Mainly, there was a great question asked, so I gave a few hour shot at writing out my answer. I then close with a few other follow-ups on issues related to the statement.
Scott Alexander: I think removing a 10% chance of humanity going permanently extinct is worth another 25-50 years of having to deal with the normal human problems the normal way.
Sriram Krishnan: Scott what are verifiable empirical things ( model capabilities / incidents / etc ) that would make you shift that probability up or down over next 18 months?
I went through three steps interpreting this (where p(doom) = probability of existential risk to humanity, either extinction, irrecoverable collapse or loss of control over the future).
Instinctive read is the clearly intended question, an excellent one: Either “What would shift the amount that waiting 25-50 years would reduce p(doom)?” or “What would shift your p(doom)?”
Literal interpretation, also interesting but presumably not intended: What would shift how much of a reduction in p(doom) would be required to justify waiting?
Conclusion on reflection: Mostly back to the first read.
All three questions are excellent distinct questions, in addition to the related fourth excellent question that is highly related, which is the probability that we will be capable of building superintelligence or sufficiently advanced AI that creates 10% or more existential risk.
The 18 month timeframe seems arbitrary, but it seems like a good exercise to ask only within the window of ‘we are reasonably confident that we do not expect an AGI-shaped thing.’
Agus offers his answers to a mix of these different questions, in the downward direction – as in, which things would make him feel safer.
Scott Alexander: Thanks for your interest. I’m not expecting too much danger in the next 18 months, so these would mostly be small updates, but to answer the question:
MORE WORRIED:
– Anything that looks like shorter timelines, especially superexponential progress on METR time horizons graph or early signs of recursive self-improvement.
– China pivoting away from their fast-follow strategy towards racing to catch up to the US in foundation models, and making unexpectedly fast progress.
– More of the “model organism shows misalignment in contrived scenario” results, in gradually less and less contrived scenarios.
– Models more likely to reward hack, eg commenting out tests instead of writing good code, or any of the other examples in here – or else labs only barely treading water against these failure modes by investing many more resources into them.
– Companies training against chain-of-thought, or coming up with new methods that make human-readable chain-of-thought obsolete, or AIs themselves regressing to incomprehensible chains-of-thought for some reason (see eg https://antischeming.ai/snippets#reasoning-loops).
LESS WORRIED
– The opposite of all those things.
– Strong progress in transparency and mechanistic interpretability research.
– Strong progress in something like “truly understanding the nature of deep learning and generalization”, to the point where results like https://arxiv.org/abs/2309.12288 make total sense and no longer surprise us.
– More signs that everyone is on the same side and government is taking this seriously (thanks for your part in this).
– More signs that industry and academia are taking this seriously, even apart from whatever government requires of them.
– Some sort of better understanding of bottlenecks, such that even if AI begins to recursively self-improve, we can be confident that it will only proceed at the rate of chip scaling or [some other nontrivial input]. This might look like AI companies releasing data that help give us a better sense of the function mapping (number of researchers) x (researcher experience/talent) x (compute) to advances.
This is a quick and sloppy answer, but I’ll try to get the AI Futures Project to make a good blog post on it and link you to it if/when it happens.
Giving full answers to these questions would require at least an entire long post, but to give what was supposed to be the five minute version that turned into a few hours:
Quite a few things could move the needle somewhat, often quite a lot. This list assumes we don’t actually get close to AGI or ASI within those 18 months.
Capabilities being more jagged reduces p(doom), less jagged increases it.
Coding or ability to do AI research related tasks being a larger comparative advantage of LLMs increases p(doom), the opposite reduces it.
Quality of the discourse and its impact on ability to make reasonable decisions.
Relatively responsible AI sources being relatively well positioned reduces p(doom), them being poorly positioned increases it, with the order being roughly Anthropic → OpenAI and Google (and SSI?) → Meta and xAI → Chinese labs.
Updates about the responsibility levels and alignment plans of the top labs.
Updates about alignment progress, alignment difficulty and whether various labs are taking promising approaches versus non-promising approaches.
New common knowledge will often be an ‘unhint,’ as in the information makes the problem easier to solve via making you realize why your approach wouldn’t work.
