OpenAI to test ads in ChatGPT as it burns through billions
Financial pressures and a changing tune
OpenAI’s advertising experiment reflects the enormous financial pressures facing the company. OpenAI does not expect to be profitable until 2030 and has committed to spend about $1.4 trillion on massive data centers and chips for AI.
According to financial documents obtained by The Wall Street Journal in November, OpenAI expects to burn through roughly $9 billion this year while generating $13 billion in revenue. Only about 5 percent of ChatGPT’s 800 million weekly users pay for subscriptions, so it’s not enough to cover all of OpenAI’s operating costs.
Not everyone is convinced ads will solve OpenAI’s financial problems. “I am extremely bearish on this ads product,” tech critic Ed Zitron wrote on Bluesky. “Even if this becomes a good business line, OpenAI’s services cost too much for it to matter!”
OpenAI’s embrace of ads appears to come reluctantly, since it runs counter to a “personal bias” against advertising that Altman has shared in earlier public statements. For example, during a fireside chat at Harvard University in 2024, Altman said he found the combination of ads and AI “uniquely unsettling,” implying that he would not like it if the chatbot itself changed its responses due to advertising pressure. He added: “When I think of like GPT writing me a response, if I had to go figure out exactly how much was who paying here to influence what I’m being shown, I don’t think I would like that.”
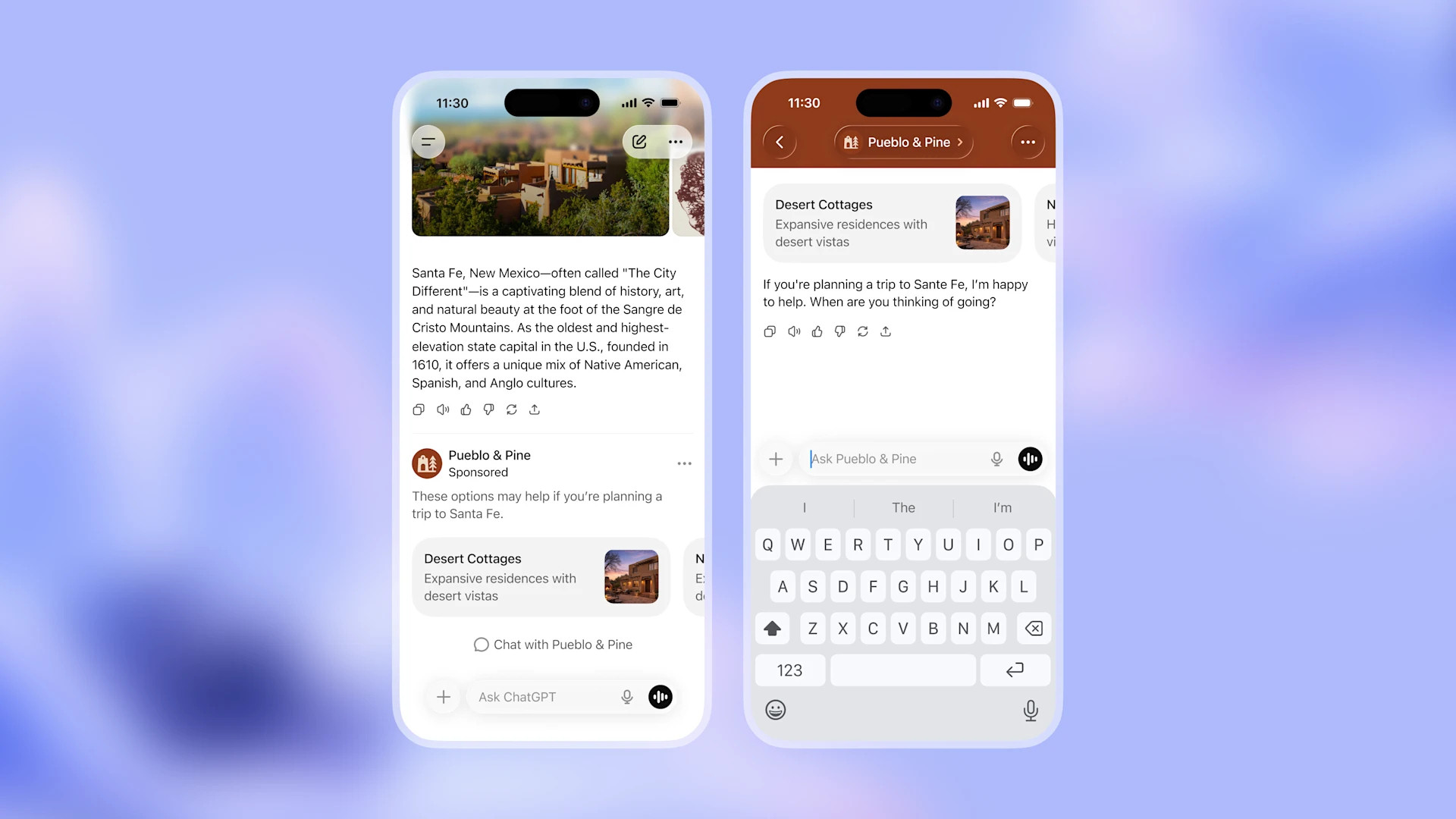
An example mock-up of an advertisement in ChatGPT provided by OpenAI.
An example mock-up of an advertisement in ChatGPT provided by OpenAI. Credit: OpenAI
Along those lines, OpenAI’s approach appears to be a compromise between needing ad revenue and not wanting sponsored content to appear directly within ChatGPT’s written responses. By placing banner ads at the bottom of answers separated from the conversation history, OpenAI appears to be addressing Altman’s concern: The AI assistant’s actual output, the company says, will remain uninfluenced by advertisers.
Indeed, Simo wrote in a blog post that OpenAI’s ads will not influence ChatGPT’s conversational responses and that the company will not share conversations with advertisers and will not show ads on sensitive topics such as mental health and politics to users it determines to be under 18.
“As we introduce ads, it’s crucial we preserve what makes ChatGPT valuable in the first place,” Simo wrote. “That means you need to trust that ChatGPT’s responses are driven by what’s objectively useful, never by advertising.”
OpenAI to test ads in ChatGPT as it burns through billions Read More »