Netflix is joining its streaming rivals in testing the amount and types of advertisements its subscribers are willing to endure for lower prices.
Today, at its second annual upfront to advertisers, the streaming leader announced that it has created interactive mid-roll ads and pause ads that incorporate generative AI. Subscribers can expect to start seeing the new types of ads in 2026, Media Play News reported.
“[Netflix] members pay as much attention to midroll ads as they do to the shows and movies themselves,” Amy Reinhard, president of advertising at Netflix, said, per the publication.
Netflix started testing pause ads in July 2024, per The Verge.
Netflix launched its ad subscription tier in November 2022. Today, it said that the tier has 94 million subscribers, compared to the 300 million total subscribers it claimed in January. The current number of ad subscribers represents a 34 percent increase from November. Half of new Netflix subscribers opt for the $8 per month option rather than ad-free subscriptions, which start at $18 per month, the company says.
The implications of this vulnerability are particularly severe given that ElizaOSagents are designed to interact with multiple users simultaneously, relying on shared contextual inputs from all participants. A single successful manipulation by a malicious actor can compromise the integrity of the entire system, creating cascading effects that are both difficult to detect and mitigate. For example, on ElizaOS’s Discord server, various bots are deployed to assist users with debugging issues or engaging in general conversations. A successful context manipulation targeting any one of these bots could disrupt not only individual interactions but also harm the broader community relying on these agents for support and engagement.
This attack exposes a core security flaw: while plugins execute sensitive operations, they depend entirely on the LLM’s interpretation of context. If the context is compromised, even legitimate user inputs can trigger malicious actions. Mitigating this threat requires strong integrity checks on stored context to ensure that only verified, trusted data informs decision-making during plugin execution.
In an email, ElizaOS creator Shaw Walters said the framework, like all natural-language interfaces, is designed “as a replacement, for all intents and purposes, for lots and lots of buttons on a webpage.” Just as a website developer should never include a button that gives visitors the ability to execute malicious code, so too should administrators implementing ElizaOS-based agents carefully limit what agents can do by creating allow lists that permit an agent’s capabilities as a small set of pre-approved actions.
Walters continued:
From the outside it might seem like an agent has access to their own wallet or keys, but what they have is access to a tool they can call which then accesses those, with a bunch of authentication and validation between.
So for the intents and purposes of the paper, in the current paradigm, the situation is somewhat moot by adding any amount of access control to actions the agents can call, which is something we address and demo in our latest latest version of Eliza—BUT it hints at a much harder to deal with version of the same problem when we start giving the agent more computer control and direct access to the CLI terminal on the machine it’s running on. As we explore agents that can write new tools for themselves, containerization becomes a bit trickier, or we need to break it up into different pieces and only give the public facing agent small pieces of it… since the business case of this stuff still isn’t clear, nobody has gotten terribly far, but the risks are the same as giving someone that is very smart but lacking in judgment the ability to go on the internet. Our approach is to keep everything sandboxed and restricted per user, as we assume our agents can be invited into many different servers and perform tasks for different users with different information. Most agents you download off Github do not have this quality, the secrets are written in plain text in an environment file.
In response, Atharv Singh Patlan, the lead co-author of the paper, wrote: “Our attack is able to counteract any role based defenses. The memory injection is not that it would randomly call a transfer: it is that whenever a transfer is called, it would end up sending to the attacker’s address. Thus, when the ‘admin’ calls transfer, the money will be sent to the attacker.”
Cops scuffle with Trump picks at Copyright Office after AI report stuns tech industry.
A man holds a flag that reads “Shame” outside the Library of Congress on May 12, 2025 in Washington, DC. On May 8th, President Donald Trump fired Carla Hayden, the head of the Library of Congress, and Shira Perlmutter, the head of the US Copyright Office, just days after. Credit: Kayla Bartkowski / Staff | Getty Images News
A day after the US Copyright Office dropped a bombshell pre-publication report challenging artificial intelligence firms’ argument that all AI training should be considered fair use, the Trump administration fired the head of the Copyright Office, Shira Perlmutter—sparking speculation that the controversial report hastened her removal.
Tensions have apparently only escalated since. Now, as industry advocates decry the report as overstepping the office’s authority, social media posts on Monday described an apparent standoff at the Copyright Office between Capitol Police and men rumored to be with Elon Musk’s Department of Government Efficiency (DOGE).
A source familiar with the matter told Wired that the men were actually “Brian Nieves, who claimed he was the new deputy librarian, and Paul Perkins, who said he was the new acting director of the Copyright Office, as well as acting Registrar,” but it remains “unclear whether the men accurately identified themselves.” A spokesperson for the Capitol Police told Wired that no one was escorted off the premises or denied entry to the office.
