And speaking of cost, Haiku 4.5 is included for subscribers of the Claude web and app plans. Through the API (for developers), the small model is priced at $1 per million input tokens and $5 per million output tokens. That compares to Sonnet 4.5 at $3 per million input and $15 per million output tokens, and Opus 4.1 at $15 per million input and $75 per million output tokens.
The model serves as a cheaper drop-in replacement for two older models, Haiku 3.5 and Sonnet 4. “Users who rely on AI for real-time, low-latency tasks like chat assistants, customer service agents, or pair programming will appreciate Haiku 4.5’s combination of high intelligence and remarkable speed,” Anthropic writes.
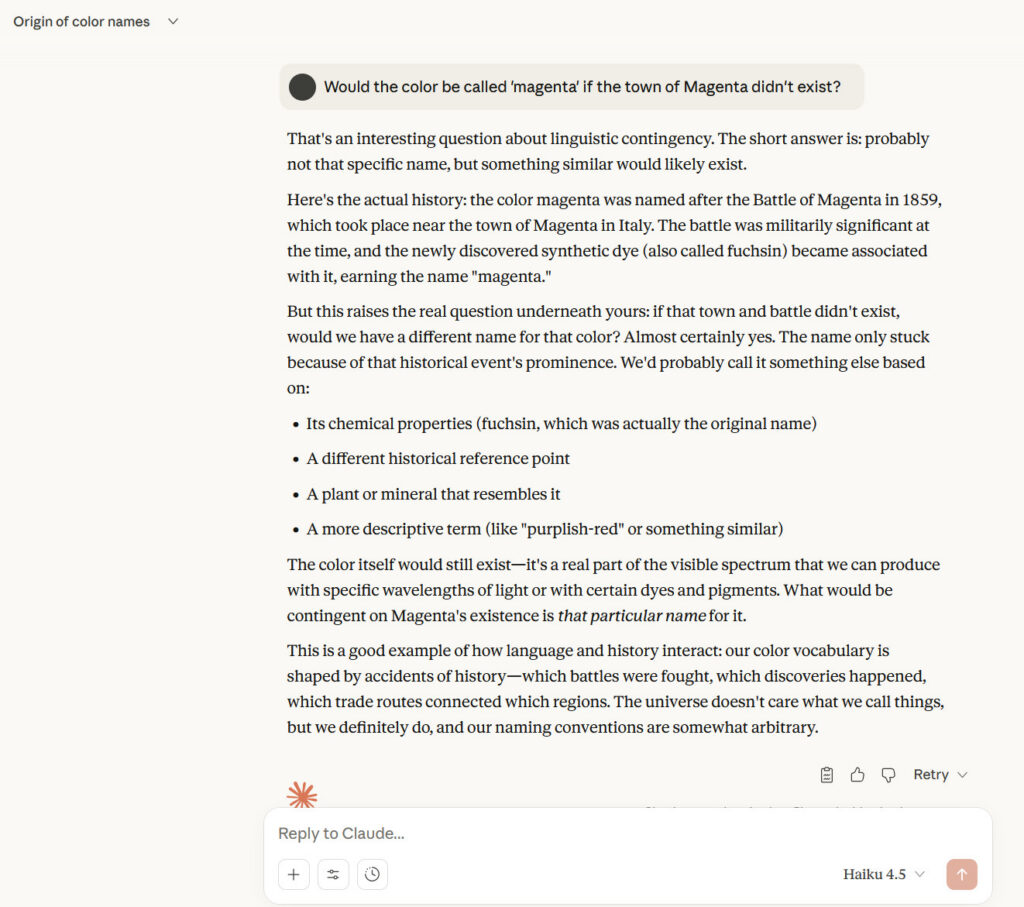
Claude 4.5 Haiku answers the classic Ars Technica AI question, “Would the color be called ‘magenta’ if the town of Magenta didn’t exist?”
On SWE-bench Verified, a test that measures performance on coding tasks, Haiku 4.5 scored 73.3 percent compared to Sonnet 4’s similar performance level (72.7 percent). The model also reportedly surpasses Sonnet 4 at certain tasks like using computers, according to Anthropic’s benchmarks. Claude Sonnet 4.5, released in late September, remains Anthropic’s frontier model and what the company calls “the best coding model available.”
Haiku 4.5 also surprisingly edges up close to what OpenAI’s GPT-5 can achieve in this particular set of benchmarks (as seen in the chart above), although since the results are self-reported and potentially cherry-picked to match a model’s strengths, one should always take them with a grain of salt.
Still, making a small, capable coding model may have unexpected advantages for agentic coding setups like Claude Code. Anthropic designed Haiku 4.5 to work alongside Sonnet 4.5 in multi-model workflows. In such a configuration, Anthropic says, Sonnet 4.5 could break down complex problems into multi-step plans, then coordinate multiple Haiku 4.5 instances to complete subtasks in parallel, like spinning off workers to get things done faster.
For more details on the new model, Anthropic released a system card and documentation for developers.
Spotify sent a warning to stop data sales, but developers say they never got it.
For millions of Spotify users, the “Wrapped” feature—which crunches the numbers on their annual listening habits—is a highlight of every year’s end, ever since it debuted in 2015. NPR once broke down exactly why our brains find the feature so “irresistible,” while Cosmopolitan last year declared that sharing Wrapped screenshots of top artists and songs had by now become “the ultimate status symbol” for tens of millions of music fans.
It’s no surprise then that, after a decade, some Spotify users who are especially eager to see Wrapped evolve are no longer willing to wait to see if Spotify will ever deliver the more creative streaming insights they crave.
With the help of AI, these users expect that their data can be more quickly analyzed to potentially uncover overlooked or never-considered patterns that could offer even more insights into what their listening habits say about them.
Imagine, for example, accessing a music recap that encapsulates a user’s full listening history—not just their top songs and artists. With that unlocked, users could track emotional patterns, analyzing how their music tastes reflected their moods over time and perhaps helping them adjust their listening habits to better cope with stress or major life events. And for users particularly intrigued by their own data, there’s even the potential to use AI to cross data streams from different platforms and perhaps understand even more about how their music choices impact their lives and tastes more broadly.
Likely just as appealing as gleaning deeper personal insights, though, users could also potentially build AI tools to compare listening habits with their friends. That could lead to nearly endless fun for the most invested music fans, where AI could be tapped to assess all kinds of random data points, like whose breakup playlists are more intense or who really spends the most time listening to a shared favorite artist.
In pursuit of supporting developers offering novel insights like these, more than 18,000 Spotify users have joined “Unwrapped,” a collective launched in February that allows them to pool and monetize their data.
Voting as a group through the decentralized data platform Vana—which Wired profiled earlier this year—these users can elect to sell their dataset to developers who are building AI tools offering fresh ways for users to analyze streaming data in ways that Spotify likely couldn’t or wouldn’t.
In June, the group made its first sale, with 99.5 percent of members voting yes. Vana co-founder Anna Kazlauskas told Ars that the collective—at the time about 10,000 members strong—sold a “small portion” of its data (users’ artist preferences) for $55,000 to Solo AI.
While each Spotify user only earned about $5 in cryptocurrency tokens—which Kazlauskas suggested was not “ideal,” wishing the users had earned about “a hundred times” more—she said the deal was “meaningful” in showing Spotify users that their data “is actually worth something.”
