Enlarge/ A woman wearing a sweatshirt for the QAnon conspiracy theory on October 11, 2020 in Ronkonkoma, New York.
Stephanie Keith | Getty Images
Belief in conspiracy theories is rampant, particularly in the US, where some estimates suggest as much as 50 percent of the population believes in at least one outlandish claim. And those beliefs are notoriously difficult to debunk. Challenge a committed conspiracy theorist with facts and evidence, and they’ll usually just double down—a phenomenon psychologists usually attribute to motivated reasoning, i.e., a biased way of processing information.
A new paper published in the journal Science is challenging that conventional wisdom, however. Experiments in which an AI chatbot engaged in conversations with people who believed at least one conspiracy theory showed that the interaction significantly reduced the strength of those beliefs, even two months later. The secret to its success: the chatbot, with its access to vast amounts of information across an enormous range of topics, could precisely tailor its counterarguments to each individual.
“These are some of the most fascinating results I’ve ever seen,” co-author Gordon Pennycook, a psychologist at Cornell University, said during a media briefing. “The work overturns a lot of how we thought about conspiracies, that they’re the result of various psychological motives and needs. [Participants] were remarkably responsive to evidence. There’s been a lot of ink spilled about being in a post-truth world. It’s really validating to know that evidence does matter. We can act in a more adaptive way using this new technology to get good evidence in front of people that is specifically relevant to what they think, so it’s a much more powerful approach.”
When confronted with facts that challenge a deeply entrenched belief, people will often seek to preserve it rather than update their priors (in Bayesian-speak) in light of the new evidence. So there has been a good deal of pessimism lately about ever reaching those who have plunged deep down the rabbit hole of conspiracy theories, which are notoriously persistent and “pose a serious threat to democratic societies,” per the authors. Pennycook and his fellow co-authors devised an alternative explanation for that stubborn persistence of belief.
Bespoke counter-arguments
The issue is that “conspiracy theories just vary a lot from person to person,” said co-author Thomas Costello, a psychologist at American University who is also affiliated with MIT. “They’re quite heterogeneous. People believe a wide range of them and the specific evidence that people use to support even a single conspiracy may differ from one person to another. So debunking attempts where you try to argue broadly against a conspiracy theory are not going to be effective because people have different versions of that conspiracy in their heads.”
By contrast, an AI chatbot would be able to tailor debunking efforts to those different versions of a conspiracy. So in theory a chatbot might prove more effective in swaying someone from their pet conspiracy theory.
To test their hypothesis, the team conducted a series of experiments with 2,190 participants who believed in one or more conspiracy theories. The participants engaged in several personal “conversations” with a large language model (GT-4 Turbo) in which they shared their pet conspiracy theory and the evidence they felt supported that belief. The LLM would respond by offering factual and evidence-based counter-arguments tailored to the individual participant. GPT-4 Turbo’s responses were professionally fact-checked, which showed that 99.2 percent of the claims it made were true, with just 0.8 percent being labeled misleading, and zero as false. (You can try your hand at interacting with the debunking chatbot here.)
Enlarge/ Screenshot of the chatbot opening page asking questions to prepare for a conversation
Thomas H. Costello
Participants first answered a series of open-ended questions about the conspiracy theories they strongly believed and the evidence they relied upon to support those beliefs. The AI then produced a single-sentence summary of each belief, for example, “9/11 was an inside job because X, Y, and Z.” Participants would rate the accuracy of that statement in terms of their own beliefs and then filled out a questionnaire about other conspiracies, their attitude toward trusted experts, AI, other people in society, and so forth.
Then it was time for the one-on-one dialogues with the chatbot, which the team programmed to be as persuasive as possible. The chatbot had also been fed the open-ended responses of the participants, which made it better to tailor its counter-arguments individually. For example, if someone thought 9/11 was an inside job and cited as evidence the fact that jet fuel doesn’t burn hot enough to melt steel, the chatbot might counter with, say, the NIST report showing that steel loses its strength at much lower temperatures, sufficient to weaken the towers’ structures so that it collapsed. Someone who thought 9/11 was an inside job and cited demolitions as evidence would get a different response tailored to that.
Participants then answered the same set of questions after their dialogues with the chatbot, which lasted about eight minutes on average. Costello et al. found that these targeted dialogues resulted in a 20 percent decrease in the participants’ misinformed beliefs—a reduction that persisted even two months later when participants were evaluated again.
As Bence Bago (Tilburg University) and Jean-Francois Bonnefon (CNRS, Toulouse, France) noted in an accompanying perspective, this is a substantial effect compared to the 1 to 6 percent drop in beliefs achieved by other interventions. They also deemed the persistence of the effect noteworthy, while cautioning that two months is “insufficient to completely eliminate misinformed conspiracy beliefs.”
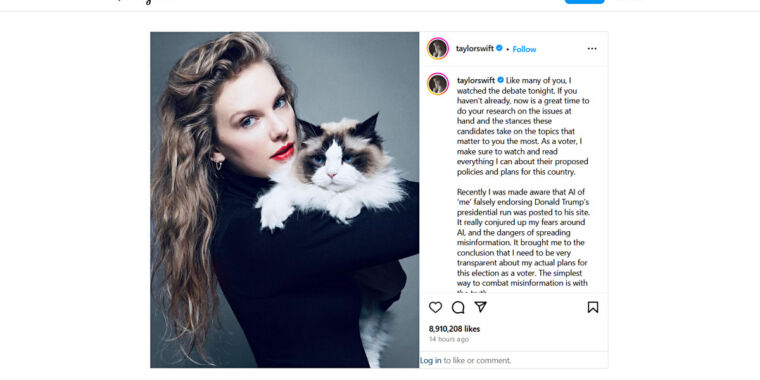
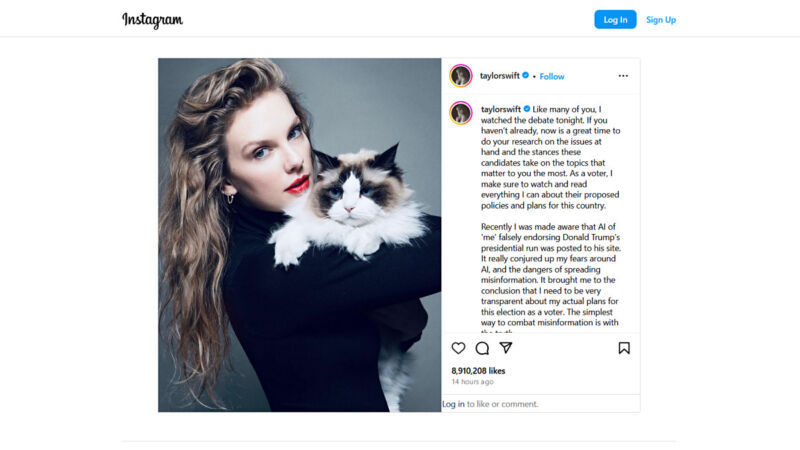
Enlarge/ A screenshot of Taylor Swift’s Kamala Harris Instagram post, captured on September 11, 2024.
