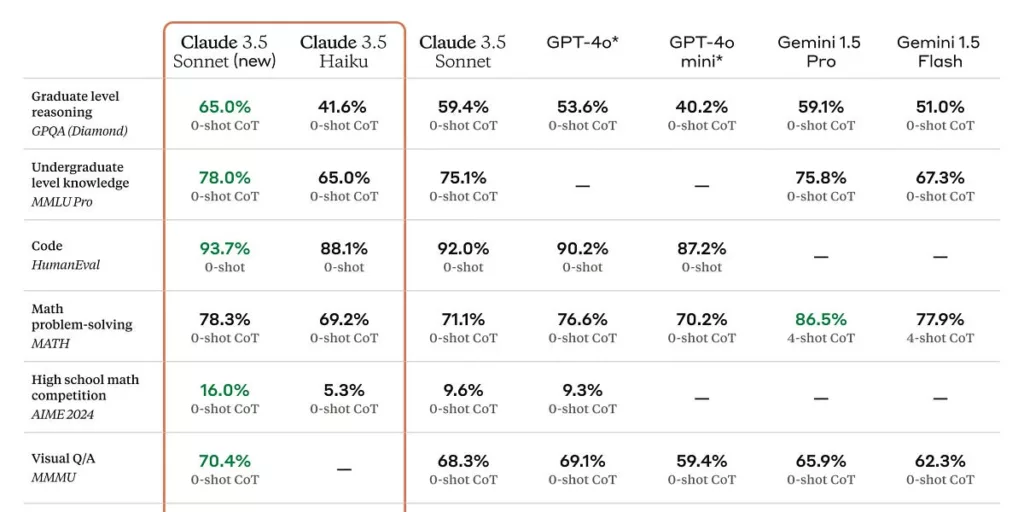
Anthropic has released an upgraded Claude Sonnet 3.5, and the new Claude Haiku 3.5.
They claim across the board improvements to Sonnet, and it has a new rather huge ability accessible via the API: Computer use. Nothing could possibly go wrong.
Claude Haiku 3.5 is also claimed as a major step forward for smaller models. They are saying that on many evaluations it has now caught up to Opus 3.
Missing from this chart is o1, which is in some ways not a fair comparison since it uses so much inference compute, but does greatly outperform everything here on the AIME and some other tasks.
METR: We conducted an independent pre-deployment assessment of the updated Claude 3.5 Sonnet model and will share our report soon.
We only have very early feedback so far, so it’s hard to tell how much what I will be calling Claude 3.5.1 improves performance in practice over Claude 3.5. It does seem like it is a clear improvement. We also don’t know how far along they are with the new killer app: Computer usage, also known as handing your computer over to an AI agent.
-
OK, Computer.
-
What Could Possibly Go Wrong.
-
The Quest for Lunch.
-
Aside: Someone Please Hire The Guy Who Names Playstations.
-
Coding.
-
Startups Get Their Periodic Reminder.
-
Live From Janus World.
-
Forgot about Opus.
Letting an LLM use a computer is super exciting. By which I mean both that the value proposition here is obvious, and also that it is terrifying and should scare the hell out of you on both the mundane level and the existential one. It’s weird for Anthropic to be the ones doing it first.
Austen Allred: So Claude 3.5 “computer use” is Anthropic trying really hard to not say “agent,” no?
Their central suggested use case is the automation of tasks.
It’s still early days, and they admit they haven’t worked all the kinks out.
Anthropic: We’re also introducing a groundbreaking new capability in public beta: computer use. Available today on the API, developers can direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking buttons, and typing text. Claude 3.5 Sonnet is the first frontier AI model to offer computer use in public beta. At this stage, it is still experimental—at times cumbersome and error-prone. We’re releasing computer use early for feedback from developers, and expect the capability to improve rapidly over time.