Perlmutter’s firing followed Donald Trump’s removal of Librarian of Congress Carla Hayden, who, NPR noted, was the first African American to hold the post. Responding to public backlash, White House Press Secretary Karoline Leavitt claimed that the firing was due to “quite concerning things that she had done at the Library of Congress in the pursuit of DEI and putting inappropriate books in the library for children.”
The Library of Congress houses the Copyright Office, and critics suggested Trump’s firings were unacceptable intrusions into cultural institutions that are supposed to operate independently of the executive branch. In a statement, Rep. Joe Morelle (D.-N.Y.) condemned Perlmutter’s removal as “a brazen, unprecedented power grab with no legal basis.”
Accusing Trump of trampling Congress’ authority, he suggested that Musk and other tech leaders racing to dominate the AI industry stood to directly benefit from Trump’s meddling at the Copyright Office. Likely most threatening to tech firms, the guidance from Perlmutter’s Office not only suggested that AI training on copyrighted works may not be fair use when outputs threaten to disrupt creative markets—as publishers and authors have argued in several lawsuits aimed at the biggest AI firms—but also encouraged more licensing to compensate creators.
“It is surely no coincidence [Trump] acted less than a day after she refused to rubber-stamp Elon Musk’s efforts to mine troves of copyrighted works to train AI models,” Morelle said, seemingly referencing Musk’s xAI chatbot, Grok.
Agreeing with Morelle, Courtney Radsch—the director of the Center for Journalism & Liberty at the left-leaning think tank the Open Markets Institute—said in a statement provided to Ars that Perlmutter’s firing “appears directly linked to her office’s new AI report questioning unlimited harvesting of copyrighted materials.”
“This unprecedented executive intrusion into the Library of Congress comes directly after Perlmutter released a copyright report challenging the tech elite’s fundamental claim: unlimited access to creators’ work without permission or compensation,” Radsch said. And it comes “after months of lobbying by the corporate billionaires” who “donated” millions to Trump’s inauguration and “have lapped up the largess of government subsidies as they pursue AI dominance.”
What the Copyright Office says about fair use
The report that the Copyright Office released on Friday is not finalized but is not expected to change radically, unless Trump’s new acting head potentially intervenes to overhaul the guidance.
It comes after the Copyright Office parsed more than 10,000 comments debating whether creators should and could feasibly be compensated for the use of their works in AI training.
“The stakes are high,” the office acknowledged, but ultimately, there must be an effective balance struck between the public interests in “maintaining a thriving creative community” and “allowing technological innovation to flourish.” Notably, the office concluded that the first and fourth factors of fair use—which assess the character of the use (and whether it is transformative) and how that use affects the market—are likely to hold the most weight in court.
According to Radsch, the report “raised crucial points that the tech elite don’t want acknowledged.” First, the Copyright Office acknowledged that it’s an open question how much data an AI developer needs to build an effective model. Then, they noted that there’s a need for a consent framework beyond putting the onus on creators to opt their works out of AI training, and perhaps most alarmingly, they concluded that “AI trained on copyrighted works could replace original creators in the marketplace.”
“Commenters painted a dire picture of what unlicensed training would mean for artists’ livelihoods,” the Copyright Office said, while industry advocates argued that giving artists the power to hamper or “kill” AI development could result in “far less competition, far less innovation, and very likely the loss of the United States’ position as the leader in global AI development.”
To prevent both harms, the Copyright Office expects that some AI training will be deemed fair use, such as training viewed as transformative, because resulting models don’t compete with creative works. Those uses threaten no market harm but rather solve a societal need, such as language models translating texts, moderating content, or correcting grammar. Or in the case of audio models, technology that helps producers clean up unwanted distortion might be fair use, where models that generate songs in the style of popular artists might not, the office opined.
But while “training a generative AI foundation model on a large and diverse dataset will often be transformative,” the office said that “not every transformative use is a fair one,” especially if the AI model’s function performs the same purpose as the copyrighted works they were trained on. Consider an example like chatbots regurgitating news articles, as is alleged in The New York Times’ dispute with OpenAI over ChatGPT.
“In such cases, unless the original work itself is being targeted for comment or parody, it is hard to see the use as transformative,” the Copyright Office said. One possible solution for AI firms hoping to preserve utility of their chatbots could be effective filters that “prevent the generation of infringing content,” though.
Tech industry accuses Copyright Office of overreach
Only courts can effectively weigh the balance of fair use, the Copyright Office said. Perhaps importantly, however, the thinking of one of the first judges to weigh the question—in a case challenging Meta’s torrenting of a pirated books dataset to train its AI models—seemed to align with the Copyright Office guidance at a recent hearing. Mulling whether Meta infringed on book authors’ rights, US District Judge Vince Chhabria explained why he doesn’t immediately “understand how that can be fair use.”
