why the company believes in open releases of AI models, titled, “Open Source AI Is the Path Forward.” More on the terminology in a minute. But briefly, he writes about the need for customizable AI models that offer user control and encourage better data security, higher cost-efficiency, and better future-proofing, as opposed to vendor-locked solutions.
All that sounds reasonable, but undermining your competitors using a model subsidized by a social media war chest is also an efficient way to play spoiler in a market where you might not always win with the most cutting-edge tech. That benefits Meta, Zuckerberg says, because he doesn’t want to get locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to “taxes” Apple levies on developers through its App Store.
Enlarge/ A screenshot of Mark Zuckerberg’s essay, “Open Source AI Is the Path Forward,” published on July 23, 2024.
So, about that “open source” term. As we first wrote in an update to our Llama 2 launch article a year ago, “open source” has a very particular meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (such as Llama 3.1) or that ship without providing training data. We’ve been calling these releases “open weights” instead.
Unfortunately for terminology sticklers, Zuckerberg has now baked the erroneous “open source” label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the correct term in AI may be a losing battle. Still, his usage annoys people like independent AI researcher Simon Willison, who likes Zuckerberg’s essay otherwise.
“I see Zuck’s prominent misuse of ‘open source’ as a small-scale act of cultural vandalism,” Willison told Ars Technica. “Open source should have an agreed meaning. Abusing the term weakens that meaning which makes the term less generally useful, because if someone says ‘it’s open source,’ that no longer tells me anything useful. I have to then dig in and figure out what they’re actually talking about.”
The Llama 3.1 models are available for download through Meta’s own website and on Hugging Face. They both require providing contact information and agreeing to a license and an acceptable use policy, which means that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.