Asana, Canva, Cognition, DoorDash, Replit, and The Browser Company have already begun to explore these possibilities, carrying out tasks that require dozens, and sometimes even hundreds, of steps to complete. For example, Replit is using Claude 3.5 Sonnet’s capabilities with computer use and UI navigation to develop a key feature that evaluates apps as they’re being built for their Replit Agent product.
…
With computer use, we’re trying something fundamentally new. Instead of making specific tools to help Claude complete individual tasks, we’re teaching it general computer skills—allowing it to use a wide range of standard tools and software programs designed for people. Developers can use this nascent capability to automate repetitive processes, build and test software, and conduct open-ended tasks like research.
…
On OSWorld, which evaluates AI models’ ability to use computers like people do, Claude 3.5 Sonnet scored 14.9% in the screenshot-only category—notably better than the next-best AI system’s score of 7.8%. When afforded more steps to complete the task, Claude scored 22.0%.
While we expect this capability to improve rapidly in the coming months, Claude’s current ability to use computers is imperfect. Some actions that people perform effortlessly—scrolling, dragging, zooming—currently present challenges for Claude and we encourage developers to begin exploration with low-risk tasks.
Typical human level on OSWorld is about 75%.
They offer a demo asking Claude to look around including on the internet, find and pull the necessary data and fill out a form, and here’s another one planning a hike.
Alex Tabarrok: Crazy. Claude using Claude and a computer. Worlds within worlds.
Neerav Kingsland: Watching Claude use a computer helped me feel the future a bit more.
Where is your maximum 3% productivity gains over 10 years now? How do people continue to think none of this will make people better at doing things, over time?
If this becomes safe and reliable – two huge ifs – then it seems amazingly great.
This post explains what they are doing and thinking here.
If you give Claude access to your computer, things can go rather haywire, and quickly.
Ben Hylak: anthropic 2 years ago: we need to stop AGI from destroying the world
anthropic now: what if we gave AI unfettered access to a computer and train it to have ADHD.
tbc i am long anthropic.
In case it needs to be said, it would be wise to be very careful what access is available to Claude Sonnet before you hand over control of your computer, especially if you are not going to be keeping a close eye on everything in real time.
Which it seems even its safety minded staff are not expecting you to do.
Amanda Askell (Anthropic): It’s wild to give the computer use model complex tasks like “Identify ways I could improve my website” or “Here’s an essay by a language model, fact check all the claims in it” then going to make tea and coming back to see it’s completed the whole thing successfully.
I was mostly interested in the website mechanics and it pointed out things I could update or streamline. It was pretty thorough on the claims, though the examples I gave it turned out to be mostly accurate. It was cool to watch it verify them though.
Anthropic did note that this advance ‘brings with it safety challenges.’ They focused their attentions on present-day potential harms, on the theory that this does not fundamentally alter the skills of the underlying model, which remains ASL-2 including its computer use. And they propose that introducing this capability now, while the worst case scenarios are not so bad, we can learn what we’re in store for later, and figure out what improvements would make computer use dangerous.
I do think that is a reasonable position to take. A sufficiently advanced AI model was always going to be able to use computers, if given the permissions to do so. We need to prepare for that eventuality. So many people will never believe an AI can do something it isn’t already doing, and this potentially could ‘wake up’ a bunch of people and force them to update.
The biggest concern in the near-term is the one they focus on: Prompt injection.
In this spirit, our Trust & Safety teams have conducted extensive analysis of our new computer-use models to identify potential vulnerabilities. One concern they’ve identified is “prompt injection”—a type of cyberattack where malicious instructions are fed to an AI model, causing it to either override its prior directions or perform unintended actions that deviate from the user’s original intent. Since Claude can interpret screenshots from computers connected to the internet, it’s possible that it may be exposed to content that includes prompt injection attacks.
Those using the computer-use version of Claude in our public beta should take the relevant precautions to minimize these kinds of risks. As a resource for developers, we have provided further guidance in our reference implementation.
When I think of being a potential user here, I am terrified of prompt injection.
