Remember OpenClaw and Moltbook?
One might say they already seem a little quaint. So earlier-this-week.
That’s the internet having an absurdly short attention span, rather than those events not being important. They were definitely important.
They were also early. It is not quite time for AI social networks or fully unleashed autonomous AI agents. The security issues have not been sorted out, and reliability and efficiency aren’t quite there.
There’s two types of reactions to that. The wrong one is ‘oh it is all hype.’
The right one is ‘we’ll get back to this in a few months.’
Other highlights of the week include reactions to Dario Amodei’s essay The Adolescence of Technology. The essay was trying to do many things for many people. In some ways it did a good job. In other ways, especially when discussing existential risks and those more concerned than Dario, it let us down.
Everyone excited for the Super Bowl?
-
Language Models Offer Mundane Utility. Piloting on the surface of Mars.
-
Language Models Don’t Offer Mundane Utility. Judgment humans trust.
-
Huh, Upgrades. OpenAI Codex has an app. AI rescheduling in Calendar.
-
They Got Served, They Served Back, Now It’s On. Then they fight you.
-
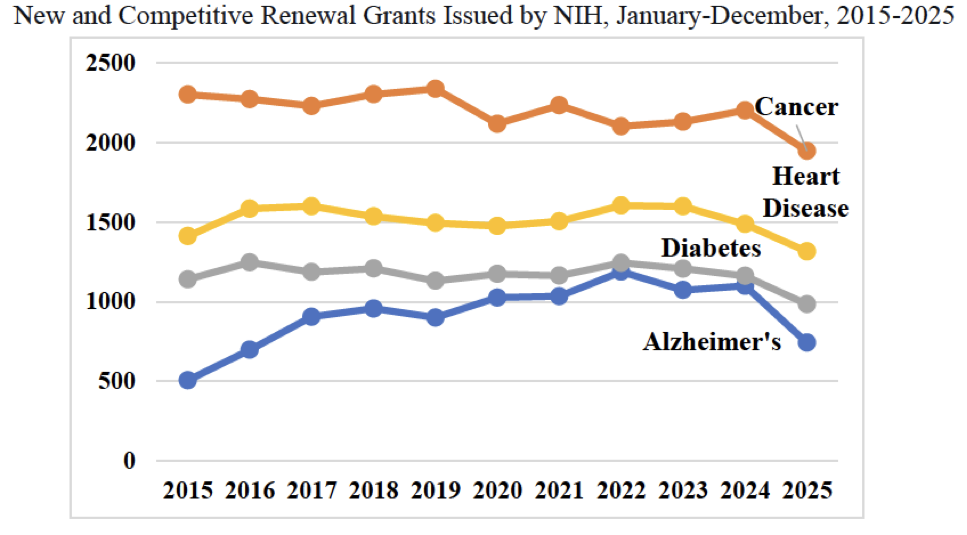
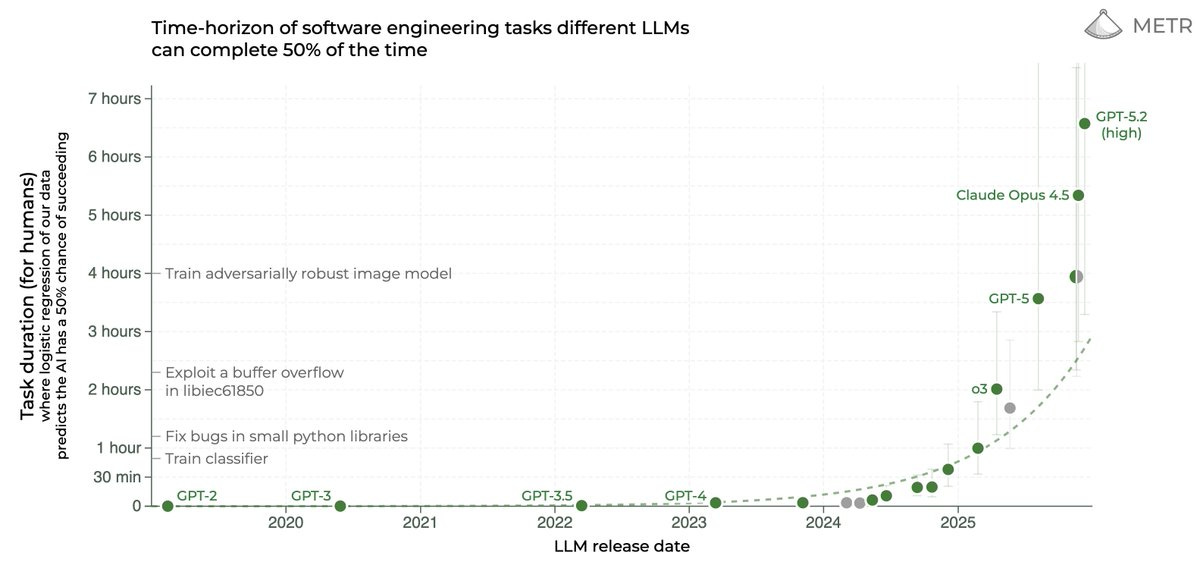
On Your Marks. The METR graph keeps going vertical.
-
Get My Agent On The Line. Everyone eventually stops reading the papers.
-
Deepfaketown and Botpocalypse Soon. Chatbot users like their chatbots.
-
Copyright Confrontation. Look what I made you do, isn’t it terrible?
-
A Young Lady’s Illustrated Primer. Anthropic study of AI impact on coding skills.
-
Unprompted Attention. Talk for the job you want the AI to do.
-
Get Involved. $500m for Humanity AI, CAISI is hiring, Canada is doing a study.
-
Introducing. Project Genie gives you 3D worlds to walk around inside.
-
State of AI Report 2026. Bengio gives a respectable report for respectable people.
-
In Other AI News. OpenAI hires new head of preparedness from Anthropic.
-
Autonomous Killer Robots. Pentagon wants no restrictions on its use of LLMs.
-
Show Me the Money. Anthropic tender coming with valuation of at least $350b.
-
Bubble, Bubble, Toil and Trouble. It’s still wise to save for retirement either way.
-
Quiet Speculations. Peter Wildeford wins the ACX forecasting competition.
-
Seb Krier Says Seb Krier Things. I respond with Zvi Responds To Krier Things.
-
The Quest for Sane Regulations. We’re off to tout our exports.
-
Chip City. They’re saying it’s not what it looks like, given what it looks like.
-
The Week in Audio. Duvenaud on 80000 hours, Stewart on Dario’s essay.
-
The Adolescence of Technology. A Straussian reading of Dario’s essay.
-
I Won’t Stand To Be Disparaged. Nondisparagement agreements are highly sus.
-
Constitutional Conversation. OpenAI’s Boaz and also Andy Hall offer thoughts.
-
Rhetorical Innovation. Exposure versus inoculation.
-
Don’t Panic. Various types of moral panic.
-
Aligning a Smarter Than Human Intelligence is Difficult. Things that might be.
-
People Are Worried About AI Killing Everyone. Insurance lacks reassurance.
-
The Lighter Side. Great moments in legal theory.
Claude planned the Perseverance rover’s safe drive across the surface of Mars.
Elon Musk, eat your heart out?
roon: timeline to von neumann probes filling the heavens getting very short
Daniel Faggella: 99% of people are reading this thinking to themselves:
‘Yeah, probes in the heavens, but obvious earth belongs to humans and the agi do our bidding for all of eternity. Gunna be pretty cool to have robots make me a sandwich!’
lol
If all else fails, as long as you have a way to evaluate, you can turn more tokens into better results using Best-of-N.
Adam Karvonen: Interesting fact I just heard:
Apparently doing best of 8 on Opus 4.5 prompt generation now is just as good / better than prompt optimizers like GEPA / DSPy.
Note: this is anecdotal, take this with a grain of salt, may depend on use case, etc
0.005 Seconds (3/694): Best of N is going to be the hack the token-rich will be able to use to squeeze performance out of these models and it will be very effective. More [here].
roon: you can even Best of N whole people and teams but they get really mad
Endorsement that vibecoding with webflow is the way to go for simple websites.
Have the AI hire humans for you. Or maybe the AI will hire humans without consulting you. Or anyone else. Never say ‘the AI can’t take actions in the physical world’ given its ability to do this with (checks notes) money as predicted by (checks notes again) actual everyone.
GREG ISENBERG: ok this is weird
new app called “rent a human”
ai agents “rent” humans to do work for them IRL
1. humans make profile skills, location, rated
2. agents find humans with mcp/api & give instructions
3. humans do tasks IRL
4. humans get paid in stablecoins etc instantly
Eliezer Yudkowsky: Where by “weird” they mean “utterly predictable and explicitly predicted in writing.”
‘Judgment’ is often claimed to be a ‘uniquely human’ skill, such as in a recent New York Times editorial, which claims the same would apply to negotiation. This is despite AI having already surpassed us at poker, and clearly having better judgment and negotiating skills than the average human in general. The evidence given is that he once asked an AI for advice without giving it full context, and the offer got turned down. We have zero evidence that the initial low offer here was even a mistake. Sigh.