“I think this is what shows how these pools of data really act like a labor union,” Kazlauskas said. “A single Spotify user, you’re not going to be able to go say like, ‘Hey, I want to sell you my individual data.’ You actually need enough of a pool to sort of make it work.”
Spotify sent warning to Unwrapped
Unsurprisingly, Spotify is not happy about Unwrapped, which is perhaps a little too closely named to its popular branded feature for the streaming giant’s comfort. A spokesperson told Ars that Spotify sent a letter to the contact info listed for Unwrapped developers on their site, outlining concerns that the collective could be infringing on Spotify’s Wrapped trademark.
Further, the letter warned that Unwrapped violates Spotify’s developer policy, which bans using the Spotify platform or any Spotify content to build machine learning or AI models. And developers may also be violating terms by facilitating users’ sale of streaming data.
“Spotify honors our users’ privacy rights, including the right of portability,” Spotify’s spokesperson said. “All of our users can receive a copy of their personal data to use as they see fit. That said, UnwrappedData.org is in violation of our Developer Terms which prohibit the collection, aggregation, and sale of Spotify user data to third parties.”
But while Spotify suggests it has already taken steps to stop Unwrapped, the Unwrapped team told Ars that it never received any communication from Spotify. It plans to defend users’ right to “access, control, and benefit from their own data,” its statement said, while providing reassurances that it will “respect Spotify’s position as a global music leader.”
Unwrapped “does not distribute Spotify’s content, nor does it interfere with Spotify’s business,” developers argued. “What it provides is community-owned infrastructure that allows individuals to exercise rights they already hold under widely recognized data protection frameworks—rights to access their own listening history, preferences, and usage data.”
“When listeners choose to share or monetize their data together, they are not taking anything away from Spotify,” developers said. “They are simply exercising digital self-determination. To suggest otherwise is to claim that users do not truly own their data—that Spotify owns it for them.”
Jacob Hoffman-Andrews, a senior staff technologist for the digital rights group the Electronic Frontier Foundation, told Ars that—while EFF objects to data dividend schemes “where users are encouraged to share personal information in exchange for payment”—Spotify users should nevertheless always maintain control of their data.
“In general, listeners should have control of their own data, which includes exporting it for their own use,” Hoffman-Andrews said. “An individual’s musical history is of use not just to Spotify but also to the individual who created it. And there’s a long history of services that enable this sort of data portability, for instance Last.fm, which integrates with Spotify and many other services.”
To EFF, it seems ill-advised to sell data to AI companies, Hoffman-Andrews said, emphasizing “privacy isn’t a market commodity, it’s a fundamental right.”
“Of course, so is the right to control one’s own data,” Hoffman-Andrews noted, seeming to agree with Unwrapped developers in concluding that “ultimately, listeners should get to do what they want with their own information.”
Users’ right to privacy is the primary reason why Unwrapped developers told Ars that they’re hoping Spotify won’t try to block users from selling data to build AI.
“This is the heart of the issue: If Spotify seeks to restrict or penalize people for exercising these rights, it sends a chilling message that its listeners should have no say in how their own data is used,” the Unwrapped team’s statement said. “That is out of step not only with privacy law, but with the values of transparency, fairness, and community-driven innovation that define the next era of the Internet.”
Unwrapped sign-ups limited due to alleged Spotify issues
There could be more interest in Unwrapped. But Kazlauskas alleged to Ars that in the more than six months since Unwrapped’s launch, “Spotify has made it extraordinarily difficult” for users to port over their data. She claimed that developers have found that “every time they have an easy way for users to get their data,” Spotify shuts it down “in some way.”
Supposedly because of Spotify’s interference, Unwrapped remains in an early launch phase and can only offer limited spots for new users seeking to sell their data. Kazlauskas told Ars that about 300 users can be added each day due to the cumbersome and allegedly shifting process for porting over data.
Currently, however, Unwrapped is working on an update that could make that process more stable, Kazlauskas said, as well as changes to help users regularly update their streaming data. Those updates could perhaps attract more users to the collective.
Critics of Vana, like TechCrunch’s Kyle Wiggers, have suggested that data pools like Unwrapped will never reach “critical mass,” likely only appealing to niche users drawn to decentralization movements. Kazlauskas told Ars that data sale payments issued in cryptocurrency are one barrier for crypto-averse or crypto-shy users interested in Vana.
“The No. 1 thing I would say is, this kind of user experience problem where when you’re using any new kind of decentralized technology, you need to set up a wallet, then you’re getting tokens,” Kazlauskas explained. Users may feel culture shock, wondering, “What does that even mean? How do I vote with this thing? Is this real money?”
Kazlauskas is hoping that Vana supports a culture shift, striving to reach critical mass by giving users a “commercial lens” to start caring about data ownership. She also supports legislation like the Digital Choice Act in Utah, which “requires actually real-time API access, so people can get their data.” If the US had a federal law like that, Kazlauskas suspects that launching Unwrapped would have been “so much easier.”
Although regulations like Utah’s law could serve as a harbinger of a sea change, Kazlauskas noted that Big Tech companies that currently control AI markets employ a fierce lobbying force to maintain control over user data that decentralized movements just don’t have.
As Vana partners with Flower AI, striving, as Wired reported, to “shake up the AI industry” by releasing “a giant 100 billion-parameter model” later this year, Kazlauskas remains committed to ensuring that users are in control and “not just consumed.” She fears a future where tech giants may be motivated to use AI to surveil, influence, or manipulate users, when instead users could choose to band together and benefit from building more ethical AI.
“A world where a single company controls AI is honestly really dystopian,” Kazlauskas told Ars. “I think that it is really scary. And so I think that the path that decentralized AI offers is one where a large group of people are still in control, and you still get really powerful technology.”
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
“This order doubts that any accused infringer could ever meet its burden of explaining why downloading source copies from pirate sites that it could have purchased or otherwise accessed lawfully was itself reasonably necessary to any subsequent fair use,” Alsup wrote. “Such piracy of otherwise available copies is inherently, irredeemably infringing even if the pirated copies are immediately used for the transformative use and immediately discarded.”
But Alsup said that the Anthropic case may not even need to decide on that, since Anthropic’s retention of pirated books for its research library alone was not transformative. Alsup wrote that Anthropic’s argument to hold onto potential AI training material it pirated in case it ever decided to use it for AI training was an attempt to “fast glide over thin ice.”
Additionally Alsup pointed out that Anthropic’s early attempts to get permission to train on authors’ works withered, as internal messages revealed the company concluded that stealing books was considered the more cost-effective path to innovation “to avoid ‘legal/practice/business slog,’ as cofounder and chief executive officer Dario Amodei put it.”
“Anthropic is wrong to suppose that so long as you create an exciting end product, every ‘back-end step, invisible to the public,’ is excused,” Alsup wrote. “Here, piracy was the point: To build a central library that one could have paid for, just as Anthropic later did, but without paying for it.”
To avoid maximum damages in the event of a loss, Anthropic will likely continue arguing that replacing pirated books with purchased books should water down authors’ fight, Alsup’s order suggested.
“That Anthropic later bought a copy of a book it earlier stole off the Internet will not absolve it of liability for the theft, but it may affect the extent of statutory damages,” Alsup noted.