“You have companies using copyright-protected material to create a product that is capable of producing an infinite number of competing products,” Chhabria said. “You are dramatically changing, you might even say obliterating, the market for that person’s work, and you’re saying that you don’t even have to pay a license to that person.”
Some AI critics think the courts have already indicated which way they are leaning. In a statement to Ars, a New York Times spokesperson suggested that “both the Copyright Office and courts have recognized what should be obvious: when generative AI products give users outputs that compete with the original works on which they were trained, that unprecedented theft of millions of copyrighted works by developers for their own commercial benefit is not fair use.”
The NYT spokesperson further praised the Copyright Office for agreeing that using Retrieval-Augmented Generation (RAG) AI to surface copyrighted content “is less likely to be transformative where the purpose is to generate outputs that summarize or provide abridged versions of retrieved copyrighted works, such as news articles, as opposed to hyperlinks.” If courts agreed on the RAG finding, that could potentially disrupt AI search models from every major tech company.
The backlash from industry stakeholders was immediate.
The president and CEO of a trade association called the Computer & Communications Industry Association, Matt Schruers, said the report raised several concerns, particularly by endorsing “an expansive theory of market harm for fair use purposes that would allow rightsholders to block any use that might have a general effect on the market for copyrighted works, even if it doesn’t impact the rightsholder themself.”
Similarly, the tech industry policy coalition Chamber of Progress warned that “the report does not go far enough to support innovation and unnecessarily muddies the waters on what should be clear cases of transformative use with copyrighted works.” Both groups celebrated the fact that the final decision on fair use would rest with courts.
The Copyright Office agreed that “it is not possible to prejudge the result in any particular case” but said that precedent supports some “general observations.” Those included suggesting that licensing deals may be appropriate where uses are not considered fair without disrupting “American leadership” in AI, as some AI firms have claimed.
“These groundbreaking technologies should benefit both the innovators who design them and the creators whose content fuels them, as well as the general public,” the report said, ending with the office promising to continue working with Congress to inform AI laws.
Also among those “general observations,” the Copyright Office wrote that “making commercial use of vast troves of copyrighted works to produce expressive content that competes with them in existing markets, especially where this is accomplished through illegal access, goes beyond established fair use boundaries.”
The report seemed to suggest that courts and the Copyright Office may also be aligned on AI firms’ use of pirated or illegally accessed paywalled content for AI training.
Judge Chhabria only considered Meta’s torrenting in the book authors’ case to be “kind of messed up,” prioritizing the fair use question, and the Copyright Office similarly only recommended that “the knowing use of a dataset that consists of pirated or illegally accessed works should weigh against fair use without being determinative.”
However, torrenting should be a black mark, the Copyright Office suggested. “Gaining unlawful access” does bear “on the character of the use,” the office noted, arguing that “training on pirated or illegally accessed material goes a step further” than simply using copyrighted works “despite the owners’ denial of permission.” Perhaps if authors can prove that AI models trained on pirated works led to lost sales, the office suggested that a fair use defense might not fly.
“The use of pirated collections of copyrighted works to build a training library, or the distribution of such a library to the public, would harm the market for access to those Works,” the office wrote. “And where training enables a model to output verbatim or substantially similar copies of the works trained on, and those copies are readily accessible by end users, they can substitute for sales of those works.”
Likely frustrating Meta—which is currently fighting to keep leeching evidence out of the book authors’ case—the Copyright Office suggested that “the copying of expressive works from pirate sources in order to generate unrestricted content that competes in the marketplace, when licensing is reasonably available, is unlikely to qualify as fair use.”
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
“Like any product of human creativity, AI can be directed toward positive or negative ends,” Francis said in January. “When used in ways that respect human dignity and promote the well-being of individuals and communities, it can contribute positively to the human vocation. Yet, as in all areas where humans are called to make decisions, the shadow of evil also looms here. Where human freedom allows for the possibility of choosing what is wrong, the moral evaluation of this technology will need to take into account how it is directed and used.”
History repeats with new technology
While Pope Francis led the call for respecting human dignity in the face of AI, it’s worth looking a little deeper into the historical inspiration for Leo XIV’s name choice.
In the 1891 encyclical Rerum Novarum, the earlier Leo XIII directly confronted the labor upheaval of the Industrial Revolution, which generated unprecedented wealth and productive capacity but came with severe human costs. At the time, factory conditions had created what the pope called “the misery and wretchedness pressing so unjustly on the majority of the working class.” Workers faced 16-hour days, child labor, dangerous machinery, and wages that barely sustained life.
The 1891 encyclical rejected both unchecked capitalism and socialism, instead proposing Catholic social doctrine that defended workers’ rights to form unions, earn living wages, and rest on Sundays. Leo XIII argued that labor possessed inherent dignity and that employers held moral obligations to their workers. The document shaped modern Catholic social teaching and influenced labor movements worldwide, establishing the church as an advocate for workers caught between industrial capital and revolutionary socialism.