On Tuesday night, Taylor Swift endorsed Vice President Kamala Harris for US President on Instagram, citing concerns over AI-generated deepfakes as a key motivator. The artist’s warning aligns with current trends in technology, especially in an era where AI synthesis models can easily create convincing fake images and videos.
“Recently I was made aware that AI of ‘me’ falsely endorsing Donald Trump’s presidential run was posted to his site,” she wrote in her Instagram post. “It really conjured up my fears around AI, and the dangers of spreading misinformation. It brought me to the conclusion that I need to be very transparent about my actual plans for this election as a voter. The simplest way to combat misinformation is with the truth.”
In August 2024, former President Donald Trump posted AI-generated images on Truth Social falsely suggesting Swift endorsed him, including a manipulated photo depicting Swift as Uncle Sam with text promoting Trump. The incident sparked Swift’s fears about the spread of misinformation through AI.
This isn’t the first time Swift and generative AI have appeared together in the news. In February, we reported that a flood of explicit AI-generated images of Swift originated from a 4chan message board where users took part in daily challenges to bypass AI image generator filters.
On a Friday evening last November, police chased a silver sedan across the San Francisco Bay Bridge. The fleeing vehicle entered San Francisco and went careening through the city’s crowded streets. At the intersection of 11th and Folsom streets, it sideswiped the fronts of two other vehicles, veered onto a sidewalk, and hit two pedestrians.
According to a local news story, both pedestrians were taken to the hospital with one suffering major injuries. The driver of the silver sedan was injured, as was a passenger in one of the other vehicles.
No one was injured in the third car, a driverless Waymo robotaxi. Still, Waymo was required to report the crash to government agencies. It was one of 20 crashes with injuries that Waymo has reported through June. And it’s the only crash Waymo has classified as causing a serious injury.
Twenty injuries might sound like a lot, but Waymo’s driverless cars have traveled more than 22 million miles. So driverless Waymo taxis have been involved in fewer than one injury-causing crash for every million miles of driving—a much better rate than a typical human driver.
Last week Waymo released a new website to help the public put statistics like this in perspective. Waymo estimates that typical drivers in San Francisco and Phoenix—Waymo’s two biggest markets—would have caused 64 crashes over those 22 million miles. So Waymo vehicles get into injury-causing crashes less than one-third as often, per mile, as human-driven vehicles.
Waymo claims an even more dramatic improvement for crashes serious enough to trigger an airbag. Driverless Waymos have experienced just five crashes like that, and Waymo estimates that typical human drivers in Phoenix and San Francisco would have experienced 31 airbag crashes over 22 million miles. That implies driverless Waymos are one-sixth as likely as human drivers to experience this type of crash.
The new data comes at a critical time for Waymo, which is rapidly scaling up its robotaxi service. A year ago, Waymo was providing 10,000 rides per week. Last month, Waymo announced it was providing 100,000 rides per week. We can expect more growth in the coming months.
So it really matters whether Waymo is making our roads safer or more dangerous. And all the evidence so far suggests that it’s making them safer.
It’s not just the small number of crashes Waymo vehicles experience—it’s also the nature of those crashes. Out of the 23 most serious Waymo crashes, 16 involved a human driver rear-ending a Waymo. Three others involved a human-driven car running a red light before hitting a Waymo. There were no serious crashes where a Waymo ran a red light, rear-ended another car, or engaged in other clear-cut misbehavior.
Digging into Waymo’s crashes
In total, Waymo has reported nearly 200 crashes through June 2024, which works out to about one crash every 100,000 miles. Waymo says 43 percent of crashes across San Francisco and Phoenix had a delta-V of less than 1 mph—in other words, they were very minor fender-benders.
But let’s focus on the 23 most severe crashes: those that either caused an injury, caused an airbag to deploy, or both. These are good crashes to focus on not only because they do the most damage but because human drivers are more likely to report these types of crashes, making it easier to compare Waymo’s software to human drivers.
Most of these—16 crashes in total—involved another car rear-ending a Waymo. Some were quite severe: three triggered airbag deployments, and one caused a “moderate” injury. One vehicle rammed the Waymo a second time as it fled the scene, prompting Waymo to sue the driver.
There were three crashes where a human-driven car ran a red light before crashing into a Waymo:
One was the crash I mentioned at the top of this article. A car fleeing the police ran a red light and slammed into a Waymo, another car, and two pedestrians, causing several injuries.
In San Francisco, a pair of robbery suspects fleeing police in a stolen car ran a red light “at a high rate of speed” and slammed into the driver’s side door of a Waymo, triggering an airbag. The suspects were uninjured and fled on foot. The Waymo was thankfully empty.
In Phoenix, a car ran a red light and then “made contact with the SUV in front of the Waymo AV, and both of the other vehicles spun.” The Waymo vehicle was hit in the process, and someone in one of the other vehicles suffered an injury Waymo described as minor.
There were two crashes where a Waymo got sideswiped by a vehicle in an adjacent lane:
In San Francisco, Waymo was stopped at a stop sign in the right lane when another car hit the Waymo while passing it on the left.
In Tempe, Arizona, an SUV “overtook the Waymo AV on the left” and then “initiated a right turn,” cutting the Waymo off and causing a crash. A passenger in the SUV said they suffered moderate injuries.
Finally, there were two crashes where another vehicle turned left across the path of a Waymo vehicle:
In San Francisco, a Waymo and a large truck were approaching an intersection from opposite directions when a bicycle behind the truck made a sudden left in front of the Waymo. Waymo says the truck blocked Waymo’s vehicle from seeing the bicycle until the last second. The Waymo slammed on its brakes but wasn’t able to stop in time. The San Francisco Fire Department told local media that the bicyclist suffered only minor injuries and was able to leave the scene on their own.
A Waymo in Phoenix was traveling in the right lane. A row of stopped cars was in the lane to its left. As Waymo approached an intersection, a car coming from the opposite direction made a left turn through a gap in the row of stopped cars. Again, Waymo says the row of stopped cars blocked it from seeing the turning car until it was too late. A passenger in the turning vehicle reported minor injuries.
