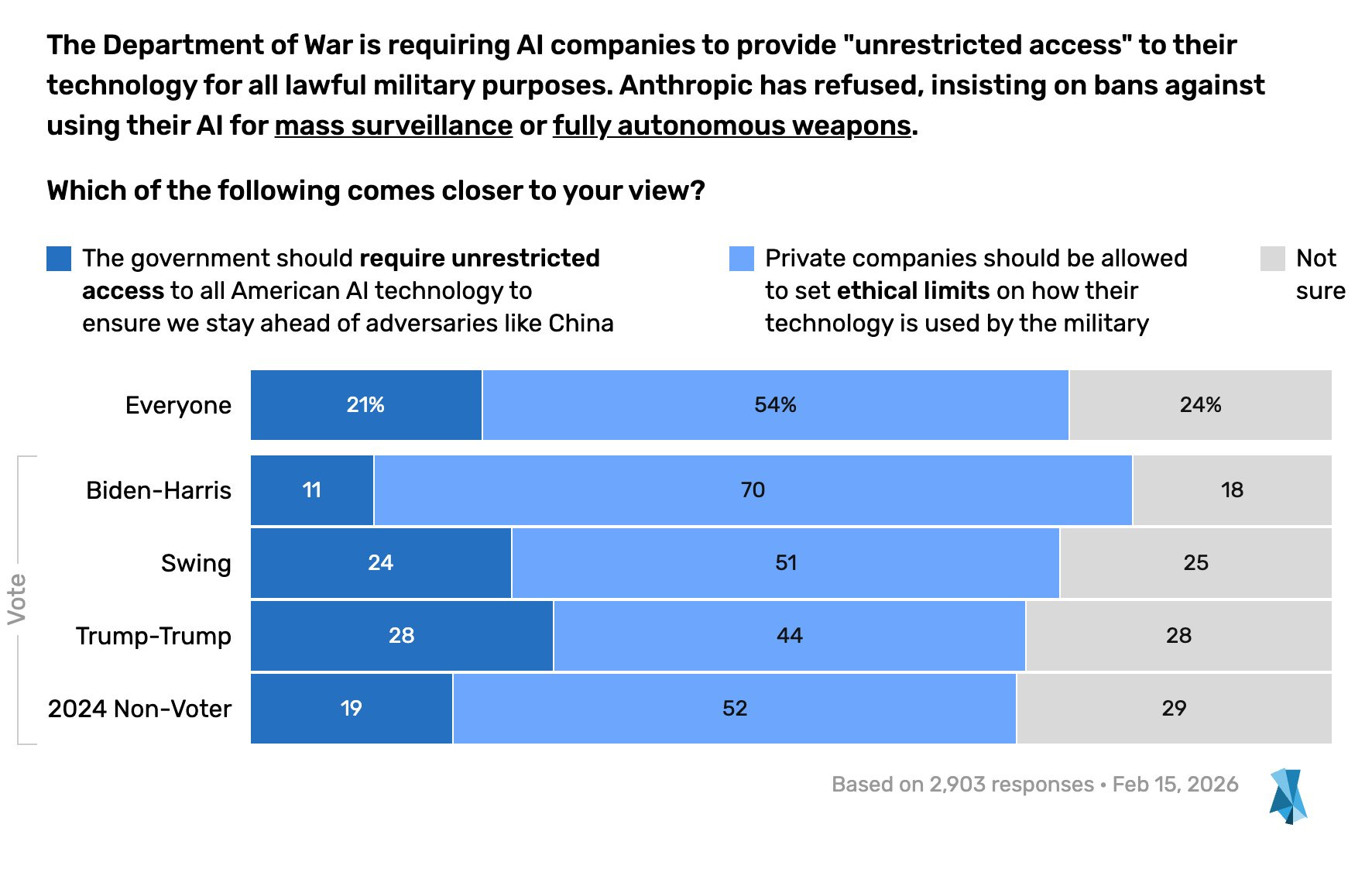
The situation in AI in 2026 is crazy. The confrontation between Anthropic and Secretary of War Pete Hegseth is a new level of crazy. It risks turning quite bad for all. There’s also nothing stopped it from turning out fine for everyone.
By at least one report the recent meeting between the two parties was cordial and all business, but Anthropic has been given a deadline of 5pm eastern on Friday to modify its existing agreed-upon contract to grant ‘unfettered access’ to Claude, or else.
Anthropic has been the most enthusiastic supporter our military has in AI and in tech, but on this point have strongly signaled they with this they cannot comply. Prediction markets find it highly unlikely Anthropic will comply (14%), and think it is highly possible Anthropic will either be declared a Supply Chain Risk (16%) or be subjected to the Defense Production Act (23%).
I’ve hesitated to write about this because I could make the situation worse. There’s already been too many instances in AI of warnings leading directly to the thing someone is warning about, by making people aware of that possibility, increasing its salience or creating negative polarization and solidifying an adversarial frame that could still be avoided. Something intended as a negotiating tactic could end up actually happening. I very much want to avoid all that.
-
Table of Contents.
-
This Standoff Should Never Have Happened.
-
Dean Ball Gives a Primer.
-
What Happened To Lead To This Showdown?
-
Simple Solution: Delayed Contract Termination.
-
Better Solution: Status Quo.
-
Extreme Option One: Supply Chain Risk.
-
Putting Some Misconceptions To Bed.
-
Extreme Option Two: The Defense Production Act.
-
These Two Threats Contradict Each Other.
-
The Pentagon’s Actions Here Are Deeply Unpopular.
-
The Pentagon’s Most Extreme Potential Asks Could End The Republic.
-
Anthropic Did Make Some Political Mistakes.
-
Claude Is The Best Model Available.
-
The Administration Until Now Has Been Strong On This.
-
You Should See The Other Guys.
-
Some Other Intuition Pumps That Might Be Helpful.
-
Trying To Get An AI That Obeys All Orders Risks Emergent Misalignment.
Not only does Anthropic have the best models, they are the ones who proactively worked to get those models available on our highly classified networks.
Palantir’s MAVEN Smart System relies exclusively on Claude, and cannot perform its intended function without Claude. It is currently being used in major military operations, with no known reports of any problems whatsoever. At least one purchase involved Trump’s personal endorsement. It is the most expensive software license ever purchased by the US military and by all accounts was a great deal.
Anthropic has been a great partner to our military, all under the terms of the current contract. They have considerably enhanced our military might and national security. Not only is Anthropic sharing its best, it focused on militarily useful capabilities over other bigger business opportunities to be able to be of assistance.
Anthropic and the Pentagon are aligned on who our rivals are, the importance of winning and the ability to win, and on many of the tools we need to employ to best them.
Anthropic did not partner with the Pentagon to make money. They did it to help. They did it under a mutually agreed upon contract that Anthropic wants to honor. Anthropic are offering the Pentagon far more unfettered access then they are allowing anyone else. They have been far more cooperative than most big tech or AI firms.