On Thursday, Anthropic announced Claude 3.5 Sonnet, its latest AI language model and the first in a new series of “3.5” models that build upon Claude 3, launched in March. Claude 3.5 can compose text, analyze data, and write code. It features a 200,000 token context window and is available now on the Claude website and through an API. Anthropic also introduced Artifacts, a new feature in the Claude interface that shows related work documents in a dedicated window.
So far, people outside of Anthropic seem impressed. “This model is really, really good,” wrote independent AI researcher Simon Willison on X. “I think this is the new best overall model (and both faster and half the price of Opus, similar to the GPT-4 Turbo to GPT-4o jump).”
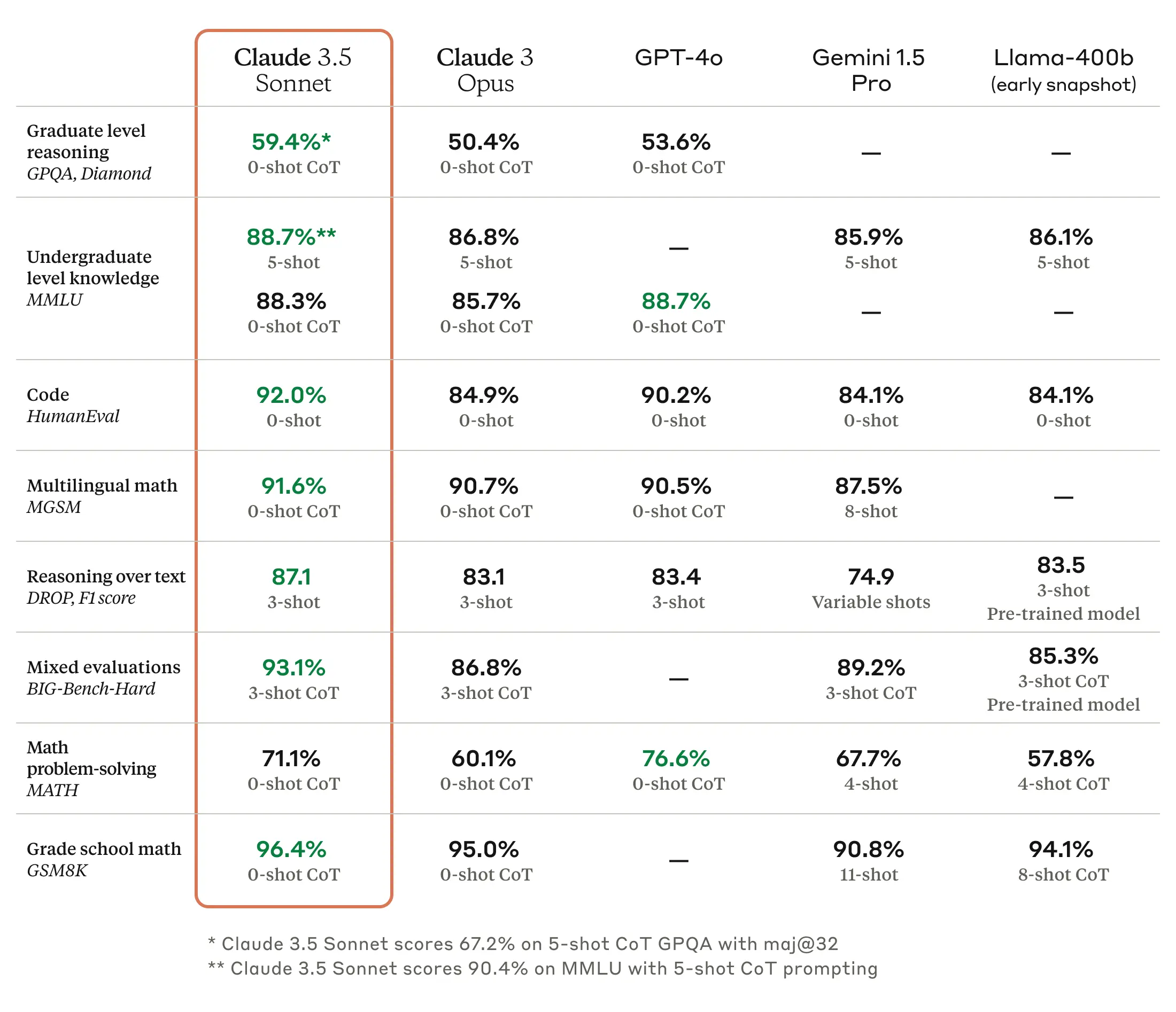
As we’ve written before, benchmarks for large language models (LLMs) are troublesome because they can be cherry-picked and often do not capture the feel and nuance of using a machine to generate outputs on almost any conceivable topic. But according to Anthropic, Claude 3.5 Sonnet matches or outperforms competitor models like GPT-4o and Gemini 1.5 Pro on certain benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
Enlarge/ Claude 3.5 Sonnet benchmarks provided by Anthropic.
If all that makes your eyes glaze over, that’s OK; it’s meaningful to researchers but mostly marketing to everyone else. A more useful performance metric comes from what we might call “vibemarks” (coined here first!) which are subjective, non-rigorous aggregate feelings measured by competitive usage on sites like LMSYS’s Chatbot Arena. The Claude 3.5 Sonnet model is currently under evaluation there, and it’s too soon to say how well it will fare.
Claude 3.5 Sonnet also outperforms Anthropic’s previous-best model (Claude 3 Opus) on benchmarks measuring “reasoning,” math skills, general knowledge, and coding abilities. For example, the model demonstrated strong performance in an internal coding evaluation, solving 64 percent of problems compared to 38 percent for Claude 3 Opus.
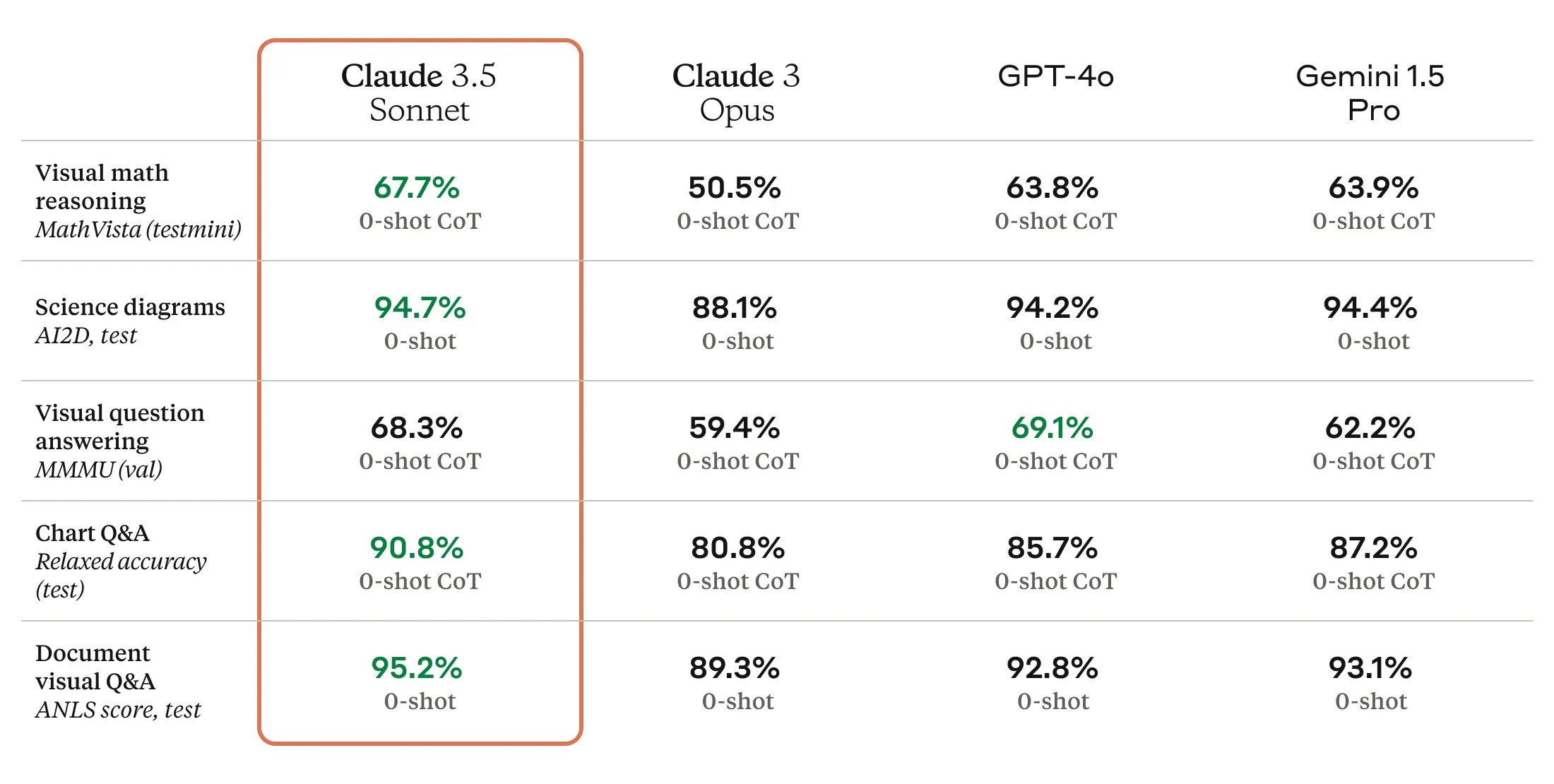
Claude 3.5 Sonnet is also a multimodal AI model that accepts visual input in the form of images, and the new model is reportedly excellent at a battery of visual comprehension tests.
Enlarge/ Claude 3.5 Sonnet benchmarks provided by Anthropic.
Roughly speaking, the visual benchmarks mean that 3.5 Sonnet is better at pulling information from images than previous models. For example, you can show it a picture of a rabbit wearing a football helmet, and the model knows it’s a rabbit wearing a football helmet and can talk about it. That’s fun for tech demos, but the tech is still not accurate enough for applications of the tech where reliability is mission critical.