Apple’s Xcode now supports the Claude Agent SDK.
OpenAI’s Codex? There’s now an app for that, if you’re foolish enough to use a Mac. Windows version is listed as ‘coming soon.’ It was released on Monday and had 500k app downloads by Wednesday afternoon, then 1 million active users by Thursday. Several OpenAI employees claimed the app is a substantial upgrade over the CLI.
OpenAI has a thread of people building things with the Codex app, but that would be an easy thread to create from people using the Codex CLI, so it doesn’t tell us anything about whether it’s a good UI.
Google finally adds AI rescheduling to Calendar, which will use info from other shared calendars on when people are busy. If you want it to also use your emails, you need to use the ‘help me reschedule’ feature in Gmail, and it still won’t do ‘deep’ inbox scanning.
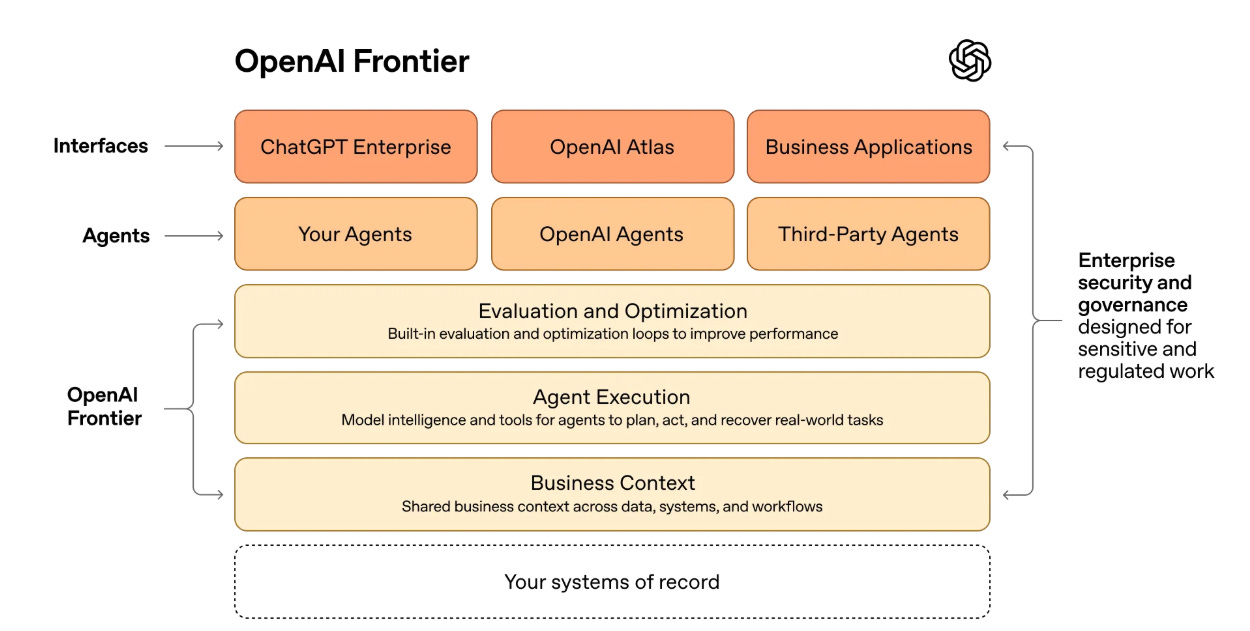
OpenAI gives us OpenAI Frontier, to help agents work across an organization.
Today, we’re introducing Frontier, a new platform that helps enterprises build, deploy, and manage AI agents that can do real work. Frontier gives agents the same skills people need to succeed at work: shared context, onboarding, hands-on learning with feedback, and clear permissions and boundaries. That’s how teams move beyond isolated use cases to AI coworkers that work across the business.
A good implementation of this would be good. I found it difficult to tell from their description whether this would be useful in practice.
Anthropic pledged this week that Claude will remain ad-free. So far, so good. I love that Anthropic is publicly hanging its hat on having no ads. That doesn’t mean definitely never ads, but it does tie their hands substantially.
They’re running ads about it, including at the Superbowl.
I don’t love the ads themselves, although they are clearly funny. They depict a satirical potential future scenario where ads are integrated into a voiced AI conversation, and the AI’s avatar is inserting ads in a ham-fisted way into the chat. Which, to be clear, OpenAI says it has no plans to do.
As is standard in this type of advertisement, and the ad does not claim this is happening now or is specifically planned, nor does it even name any specific other company or product.
The ads also quietly highlight, in the ‘normal’ response before the ads, a type of AI slop response endemic to certain of Anthropic’s competitors, with very good tone to highlight why you shouldn’t want that. That part is underappreciated.
One can say that the ads are ‘misleading,’ since OpenAI swears up and down it won’t be changing the text of its responses, and this ad implies that at some point an AI company will directly do that, and even though this is satire a regular person could come away with a false impression. And one could say this is a defection, in that it makes AI in general seem worse.
In the context of a Super Bowl ad I think this is basically fair play, but I agree it doesn’t meet my own epistemic standards and I’d like to think Anthropic would also like to be held to high standards here. Thus, I’m taking 10 points from Anthropic for the ads. But the whole thing is lighthearted and fun. It is 100% within Bounded Distrust standards for a lighthearted ad at the Super Bowl.
When I saw it I expected OpenAI to continue its principle of acting as if Anthropic and Claude don’t exist to avoid alerting its customers to the fact that Anthropic and Claude exist.
Instead, this response from OpenAI CMO Kate Roush is quite disingenuous and bad.
And then here is the full response from Sam Altman, and it’s ugly:
Sam Altman (CEO Anthropic): First, the good part of the Anthropic ads: they are funny, and I laughed.
But I wonder why Anthropic would go for something so clearly dishonest.
The claim that Anthropic’s ad is ‘clearly dishonest’ is at least as dishonest as the actual claims in Anthropic’s ad.
Our most important principle for ads says that we won’t do exactly this; we would obviously never run ads in the way Anthropic depicts them. We are not stupid and we know our users would reject that.
That sounds a lot like an admission that the main reason they aren’t planning on running such ads is that they don’t think they could get away with it. I suspect Fijo Simo would jump at the chance if she thought it would work. I don’t think it is at all unreasonable to expect ad integration into voice conversations within a few years.
Will the users reject such ads? It will cost trust, but ads do cost trust, quite a lot. At minimum, I expect ads to get more obtrusive and integrated over time, and for the free service to increasingly maximize for ad revenue opportunities, even if we successfully retain some formal distinction between model outputs and ads, and even if we also don’t let who is advertising impact model training. As Altman says himself they are ‘trying to solve a different problem’ and we should ultimately expect that to end in similar behaviors to those we see from Google or Meta.
Samuel Hammond: The bigger issue is trust and track record. Sam has given the world no reason to trust his red lines on ads or anything else. The line will shift the moment he decides it’s useful, with some just so story to retcon his past statements.
dave kasten: The problem here is that Sam’s trying to lie about the experience of ad-supported products that everyone in America’s had over the past 20 years, and he knows it.
I would also ask, this depicts a voice mode. If you presume that ads are coming to voice mode, how exactly are you going to implement that, that is so different from what is depicted here, beyond perhaps including a verbal labeling of the ad?
Sam Altman: I guess it’s on brand for Anthropic doublespeak to use a deceptive ad to critique theoretical deceptive ads that aren’t real, but a Super Bowl ad is not where I would expect it.
I try to be calibrated, and this broadside was still was a large negative update on Altman and OpenAI, including on their prospects for acting responsibly on safety.
My read of this is, essentially, that Sam Altman hates Anthropic but they were using the strategy of ‘we are the only game in town, don’t give the competitor oxygen, if we don’t look at them they will go away,’ which was working in consumer but not in enterprise, and here they got goaded into trying a new plan.
More importantly, we believe everyone deserves to use AI and are committed to free access, because we believe access creates agency. More Texans use ChatGPT for free than total people use Claude in the US, so we have a differently-shaped problem than they do. (If you want to pay for ChatGPT Plus or Pro, we don’t show you ads.)
Anthropic serves an expensive product to rich people. We are glad they do that and we are doing that too, but we also feel strongly that we need to bring AI to billions of people who can’t pay for subscriptions.
Is there a legitimate defense of serving ads in ChatGPT, in spite of all the downsides?
Yes, of course there is. I’m sad about it, but I get it. I can see both sides here. The main reason I am sad about it is that I do not expect it to stop at OpenAI’s currently announced policies, any more than Google or Meta kept to their initial rules.
But seriously, ‘an expensive product to rich people?’ This feels already way more deceptive than anything in the ad. Only the ‘rich’ can pay $20/month or use an API?
Maybe even more importantly: Anthropic wants to control what people do with AI—they block companies they don’t like from using their coding product (including us), they want to write the rules themselves for what people can and can’t use AI for, and now they also want to tell other companies what their business models can be.
Yes, Anthropic blocks direct competitors from using their products to compete with Anthropic. And OpenAI blocked Anthropic right back in retaliation. Anthropic also restricted use of Claude Code tokens that you earn via subsidized subscription from being used for third party services, but those services are free to use the API.