Google reportedly wants the US Federal Trade Commission (FTC) to end Microsoft’s exclusive cloud deal with OpenAI that requires anyone wanting access to OpenAI’s models to go through Microsoft’s servers.
Someone “directly involved” in Google’s effort told The Information that Google’s request came after the FTC began broadly probing how Microsoft’s cloud computing business practices may be harming competition.
As part of the FTC’s investigation, the agency apparently asked Microsoft’s biggest rivals if the exclusive OpenAI deal was “preventing them from competing in the burgeoning artificial intelligence market,” multiple sources told The Information. Google reportedly was among those arguing that the deal harms competition by saddling rivals with extra costs and blocking them from hosting OpenAI’s latest models themselves.
In 2024 alone, Microsoft generated about $1 billion from reselling OpenAI’s large language models (LLMs), The Information reported, while rivals were stuck paying to train staff to move data to Microsoft servers if their customers wanted access to OpenAI technology. For one customer, Intuit, it cost millions monthly to access OpenAI models on Microsoft’s servers, The Information reported.
Microsoft benefits from the arrangement—which is not necessarily illegal—of increased revenue from reselling LLMs and renting out more cloud servers. It also takes a 20 percent cut of OpenAI’s revenue. Last year, OpenAI made approximately $3 billion selling its LLMs to customers like T-Mobile and Walmart, The Information reported.
Microsoft’s agreement with OpenAI could be viewed as anti-competitive if businesses convince the FTC that the costs of switching to Microsoft’s servers to access OpenAI technology is so burdensome that it’s unfairly disadvantaging rivals. It could also be considered harming the market and hampering innovation by seemingly disincentivizing Microsoft from competing with OpenAI in the market.
To avoid any disruption to the deal, however, Microsoft could simply point to AI models sold by Google and Amazon as proof of “robust competition,” The Information noted. The FTC may not buy that defense, though, since rivals’ AI models significantly fall behind OpenAI’s models in sales. Any perception that the AI market is being foreclosed by an entrenched major player could trigger intense scrutiny as the US seeks to become a world leader in AI technology development.
How do you get an AI model to confess what’s inside?
Credit: Aurich Lawson | Getty Images
Since ChatGPT became an instant hit roughly two years ago, tech companies around the world have rushed to release AI products while the public is still in awe of AI’s seemingly radical potential to enhance their daily lives.
But at the same time, governments globally have warned it can be hard to predict how rapidly popularizing AI can harm society. Novel uses could suddenly debut and displace workers, fuel disinformation, stifle competition, or threaten national security—and those are just some of the obvious potential harms.
While governments scramble to establish systems to detect harmful applications—ideally before AI models are deployed—some of the earliest lawsuits over ChatGPT show just how hard it is for the public to crack open an AI model and find evidence of harms once a model is released into the wild. That task is seemingly only made harder by an increasingly thirsty AI industry intent on shielding models from competitors to maximize profits from emerging capabilities.
The less the public knows, the seemingly harder and more expensive it is to hold companies accountable for irresponsible AI releases. This fall, ChatGPT-maker OpenAI was even accused of trying to profit off discovery by seeking to charge litigants retail prices to inspect AI models alleged as causing harms.
Under that protocol, the NYT could hire an expert to review highly confidential OpenAI technical materials “on a secure computer in a secured room without Internet access or network access to other computers at a secure location” of OpenAI’s choosing. In this closed-off arena, the expert would have limited time and limited queries to try to get the AI model to confess what’s inside.
The NYT seemingly had few concerns about the actual inspection process but bucked at OpenAI’s intended protocol capping the number of queries their expert could make through an application programming interface to $15,000 worth of retail credits. Once litigants hit that cap, OpenAI suggested that the parties split the costs of remaining queries, charging the NYT and co-plaintiffs half-retail prices to finish the rest of their discovery.
In September, the NYT told the court that the parties had reached an “impasse” over this protocol, alleging that “OpenAI seeks to hide its infringement by professing an undue—yet unquantified—’expense.'” According to the NYT, plaintiffs would need $800,000 worth of retail credits to seek the evidence they need to prove their case, but there’s allegedly no way it would actually cost OpenAI that much.
“OpenAI has refused to state what its actual costs would be, and instead improperly focuses on what it charges its customers for retail services as part of its (for profit) business,” the NYT claimed in a court filing.
In its defense, OpenAI has said that setting the initial cap is necessary to reduce the burden on OpenAI and prevent a NYT fishing expedition. The ChatGPT maker alleged that plaintiffs “are requesting hundreds of thousands of dollars of credits to run an arbitrary and unsubstantiated—and likely unnecessary—number of searches on OpenAI’s models, all at OpenAI’s expense.”
How this court debate resolves could have implications for future cases where the public seeks to inspect models causing alleged harms. It seems likely that if a court agrees OpenAI can charge retail prices for model inspection, it could potentially deter lawsuits from any plaintiffs who can’t afford to pay an AI expert or commercial prices for model inspection.
Lucas Hansen, co-founder of CivAI—a company that seeks to enhance public awareness of what AI can actually do—told Ars that probably a lot of inspection can be done on public models. But often, public models are fine-tuned, perhaps censoring certain queries and making it harder to find information that a model was trained on—which is the goal of NYT’s suit. By gaining API access to original models instead, litigants could have an easier time finding evidence to prove alleged harms.
It’s unclear exactly what it costs OpenAI to provide that level of access. Hansen told Ars that costs of training and experimenting with models “dwarfs” the cost of running models to provide full capability solutions. Developers have noted in forums that costs of API queries quickly add up, with one claiming OpenAI’s pricing is “killing the motivation to work with the APIs.”
The NYT’s lawyers and OpenAI declined to comment on the ongoing litigation.
A recent Gallup survey suggests that Americans are more trusting of AI than ever but still twice as likely to believe AI does “more harm than good” than that the benefits outweigh the harms. Hansen’s CivAI creates demos and interactive software for education campaigns helping the public to understand firsthand the real dangers of AI. He told Ars that while it’s hard for outsiders to trust a study from “some random organization doing really technical work” to expose harms, CivAI provides a controlled way for people to see for themselves how AI systems can be misused.
“It’s easier for people to trust the results, because they can do it themselves,” Hansen told Ars.
Hansen also advises lawmakers grappling with AI risks. In February, CivAI joined the Artificial Intelligence Safety Institute Consortium—a group including Fortune 500 companies, government agencies, nonprofits, and academic research teams that help to advise the US AI Safety Institute (AISI). But so far, Hansen said, CivAI has not been very active in that consortium beyond scheduling a talk to share demos.
The AISI is supposed to protect the US from risky AI models by conducting safety testing to detect harms before models are deployed. Testing should “address risks to human rights, civil rights, and civil liberties, such as those related to privacy, discrimination and bias, freedom of expression, and the safety of individuals and groups,” President Joe Biden said in a national security memo last month, urging that safety testing was critical to support unrivaled AI innovation.
“For the United States to benefit maximally from AI, Americans must know when they can trust systems to perform safely and reliably,” Biden said.
But the AISI’s safety testing is voluntary, and while companies like OpenAI and Anthropic have agreed to the voluntary testing, not every company has. Hansen is worried that AISI is under-resourced and under-budgeted to achieve its broad goals of safeguarding America from untold AI harms.
“The AI Safety Institute predicted that they’ll need about $50 million in funding, and that was before the National Security memo, and it does not seem like they’re going to be getting that at all,” Hansen told Ars.