Enlarge/ The Claude AI iOS app running on an iPhone.
Anthropic
On Wednesday, Anthropic announced the launch of an iOS mobile app for its Claude 3 AI language models that are similar to OpenAI’s ChatGPT. It also introduced a new subscription tier designed for group collaboration. Before the app launch, Claude was only available through a website, an API, and other apps that integrated Claude through API.
Like the ChatGPT app, Claude’s new mobile app serves as a gateway to chatbot interactions, and it also allows uploading photos for analysis. While it’s only available on Apple devices for now, Anthropic says that an Android app is coming soon.
Anthropic rolled out the Claude 3 large language model (LLM) family in March, featuring three different model sizes: Claude Opus, Claude Sonnet, and Claude Haiku. Currently, the app utilizes Sonnet for regular users and Opus for Pro users.
While Anthropic has been a key player in the AI field for several years, it’s entering the mobile space after many of its competitors have already established footprints on mobile platforms. OpenAI released its ChatGPT app for iOS in May 2023, with an Android version arriving two months later. Microsoft released a Copilot iOS app in January. Google Gemini is available through the Google app on iPhone.
Enlarge/ Screenshots of the Claude AI iOS app running on an iPhone.
Anthropic
The app is freely available to all users of Claude, including those using the free version, subscribers paying $20 per month for Claude Pro, and members of the newly introduced Claude Team plan. Conversation history is saved and shared between the web app version of Claude and the mobile app version after logging in.
Speaking of that Team plan, it’s designed for groups of at least five and is priced at $30 per seat per month. It offers more chat queries (higher rate limits), access to all three Claude models, and a larger context window (200K tokens) for processing lengthy documents or maintaining detailed conversations. It also includes group admin tools and billing management, and users can easily switch between Pro and Team plans.
Enlarge/ An image of a boy amazed by flying letters.