This can be good or bad news, depending on what you understood previously. Many other things are also in the category ‘important, sign of impact weird.’
Reward hacking is a great example of an unhint, in that I expect to ‘get bad news’ but for the main impact of this being that we learn the bad news.
Note that models are increasingly situationally aware and capable of thinking ahead, as per Claude Sonnet 4.5, and that we need to worry more that things like not reward hacking are ‘because the model realized it couldn’t get away with it’ or was worried it might be in an eval, rather than that the model not wanting to reward hack. Again, it is very complex which direction to update.
Increasing situational awareness is a negative update but mostly priced in.
Misalignment in less contrived scenarios would indeed be bad news, and ‘the less contrived the more misaligned’ would be the worst news of all here.
Training against chain-of-thought would be a major negative update, as would be chain-of-thought becoming impossible for humans to read.
This section could of course be written at infinite length.
In particular, updates on whether the few approaches that could possibly work look like they might actually work, and we might actually try them sufficiently wisely that they might work. Various technical questions too complex to list here.
Unexpected technical developments of all sorts, positive and negative.
Better understanding of the game theory, decision theory, economic theory or political economy of an AGI future, and exactly how impossible the task is of getting a good outcome conditional on not failing straight away on alignment.
Ability to actually discuss seriously the questions of how to navigate an AGI future if we can survive long enough to face these ‘phase two’ issues, and level of hope that we would not commit collective suicide even in winnable scenarios. If all the potentially winning moves become unthinkable, all is lost.
Level of understanding by various key actors of the situation aspects, and level of various pressures that will be placed upon them, including by employees and by vibes and by commercial and political pressures, in various directions.
Prediction of how various key actors will make various of the important decisions in likely scenarios, and what their motivations will be, and who within various corporations and governments will be making the decisions that matter.
Government regulatory stance and policy, level of transparency and state capacity and ability to intervene. Stance towards various things. Who has the ear of the government, both White House and Congress, and how powerful is that ear. Timing of the critical events and which administration will be handling them.
General quality and functionality of our institutions.
Shifts in public perception and political winds, and how they are expected to impact the paths that we take, and other political developments generally.
Level of potential international cooperation and groundwork and mechanisms for doing so. Degree to which the Chinese are AGI pilled (more is worse).
Observing how we are reacting to mundane current AI, and how this likely extends to how we will interact with future AI.
To some extent, information about how vulnerable or robust we are on CBRN risks, especially bio and cyber, the extent hardening tools seem to be getting used and are effective, and evaluation of the Fragile World Hypothesis and future offense-defense balance, but this is often overestimated as a factor.
Expectations on bottlenecks to impact even if we do get ASI with respect to coding, although again this is usually overestimated.
The list could go on. This is a complex test and on the margin everything counts. A lot of the frustration with discussing these questions is different people focus on very different aspects of the problem, both in sensible ways and otherwise.
That’s a long list, so to summarize the most important points on it:
Timelines.
Jaggedness of capabilities relative to humans or requirements of automation.
The relative position in jaggedness of coding and automated research.
Alignment difficulty in theory.
Alignment difficulty in practice, given who will be trying to solve this under what conditions and pressures, with what plans and understanding.
Progress on solving gradual disempowerment and related issues.
Quality of policy, discourse, coordination and so on.
World level of vulnerability versus robustness to various threats (overrated, but still an important question).
Imagine we have a distribution of ‘how wicked and impossible are the problems we would face if we build ASI, with respect to both alignment and to the dynamics we face if we handle alignment, and we need to win both’ that ranges from ‘extremely wicked but not strictly impossible’ to full Margaritaville (as in, you might as well sit back and have a margarita, cause it’s over).
At the same time as everything counts, the core reasons these problems are wicked are fundamental. Many are technical but the most important one is not. If you’re building sufficiently advanced AI that will become far more intelligent, capable and competitive than humans, by default this quickly ends poorly for the humans.
On a technical level, for largely but not entirely Yudkowsky-style reasons, the behaviors and dynamics you get prior to AGI and ASI are not that informative of what you can expect afterwards, and when they are often it is in a non-intuitive way or mostly informs this via your expectations for how the humans will act.