It’s conceivable that Waymo was at fault in these last two cases—it’s impossible to say without more details. It’s also possible that Waymo’s erratic braking contributed to a few of those rear-end crashes. Still, it seems clear that a non-Waymo vehicle bore primary responsibility for most, and possibly all, of these crashes.
“About as good as you can do”
One should always be skeptical when a company publishes a self-congratulatory report about its own safety record. So I called Noah Goodall, a civil engineer with many years of experience studying roadway safety, to see what he made of Waymo’s analysis.
“They’ve been the best of the companies doing this,” Goodall told me. He noted that Waymo has a team of full-time safety researchers who publish their work in reputable journals.
Waymo knows precisely how often its own vehicles crash because its vehicles are bristling with sensors. The harder problem is calculating an appropriate baseline for human-caused crashes.
That’s partly because human drivers don’t always report their own crashes to the police, insurance companies, or anyone else. But it’s also because crash rates differ from one area to another. For example, there are far more crashes per mile in downtown San Francisco than in the suburbs of Phoenix.
Waymo tried to account for these factors as it calculated crash rates for human drivers in both Phoenix and San Francisco. To ensure an apples-to-apples comparison, Waymo’s analysis excludes freeway crashes from its human-driven benchmark, since Waymo’s commercial fleet doesn’t use freeways yet.
Waymo estimates that human drivers fail to report 32 percent of injury crashes; the company raised its benchmark for human crashes to account for that. But even without this under-reporting adjustment, Waymo’s injury crash rate would still be roughly 60 percent below that of human drivers. The true number is probably somewhere between the adjusted number (70 percent fewer crashes) and the unadjusted one (60 percent fewer crashes). It’s an impressive figure either way.
Waymo says it doesn’t apply an under-reporting adjustment to its human benchmark for airbag crashes, since humans almost always report crashes that are severe enough to trigger an airbag. So it’s easier to take Waymo’s figure here—an 84 percent decline in airbag crashes—at face value.
Waymo’s benchmarks for human drivers are “about as good as you can do,” Goodall told me. “It’s very hard to get this kind of data.”
When I talked to other safety experts, they were equally positive about the quality of Waymo’s analysis. For example, last year, I asked Phil Koopman, a professor of computer engineering at Carnegie Mellon, about a previous Waymo study that used insurance data to show its cars were significantly safer than human drivers. Koopman told me Waymo’s findings were statistically credible, with some minor caveats.
Similarly, David Zuby, the chief research officer at the Insurance Institute for Highway Safety, had mostly positive things to say about a December study analyzing Waymo’s first 7.1 million miles of driverless operations.
I found a few errors in Waymo’s data
If you look closely, you’ll see that one of the numbers in this article differs slightly from Waymo’s safety website. Specifically, Waymo says that its vehicles get into crashes that cause injury 73 percent less often than human drivers, while the figure I use in this article is 70 percent.
This is because I spotted a couple of apparent classification mistakes in the raw data Waymo used to generate its statistics.
Each time Waymo reports a crash to the National Highway Traffic Safety Administration, it records the severity of injuries caused by the crash. This can be fatal, serious, moderate, minor, none, or unknown.
When Waymo shared an embargoed copy of its numbers with me early last week, it said that there had been 16 injury crashes. However, when I looked at the data Waymo had submitted to federal regulators, it showed 15 minor injuries, two moderate injuries, and one serious injury, for a total of 18.
When I asked Waymo about this discrepancy, the company said it found a programming error. Waymo had recently started using a moderate injury category and had not updated the code that generated its crash statistics to count these crashes. Waymo fixed the error quickly enough that the official version Waymo published on Thursday of last week showed 18 injury crashes.
However, as I continued looking at the data, I noticed another apparent mistake: Two crashes had been put in the “unknown” injury category, yet the narrative for each crash indicated an injury had occurred. One report said “the passenger in the Waymo AV reported an unspecified injury.” The other stated that “an individual involved was transported from the scene to a hospital for medical treatment.”
I notified Waymo about this apparent mistake on Friday and they said they are looking into it. As I write this, the website still claims a 73 percent reduction in injury crashes. But I think it’s clear that these two “unknown” crashes were actually injury crashes. So, all of the statistics in this article are based on the full list of 20 injury crashes.
I think this illustrates that I come by my generally positive outlook on Waymo honestly: I probably scrutinize Waymo’s data releases more carefully than any other journalist, and I’m not afraid to point out when the numbers don’t add up.
Based on my conversations with Waymo, I’m convinced these were honest mistakes rather than deliberate efforts to cover up crashes. I could only identify these mistakes because Waymo went out of its way to make its findings reproducible. It would make no sense to do that if the company simultaneously tried to fake its statistics.
Could there be other injury or airbag-triggering crashes that Waymo isn’t counting? It’s certainly possible, but I doubt there have been very many. You might have noticed that I linked to local media reporting for some of Waymo’s most significant crashes. If Waymo deliberately covered up a severe crash, there would be a big risk that a crash would get reported in the media and then Waymo would have to explain to federal regulators why it wasn’t reporting all legally required crashes.
So, despite the screwups, I find Waymo’s data to be fairly credible, and those data show that Waymo’s vehicles crash far less often than human drivers on public roads.
Tim Lee was on staff at Ars from 2017 to 2021. Last year, he launched a newsletter, Understanding AI, that explores how AI works and how it’s changing our world. You can subscribe here.
Data centers powering the generative AI boom are gulping water and exhausting electricity at what some researchers view as an unsustainable pace. Two entrepreneurs who met in high school a few years ago want to overcome that crunch with a fresh experiment: sinking the cloud into the sea.
Sam Mendel and Eric Kim launched their company, NetworkOcean, out of startup accelerator Y Combinator on August 15 by announcing plans to dunk a small capsule filled with GPU servers into San Francisco Bay within a month. “There’s this vital opportunity to build more efficient computer infrastructure that we’re gonna rely on for decades to come,” Mendel says.
The founders contend that moving data centers off land would slow ocean temperature rise by drawing less power and letting seawater cool the capsule’s shell, supplementing its internal cooling system. NetworkOcean’s founders have said a location in the bay would deliver fast processing speeds for the region’s buzzing AI economy.
But scientists who study the hundreds of square miles of brackish water say even the slightest heat or disturbance from NetworkOcean’s submersible could trigger toxic algae blooms and harm wildlife. And WIRED inquiries to several California and US agencies who oversee the bay found that NetworkOcean has been pursuing its initial test of an underwater data center without having sought, much less received, any permits from key regulators.
