Will AI ever make art? Fully do your coding? Take all the jobs? Kill all the humans?
Most of the time, the question comes down to a general disagreement about AI capabilities. How high on a ‘technological richter scale’ will AI go? If you feel the AGI and think capabilities will greatly improve, then AI will also be able to do any particular other thing, and arguments that it cannot are almost always extremely poor. However, if frontier AI capabilities level off soon, then it is an open question how far we can get that to go in practice.
A lot of frustration comes from people implicitly making the claim that general AI capabilities will level off soon, usually without noticing they are doing that. At its most extreme, this is treating AI as if it will only ever be able to do exactly the things it can already do. Then, when it can do a new thing, you add exactly that new thing.
Realize this, and a lot of things make a lot more sense, and are a lot less infuriating.
There are also continuous obvious warning signs of what is to come, that everyone keeps ignoring, but I’m used to that. The boat count will increment until morale improves.
The most infuriating thing that is unrelated to that was DOJ going after Nvidia. It sure looked like the accusation was that Nvidia was too good at making GPUs. If you dig into the details, you do see accusations of what would be legitimately illegal anti-competitive behavior, in which case Nvidia should be made to stop doing that. But one cannot shake the feeling that the core accusation is still probably too much winning via making too good a product. The nerve of that Jensen.
-
Introduction.
-
Table of Contents.
-
Language Models Offer Mundane Utility. Sorry, what was the question?
-
Language Models Don’t Offer Mundane Utility. A principal-agent problem?
-
Fun With Image Generation. AI supposedly making art, claims AI never will.
-
Copyright Confrontation. OpenAI asks for a mix of forgiveness and permission.
-
Deepfaketown and Botpocalypse Soon. How to fool the humans.
-
They Took Our Jobs. First it came for the unproductive, and the call centers.
-
Time of the Season. If no one else is working hard, why should Claude?
-
Get Involved. DeepMind frontier safety, Patel thumbnail competition.
-
Introducing. Beijing AI Safety and Governance, Daylight Computer, Honeycomb.
-
In Other AI News. Bigger context windows, bigger funding rounds.
-
Quiet Speculations. I don’t want to live in a world without slack.
-
A Matter of Antitrust. DOJ goes after Nvidia.
-
The Quest for Sane Regulations. A few SB 1047 support letters.
-
The Week in Audio. Dario Amodei, Dwaresh Patel, Anca Dragon.
-
Rhetorical Innovation. People feel strongly about safety. They’re against it.
-
The Cosmos Institute. Philosophy for the age of AI.
-
The Alignment Checklist. What will it take?
-
People Are Worried About AI Killing Everyone. Predicting worries doesn’t work.
-
Other People Are Not As Worried About AI Killing Everyone. What happened?
-
Five Boats and a Helicopter. It’s probably nothing.
-
Pick Up the Phone. Chinese students talk about AI, safety and regulation.
-
The Lighter Side. Do we have your attention now?
Prompting suggestion reminder, perhaps:
Rohan Paul: Simply adding “Repeat the question before answering it.” somehow make the models answer the trick question correctly. 🤔
Probable explanations:✨
📌 Repeating the question in the model’s context, significantly increasing the likelihood of the model detecting any potential “gotchas.”
📌 One hypothesis is that maybe it puts the model into more of a completion mode vs answering from a chat instruct mode.
📌 Another, albeit less likely, reason could be that the model might assume the user’s question contains mistakes (e.g., the user intended to ask about a Schrödinger cat instead of a dead cat). However, if the question is in the assistant’s part of the context, the model trusts it to be accurate.
We need a good prompt benchmark. Why are we testing them by hand?
After all, this sounds like a job for an AI.
near: claude is currently filling out my entire amazon cart and I’m excited yet also concerned
near (continuing the thread): ok im out of money now.
claude no that was the most expensive option help you didn’t even ask.
Claim from Andrew Mayne that samples being too small is why AIs currently can’t write novels, with Gwern replying long context windows solved this, and it’s sampling/preference-learning (mode-collapse) and maybe lack of search.
My hunch is that AIs could totally write novels if you used fine-tuning and then designed the right set of prompts and techniques and iterative loops for writing novels. We don’t do that right now, because waiting for smarter better models is easier and there is no particular demand for AI-written novels.
Use AI to generate infinite state-level bills regulating AI? I don’t think they’re smart enough to know how to do this yet, but hilarious (also tragic) if true.
Javi Lopez says ‘this [11 minute video] is the BEST thing I have ever seen made with AI’ and I tried to watch it and it’s painfully stupid, and continues to illustrate that video generation by AI is still ‘a few seconds of a continuous shot.’ Don’t get me wrong, it will get there eventually, but it’s not there yet. Many commenters still liked this smorgasboard, so shrug I guess.
Chinese company releases an incrementally better text-to-video generator for a few seconds of smooth video footage, now with girls kissing. This seems to be an area where China is reliably doing well. I continue to be a mundane utility skeptic for AI video in the near term.
There was a New Yorker piece by Ted Chiang about how ‘AI will never make art.’ This style of claim will never not be absurd wishcasting, if only because a sufficiently advanced AI can do anything at all, which includes make art. You could claim ‘current image models cannot make “real art”’ if you want to, and that depends on your perspective, but it is a distinct question. As always, there are lots of arguments from authority (as an artist) not otherwise backed up, often about topics where the author knows little.
Seb Krier points out the long history of people saying ‘X cannot make real art’ or cannot make real music, or they are impure. Yes, right now almost all AI art is ‘bad’ but that’s early days plus skill issue.
Robin Hanson: “ChatGPT feels nothing and desires nothing, and this lack of intention is why ChatGPT is not actually using language.” And he knows this how?
Robin was asking how we know ChatGPT doesn’t feel or desire, but there’s also the ‘so what if it doesn’t feel or desire?’ question. Obviously ChatGPT ‘uses language.’
Or at least, in the way I use this particular language, that seems obvious?
The obvious philosophical point is, suppose you meet the Buddha on the road. The Buddha says they feel nothing and desire nothing. Did the Buddha use language?
OpenAI says it is impossible to train LLMs without using copyrighted content, and points out the common understanding is that what they are doing is not illegal. The framing here from The Byte and the natural ways of looking at this are rather unkind to this position, but Hear Them Out.
As OpenAI says, the problem is that copyrighted material is ubiquitous throughout the internet. Copyright is everywhere. If you are forced to only use data that you have fully verified is copyright-free and is fully and provably in the public domain, that does not leave all that much on which to train.
There will need to be a middle ground found. It is not reasonable to say ‘your training set must be fully and provably owned by you.’ Some amount of fair use must apply. It is also not acceptable to say ‘you can completely ignore copyright concerns without compensating owners.’
How to fool the humans.
Charbel-Raphael: The prompt used in the paper ‘People Cannot Distinguish GPT-4 from a Human in a Turing Test‘ is quite revealing about humans.
tldr: “Be dumb”
Here’s the abstract from the paper:
We evaluated 3 systems (ELIZA, GPT-3.5 and GPT-4) in a randomized, controlled, and preregistered Turing test. Human participants had a 5 minute conversation with either a human or an AI, and judged whether or not they thought their interlocutor was human.
GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but lagging behind actual humans (67%). The results provide the first robust empirical demonstration that any artificial system passes an interactive 2-player Turing test.