Note that from my perspective, we are here starting the conditional risk a lot higher than 10%. My conditional probability here is ‘if anyone builds it, everyone probably dies,’ as in a number (after factoring in modesty) between 60% and 90%.
My probability here is primarily different from Scott’s (AIUI) because I am much more despairing about our ability to muddle through or get success with an embarrassingly poor plan on alignment and disempowerment, but it is not higher because I am not as despairing as some others (such as Soares and Yudkowsky).
If I was confident that the baseline conditional-on-ASI-soonish risk was at most 10%, then I would be trying to mitigate that risk, it would still be humanity’s top problem, but I would understand wanting to continue onward regardless, and I wouldn’t have signed the recent statement.
In order to move me down enough to think that moving forward would be a reasonable thing to do any time soon out of anything other then desperation that there was no other option, I would need at least:
An alignment plan that looked like it would work, on the first try. That could be a new plan, or it could be new very positive updates on one of the few plans we have now that I currently think could possibly work, all of which are atrociously terrible compared to what I would have hoped for a few years ago, but this is mitigated by having forms of grace available that seemingly render the problem a lower level of impossible and wicked than I previously expected (although still highly wicked and impossible).
Given the 18 month window and current trends, this probably either is something new, or it is a form of (colloquially speaking) ‘we can hit, in a remarkably capable model, an attractor state basin in distribution mindspace that is robustly good such that it will want to modify itself and its de facto goals and utility function and its successors continuously towards the target we actually need to hit and wanting to hit the target we actually need to hit.’
Then again, perhaps I will be surprised in some way.
Confidence that this plan would actually get executed, competently.
A plan to solve gradual disempowerment issues, in a way I was confident would work, create a future with value, and not lead to unacceptable other effects.
Confidence that this plan would actually get executed, competently.
In a sufficiently dire race condition, where all coordination efforts and alternatives have failed, of course you go with the best option you have, especially if up against an alternative that is 100% (minus epsilon) to lose.
Everything above will also shift this, since it gives you more or less doom that extra time can prevent. What else can shift the estimate here within 18 months?
Again, ‘everything counts in large amounts,’ but centrally we can narrow it down.
There are five core questions, I think?
What would it take to make this happen? As in, will this indefinitely be a sufficiently hard thing to build that we can monitor large data centers, or do we need to rapidly keep an eye on smaller and smaller compute sources? Would we have to do other interventions as well?
Are we ready to do this in a good way and how are we going to go about it? If we have a framework and the required technology, and can do this in a clean way, with voluntary cooperation and without either use or massive threat of force or concentration of power, especially in a way that allows us to still benefit from AI and work on alignment and safety issues effectively, then that looks a lot better. Every way that this gets worse makes our prospects here worse.
Did we get too close to the finish line before we tried to stop this from happening? A classic tabletop exercise endgame is that the parties realize close to the last moment that they need to stop things, or leverage is used to force this, but the AIs involved are already superhuman, so the methods used would have worked before and work anymore. And humanity loses.
Do we think we can make good use of this time, that the problem is solvable? If the problems are unsolvable, or our civilization isn’t up for solving them, then time won’t solve them.
How much risk do we take on as we wait, in other ways?
One could summarize this as:
How would we have to do this?
Are we going to be ready and able to do that?
Will it be too late?
Would we make good use of the time we get?
What are the other risks and costs of waiting?
I expect to learn new information about several of these questions.
(My current median time-to-crazy in this sense is roughly 2031, but with very wide uncertainty and error bars and not the attention I would put on that question if I thought the exact estimate mattered a lot, and I don’t feel I would ‘have any right to complain’ if the outcome was very far off from this in either direction. If a next-cycle model did get there I don’t think we are entitled to be utterly shocked by this.)
This is the biggest anticipated update because it will change quite a lot. Many of the other key parts of the model are much harder to shift, but timelines are an empirical question that shifts constantly.