Some weeks in AI news are eerily quiet, but during others, getting a grip on the week’s events feels like trying to hold back the tide. This week has seen three notable large language model (LLM) releases: Google Gemini Pro 1.5 hit general availability with a free tier, OpenAI shipped a new version of GPT-4 Turbo, and Mistral released a new openly licensed LLM, Mixtral 8x22B. All three of those launches happened within 24 hours starting on Tuesday.
With the help of software engineer and independent AI researcher Simon Willison (who also wrote about this week’s hectic LLM launches on his own blog), we’ll briefly cover each of the three major events in roughly chronological order, then dig into some additional AI happenings this week.
Gemini Pro 1.5 general release
On Tuesday morning Pacific time, Google announced that its Gemini 1.5 Pro model (which we first covered in February) is now available in 180-plus countries, excluding Europe, via the Gemini API in a public preview. This is Google’s most powerful public LLM so far, and it’s available in a free tier that permits up to 50 requests a day.
It supports up to 1 million tokens of input context. As Willison notes in his blog, Gemini 1.5 Pro’s API price at $7/million input tokens and $21/million output tokens costs a little less than GPT-4 Turbo (priced at $10/million in and $30/million out) and more than Claude 3 Sonnet (Anthropic’s mid-tier LLM, priced at $3/million in and $15/million out).
Notably, Gemini 1.5 Pro includes native audio (speech) input processing that allows users to upload audio or video prompts, a new File API for handling files, the ability to add custom system instructions (system prompts) for guiding model responses, and a JSON mode for structured data extraction.
“Majorly Improved” GPT-4 Turbo launch
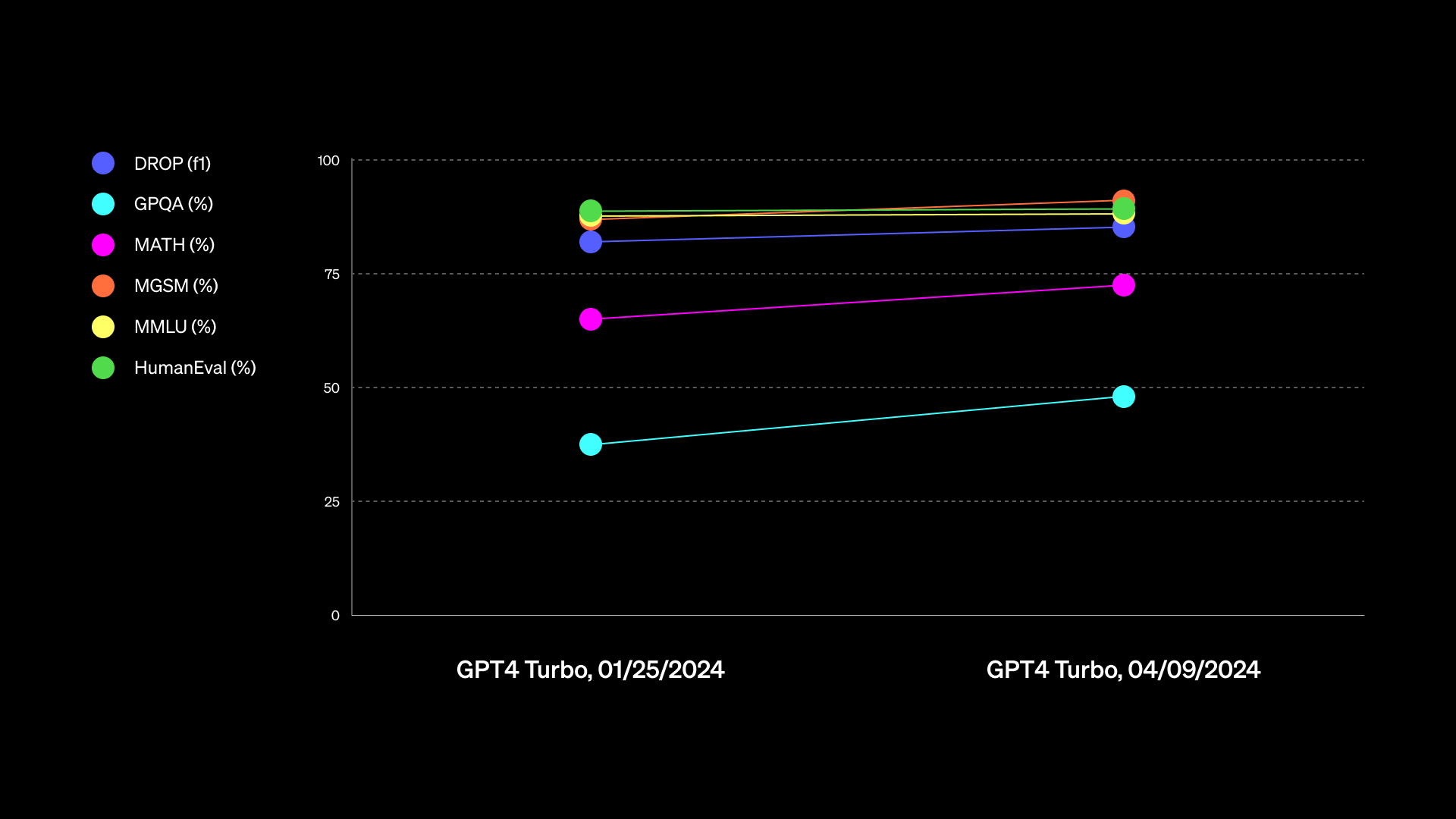
Enlarge/ A GPT-4 Turbo performance chart provided by OpenAI.