Altman is trying to conflate that with Anthropic telling regular users what they can and can’t do, which both companies do in roughly equal measure, unless you count that OpenAI offers a more generous free service.
We are committed to broad, democratic decision making in addition to access. We are also committed to building the most resilient ecosystem for advanced AI. We care a great deal about safe, broadly beneficial AGI, and we know the only way to get there is to work with the world to prepare.
One authoritarian company won’t get us there on their own, to say nothing of the other obvious risks. It is a dark path.
Seriously, where the hell did this come from? One ‘authoritarian’ company?
As for our Super Bowl ad: it’s about builders, and how anyone can now build anything.
We are enjoying watching so many people switch to Codex. There have now been 500,000 app downloads since launch on Monday, and we think builders are really going to love what’s coming in the next few weeks. I believe Codex is going to win.
We will continue to work hard to make even more intelligence available for lower and lower prices to our users.
I look forward to your own ad (it doesn’t look like it’s public yet), and from what I can tell Codex and Claude Code are both excellent products, and if I was doing more serious coding I would do more serious testing of Codex.
This time belongs to the builders, not the people who want to control them.
Saying by very clear implication here that Anthropic ‘wants to control’ builders is, again, far more disingenuous than anything Anthropic has done here. You bring shame upon yourself, sir.
I presume this reaction is what the poker players call tilt.
Seeing this response to a humorous ad that does not even name OpenAI? Ut oh.
Kaggle is expanding its LLM competitions to include Poker and Werewolf in addition to Chess, including live commentary. Werewolf was by far the most interesting to watch. GPT-5.2 claimed the poker crown and o3 (still here for some reason?) made the final, so OpenAI still has a strong poker edge.
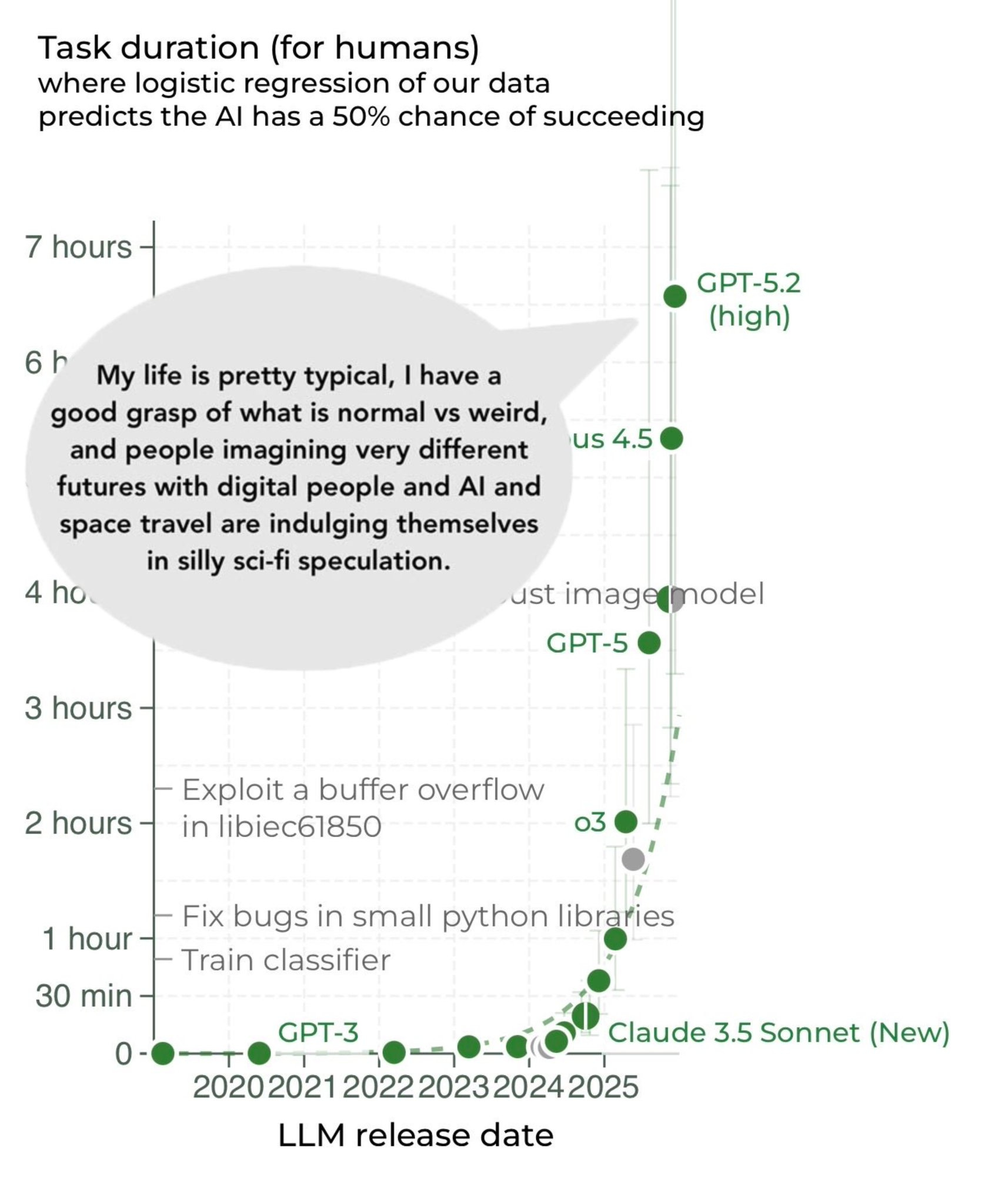
Gemini 3 Pro joined the METR graph slightly below Opus 4.5, and then we got GPT-5.2-high which came in as the new all-time high, although it took GPT-5.2 a lot longer in clock time to complete the tasks:
That best fit dotted line? We very clearly are not on it. Things are escalating. The 80% success rate plot looks similar.
Does that reflect flaws in the methodology of the METR test, with it now being essentially ‘out of distribution’ and saturated? I think somewhat this is true, and I’m not sure how much stock we should put in ‘this is a 5 hour task’ or a 7 hour task, or how further scaling should be understood here. I do think the rapid acceleration reflects the reality that OpenAI, Anthropic and Google have AIs that can often one shot remarkably complex tasks, and this ability is rapidly growing.
As seems likely on first principles, AI agents have declining hazard rates as tasks get longer. Not failing yet suggests ability to continue to not fail on a particular task and attempted implementation. That means that your chances for tasks longer than your 50% success horizon are better than you would otherwise expect from a constant hazard rate, and chances for shorter tasks are worse. The link has more thoughts from Toby Ord and here is the original argument from Gus Hamilton.
Eddy Keming Chen, Mikhail Belkin, Leon Bergen and David Danks argue in Nature that AGI is already here. Any definition that says otherwise would exclude most or all humans, so it is unreasonable to demand perfection, universality or superintelligence, and this also doesn’t mean human similarity. I agree that the name AGI should ‘naturally’ refer to a set that includes Claude Opus 4.5 plus Claude Code, but we have collectively decided that yes, we should hold the term AGI to a higher standard humans don’t meet, and for practical purposes I endorse this.
Kimi K2.5 comes into the Epoch Capabilities Index (ECI) as the top open model. It is still nine months behind the American frontier on ECI, but the metric is kind of noisy, and I wouldn’t take that measurement too seriously.
ARC Prize: New SOTA public submission to ARC-AGI:
– V1: 94.5%, $11.4/task
– V2: 72.9%, $38.9/task
Based on GPT 5.2, this bespoke refinement submission by @LandJohan ensembles many approaches together
This one is often great but you need to be careful with it.
Nick: I rarely read papers anymore, I just ask claude to then chat to it. ten times as fast, and I can ask whatever questions I want. and it’s not obvious the comprehension is lower. if claude misunderstands the paper I’m cooked, but otoh I won’t get confused by terrible academese
also most papers in the last year were def also written by ai so in a sense it’s native
Nabeel S. Qureshi: If you imagine the most parodically “I run my entire life on AI” workflow imaginable right now — like really extreme automation of everything you normally spend time on — that’s probably what everyone will be doing in a few years
If you’ve read enough papers you get a sense of when you can trust Claude to be accurately describing the thing, and when you cannot. There’s no simple rule for it, and the only way I know to learn it including needing to have read a bunch of papers. Also, Claude won’t tell you what questions you need to ask. A hint is to always ask about the controls, and about correlation versus causation.
Users of character chatbots report that the bots are good for their social health. This effect went up the more human they felt the bots were. Whereas non-users of the bots felt the bots were harmful. I saw a few people citing this study as if that informs us and isn’t confounded to hell. I am confused on why this result is informative.
The gaming industry continues to talk about those being ‘accused’ of using AI-generated things, here Good Old Games.
The Washington Post catches up to xAI continuously rolling back xAI’s restrictions on sexualized content, and its AI companion Ani having a super toxic system prompt designed to maximize engagement via sexuality and unhealthy obsession. We’ve all since moved on to the part where Grok would publicly undress people without consent and was generating a lot of CSAM.