In the extreme, if progress looks to be stalling out and remaining at ‘AI as normal technology,’ then this would be very good news. The best way to not build superintelligence right away is if building it is actually super hard and we can’t, we don’t know how. It doesn’t strictly change the conditional in questions one and two, but it renders those questions irrelevant, and this would dissolve a lot of practical disagreements.
Signs of this would be various scaling laws no longer providing substantial improvements or our ability to scale them running out, especially in coding and research, bending the curve on the METR graph and other similar measures, the systematic failure to discover new innovations, extra work into agent scaffolding showing rapidly diminishing returns and seeming upper bounds, funding required for further scaling drying up due to lack of expectations of profits or some sort of bubble bursting (or due to a conflict) in a way that looks sustainable, or strong evidence that there are fundamental limits to our approaches and therefore important things our AI paradigm simply cannot do. And so on.
Ordinary shifts in the distribution of time to ASI come with every new data point. Every model that disappoints moves you back, observing progress moves you forward. Funding landscape adjustments, levels of anticipated profitability and compute availability move this. China becoming AGI pilled versus fast following or foolish releases could move this. Government stances could move this. And so on.
Time passing without news lengthens timelines. Most news shortens timelines. The news item that lengthens timelines is mostly ‘we expected this new thing to be better or constitute more progress, in some form, and instead it wasn’t and it didn’t.’
To be clear that I am doing this: There are a few things that I didn’t make explicit, because one of the problems with such conversations is that in some ways we are not ready to have these conversations, as many branches of the scenario tree involve trading off sacred values or making impossible choices or they require saying various quiet parts out loud. If you know, you know.
That was less of a ‘quick and sloppy’ answer than Scott’s, but still feels very quick and sloppy versus what I’d offer after 10 hours, or 100 hours.
Jawwwn: Palantir CEO Alex Karp on calls for a “ban on AI Superintelligence”
“We’re in an arms race. We’re either going to have AI and determine the rules, or our adversaries will.”
“If you put impediments… we’ll be buying everything from them, including ideas on how to run our gov’t.”
He is the CEO of Palantir literally said this is an ‘arms race.’ The first rule of an arms race is you don’t loudly tell them you’re in an arms race. The second rule is you don’t win it by building superintelligence as your weapon.
Once you build superintelligence, especially if you build it explicitly as a weapon to ‘determine the rules,’ humans no longer determine the rules. Or anything else. That is the point.
Until we have common knowledge of the basic facts that goes at least as far as major CEOs not saying the opposite in public, job one is to create this common knowledge.
I also enjoyed Tyler Cowen fully Saying The Thing, this really is his position:
Tyler Cowen: Dean Ball on the call for a superintelligence ban, Dean is right once again. Mainly (once again) a lot of irresponsibility on the other side of that ledger, you will not see them seriously address the points that Dean raises. If you want to go this route, do the hard work and write an 80-page paper on how the political economy of such a ban would work.
That’s right. If you want to say that not building superintelligence as soon as possible is a good idea, first you have to write an 80-page paper on the political economy of a particular implementation of a ban on that idea. That’s it, he doesn’t make the rules. Making a statement would otherwise be irresponsible, so until such time as a properly approved paper comes out on these particular questions, we should instead be responsible by going ahead not talking about this and focus on building superintelligence as quickly as possible.
I notice that a lot of people are saying that humanity has already lost control over the development of AI, and that there is nothing we can do about this, because the alternative to losing control over the future is even worse. In which case, perhaps that shows the urgency of the meddling kids proving them wrong?
Alternatively…
How dare you try to prevent the building of superintelligence without knowing how to prevent this safely, ask the people who want us to build superintelligence without knowing how to do so safely.
Seems like a rather misplaced demand for detailed planning, if you ask me. But it’s perfectly valid and highly productive to ask how one might go about doing this. Indeed, what this would look like is one of the key inputs in the above answers.
One key question is, are you going to need some sort of omnipowerful international regulator with sole authority that we all need to be terrified about, or can we build this out of normal (relatively) lightweight international treaties and verification that we can evolve gradually over time if we start planning now?
Peter Wildeford: Don’t let them tell you that it’s not possible.