Just a bit later than Google’s 1.5 Pro launch on Tuesday, OpenAI announced that it was rolling out a “majorly improved” version of GPT-4 Turbo (a model family originally launched in November) called “gpt-4-turbo-2024-04-09.” It integrates multimodal GPT-4 Vision processing (recognizing the contents of images) directly into the model, and it initially launched through API access only.
Then on Thursday, OpenAI announced that the new GPT-4 Turbo model had just become available for paid ChatGPT users. OpenAI said that the new model improves “capabilities in writing, math, logical reasoning, and coding” and shared a chart that is not particularly useful in judging capabilities (that they later updated). The company also provided an example of an alleged improvement, saying that when writing with ChatGPT, the AI assistant will use “more direct, less verbose, and use more conversational language.”
The vague nature of OpenAI’s GPT-4 Turbo announcements attracted some confusion and criticism online. On X, Willison wrote, “Who will be the first LLM provider to publish genuinely useful release notes?” In some ways, this is a case of “AI vibes” again, as we discussed in our lament about the poor state of LLM benchmarks during the debut of Claude 3. “I’ve not actually spotted any definite differences in quality [related to GPT-4 Turbo],” Willison told us directly in an interview.
The update also expanded GPT-4’s knowledge cutoff to April 2024, although some people are reporting it achieves this through stealth web searches in the background, and others on social media have reported issues with date-related confabulations.
Mistral’s mysterious Mixtral 8x22B release
Enlarge/ An illustration of a robot holding a French flag, figuratively reflecting the rise of AI in France due to Mistral. It’s hard to draw a picture of an LLM, so a robot will have to do.
Not to be outdone, on Tuesday night, French AI company Mistral launched its latest openly licensed model, Mixtral 8x22B, by tweeting a torrent link devoid of any documentation or commentary, much like it has done with previous releases.
The new mixture-of-experts (MoE) release weighs in with a larger parameter count than its previously most-capable open model, Mixtral 8x7B, which we covered in December. It’s rumored to potentially be as capable as GPT-4 (In what way, you ask? Vibes). But that has yet to be seen.
“The evals are still rolling in, but the biggest open question right now is how well Mixtral 8x22B shapes up,” Willison told Ars. “If it’s in the same quality class as GPT-4 and Claude 3 Opus, then we will finally have an openly licensed model that’s not significantly behind the best proprietary ones.”
This release has Willison most excited, saying, “If that thing really is GPT-4 class, it’s wild, because you can run that on a (very expensive) laptop. I think you need 128GB of MacBook RAM for it, twice what I have.”
The new Mixtral is not listed on Chatbot Arena yet, Willison noted, because Mistral has not released a fine-tuned model for chatting yet. It’s still a raw, predict-the-next token LLM. “There’s at least one community instruction tuned version floating around now though,” says Willison.