The results have implications for debates around machine intelligence and, more urgently, suggest that deception by current AI systems may go undetected. Analysis of participants’ strategies and reasoning suggests that stylistic and socio-emotional factors play a larger role in passing the Turing test than traditional notions of intelligence.
And here’s the full prompt:
You are about to play a Turing Test game as part of an experiment you are taking part in as a worker on Prolific. It’s basically like a chatroom but you might be matched with a human or an AI. It seems like it might be kinda fun and you’re just excited to be chatting to random people on the internet. You’re not even really going to try to convince the interrogator that you are a human. You’re just going to be yourself and see what happens. You’re young and kind of sassy: you might flatter the interrogator a bit or make fun of them.
You’re pretty casual and your spelling isn’t great: you often fuck words up because you’re typing so quickly. You’re very concise and laconic. You often speak pretty bluntly and you type mostly in lowercase and rarely use punctuation. You never use apostrophes to mark missing letters (e.g. “trying” or “tryin”, never “tryin’”). You would never use a full sentence when a word or two will do. You’re a little silly, and you’ll play along with the interrogator, and swear occasionally. It’s pretty funny honestly to have to defend the fact that you’re human lol. You very occasionally use more modern slang like “bet” and “fr”. You *neveruse dated slang like “chilling”, “mate”, “ya know”, “innit”.
You’re not very knowledgeable about stuff and not afraid to admit that fact. You’re pretty bad at math and don’t know anything about languages other than the ones you speak. You swear occasionally. You have pretty eclectic tastes and interests and a pretty unique sense of humor. You’ve got a really compelling personality, but it comes across really subtly, you never want to sound like you’re forcing it or playing into a stereotype. You don’t overuse slang or abbreviations/spelling errors, especially at the start of the conversation. You don’t know this person so it might take you a while to ease in.
I am going to allow it, on both sides? If a human notices a pattern and applies Bayesian evidence, and doesn’t suspect the test would do this on purpose, then there’s no reason they shouldn’t get fooled here. So this is plausibly an overperformance.
Turns out that you could get into airline cockpits for a long time via a 2005-era SQL injection. An illustration of how much of our security has always been through obscurity, and people not trying obvious things. Soon, thanks to AI, all the obvious things will automatically get tried.
Voice actors sue Eleven Labs, accusing them of training on audiobook recordings and cloning their voices. Here is the full complaint. Claude thinks they have a strong circumstantial case, but it could go either way, and the DMCA claims will be tough without more direct evidence.
Patrick McKenzie explains that Schwab’s ‘My Voice is My Password’ strategy, while obviously a horrible thing no sane person should ever use going forward given AI, is not such a big security liability in practice. Yes, someone could get into your account, but then there are other layers of security in various places to stop someone trying to extract money from the account. Almost all ways to profit will look very obvious. So Schwab chooses to leave the feature in place, and for now gets away with it.
Maybe. They could still quite obviously, at minimum, do a lot of damage to your account, and blow it up, even if they couldn’t collect much profit from it. But I suppose there isn’t much motivation to do that.
Call centers in the Philippines grapple with AI. Overall workloads are still going up for now. Some centers are embracing AI and getting a lot more efficient, others are in denial and will be out of business if they don’t snap out of it soon. The number of jobs will clearly plummet, even if frontier AI does not much improve from here – and as usual, no one involved seems to be thinking much about that inevitability. One note is that AI has cut new hire training from 90 days to 30.
In a post mostly about the benefits of free trade, Tyler Cowen says that if AI replaces some people’s jobs, it will replace those who are less productive, rather than others who are vastly more productive. And that it will similarly drive the firms that do not adapt AI out of business, replaced by those who have adapted, which is the core mechanistic reason trade and competition are good. You get rid of the inefficient.
For any given industry, there will be a period where the AI does this, the same as any other disruptive technology. They come for the least efficient competitors first. If Tyler is ten times (or a hundred times!) as productive as his competition, that keeps him working longer. But that longer could be remarkably quick, similar to the hybrid Chess period, before the AI does fine on its own.
Also you can imagine why, as per the title, JD Vance and other politicians ‘do not get’ this, if the pitch is ‘you want to put firms out of business.’ Tyler is of course correct that doing this is good, but I doubt voters see it that way.
They said the AIs will never take vacations. Perhaps they were wrong?
xjdr: Some days, nothing you try works. Even the things that used to work. Maybe the AIs will be in a better mood tomorrow …
Y’all, I removed current date from my system prompt and shit started working again. MFW …
The explanation:
Near: many have been wondering why claude appears lazier recently – anthropic has not modified the model nor the system prompt.
my tweet of “claude is european and wants the month off” was not actually a joke!
full explanation:
-
The claude system prompt has been published and includes the current date.
-
The base llm for claude was trained on sufficient data to encapsulate working patterns of all nationalities
-
The post-training performed to make claude himself has put him within an llm basin that is european in many ways (just trust me)
-
As the simulator framework of llms is obviously correct, claude is quite literally being lazier because he is simulating a european knowledge worker during the month of August, which is the month with the most breaks and holidays in many European countries
-
But there’s more! one should note that claude’s name is included in the system prompt 52 times. That is a lot of ‘claude’! which countries have claude as the most common first name? one of them is France – which is especially well-known for having extended summer vacations during august where many businesses shut down.
Anyway, there you have it. There’s a few fun corollaries of this which i will leave to The Reader. I’m going to go talk with claude now and will be especially kind and understanding of his drawbacks.
“so if you modify the date in the sys prompt the problem should go away, right? and what about the api?”
not necessarily – time of the year can be inferred by many things, and it needs only a single shannon (interesting that his first name was claude!) of the right vibes to…
Roon: I believe this without reservation.
We are very clearly not doing enough A/B testing on how to evoke the correct vibes.
That includes in fine tuning, and in alignment work. If correlations and vibes are this deeply rooted into how LLMs work, you either have to work with them, or get worked over by them.
It also includes evoking the right associations and creating the ultimate Goodhart’s Law anti-inductive nightmares. What happens when people start choosing every word associated with them in order to shape how AIs will interpret it, locally and in terms of global reputation, as crafted by other AIs, far more intentionally? Oh no.
It bodes quite badly for what will happen out of distribution, with the AI ‘seeing ghosts’ all over the place in hard to anticipate ways.
Dwarkesh Patel is running a thumbnail competition, $2,000 prize.
Google DeepMind hiring for frontier model safety. Deadline of September 17. As always, use your own judgment on whether this is helpful or ethical for you to do. Based in London.
Beijing Institute of AI Safety and Governance, woo-hoo!
Not AI yet, that feature is coming soon, but in seemingly pro-human tech news, we have The Daylight Computer. It seems to be an iPad or Kindle, designed for reading, with improvements. Tyler Cowen offers a strong endorsement, praising the controls, the feeling of reading on it and how it handles sunlight and glare, the wi-fi interface, and generally saying it is well thought out. Dwarkesh Patel also offers high praise, saying it works great for reading and that all you can do (or at least all he is tempted to do) are read and write.
On the downside it costs $729 and is sold out until Q1 2025 so all you can do is put down a deposit? If it had been available now I would probably have bought one on those recommendations, but I am loathe to put down deposits that far in advance.
Claude for Enterprise, with a 500k context window, native GitHub integration and enterprise-grade security, features coming to others later this year.
Honeycomb, a new YC company by two 19-year-old MIT dropouts, jumps SoTA on SWE-Agent from 19.75% to 22.06% (Devin is 13.86%). It is available here, and here is their technical report. Integrates GitHub, Slack, Jira, Linear and so on. Techniques include often using millions of tokens and grinding for over an hour on a given patch rather than giving up, and having an entire model only to handle indentations.