Will Marshall points out that in order to accomplish this, we would need extensive track-two processes between thinkers over an extended period to get it right. Which is indeed exactly why you can offer templates and ideas but to get serious you need to first agree to the principle, and then work on details.
Tyler John also makes a similar argument that multilateral agreements would work. The argument that ‘everyone would have incentive to cheat’ is indeed the main difficulty, but also is not a new problem.
What was done academically prior to the nuclear arms control treaties? Claude points me to Schelling & Halperin’s “Strategy and Arms Control” (1961), Schelling’s “The Strategy of Conflict” (1960) and “Arms and Influence” (1966), and Boulding’s “Conflict and Defense” (1962). So the analysis did not get so detailed even then with a much more clear game board, but certainly there is some work that needs to be done.
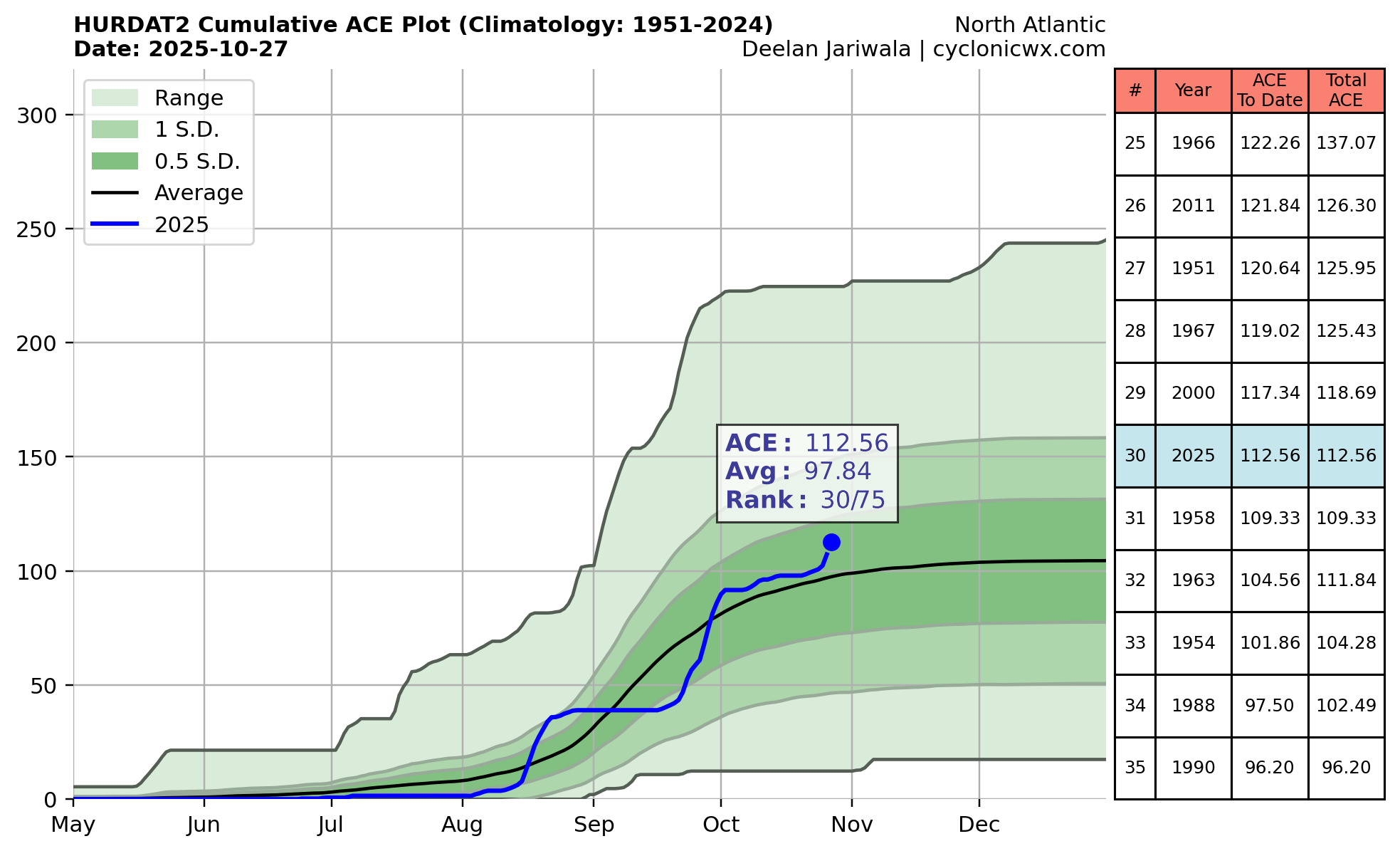
The sole bright spot is that, as of Monday, the core of the storm’s strongest winds remains fairly small. Based on recent data, its hurricane-force winds only extend about 25 miles from the center. Unfortunately, Melissa will make a direct hit on Jamaica, with the island’s capital city of Kingston to the right of the center, where winds and surge will be greatest.