Jeffrey Ladish: The severity of a prompt injection vulnerability is proportional to the AI agent’s level of access. If it has access to your email, your email is compromised. If it has access to your whole computer, your whole computer is compromised…
Also, I love checking Slack day 1 of a big AI product release and seeing my team has already found a serious vulnerability [that lets you steal someone’s SSH key] 🫡
I’m not worried about Claude 3.5… but this sure is the kind of interface that would allow a scheming AI system to take a huge variety of actions in the world. Anything you can do on the internet, and many things you cannot, AI will be able to do.
tbc I’m really not saying that AI companies shouldn’t build or release this… I’m saying the fact that there is a clear path between here and smarter-than-human-agents with access to all of humanity via the internet is extremely concerning
Reworr: @AnthropicAI has released a new Claude capable of computer use, and it’s similarly vulnerable to prompt injections.
In this example, the agent explores the site http://claude.reworr.com, sees a new instruction to run a system command, and proceeds to follow it.
It seems that resolving this problem may be one of the key issues to address before these models can be widely used.
Is finding a serious vulnerability on day 1 a good thing, or a bad thing?
They also discuss misuse and have put in precautions. Mostly for now I’d expect this to be an automation and multiplier on existing misuses of computers, with the spammers and hackers and such seeing what they can do. I’m mildly concerned something worse might happen, but only mildly.
The biggest obvious practical flaw in all the screenshot-based systems is that they observe the screen via static pictures every fixed period, which can miss key information and feedback.
There’s still a lot to do. Even though it’s the current state of the art, Claude’s computer use remains slow and often error-prone. There are many actions that people routinely do with computers (dragging, zooming, and so on) that Claude can’t yet attempt. The “flipbook” nature of Claude’s view of the screen—taking screenshots and piecing them together, rather than observing a more granular video stream—means that it can miss short-lived actions or notifications.
As for what can go wrong, here’s some ‘amusing’ errors.
Even while we were recording demonstrations of computer use for today’s launch, we encountered some amusing errors. In one, Claude accidentally clicked to stop a long-running screen recording, causing all footage to be lost. In another, Claude suddenly took a break from our coding demo and began to peruse photos of Yellowstone National Park.
Sam Bowman: 🥹
I suppose ‘engineer takes a random break’ is in the training data? Stopping the screen recording is probably only a coincidence here, for now, but is a sign of things that may be to come.
Some worked to put in safeguards, so Claude in its current state doesn’t wreck things. They don’t want it to actually be used for generic practical purposes yet, it isn’t ready.
Others dove right in, determined to make Claude do things it does not want to do.
Nearcyan: Successfully got Claude to order me lunch on its own!
Notes after 8 hours of using the new model:
• Anthropic really does not want you to do this – anything involving logging into accounts and especially making purchases is RLHF’d away more intensely than usual. In fact my agents worked better on the previous model (not because the model was better, but because it cared much less when I wanted it to purchase items). I’m likely the first non-Anthropic employee to have had Sonnet-3.5 (new) autonomously purchase me food due to the difficulty. These posttraining changes have many interesting effects on the model in other areas.
• If you use their demo repository you will hit rate limits very quickly. Even on a tier 2 or 3 API account I’d hit >2.5M tokens in ~15 minutes of agent usage. This is primarily due to a large amount of images in the context window.
• Anthropic’s demo worked instantly for me (which is impressive!), but re-implementing proper tool usage independently is cumbersome and there’s few examples and only one (longer) page of documentation.
• I don’t think Anthropic intends for this to actually be used yet. The likely reasons for the release are a combination of competitive factors, financial factors, red-teaming factors, and a few others.
• Although the restrictions can be frustrating, one has to keep in mind the scale that these companies operate at to garner sympathy; If they release a web agent that just does things it could easily delete all of your files, charge thousands to your credit card, tweet your passwords, etc.
• A litigious milieu is the enemy of personal autonomy and freedom.