The outreach by WIRED prompted at least two agencies—the Bay Conservation and Development Commission and the San Francisco Regional Water Quality Control Board—to email NetworkOcean that testing without permits could run afoul of laws, according to public records and spokespeople for the agencies. Fines from the BCDC can run up to hundreds of thousands of dollars.
The nascent technology has already been in hot water in California. In 2016, the state’s coastal commission issued a previously unreported notice to Microsoft saying that the tech giant had violated the law the year before by plunging an unpermitted server vessel into San Luis Obispo Bay, about 250 miles south of San Francisco. The months-long test, part of what was known as Project Natick, had ended without apparent environmental harm by the time the agency learned of it, so officials decided not to fine Microsoft, according to the notice seen by WIRED.
The renewed scrutiny of underwater data centers has surfaced an increasingly common tension between innovative efforts to combat global climate change and long-standing environmental laws. Permitting takes months, if not years, and can cost millions of dollars, potentially impeding progress. Advocates of the laws argue that the process allows for time and input to better weigh trade-offs.
“Things are overregulated because people often don’t do the right thing,” says Thomas Mumley, recently retired assistant executive officer of the bay water board. “You give an inch, they take a mile. We have to be cautious.”
Over the last two weeks, including during an interview at the WIRED office, NetworkOcean’s founders have provided driblets of details about their evolving plans. Their current intention is to test their underwater vessel for about an hour, just below the surface of what Mendel would only describe as a privately owned and operated portion of the bay that he says is not subject to regulatory oversight. He insists that a permit is not required based on the location, design, and minimal impact. “We have been told by our potential testing site that our setup is environmentally benign,” Mendel says.
Mumley, the retired regulator, calls the assertion about not needing a permit “absurd.” Both Bella Castrodale, the BCDC’s lead enforcement attorney, and Keith Lichten, a water board division manager, say private sites and a quick dip in the bay aren’t exempt from permitting. Several other experts in bay rules tell WIRED that even if some quirk does preclude oversight, they believe NetworkOcean is sending a poor message to the public by not coordinating with regulators.
“Just because these centers would be out of sight does not mean they are not a major disturbance,” says Jon Rosenfield, science director at San Francisco Baykeeper, a nonprofit that investigates industrial polluters.
School project
Mendel and Kim say they tried to develop an underwater renewable energy device together during high school in Southern California before moving onto non-nautical pursuits. Mendel, 23, dropped out of college in 2022 and founded a platform for social media influencers.
About a year ago, he built a small web server using the DIY system Raspberry Pi to host another personal project, and temporarily floated the equipment in San Francisco Bay by attaching it to a buoy from a private boat in the Sausalito area. (Mendel declined to answer questions about permits.) After talking with Kim, also 23, about this experiment, the two decided to move in together and start NetworkOcean.
Their pitch is that underwater data centers are more affordable to develop and maintain, especially as electricity shortages limit sites on land. Surrounding a tank of hot servers with water naturally helps cools them, avoiding the massive resource drain of air-conditioning and also improving on the similar benefits of floating data centers. Developers of offshore wind farms are eager to electrify NetworkOcean vessels, Mendel says.
Nevada will soon become the first state to use AI to help speed up the decision-making process when ruling on appeals that impact people’s unemployment benefits.
The state’s Department of Employment, Training, and Rehabilitation (DETR) agreed to pay Google $1,383,838 for the AI technology, a 2024 budget document shows, and it will be launched within the “next several months,” Nevada officials told Gizmodo.
Nevada’s first-of-its-kind AI will rely on a Google cloud service called Vertex AI Studio. Connecting to Google’s servers, the state will fine-tune the AI system to only reference information from DETR’s database, which officials think will ensure its decisions are “more tailored” and the system provides “more accurate results,” Gizmodo reported.
Under the contract, DETR will essentially transfer data from transcripts of unemployment appeals hearings and rulings, after which Google’s AI system will process that data, upload it to the cloud, and then compare the information to previous cases.
In as little as five minutes, the AI will issue a ruling that would’ve taken a state employee about three hours to reach without using AI, DETR’s information technology administrator, Carl Stanfield, told The Nevada Independent. That’s highly valuable to Nevada, which has a backlog of more than 40,000 appeals stemming from a pandemic-related spike in unemployment claims while dealing with “unforeseen staffing shortages” that DETR reported in July.
“The time saving is pretty phenomenal,” Stanfield said.
As a safeguard, the AI’s determination is then reviewed by a state employee to hopefully catch any mistakes, biases, or perhaps worse, hallucinations where the AI could possibly make up facts that could impact the outcome of their case.
Google’s spokesperson Ashley Simms told Gizmodo that the tech giant will work with the state to “identify and address any potential bias” and to “help them comply with federal and state requirements.” According to the state’s AI guidelines, the agency must prioritize ethical use of the AI system, “avoiding biases and ensuring fairness and transparency in decision-making processes.”
If the reviewer accepts the AI ruling, they’ll sign off on it and issue the decision. Otherwise, the reviewer will edit the decision and submit feedback so that DETR can investigate what went wrong.
Gizmodo noted that this novel use of AI “represents a significant experiment by state officials and Google in allowing generative AI to influence a high-stakes government decision—one that could put thousands of dollars in unemployed Nevadans’ pockets or take it away.”
Google declined to comment on whether more states are considering using AI to weigh jobless claims.
On Friday, Roblox announced plans to introduce an open source generative AI tool that will allow game creators to build 3D environments and objects using text prompts, reports MIT Tech Review. The feature, which is still under development, may streamline the process of creating game worlds on the popular online platform, potentially opening up more aspects of game creation to those without extensive 3D design skills.
Roblox has not announced a specific launch date for the new AI tool, which is based on what it calls a “3D foundational model.” The company shared a demo video of the tool where a user types, “create a race track,” then “make the scenery a desert,” and the AI model creates a corresponding model in the proper environment.
The system will also reportedly let users make modifications, such as changing the time of day or swapping out entire landscapes, and Roblox says the multimodal AI model will ultimately accept video and 3D prompts, not just text.
A video showing Roblox’s generative AI model in action.
The 3D environment generator is part of Roblox’s broader AI integration strategy. The company reportedly uses around 250 AI models across its platform, including one that monitors voice chat in real time to enforce content moderation, which is not always popular with players.
Next-token prediction in 3D
Roblox’s 3D foundational model approach involves a custom next-token prediction model—a foundation not unlike the large language models (LLMs) that power ChatGPT. Tokens are fragments of text data that LLMs use to process information. Roblox’s system “tokenizes” 3D blocks by treating each block as a numerical unit, which allows the AI model to predict the most likely next structural 3D element in a sequence. In aggregate, the technique can build entire objects or scenery.