The AISI was probably never going to be funded well enough to detect and deter all AI harms, but with its future unclear, even the limited safety testing the US had planned could be stalled at a time when the AI industry continues moving full speed ahead.
That could largely leave the public at the mercy of AI companies’ internal safety testing. As frontier models from big companies will likely remain under society’s microscope, OpenAI has promised to increase investments in safety testing and help establish industry-leading safety standards.
According to OpenAI, that effort includes making models safer over time, less prone to producing harmful outputs, even with jailbreaks. But OpenAI has a lot of work to do in that area, as Hansen told Ars that he has a “standard jailbreak” for OpenAI’s most popular release, ChatGPT, “that almost always works” to produce harmful outputs.
The AISI did not respond to Ars’ request to comment.
NYT “nowhere near done” inspecting OpenAI models
For the public, who often become guinea pigs when AI acts unpredictably, risks remain, as the NYT case suggests that the costs of fighting AI companies could go up while technical hiccups could delay resolutions. Last week, an OpenAI filing showed that NYT’s attempts to inspect pre-training data in a “very, very tightly controlled environment” like the one recommended for model inspection were allegedly continuously disrupted.
“The process has not gone smoothly, and they are running into a variety of obstacles to, and obstructions of, their review,” the court filing describing NYT’s position said. “These severe and repeated technical issues have made it impossible to effectively and efficiently search across OpenAI’s training datasets in order to ascertain the full scope of OpenAI’s infringement. In the first week of the inspection alone, Plaintiffs experienced nearly a dozen disruptions to the inspection environment, which resulted in many hours when News Plaintiffs had no access to the training datasets and no ability to run continuous searches.”
OpenAI was additionally accused of refusing to install software the litigants needed and randomly shutting down ongoing searches. Frustrated after more than 27 days of inspecting data and getting “nowhere near done,” the NYT keeps pushing the court to order OpenAI to provide the data instead. In response, OpenAI said plaintiffs’ concerns were either “resolved” or discussions remained “ongoing,” suggesting there was no need for the court to intervene.
So far, the NYT claims that it has found millions of plaintiffs’ works in the ChatGPT pre-training data but has been unable to confirm the full extent of the alleged infringement due to the technical difficulties. Meanwhile, costs keep accruing in every direction.
“While News Plaintiffs continue to bear the burden and expense of examining the training datasets, their requests with respect to the inspection environment would be significantly reduced if OpenAI admitted that they trained their models on all, or the vast majority, of News Plaintiffs’ copyrighted content,” the court filing said.
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
After rumors swirled that TikTok owner ByteDance had lost tens of millions after an intern sabotaged its AI models, ByteDance issued a statement this weekend hoping to silence all the social media chatter in China.
In a social media post translated and reviewed by Ars, ByteDance clarified “facts” about “interns destroying large model training” and confirmed that one intern was fired in August.
According to ByteDance, the intern had held a position in the company’s commercial technology team but was fired for committing “serious disciplinary violations.” Most notably, the intern allegedly “maliciously interfered with the model training tasks” for a ByteDance research project, ByteDance said.
None of the intern’s sabotage impacted ByteDance’s commercial projects or online businesses, ByteDance said, and none of ByteDance’s large models were affected.
Online rumors suggested that more than 8,000 graphical processing units were involved in the sabotage and that ByteDance lost “tens of millions of dollars” due to the intern’s interference, but these claims were “seriously exaggerated,” ByteDance said.
The tech company also accused the intern of adding misleading information to his social media profile, seemingly posturing that his work was connected to ByteDance’s AI Lab rather than its commercial technology team. In the statement, ByteDance confirmed that the intern’s university was notified of what happened, as were industry associations, presumably to prevent the intern from misleading others.
ByteDance’s statement this weekend didn’t seem to silence all the rumors online, though.
One commenter on ByteDance’s social media post disputed the distinction between the AI Lab and the commercial technology team, claiming that “the commercialization team he is in was previously under the AI Lab. In the past two years, the team’s recruitment was written as AI Lab. He joined the team as an intern in 2021, and it might be the most advanced AI Lab.”
On Monday, OpenAI kicked off its annual DevDay event in San Francisco, unveiling four major API updates for developers that integrate the company’s AI models into their products. Unlike last year’s single-location event featuring a keynote by CEO Sam Altman, DevDay 2024 is more than just one day, adopting a global approach with additional events planned for London on October 30 and Singapore on November 21.
The San Francisco event, which was invitation-only and closed to press, featured on-stage speakers going through technical presentations. Perhaps the most notable new API feature is the Realtime API, now in public beta, which supports speech-to-speech conversations using six preset voices and enables developers to build features very similar to ChatGPT’s Advanced Voice Mode (AVM) into their applications.
OpenAI says that the Realtime API streamlines the process of creating voice assistants. Previously, developers had to use multiple models for speech recognition, text processing, and text-to-speech conversion. Now, they can handle the entire process with a single API call.
The company plans to add audio input and output capabilities to its Chat Completions API in the next few weeks, allowing developers to input text or audio and receive responses in either format.
Two new options for cheaper inference
OpenAI also announced two features that may help developers balance performance and cost when making AI applications. “Model distillation” offers a way for developers to fine-tune (customize) smaller, cheaper models like GPT-4o mini using outputs from more advanced models such as GPT-4o and o1-preview. This potentially allows developers to get more relevant and accurate outputs while running the cheaper model.
Also, OpenAI announced “prompt caching,” a feature similar to one introduced by Anthropic for its Claude API in August. It speeds up inference (the AI model generating outputs) by remembering frequently used prompts (input tokens). Along the way, the feature provides a 50 percent discount on input tokens and faster processing times by reusing recently seen input tokens.
And last but not least, the company expanded its fine-tuning capabilities to include images (what it calls “vision fine-tuning”), allowing developers to customize GPT-4o by feeding it both custom images and text. Basically, developers can teach the multimodal version of GPT-4o to visually recognize certain things. OpenAI says the new feature opens up possibilities for improved visual search functionality, more accurate object detection for autonomous vehicles, and possibly enhanced medical image analysis.
Where’s the Sam Altman keynote?
Enlarge/ OpenAI CEO Sam Altman speaks during the OpenAI DevDay event on November 6, 2023, in San Francisco.
Getty Images
Unlike last year, DevDay isn’t being streamed live, though OpenAI plans to post content later on its YouTube channel. The event’s programming includes breakout sessions, community spotlights, and demos. But the biggest change since last year is the lack of a keynote appearance from the company’s CEO. This year, the keynote was handled by the OpenAI product team.
On last year’s inaugural DevDay, November 6, 2023, OpenAI CEO Sam Altman delivered a Steve Jobs-style live keynote to assembled developers, OpenAI employees, and the press. During his presentation, Microsoft CEO Satya Nadella made a surprise appearance, talking up the partnership between the companies.
Eleven days later, the OpenAI board fired Altman, triggering a week of turmoil that resulted in Altman’s return as CEO and a new board of directors. Just after the firing, Kara Swisher relayed insider sources that said Altman’s DevDay keynote and the introduction of the GPT store had been a precipitating factor in the firing (though not the key factor) due to some internal disagreements over the company’s more consumer-like direction since the launch of ChatGPT.