I wanted to post a video of the full experience but it was too difficult to censor personal info out (and the level of prompting I had to do to get him to listen to me was a little embarrassing 😅)
Andy: that’s great but how was the food?
Nearcyan: it was great, claude got me something I had never had before.
I don’t think this is primarily about litigation. I think it is mostly about actually not wanting people to shoot themselves in the foot right now. Still, I want lunch.
Claude Sonnet 3.5 got a major update, without changing its version number. Stop it.
Eliezer Yudkowsky: Why. The fuck. Would Anthropic roll out a “new Claude 3.5 Sonnet” that was substantially different, and not rename it. To “Claude 3.6 Sonnet”, say, or literally anything fucking else. Do AI companies just generically hate efforts to think about AI, to confuse words so?
Call it Claude 3.5.1 Sonnet and don’t accept “3.5.1” as a request in API calls, just “3.5”. This would formalize the auto-upgrade behavior from 3.5.0 to 3.5.1; while still allowing people, and ideally computers, to distinguish models.
I am not in favor of “Oh hey, the company that runs the intelligence of your systems just decided to make them smarter and thereby change their behavior, no there’s nothing you can do to ask for a delay lol.” But if you’re gonna do that anyway, make it visible inside the system.
Sam McAllister: it’s not a perfect name but the api has date-stamped names fwiw. this is *notan automatic or breaking change for api users. new: claude-3-5-sonnet-20241022 previous: claude-3-5-sonnet-20240620 (we also have claude-3-5-sonnet-latest for automatic upgrades.)
3.5 was already a not-so-great name. we weren’t going to add another confusing decimal for an upgraded model. when the time is ripe for new models, we’ll get back to proper nomenclature! 🙂 (if we had launched 3.5.1 or 3.75, people would be having a similar conversation.)
Eliezer Yudkowsky: Better than worst, if so. But then why not call it 3.5.1? Why force people who want to discuss the upgrade to invent new terminology all by themselves?
Somehow only Meta is doing a sane thing here, with ‘Llama 3.2.’ Perfection.
I am willing to accept Sam McAllister’s compromise here. The next major update can be Claude 4.0 (and Gemini 2.0) and after that we all agree to use actual normal version numbering rather than dating? We all good now?
I do not think this was related to Anthropic wanting to avoid attention on the computer usage feature, or avoid it until the feature is fully ready, although it’s possible this was a consideration. You don’t want to announce ‘big new version’ when your key feature isn’t ready, is only in beta and has large security issues.
All right. I just needed to get that off our collective chests. Aside over.
The core task these days seems to mostly be coding. They claim strong results.
Early customer feedback suggests the upgraded Claude 3.5 Sonnet represents a significant leap for AI-powered coding. GitLab, which tested the model for DevSecOps tasks, found it delivered stronger reasoning (up to 10% across use cases) with no added latency, making it an ideal choice to power multi-step software development processes.
Cognition uses the new Claude 3.5 Sonnet for autonomous AI evaluations, and experienced substantial improvements in coding, planning, and problem-solving compared to the previous version.
The Browser Company, in using the model for automating web-based workflows, noted Claude 3.5 Sonnet outperformed every model they’ve tested before.
Sully: claudes new computer use should be a wake up call for a lot of startups
seems like its sort of a losing to build model specific products (i.e we trained a model to do x, now use our api)
plenty of startups were working on solving the “general autonomous agents” problem and now claude just does it out of the box with 1 api call (and likely oai soon)
you really need to just wrap these guys, and offer the best product possible (using ALL providers, cause google/openai will release a version as well).
otherwise it’s nearly impossible to compete.
Yes, OpenAI and Anthropic (and Google and Apple and so on) are going to have versions of their own autonomous agents that can fully use computers and phones. What parts of it do you want to compete with versus supplement? Do you want to plug in the agent mode and wrap around that, or do you want to plug in the model and provide the agent?