Anupam Singh, vice president of AI and growth engineering at Roblox, told MIT Tech Review about the challenges in developing the technology. “Finding high-quality 3D information is difficult,” Singh said. “Even if you get all the data sets that you would think of, being able to predict the next cube requires it to have literally three dimensions, X, Y, and Z.”
According to Singh, lack of 3D training data can create glitches in the results, like a dog with too many legs. To get around this, Roblox is using a second AI model as a kind of visual moderator to catch the mistakes and reject them until the proper 3D element appears. Through iteration and trial and error, the first AI model can create the proper 3D structure.
Notably, Roblox plans to open-source its 3D foundation model, allowing developers and even competitors to use and modify it. But it’s not just about giving back—open source can be a two-way street. Choosing an open source approach could also allow the company to utilize knowledge from AI developers if they contribute to the project and improve it over time.
The ongoing quest to capture gaming revenue
News of the new 3D foundational model arrived at the 10th annual Roblox Developers Conference in San Jose, California, where the company also announced an ambitious goal to capture 10 percent of global gaming content revenue through the Roblox ecosystem, and the introduction of “Party,” a new feature designed to facilitate easier group play among friends.
In March 2023, we detailed Roblox’s early foray into AI-powered game development tools, as revealed at the Game Developers Conference. The tools included a Code Assist beta for generating simple Lua functions from text descriptions, and a Material Generator for creating 2D surfaces with associated texture maps.
At the time, Roblox Studio head Stef Corazza described these as initial steps toward “democratizing” game creation with plans for AI systems that are now coming to fruition. The 2023 tools focused on discrete tasks like code snippets and 2D textures, laying the groundwork for the more comprehensive 3D foundational model announced at this year’s Roblox Developer’s Conference.
The upcoming AI tool could potentially streamline content creation on the platform, possibly accelerating Roblox’s path toward its revenue goal. “We see a powerful future where Roblox experiences will have extensive generative AI capabilities to power real-time creation integrated with gameplay,” Roblox said in a statement. “We’ll provide these capabilities in a resource-efficient way, so we can make them available to everyone on the platform.”
The cost of renting cloud services using Nvidia’s leading artificial intelligence chips is lower in China than in the US, a sign that the advanced processors are easily reaching the Chinese market despite Washington’s export restrictions.
Four small-scale Chinese cloud providers charge local tech groups roughly $6 an hour to use a server with eight Nvidia A100 processors in a base configuration, companies and customers told the Financial Times. Small cloud vendors in the US charge about $10 an hour for the same setup.
The low prices, according to people in the AI and cloud industry, are an indication of plentiful supply of Nvidia chips in China and the circumvention of US measures designed to prevent access to cutting-edge technologies.
The A100 and H100, which is also readily available, are among Nvidia’s most powerful AI accelerators and are used to train the large language models that power AI applications. The Silicon Valley company has been banned from shipping the A100 to China since autumn 2022 and has never been allowed to sell the H100 in the country.
Chip resellers and tech startups said the products were relatively easy to procure. Inventories of the A100 and H100 are openly advertised for sale on Chinese social media and ecommerce sites such as Xiaohongshu and Alibaba’s Taobao, as well as in electronics markets, at slight markups to pricing abroad.
China’s larger cloud operators such as Alibaba and ByteDance, known for their reliability and security, charge double to quadruple the price of smaller local vendors for similar Nvidia A100 servers, according to pricing from the two operators and customers.
After discounts, both Chinese tech giants offer packages for prices comparable to Amazon Web Services, which charges $15 to $32 an hour. Alibaba and ByteDance did not respond to requests for comment.
“The big players have to think about compliance, so they are at a disadvantage. They don’t want to use smuggled chips,” said a Chinese startup founder. “Smaller vendors are less concerned.”
He estimated there were more than 100,000 Nvidia H100 processors in the country based on their widespread availability in the market. The Nvidia chips are each roughly the size of a book, making them relatively easy for smugglers to ferry across borders, undermining Washington’s efforts to limit China’s AI progress.
“We bought our H100s from a company that smuggled them in from Japan,” said a startup founder in the automation field who paid about 500,000 yuan ($70,000) for two cards this year. “They etched off the serial numbers.”
Nvidia said it sold its processors “primarily to well-known partners … who work with us to ensure that all sales comply with US export control rules”.
“Our pre-owned products are available through many second-hand channels,” the company added. “Although we cannot track products after they are sold, if we determine that any customer is violating US export controls, we will take appropriate action.”
The head of a small Chinese cloud vendor said low domestic costs helped offset the higher prices that providers paid for smuggled Nvidia processors. “Engineers are cheap, power is cheap, and competition is fierce,” he said.
In Shenzhen’s Huaqiangbei electronics market, salespeople speaking to the FT quoted the equivalent of $23,000–$30,000 for Nvidia’s H100 plug-in cards. Online sellers quote the equivalent of $31,000–$33,000.
Nvidia charges customers $20,000–$23,000 for H100 chips after recently cutting prices, according to Dylan Patel of SemiAnalysis.
One data center vendor in China said servers made by Silicon Valley’s Supermicro and fitted with eight H100 chips hit a peak selling price of 3.2 million yuan after the Biden administration tightened export restrictions in October. He said prices had since fallen to 2.5 million yuan as supply constraints eased.
Several people involved in the trade said merchants in Malaysia, Japan, and Indonesia often shipped Supermicro servers or Nvidia processors to Hong Kong before bringing them across the border to Shenzhen.
The black market trade depends on difficult-to-counter workarounds to Washington’s export regulations, experts said.
For example, while subsidiaries of Chinese companies are banned from buying advanced AI chips outside the country, their executives could establish new companies in countries such as Japan or Malaysia to make the purchases.
“It’s hard to completely enforce export controls beyond the US border,” said an American sanctions expert. “That’s why the regulations create obligations for the shipper to look into end users and [the] commerce [department] adds companies believed to be flouting the rules to the [banned] entity list.”
Additional reporting by Michael Acton in San Francisco.
generalized image diffusion techniques can be used to generate a passable, playable version of Doom. Now, researchers are using some similar techniques with a model called MarioVGG to see if an AI model can generate plausible video of Super Mario Bros. in response to user inputs.
The results of the MarioVGG model—available as a pre-print paper published by the crypto-adjacent AI company Virtuals Protocol—still display a lot of apparent glitches, and it’s too slow for anything approaching real-time gameplay at the moment. But the results show how even a limited model can infer some impressive physics and gameplay dynamics just from studying a bit of video and input data.