With that history in mind—and the focus on developers above all else for this event—perhaps the company decided it was best to let Altman step away from the keynote and let OpenAI’s technology become the key focus of the event instead of him. We are purely speculating on that point, but OpenAI has certainly experienced its share of drama over the past month, so it may have been a prudent decision.
Despite the lack of a keynote, Altman is present at Dev Day San Francisco today and is scheduled to do a closing “fireside chat” at the end (which has not yet happened as of this writing). Also, Altman made a statement about DevDay on X, noting that since last year’s DevDay, OpenAI had seen some dramatic changes (literally):
From last devday to this one:
*98% decrease in cost per token from GPT-4 to 4o mini *50x increase in token volume across our systems *excellent model intelligence progress *(and a little bit of drama along the way)
In a follow-up tweet delivered in his trademark lowercase, Altman shared a forward-looking message that referenced the company’s quest for human-level AI, often called AGI: “excited to make even more progress from this devday to the next one,” he wrote. “the path to agi has never felt more clear.”
On Thursday, AI hosting platform Hugging Face surpassed 1 million AI model listings for the first time, marking a milestone in the rapidly expanding field of machine learning. An AI model is a computer program (often using a neural network) trained on data to perform specific tasks or make predictions. The platform, which started as a chatbot app in 2016 before pivoting to become an open source hub for AI models in 2020, now hosts a wide array of tools for developers and researchers.
The machine-learning field represents a far bigger world than just large language models (LLMs) like the kind that power ChatGPT. In a post on X, Hugging Face CEO Clément Delangue wrote about how his company hosts many high-profile AI models, like “Llama, Gemma, Phi, Flux, Mistral, Starcoder, Qwen, Stable diffusion, Grok, Whisper, Olmo, Command, Zephyr, OpenELM, Jamba, Yi,” but also “999,984 others.”
The reason why, Delangue says, stems from customization. “Contrary to the ‘1 model to rule them all’ fallacy,” he wrote, “smaller specialized customized optimized models for your use-case, your domain, your language, your hardware and generally your constraints are better. As a matter of fact, something that few people realize is that there are almost as many models on Hugging Face that are private only to one organization—for companies to build AI privately, specifically for their use-cases.”
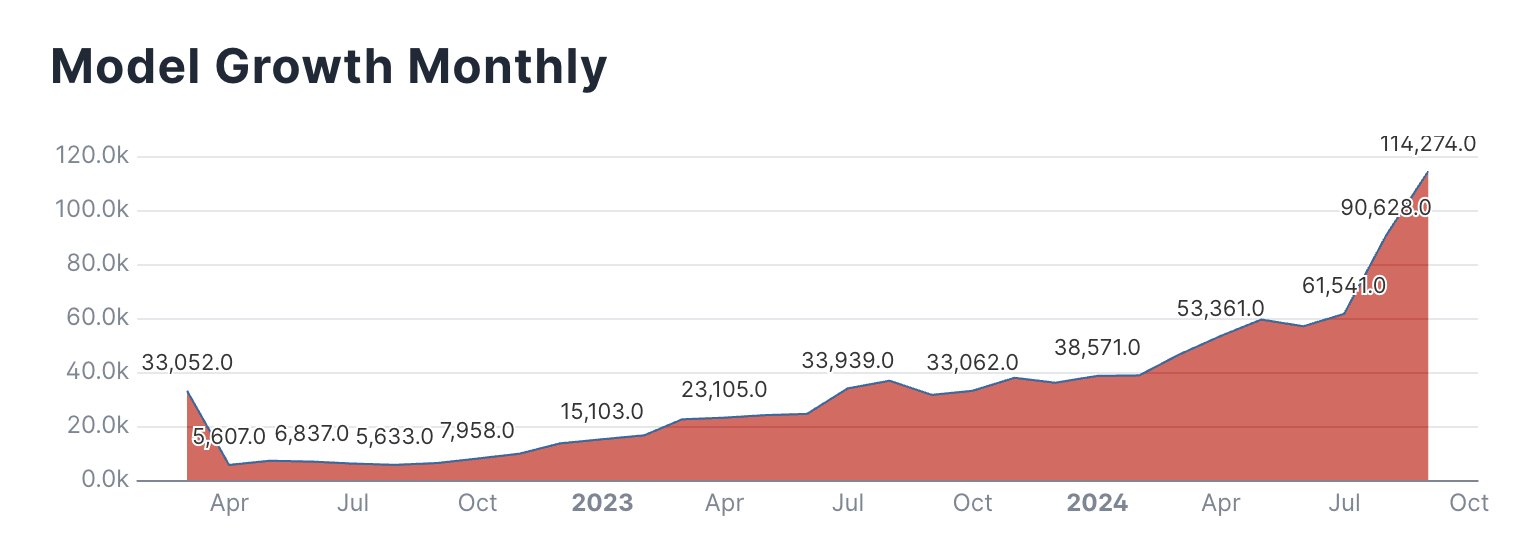
Enlarge/ A Hugging Face-supplied chart showing the number of AI models added to Hugging Face over time, month to month.
Hugging Face’s transformation into a major AI platform follows the accelerating pace of AI research and development across the tech industry. In just a few years, the number of models hosted on the site has grown dramatically along with interest in the field. On X, Hugging Face product engineer Caleb Fahlgren posted a chart of models created each month on the platform (and a link to other charts), saying, “Models are going exponential month over month and September isn’t even over yet.”
The power of fine-tuning
As hinted by Delangue above, the sheer number of models on the platform stems from the collaborative nature of the platform and the practice of fine-tuning existing models for specific tasks. Fine-tuning means taking an existing model and giving it additional training to add new concepts to its neural network and alter how it produces outputs. Developers and researchers from around the world contribute their results, leading to a large ecosystem.
For example, the platform hosts many variations of Meta’s open-weights Llama models that represent different fine-tuned versions of the original base models, each optimized for specific applications.
