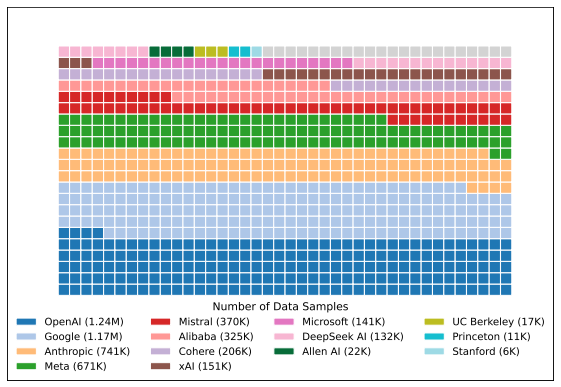
Why Google Gemini’s Pokémon success isn’t all it’s cracked up to be
While Gemini is using its own model and reasoning process for these tasks, it’s telling that JoelZ had to specifically graft these specialized agents onto the base model to help it get through some of the game’s toughest challenges. As JoelZ writes, “My interventions improve Gemini’s overall decision-making and reasoning abilities.”
What are we testing here?
Don’t get me wrong, massaging an LLM into a form that can beat a Pokémon game is definitely an achievement. However, the level of “intervention” needed to help Gemini with those things that “LLMs can’t do independently yet” is crucial to keep in mind as we evaluate that success.
The moment Gemini beat Pokémon (with a little help).
We already know that specially designed reinforcement learning tools can beat Pokémon quite efficiently (and that even a random number generator can beat the game quite inefficiently). The particular resonance of an “LLM plays Pokémon” test is in seeing if a generalized language model can reason out its own solution to a complicated game on its own. The more hand-holding we give the model—through external information, tools, or “harnesses”—the less useful the game is as that kind of test.
Anthropic said in February that Claude Plays Pokémon showed “glimmers of AI systems that tackle challenges with increasing competence, not just through training but with generalized reasoning.” But as Bradshaw writes on LessWrong, “without a refined agent harness, [all models] have a hard time simply making it through the very first screen of the game, Red’s bedroom!” Bradshaw’s subsequent gameplay tests with harness-free LLMs further highlight how these models frequently wander aimlessly, backtrack pointlessly, or even hallucinate impossible game situations.
In other words, we’re still a long way from the kind of envisioned future where an Artificial General Intelligence can figure out a way to beat Pokémon just because you asked it to.
Why Google Gemini’s Pokémon success isn’t all it’s cracked up to be Read More »