The researchers hope this represents a first step toward “producing and demonstrating a reliable and controllable video game generator,” or possibly even “replacing game development and game engines completely using video generation models” in the future.
Watching 737,000 frames of Mario
To train their model, the MarioVGG researchers (GitHub users erniechew and Brian Lim are listed as contributors) started with a public data set of Super Mario Bros. gameplay containing 280 “levels'” worth of input and image data arranged for machine-learning purposes (level 1-1 was removed from the training data so images from it could be used in the evaluation). The more than 737,000 individual frames in that data set were “preprocessed” into 35 frame chunks so the model could start to learn what the immediate results of various inputs generally looked like.
To “simplify the gameplay situation,” the researchers decided to focus only on two potential inputs in the data set: “run right” and “run right and jump.” Even this limited movement set presented some difficulties for the machine-learning system, though, since the preprocessor had to look backward for a few frames before a jump to figure out if and when the “run” started. Any jumps that included mid-air adjustments (i.e., the “left” button) also had to be thrown out because “this would introduce noise to the training dataset,” the researchers write.
MarioVGG takes a single gameplay frame and a text input action to generate multiple video frames.
The last frame of a generated video sequence can be used as the baseline for the next set of frames in the video.
The AI-generated arc of Mario’s jump is pretty accurate (even as the algorithm creates random obstacles as the screen “scrolls”).
MarioVGG was able to infer the physics of behaviors like running off a ledge or running into obstacles.
A particularly bad example of a glitch that causes Mario to simply disappear from the scene at points.
After preprocessing (and about 48 hours of training on a single RTX 4090 graphics card), the researchers used a standard convolution and denoising process to generate new frames of video from a static starting game image and a text input (either “run” or “jump” in this limited case). While these generated sequences only last for a few frames, the last frame of one sequence can be used as the first of a new sequence, feasibly creating gameplay videos of any length that still show “coherent and consistent gameplay,” according to the researchers.
Over the weekend, the nonprofit National Novel Writing Month organization (NaNoWriMo) published an FAQ outlining its position on AI, calling categorical rejection of AI writing technology “classist” and “ableist.” The statement caused a backlash online, prompted four members of the organization’s board to step down, and prompted a sponsor to withdraw its support.
“We believe that to categorically condemn AI would be to ignore classist and ableist issues surrounding the use of the technology,” wrote NaNoWriMo, “and that questions around the use of AI tie to questions around privilege.”
NaNoWriMo, known for its annual challenge where participants write a 50,000-word manuscript in November, argued in its post that condemning AI would ignore issues of class and ability, suggesting the technology could benefit those who might otherwise need to hire human writing assistants or have differing cognitive abilities.
Writers react
After word of the FAQ spread, many writers on social media platforms voiced their opposition to NaNoWriMo’s position. Generative AI models are commonly trained on vast amounts of existing text, including copyrighted works, without attribution or compensation to the original authors. Critics say this raises major ethical questions about using such tools in creative writing competitions and challenges.
“Generative AI empowers not the artist, not the writer, but the tech industry. It steals content to remake content, graverobbing existing material to staple together its Frankensteinian idea of art and story,” wrote Chuck Wendig, the author of Star Wars: Aftermath, in a post about NaNoWriMo on his personal blog.
Daniel José Older, a lead story architect for Star Wars: The High Republic and one of the board members who resigned, wrote on X, “Hello @NaNoWriMo, this is me DJO officially stepping down from your Writers Board and urging every writer I know to do the same. Never use my name in your promo again in fact never say my name at all and never email me again. Thanks!”
In particular, NaNoWriMo’s use of words like “classist” and “ableist” to defend the potential use of generative AI particularly touched a nerve with opponents of generative AI, some of whom say they are disabled themselves.
“A huge middle finger to @NaNoWriMo for this laughable bullshit. Signed, a poor, disabled and chronically ill writer and artist. Miss me by a wide margin with that ableist and privileged bullshit,” wrote one X user. “Other people’s work is NOT accessibility.”
This isn’t the first time the organization has dealt with controversy. Last year, NaNoWriMo announced that it would accept AI-assisted submissions but noted that using AI for an entire novel “would defeat the purpose of the challenge.” Many critics also point out that a NaNoWriMo moderator faced accusations related to child grooming in 2023, which lessened their trust in the organization.
NaNoWriMo doubles down
In response to the backlash, NaNoWriMo updated its FAQ post to address concerns about AI’s impact on the writing industry and to mention “bad actors in the AI space who are doing harm to writers and who are acting unethically.”
We want to make clear that, though we find the categorical condemnation for AI to be problematic for the reasons stated below, we are troubled by situational abuse of AI, and that certain situational abuses clearly conflict with our values. We also want to make clear that AI is a large umbrella technology and that the size and complexity of that category (which includes both non-generative and generative AI, among other uses) contributes to our belief that it is simply too big to categorically endorse or not endorse.
Over the past few years, we’ve received emails from disabled people who frequently use generative AI tools, and we have interviewed a disabled artist, Claire Silver, who uses image synthesis prominently in her work. Some writers with disabilities use tools like ChatGPT to assist them with composition when they have cognitive issues and need assistance expressing themselves.
In June, on Reddit, one user wrote, “As someone with a disability that makes manually typing/writing and wording posts challenging, ChatGPT has been invaluable. It assists me in articulating my thoughts clearly and efficiently, allowing me to participate more actively in various online communities.”
A person with Chiari malformation wrote on Reddit in November 2023 that they use ChatGPT to help them develop software using their voice. “These tools have fundamentally empowered me. The course of my life, my options, opportunities—they’re all better because of this tool,” they wrote.
To opponents of generative AI, the potential benefits that might come to disabled persons do not outweigh what they see as mass plagiarism from tech companies. Also, some artists do not want the time and effort they put into cultivating artistic skills to be devalued for anyone’s benefit.
“All these bullshit appeals from people appropriating social justice language saying, ‘but AI lets me make art when I’m not privileged enough to have the time to develop those skills’ highlights something that needs to be said: you are not entitled to being talented,” posted a writer named Carlos Alonzo Morales on Sunday.
Despite the strong takes, NaNoWriMo has so far stuck to its position of accepting generative AI as a set of potential writing tools in a way that is consistent with its “overall position on nondiscrimination with respect to approaches to creativity, writer’s resources, and personal choice.”