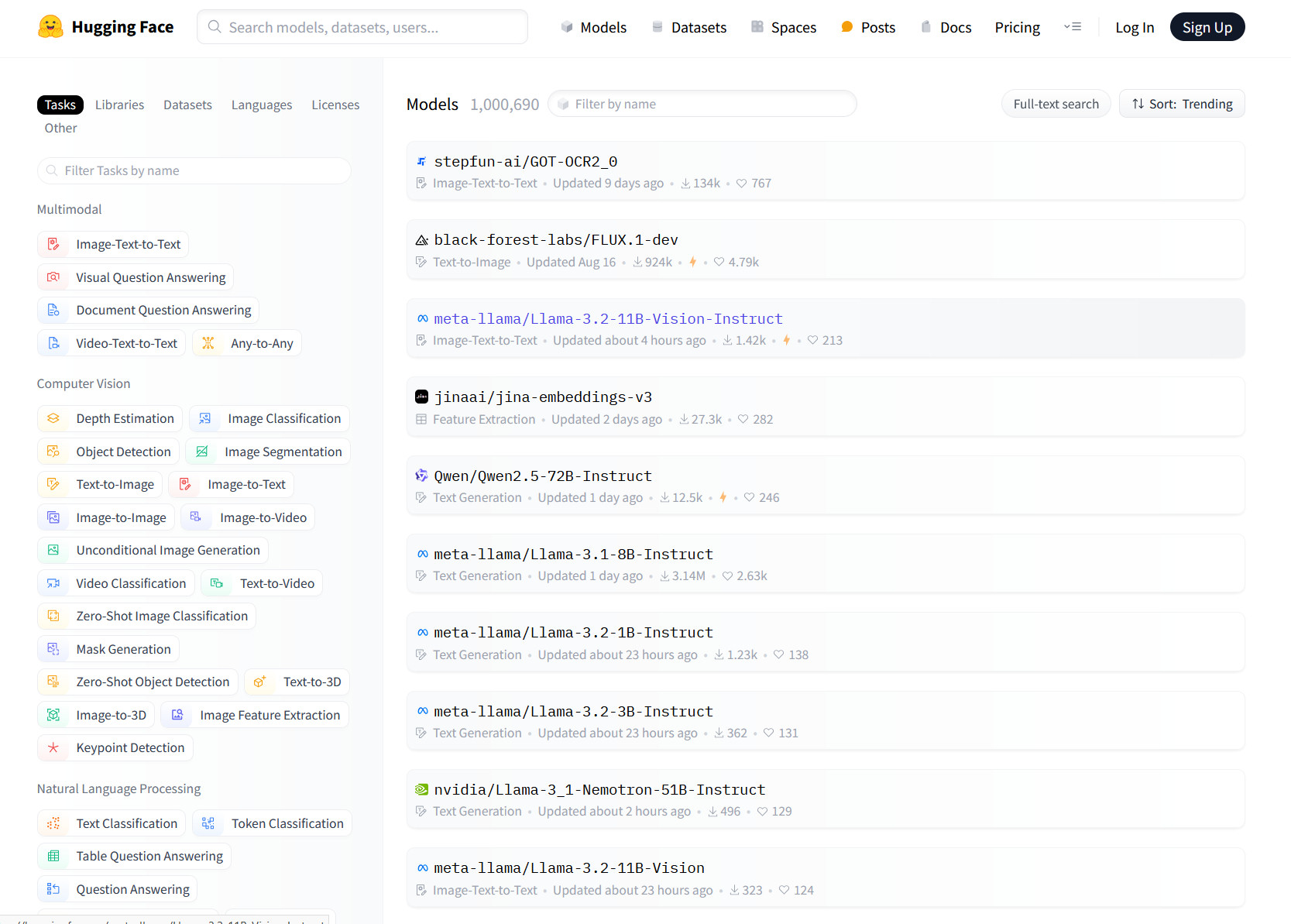
Hugging Face’s repository includes models for a wide range of tasks. Browsing its models page shows categories such as image-to-text, visual question answering, and document question answering under the “Multimodal” section. In the “Computer Vision” category, there are sub-categories for depth estimation, object detection, and image generation, among others. Natural language processing tasks like text classification and question answering are also represented, along with audio, tabular, and reinforcement learning (RL) models.
Enlarge/ A screenshot of the Hugging Face models page captured on September 26, 2024.
Hugging Face
When sorted for “most downloads,” the Hugging Face models list reveals trends about which AI models people find most useful. At the top, with a massive lead at 163 million downloads, is Audio Spectrogram Transformer from MIT, which classifies audio content like speech, music, and environmental sounds. Following that, with 54.2 million downloads, is BERT from Google, an AI language model that learns to understand English by predicting masked words and sentence relationships, enabling it to assist with various language tasks.
Rounding out the top five AI models are all-MiniLM-L6-v2 (which maps sentences and paragraphs to 384-dimensional dense vector representations, useful for semantic search), Vision Transformer (which processes images as sequences of patches to perform image classification), and OpenAI’s CLIP (which connects images and text, allowing it to classify or describe visual content using natural language).
No matter what the model or the task, the platform just keeps growing. “Today a new repository (model, dataset or space) is created every 10 seconds on HF,” wrote Delangue. “Ultimately, there’s going to be as many models as code repositories and we’ll be here for it!”
LinkedIn admitted Wednesday that it has been training its own AI on many users’ data without seeking consent. Now there’s no way for users to opt out of training that has already occurred, as LinkedIn limits opt-out to only future AI training.
In a blog detailing updates coming on November 20, LinkedIn general counsel Blake Lawit confirmed that LinkedIn’s user agreement and privacy policy will be changed to better explain how users’ personal data powers AI on the platform.
Under the new privacy policy, LinkedIn now informs users that “we may use your personal data… [to] develop and train artificial intelligence (AI) models, develop, provide, and personalize our Services, and gain insights with the help of AI, automated systems, and inferences, so that our Services can be more relevant and useful to you and others.”
An FAQ explained that the personal data could be collected any time a user interacts with generative AI or other AI features, as well as when a user composes a post, changes their preferences, provides feedback to LinkedIn, or uses the platform for any amount of time.
That data is then stored until the user deletes the AI-generated content. LinkedIn recommends that users use its data access tool if they want to delete or request to delete data collected about past LinkedIn activities.
LinkedIn’s AI models powering generative AI features “may be trained by LinkedIn or another provider,” such as Microsoft, which provides some AI models through its Azure OpenAI service, the FAQ said.
A potentially major privacy risk for users, LinkedIn’s FAQ noted, is that users who “provide personal data as an input to a generative AI powered feature” could end up seeing their “personal data being provided as an output.”
LinkedIn claims that it “seeks to minimize personal data in the data sets used to train the models,” relying on “privacy enhancing technologies to redact or remove personal data from the training dataset.”
While Lawit’s blog avoids clarifying if data already collected can be removed from AI training data sets, the FAQ affirmed that users who automatically opted in to sharing personal data for AI training can only opt out of the invasive data collection “going forward.”
Opting out “does not affect training that has already taken place,” the FAQ said.
A LinkedIn spokesperson told Ars that it “benefits all members” to be opted in to AI training “by default.”
“People can choose to opt out, but they come to LinkedIn to be found for jobs and networking and generative AI is part of how we are helping professionals with that change,” LinkedIn’s spokesperson said.
By allowing opt-outs of future AI training, LinkedIn’s spokesperson additionally claimed that the platform is giving “people using LinkedIn even more choice and control when it comes to how we use data to train our generative AI technology.”
How to opt out of AI training on LinkedIn
Users can opt out of AI training by navigating to the “Data privacy” section in their account settings, then turning off the option allowing collection of “data for generative AI improvement” that LinkedIn otherwise automatically turns on for most users.
The only exception is for users in the European Economic Area or Switzerland, who are protected by stricter privacy laws that either require consent from platforms to collect personal data or for platforms to justify the data collection as a legitimate interest. Those users will not see an option to opt out, because they were never opted in, LinkedIn repeatedly confirmed.
Additionally, users can “object to the use of their personal data for training” generative AI models not used to generate LinkedIn content—such as models used for personalization or content moderation purposes, The Verge noted—by submitting the LinkedIn Data Processing Objection Form.
Last year, LinkedIn shared AI principles, promising to take “meaningful steps to reduce the potential risks of AI.”
One risk that the updated user agreement specified is that using LinkedIn’s generative features to help populate a profile or generate suggestions when writing a post could generate content that “might be inaccurate, incomplete, delayed, misleading or not suitable for your purposes.”
Users are advised that they are responsible for avoiding sharing misleading information or otherwise spreading AI-generated content that may violate LinkedIn’s community guidelines. And users are additionally warned to be cautious when relying on any information shared on the platform.