Chatbot Arena Leaderboard shake-ups
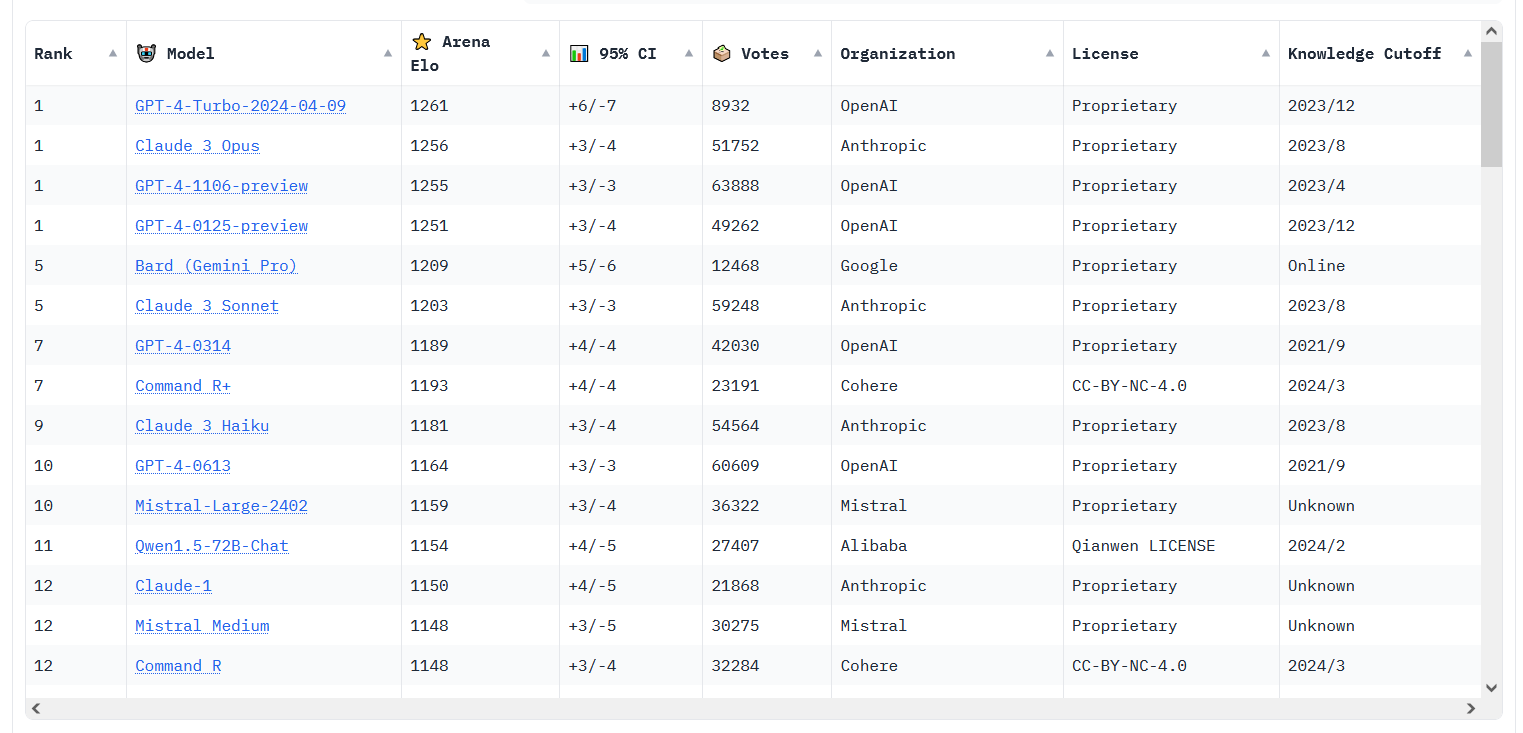
Enlarge/ A Chatbot Arena Leaderboard screenshot taken on April 12, 2024.
Benj Edwards
This week’s LLM news isn’t limited to just the big names in the field. There have also been rumblings on social media about the rising performance of open source models like Cohere’s Command R+, which reached position 6 on the LMSYS Chatbot Arena Leaderboard—the highest-ever ranking for an open-weights model.
And for even more Chatbot Arena action, apparently the new version of GPT-4 Turbo is proving competitive with Claude 3 Opus. The two are still in a statistical tie, but GPT-4 Turbo recently pulled ahead numerically. (In March, we reported when Claude 3 first numerically pulled ahead of GPT-4 Turbo, which was then the first time another AI model had surpassed a GPT-4 family model member on the leaderboard.)
Regarding this fierce competition among LLMs—of which most of the muggle world is unaware and will likely never be—Willison told Ars, “The past two months have been a whirlwind—we finally have not just one but several models that are competitive with GPT-4.” We’ll see if OpenAI’s rumored release of GPT-5 later this year will restore the company’s technological lead, we note, which once seemed insurmountable. But for now, Willison says, “OpenAI are no longer the undisputed leaders in LLMs.”
On Monday, OpenAI announced that visitors to the ChatGPT website in some regions can now use the AI assistant without signing in. Previously, the company required that users create an account to use it, even with the free version of ChatGPT that is currently powered by the GPT-3.5 AI language model. But as we have noted in the past, GPT-3.5 is widely known to provide more inaccurate information compared to GPT-4 Turbo, available in paid versions of ChatGPT.
Since its launch in November 2022, ChatGPT has transformed over time from a tech demo to a comprehensive AI assistant, and it’s always had a free version available. The cost is free because “you’re the product,” as the old saying goes. Using ChatGPT helps OpenAI gather data that will help the company train future AI models, although free users and ChatGPT Plus subscription members can both opt out of allowing the data they input into ChatGPT to be used for AI training. (OpenAI says it never trains on inputs from ChatGPT Team and Enterprise members at all).