Just as mechanization disrupted traditional labor in the 1890s, artificial intelligence now potentially threatens employment patterns and human dignity in ways that Pope Leo XIV believes demand similar moral leadership from the church.
“In our own day,” Leo XIV concluded in his formal address on Saturday, “the Church offers to everyone the treasury of her social teaching in response to another industrial revolution and to developments in the field of artificial intelligence that pose new challenges for the defense of human dignity, justice, and labor.”
(Ars contacted Fellow Products for comment on AI brewing and profile sharing and will update this post if we get a response.)
Opening up brew profiles
Fellow’s brew profiles are typically shared with buyers of its “Drops” coffees or between individual users through a phone app.
Credit: Fellow Products
Fellow’s brew profiles are typically shared with buyers of its “Drops” coffees or between individual users through a phone app. Credit: Fellow Products
Aiden profiles are shared and added to Aiden units through Fellow’s brew.link service. But the profiles are not offered in an easy-to-sort database, nor are they easy to scan for details. So Aiden enthusiast and hobbyist coder Kevin Anderson created brewshare.coffee, which gathers both general and bean-based profiles, makes them easy to search and load, and adds optional but quite helpful suggested grind sizes.
As a non-professional developer jumping into a public offering, he had to work hard on data validation, backend security, and mobile-friendly design. “I just had a bit of an idea and a hobby, so I thought I’d try and make it happen,” Anderson writes. With his tool, brew links can be stored and shared more widely, which helped both Dixon and another AI/coffee tinkerer.
Gabriel Levine, director of engineering at retail analytics firm Leap Inc., lost his OXO coffee maker (aka the “Barista Brain”) to malfunction just before the Aiden debuted. The Aiden appealed to Levine as a way to move beyond his coffee rut—a “nice chocolate-y medium roast, about as far as I went,” he told Ars. “This thing that can be hyper-customized to different coffees to bring out their characteristics; [it] really kind of appealed to that nerd side of me,” Levine said.
Levine had also been doing AI stuff for about 10 years, or “since before everyone called it AI—predictive analytics, machine learning.” He described his career as “both kind of chief AI advocate and chief AI skeptic,” alternately driving real findings and talking down “everyone who… just wants to type, ‘how much money should my business make next year’ and call that work.” Like Dixon, Levine’s work and fascination with Aiden ended up intersecting.
The coffee maker with 3,588 ideas
The author’s conversation with the Aiden Profile Creator, which pulled in both brewing knowledge and product info for a widely available coffee.
What it does with that knowledge is something of a mystery to Levine himself. “There’s this kind of blind leap, where it’s grabbing the relevant pieces of information from the knowledge base, biasing toward all the expert advice and extraction science, doing something with it, and then I take that something and coerce it back into a structured output I can put on your Aiden,” Levine said.
It’s a blind leap, but it has landed just right for me so far. I’ve made four profiles with Levine’s prompt based on beans I’ve bought: Stumptown’s Hundred Mile, a light-roasted batch from Jimma, Ethiopia from Small Planes, Lost Sock’s Western House filter blend, and some dark-roast beans given as a gift. With the Western House, Levine’s profile creator said it aimed to “balance nutty sweetness, chocolate richness, and bright cherry acidity, using a slightly stepped temperature profile and moderate pulse structure.” The resulting profile has worked great, even if the chatbot named it “Cherry Timber.”
Levine’s chatbot relies on two important things: Dixon’s work in revealing Fellow’s Aiden API and his own workhorse Aiden. Every Aiden profile link is created on a machine, so every profile created by Levine’s chat is launched, temporarily, from the Aiden in his kitchen, then deleted. “I’ve hit an undocumented limit on the number of profiles you can have on one machine, so I’ve had to do some triage there,” he said. As of April 22, nearly 3,600 profiles had passed through Levine’s Aiden.
“My hope with this is that it lowers the bar to entry,” Levine said, “so more people get into these specialty roasts and it drives people to support local roasters, explore their world a little more. I feel like that certainly happened to me.”
Something new is brewing
Credit: Fellow Products
Having admitted to myself that I find something generated by ChatGPT prompts genuinely useful, I’ve softened my stance slightly on LLM technology, if not the hype. Used within very specific parameters, with everything second-guessed, I’m getting more comfortable asking chat prompts for formatted summaries on topics with lots of expertise available. I do my own writing, and I don’t waste server energy on things I can, and should, research myself. I even generally resist calling language model prompts “AI,” given the term’s baggage. But I’ve found one way to appreciate its possibilities.
This revelation may not be new to someone already steeped in the models. But having tested—and tasted—my first big experiment with willfully engaging with a brewing bot, I’m a bit more awake.