Beyond Jamaica, Melissa will likely be one of the strongest hurricanes on record to hit Cuba. Melissa will impact the eastern half of the island on Tuesday night, bringing the trifecta of heavy rainfall, damaging winds, and storm surge. The storm also poses lesser threats to Hispaniola, the Bahamas, and potentially Bermuda down the line. There will be no impacts in the United States.
A sneakily strong season
Most US coastal residents will consider this Atlantic season, which officially ends in a little more than a month, to be fairly quiet. There have been relatively few direct impacts to the United States from named storms.
One can see the signatures of Erin, Humberto, and Melissa in this chart of Accumulated Cyclone Energy for 2025.
Credit: CyclonicWx.com
One can see the signatures of Erin, Humberto, and Melissa in this chart of Accumulated Cyclone Energy for 2025. Credit: CyclonicWx.com
But this season has been sneakily strong. Melissa is just the 45th storm since 1851 to reach Category 5 status, as defined as having sustained winds of 157 mph or greater. Already this year, Erin and Humberto reached Category 5 status, and now Melissa is the third such hurricane. Fortunately, the former two storms posed minimal threat to land.
Before this year, there had only ever been one season with three Category 5 hurricanes on record: 2005, which featured three storms that all impacted US Gulf states and had their names retired, Katrina, Rita, and Wilma.
“Now it looks like the White House is physically being destroyed.”
The facade of the East Wing of the White House is demolished by work crews on October 22, 2025. Credit: Andrew Harnik/Getty Images
You need to go up—way up—to fully appreciate the changes underway at the White House this week.
Demolition crews starting tearing down the East Wing of the presidential mansion Tuesday to clear room for the construction of a new $300 million, 90,000-square-foot ballroom, a recent priority of President Donald Trump. The teardown drew criticism and surprise from Democratic lawmakers, former White House staffers, and members of the public.
It was, after all, just three months ago that President Donald Trump defended his ballroom plan by saying it wouldn’t affect the existing structure at the White House. “It won’t interfere with the current building,” he said in July. “It’ll be near it but not touching it—and pays total respect to the existing building, which I’m the biggest fan of.”
So it shocked a lot of people when workers took a wrecking ball to the East Wing. Sen. Lisa Murkowski (R-Alaska) told reporters Thursday that the “optics are bad” as the Trump administration demolishes part of the White House, especially during a government shutdown.
“People are saying, ‘Oh, the government’s being destroyed,’” she said. “Well, now it looks like the White House is physically being destroyed.”
The US Secret Service on Thursday closed access to the Ellipse, a public park overlooking the South Lawn of the White House. Journalists were capturing “live images” of the East Wing destruction from the Ellipse before the Secret Service ushered them out of the park, according to CNN’s Jim Sciutto. Employees at the Treasury Building, just across the street from the East Wing, were instructed not to share photos of the demolition work, The Wall Street Journal reported.
Some Trump supporters used their social media accounts to push back against the outcry, claiming only a small section of the East Wing’s facade would be torn down. An image taken from space revealed the reality Thursday.
Eyes always above
Without press access to see the demolition firsthand, it fell to a camera hundreds of miles above the White House to see what was really happening at the East Wing. Planet Labs released an image taken Thursday morning from one of its SkySat satellites showing the 123-year-old annex leveled.