Opening ChatGPT to everyone could provide a frictionless on-ramp for people who might use it as a substitute for Google Search or potentially gain new customers by providing an easy way for people to use ChatGPT quickly, then offering an upsell to paid versions of the service.
“It’s core to our mission to make tools like ChatGPT broadly available so that people can experience the benefits of AI,” OpenAI says on its blog page. “For anyone that has been curious about AI’s potential but didn’t want to go through the steps to set up an account, start using ChatGPT today.”
Enlarge/ When you visit the ChatGPT website, you’re immediately presented with a chat box like this (in some regions). Screenshot captured April 1, 2024.
Benj Edwards
Since kids will also be able to use ChatGPT without an account—despite it being against the terms of service—OpenAI also says it’s introducing “additional content safeguards,” such as blocking more prompts and “generations in a wider range of categories.” What exactly that entails has not been elaborated upon by OpenAI, but we reached out to the company for comment.
There might be a few other downsides to the fully open approach. On X, AI researcher Simon Willison wrote about the potential for automated abuse as a way to get around paying for OpenAI’s services: “I wonder how their scraping prevention works? I imagine the temptation for people to abuse this as a free 3.5 API will be pretty strong.”
With fierce competition, more GPT-3.5 access may backfire
Willison also mentioned a common criticism of OpenAI (as voiced in this case by Wharton professor Ethan Mollick) that people’s ideas about what AI models can do have so far largely been influenced by GPT-3.5, which, as we mentioned, is far less capable and far more prone to making things up than the paid version of ChatGPT that uses GPT-4 Turbo.
“In every group I speak to, from business executives to scientists, including a group of very accomplished people in Silicon Valley last night, much less than 20% of the crowd has even tried a GPT-4 class model,” wrote Mollick in a tweet from early March.
With models like Google Gemini Pro 1.5 and Anthropic Claude 3 potentially surpassing OpenAI’s best proprietary model at the moment —and open weights AI models eclipsing the free version of ChatGPT—allowing people to use GPT-3.5 might not be putting OpenAI’s best foot forward. Microsoft Copilot, powered by OpenAI models, also supports a frictionless, no-login experience, but it allows access to a model based on GPT-4. But Gemini currently requires a sign-in, and Anthropic sends a login code through email.
For now, OpenAI says the login-free version of ChatGPT is not yet available to everyone, but it will be coming soon: “We’re rolling this out gradually, with the aim to make AI accessible to anyone curious about its capabilities.”
On Monday, Anthropic released Claude 3, a family of three AI language models similar to those that power ChatGPT. Anthropic claims the models set new industry benchmarks across a range of cognitive tasks, even approaching “near-human” capability in some cases. It’s available now through Anthropic’s website, with the most powerful model being subscription-only. It’s also available via API for developers.
Claude 3’s three models represent increasing complexity and parameter count: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. Sonnet powers the Claude.ai chatbot now for free with an email sign-in. But as mentioned above, Opus is only available through Anthropic’s web chat interface if you pay $20 a month for “Claude Pro,” a subscription service offered through the Anthropic website. All three feature a 200,000-token context window. (The context window is the number of tokens—fragments of a word—that an AI language model can process at once.)
We covered the launch of Claude in March 2023 and Claude 2 in July that same year. Each time, Anthropic fell slightly behind OpenAI’s best models in capability while surpassing them in terms of context window length. With Claude 3, Anthropic has perhaps finally caught up with OpenAI’s released models in terms of performance, although there is no consensus among experts yet—and the presentation of AI benchmarks is notoriously prone to cherry-picking.
Enlarge/ A Claude 3 benchmark chart provided by Anthropic.
Claude 3 reportedly demonstrates advanced performance across various cognitive tasks, including reasoning, expert knowledge, mathematics, and language fluency. (Despite the lack of consensus over whether large language models “know” or “reason,” the AI research community commonly uses those terms.) The company claims that the Opus model, the most capable of the three, exhibits “near-human levels of comprehension and fluency on complex tasks.”
That’s quite a heady claim and deserves to be parsed more carefully. It’s probably true that Opus is “near-human” on some specific benchmarks, but that doesn’t mean that Opus is a general intelligence like a human (consider that pocket calculators are superhuman at math). So, it’s a purposely eye-catching claim that can be watered down with qualifications.