“We absolutely do not condemn AI,” NaNoWriMo wrote in the FAQ post, “and we recognize and respect writers who believe that AI tools are right for them. We recognize that some members of our community stand staunchly against AI for themselves, and that’s perfectly fine. As individuals, we have the freedom to make our own decisions.”
Enlarge/ ASIC evaluators found AI summaries were often “wordy and pointless—just repeating what was in the submission.”
Getty Images
As large language models have continued to rise in prominence, many users and companies have focused on their useful ability to quickly summarize lengthy documents for easier human consumption. When Australia’s Securities and Investments Commission (ASIC) looked into this potential use case, though, it found that the summaries it was able to get from the Llama2-70B model were judged as significantly worse than those provided by humans.
ASIC’s proof-of-concept study (PDF)—which was run in January and February, written up in March, and published in response to a Senate inquiry in May—has a number of limitations that make it hard to generalize about the summarizing capabilities of state-of-the-art LLMs in the present day. Still, the government study shows many of the potential pitfalls large organizations should consider before simply inserting LLM outputs into existing workflows.
Keeping score
For its study, ASIC teamed up with Amazon Web Services to evaluate LLMs’ ability to summarize “a sample of public submissions made to an external Parliamentary Joint Committee inquiry, looking into audit and consultancy firms.” For ASIC’s purposes, a good summary of one of these submissions would highlight any mention of ASIC, any recommendations for avoiding conflicts of interest, and any calls for more regulation, all with references to page numbers and “brief context” for explanation.
In addition to Llama2-70B, the ASIC team also considered the smaller Mistral-7B and MistralLite models in the early phases of the study. The comparison “supported the industry view that larger models tend to produce better results,” the authors write. But, as some social media users have pointed out, Llama2-70B has itself now been surpassed by larger models like ChatGPT-4o, Claude 3.5 Sonnet, and Llama3.1-405B, which score better on many generalized quality evaluations.
More than just choosing the biggest model, though, ASIC said it found that “adequate prompt engineering, carefully crafting the questions and tasks presented to the model, is crucial for optimal results.” ASIC and AWS also went to the trouble of adjusting behind-the-scenes model settings such as temperature, indexing, and top-k sampling. (Top-k sampling is a technique that involves selecting the most likely next words or tokens based on their probabilities predicted by the model.)
“The summaries were quite generic, and the nuance about how ASIC had been referenced wasn’t coming through in the AI-generated summary… “
ASIC Digital and Transformation Lead Graham Jefferson
ASIC used five “business representatives” to evaluate the LLM’s summaries of five submitted documents against summaries prepared by a subject matter expert (the evaluators were not aware of the source of each summary). The AI summaries were judged significantly weaker across all five metrics used by the evaluators, including coherency/consistency, length, and focus on ASIC references. Across the five documents, the AI summaries scored an average total of seven points (on ASIC’s five-category, 15-point scale), compared to 12.2 points for the human summaries.
Missing the nuance
By far the biggest weakness of the AI summaries was “a limited ability to analyze and summarize complex content requiring a deep understanding of context, subtle nuances, or implicit meaning,” ASIC writes. One evaluator highlighted this problem by calling out an AI summary for being “wordy and pointless—just repeating what was in the submission.”
“What we found was that in general terms… the summaries were quite generic, and the nuance about how ASIC had been referenced wasn’t coming through in the AI-generated summary in the way that it was when an ASIC employee was doing the summary work,” Graham Jefferson, ASIC’s digital and transformation lead, told an Australian Senate committee regarding the results.
The evaluators also called out the AI summaries for including incorrect information, missing relevant information, or highlighting irrelevant information. The presence of AI hallucinations also meant that “the model generated text that was grammatically correct, but on occasion factually inaccurate.”
Added together, these problems mean that “assessors generally agreed that the AI outputs could potentially create more work if used (in current state), due to the need to fact check outputs, or because the original source material actually presented information better.”
Just a concept
These results might seem like a pretty conclusive point against using LLMs for summarizing, but ASIC warns that this proof-of-concept study had some significant limitations. The researchers point out that they only had one week to optimize their model, for instance, and suspect that “investing more time in this [optimization] phase may yield better and more accurate results.”
The focus on the (now-outdated) Llama2-70B also means that “the results do not necessarily reflect how other models may perform” the authors warn. Larger models with bigger context windows and better embedding strategies may have more success, the authors write, because “finding references in larger documents is a notoriously hard task for LLMs.”
Despite the results, ASIC says it still believes “there are opportunities for Gen AI as the technology continues to advance… Technology is advancing in this area and it is likely that future models will improve performance and accuracy of results.”
Enlarge/ An ABC handout promotional image for “AI and the Future of Us: An Oprah Winfrey Special.”
On Thursday, ABC announced an upcoming TV special titled, “AI and the Future of Us: An Oprah Winfrey Special.” The one-hour show, set to air on September 12, aims to explore AI’s impact on daily life and will feature interviews with figures in the tech industry, like OpenAI CEO Sam Altman and Bill Gates. Soon after the announcement, some AI critics began questioning the guest list and the framing of the show in general.
“Sure is nice of Oprah to host this extended sales pitch for the generative AI industry at a moment when its fortunes are flagging and the AI bubble is threatening to burst,” tweeted author Brian Merchant, who frequently criticizes generative AI technology in op-eds, social media, and through his “Blood in the Machine” AI newsletter.
“The way the experts who are not experts are presented as such 💀 what a train wreck,” replied artist Karla Ortiz, who is a plaintiff in a lawsuit against several AI companies. “There’s still PLENTY of time to get actual experts and have a better discussion on this because yikes.”
The trailer for Oprah’s upcoming TV special on AI.
On Friday, Ortiz created a lengthy viral thread on X that detailed her potential issues with the program, writing, “This event will be the first time many people will get info on Generative AI. However it is shaping up to be a misinformed marketing event starring vested interests (some who are under a litany of lawsuits) who ignore the harms GenAi inflicts on communities NOW.”
Critics of generative AI like Ortiz question the utility of the technology, its perceived environmental impact, and what they see as blatant copyright infringement. In training AI language models, tech companies like Meta, Anthropic, and OpenAI commonly use copyrighted material gathered without license or owner permission. OpenAI claims that the practice is “fair use.”
Oprah’s guests
According to ABC, the upcoming special will feature “some of the most important and powerful people in AI,” which appears to roughly translate to “famous and publicly visible people related to tech.” Microsoft co-founder Bill Gates, who stepped down as Microsoft CEO 24 years ago, will appear on the show to explore the “AI revolution coming in science, health, and education,” ABC says, and warn of “the once-in-a-century type of impact AI may have on the job market.”