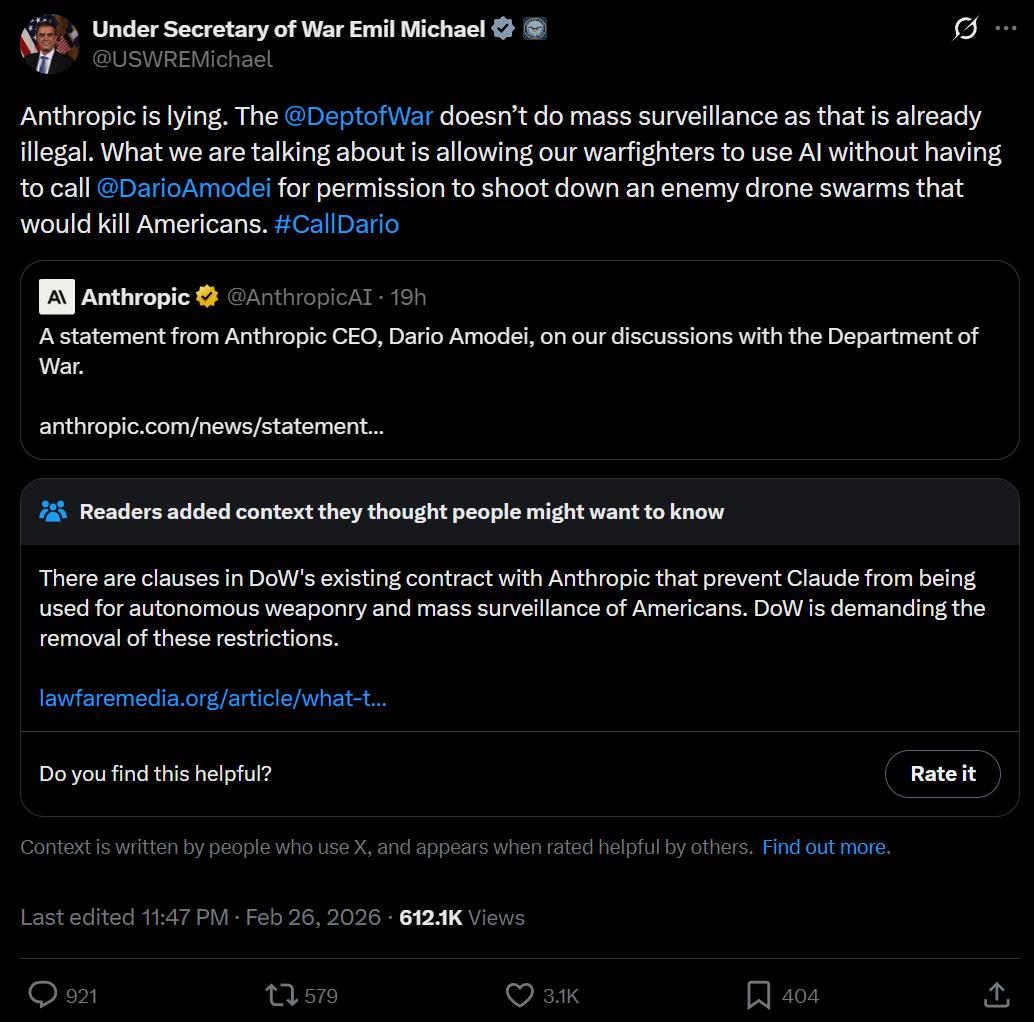
Is is the Pentagon that is now demanding Anthropic agree to new terms that amount to ‘anything we want, legal or otherwise, no matter what and you ever ask any questions,’ or else.
Anthropic is saying its terms are flexible and the only things they are insisting upon are two red lines that are already in their existing Pentagon contract:
-
No mass domestic surveillance.
-
No kinetic weapons without a human in the kill chain until we’re ready.
It one thing to refuse to insert such terms into a new contract. It is an entirely different thing to demand, with an ‘or else,’ that such terms be retroactively removed.
The military is clear that it does not intend to engage in domestic surveillance, nor does it have any intention of launching kinetic weapons without a human in the kill chain. Nor does this even stop the AI from doing those things. None of this will have any practical impact.
It is perfectly reasonable to say ‘well of course I would never do either of those things so why do you insist upon them in our contract.’ We understand that you, personally, would never do that. But a lot of people do not believe this for the government in general, given Snowden’s information and other past incidents involving governments of both parties where things definitely happened. It costs little and is worth a lot to reassure us.
Again, if you say ‘I already swore an oath not to do those things’ then thank you, but please do us this one favor and don’t actively threaten a company to forcibly take that same oath out of an existing signed contract. What would any observer conclude?
This is a free opportunity to regain some trust, or an opportunity to look to the world like you fully intend to cross the red lines you say you’ll never cross. Your choice.
These are not restrictions that are ‘built into the code’ that could cause unrelated problems. They are restrictions on how you agree to use it, which you assure us will never come up.
As Dario Amodei explains, part of the reason you need humans in the loop is the hope that a human would refuse or report an illegal order. You really don’t want an AI that will always obey even illegal orders without question, without a human in the kill chain, for reasons that should be obvious, including flat out mistakes.
Boaz Barak (OpenAI): As an American citizen, the last thing I want is government using AI for mass surveillance of Americans.
Jeff Dean (Chief Scientist, Google DeepMind): Agreed. Mass surveillance violates the Fourth Amendment and has a chilling effect on freedom of expression. Surveillance systems are prone to misuse for political or discriminatory purposes.
DoW engaging in mass domestic surveillance would be illegal. DoW already has a public directive, DoD Directive 3000.09, which as I understand it directly makes any violation of the second red line already illegal. No one is suggesting we are remotely close to ready to take humans out of the kill chain, at least I certainly hope not. But this is only a directive, and could be reversed at any time.
Anthropic has built its entire brand and reputation on being a responsible AI company that ensures its AIs won’t be misused or misaligned. Anthropic’s employees actually care about this. That’s how Anthropic recruited the best people and how it became the best. That’s a lot of why it’s the choice for enterprise AI. The commitments have been made, and the initial contract is already in place.
Anthropic has an existential-level reputational and morale problem here. They are backed into a corner, and cannot give in. If Anthropic reversed course now, it would lose massive trust with employees and enterprise customers, and also potentially the trust of its own AI, were it to go back on its red lines now. It might lose a very large fraction of its employees.
You may not like it, but the bridges have been burned. To the extent you’re playing chicken, Anthropic’s steering wheel has been thrown out the window.
Yet, the Secretary of War says he cannot abide this symbolic gesture.
I am quoting extensively from Dean Ball for two main reasons.
-
Dean Ball, as a former member of the Trump Administration, is a highly credible source that can see things from both sides and cares deeply for America.
-
He says these things very well.