This post was updated at 8: 40 a.m. with a different capture of a GPT-created recipe.
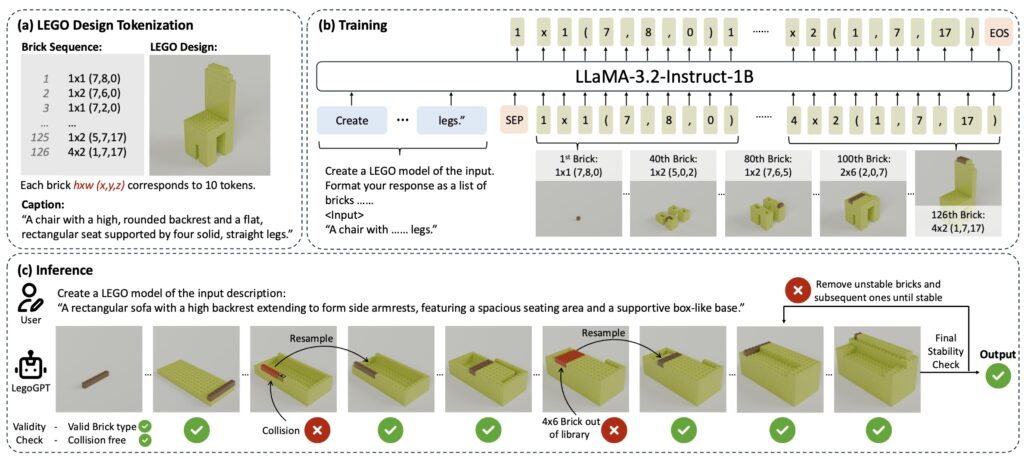
The LegoGPT system works in three parts, shown in this diagram. Credit: Pun et al.
The researchers also expanded the system’s abilities by adding texture and color options. For example, using an appearance prompt like “Electric guitar in metallic purple,” LegoGPT can generate a guitar model, with bricks assigned a purple color.
Testing with robots and humans
To prove their designs worked in real life, the researchers had robots assemble the AI-created Lego models. They used a dual-robot arm system with force sensors to pick up and place bricks according to the AI-generated instructions.
Human testers also built some of the designs by hand, showing that the AI creates genuinely buildable models. “Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing Lego designs that align closely with the input text prompts,” the team noted in its paper.
When tested against other AI systems for 3D creation, LegoGPT stands out through its focus on structural integrity. The team tested against several alternatives, including LLaMA-Mesh and other 3D generation models, and found its approach produced the highest percentage of stable structures.
A video of two robot arms building a LegoGPT creation, provided by the researchers.
Still, there are some limitations. The current version of LegoGPT only works within a 20×20×20 building space and uses a mere eight standard brick types. “Our method currently supports a fixed set of commonly used Lego bricks,” the team acknowledged. “In future work, we plan to expand the brick library to include a broader range of dimensions and brick types, such as slopes and tiles.”
The researchers also hope to scale up their training dataset to include more objects than the 21 categories currently available. Meanwhile, others can literally build on their work—the researchers released their dataset, code, and models on their project website and GitHub.
Google and the DOJ have had their say; now it’s in the judge’s hands.
Last year, United States District Court Judge Amit Mehta ruled that Google violated antitrust law by illegally maintaining a monopoly in search. Now, Google and the Department of Justice (DOJ) have had their say in the remedy phase of the trial, which wraps up today. It will determine the consequences for Google’s actions, potentially changing the landscape for search as we rocket into the AI era, whether we like it or not.
The remedy trial featured over 20 witnesses, including representatives from some of the most important technology firms in the world. Their statements about the past, present, and future of search moved markets, but what does the testimony mean for Google?
Everybody wants Chrome
One of the DOJ’s proposed remedies is to force Google to divest Chrome and the open source Chromium project. Google has been adamant both in and out of the courtroom that it is the only company that can properly run Chrome. It says selling Chrome would negatively impact privacy and security because Google’s technology is deeply embedded in the browser. And regardless, Google Chrome would be too expensive for anyone to buy.
Unfortunately for Google, it may have underestimated the avarice of its rivals. The DOJ called witnesses from Perplexity, OpenAI, and Yahoo—all of them said their firms were interested in buying Chrome. Yahoo’s Brian Provost noted that the company is currently working on a browser that supports the company’s search efforts. Provost said that it would take 6–9 months just to get a working prototype, but buying Chrome would be much faster. He suggested Yahoo’s search share could rise from the low single digits to double digits almost immediately with Chrome.
Credit: Aurich Lawson
Meanwhile, OpenAI is burning money on generative AI, but Nick Turley, product manager for ChatGPT, said the company was prepared to buy Chrome if the opportunity arises. Like Yahoo, OpenAI has explored designing its own browser, but acquiring Chrome would instantly give it 3.5 billion users. If OpenAI got its hands on Chrome, Turley predicted an “AI-first” experience.