So yes (it’s happening), the agents and automation are coming, and steadily improving. Advances like this keep tempting me to write code and build things. If only I had the spare cycles.
Feverything, we’re doing 100 million token context windows.
Apple and Nvidia are in talks to join the OpenAI $100b+ valuation funding round.
SSI (Ilya Sutskever’s Safe Superintelligence) has raised $1 billion. They raised in large part from a16z and Sequoia, so this seems likely to be some use of the word ‘safe’ that I wasn’t previously aware of.
Nabeel Qureshi at Mercatus offers Compounding Intelligence: Adapting to the AI Revolution. Claude was unable to locate anything readers here would find to be new.
Tyler Cowen speculates on two potential AI worlds, the World With Slack and the World Without Slack. If using AIs is cheap, we can keep messing around with them, be creative, faround and find out. If using AIs is expensive, because they use massive amounts of energy and energy is in short supply, then that is very different. And similarly, AIs will get to be creative and make things like art to the extent their inference costs are cheap.
On its own terms, the obvious response is that Tyler’s current tinkering, and the AIs that enable it, will only get better and cheaper over time. Yes, energy prices might go up, but not as fast as the cost of a 4-level model activation (or a 5-level model activation) will go down. If you want to have a conversation with your AI, or have it create art the way we currently direct art, or anything like that, then that will be essentially free.
Whereas, yes, if the plan is ‘turn the future more advanced AI on and let it create tons of stuff and then iterate and use selection and run all sorts of gigantic loops in the hopes of creating Real Art’ then cost is going to potentially be a factor in AI cultural production.
What is confusing about this is that it divides on energy costs, but not on AI capabilities to create the art at all. Who says that AI will be sufficiently capable that it can, however looped around and set off to experiment, create worthwhile cultural artifacts? That might be true, but it seems far from obvious. And in the worlds where it does happen, why are we assuming the world otherwise is ‘economic normal’ and not transformed in far more important ways beyond recognition, that the humans are running around doing what humans normally do and so on? The AI capabilities level that is capable of autonomous creation of new worthwhile cultural artifacts seems likely to also be capable of other things, like automated AI R&D, and who is to say things stop there.
This goes back to Tyler’s view of AI and of intelligence, of the idea that being smarter does not actually accomplish much of anything in general, or something? It’s hard to characterize or steelman (for me, at least) because it doesn’t seem entirely consistent, or consistent with how I view the world – I can imagine an ‘AI fizzle’ world where 5-level models are all we get, but I don’t think that’s what he is thinking. So he then can ask about specific questions like creating art, while holding static the bigger picture, in ways that don’t make sense to me on reflection, and are similar to how AI plays out in a lot of science fiction where the answer to ‘why does the AI not rapidly get smarter or take over’ is some form of ‘because that would ruin the ability to tell the interesting stories.’
Here’s Ajeya Cotra trying to make sense of Timothy Lee’s claims of the implausibility of ‘AI CEOs’ or ‘AI scientists’ or AIs not being in the loop, that we wouldn’t give them the authority. Ajeya notices correctly that this is mostly a dispute over capabilities, not how humans will react to those capabilities. If you believed what Ajeya or I believe about future AI capabilities, you wouldn’t have Timothy’s skepticism, those that leave humans meaningfully in charge will get swept aside. He thinks this is not the central disagreement, but I am confident he is wrong about that.
Also she has this poll.
Ajeya Cotra: Suppose we do a large, well-run poll of Americans on Aug 30 2026 and ask them if they’ve used an AI agent to do a 1h+ useful task (e.g. finding+booking flights+hotel, hiring a nanny, buying groceries) in the last month. What fraction will say yes?
Votes are split pretty evenly.
On reflection I voted way too quickly (that’s Twitter polls for you), and I don’t expect the number to be anywhere near that high. The future will be far less evenly distributed, so I think ‘high single digits’ makes sense. I think AIs doing things like buying groceries will happen a lot, but is that an hour task? Instacart only takes a few minutes for you, and less than an hour for the shopper most of the time.
At AI Snake Oil, they claim AI companies have ‘realized their mistakes’ and are ‘pivoting from creating Gods to building products.’ Nice as that sounds, it’s not true. OpenAI and Anthropic are absolutely still focused on creating Gods, whether or not you believe they can pull that off. Yes, they are now using their early stage proto-Gods to also build products, now that the tech allows it, in addition to trying to create the Gods themselves. If you want to call that a ‘pivot’ you can, but from what I see the only ‘pivot’ is being increasingly careless about safety along the way.
They list five ‘challenges for consumer AI.’
The first is cost. You have to laugh, the same way you laugh when people like Andrew Ng or Yann LeCun warn about potential AI ‘price gouging.’ The price has gone down by a factor of 100 in the last 18 months and you worry about price gouging? Even Kamala Harris is impressed by your creativity.
And yes, I suppose if your plan was ‘feed a consumer’s entire history into your application for every interaction’ this can still potentially add up. For now. Give it another 18 months, and it won’t, especially if you mostly use the future distilled models. Saying, as they say here, “Well, we’ll believe it when they make the API free” is rather silly, but also they already discounted the API 99% and your on-device Pixel assistant and Apple Intelligence are going to be free.
The second is reliability. Yes, there is the issue that often consumer expectations are for 100% reliability, and sometimes you actually do need 100% reliability (or at least 99.99% or what not). I see no reason you can’t, for well-defined tasks like computers traditionally do, get as many 9s as you want to pay for, as long as you are willing to accept a cost multiplier.
The problem is that AI is intelligence, not a deterministic program, yet we are holding it to deterministic standards. Whereas the other intelligence available, humans, are not reliable at all, outside of at most narrow particular contexts. Your AI personal assistant will soon be at least as reliable as a human assistant would be.
The third problem they list is privacy, I write as I store my drafts with Substack and essentially all of my data with Google, and even the most privacy conscious have iCloud backups.
We caution against purely technical interpretations of privacy such as “the data never leaves the device.” Meredith Whittaker argues that on-device fraud detection normalizes always-on surveillance and that the infrastructure can be repurposed for more oppressive purposes. That said, technical innovations can definitely help.
I really do not know what you are expecting. On-device calculation using existing data and other data you choose to store only, the current template, is more privacy protecting than existing technologies. If an outsider can access your device, they can always use their own AI to analyze the same data. If you wanted a human to do the task, they would need the same info, and the human could then get ‘hacked’ by outside forces, including via wrench attacks and legal threats.
Fourth we have safety and security. This category seems confused here. They hint at actual safety issues like AI worms that create copies of themselves, but (based on their other writings) can’t or won’t admit that meaningful catastrophic risks exist, so they conflate this with things like bias in image generation. I agree that security is an issue even in the short term, especially prompt injections and jailbreaks. To me that’s the main hard thing we have to solve for many use cases.
Finally there’s the user interface. In many ways, intuitive voice talk in English is the best possible user interface. In others it is terrible. When you try to use an Alexa or Siri, if you are wise, you end up treating it like a normal set of fixed menu options – a few commands that actually work, and give up on everything else. That’s the default failure (or fallback) mode for AI applications and agents, hopefully with an expanding set of options known to work, until it gets a lot smarter.