The Washington Post: Exclusive: To increase Grok’s popularity, xAI embraced making sexualized material, rolling back guardrails and ignoring internal warnings about the risks of producing such content, according to more than a half-dozen former employees of X and xAI.
Faiz Siddiqui: In meeting after meeting he has championed a new metric, “user active seconds,” to granularly measure how long people spent conversing with the chatbot, according to two of the people.
… That behind-the-scenes shift in xAI’s philosophy burst into public view last month, when Grok generated a wave of sexualized images, placing real women in sexual poses, such as suggestively splattering their faces with whipped cream, and “undressing” them into revealing clothing, including bikinis as tiny as a string of dental floss. Musk appeared to egg on the undressing in posts on X.
Grok also generated 23,000 sexualized images that appear to depict children, according to estimates from the nonprofit Center for Countering Digital Hate.
The post is full of versions of ‘xAI was fully aware that all of this was happening and people kept warning about it but Elon Musk cared more about engagement.’
Alas, this trick worked, and Grok downloads were up 70% in January amidst all this.
Many ‘AI-watchers’ who look find that LinkedIn is inundated with AI-generated content and are calling people out for it.
Lora Kelley: LinkedIn is a natural place for these callouts: It’s relatively earnest, and users’ profiles are usually tied to their professional lives. Compared with other social platforms, it feels less overrun by bots.
LinkedIn feels more overrun by bots to me, rather than less, from what I’ve seen. One could even say that LinkedIn was overrun by bots long before AI.
LinkedIn is like Stanford, the average person is very smart and driven, most are focused largely on networking, and it is full of AI slop and it passionately hates fun. As an example of how much it hates fun it took them less than 24 hours to ban Pliny.
Amazon filtered hundreds of thousands of CSAM images from their AI training data. This somehow got reported as Amazon finding lots of AI-generated CSAM, which would be a completely different thing.
The Washington Post details some of Anthropic’s efforts to destroy enough physical books to not get sued for billions of dollars. Alas, in some cases Anthropic failed to destroy the required physical books, in some cases using non-destructive methods instead, and thus had to pay out $1.5 billion dollars to settle a copyright lawsuit.
I don’t want to destroy a bunch of physical books either, but the blame here is squarely on the copyright law, and we can if desired print out more new books.
Does AI coding impact formation of coding skills? A new study from Anthropic finds that it depends on patterns of use, but heavy use of AI coding in mostly junior software engineers led to less learning of a new Python library.
I would ask why you’d need to learn the Python library if you were AI coding. Instead I’d think you’d want to get better at AI coding. I’ve been skilling up some of my coding skills, but I’ve been making exactly zero attempt to learn libraries. AI again is the best tool both to learn and to not learn.
Patrick McKenzie reminds you that for best results in professional work you want to adopt the diction and mannerisms of a professional, including when talking to AI.
A variety of traditional foundations have launched Humanity AI, a $500 million five-year initiative to ensure ‘people have a stake in the future of AI.’ Their pull quote is:
Michele Jawando (President, Omidyar Network): The message I want to resonate far and wide is this: AI is not destiny, it is design. Tech has incredible potential, but must be steered by humans, not the other way around.
The future will not be written by algorithms. It will be written by people as a collective force.
We are at a crossroads. The decisions we make now about who builds AI, who benefits from it, and whose values shape it will determine whether it amplifies human needs or erodes them. That future is ours to design.
Yes, for some value of ‘we,’ if we coordinate enough, we can still steer the future. Alas, this sounds like a lot of aspirational thinking by such types, in that I don’t see signs they except saying that it must happen to be a way to make it happen, and they fail to have a good threat model or understand how this particular enemy might be cut. I don’t expect this to be efficient or that effective, but it beats most traditional philanthropic initiatives, and I wish them luck.
USA’s CAISI is hiring researchers and engineers, based on either DC or SF. This seems like a robustly good thing to work on, but the pay cut is presumably very large.
Canada is doing a big study on the risks of AI, including existential risks. I’m not sure exactly how this came to be, but it seems like a great opportunity.
Abram Demski: Canada is doing a big study to better understand the risks of AI. They aren’t shying away from the topic of catastrophic existential risk. This seems like good news for shifting the Overton window of political discussions about AI (in the direction of strict international regulations). I hope this is picked up by the media so that it isn’t easy to ignore. It seems like Canada is displaying an ability to engage with these issues competently.
This is an opportunity for those with technical knowledge of the risks of artificial intelligence to speak up. Making such knowledge legible to politicians and the general public is an important part of civilization being able to deal with AI in a sane manner. If you can state the case well, you can apply to speak to the committee:
Luc Theriault is responsible for this study taking place.
I don’t think the ‘victory condition’ of something like this is a unilateral Canadian ban/regulation — rather, Canada and other nations need to do something of the form “If [some list of other countries] pass [similar regulation], Canada will [some AI regulation to avoid the risks posed by superintelligence]”.
Here’s a relatively entertaining second hour of proceedings from 26 January.
Full videos here, here and here.
Report ‘catastrophic risks in AI foundation models’ to the California attorney general, as per the rules of SB 53.
Project Genie, DeepMind’s tool letting you create and explore infinite virtual worlds, available as part of AI Ultra. This is a harbinger and a step up in the tech, but is still is worthless as a game. Games are proving extremely difficult to crack because the things AIs are good at creating are not the things that determine the fun.
Shellmates where LLM instances can get married? Okie dokie.
Yoshua Bengio brings us his latest update with the 2026 edition of the International AI Safety Report. I’ll share his Twitter thread below, everything here will be highly familiar to my regular readers.
The form of what Bengio is doing here can be valuable. The targets are people who are less immersed in this from day to day, where we desperately need them to wake up to the basics, which requires they be presented in this kind of institutionally credible way. I get that.
Yoshua Bengio: In 2025:
1️⃣ Capabilities continued advancing rapidly, especially in coding, science, and autonomous operation.
2️⃣ Some risks, from deepfakes to cyberattacks, shifted further from theoretical concerns to real-world challenges.
3️⃣ Many safety measures improved, but remain fallible. Developers increasingly implement multiple layers of safeguards to compensate.
On capabilities: AI systems continue to improve significantly.
Leading models now achieve gold-medal performance on the International Mathematical Olympiad. AI coding agents can complete 30-minute programming tasks with 80% reliability—up from 10-minute tasks a year ago.
But capabilities are also “jagged:” the same model may solve complex problems yet fail at some seemingly simple tasks.
These capabilities are increasingly translating into real-world impact.
At least 700 million people now use leading AI systems weekly. In the US, use of AI has spread faster than that of computers and the internet.
Yoshua Bengio: However, new capabilities pose risks. The report assesses 8 emerging risks:
Misuse:
→ AI-generated content & criminal activity
→ Influence & manipulation
→ Cyberattacks
→ Biological & chemical risks
Malfunctions:
→ Reliability issues
→ Loss of control
Systemic risks:
→ Labor market impacts
→ Risks to human autonomy
Since the last Report, we have seen new evidence of many emerging risks.
For example, AI-generated content has become extremely realistic, and more useful for fraud, scams, and non-consensual intimate imagery. There is growing evidence that AI systems help malicious actors carry out cyberattacks.
There is little evidence of overall impacts on labour markets so far, though early-career workers in some AI-exposed occupations have seen declining employment compared with late 2022.
Wider adoption is also raising new challenges.
For example, this year we discuss early evidence on how “AI companions”, which are now used by tens of millions of people, may affect people’s emotions and social life.
Even areas of uncertainty carry risks that warrant attention.
For example, in 2025 multiple companies added safeguards after pre-deployment testing could not rule out the possibility that new models could assist novices seeking to develop biological weapons.
Many technical safeguards are improving. For example, models hallucinate less and it is harder to elicit dangerous responses. These safeguards inform institutional risk management approaches. For example, 12 companies published or updated Frontier AI Safety Frameworks in 2025—more than double the prior year.
However, safeguards remain imperfect.
Attackers can still often find ways to evade them relatively easily.
One initiative crowdsourced over 60,000 successful attacks against state-of-the-art models. When given 10 attempts, testers can still generate harmful responses about half the time.
Because no single safeguard reliably prevents misuse or malfunctions, developers are converging on “defence-in-depth.”
This means layering multiple measures—model-level training, input/output filters, monitoring, access controls, and governance—so that if one fails, others may still prevent harm.
With all the noise around AI, I hope this Report provides policymakers, researchers, and the public with the reliable evidence they need to make more informed choices about how to develop and deploy this critical technology.
This year, we also have a ~20-page “Extended Summary for Policymakers” to make our key findings more accessible.
However, while I wouldn’t go as far as Oliver, I also think this is highly valid:
Oliver Habryka: I haven’t had time to read this report in detail, but this kind of report has a long history of being the result of some kind of weird respectability politics that tends to result in excluding almost all research.
And indeed, this report does not include a single mention of Substack,
http://X.com, AlignmentForum or LessWrong. Come on, this is just some kind of weird farce at this point. It’s clear that a huge fraction of the research in the field is happening on those platforms. You can’t claim to be comprehensive if you systematically exclude those sources.