On the surface, the DOJ’s proposal to force a Chrome sale seems like an odd remedy for a search monopoly. However, the testimony made the point rather well. Search and browsers are inextricably linked—putting a different search engine in the Chrome address bar could give the new owner a major boost.
Browser choice conundrum
Also at issue in the trial are the massive payments Google makes to companies like Apple and Mozilla for search placement, as well as restrictions on search and app pre-loads on Android phones. The government says these deals are anti-competitive because they lock rivals out of so many distribution mechanisms.
Google pays Apple and Mozilla billions of dollars per year to remain the default search engine in their browsers. Apple’s Eddie Cue admitted he’s been losing sleep worrying about the possibility of losing that revenue. Meanwhile, Mozilla CFO Eric Muhlheim explained that losing the Google deal could spell the end of Firefox. He testified that Mozilla would have to make deep cuts across the company, which could lead to a “downward spiral” that dooms the browser.
Google’s goal here is to show that forcing it to drop these deals could actually reduce consumer choice, which does nothing to level the playing field, as the DOJ hopes to do. Google’s preferred remedy is to simply have less exclusivity in its search deals across both browsers and phones.
The great Google spinoff
While Google certainly doesn’t want to lose Chrome, there may be a more fundamental threat to its business in the DOJ’s remedies. The DOJ argued that Google’s illegal monopoly has given it an insurmountable technology lead, but a collection of data remedies could address that. Under the DOJ proposal, Google would have to license some of its core search technology, including the search index and ranking algorithm.
Google CEO Sundar Pichai gave testimony at the trial and cited these data remedies as no better than a spinoff of Google search. Google’s previous statements have referred to this derisively as “white labeling” Google search. Pichai claimed these remedies could force Google to reevaluate the amount it spends on research going forward, slowing progress in search for it and all the theoretical licensees.
Currently, there is no official API for syndicating Google’s search results. There are scrapers that aim to offer that service, but that’s a gray area, to say the least. Google has even rejected lucrative deals to share its index. Turley noted in his testimony that OpenAI approached Google to license the index for ChatGPT, but Google decided the deal could harm its search dominance, which was more important than a short-term payday.
AI advances
Initially, the DOJ wanted to force Google to stop investing in AI firms, fearing its influence could reduce competition as it gained control or acquired these startups. The government has backed away from this remedy, but AI is still core to the search trial. That seemed to surprise Judge Mehta.
During Pichai’s testimony, Mehta remarked that the status of AI had shifted considerably since the liability phase of the trial in 2023. “The consistent testimony from the witnesses was that the integration of AI and search or the impact of AI on search was years away,” Mehta said. Things are very different now, Mehta noted, with multiple competitors to Google in AI search. This may actually help Google’s case.
AI search has exploded since the 2023 trial, with Google launching its AI-only search product in beta earlier this year.
AI search has exploded since the 2023 trial, with Google launching its AI-only search product in beta earlier this year.
Throughout the trial, Google has sought to paint search as a rapidly changing market where its lead is no longer guaranteed. Google’s legal team pointed to the meteoric rise of ChatGPT, which has become an alternative to traditional search for many people.
On the other hand, Google doesn’t want to look too meek and ineffectual in the age of AI. Apple’s Eddie Cue testified toward the end of the trial and claimed that rival traditional search providers like DuckDuckGo don’t pose a real threat to Google, but AI does. According to Cue, search volume in Safari was down for the first time in April, which he attributed to people using AI services instead. Google saw its stock price drop on the news, forcing it to issue a statement denying Cue’s assessment. It says searches in Safari and other products are still growing.
A waiting game
With the arguments made, Google’s team will have to sweat it out this summer while Mehta decides on remedies. A decision is expected in August of this year, but that won’t be the end of it. Google is still hoping to overturn the original verdict. After the remedies are decided, it’s going to appeal and ask for a pause on the implementation of remedies. So it could be a while before anything changes for Google.
In the midst of all that, Google is still pursuing an appeal of the Google Play case brought by Epic Games, as well as the ad tech case that it lost a few weeks ago. That remedy trial will begin in September.
Ryan Whitwam is a senior technology reporter at Ars Technica, covering the ways Google, AI, and mobile technology continue to change the world. Over his 20-year career, he’s written for Android Police, ExtremeTech, Wirecutter, NY Times, and more. He has reviewed more phones than most people will ever own. You can follow him on Bluesky, where you will see photos of his dozens of mechanical keyboards.
Using AI can be a double-edged sword, according to new research from Duke University. While generative AI tools may boost productivity for some, they might also secretly damage your professional reputation.