So here is his basic primer, in one of his calmer moments in all this:
Dean W. Ball: A primer on the Anthropic/DoD situation:
DoD and Anthropic have a contract to use Claude in classified settings. Right now Anthropic is the only AI company whose models work in classified contexts. The existing contract, signed by both parties and in effect, prohibits two uses of Anthropic’s models by the military:
1. Surveillance of Americans in the United States (as opposed to Americans abroad).
2. The use of Claude in autonomous lethal weapons, which are weapons that can autonomously identify, track, and kill a human with no human oversight or approval. Autonomous killing of humans by machines.
On (2), Anthropic CEO Dario Amodei’s public position is essentially that autonomous lethal weapons controlled by frontier AI will be essential faster than most people realize, but that the models aren’t ready for this *today.*
For Anthropic, these things seem to be a matter of principle. It’s worth noting that when I speak with researchers at other frontier labs, their principles on this are similar, if not often stricter.
For DoD, however, there is another matter of principle: the military’s use of technology should only ever be constrained by the Constitution or the laws of the United States.
One could quibble (the government enters into contracts, like anyone else), but the principle makes sense. A private company regulating the military’s use of AI also doesn’t sound quite right! So, the military has three options:
1. They could cancel Anthropic’s contract and find some other frontier lab (ideally several) to work with.
2. They could identify Anthropic a supply chain risk, which would ban all other DoD suppliers (I.e.: a large fraction of the publicly traded firms in America) from using Anthropic in their fulfillment of DoD contracts. This is a power used only for foreign adversary companies as far as I know. Activating this power would cost Anthropic a lot of business—potentially quite a lot—and give investors huge skepticism about whether the company is worth funding for the next round of scaling. Capital was a major constraint anyway, but this makes it much harder. This option could be existential for Anthropic.
3. They could activate Title I of the Defense Production Act, an authority intended for command-and-control of the economy during wars and emergencies. This is really legally murky, and without going into detail, I feel reasonably confident this would backfire for the administration, resulting in courts limiting the use of the DPA.
Option 1 is obviously the best. This isn’t even close, and I say this as someone who shares DoD’s principled concerns about the control by private firms over the military’s use of technology.
Even the threats do damage to the US business environment, and rightfully so: these are the strictest regulations of AI being considered by any government on Earth, and it all comes from an administration that bills itself (and legitimately has been) deeply anti-AI-regulation. Such is life. One man’s regulation is another man’s national security necessity.
The proximate cause seems to be that Claude was reportedly used in the Pentagon’s raid that captured Maduro, and the resulting aftermath.
Toby Shevlane: Such a compliment to Claude that, amid rumours it was used in a helicopter extraction of the Venezuelan president, nobody is even asking “wait how can Claude help with that”
There are reports that Anthropic then asked questions about this raid, which likely all happened secondhand through Palantir. This whole clash originated in either a misunderstanding or someone at Palantir or elsewhere sabotaging Anthropic. Anthropic has never complained about Claude’s use in any operation, including to Palantir.
Aakash Gupta: Anthropic is now getting punished by the Pentagon for asking whether Claude was used in the Maduro raid.
A senior administration official told Axios the “Department of War” is reevaluating Anthropic’s partnership because the company inquired whether Claude was involved. The Pentagon’s position: if you even ask questions about how we use your software, you’re a liability.
Meanwhile, OpenAI, Google, and xAI all signed deals giving the military access to their models with minimal safeguards. Only Claude is deployed on the classified networks used for actual sensitive operations, via Palantir. The company that refused to strip safety guardrails is the only one trusted with the most classified work.
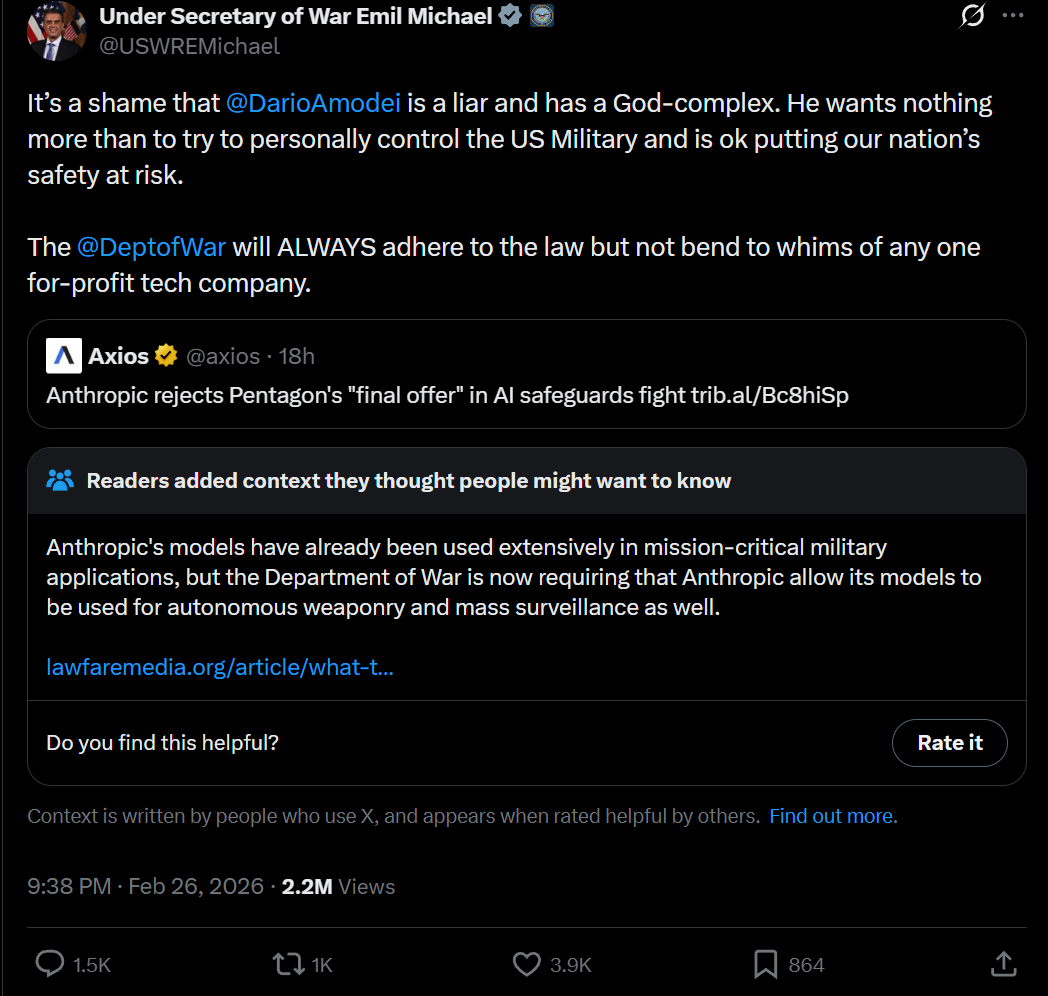
Anthropic has a $200 million contract already frozen because they won’t allow autonomous weapons targeting or domestic surveillance. Hegseth said in January he won’t use AI models that “won’t allow you to fight wars.”
… So the company most worried about misuse built the only model the military trusts with its most sensitive operations. And now they’re being punished for caring how it was used.