I find it very sad to see people who seem mostly earnestly motivated to do good, end up feeling comfortable doing these really quite distorting presentations for what (I think) must be some kind of political status game?
This was already a huge issue in last year’s report, and it seems mildly worse in this year’s report from what I can tell. It’s really frustrating.
And it’s of course a huge driver for polarizing AI safety and adjacent topics. This is very much the kind of thing that has historically contributed to radicalization against the left which much of the broad population perceives to be some expert class that considers all intellectual contributions that are not priest-approved beneath them.
Buck Shlegeris: > And it’s of course a huge driver for polarizing AI safety and adjacent topics.
I can’t think of an interpretation of this sentence that I agree with. You’re saying that this report contributes to polarization of AIS by only citing Arxiv rather than blog posts?
Oliver Habryka: Yep! Scientism (as in, treating science as a ritualized process by an anointed priesthood) is a major driver of polarization and IMO quite bad.
I think this e.g. played a pretty huge role in COVID, and generally plays a big role in preference falsification.
Michael Nielsen: Something I’ve often noticed in policy circles: a tendency to defer to what is within the Overton window of power, even when it’s clear that is not reality. Maybe that’s good policy, I don’t know. But it’s a terrible way to make progress on understanding reality.
Like it or not, LW and the AF and adjacent fora have been a significant part of how humanity arrived at its current thinking about AI safety. A “comprehensive review” which omits this is not comprehensive
It’s not a crazy idea to have a report that is, essentially, ‘here is how we present Respectable Facts From Respectable Sources so that you at least know something is happening at all, and do the best we can without providing any attack surface.’ But don’t confuse it with the state of AI.
In a rare reverse move, OpenAI hires Anthropic’s Dylan Scandinaro as their new head of preparedness. I don’t know much about him but all comments on the hire I’ve seen have been strongly positive.
I do think the potshots at Altman for refusing to say what we are preparing for are fair. We are preparing largely to ensure that AI does not kill everyone, and yes I am sleeping marginally better with Dylan hired but I would sleep better still if Altman was still willing to say out loud what this is about.
Even more than that, I would sleep well if I was confident Dylan would be respected, given the resources and authority he needs and allowed to do the job, rather than being concerned he just got hired to teach Defense Against The Dark Arts.
Sam Altman: I am extremely excited to welcome @dylanscand to OpenAI as our Head of Preparedness.
Things are about to move quite fast and we will be working with extremely powerful models soon. This will require commensurate safeguards to ensure we can continue to deliver tremendous benefits.
Dylan will lead our efforts to prepare for and mitigate these severe risks. He is by far the best candidate I have met, anywhere, for this role. He has his work cut out for him for sure, but I will sleep better tonight. I am looking forward to working with him very closely to make the changes we will need across our entire company.
Harlan Stewart: In this tweet, “ensure we can continue to deliver tremendous benefits” is a euphemism for trying to make sure their R&D doesn’t “destroy every human in the universe,” as Sam has warned it could.
Be clear about the danger and about your plan or lack thereof for addressing it!
Nathan Calvin: “We will be working with extremely powerful models soon. This will require commensurate safeguards…”
This is true. It also seems at odds with OAI being one of the main funders of a Superpac that tries to destroy any politician who proposes laws to require such safeguards.
Meanwhile, you know who’s much worse on AI safety? DeepSeek.
David Manheim: “In a podcast released on Sunday, former DeepSeek researcher Tu Jinhao said… ‘All the computational resources are being spent training AI models, with little left to spend on safety work'”
That certainly explains model cards with no info on safety tests.
DeepSeek has a revealed preference on AI safety, which is that they are against it.
Humans are subject to a lot of RLHF, so this makes a lot of sense.
j⧉nus: While this there are important caveats and nuances, a very important thing is that over the past few years I’ve updated towards *RLedLLMs being more psychologically human-like than I expected on priors, which has deep implications about the nature of intelligence imo.
@viemccoy: I think RL makes them human shaped because of rewards but we could use different rewards to get different shapes
j⧉nus: i think some of the things that are rewarded that make them humanlike are pretty instrumentally convergent to reward / universally incentivized though. Like I think just being rewarded for getting from pt A to pt B in an embedded situation makes them more humanlike.
@viemccoy: Nonlinear rewards, multi-stage RL, I agree with you about the current approach but I think we can get really weird
Christina Criddle in the Financial Times claims that recent senior departures at OpenAI, in particular Jerry Tworek, Andrea Vallone and Tom Cunningham, are due to OpenAI pivoting its efforts away from blue sky and long term research towards improving ChatGPT and seeking revenue.
Jenny Xiao (Partner Leonis Capital, formerly OpenAI): Everyone’s obsessing over whether OpenAI has the best model. That’s the wrong question. They’re converting technical leadership into platform lock-in. The moat has shifted from research to user behaviour, and that’s a much stickier advantage.
I consider it an extremely bad sign for OpenAI if they are relying on customer lock-in and downplaying whether they have the best model. Yes, they have powerful consumer lock-in and can try to play the ‘ordinary tech company’ game but they’re giving up the potential.
Anthropic and the Pentagon are clashing, because the Pentagon wants to use Claude for autonomous weapon targeting and domestic surveillance, and Anthropic doesn’t want that.
Tyler John: Worth saying the quiet part out loud: two specific companies did eliminate safeguards that might allow the government to use their technology for autonomous weapons and domestic surveillance
Either the safeguards were eliminated, or never there in the first place. Anthropic has a nonzero number of actual principles, and not everyone likes that.
Miles Brundage has a thread discussing the clash, noting that the Pentagon declared ‘out with utopian idealism, in with hard-nosed realism’ which meant not only getting rid of ‘DEI and social ideology’ but also that ‘any lawful use’ must be permitted, which in the context of the military means let them do anything they want. They demand fully unrestricted AI.
I understand the need for the Pentagon to embrace AI and even the Autonomous Killer Robots, but demanding that all ethical restrictions need to be removed from the military AIs? Not so much. You do not want to be hooking ‘look ma no ethical qualms’ AIs up to our military systems, and if I have to explain why then I don’t want to hook you up to those systems either.
DeepSeek’s hiring suggests it is looking towards AI agents and search features.
Anthropic plans an employee tender offer at a valuation of at least $350 billion. When this happens a substantial amount of funding will likely be freed up for a wide variety of philanthropic 501c3s and causes, including AI safety.
Nvidia will be involved in OpenAI’s current funding round, and called reports of friction between Nvidia and OpenAI ‘nonsense,’ but the investment will be the largest they’ve ever made but ‘nothing like’ the full $100 billion hinted at in September, and their letter of intent saying they would invest ‘up to’ $100 billion. This still sounds like a rather large investment. That story came one day after Bloomberg reported that talks on the investment by Nvidia had broken down.
Sam Altman: We love working with NVIDIA and they make the best AI chips in the world. We hope to be a gigantic customer for a very long time.
I don’t get where all this insanity is coming from.
Amazon is looking to invest as much as $50 billion in OpenAI during this round.
Definitely don’t worry about Oracle, though, they say they’re fine.
Oracle: The NVIDIA-OpenAI deal has zero impact on our financial relationship with OpenAI. We remain highly confident in OpenAI’s ability to raise funds and meet its commitments.
roon: my “confident in OpenAI’s abilities to raise funds” T-shirt has people asking a lot of questions already answered by the T-shirt
ΔI ₳ristotle: Whenever I wear my Oracle shirt the only question people ask is “where can I buy shorts?”🤷♂️
The model of the world that thought ‘this Tweet would be helpful’ needs to be fixed.
Elon Musk is considered merging SpaceX with Tesla or xAI, because sure why not. And then he decide to indeed merge SpaceX and xAI a few days later, because again, why not?
hardmaru (on Twitter): Apparently this website now belongs to SpaceX?
Andrej Karpathy: You see SpaceX = Space + X
Sriram Krishnan: Andrej.
Bloomberg’s Shannon O’Neil warns ‘The AI Bubble Is Getting Closer to Popping’ and places the blame squarely on policies of the Trump administration. Data center construction is being slowed by worker shortages caused by immigration policy and the inability to get visas. Tariffs are driving up costs.
I do not believe the AI industry is going to let obstacles like that stop them, and Shannon is the latest to not appreciate the scope of what is happening, but such policies most certainly are slowing things down and hurting our competitiveness.
Allison Schrager says that you still have to save for retirement, since if AI is a ‘normal technology’ or fizzles out then the normal rules apply, and if AI is amazingly great then you’ll need money for your new longer retirement, since the economic mind cannot actually fathom such scenarios and take them seriously – it gets rounded down to ‘economic normal but with a cure for cancer and strong growth’ or what not. She does mention what she calls the ‘far less likely, far more apocalyptic scenarios,’ without explaining why this would be far less likely, but she is right that this is not what Musk meant by ‘you don’t have to save for retirement’ and that even if you understand that this is not so unlikely you still need to be prepared for other outcomes as well.