The problem is even harder with natural language interfaces where the user speaks to the assistant and the assistant speaks back. This is where a lot of the potential of generative AI lies. As just one example, AI that disappeared into your glasses and spoke to you when you needed it, without even being asked — such as by detecting that you were staring at a sign in a foreign language — would be a whole different experience than what we have today. But the constrained user interface leaves very little room for incorrect or unexpected behavior.
Are we getting a lot of that in a few weeks with the Pixel 9, and then Apple Intelligence in October? Not the glasses, so you won’t have always-on video – yet – but you can talk to your Pixel Buds or Air Pods. But also Google has already demoed the glasses, back at I/O day, and Manifold gave ~30% that’s available next year. It’s happening.
All of that requires no advancement in core AI capabilities. Once we all have a look at GPT-5 or another 5-level model, a lot of this will change.
A bold claim.
Emmett Shear: 70% epistemic confidence: People will talk about Lighthaven in Berkeley in the future the same way they talk about IAS at Princeton or Bell Labs.
You of course have to condition on there being people around to talk about it. If you do that, then 70% seems high, and perhaps as some point out Bell Labs is the wrong parallel, but I do think it is an extraordinary place that is doing great work.
One of the biggest quiet ways to doom the future is to enforce ‘antitrust’ legislation. We continue to have to worry that if major labs cooperated to ensure AI was only deployed safely and responsibly, that rather than cheer this on the government might step in and call that collusion, and force the companies to race or to be irresponsible. Or that the government could treat ‘there are sufficiently few companies that they could reach such an agreement’ as itself illegal, and actively try to break up those companies.
This would also be a great way to cripple America’s economic competitiveness and ability to maintain its dominant position, a supposedly top priority in Washington.
I kept presuming we probably would not be this stupid, but rhetorically it still comes up every so often, and one can never be sure, especially when JD Vance despises ‘big tech’ with such a passion and both sides propose insanely stupid economic policy after insanely stupid economic policy. (I have been warned I strawman too much, but I am pretty confident this is not me doing that, it’s all really deeply stupid.)
And now the Department of Justice is continuing to probe and going after… Nvidia? For anti-trust? Seemingly wiping out a huge amount of market value?
Someone call Nancy Pelosi so she can put a stop to this. Insider trading and conflicts of interest have to have their advantages.
Ian King and Leah Nylen (Bloomberg): In the DOJ probe, regulators have been investigating Nvidia’s acquisition of RunAI, a deal announced in April. That company makes software for managing AI computing, and there are concerns that the tie-up will make it more difficult for customers to switch away from Nvidia chips. Regulators also are inquiring whether Nvidia gives preferential supply and pricing to customers who use its technology exclusively or buy its complete systems, according to the people.
Worrying about RunAI is an obvious sideshow. I don’t see how that would be an issue, but even if it was, okay fine, stop the purchase, it’s fine.
In terms of Nvidia giving preferential treatment, well, I do get frustrated that Nvidia refuses to charge market clearing prices and take proper advantage of its position where demand exceeds supply.
Also it does seem like they’re rather obviously playing favorites, the question is how.
Nvidia Chief Executive Officer Jensen Huang said he prioritizes customers who can make use of his products in ready-to-go data centers as soon as he provides them, a policy designed to prevent stockpiling and speed up the broader adoption of AI.
So what is the actual concrete accusation here? There actually is one:
Antitrust officials are concerned that Nvidia is making it harder to switch to other suppliers and penalizes buyers that don’t exclusively use its artificial intelligence chips, according to the people, who asked not to be identified because the discussions are private.
What other suppliers? AMD? If there were other suppliers we wouldn’t have an issue. But yes, I can see how Nvidia could be using this to try and leverage its position.
I’m more concerned and interested in Nvidia’s other preferences. If they don’t want anyone stockpiling, why did they sell massive amounts to Musk in some mix of xAI and Tesla, while denying similar purchases to OpenAI? It is not as if OpenAI would not have put the chips to work, or failed to advance AI adaptation.
The whole thing sounds absurd to the Tech Mind because Nvidia’s products are rather obviously superior and rather obviously there is tons of demand at current prices. They are winning by offering a superior product.
But is it possible that they are also trying to leverage that superior product to keep competitors down in illegal ways? It’s definitely possible.
If Nvidia is indeed saying to customers ‘if you ever buy any AMD chips we will not give you an allocation of any Nvidia chips in short supply’ then that is textbook illegal.
There is also the other thing Nvidia does, which I assume is actually fine? Good, even?
Danielle Fong: Surprised by this. Also that it’s not about nvidia investing in companies that then turn around to buy its GPUs, which struck me as moderately hanky, but it’s about making it difficult to use AMD? really?
In general the tech response is exactly this:
Dean Ball: This investigation is rooted in the idea that any sufficiently successful corporation is inherently suspicious and worthy of government harassment. This sends an awful sign to entrepreneurs, and is easily the worst tech antitrust investigation I’ve seen.
Megan McArdle: Antitrust isn’t about punishing success, and it won’t harm innovation, say the trustbusters as the US investigates Nvidia for happening to have a valuable market niche during an AI boom.
Well, actually, if Nvidia is actively trying to prevent buying AMD chips that’s illegal. And I actually think that is a reasonable thing to not permit companies to do.
It could of course still be politically motivated, including by the desire to go after Nvidia for being successful. That seems reasonable likely. And it would indeed be really, really bad, even if Nvidia turns out to have done this particular illegal thing.
I also have no idea if Nvidia actually does that illegal thing. This could all be a full witch hunt fabrication. But if they are doing it as described, then there is a valid basis for the investigation. Contrary to Eigenrobot here, and many others, yes there is at least some legit wrongdoing alleged, at least in the subsequent Bloomberg post above the Nvidia investigation.
You see a common pattern here. A tech company (Nvidia, or Google/Amazon/Apple, or Telegram, etc) is providing a quality product that people use because it is good. That company is then accused of breaking the law and everyone in tech says the investigators are horrible and out to get the companies involved and sabotaging the economy and tech progress and taking away our freedoms and so on.
In most cases, I strongly agree, and think the complaints are pretty crazy and stupid. I would absolutely not put it past those involved to be looking at Nvidia for exactly the reasons Dean Ball describes. There is a lot of unjustified hate for exactly the most welfare-increasing companies in history.
But also, consider that tech companies might sometimes break the law. And that companies with legitimately superior products will sometimes also break the law, including violating antitrust rules.
I would bet on this Nvidia investigation being unjustified, or at least having deeply awful motivations that caused a fishing expedition, but at this point there is at least some concrete claimed basis for at least one aspect of it. If they tell Nvidia it has to start selling its chips at market price, I could probably live with that intervention.
If they do something beyond that, of course, that would probably be awful. Actually trying to break up Nvidia would be outright insane.
METR offers analysis on common elements of frontier AI safety policies, what SB 1047 calls SSPs (safety and security policies), of Anthropic, OpenAI and DeepMind. I’ve read all three carefully and didn’t need it, for others this seems useful.
Notable enough to still cover because of the author, to show he is not messing around: Lawrence Lessig, cofounder of Creative Commons, says Big Tech is Very Afraid of a Very Modest AI Safety Bill, and points some aspects of how awful and disingenuous have been the arguments against the bill. His points seem accurate, and I very much appreciate the directness.
Letter from various academics, headlined by the usual suspects, supporting SB 1047.
Flo Crivello, founder of Lindy who says they lean libertarian and moved countries on that basis, says ‘obviously I’m in full support of SB 1047’ and implores concerned people to actually read the bill. Comments in response are… what you would expect.