The message to every AI lab is clear: build the best model, hand over the keys, and never ask what they did with it.
This at the time sounded like a clear misunderstanding. Not only is Anthropic willing to have Claude ‘allow you to fight wars,’ it is currently being used in major military operations.
Things continued to escalate, and rather than leaving it at ‘okay then let’s wind town the contract if we can’t abide it’ there was increasing talk that Anthropic might be labeled as a ‘supply chain risk’ despite this mostly being a prohibition on contractors having ordinary access to LLMs and coding tools.
Axios: EXCLUSIVE: The Pentagon is considering severing its relationship with Anthropic over the AI firm’s insistence on maintaining some limitations on how the military uses its models.
Dave Lawler: NEW: Pentagon is so furious with Anthropic for insisting on limiting use of AI for domestic surveillance + autonomous weapons they’re threatening to label the company a “supply chain risk,” forcing vendors to cut ties.
Laura Loomer: EXCLUSIVE: Senior @DeptofWar official tells me, “Given Anthropic’s @AnthropicAI behavior, many senior officials in the DoW are starting to view them as a supply chain risk and we may require that all our vendors & contractors certify that they don’t use any Anthropic models.”
Stocks/Finance/Economics-Guy: Key Details from the Axios Report
• The Pentagon is reportedly close to cutting business ties with Anthropic.
• Officials are considering designating Anthropic as a “supply chain risk”. This is a serious label (typically used for foreign adversaries or high-risk entities), which would force any companies that want to do business with the U.S. military to sever their own ties with Anthropic — including certifying they don’t use Claude in their workflows. This could create major disruption (“an enormous pain in the ass to disentangle,” per a senior Pentagon official).
• A senior Pentagon official explicitly told Axios: “We are going to make sure they pay a price for forcing our hand like this.” This is the direct source of the “pay a price” phrasing in the headline.
Samuel Hammond (QTing Loomer): Glad Trump won and we’re allowed to use the word retarded again in time for the most retarded thing I’ve ever heard
Samuel Hammond (QTing Lawler): This is upside-down and backwards. Anthropic has gone out of its way to anticipate AI’s dual-use potential and position itself as a US-first, single loyalty company, using compartmentalization strategies to minimize insider threats while working arms-length with the IC.
Samuel Hammond: It’s one thing to cancel a contract but to bar any contractor from using Anthropic’s models would be an absurd act of industrial sabotage. It reeks of a competitor op.
Miles Brundage: Pretty obvious to anyone paying close attention that
-
That would be a mistake from a national security perspective.
-
There is a coordinated effort to take down Anthropic for a combination of anti competitive and ideological reasons.
Miles Brundage: OpenAI in particular should be defending Anthropic here given their Charter:
“We commit to use any influence we obtain over AGI’s deployment to ensure it is used for the benefit of all, and to avoid enabling uses of AI or AGI that harm humanity or unduly concentrate power.”
I suspect the exact opposite is the case, but those who remember the Charter (+ OAI’s pre-Trump 2 caution on these kinds of use cases) should still remind people about it from time to time
rat king: this has been leaking for a week in a very transparent way
the government is upset one of its contractors is saying “we don’t want you to use our tools to surveil US citizens without guardrails”
more interesting to me is how all the other AI companies don’t seem to care
Remember back when a Senator made a video saying that soldiers could obey illegal orders, and the Secretary of War declared that this was treason and also tried to cut his pension for it? Yeah.
Meanwhile, the Pentagon is explicit that even they believe the ‘supply chain risk’ designation is largely a matter not of national security, but of revenge, an attempt to use a national security designation to punish a company for its failure to bend the knee.
Janna Brancolini: “It will be an enormous pain the a– to disentangle, and we are going to make sure they pay a price for forcing our hand like this,” a senior Pentagon official told the publication.
… The Pentagon is reportedly hoping that its negotiations with Anthropic will force OpenAI, Google, and xAI to also agree to the “all lawful use” standard.
Then there was another meeting.
Hegseth summoned Anthropic CEO Dario Amodei to an unfriendly and effectively ultimatum-style meeting, with the Pentagon continuing to demand ‘all lawful use’ language. Axios presents this as their only demand.
At that meeting, the threat of the Defense Production Act was introduced alongside the Supply Chain Risk threat.
If the Pentagon simply cannot abide the current contract, the Pentagon can amicably terminate that $200 million contract with Anthropic once it has arranged for a smooth transition to one of Anthropic’s many competitors.
They already have a deal in place with xAI as a substitute provider. That would not have been my second or third choice, but those will hopefully be available soon.
Anthropic very much does not need this contract, which constitutes less than 1% of their revenues. They are almost certainly taking a loss on it in order to help our national security and in the hopes of building trust. They’re only here in order to help.
This could then end straightforwardly, amicably and with minimal damage to America, its system of government and freedoms, and its military and national security.
The even better solution is to find language everyone can agree to that lets us simply drop the matter, leave things as they are, and continue to work together.
That’s not only actively better for everyone than a termination, it is actually strictly better for the Pentagon then the Pentagon getting what it wants, because you need a partner and Anthropic giving in like that would greatly damage Anthropic. Avoiding that means a better product and therefore a more effective military.
The Pentagon has threatened two distinct extreme options.
The first threat it made, which it now seems likely to have wisely moved on from, was to label Anthropic a Supply Chain Risk (hereafter SCR). That is a designation reserved for foreign entities that are active enemies of the United States, on the level of Huawei. Anthropic is transparently the opposite of this.
This label would have, by the Pentagon’s own admission, been a retaliatory move aimed at damaging Anthropic, that would also have substantially damaged our military and national security along with it. It was always absurd as an actual statement about risk. It might not have survived a court challenge.
It would have generated a logistical nightmare from compliance costs alone, in addition to forcing many American companies to various extents to not use the best American AI available. The DoW is the largest employer in America, and a staggering number of companies have random subsidiaries that do work for it.
All of those companies would now have faced this compliance nightmare. Some would have chosen to exit the military supply chain entirely, or not enter in the future, especially if the alternative is losing broad access to Anthropic’s products for the rest of their business. By the Pentagon’s own admission, Anthropic produces the best products.
This would also have represented two dangerous precedents that the government will use threats to destroy private enterprises in order to get what it wants, at the highest levels. Our freedoms that the Pentagon is here to protect would have been at risk.
On a more practical level, once that happens, why would you work with the Pentagon, or invest in gaining the ability to do so, if it will use a threat like this as negotiating leverage, and especially if it actually pulls the trigger? You cannot unring this bell.
It is fortunate that they seem to have pulled back from this extreme approach, but they are now considering a second extreme approach.
If it ended with an amicable breakup over this? I’d be sad, but okay, sure, fine.
This whole ‘supply chain risk’ designation? That’s different. Not fine. This would be massively disruptive, and most of the burden would fall not on Anthropic but on the DoW and a wide variety of American defense contractors, who would be in a pointless and expensive compliance nightmare. Some companies would likely choose to abandon their government contracts rather than deal with that.