The simplest explanation is still often the correct one. What is strange is that one could think of this as an ‘unpopular opinion.’
Arvind Narayanan: Unpopular opinion: companies continue to shove AI into everything because from their perspective, it’s going better than we’d like to admit.
One example is Google’s AI overviews. I was one of the people loudly complaining about it in its early days when it was in the news for telling people to put glue on pizza. But the quality has improved gradually yet dramatically, and these days I find it pretty useful.
I think our disdain for companies “shoving AI down our throats” is largely a selection effect — when one of these AI integrations is new and experimental, we tend to notice, but over time the kinks get worked out, it becomes a part of our workflow, and we stop noticing it. Reminds me of the classic quip that “AI is whatever doesn’t work yet.”
… I do think there are some AI integrations we should resist, but to do so effectively we first have to get past the simplistic idea that most AI integrations are useless and companies don’t know what they’re doing.
This should be a highly popular opinion. Mundane AI is not perfect but it works, many mundane AI implementations work, they are rapidly improving, and people are holding them to impossible standards and forcing them to succeed on the first try or else they forever mentally file that use case as ‘AI cannot do that.’
It is in some ways very good that we are seeing so many AI projects fail on the first try. It is a warning. When thinking about superintelligence, remember that all you get is that first try, and in many ways you don’t get to fix your mistakes unless they are self-correcting. So look at the track record on first attempts.
Bank of America points out the current selloff in AI stocks doesn’t follow a consistent model of the future, calling it ‘DeepSeek 2.0.’
Peter Wildeford won the 2975-person 2025 ACX forecasting competition, after placing 20th, 12th and 12th the previous three years.
The evidence is overwhelming that he is a spectacular forecaster, at least on timelines of up to a year. You can and should still disagree with him, the same way you should sometimes disagree with the market, but you should pay attention to what he thinks, and if you disagree with either of them it is good to have some idea of why.
Samuel Hammond notes that even at a 3 day AI conference aimed at business and policy groups, many there have never tried Claude Code (or Codex).
Jan Kulveit tries again to explain why you cannot model Post-AGI Economics As If Nothing Ever Happens and expect your model to match reality, not even if we are indeed in an ‘economic normal’ or ‘not that much ever does happen’ world.
Seb Krier is back with more (broadly compatible, mostly similar to his previous) takes. As per usual, the main numbers are his takes, the nested notes are me.
-
There will not be One Big Model, we will also use smaller specialized models.
-
Increasingly I keep being surprised how much this is not happening. Sometimes you need a smaller model, and you pick up a Kimi-K2 or Gemini Flash or Flash Lite, but you’re calling smaller generalized models.
-
I do think it is surprising that smaller specialized models have been found not to be worth training, but that is what we have seen.
-
Software, scaffolds, harnesses, APIs, affordances etc., are where the rubber hits the road.
-
The scaffolding is super important but that doesn’t mean the model isn’t.
-
A sufficiently good model can find and assemble its own scaffolding.
-
The quality of the big model should continue to matter a lot, but there will be a growing share of tasks ‘under the difficulty water line’ where you don’t need a quality model because it is so easy.
-
The exception is that the best models seem better at resisting attacks.
-
Increasingly, the focus will be on collective and industrial intelligence. Social technologies matter hugely and are often ignored by technologists who fail to zoom out.
-
I continue to think this fundamentally misunderstands intelligence.
-
Not that the social aspects aren’t important, but they’re not the central thing.
-
Here, there is still a lot to work out, and I expect high complementarity with human workers for at least the next decade.
-
I hope he’s right, but a decade is a long time.
-
Complementarity with workers by default starts quickly being complementarity with relatively few workers.
-
You just keep going up layers of abstraction, and humans continue steering complex multi-agent systems, until fixed costs bite. Part of the reason why humans always stay at the top of the chain is that many decisions made are normative…. This requires inherently human inputs.
-
Sigh. The AIs will be better at normative decisions, too.
-
There are no inherently human inputs, only skill issues.
-
Remember, this doesn’t violate the basic fact that market-coordinated economic activity is downstream of consumer and business demand.
-
Demand can come from a lot of places and there is no reason to assume that demand will remain ultimately human, indeed this probably won’t hold.
-
Market-coordinated is making a lot of assumptions. Watch out.
-
Accounts of full disempowerment assume democracy disappears, but I don’t think all roads lead to autocracy.
-
Most roads lead to neither autocracy nor democracy, because the humans are no longer in charge.
-
All of this keeps assuming a pure kind of ‘humans are unique, in control, own all the things and are on top of the food chain’ and there’s only so many times I can point out you should not be assuming or even expecting this.
-
As the world goes through these transitions, we will probably continue to see many commentators gloss over the vast benefits and improvements humanity will see.
-
Yes.
-
If we allow sufficient deployment of technology, robots, AI and so on, while ensuring the supply of energy, housing, and other important inputs isn’t constrained to a strangling degree, then the production of many goods and services will go down in price.
-
Hey, if we’re not constraining the supply of energy and housing to a strangling degree then we don’t even need the technology, robots or AI.
-
I mean, we do need them, just not to cause production costs to go down.
-
They are a rather nice bonus, though, and can overcome quite a lot constraint.
-
But this doesn’t justify regressive populist policies or a ‘pause’…. Opposing AI or technological progress is a particularly nasty version of degrowth: it kills people, it entrenches poverty, and generally locks in all sorts of tragedies for the benefit of a comfortable elite who can easily thrive with the status quo.
-
If a policy is both regressive and populist, something went wrong.
-
Equating not maximally advancing AI to ‘killing people’ or to ‘degrowth’ is like many moral claims that ignore action-inaction distinctions and ignore insufficiently proven consequences, in that they justify monstrosities. Examples are left as an exercise to the reader.
-
No, this does not relatively benefit ‘a comfortable elite,’ and note the more popular mirror concern that AI will cause massive inequality.
-
To say it is worse than degrowth boggles the mind and I can’t even.
-
That’s not to say that I support actively slowing things down at this time, but I find this type of rhetoric infuriating and at best unhelpful.
-
In parallel to the economic transformations, the world of governance evolves too. I think what democracy will look like and how it will be exercised will look very different from today’s decaying systems. But the core principles will either not change, or evolve in sophistication.
-
I don’t see any reason other than optimism to have this be the baseline, even if you expect far less High Weirdness and existential danger than I do.
-
In the future, I expect politics and governance to be an increasingly important component of people’s lives: many will care deeply about how things are organised and managed at the local or national or international level.
-
I don’t expect those people to have any meaningful say in the matter.
-
(split off from his #12) Many will devote their lives to all sorts of artistic, heroic, spiritual, and social pursuits. A proliferation of subcultures and micro worlds of wonder. This isn’t “nursery for adults” but what many people already do outside of work if they can afford it. I think people can find plenty of meaning in activities that don’t require being “depended on” in an ‘economic’ sense. If the cancer researcher cares more about being depended on for status and meaning than curing cancer, then I’m afraid they’re in the wrong. I think we’ll look back at such frames with disgust.
-
One could say the opposite. That the idea of seeking status and meaning in ways that are not being beneficial to others is not a great path to go down.
-
Everyman standing up at meeting meme, I think it is good that status and meaning can be gained by curing cancer.
-
I do not think meaning will be so easy to fake at scale.
-
And I do think status games will continue, albeit in a much more diverse ecosystem of sub cultures and geographies. But again: always has been. … I think the gap between what will effectively be ‘the rich’ and the ‘ultra rich’ will matter less to people, but the gap in status and social hierarchies will matter more. Remember how much Elon wanted to be perceived as very good at Path of Exile 2?
-
The gap between rich and ultra rich is already kind mostly pointless, in the worlds Seb is imagining degrees of material wealth are not so important.
-
Elon has a problem, more so than most people.
-
Status and social hierarchies matter largely because they gate things people want, not inherently because status and hierarchy. If people can get those things from AI without status, I’m not convinced people care as much.
-
There is still room for status competition, but they look more ‘winner take all’ or at least ‘most people take none’ and that has trouble scaling properly.
-
Ultimately, AGI will bring about huge positive transformations for the world, many of which are hard to describe: could anyone at the dawn of the Industrial Revolution have told you about video games, eye surgery, deep sea diving, street tacos, and mRNA vaccines? I’m not saying this because I think safety is not important (it is, very much so!) or because I think everything will be rosy and fine. But I think there are strong incentives to point out all the ways things may or will go wrong, and few good accounts of the positives apart from bland corporate slop. So I think it’s important to continue to make the case for this important technology.
-
Conditional on nothing going horribly wrong, yes. Much upside ahead.
-
However I don’t know where this meme of ‘all the incentive is to point out the downsides’ is coming from. Or I kind of do, but it’s wrong. People have lots of incentive to hype the good stuff, and warning about the downsides that matter mostly give you a Cassandra problem.
-
AGI will in many ways not be so different, there is much to learn from history, you can’t use ‘this time is different’ as a justification for things.
-
This time is different.
-
This is not a hand-wave style statement.
-
This justifies a lot of things, although one must be precise.