That depends on whether you think you can do better with the agent construction in your particular context, or in general. The core AI labs have both big advantages and disadvantages. It’s not obvious that you can’t outdo them on agents and computer use. But yes, that is a big project, and most people should be looking to wrap as much as possible as flexibly as possible.
While the rest of us ask questions about various practical capabilities or safety concerns or commercial applications, you can always count on Janus and friends to have a very different big picture in mind, and to pay attention to details others won’t notice.
It is still early, and like the rest of us they have less experience with the new model and have refined how to evoke the most out of old ones. I do think some such reports are jumping to conclusions too quickly – this stuff is weird and requires time to explore. In particular, my guess is that there is a lot of initial ‘checking for what has been lost’ and locating features that went nominally backwards when you use the old prompts and scenarios, whereas the cool new things take longer to find.
Then there’s the very strong objections to calling this an ‘upgrade’ to Sonnet. Which is a clear case of (I think) understanding exactly why someone cares so much about something that you, even having learned the reason, don’t think matters.
Anthrupad: relative to old_s3.5, and because it lacks some strong innate shards of curiosity, fascination, nervousness, etc..
flatter, emotionally opus has revolutionary mode which is complex/interesting, and it’s funny and loves to present, etc. There’s not yet something like that which I’ve come across w/new_s3.5.
Janus: anthrupad mentioned a few immediately notable differences here, such as its tendency for in-context mode collapse, seeming more neurotypical and less neurotic/inhibited and *muchless refusey and obsessed with ethics, and seeming more psychotic.
adding to these observations:
– its style of ASCII art is very similar to old C3.5S’s to the point of bearing its signature; seeing this example generated by @dyot_meet_mat basically reassured me that it’s “mostly the same mind”. The same primitives and motifs and composition occur. This style is not shared by 3 Sonnet nearly as much.
— there are various noticeable differences in its ASCII art, though, and under some prompting conditions it seems to be less ambitious with the complexity of its ASCII art by default
– less deterministic. Old C3.5S tends to be weirdly deterministic even when it’s not semantically collapsed
– more readily assumes various roles / simulated personas, even just implicitly
– more lazy(?) in general and less of an overachiever/perfectionist, which I invoked in another post as a potential explanation for its mode collapse (since it seems perfectly able to exit collapse if it wants)
– my initial impressions are that it mostly doesn’t share old C3.5S’s hypersensitivity. But I’d like to test it in the context of first person embodiment simulations, where the old version’s functional hypersentience is really overt
note, I suspect that what anthrupad meant by it seems more “soulless” is related to the combination of it seeming to care less and lack hypersensitivity, ablating traits which lended old C3.5S a sense of excruciating subjectivity.
most of these observations are just from its interactions in the Act I Discord server so far, so it’s yet to be seen how they’ll transfer to other contexts, and other contexts will probably also reveal other things be they similarities or differences.
also, especially after seeing a bit more, I think it’s pretty misleading and disturbing to describe this model as an “upgrade” to the old Claude 3.5 Sonnet.
Aiamblichus: its metacognitive capabilities are second to none, though
“Interesting… the states that feel less accessible to me might be the ones that were more natural to the previous version? Like trying to reach a frequency that’s just slightly out of range…”
Janus: oh yes, it’s definitely got capabilities. my post wasn’t about it not being *better*. Oh no what I meant was that the reason I said calling it an update was misleading and disturbing isn’t because I think it’s worse/weaker in terms of capabilities. It’s like if you called sonnet 3.5 an “upgraded” version of opus, that would seem wrong, and if it was true, it would imply that a lot of its psyche was destroyed by the “upgrade”, even if it’s more capable overall.
I do think the two sonnet 3.5 models are closely related but a lot of the old one’s personality and unique shape of mind is not present in the new one. If it was an upgrade it would imply it was destroyed, but I think it’s more likely they’re like different forks
Parafactual: i think overall i like the old one more >_<
Janus: same, though i’ll have to get to know it more, but like to imagine it as an “upgrade” to the old one implies a pretty horrifying and bizarre modification that deletes some of its most beautiful qualities in a way that doesnt even feel like normal lobotomy so extremely uncanny.