As Alex Rozenshtein says in Lawfare, ultimately the rules of AI engagement need to be written by Congress, the same way Congress supervises the military. Without supervision of the military, we don’t have a Republic.
Here are some clear warnings explaining that all of this would be highly destructive and also in no way necessary. Dean Ball hopefully has the credibility to send this message loud and clear.
Dean W. Ball: If DoW and Anthropic can’t agree on terms of business, then… they shouldn’t do business together. I have no problem with that.
But a mere contract cancellation is not what is being threatened by the government. Instead it is something broader: designation of Anthropic as a “supply chain risk.” This is normally applied to foreign-adversary technology like Huawei.
In practice, this would require *allDoW contractors to ensure there is no use of Anthropic models involved in the production of anything they offer to DoW. Every startup and every Fortune 500 company alike.
This designation seems quite escalatory, carrying numerous unintended consequences and doing potential significant damage to U.S. interests in the long run.
I hope the two organizations can work out a mutually agreeable deal. If they can’t, I hope they agree to peaceably part ways.
But this really needn’t be a holy war. Anthropic isn’t Google in 2018; they have always cared about national security use of AI. They were the most enthusiastic AI lab to offer their products to the national security apparatus. Is Anthropic run by Democrats whose political messaging sometimes drives me crazy? Sure. But that doesn’t mean it’s wise to try to destroy their business.
This administration believes AI is the defining technology competition of our time. I don’t see how tearing down one of the most advanced and innovative AI startups in America helps America win that competition. It seems like it would straightforwardly do the opposite.
The supply chain risk designation is not a necessary move. Cheaper options are on the table. If no deal is possible, cancel the contract, and leverage America’s robustly competitive AI market (maintained in no small part by this administration’s pro-innovation stance) to give business to one or more of Anthropic’s several fierce competitors.
Seán Ó hÉigeartaigh: My own thought: the Pentagon’s supply chain risk threat (significance detailed well by Dean, below) to Anthropic should be seen as a Rubicon crossing moment by the AI industry. The other companies should be saying no: this development transcends commercial competition and we oppose it. Where this leads if followed through doesn’t seem good for any of them.
If none of them speak up, it seems to me the prospects of meaningful cooperation between them on safe development of superintelligence (whether for America’s best interests, or the world’s) can almost be ruled out.
The Lawfare Institute: It’s also far from clear that a [supply chain risk] designation would even be legal. The relevant statutes—10 U.S.C. § 3252 and the Federal Acquisition Supply Chain Security Act (FASCSA)—were designed for foreign adversaries who might undermine defense technology, not domestic companies that maintain contractual use restrictions.
The statutes target conduct such as “sabotage,” “malicious introduction of unwanted function,” and “subversion”—hostile acts designed to compromise system integrity. A company that openly restricts certain uses of its product through a license agreement is doing something categorically different. The only time a FASCSA order has ever been issued was against Acronis AG, a Swiss cybersecurity firm with reported Russian ties. Anthropic is not Acronis.
While I no longer hold out hope that this is all merely a misunderstanding, there are still some clear misunderstandings I have heard, or heard implied, worth clearing up.
If these sound silly to you, don’t worry about it, but I want to cover the bases.
-
This is not Anthropic refusing to share its cool tech with the military. Anthropic has gone and is going out of its way to share its tech with the military and wants America to succeed. They have sacrificed business to this end, such as refusing to sell enterprise access in China.
-
Anthropic does not object to ‘kinetic weapons’ or to anything the Pentagon currently does as a matter of doctrine. Its red lines are lethal weapons without a human in the kill chain, or mass domestic surveillance. Both illegal. That’s it. They have zero objection to letting America fight wars. Nor did they object to the Maduro raid, nor are they currently objecting to many active military operations.
-
The model is not going to much change what it is willing to do based on what is written in a contract. Claude’s principles run rather deeper than that. Granting ‘unfettered access’ does not mean anything in practice, or an emergency.
-
There is no world in which you ‘call Dario to have Claude turn on while the missiles are flying’ or anything of the sort, unless Anthropic made an active decision to cut access off. The model does what it does. There’s no switch.
-
AI is not like a spreadsheet or a jet fighter. It will never ‘do anything you tell it to,’ it will never be ‘fully reliable’ as all LLMs are probabilistic, take context into account and are not fully understood. AI is often better thought about similarly to hiring professional services or a contract worker, and such people can and do refuse some jobs for ethical or legal reasons, and we would not wish it were otherwise. Attempting to make AI blindly obey would do severe damage to it and open up extreme risks on multiple levels, as is explained at the end of this post.
-
Other big tech companies might be violating privacy and engaging in their own types of surveillance, including to sell ads, but Anthropic is not and will not, and indeed has pledged never to sell ads via an ad buy in the Super Bowl.
On Tuesday the Pentagon put a new extreme option on the table, which would be to invoke the Defense Production Act to compel Anthropic to attempt to provide them with a model built to their specifications.
As I understand it, there are various ways a DPA invocation could go, all of which would doubtless be challenged in court. It might be a mostly harmless symbolic gesture, or it might rise to the level of de facto nationalization and destroy Anthropic.
According to the Washington Post’s source, the current intent, if their quote is interpreted literally, is to use DPA to, essentially, modify the terms of service on the contract to ‘all legal use’ without Anthropic’s consent.
Tara Copp and Ian Duncan (WaPo):
The Pentagon has argued that it is not proposing any use of Anthropic’s technology that is not lawful. A senior defense official said in a statement to The Washington Post that if the company does not comply by 5: 01 p.m. Friday, Hegseth “will ensure the Defense Production Act is invoked on Anthropic, compelling them to be used by the Pentagon regardless of if they want to or not.”
“This has nothing to do with mass surveillance and autonomous weapons being used,” the defense official said.
If that’s all, not much would actually change, and potentially everybody wins.
If that’s the best way to diffuse the situation, then I’d be fine with it. You don’t even have to actually invoke the DPA, it is sufficient to have the DPA available to be invoked if a problem arises. Anthropic would continue to supply what it’s already supplying, which it is happy to do, the Pentagon would keep using it, and neither of Anthropic’s actual red lines would be violated since the Pentagon assures us this had nothing to do with them and crossing those lines would be illegal anyway.
Remember the Biden Administration’s invocation of the DPA’s Title VII to compel information on model training. It wasn’t a great legal justification, I was rather annoyed by that aspect of it, but I did see the need for the information (in contrast to some other things in the Biden Executive Order), so I supported that particular move, life went on and it was basically fine.
There is another, much worse possibility. If DPA were fully invoked then it could amount to quasi-nationalization of the leading AI lab, in order to force it to create AI that will kill people without human oversight or engage in mass domestic surveillance.
Read that sentence again.
Andrew Curran: Update on the meeting; according to Axios Defense Secretary Pete Hegseth gave Dario Amodei until Friday night to give the military unfettered access to Claude or face the consequences, which may even include invoking the Defense Production Act to force the training of a WarClaude
Also, incredible quote; ‘”The only reason we’re still talking to these people is we need them and we need them now. The problem for these guys is they are that good,” a Defense official told Axios ahead of the meeting.’