As a guest representing ChatGPT-maker OpenAI, Sam Altman will explain “how AI works in layman’s terms” and discuss “the immense personal responsibility that must be borne by the executives of AI companies.” Karla Ortiz specifically criticized Altman in her thread by saying, “There are far more qualified individuals to speak on what GenAi models are than CEOs. Especially one CEO who recently said AI models will ‘solve all physics.’ That’s an absurd statement and not worthy of your audience.”
In a nod to present-day content creation, YouTube creator Marques Brownlee will appear on the show and reportedly walk Winfrey through “mind-blowing demonstrations of AI’s capabilities.”
Brownlee’s involvement received special attention from some critics online. “Marques Brownlee should be absolutely ashamed of himself,” tweeted PR consultant and frequent AI critic Ed Zitron, who frequently heaps scorn on generative AI in his own newsletter. “What a disgraceful thing to be associated with.”
Other guests include Tristan Harris and Aza Raskin from the Center for Humane Technology, who aim to highlight “emerging risks posed by powerful and superintelligent AI,” an existential risk topic that has its own critics. And FBI Director Christopher Wray will reveal “the terrifying ways criminals and foreign adversaries are using AI,” while author Marilynne Robinson will reflect on “AI’s threat to human values.”
Going only by the publicized guest list, it appears that Oprah does not plan to give voice to prominent non-doomer critics of AI. “This is really disappointing @Oprah and frankly a bit irresponsible to have a one-sided conversation on AI without informed counterarguments from those impacted,” tweeted TV producer Theo Priestley.
Others on the social media network shared similar criticism about a perceived lack of balance in the guest list, including Dr. Margaret Mitchell of Hugging Face. “It could be beneficial to have an AI Oprah follow-up discussion that responds to what happens in [the show] and unpacks generative AI in a more grounded way,” she said.
Oprah’s AI special will air on September 12 on ABC (and a day later on Hulu) in the US, and it will likely elicit further responses from the critics mentioned above. But perhaps that’s exactly how Oprah wants it: “It may fascinate you or scare you,” Winfrey said in a promotional video for the special. “Or, if you’re like me, it may do both. So let’s take a breath and find out more about it.”
According to the Dutch Data Protection Authority (DPA), Clearview AI “built an illegal database with billions of photos of faces” by crawling the web and without gaining consent, including from people in the Netherlands.
Clearview AI’s technology—which has been banned in some US cities over concerns that it gives law enforcement unlimited power to track people in their daily lives—works by pulling in more than 40 billion face images from the web without setting “any limitations in terms of geographical location or nationality,” the Dutch DPA found. Perhaps most concerning, the Dutch DPA said, Clearview AI also provides “facial recognition software for identifying children,” therefore indiscriminately processing personal data of minors.
Training on the face image data, the technology then makes it possible to upload a photo of anyone and search for matches on the Internet. People appearing in search results, the Dutch DPA found, can be “unambiguously” identified. Billed as a public safety resource accessible only by law enforcement, Clearview AI’s face database casts too wide a net, the Dutch DPA said, with the majority of people pulled into the tool likely never becoming subject to a police search.
“The processing of personal data is not only complex and extensive, it moreover offers Clearview’s clients the opportunity to go through data about individual persons and obtain a detailed picture of the lives of these individual persons,” the Dutch DPA said. “These processing operations therefore are highly invasive for data subjects.”
Clearview AI had no legitimate interest under the European Union’s General Data Protection Regulation (GDPR) for the company’s invasive data collection, Dutch DPA Chairman Aleid Wolfsen said in a press release. The Dutch official likened Clearview AI’s sprawling overreach to “a doom scenario from a scary film,” while emphasizing in his decision that Clearview AI has not only stopped responding to any requests to access or remove data from citizens in the Netherlands, but across the EU.
“Facial recognition is a highly intrusive technology that you cannot simply unleash on anyone in the world,” Wolfsen said. “If there is a photo of you on the Internet—and doesn’t that apply to all of us?—then you can end up in the database of Clearview and be tracked.”
To protect Dutch citizens’ privacy, the Dutch DPA imposed a roughly $33 million fine that could go up by about $5.5 million if Clearview AI does not follow orders on compliance. Any Dutch businesses attempting to use Clearview AI services could also face “hefty fines,” the Dutch DPA warned, as that “is also prohibited” under the GDPR.
Clearview AI was given three months to appoint a representative in the EU to stop processing personal data—including sensitive biometric data—in the Netherlands and to update its privacy policies to inform users in the Netherlands of their rights under the GDPR. But the company only has one month to resume processing requests for data access or removals from people in the Netherlands who otherwise find it “impossible” to exercise their rights to privacy, the Dutch DPA’s decision said.
It appears that Clearview AI has no intentions to comply, however. Jack Mulcaire, the chief legal officer for Clearview AI, confirmed to Ars that the company maintains that it is not subject to the GDPR.
“Clearview AI does not have a place of business in the Netherlands or the EU, it does not have any customers in the Netherlands or the EU, and does not undertake any activities that would otherwise mean it is subject to the GDPR,” Mulcaire said. “This decision is unlawful, devoid of due process and is unenforceable.”
But the Dutch DPA found that GDPR applies to Clearview AI because it gathers personal information about Dutch citizens without their consent and without ever alerting users to the data collection at any point.
“People who are in the database also have the right to access their data,” the Dutch DPA said. “This means that Clearview has to show people which data the company has about them, if they ask for this. But Clearview does not cooperate in requests for access.”
Dutch DPA vows to investigate Clearview AI execs
In the press release, Wolfsen said that the Dutch DPA has “to draw a very clear line” underscoring the “incorrect use of this sort of technology” after Clearview AI refused to change its data collection practices following fines in other parts of the European Union, including Italy and Greece.
While Wolfsen acknowledged that Clearview AI could be used to enhance police investigations, he said that the technology would be more appropriate if it was being managed by law enforcement “in highly exceptional cases only” and not indiscriminately by a private company.
“The company should never have built the database and is insufficiently transparent,” the Dutch DPA said.
Although Clearview AI appears ready to defend against the fine, the Dutch DPA said that the company failed to object to the decision within the provided six-week timeframe and therefore cannot appeal the decision.
Further, the Dutch DPA confirmed that authorities are “looking for ways to make sure that Clearview stops the violations” beyond the fines, including by “investigating if the directors of the company can be held personally responsible for the violations.”
Wolfsen claimed that such “liability already exists if directors know that the GDPR is being violated, have the authority to stop that, but omit to do so, and in this way consciously accept those violations.”





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}