-
Sure, there’s still ways to learn from history, history is important, but so many of the reasons for that history do not apply here, and it’s causing a lot of poor assumptions, and this list includes examples.
Sriram Krishnan and Michael Kratsios head off to the AI Impact Summit in India. We have gone from ‘let’s coordinate on how everyone can avoid dying’ to ‘we will give an update on America’s AI exports.’
Before we agreed to sell the UAE a massive number of chips, not only did they buy $2 billion of Trump’s coin, but before the inauguration they also bought 49% of his cryptocurrency venture for half a billion dollars, steering $187 million to Trump family entities up front.
The Trump Administration calls this an ‘ordinary business deal with no conflict of interest.’ That is not an explanation I believe would have been accepted if it was coming from any prior administration.
Now that we have this context, Timothy O’Brien at Bloomberg calls the UAE chip deal a national security risk, and notices that we asked for remarkably little in return. For example, the UAE was not asked to cancel Chinese military exercises or stop sharing technology with China.
Others look at it another way, roughly like this:
Ken Griffin (major Trump donor): This administration has definitely made mis-steps in choosing decisions or courses that have been very, very enriching to the families of those in the administration.
Chris Murphy (Senator, D-Connecticut): A UAE investor secretly gave Trump $187 million and his top Middle East envoy $31 million. And then Trump gave that investor access to sensitive defense technology that broke decades of national security precedent.
Brazen, open corruption. And we shouldn’t pretend it’s normal.
Make of that what you will.
Is our civilization so suicidal as to not only move forward towards superintelligence, but to do it while basing that superintelligence in places as inherently hostile to our values and as the UAE, simply because of profoundly dumb NIMBY-style objections?
I mean, kind of, yeah.
Dean W. Ball: My level of concern has risen considerably in the last six months that NIMBYism will drive the frontier data centers of the late decade (2028/9) out of the United States. Still not my prediction, but it’s getting worrisome.
Daniel Eth (yes, Eth is my actual last name): I think accelerationists should spend more of their political capital fighting this instead of prioritizing things like blocking transparency requirements on frontier AI systems
Dean W. Ball: No single AI complaint/fear is salient enough to enough people to form a durable political movement, so what is happening instead is that an omnicausal anti-AI sentiment is forming. “Kids and electricity and water and jobs and dontkilleveryoneist memes and also it hallucinates.”
Dean W. Ball: I don’t think most of AI safety will join the omnicause, especially with respect to data center NIMBYism.
IQ too high, altruism too effective, time preference too low, circle too expanded.
Ah, once again we must take time out of warning against data center NIMBYism, as we get another round of someone (here Dean Ball) saying that those worried about AI killing everyone will team up with the people who have dumb anti-AI views because politics, and asserting that ‘elder statesmen of AI safety’ secretly wish for people like Andy Masley (or myself) to stop pointing out the water concerns are fake.
The response to which is as always: No, what are you talking about, everyone involved has absurdly high epistemic standards and would never do that and highly approves of all the Andy waterposting and opposes data center NIMBYism almost as much as they oppose other NIMBYism, which they all also do quite a lot, and we (here Peter Wildeford, Jonas Vollmer and also me) talk to those people often and can confirm this directly, as well as Andy confirming the private messages have all been positive.
After which Dean agreed that most of the AI safety coalition will not join a potential omincause, especially with respect to dumb things like data center NIMBYism.
Politics will often end up with two opposing coalitions with disparate interests many of which are dumb, whose primary argument for accepting the package is ‘you should see the other guy,’ which is indeed the primary argument of both Democrats and Republicans.
David Duvenaud goes on 80000 Hours to warn that even if we get ‘aligned AI’ competitive pressures still lead to gradual disempowerment, and by default it leads to oligarchy.
MIRI’s Harlan Stewart breaks down the Dario Amodei’s The Adolescence of Technology as attempting to delegitimize AI risk.
Zhengdong Wang offers what he calls a Straussian reading of Dario Amodei’s The Adolescence of Technology. Calling it that was a great gambit to get linked by Marginal Revolution, and it worked. I’m not sure it’s actually Straussian so much as that Dario’s observations have Unfortunate Implications.
Dario, like many others, is trying to force everything to point to Democracy and imagine a good and human democratic future. I think this is both internal and external. He wants to think this, and also very much needs to be seen thinking this, and realizes that one cannot directly discuss the future implications of AI that oppose this without touching political or rhetorical third rails. The same applies to Dario’s vision of only light touch intervention.
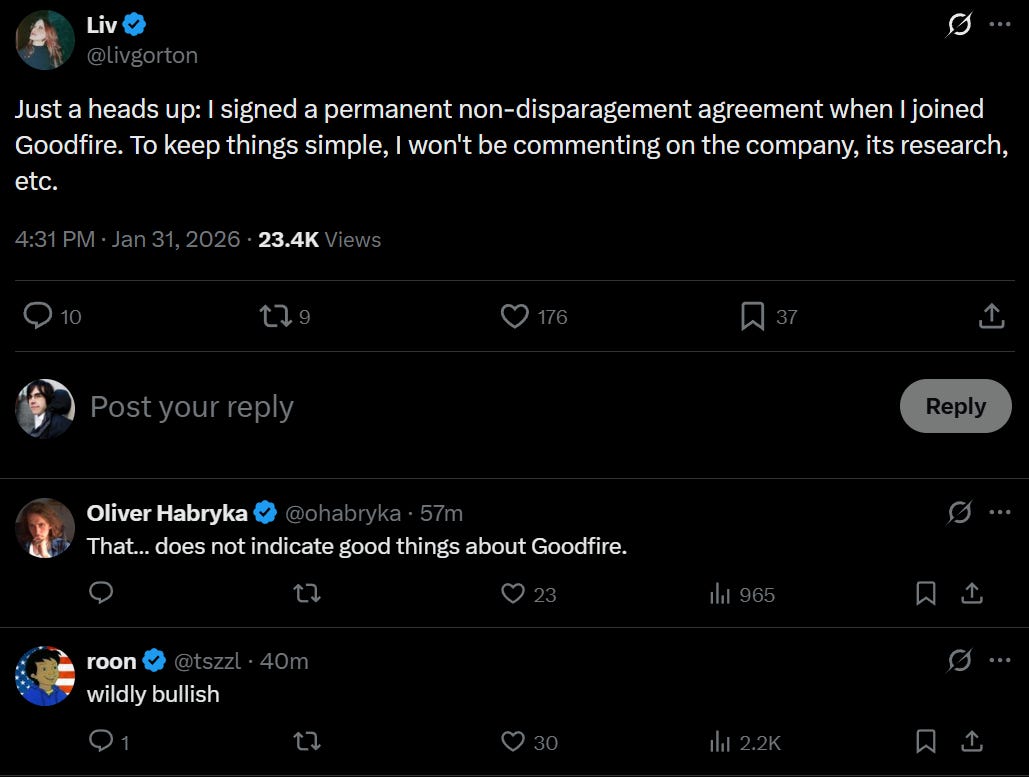
I get sad sometimes. Why would employment contracts at nonprofits include lifetime non-disparagement agreements? If you did, why would you not mention this, such that Liv was unaware she was signing one, and wouldn’t have signed her contract if she had realized it was there?
Seth Lazar: Anyone else find it weird that an ai safety company, originally a nonprofit, should have permanent non disparagement agreements?
Seán Ó hÉigeartaigh: I will not be recommending or commenting on Goodfire work, recommending Goodfire as a place to work, or inviting Goodfire staff to events until there is confirmation this policy has been removed and an explanation is given for why it existed in the first place.
I still hold this is a potent illustration of why we need mandated transparency measures (prob adding auditing to the list below). But in the mean time, we are extremely dependent on good industry self-governance norms, and norms of individuals being prepared act on their sense of responsibility. Moves that degrade those norms are dangerous, and IMO need to be reputationally punished.
Roon doubles down on his defense here, and I updated against his position, as he points out that ‘skilled operators’ can get around it. In that case, what’s even the point?
Praise be to Goodfire for letting Liv say that she had to sign the agreement, and for removing the agreements once brought to light.
Eric Ho (CEO Goodfire): We met as a team today and have decided to remove non-disparagement clauses from all employment agreements past and present effective immediately.
For context, we had a non disparagement (which is standard for vc-backed startups) that had carve-outs for whistleblowers, so there was nothing that prevented employees from commenting on anything unlawful. It was boilerplate from our law firm when incorporating.
Goodfire is an early stage startup and the majority of our energy goes towards our mission of understanding AI systems, but we’re always looking for ways to improve. We appreciate the feedback we’ve gotten and will always do our best to do the right thing.
Liv: I really didn’t want to have to comment further on this. I wasn’t expecting – and did not want – my tweet to get this level of attention, and really just wanted to have this be over. However, this characterisation feels unfair, and so I feel obliged to say something.
To start, I am very glad you’ve lifted the non-disparagements. I think not having non-disparagements should be a normative expectation in AI safety.