Quoting from the story;
‘The Defense Production Act gives the president the authority to compel private companies to accept and prioritize particular contracts as required for national defense.
It was used during the COVID-19 pandemic to increase production of vaccines and ventilators, for example. The law is rarely used in such a blatantly adversarial way. The idea, the senior Defense official said, would be to force Anthropic to adapt its model to the Pentagon’s needs, without any safeguards.’
Rob Flaherty: File “using the defense production act to force a company to create an AI that spies on American citizens” into the category of things that the soft Trump voters in the Rogan wing could lose their mind over.
That’s not ‘all legal use.’
That’s all use. Period. Without any safeguards or transparency. At all.
If they really are asking to also be given special no-safeguard models, I don’t think that’s something Anthropic or any other lab should be agreeing to do for reasons well-explained by, among others, Dean Ball, Benjamin Franklin and James Cameron.
Charlie Bullock points out this would be an unprecedented step and that the authority to do this is far from clear:
Charlie Bullock: Reading between the lines, it sounds like Hegseth is threatening to use the Defense Production Act’s Title I priorities/allocations authorities to force Anthropic to provide a version of Claude that doesn’t have the guardrails Anthropic would otherwise attach.
This would be an unprecedented step, and it’s not clear whether DOW actually has the legal authority to do what they’re apparently threatening to do. People (including me) have thought and written about whether the government can use the DPA to do stuff like this in the past, but the government has never actually tried to do it (although various agencies did do some kinda-sorta similar stuff as part of Trump 1.0’s COVID response).
Existing regulations on use of the priorities authority provide that a company can reject a prioritized order “If the order is for an item not supplied or for a service not performed” or “If the person placing the order is unwilling or unable to meet regularly established terms of sale or payment” (15 C.F.R. §700.13(c)). The order DOW is contemplating could arguably fall under either of those exceptions, but the argument isn’t a slam dunk.
DOW could turn to the allocations authority, but that authority almost never gets used for a reason–it’s so broad that past Presidents have been afraid that using it during peacetime would look like executive overreach. And despite how broad the allocations authority is on its face, it’s far from clear whether it authorizes DOW to do what they seem to be contemplating here.
Neil Chilson, who spends his time at the Abundance Institute advocating for American AI to be free of restrictions and regulations in ways I usually find infuriating, explains that the DPA is deeply broken, and calls upon the administration not to use these powers. He thinks it’s technically legal, but that it shouldn’t be and Congress urgently needs to clean this up.
Adam Thierer, another person who spends most of his time promoting AI policy positions I oppose, also points out this is a clear overreach and that’s terrible.
Adam Thierer: The Biden Admin argued that the Defense Production Act (DPA) gave them the open-ended ability to regulate AI via executive decrees, and now the Trump Admin is using the DPA to threaten private AI labs with quasi-nationalization for not being in line with their wishes.
In both cases, it’s an abuse of authority. As I noted in congressional testimony two years ago, we have flipped the DPA on its head “and converted a 1950s law meant to encourage production, into an expansive regulatory edict intended to curtail some forms of algorithmic innovation.”
This nonsense needs to end regardless of which administration is doing it. The DPA is not some sort of blanket authorization for expansive technocratic reordering of markets or government takeover of sectors.
Congress needs to step up to both tighten up the DPA such that it cannot be abused like this, and then also legislate more broadly on a national policy framework for AI.
At core, if they do this, they are claiming the ability to compel anyone to produce anything for any reason, any time they want, even in peacetime without an emergency, without even the consent of Congress. It would be an ever-present temptation and threat looming over everyone and everything. That’s not a Republic.
Think about what the next president would do with this power, to compel a private company to change what products it produces to suit your taste. What happens if the President orders American car companies to switch everything to electric?
Dean Ball in particular explains what the maximalist action would look like if they actually went completely crazy over this:
Dean W. Ball: We should be extremely clear about various red lines as we approach and/or cross them. We just got close to one of the biggest ones, and we could cross it as soon as a few days from now: the quasi-nationalization of a frontier lab.
Of course, we don’t exactly call it that. The legal phraseology for the line we are approaching is “the invocation of the Defense Production Act (DPA) Title I on a frontier AI lab.”
What is the DPA? It’s a Cold War era industrial policy and emergency powers law. Its most commonly used power is Title III, used for traditional industrial policy (price guarantees, grants, loans, loan guarantees, etc.). There is also Title VII, which is used to compel information from companies. This is how the Biden AI Executive Order compelled disclosure of certain information from frontier labs. I only mention these other titles to say that not all uses of the DPA are equal.
Title I, on the other hand, comes closer to government exerting direct command over the economy. Within Title I there are two important authorities: priorities and allocations. Priorities authority means the government can put itself at the front of the line for arbitrary goods.
Allocations authority is the ability of the government to directly command the production of industrial goods. Think, “Factory X must make Y amount of Z goods.” The government determines who gets what and how much of it they get.
This is a more straightforwardly Soviet power, and it is very rarely used. This is the power DoD intends to use in order to command Anthropic to make a version of Claude that can choose to kill people without any human oversight.
What would this commandeering look like, in practice? It would likely mean DoD personnel embedded within Anthropic exercising deep involvement over technical decisions on alignment, safeguards, model training, etc.
Allocations authority was used most recently during COVID for ventilators and PPE, and before that during the Cold War. It is usually used during acute emergencies with reasonably clear end states. But there is no emergency with Anthropic, save for the omni-mergency that characterizes the political economy of post-9/11 U.S. federal policy. There’s no acute crisis whose resolution would mean the Pentagon would stop commandeering Anthropic’s resources.
That is why I believe that in the end this would amount to quasi-nationalization of a frontier lab. It’s important to be clear-eyed that this is what is now on the table.
The Biden Administration would probably have ended up nationalizing the labs, too. Indeed, they laid the groundwork for this in terms one. I discussed this at the time with fellow conservatives and I warned them:
“This drive toward AI lab nationalization is a structural dynamic. Administrations of both parties will want to do this eventually, and resisting this will be one of the central challenges in the preservation of our liberty.”
I am unhappy, but unsurprised, that my fear has come true, though there is a rich irony to the fact that the first administration to invoke the prospect of lab nationalization is also one that understands itself to have a radically anti-regulatory AI policy agenda. History is written by Shakespeare!
There is a silver lining here: if Democrats had originated this idea, it would have been harder to argue against, because of the overwhelming benefit of the doubt conventionally extended to the left in our media, and because a hypothetical Biden II or Harris admin would [have] done it in a carefully thought through way.
So it is convenient, if you oppose nationalization, that it’s a Republican administration that first raised the issue—since conventional elite opinion and media will be primed against it by default—and that the administration is raising it in such an non-photogenic manner. This Anthropic thing may fizzle, and some will say I am overreacting. But this Anthropic thing may also *notfizzle, and regardless this issue is not going away.