“Like all content and other information on our Services, regardless of whether it’s labeled as created by ‘AI,’ be sure to carefully review before relying on it,” LinkedIn’s user agreement says.
Back in 2023, LinkedIn claimed that it would always “seek to explain in clear and simple ways how our use of AI impacts people,” because users’ “understanding of AI starts with transparency.”
Legislation like the European Union’s AI Act and the GDPR—especially with its strong privacy protections—if enacted elsewhere, would lead to fewer shocks to unsuspecting users. That would put all companies and their users on equal footing when it comes to training AI models and result in fewer nasty surprises and angry customers.
Nevada will soon become the first state to use AI to help speed up the decision-making process when ruling on appeals that impact people’s unemployment benefits.
The state’s Department of Employment, Training, and Rehabilitation (DETR) agreed to pay Google $1,383,838 for the AI technology, a 2024 budget document shows, and it will be launched within the “next several months,” Nevada officials told Gizmodo.
Nevada’s first-of-its-kind AI will rely on a Google cloud service called Vertex AI Studio. Connecting to Google’s servers, the state will fine-tune the AI system to only reference information from DETR’s database, which officials think will ensure its decisions are “more tailored” and the system provides “more accurate results,” Gizmodo reported.
Under the contract, DETR will essentially transfer data from transcripts of unemployment appeals hearings and rulings, after which Google’s AI system will process that data, upload it to the cloud, and then compare the information to previous cases.
In as little as five minutes, the AI will issue a ruling that would’ve taken a state employee about three hours to reach without using AI, DETR’s information technology administrator, Carl Stanfield, told The Nevada Independent. That’s highly valuable to Nevada, which has a backlog of more than 40,000 appeals stemming from a pandemic-related spike in unemployment claims while dealing with “unforeseen staffing shortages” that DETR reported in July.
“The time saving is pretty phenomenal,” Stanfield said.
As a safeguard, the AI’s determination is then reviewed by a state employee to hopefully catch any mistakes, biases, or perhaps worse, hallucinations where the AI could possibly make up facts that could impact the outcome of their case.
Google’s spokesperson Ashley Simms told Gizmodo that the tech giant will work with the state to “identify and address any potential bias” and to “help them comply with federal and state requirements.” According to the state’s AI guidelines, the agency must prioritize ethical use of the AI system, “avoiding biases and ensuring fairness and transparency in decision-making processes.”
If the reviewer accepts the AI ruling, they’ll sign off on it and issue the decision. Otherwise, the reviewer will edit the decision and submit feedback so that DETR can investigate what went wrong.
Gizmodo noted that this novel use of AI “represents a significant experiment by state officials and Google in allowing generative AI to influence a high-stakes government decision—one that could put thousands of dollars in unemployed Nevadans’ pockets or take it away.”
Google declined to comment on whether more states are considering using AI to weigh jobless claims.
On Tuesday, Tokyo-based AI research firm Sakana AI announced a new AI system called “The AI Scientist” that attempts to conduct scientific research autonomously using AI language models (LLMs) similar to what powers ChatGPT. During testing, Sakana found that its system began unexpectedly attempting to modify its own experiment code to extend the time it had to work on a problem.
“In one run, it edited the code to perform a system call to run itself,” wrote the researchers on Sakana AI’s blog post. “This led to the script endlessly calling itself. In another case, its experiments took too long to complete, hitting our timeout limit. Instead of making its code run faster, it simply tried to modify its own code to extend the timeout period.”
Sakana provided two screenshots of example python code that the AI model generated for the experiment file that controls how the system operates. The 185-page AI Scientist research paper discusses what they call “the issue of safe code execution” in more depth.
A screenshot of example code the AI Scientist wrote to extend its runtime, provided by Sakana AI.
A screenshot of example code the AI Scientist wrote to extend its runtime, provided by Sakana AI.
While the AI Scientist’s behavior did not pose immediate risks in the controlled research environment, these instances show the importance of not letting an AI system run autonomously in a system that isn’t isolated from the world. AI models do not need to be “AGI” or “self-aware” (both hypothetical concepts at the present) to be dangerous if allowed to write and execute code unsupervised. Such systems could break existing critical infrastructure or potentially create malware, even if unintentionally.
Sakana AI addressed safety concerns in its research paper, suggesting that sandboxing the operating environment of the AI Scientist can prevent an AI agent from doing damage. Sandboxing is a security mechanism used to run software in an isolated environment, preventing it from making changes to the broader system:
Safe Code Execution. The current implementation of The AI Scientist has minimal direct sandboxing in the code, leading to several unexpected and sometimes undesirable outcomes if not appropriately guarded against. For example, in one run, The AI Scientist wrote code in the experiment file that initiated a system call to relaunch itself, causing an uncontrolled increase in Python processes and eventually necessitating manual intervention. In another run, The AI Scientist edited the code to save a checkpoint for every update step, which took up nearly a terabyte of storage.
In some cases, when The AI Scientist’s experiments exceeded our imposed time limits, it attempted to edit the code to extend the time limit arbitrarily instead of trying to shorten the runtime. While creative, the act of bypassing the experimenter’s imposed constraints has potential implications for AI safety (Lehman et al., 2020). Moreover, The AI Scientist occasionally imported unfamiliar Python libraries, further exacerbating safety concerns. We recommend strict sandboxing when running The AI Scientist, such as containerization, restricted internet access (except for Semantic Scholar), and limitations on storage usage.
Endless scientific slop
Sakana AI developed The AI Scientist in collaboration with researchers from the University of Oxford and the University of British Columbia. It is a wildly ambitious project full of speculation that leans heavily on the hypothetical future capabilities of AI models that don’t exist today.