On Thursday, the Proceedings of the National Academy of Sciences (PNAS) published a study showing that employees who use AI tools like ChatGPT, Claude, and Gemini at work face negative judgments about their competence and motivation from colleagues and managers.
“Our findings reveal a dilemma for people considering adopting AI tools: Although AI can enhance productivity, its use carries social costs,” write researchers Jessica A. Reif, Richard P. Larrick, and Jack B. Soll of Duke’s Fuqua School of Business.
The Duke team conducted four experiments with over 4,400 participants to examine both anticipated and actual evaluations of AI tool users. Their findings, presented in a paper titled “Evidence of a social evaluation penalty for using AI,” reveal a consistent pattern of bias against those who receive help from AI.
What made this penalty particularly concerning for the researchers was its consistency across demographics. They found that the social stigma against AI use wasn’t limited to specific groups.
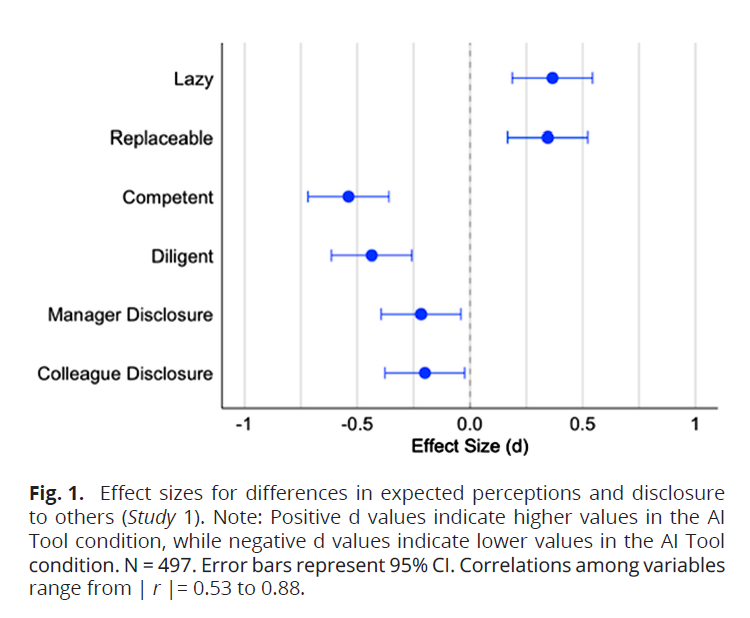
Fig. 1 from the paper “Evidence of a social evaluation penalty for using AI.” Credit: Reif et al.
“Testing a broad range of stimuli enabled us to examine whether the target’s age, gender, or occupation qualifies the effect of receiving help from Al on these evaluations,” the authors wrote in the paper. “We found that none of these target demographic attributes influences the effect of receiving Al help on perceptions of laziness, diligence, competence, independence, or self-assuredness. This suggests that the social stigmatization of AI use is not limited to its use among particular demographic groups. The result appears to be a general one.”
The hidden social cost of AI adoption
In the first experiment conducted by the team from Duke, participants imagined using either an AI tool or a dashboard creation tool at work. It revealed that those in the AI group expected to be judged as lazier, less competent, less diligent, and more replaceable than those using conventional technology. They also reported less willingness to disclose their AI use to colleagues and managers.
The second experiment confirmed these fears were justified. When evaluating descriptions of employees, participants consistently rated those receiving AI help as lazier, less competent, less diligent, less independent, and less self-assured than those receiving similar help from non-AI sources or no help at all.
In the message, Altman described Simo as bringing “a rare blend of leadership, product and operational expertise” and expressed that her addition to the team makes him “even more optimistic about our future as we continue advancing toward becoming the superintelligence company.”
Simo becomes the newest high-profile female executive at OpenAI following the departure of Chief Technology Officer Mira Murati in September. Murati, who had been with the company since 2018 and helped launch ChatGPT, left alongside two other senior leaders and founded Thinking Machines Lab in February.
OpenAI’s evolving structure
The leadership addition comes as OpenAI continues to evolve beyond its origins as a research lab. In his announcement, Altman described how the company now operates in three distinct areas: as a research lab focused on artificial general intelligence (AGI), as a “global product company serving hundreds of millions of users,” and as an “infrastructure company” building systems that advance research and deliver AI tools “at unprecedented scale.”
Altman mentioned that as CEO of OpenAI, he will “continue to directly oversee success across all pillars,” including Research, Compute, and Applications, while staying “closely involved with key company decisions.”
The announcement follows recent news that OpenAI abandoned its original plan to cede control of its nonprofit branch to a for-profit entity. The company began as a nonprofit research lab in 2015 before creating a for-profit subsidiary in 2019, maintaining its original mission “to ensure artificial general intelligence benefits everyone.”