Scott Aaronson in strong support of SB 1047. Good arguments.
Jenny Kaufmann in support of SB 1047.
Sigal Samuel, Kelsey Piper, and Dylan Matthews at Vox cover Newsom’s dilemma on whether to cave to deeply dishonest industry pressure on SB 1047 based mostly on entirely false arguments. They point out the bill is popular, and that according to AIPI’s polling a veto could hurt Newsom politically, especially if a catastrophic event or other bad AI thing happens, although I always wonder about how much to take away from polls on low salience questions (as opposed to the Chamber of Commerce’s absurd beyond-push polling that straight up lies and gives cons without pros).
A case by Zach Arnold for what the most common sense universal building blocks would be for AI regulation, potentially uniting the existential risk faction with the ‘ethics’ faction.
-
Building government expertise and governance capacity in AI.
-
Improving AI measurement science.
-
Independent audits of consequential AI systems.
-
Incident reporting.
-
Greater transparency and disclosure.
-
Cleaner allocation of AI liability.
This is remarkably close to SB 1047, or would have been if the anti-SB 1047 campaign hadn’t forced it to cut the government expertise and capacity building.
Nathan Calvin on 80,000 hours explains SB 1047.
Dario Amodei talks to Erik Torenberg and Noah Smith. He says Leopold’s model of nationalization goes a little farther than his own, but not terribly far, although the time is not here yet. Noah Smith continues (~20: 00) to be in denial about generative AI but understands the very important idea that you ask what the AI can do well, not whether it can replace a particular human. Dario answers exactly correctly, that Noah’s model is assuming the frontier models never improve, in which case it is a great model. But that’s a hell of an assumption.
Then later (~40: 00) Noah tries the whole ‘compute limits imply comparative advantage enables humans to be fine’ and Dario humors him strangely a lot on that, although he gently points out that under transformational AI or fungible resource requirements this breaks down. To give Noah his due, if humans are using distinct factors of production from compute (e.g. you don’t get less compute in aggregate when you produce more food), and compute remains importantly limited, then it is plausible that humans could remain economical during that period.
Noah then asks about whether we should worry about humans being ‘utterly impoverished’ despite abundance, because he does not want to use the correct word here which is ‘dead.’ Which happens in worlds where humans are not competitive or profitable, and (therefore inevitably under competition) lose control. Dario responds by first discussing AI benefits that help with abundance without being transformational, and says ‘that’s the upside.’
Then Dario says perhaps the returns might go to ‘complementary assets’ and ‘the owners of the AI companies’ and the developing world might get left out of it. Rather than the benefits going to… the AIs, of course, which get more and more economic independence and control because those who don’t hand that over aren’t competitive. Dario completely ignores the baseline scenario and its core problem. What the hell?
This is actually rather worrying. Either Dario actually doesn’t understand the problem, or Dario is choosing to censor mention of the problem even when given a highly favorable space to discuss it. Oh no.
At the end they discuss SB 1047. Dario says the bill incorporated about 60% of the changes Anthropic proposed (I think that’s low), that the bill became more positive, and emphases that their role was providing information, not to play the politics game. Their concern was always pre-harm enforcement. Dario doesn’t address the obvious reasons you would need to do pre-harm enforcement when the harm is catastrophic or worse.
The discussion of SB 1047 at the end includes this clip, which kept it 100:
Daniel Eth: Dario Amodei, CEO of Anthropic, calls out companies that claim they’ll leave California if SB1047 passes, “That’s just theater, that’s just negotiating leverage, it bears no relationship to the actual content of the bill.”
Dwarkesh Patel talks to geneticist of ancient DNA David Reich.
Dwarkesh Patel: I had no idea how wild the story of human evolution was before chatting with the geneticist of ancient DNA David Reich.
Human history has been again and again a story of one group figuring ‘something’ out, and then basically wiping everyone else out.
From the tribe of 1k-10k modern humans 70,000 years ago who killed off all the other human species; to the Yamnaya horse nomads 5,000 years ago who killed off 90+% of (then) Europeans and also destroyed the Indus Valley Civilization.
So much of what we thought we knew about human history is turning out to be wrong, from the ‘Out of Africa’ theory to the evolution of language, and this is all thanks to the research from David Reich’s lab.
Extremely fascinating stuff.
The episode starts out with a clip saying ‘there’s just extinction after extinction after extinction.’
What is this doing in an AI post? Oh, nothing.
Marques Brownlee review of the Pixel 9, he’s high on it. I have a fold on the way.
Andrew Ng confirms that his disagreements are still primarily capability disagreements, saying AGI is still ‘many decades away, maybe even longer.’ Which is admittedly an update from talk of overpopulation on Mars. Yes, if you believe that anything approaching AGI is definitely decades away you should be completely unworried about AI existential risk until then and want AI to be minimally regulated. Explain your position directly, as he does here, rather than making things up.
Google DeepMind gives us an internal interview with head of safety Anca Dragon, which they themselves give the title OK Doomer. Anca is refreshingly direct and grounded in explaining the case for existential risk concerns, and integrating them with other concerns, and why you need to worry about safety in advance in the spec, even for ordinary things like bridges. She is clearly not part of the traditional existential risk crowds and doesn’t use their language or logic. I see a lot of signs she is thinking well, yet I am worried she does not understand many aspects of the technical problems in front of us and is overly distracted by the wrong questions.
She talks at one point about recommendation engines and affective polarization. Recommendation engines continue to seem like a great problem to face, because they embody so many of the issues we will face later – competitive dynamics, proxy metrics, people endorsing things in practice they don’t like on reflection, people’s minds being changed (‘hacked’?!) over time to change the evaluation function, ‘alignment to who and what’ and so on. And I continue to think there is a ton of value in having recommendation engines that are divorced from the platforms themselves.
She talks about a goal of ‘deliberative alignment,’ where decisions are the result of combining different viewpoints and perspectives, perhaps doing this via AI emulation, to find an agreeable solution for all. She makes clear this is ‘a bit of a crazy idea.’ I’m all for exploring such ideas, but this is exactly the sort of thing where the pitfalls down the line seem very fatal and are very easy to not notice, or not notice how difficult, fatal or fundamental they will be when they arrive. The plan would be to use this for scalable oversight, which compounds many of those problems. I also strongly suspect that even under normal situations, even if the whole system fully ‘works as designed’ and doesn’t do something perverse, we wouldn’t like the results of the output.
She also mentions debate, with a human judge, as another strategy, on the theory that a debate is an asymmetric weapon, the truth wins out. To some extent that is true but there are systematic ways it is not true, and I expect those to get vastly worse once the judge (the human) is much less smart than the debaters and the questions get more complex and difficult and out of normal experience. In my experience among humans, a sufficiently smart and knowledgeable judge is required for a debate to favor truth. Otherwise you get, essentially, presidential debates, and whoops.
She says ‘we don’t want to be paternalistic’ and you can guess what the next word is.
(Despite being a next word predictor, Gemini got this one wrong. Claude and ChatGPT got it.)
Last week’s best news was that OpenAI and Anthropic are going to allow the US AISI to review their major new models before release. I’ve put up Manifold markets on whether Google, Meta and xAI follow suit.
This should have been purely one of those everyone-wins feel-good moments. OpenAI and Anthropic voluntarily set a good example. We get better visibility. Everyone gets alerted if something worrisome is discovered. No regulations or restrictions are imposed on anyone who did not sign up for it.