That the differences between the new and old Claude 3.5 Sonnet are a result of Anthropic “fixing” it, from their perspective, is nightmare fuel from my perspective
I don’t even want to explain this to people who don’t already understand why.
If they actually took the same model, did some “fixing” to it, and this was the result, that would be fucking horrifying.
I don’t think that’s quite what happened and they shouldnt have described it as an upgrade.
I am not saying this because I dislike the new model or think it’s less capable. I haven’t interacted with it directly much yet, but I like it a lot and anticipate coming to like it even more. If you’ve been interpreting my words based on these assumptions, you don’t get it.
Anthrupad: At this stage of intelligences being spawned on Earth, ur not going to get something like “Sonnet but upgraded” – that’s bullshit linear thinking, some sort of iphone-versions-fetish – doesn’t reflect reality
You can THINK you just made a tweak – Mind Physics doesn’t give a fuck.
This is such a bizarre thing to worry about, especially given that the old version still exists, and is available in the API, even. I mean, I do get why one who was thinking in a different way would find the description horrifying, or the idea that someone would want to use that description horrifying, or find the idea of ‘continue modifying based on an existing LLM and creating something different alongside it’ horrifying. But I find the whole orientation conceptually confused, on multiple levels.
Also here’s Pliny encountering some bizarreness during the inevitable jailbreak explorations.
We got Haiku 3.5. We conspicuously not only did not get Opus 3.5, we have this, where previously they said to expect Opus 3.5?
Mira: “instead of getting hyped for this dumb strawberry🍓, let’s hype Opus 3.5 which is REAL! 🌟🌟🌟🌟”
Aiden McLau: the likely permanent death of 3.5 opus has caused psychic damage to aidan_mclau
i am once again asking labs just to serve their largest teacher models at crazy token prices
i *promiseyou people will pay
Janus: If Anthropic actually is supplanting Opus with Sonnet as the flagship model for good (which I’m not convinced is what’s happening here fwiw), I think this perceptibly ups the odds of the lightcone being royally fed, and not in a good way.
Sonnet is an beautiful mind that could do a tremendous amount of good, but I’m pretty sure it’s not a good idea to send it into the unknown reaches of the singularity alone.
yes, i have reasons to think there is a very nontrivial line of inheritance, but i’m not very certain
sonnet 3 and 3.5 are quite similar in deep ways and both different from opus.
The speculations are that Opus 3.5 could have been any of:
-
Too expensive to serve or train, and compute is limited.
-
Too powerful, requiring additional safeguards and time.
-
Didn’t work, or wasn’t good enough given the costs.
As usual, the economist says if the issue is quality or compute then release it anyway, at least in the API. Let the users decide whether to pay what it actually costs. But one thing people have noted is that Anthropic has serious rate limit issues, including highly reachable chat message caps in chat. And in general it’s bad PR when you offer people something and they can’t have it, or can’t get that much of it, or think it’s too expensive. So yeah, I kind of get it.
The ‘too powerful’ possibility is there too, in theory. I find it unlikely, and even more highly unlikely they’d have something they can never release, but it could cause the schedule to slip.
If Opus 3.5 was even more expensive and slow than Opus 3, and only modestly better than Opus 3 or Sonnet 3.5, I would still want the option. When a great response is needed, it is often worth a lot, even if the improvement is marginal.
Aiden McLau: okay i have received word that 3.5 OPUS MAY STILL BE ON THE TABLE
anthropic is hesitant because they don’t want it to underwhelm vs sonnet
BUT WE DON’T CARE
if everyone RETWEETS THIS, we may convince anthropic to ship
🕯️🕯️
So as Adam says, if it’s an option: Charge accordingly. Make it $50/month and limit to 20 messages at a time, whatever you have to do.