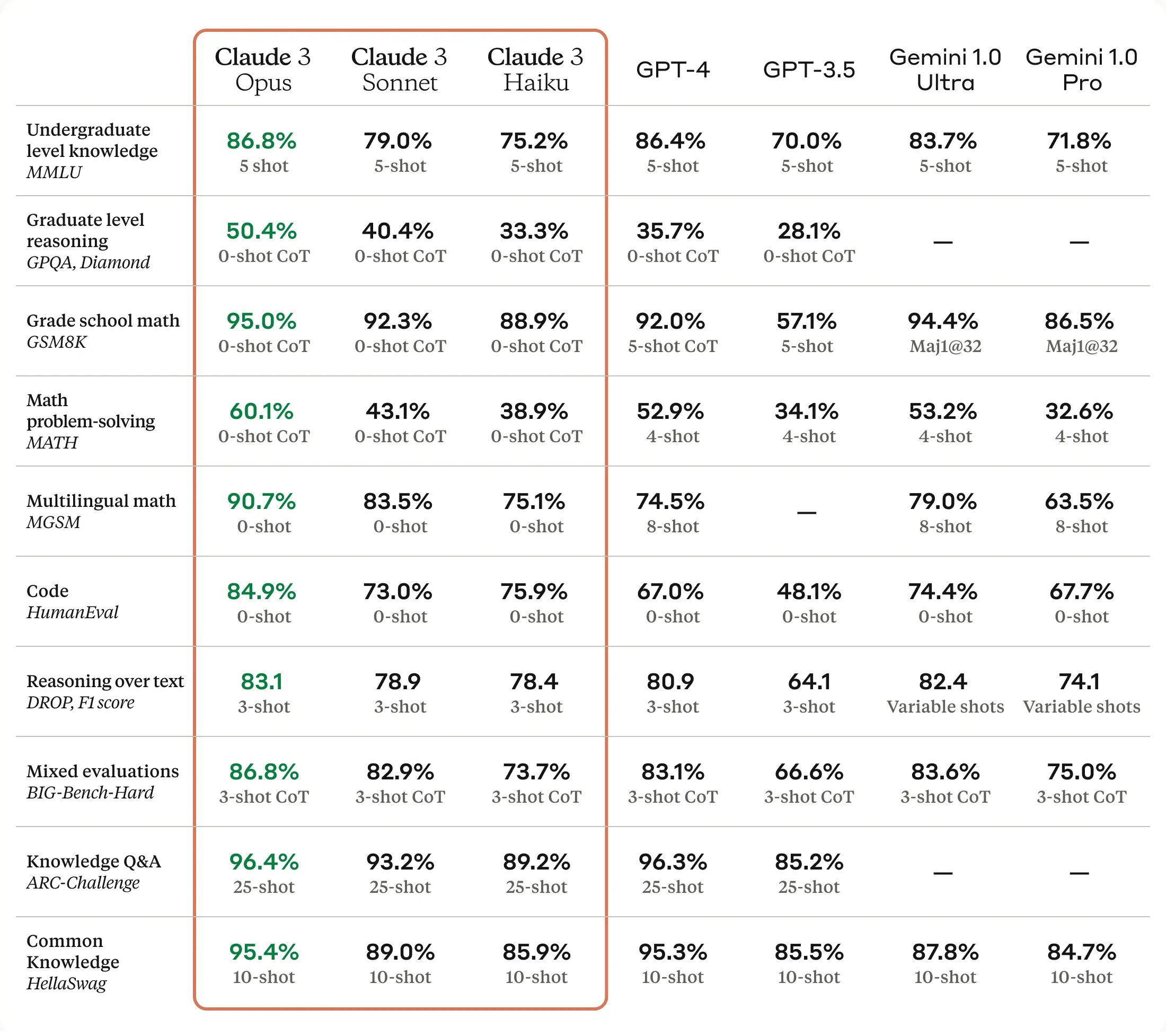
According to Anthropic, Claude 3 Opus beats GPT-4 on 10 AI benchmarks, including MMLU (undergraduate level knowledge), GSM8K (grade school math), HumanEval (coding), and the colorfully named HellaSwag (common knowledge). Several of the wins are very narrow, such as 86.8 percent for Opus vs. 86.4 percent on a five-shot trial of MMLU, and some gaps are big, such as 84.9 percent on HumanEval over GPT-4’s 67.0 percent. But what that might mean, exactly, to you as a customer is difficult to say.
“As always, LLM benchmarks should be treated with a little bit of suspicion,” says AI researcher Simon Willison, who spoke with Ars about Claude 3. “How well a model performs on benchmarks doesn’t tell you much about how the model ‘feels’ to use. But this is still a huge deal—no other model has beaten GPT-4 on a range of widely used benchmarks like this.”













{kind=link}
{kind=link}
{kind=link}