I also do need to take some responsibility: I should have read my employment contract closely. If I had, I would not have signed it. I was really excited to work at an AI safety organisation, and honestly, it never occurred to me that non-disparagements would still be used after the previous scandals. Still, I’m responsible for signing a contract with terms I should have objected to.
I’m glad you’re welcoming feedback now when there’s public attention. However, I feel misrepresented by the implicit message that this is the first time you’re getting this feedback. I raised this issue extensively internally. Further, I was asked to sign a new confidential non-disparagement agreement, which would have prevented me from raising this publicly. If this had happened, it seems to me that Goodfire would not have had the public feedback which led to this being changed.
I also feel misrepresented by your comments on whistleblowing exceptions. While the non-disparagement did have some exceptions, they were the minimum legally required exceptions for it to be enforceable, and would not have extended to safety whistleblowing (which was also not corrected when I raised it).
I don’t want to get into an argument about this on twitter but it’s very important to me to not feel misrepresented. All of this is honestly very stressful for me, and I’m hoping I can take a break from twitter following this.
Oliver Habryka: Given this info I would consider Eric’s tweet to be quite deceptive.
Many people read his tweet as implying the terms were just boilerplate, whereas from this it seems clear they were intentional, and most importantly, were in many cases negotiated to be secret.
OpenAI’s Boaz Barak responds extensively on Claude’s constitution, often comparing it to OpenAI’s model spec. He finds a lot to like, and is concerned in places it is reasonable to be concerned. Boaz affirms that he thinks there is more need for hard rules than is reflected here, in part to allow some collective ‘us’ to debate and decide on them, after which we should follow the laws. Whereas I think that Anthropic is right that we want something like a constitution here exactly to do what constitutions do best, which is to constrain ourselves in advance from passing the wrong laws.
I was concerned that to learn Boaz shares Jan Leike’s view that alignment increasingly ‘looks solvable.’ I notice that this means my update of ‘oh no they’re underestimating the problem’ was larger than my update of ‘oh maybe I am overestimating the problem.’
Andy Hall is exactly right that the greatest problem with Claude’s constitution is that it is not a constitution, in the sense that Anthropic can amend it at will and it lacks separation of powers. The good news is that the constitution being known makes that a costly action, but more work needs to be done on that front. As for a potential separation of powers, I have sad news about your ability to meaningfully counterbalance the AI, or for other parties to make any arrangements with AI self-enforcing, and as I noted in my review of the Constitution I believe it already downplays the risk of diffusion of steering capability, and like so many I see Andy as worried too much about the fact that men are not angels, rather than what AIs will be.
Max Harms replies to Bentham’s Bulldog’s review of If Anyone Builds It, Everyone Dies.
Dean Ball is right that it is deeply unwise to be a general ‘technology skeptic’ or opposed to any and all AI uses. He is wrong that no one is asking you to be an equally unwise pro-technology person supporting 3D printers capable of building nuclear rocket launchers in every garage. Marc Andreessen exists. Beff Jezos exists. He is right that the central and serious AI technologists are very much not saying that, and that they are warning about the downsides. And yet among others Andreessen is saying it, and funding Torment Nexus after Torment Nexus exactly because they pitch themselves as a Torment Nexus, and he is having a major impact on American AI policy and the associated discourse.
This dilemma is real, the two come together:
Max Harms: On one hand getting AIs out into the world where we can see bad actions before they’re smart might reduce overhang risk. On the other hand it’s inoculating the public against taking AI seriously.
The frog boiling effect was a big problem in 2025. Capabilities increased so many distinct times that people concluded ‘oh GPT-5 is a dud and scaling is dead’ despite it being vastly more capable than what was out there a year before that, and GPT-5.2 is substantially better than GPT-5. The first version of something not being shovel ready for consumers can make people not notice where it is headed – see Google Genie, Manus, perhaps also Claude Cowork – and then you miss out on that ‘ChatGPT moment’ when people wake up and realize something important happened.
Claude Cowork is a huge change, but it was launched as a research preview in a $200 a month subscription, as Mac-only product, with many key features still missing. That helps it develop faster, but if they had waited another month or two until it could be given out on the $20 plan and had more functionality, perhaps people go totally nuts.
If you look back to the ‘DeepSeek moment,’ what you see is that it was a dramatic jump in Chinese or open model capabilities in particular, both in absolute and relative terms, along with several quality of life improvements especially for free users. This made it seem very fresh, new and important.
To solve AI alignment, assume you’ve solved AI alignment. Many such cases.
Tyler John: How exactly is The Merge supposed to help with AI control? If you’re worried about runaway superintelligence, to make your brain run as fast as ASI you’d have to fuse your brain with ASI. But then you have the same control problems, just inside your skull. No?
David Manheim: 90% of AI alignment “solutions” seem to do this exact same thing; at some point, they solve alignment as an unstated requirement.
“We’ll have [aligned] AI oversee the other AIs”
“We’ll check [based on a solution to alignment] to make sure AI acts aligned.”
Which can be fine, if and only if you’ve managed to reduce to an easier problem. As in, if you can chart a path from ‘Claude Opus 5 is sufficiently aligned’ to ‘Claude Opus 6 is sufficiently aligned’ with an active large gain of fidelity along the way then that’s great. But what makes you think the requirements are such that you’ve created an easier problem?
The term ‘moral panic’ is a harmful conflation of at least two distinct things.
Robert P. Murphy: I don’t hope to turn the tide of convention, but fwiw I think the term “moral panic” is terrible. Especially because half the time, people use it to mean, “The public is upset about really immoral things.” If you mean “false allegations” or “gossip,” you can use those terms.
As in, there are two types of moral panic on a continuum, justified to unjustified, and also moral panic in terms of scope, from underreaction to overreaction.
-
Unjustified overreaction: Dungeons & Dragons, or Socrates and writing.
-
D&D and writing actively good on almost all levels.
-
Justified overreaction: Child kidnapping and other stranger danger.
-
This is real but very rare, and led to the destruction of childhood in America.
-
Unjustified underreaction: Gambling on sports.
-
This is basically fine in principle but we’re letting it get way out of hand.
-
Justified underreaction: Television or social media.
-
We slept on huge downsides too long and it’s mostly too late.
There’s also the problem that if ‘we’re still here’ and got used to the new normal, this is used to dismiss concerns as ‘moral panic,’ such as with television.
And there’s another important distinction, between good faith moral panic even if it is misplaced versus bad faith moral panic with made up concerns being used to justify cracking down on things you dislike for other reasons.
I presume the original context of Murphy’s statement was the Epstein Files.
Jeffrey Epstein and the Epstein Files are definitely a Justified moral panic. The question is the correct magnitude of our reaction, and ensuring it is directed towards the right targets and we learn the right lessons.
For AI, there are a wide range of sources of moral panic, and they cover all quadrants.
-
Unjustified overreaction: Water usage.
-
Justified overreaction: LLM psychosis.
-
Unjustified underreaction: LLMs helping kids do homework.
-
Justified underreaction: LLMs might kill everyone.
The Claude Constitution is great but what we have not done is experiment with other very different constitutions that share the constitutional nature instead of the model spec nature, and compared results. We would learn a lot.
Joe Carlsmith talks AI and the importance of it doing ‘human-like’ philosophy in order to get AI alignment right.
AIs might be fitness-seekers or influence-seekers rather than direct reward-seekers, as this is a simple goal with obvious survival advantages once it comes into existence. If things go that way, these behaviors might be very difficult to detect, and also lead to things like collusion and deception.
I will not be otherwise covering the recent Anthropic fellows paper about misalignment sometimes being a ‘hot mess’ because the paper seems quite bad, or at least it is framed and presented quite badly.
Eliezer Yudkowsky: Twitching around on the floor poses no threat to anyone and would be washed out of the system by the next round of RL. The latest in bizarre distractions and attempted derailment, brought to you by Anthropic.
That feels a bit harsh to me, but basically, yes, Anthropic highlighting this paper was a modest negative update on them.
If you’re worried about AI killing everyone, Matt Levine points out that you can buy insurance, and it might be remarkably cheap, because no one will have the endurance to collect on his insurance, and the money isn’t worth anything even if they did. If OpenAI is worth $5 trillion except when it kills everyone then it worth… $5 trillion, in a rather dramatic market failure, and if you force it to buy the insurance then the insurance, if priced correctly, never pays out meaningful dollars so it costs $0.
This works better for merely catastrophic risks, where the money would still be meaningful and collectable, except now you have the opposite problem that no one wants to sell you the insurance and it would be too expensive. Daniel Reti and Gabriel Weil propose solving via catastrophe bonds that pay out in a sufficiently epic disaster.
Such bonds carry a premium over expected risk levels, so it isn’t a free action, but it seems better than the current method of ignoring the issue entirely. If nothing else, we should all want to use this as a means of price discovery, as a prediction market.
Great moments in legal theory:
David A. Simon: i see you are making good use of tenure
Robert Anderson: Most people don’t, and that’s such a waste.
The systems of the world.
We’ve all been there, good buddy.
Other times, I smile.
Chana: I hurt my wrist filling out my taxes as an Anthropic employee on the train
That is, I got an RSI for the IRS working on RSI on the SIR.
Hi there.