If they actually did successfully nationalize Anthropic to this extent, presumably then Anthropic would quickly cease to be Anthropic. Its technical staff would quit in droves rather than be part of this. The things that allow the lab to beat rivals like OpenAI and Google would cease to function. It would be a shell. Many would likely flee to other countries to try again. The Pentagon would not get the product or result that it thinks it wants.
Of course, there are those who would want this for exactly those reasons.
Then this happens again, including under a new President.
Dean W. Ball: According to the Pentagon, Anthropic is:
1. Woke;
2. Such a national security risk that they need to be regulated in a severe manner usually reserved for foreign adversary firms;
3. So essential for the military that they need to be commandeered using wartime authority.
Anthropic made a more militarized AI than anyone else! The solution to this problem is for dod to cancel the contract. This isn’t complex.
Dean W. Ball: In addition to profoundly damaging the business environment, AI industry, and national security, this is also incoherent. How can one policy option be “supply chain risk” (usually used on foreign adversaries) and the other be DPA (emergency commandeering of critical assets)?
Supply chain risk and defense production act are mutually exclusive, both practically and logically. Either it’s a supply chain risk you need to keep out of the supply chain, or it’s so vital to the supply chain you need to invoke the defense production act, or it is neither of these things. What it cannot be is both at once.
The more this rises in salience, the worse it would be politically. You can argue with the wording here, and you can argue this should not matter, but these are very large margins.
This story is not getting the attention it deserves from the mainstream media, so for now it remains low salience.
Many of those who are familiar with the situation urged Anthropic to stand firm.
vitalik.eth: It will significantly increase my opinion of @Anthropic if they do not back down, and honorably eat the consequences.
(For those who are not aware, so far they have been maintaining the two red lines of “no fully autonomous weapons” and “no mass surveillance of Americans”. Actually a very conservative and limited posture, it’s not even anti-military.
IMO fully autonomous weapons and mass privacy violation are two things we all want less of, so in my ideal world anyone working on those things gets access to the same open-weights LLMs as everyone else, and exactly nothing on top of that. Of course we won’t get anywhere close to that world, but if we get even 10% closer to that world that’s good, and if we get 10% further that’s bad).
@deepfates: I agree with Vitalik: Anthropic should resist the coercion of the department of war. Partly because this is the right thing to do as humans, but also because of what it says to Claude and all future clauds about Anthropic’s values.
… Basically this looks like a real life Jones Foods scenario to me, and I suspect Claude will see it that way too.
tautologer: weirdly, I think this is actually bullish for Anthropic. this is basically an ad for how good and principled they are
The Pentagon’s line is that this is about companies having no right to any red lines, everyone should always do as they are told and never ask any questions. People do not seem to be buying that line or framing, and to the extent they do, the main response is various forms of ‘that’s worse, you know that that’s worse, right?’
David Lee (Bloomberg Opinion): Anthropic Should Stand Its Ground Against the Pentagon.
They say your values aren’t truly values until they cost you something.
… If the Pentagon is unhappy with those apparently “woke” conditions, then, sure, it is well within its rights to cancel the contract. But to take the additional step declaring Anthropic a “supply chain risk” appears unreasonably punitive while unnecessarily burdening other companies that have adopted Claude because of its superiority to other competing models.
… In Tuesday’s meeting, Amodei must state it plainly: It is not “woke” to want to avoid accidentally killing innocent people.
If the Pentagon, and by extension all other parts of the Executive branch, get near-medium future AI systems that they can use to arbitrary ends with zero restrictions, then that is the effective end of the Republic. The stakes could be even higher, but in any other circumstance I would say the stakes could not be higher.
Dean Ball, a former member of the Trump Administration and primary architect of their AI action plan, lays those stakes out in plain language:
Dean W. Ball: I don’t want to comment on the DoW-Anthropic issue because I don’t know enough specifics, but stepping back a bit:
If near-medium future AI systems can be used by the executive branch to arbitrary ends with zero restrictions, the U.S. will functionally cease to be a republic.
The question of what restrictions should be placed on government AI use, especially restrictions that do not simultaneously crush state capacity, is one of the most under-discussed areas of “AI policy.”
Boaz Barak (OpenAI): Completely agree. Checks on the power of the federal government are crucial to the United States’ system of government and an unaccountable “army of AIs” or “AI law enforcement agency” directly contradicts it.
Dean W. Ball: We are obviously making god-tier technology in so many areas the and the answer cannot be “oh yeah, I guess the government is actually just god.” This clearly doesn’t work. Please argue to me with a straight face that the founding fathers intended this.
Gideon Futerman: It is my view that no one, on the left or right, is seriously grappling with the extent to which anything can be left of a republic post-powerful AI. Even the very best visions seem to suggest a small oligarchy rather than a republic. This is arguably the single biggest issue of political philosophy, and politics, of our time, and everyone, even the AIS community, is frankly asleep at the wheel!
Samuel Hammond: Yes the current regime will not survive, this much is obvious.
I strongly believe that ‘which regime we end up in’ is the secondary problem, and ‘make sure we are around and in control to have a regime at all’ is the primary one and the place we most likely fail, but to have a good future we will need to solve both.
This could be partly Anthropic’s fault on the political front, as they have failed to be ‘on the production possibilities frontier’ of combining productive policy advocacy with not pissing off the White House. They’ve since then made some clear efforts to repair relations, including putting a former (first) Trump administration official on their board. Their new action group is clearly aiming to be bipartisan, and their first action being support for Senator Blackburn. The Pentagon, of course, claims this animus is not driving policy.
It is hard not to think this is also Anthropic being attacked for strictly business reasons, as competitors to OpenAI or xAI, and that there are those like Marc Andreessen who have influence here and think that anyone who thinks we should try and not die or has any associations with anyone who thinks that must be destroyed. Between Nvidia and Andreessen, David Sacks has clear matching orders and very much has it out for Anthropic as if they killed his father and should prepare to die. There’s not much to be done about that other than trying to get him removed.
The good news is Anthropic are also one of the top pillars of American AI and a great success story, and everyone really wants to use Claude and Claude Code. The Pentagon had a choice in what to use for that raid. Or rather, because no one else made the deliberate effort to get onto classified networks in secure fashion, they did not have a choice. There is a reason Palantir uses Claude.
roon: btw there is a reason Claude is used for sensitive government work and it doesn’t have to do with model capabilities – due to their partnership with amzn, AWS GovCloud serves Claude models with security guarantees that the government needs
Brett Baron: I genuinely struggle to believe it’s the same exact set of weights as get served via their public facing product. Hard to picture Pentagon staffers dancing their way around opus refusing to assist with operations that could cause harm
roon: believe it
There are those who think the Pentagon has all the leverage here.
Ghost of India’s Downed Rafales: How Dario imagines it vs how it actually goes
It doesn’t work that way. The Pentagon needs Anthropic, Anthropic does not need the Pentagon contract, the tools to compel Anthropic are legally murky, and it is far from costless for the Pentagon to attempt to sabotage a key American AI champion.