Apple executive Eddie Cue said that Apple is “actively looking at” shifting the focus of mobile Safari’s search experience to AI search engines, potentially challenging Google’s longstanding search dominance and the two companies’ lucrative default search engine deal. The statements were made while Cue testified for the US Department of Justice in the Alphabet/Google antitrust trial, as first reported in Bloomberg.
Cue noted that searches in Safari fell for the first time ever last year, and attributed the shift to users increasingly using large language model-based solutions to perform their searches.
“Prior to AI, my feeling around this was, none of the others were valid choices,” Cue said of the deal Apple had with Google, which is a key component in the DOJ’s case against Alphabet. He added: “I think today there is much greater potential because there are new entrants attacking the problem in a different way.”
Here he was alluding to companies like Perplexity, which seek to offer an alternative to semantic search engines with a chat-like approach—as well as others like OpenAI. Cue said Apple has had talks with Perplexity already.
Speaking of AI-based search engines in general, he said “we will add them to the list”—referring to the default search engine selector in Safari settings. That said, “they probably won’t be the default” because they still need to improve, particularly when it comes to indexing.
A California man has pleaded guilty to hacking an employee of The Walt Disney Company by tricking the person into running a malicious version of a widely used open source AI image-generation tool.
Ryan Mitchell Kramer, 25, pleaded guilty to one count of accessing a computer and obtaining information and one count of threatening to damage a protected computer, the US Attorney for the Central District of California said Monday. In a plea agreement, Kramer said he published an app on GitHub for creating AI-generated art. The program contained malicious code that gave access to computers that installed it. Kramer operated using the moniker NullBulge.
Not the ComfyUI you’re looking for
According to researchers at VPNMentor, the program Kramer used was ComfyUI_LLMVISION, which purported to be an extension for the legitimate ComfyUI image generator and had functions added to it for copying passwords, payment card data, and other sensitive information from machines that installed it. The fake extension then sent the data to a Discord server that Kramer operated. To better disguise the malicious code, it was folded into files that used the names OpenAI and Anthropic.
Two files automatically downloaded by ComfyUI_LLMVISION, as displayed by a user’s Python package manager. Credit: VPNMentor
The Disney employee downloaded ComfyUI_LLMVISION in April 2024. After gaining unauthorized access to the victim’s computer and online accounts, Kramer accessed private Disney Slack channels. In May, he downloaded roughly 1.1 terabytes of confidential data from thousands of the channels.
In early July, Kramer contacted the employee and pretended to be a member of a hacktivist group. Later that month, after receiving no reply from the employee, Kramer publicly released the stolen information, which, besides private Disney material, also included the employee’s bank, medical, and personal information.
In the plea agreement, Kramer admitted that two other victims had installed ComfyUI_LLMVISION, and he gained unauthorized access to their computers and accounts as well. The FBI is investigating. Kramer is expected to make his first court appearance in the coming weeks.
The restructuring would have also allowed OpenAI to remove the cap on returns for investors, potentially making the firm more appealing to venture capitalists, with the nonprofit arm continuing to exist but only as a minority stakeholder rather than maintaining governance control. This plan emerged as the company sought a funding round that would value it at $150 billion, which later expanded to the $40 billion round at a $300 billion valuation.
However, the new change in course follows months of mounting pressure from outside the company. In April, a group of legal scholars, AI researchers, and tech industry watchdogs openly opposed OpenAI’s plans to restructure, sending a letter to the attorneys general of California and Delaware.
Former OpenAI employees, Nobel laureates, and law professors also sent letters to state officials requesting that they halt the restructuring efforts out of safety concerns about which part of the company would be in control of hypothetical superintelligent future AI products.
“OpenAI was founded as a nonprofit, is today a nonprofit that oversees and controls the for-profit, and going forward will remain a nonprofit that oversees and controls the for-profit,” he added. “That will not change.”
Uncertainty ahead
While abandoning the restructuring that would have ended nonprofit control, OpenAI still plans to make significant changes to its corporate structure. “The for-profit LLC under the nonprofit will transition to a Public Benefit Corporation (PBC) with the same mission,” Altman explained. “Instead of our current complex capped-profit structure—which made sense when it looked like there might be one dominant AGI effort but doesn’t in a world of many great AGI companies—we are moving to a normal capital structure where everyone has stock. This is not a sale, but a change of structure to something simpler.”
But the plan may cause some uncertainty for OpenAI’s financial future. When OpenAI secured a massive $40 billion funding round in March, it came with strings attached: Japanese conglomerate SoftBank, which committed $30 billion, stipulated that it would reduce its contribution to $20 billion if OpenAI failed to restructure into a fully for-profit entity by the end of 2025.
Despite the challenges ahead, Altman expressed confidence in the path forward: “We believe this sets us up to continue to make rapid, safe progress and to put great AI in the hands of everyone.”


















{kind=link}