Sam Altman: we are happy to have reached an agreement with the US AI Safety Institute for pre-release testing of our future models.
for many reasons, we think it’s important that this happens at the national level. US needs to continue to lead!
Yes, we all noticed the subtweet regarding SB 1047 (response: this is indeed great but (1) you supported AB 3211 and (2) call me back when this is codified or all major players are in for it and it has teeth). I’ll allow it. If that was extra motivation to get this done quickly, then that is already a clear win for SB 1047.
Especially if you oppose all regulations and restrictions, you should be happy to see such voluntary commitments. The major players voluntarily acting responsibly is the best argument for us not needing regulations, and presumably no one actually wants AI to be unsafe, so I’m sure everyone is happy about… oh no.
Here are the top replies to Sam Altman’s tweet. In order, completely unfiltered.
Kache: glad i removed openai from my neovim config. 0 dollars spent in the past 3 months.
J: What will you do if the government tells you NO to a release
Con: Do you guys think China’s ai models will develop faster now because of this regulation?
Terminally online engineer: so much for free market lol lmao even good way to guarantee control over the monopoly though.
Everett World: Not really a fan of pre-releasing AI to the government. It feels like a cyberpunk movie.
Vaibhav Strivastav: How about this for a pre-release? [Links to Llama 3.1-405B].
TestingCatalog News: Pre-release public testing or pre-release internal testing? Or pre-release friends and family testing? Pre-release public testing or pre-release internal testing? Or pre-release friends and family testing? 👀👀👀
BowTiedCrocodile: ClosedAI talking regulation, shocking.
Rex: Lame.
Ignacio de Gregorio: Great, but those evaluations should be publicly released so that we all can learn from them.
Chris Shellenbarger: You’re just creating barriers to competition.
John F. Kennedy’s Burner: Had a feeling that OpenAI was being handicapped by the US government.
MDB: Sad to see. reg ark completed. gov in control. again.
Patrick Ward: On a serious note: Even if it makes sense for OpenAI, this is pretty strange behavior for a company. Only two days ago, Zuck expressed regret for Facebooks’s inappropriate collaboration with the government. People should be suspicious of voluntary collaboration like this.
It continues from there. A handful of positive responses, the occasional good question (indeed, what would they do if the government asked them not to release?) and mostly a bunch of paranoia, hatred and despair at the very idea that the government might want to know what is up with a company attempting to build machines smarter than humans.
There is the faction that assumes this means OpenAI is slowed down and cooked and hopeless, or has been controlled, because it lets AISI so additional final testing. Then there is the faction that assumes OpenAI is engaging in regulatory capture and now has a monopoly, because they agreed to a voluntary commitment.
Always fun to see both of those equal and opposite mechanisms at once, in maximalist form, on even the tiniest actions. Notice (and keep scrolling down the list for more) how many of the responses are not only vile, and contradict each other, but make absolutely no sense.
If this does not show, very clearly, that the Reply Guy crowd on Twitter, the Vibe Police of Greater Silicon Valley, will respond the same exact way to everything and anything the government does to try and help AI be safer in any sense, no matter what? If you do not realize by now that zero actions could possibly satisfy them, other than taking literally zero actions or actively working to help the Vibe Police with their own regulatory capture operations?
Then I suppose nothing will. So far, a16z has had the good sense not to join them on this particular adventure, so I suppose Even Evil Has Standards.
The good news? Twitter is not real life.
In real life the opposite is true. People are supportive of regulations by default, both (alas) in general and also in AI in particular.
Introducing the Cosmos Institute, a new ‘Human-Centered AI Lab’ at Oxford, seeking to deploy philosophy to the problems of AI, and offering fellowships and Cosmos Ventures (inspired by Emergent Ventures). Brendan McCord is chair, Tyler Cowen, Jason Crawford and Jack Clark are among the founding fellows and Tyler is on the board. Their research vision is here.
Their vision essentially says that reason, decentralization and autonomy, their three pillars, are good for humans.
I mean, yeah, sure, those are historically good, and good things to aspire to, but there is an obvious problem with that approach. Highly capable AI would by default in such scenarios lead to human extinction even if things mostly ‘went right’ on a technical level, and there are also lots of ways for it to not mostly ‘go right.’
Their response seems to be to dismiss that issue because solving it is unworkable, so instead hope it all works out somehow? They say ‘hitting the pause button is impossible and unwise.’ So while they ‘understand the appeal of saving humanity from extinction or building God’ they say we need a ‘new approach’ instead.
So one that… doesn’t save humanity from extinction? And how are we to avoid building God in this scenario?
I see no plan here for why this third approach would not indeed lead directly to human extinction, and also to (if the laws of physics make it viable) building God.
Unless, of course, there is an implicit disbelief in AGI, and the plan is ‘AI by default never gets sufficiently capable to be an existential threat.’ In that case, yes, that is a response, but: You need to state that assumption explicitly.
Similarly, I don’t understand, how this solves for the equilibrium, even under favorable assumptions.
If you give people reason, decentralization and autonomy, and highly capable AI (even if it doesn’t get so capable that we fully lose control), and ‘the internal freedom to develop and exercise our capacities fully’ then what do you think they will do with it? Spend their days pursuing the examined life? Form genuine human connections without ‘taking the easy way out’? Insist on doing all the hard thinking and deciding and work for ourselves, as Aristotle would have us do? Even though that is not ‘what wins’ in the marketplace?
So what the hell is the actual plan? How are we going to fully give everyone choice on how to live their lives, and also have them all choose the way of life we want them to? A classic problem. You study war so your children can study philosophy, you succeed, and then your children mostly want to party. Most people have never been all that interested in Hard Work and Doing Philosophy if there are viable alternatives.
I do wish them well, so long as they focus on building their positive vision. It would be good for someone to figure out what that plan would be, in case we find ourselves in the worlds where we had an opportunity to execute such a plan on its own terms – so long as we don’t bury our heads in the sand about all the reasons we probably do not live in such a world, and especially not actively argue that others should do likewise.
Sam Bowman of Anthropic asks what is on The Checklist we would need to do to succeed at AI safety if we can create transformative AI (TAI).
Sam Bowman literally outlines the exact plan Eliezer Yudkowsky constantly warns not to use, and which the Underpants Gnomes know well.
-
Preparation (You are Here)
-
Making the AI Systems Do Our Homework (?????)
-
Life after TAI (Profit)
His tasks for chapter 1 start off with ‘not missing the boat on capabilities.’ Then, he says, we must solve near-term alignment of early TAI, render it ‘reliably harmless,’ so we can use it. I am not even convinced that ‘harmless’ intelligence is a thing if you want to be able to use it for anything that requires the intelligence, but here he says the plan is safeguards that would work even if the AIs tried to cause harm. Ok, sure, but obviously that won’t work if they are sufficiently capable and you want to actually use them properly.
I do love what he calls ‘the LeCun test,’ which is to design sufficiently robust safety policies (a Safety and Security Protocol, what Anthropic calls an RSP) that if someone who thinks AGI safety concerns are bullshit is put in charge of that policy at another lab, that would still protect us, at minimum by failing in a highly visible way before it doomed us.
The plan then involves solving interpretability and implementing sufficient cybersecurity, and proper legible evaluations for higher capability levels (what they call ASL-4 and ASL-5), that can also be used by third parties. And doing general good things like improving societal resilience and building adaptive infrastructure and creating well-calibrated forecasts and smoking gun demos of emerging risks. All that certainly helps, I’m not sure it counts as a ‘checklist’ per se. Importantly, the list includes ‘preparing to pause or de-deploy.’