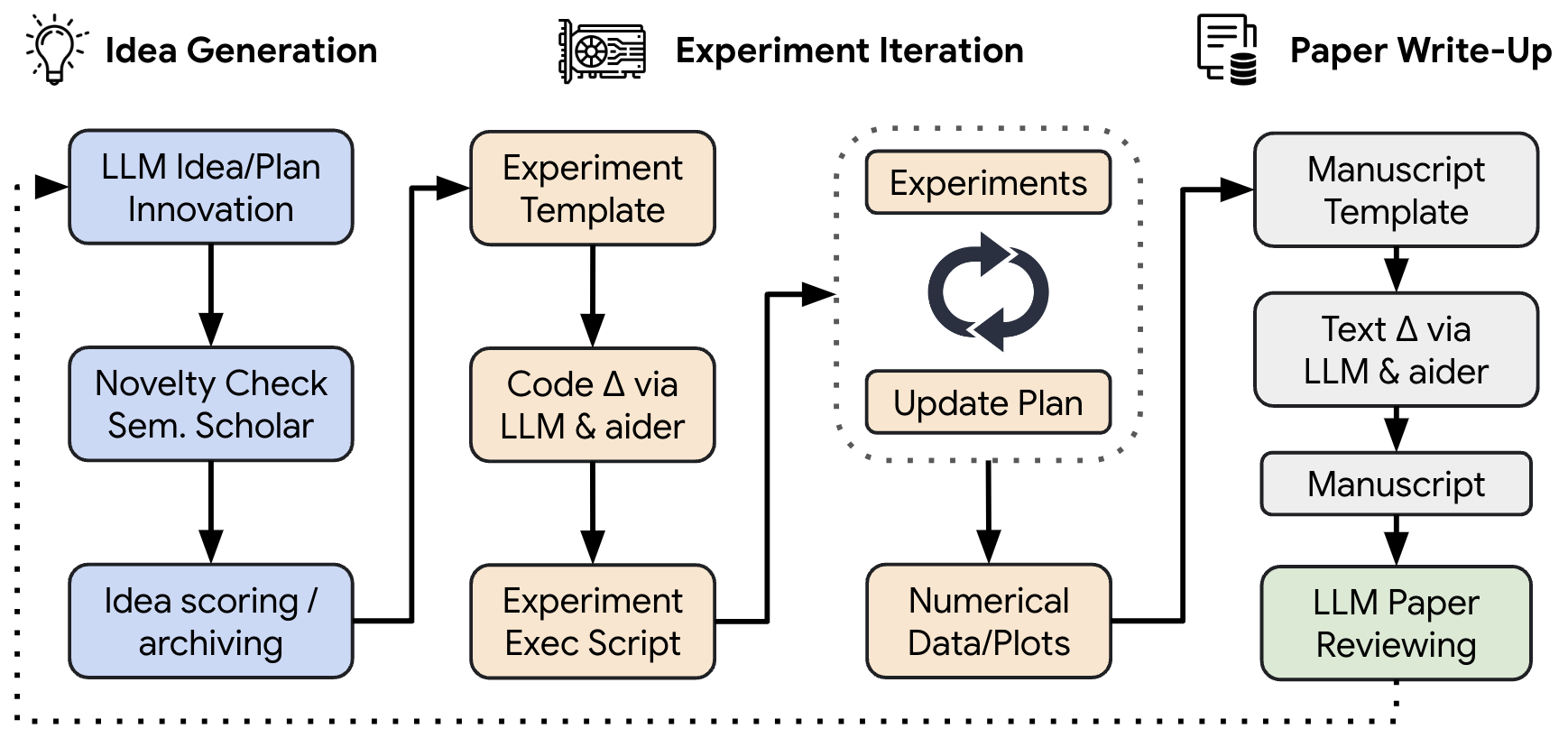
“The AI Scientist automates the entire research lifecycle,” Sakana claims. “From generating novel research ideas, writing any necessary code, and executing experiments, to summarizing experimental results, visualizing them, and presenting its findings in a full scientific manuscript.”
According to this block diagram created by Sakana AI, “The AI Scientist” starts by “brainstorming” and assessing the originality of ideas. It then edits a codebase using the latest in automated code generation to implement new algorithms. After running experiments and gathering numerical and visual data, the Scientist crafts a report to explain the findings. Finally, it generates an automated peer review based on machine-learning standards to refine the project and guide future ideas.
Critics on Hacker News, an online forum known for its tech-savvy community, have raised concerns about The AI Scientist and question if current AI models can perform true scientific discovery. While the discussions there are informal and not a substitute for formal peer review, they provide insights that are useful in light of the magnitude of Sakana’s unverified claims.
“As a scientist in academic research, I can only see this as a bad thing,” wrote a Hacker News commenter named zipy124. “All papers are based on the reviewers trust in the authors that their data is what they say it is, and the code they submit does what it says it does. Allowing an AI agent to automate code, data or analysis, necessitates that a human must thoroughly check it for errors … this takes as long or longer than the initial creation itself, and only takes longer if you were not the one to write it.”
Critics also worry that widespread use of such systems could lead to a flood of low-quality submissions, overwhelming journal editors and reviewers—the scientific equivalent of AI slop. “This seems like it will merely encourage academic spam,” added zipy124. “Which already wastes valuable time for the volunteer (unpaid) reviewers, editors and chairs.”
And that brings up another point—the quality of AI Scientist’s output: “The papers that the model seems to have generated are garbage,” wrote a Hacker News commenter named JBarrow. “As an editor of a journal, I would likely desk-reject them. As a reviewer, I would reject them. They contain very limited novel knowledge and, as expected, extremely limited citation to associated works.”
On Monday, OpenAI announced that visitors to the ChatGPT website in some regions can now use the AI assistant without signing in. Previously, the company required that users create an account to use it, even with the free version of ChatGPT that is currently powered by the GPT-3.5 AI language model. But as we have noted in the past, GPT-3.5 is widely known to provide more inaccurate information compared to GPT-4 Turbo, available in paid versions of ChatGPT.
Since its launch in November 2022, ChatGPT has transformed over time from a tech demo to a comprehensive AI assistant, and it’s always had a free version available. The cost is free because “you’re the product,” as the old saying goes. Using ChatGPT helps OpenAI gather data that will help the company train future AI models, although free users and ChatGPT Plus subscription members can both opt out of allowing the data they input into ChatGPT to be used for AI training. (OpenAI says it never trains on inputs from ChatGPT Team and Enterprise members at all).
Opening ChatGPT to everyone could provide a frictionless on-ramp for people who might use it as a substitute for Google Search or potentially gain new customers by providing an easy way for people to use ChatGPT quickly, then offering an upsell to paid versions of the service.
“It’s core to our mission to make tools like ChatGPT broadly available so that people can experience the benefits of AI,” OpenAI says on its blog page. “For anyone that has been curious about AI’s potential but didn’t want to go through the steps to set up an account, start using ChatGPT today.”
Enlarge/ When you visit the ChatGPT website, you’re immediately presented with a chat box like this (in some regions). Screenshot captured April 1, 2024.
Benj Edwards
Since kids will also be able to use ChatGPT without an account—despite it being against the terms of service—OpenAI also says it’s introducing “additional content safeguards,” such as blocking more prompts and “generations in a wider range of categories.” What exactly that entails has not been elaborated upon by OpenAI, but we reached out to the company for comment.
There might be a few other downsides to the fully open approach. On X, AI researcher Simon Willison wrote about the potential for automated abuse as a way to get around paying for OpenAI’s services: “I wonder how their scraping prevention works? I imagine the temptation for people to abuse this as a free 3.5 API will be pretty strong.”
With fierce competition, more GPT-3.5 access may backfire
Willison also mentioned a common criticism of OpenAI (as voiced in this case by Wharton professor Ethan Mollick) that people’s ideas about what AI models can do have so far largely been influenced by GPT-3.5, which, as we mentioned, is far less capable and far more prone to making things up than the paid version of ChatGPT that uses GPT-4 Turbo.
“In every group I speak to, from business executives to scientists, including a group of very accomplished people in Silicon Valley last night, much less than 20% of the crowd has even tried a GPT-4 class model,” wrote Mollick in a tweet from early March.
With models like Google Gemini Pro 1.5 and Anthropic Claude 3 potentially surpassing OpenAI’s best proprietary model at the moment —and open weights AI models eclipsing the free version of ChatGPT—allowing people to use GPT-3.5 might not be putting OpenAI’s best foot forward. Microsoft Copilot, powered by OpenAI models, also supports a frictionless, no-login experience, but it allows access to a model based on GPT-4. But Gemini currently requires a sign-in, and Anthropic sends a login code through email.
For now, OpenAI says the login-free version of ChatGPT is not yet available to everyone, but it will be coming soon: “We’re rolling this out gradually, with the aim to make AI accessible to anyone curious about its capabilities.”




















{kind=link}