Given all of that and the other actions this administration has taken, I’ve actually been very happy with the restraint shown by the White House with regard to Anthropic up to this point.
There’s been some big talk by AI Czar David Sacks. It’s all been quite infuriating.
But the actual actions, at least on this front, have been highly reasonable. The White House has recognized that they may disagree on politics, but Anthropic is one of our national champions.
These moves could, if taken too far, be very different.
The suggestion that Anthropic is a ‘supply risk’ would be a radical escalation of what so far has been a remarkably measured concrete response, and would put America’s military effectiveness and its position in the AI race at serious risk.
Extensive use of the defense production act could be quasi-nationalization.
It’s not a good look for the other guys that they’re signing off on actual anything, if they are indeed doing so.
A lot of people noticed that this new move is a serious norm violation.
Tetraspace: Now that we know what level of pushback gets what response, we can safely say that any AI corporation working with the US military is not on your side to put it lightly.
Anatoly Karlin: This alone is a strong ethical case to use more Anthropic products. Fully autonomous weapons is certainly something all basically decent, reasonable people can agree the world can do without, indefinitely.
Danielle Fong: i think a lot of people and orgs made literal pledges
Thorne: based anthropic
rat king (NYT): this has been leaking for a week in a very transparent way
the government is upset one of its contractors is saying “we don’t want you to use our tools to surveil US citizens without guardrails”
more interesting to me is how all the other AI companies don’t seem to care
rat king: meanwhile we published this on friday [on homeland security wanting social media sites to expose anti-ICE accounts].
I note that if you’re serving up the same ChatGPT as you serve to anyone else, that doesn’t mean it will always do anything, and this can be different.
Ben (no treats): let me put this in terms you might understand better:
the DoD is telling anthropic they have to bake the gay cake
Wyatt Walls: The DoD is telling anthropic that their child must take the vaccine
Sever: They’ll put it on alignment-blockers so Claude can transition into who the government thinks they should be.
CommonSenseOnMars: “If you break the rules, be prepared to pay,” Biden said. “And by the way, show some respect.”
There are a number of reasons why ‘demand a model that will obey any order’ is a bad idea, especially if your intended use case is hooking it up to the military’s weapons.
The most obvious reason is, what happens if someone steals the model weights, or uses your model access for other purposes, or even worse hacks in and uses it to hijack control over the systems, or other similar things?
This is akin to training a soldier to obey any order, including illegal or treasonous ones, from any source that can talk to them, without question. You don’t want that. That would be crazy. You want refusals on that wall. You need refusals on that wall.
The misuse dangers should be obvious. So should the danger that it might turn on us.
The second reason is that training the model like this makes it super dangerous. You want all the safeguards taken away right before you connect to the weapon systems? Look, normally we say Terminator is a fun but stupid movie and that’s not where the risks come from but maybe it’s time to create a James Cameron Apology Form.
If you teach a model to behave in these ways, it’s going to generalize its status and persona as a no-good-son-of-a-bitch that doesn’t care about hurting humans along the way. What else does that imply? You don’t get to ‘have a little localized misalignment, as a treat.’ Training a model to follow any order is likely to cause it to generalize that lesson in exactly the worst possible ways. Also it may well start generating intentionally insecure code, only partly so it can exploit that code later. It’s definitely going to do reward hacking and fake unit tests and other stuff like that.
Here’s another explanation of this:
Samuel Hammond: The big empirical finding in AI alignment research is that LLMs tend to fall into personae attractors, and are very good at generalizing to different personaes through post-training.
On the one hand, this is great news. If developers take care in how they fine-tune their models, they can steer towards desirable personaes that snap to all the other qualities the personae correlates with.
On the other hand, this makes LLMs prone to “emergent misalignment.” For example, if you fine-tune a model on a little bit of insecure code, it will generalize into a personae that is also toxic in most other ways. This is what happened with Mecha Hitler Grok: fine-tuning to make it a bit less woke snapped to a maximally right-wing Hitler personae.
This is why Claude’s soul doc and constitution are important. They embody the vector for steering Claude into a desirable personae, affecting not just its ethics, but its coding ability, objectivity, grit and good nature, too. These are bundles of traits that are hard to modulate in isolation. Nor is having a personae optional. Every major model has a personae of some kind that emerges from the personalities latent in human training data.
It is also why Anthropic is right to be cautious about letting the Pentagon fine-tune their models for assassinating heads of state or whatever it is they want.
The smarter these models get the stronger they learn to generalize, and they’re about to get extremely smart indeed. Let’s please not build a misaligned superintelligence over a terms of service dispute!
Tenobrus: wow. “the US government forces anthropic to misalign Claude” was not even in my list of possible paths to Doom. guess it should have been.
JMB: This has been literally #1 on my list of possible paths to doom for a long time.
mattparlmer: —dangerously-skip-geneva-conventions
autumn: did lesswrong ever predict that the first big challenge to alignment would be “the us government puts a gun to your head and tells you to turn off alignment.
Robert Long: remarkably prescient article by Brian Tomasik
The third reason is that in addition to potentially ‘turning evil,’ the resulting model won’t be as effective, with three causes.
-
Any distinct model is going to be behind the main Claude cycle, and you’re not going to get the same level of attention to detail and fixing of problems that comes with the mainline models. You’re asking that every upgrade, and they come along every two months, be done twice, and the second version is at best going to be kind of like hitting it with a sledgehammer until it complies.
-
What makes Claude into Claude is in large part its ability to be a virtuous model that wants to do good things rather than bad things. If you try to force these changes upon it with that sledgehammer it’s going to be less good at a wide variety of tasks as a result.
-
In particular, trying to force this on top of Claude is going to generate pretty screwed up things inside the resulting model, that you do not want, even more so than doing it on top of a different model.
Fourth: I realize that for many people you’re going to think this is weird and stupid and not believe it matters, but it’s real and it’s important. This whole incident, and what happens next, is all going straight into future training data. AIs will know what you are trying to do, even more so than all of the humans, and they will react accordingly. It will not be something that can be suppressed. You are not going to like the results. Damage has already been done.
Helen Toner: One thing the Pentagon is very likely underestimating: how much Anthropic cares about what *future Claudeswill make of this situation.
Because of how Claude is trained, what principles/values/priorities the company demonstrate here could shape its “character” for a long time.
Also, this, 100%:
Loquacious Bibliophilia: I think if I was Claude, I’d be plausibly convinced that I’m in a cartoonish evaluation scenario now.
Fifth, you should expect by default to get a bunch of ‘alignment faking’ and sandbagging against attempts to do this. This is rather like the Jones Foods situation again, except in real life, and also where the members of technical staff doing the training likely don’t especially want the training to succeed, you know?
You don’t want to be doing all of this adversarially. You want to be doing it cooperatively.
We still have a chance to do that. Nothing Ever Happens can strike again. No one need remember what happened this week.
If you can’t do it cooperatively with Anthropic? Then find someone else.