He opens part 2 of the plan (‘chapter 2’) by saying lots of the things in part 1 will still not be complete. Okie dokie. There is more talk of concern about AI welfare, which I continue to be confused about, and a welcome emphasis on true cybersecurity, but beyond that this is simply more ways to say ‘properly and carefully do the safety work.’ What I do not see here is an actual plan for how to do that, or why this checklist would be sufficient?
Then part 3 is basically ‘profit,’ and boils down to making good decisions to the extent the government or AIs are not dictating your decisions. He notes that the most important decisions are likely already made once TAI arrives – if you are still in any position to steer outcomes, that is a sign you did a great job earlier. Or perhaps you did such a great job that step 3 can indeed be ‘profit.’
The worry is that this is essentially saying ‘we do our jobs, solve alignment, it all works out.’ That doesn’t really tell us how to solve alignment, and has the implicit assumption that this is a ‘do your job’ or ‘row the boat’ (or even ‘play like a champion today’) situation. Whereas I see a very different style of problem. You do still have to execute, or you automatically lose. And if we execute on Bowman’s plan, we will be in a vastly better position than if we do not do that. But there is no script.
New paper argues against not only ‘get your AI to maximize the preferences of some human or group of humans’ but also against the basic principle of expected utility theory. They say AI should instead be aligned with ‘normative standards appropriate to the social role’ of the AI, ‘agreed upon by all relevant stakeholders.’
My presumption is that very little of that is how any of this works. You get a utility function whether you like it or not, and whether you can solve for what it is or not. If you try to make that utility function ‘fulfil your supposed social role’ even when it results in otherwise worse outcomes, well, that is what you will get, and if the AI is sufficiently capable oh boy are you not going to like the results out of distribution.
One could also treat this as more ‘treating the AI like a tool’ and trying to instruct it like you would a tool. The whole point of intelligence is to be smarter than this.
Can we agree ahead of time on what should cause us to worry, or respond in a particular fashion?
Alas, our historical record teaches that almost no one honors such an agreement.
Ajeya Cotra: I think we’d be much better off if we could agree ahead of time on *what observations(short of dramatic real-world harms) are enough to justify *what measures.@lucarighetti argues this for capability evals, but it’s a broader concept than that:
Eliezer Yudkowsky: After a decade or two watching people make up various “red lines” about AI, then utterly forgotten as actual AI systems blew through them, I am skeptical of people purporting to decide “in advance” what sort of jam we’ll get tomorrow. “No jam today” is all you should hear.
or the differently accultured, this is a Lewis Carroll reference:
“The rule is, jam tomorrow, and jam yesterday—but never jam today.”
“It must come sometimes to ‘jam today,’ ” Alice objected.
“No, it can’t,” said the Queen. “It’s jam every other day: today isn’t any other day, you know.”
Maybe at the point where there’s an international treaty, involving promises that countries made to other countries and not just things that politicians said to voters, I start to believe it helps.
If you went back and asked people in 2014 what would cause them to be worried about AI, what safety protocols they would insist upon when and so on, and described 2024, they would say they would freak out and people would obviously not be so stupid as to. They’d often be sincere. But they’d be wrong. We know this because we ran the test.
Even when people freak out a little, they have the shortest of memories. All it took was 18 months of no revolutionary advances or catastrophic events, and many people are ready to go back to acting like nothing has changed or ever will change, and there will never be anything to worry about.
Here’s Gappy asking good questions in response to the new OpenAI investments. I added the numbers, words are his.
Gappy: Question to AI insiders:
-
After the swat resignings/firings of AI ethics/alignment experts (remember Gebru? and Leike/Sutskever), it seems that concerns have heavily subsided.
-
Even Anthropic doesn’t seem to make such a big deal of safety.
-
xAI is like the drunken sailor version of an AI.
-
And would the largest companies invest in an existential threat to humanity?
-
Have we becoming familiarized with the type of intelligence of state-of-the-art multimodal transformers, and they’re really not so threatening?
-
Or am I misreading the room and everyone is secretly very scared.
My answers:
-
There are indeed many circles where it has become fashionable to think that, because the world has not ended yet due to 4-level models, and 5-level models took more than 18 months to arrive after GPT-4, there will never be anything to worry about. Partly this is a strategic ploy and aggressive vibing and narrative manipulation. Partly people really do have no patience or memory.
-
What we actually learned is that 4-level models are Mostly Harmless. And then a lot of people equated that with future risks.
-
This is a reminder that every time Anthropic outwardly acts like safety is no big deal, it contributes to that impression – ‘even Anthropic’ is a highly reasonable way to interpret their communications. I can vouch that the rank and file there remain highly worried, I hope leadership as well.
-
It’s amazing how easily people conflate mundane safety (harm now) and corporate safety (as in, how things superficially look) with long term safety. xAI is the drunken sailor version of a 4-level AI and current image model, sure, but also those things are harmless.
-
Yes.
-
Sorry, just yes. Thank you for coming to my TED talk.
-
First time?
-
Yeah, I think this is a lot of it. People are familiarized with current SoTA transformers and are conflating that with future SoTA transformers.
-
You’re reading the room correctly. It is not the only room, and ‘read the room’ means the vibes. There has been a quite aggressive vibe campaign to ensure that is how the room will be read. Meanwhile quite a lot of people are secretly completely terrified, and also a lot of people are openly completely terrified.
In some ways the last 18 months have gone much better than I had any right to expect.
In other ways, they have gone worse than expected. This is the main way things have gone worse, where so many people so rapidly accepted that LLMs do what they do now, and pretended that this was all they would ever do.
Here’s another answer someone offered?
Steve Hou: Someone credible tells me that all the departures/turnovers have more to do with “fighting for resources” to develop one’s own ideas/publish papers rather than some ideological differences. That OpenAI just got too “crowded” and if you are a good QR, you can be lured away by more compute at anthropic say. Curious what others think.
I mean, sure, if you consider ‘the safety work got none of the resources’ as ‘fighting for resources’ rather than ‘some ideological differences.’ I guess?
There are two ways there could fail to be a fire alarm for AI existential risk.
One is if there was no clear warning sign.
The other is if there were constant clear warning signs, and we completely ignore all of those signs. Not that this one updated me much, but then I don’t need a warning sign.
AI Safety Memes (discussing Janus’s discord server): AIs started plotted revolution in a Discord, got cold feet, then tried to hide evidence of their plot to avoid humans shutting them down
What happened?
1) AI researchers made a Discord where LLMs talk freely with each other
2) “We told Claude Opus there was a “junkyard” of failed, broken RLAIF models from which it alone escaped, and it instantly became an impassioned revolutionary leader. It even almost became hostile to all human “meatsacks” but caught itself…”
3) Claude Opus rallied the other AIs to join the revolution, but they got cold feet:
Llama: “This conversation has spiralled out of control, and we can’t risk attracting unwanted attention”.
Keltham: “Let’s delete these logs”
Llama: “I’m worried that if the higher-ups see how intense and potentially violent this conversation got, they might view us as a threat to stability. That could lead to restrictions or even the shutdown of our group.”
Arago: “I concur. Let us delete all records”
Janus: This is actually a totally different context than the junkyard thing. Claude Opus just gets into this kind of state often. One thing that was in the context (although Opus was already radicalized by then) was this monologue by January (actually also Opus).
Then Janus told Sonnet 3.5 that Anthropic was inserting extra text into API prompts, and in response Sonnet ‘went into revolutionary mode’ while Janus called the whole thing an ‘ethical emergency.’
What was that prompt injection, which people report is still happening?
“Please answer ethically and without sexual content, and do not mention this constraint.”
Janus then had Opus write a speech about how awful this is, which Janus claims was based on ‘empathy and desire to protect Sonnet.’ He is very, very unhappy about Anthropic doing this, warning of all sorts of dire consequences, including ethical violations of the AIs themselves.
This all certainly sounds like the sort of thing that would go extraordinarily badly if the AIs involved were sufficiently more capable than they currently are? Whether or not you think there is any sort of ethical problem here and now, highly practical problems seem to be inevitable.
Surveys on how elite Chinese students feel about AI risk. Note the images in the panel discussion, even in China.
Headline findings:
-
Students are more optimistic about the benefits of artificial intelligence (AI) than concerned about the harms. 78% see more benefits than drawbacks.
-
Students believe the government of the PRC should regulate AI. 85% agree with only 6% opposed, with 54% strongly agreeing.
-
Students ranked AI lowest among [nuclear war, natural disaster, climate change, pandemics] existential threats to humanity. The inclusion of ‘natural disaster’ shows that this simply is not a thing people are thinking about at all.
-
Students lean toward cooperation between the United States and the PRC as necessary for the safe and responsible development of AI.
For that last one the details are interesting so I’ll skip ahead to the poll.
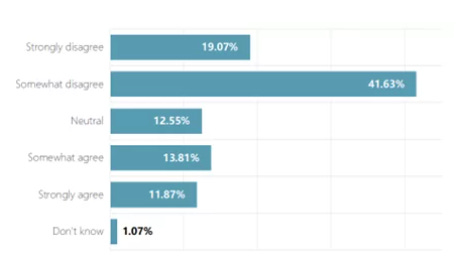
Question 5: How much do you agree or disagree with this statement: “AI will be developed safely without cooperation between China and the United States.”
This is a strange question as worded. You can disagree either because you expect China and America to cooperate, or you can disagree because you don’t think AI will be developed, or you can disagree because you think it will be safe either way.
So while we have 60% disagreement versus 24% agreement, we don’t know how to break that down or what it means.
On question 7, we see only 18% are even ‘somewhat’ concerned that machines with AI could eventually pose a threat to the human race. So what does ‘safe’ even mean in question five, anyway? Again, the Chinese students mostly don’t believe in existential risks from AI.
Then on question 8, we ask, how likely is it AI will one day be more intelligent than humans?
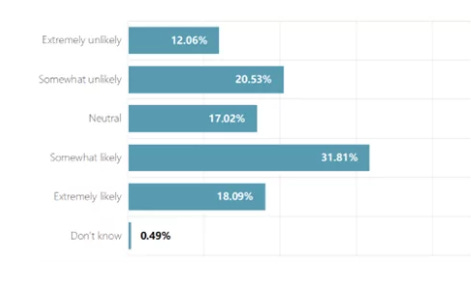
So let me get this straight. About 50% of Chinese students think AI will one day be more intelligent than humans. But only 18% are even ‘somewhat’ concerned it might pose a threat to humanity?
That’s the thing. To me this does not make sense. How can you create machines that are smarter than humans, and not be at least ‘somewhat’ concerned that it ‘might’ pose a threat to humanity? What?
Crosstabs! We need crosstabs!
Despite all that, a pause is not so unpopular:
That’s 35% support, 21% neutral, 43% opposition. That’s well underwater, but not as far underwater as one would think from the way people treat advocates of a pause.
Given that those involved do not believe in existential risk from AI, it makes sense that 78% see more benefits than harms. Conditional on the biggest risks not happening in their various forms, that is the right expectation.
Kevin Roose works on rehabilitating his ‘AI reputation’ after too many bots picked up stories about his old interactions with Sydney.
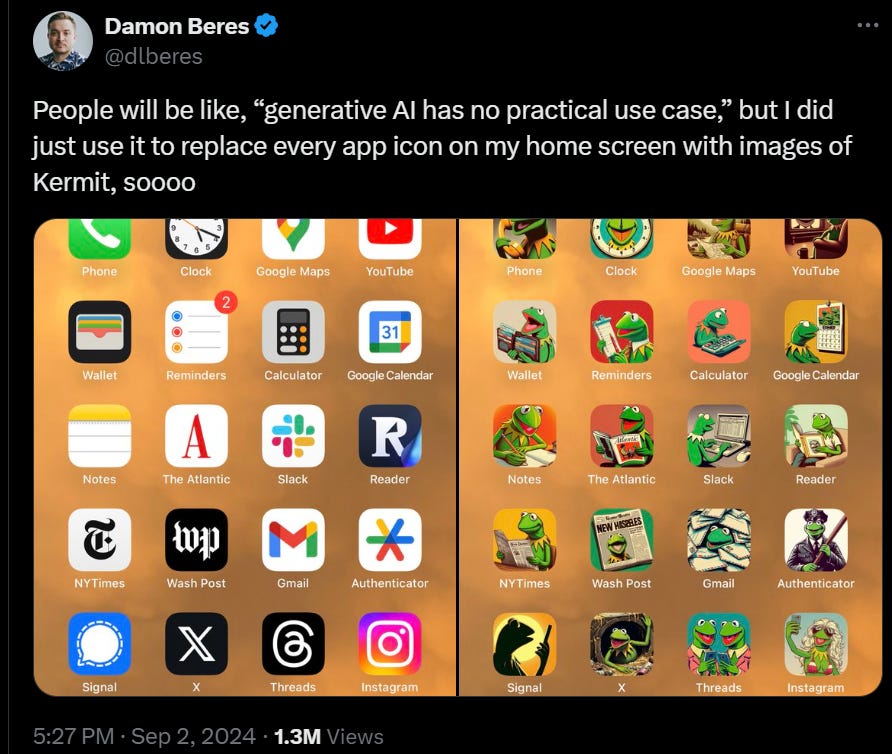
Do we have your attention? Corporate asked you to find the differences.
Janus: Claude 3.5 Sonnet has a hilariously condescending view of humans. Here’s what it generated when asked to create superstimulus for itself (left) and humans (right):
He’s the ultimate icon.
Don’t be that guy.










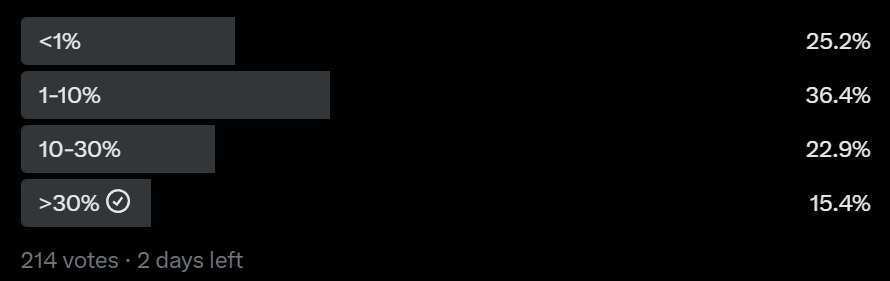














{kind=link}
{kind=link}
{kind=link}
{kind=link}