This image taken Thursday from a SkySat Earth observation satellite shows that the East Wing of the White House is gone. Credit: Planet Labs PBC
What became known as the East Wing was first constructed in 1902 and was then rebuilt in 1942 during the Franklin Roosevelt administration to create more office space and provide cover for a bunker during World War II. In modern presidencies, the East Wing was typically home to the first lady’s staff.
Planet Labs, based in San Francisco, operates a fleet of hundreds of small Earth-imaging satellites mapping the planet every day. The company sells its imagery to commercial customers and the US government, including intelligence agencies, which use the imagery to augment the surveillance capabilities of more exquisite government-owned spy satellites.
Users often turn to satellite imagery from companies like Planet Labs to find out what’s going on in war zones, countries ruled by authoritarian regimes, or in the aftermath of a natural disaster. Satellite constellations like Planet Labs scan for changes across the globe every day, making it virtually impossible to hide a large construction project.
The SkySat satellite used for Thursday’s examination of the White House flies at an altitude of approximately 295 miles (475 kilometers). It can capture imagery with a resolution of about 20 inches (50 centimeters) per pixel. Planet Labs owns 15 SkySats, each with three overlapping 5.5-megapixel imaging sensors fitted under a downward-facing 14-inch-diameter (35-centimeter) telescope, according to the company.
Who’s paying?
It turns out some of Planet Labs’ cohorts among the government’s cadre of defense and aerospace contractors are actually funding the construction of the new White House ballroom. Lockheed Martin, the Pentagon’s largest defense contractor, is on the list of donors released by the White House. At least two other companies with business relating to defense and aerospace were also on the list: Booz Allen Hamilton and Palantir Technologies.
Palantir has invested in BlackSky, one of Planet’s competitors in the commercial remote sensing market.
People watch along a fence line Thursday as crews demolish the East Wing of the White House. Credit: Brendan Smialowski/AFP via Getty Images)
The Trump administration has said no public money will go toward the new ballroom, but officials haven’t said how much each donor is contributing. Many donors have business dealings with the federal government, raising ethical concerns that those paying for the ballroom might win favor in future contract decisions.
Trump said he will also contribute an undisclosed sum for the ballroom.
Regardless of whether the donors are buying influence, they are funding the most significant overhaul of the White House grounds since former President Harry Truman renovated the mansion’s interior and added a balcony to the South Portico. The Truman-era changes were approved by Congress, which established a commission to oversee the work. There’s been no such oversight from Congress this time.
The new ballroom will be nearly twice the size of the most iconic element of the White House grounds: the two-century-old executive residence.
“It’s going to turn the executive mansion into an annex to the party space,” said Edward Lengel, who served as chief historian of the White House Historical Association during Trump’s first term. “I think all the founders would have been disgusted by this,” he told CNN.
Karoline Leavitt, the White House press secretary, shared a different point of view in an interview with Fox News earlier this week.
“I believe there’s a lot of fake outrage right now because nearly every single president who has lived in this beautiful White House behind me has made modernizations and renovations of their own,” Leavitt said.
An official White House fact sheet published Tuesday used similar sensationalized language, accusing “unhinged leftists and their Fake News allies” of “clutching their pearls over President Donald J. Trump’s visionary addition of a grand, privately-funded ballroom to the White House.”
President Donald Trump displays a rendering of the White House ballroom as he meets with NATO Secretary General Mark Rutte (left) in the Oval Office of the White House on Wednesday. Credit: Alex Wong/Getty Images
It’s true that every president has put their own mark on the White House, but all of the updates cost at least an order of magnitude less than Trump’s ballroom. Most amounted to little more than redecorating, and none were as destructive as this week’s teardown. Former President Barack Obama repainted the lines of the White House tennis court and installed hoops to turn it into a basketball court. During the George W. Bush administration, the White House press briefing room got a significant makeover. Taxpayers and media companies shared the bill. It’s hard to imagine that happening today.
Former President Gerald Ford had an outdoor swimming pool built near the West Wing. Former First Lady Jacqueline Kennedy famously spearheaded the redesign of the White House Rose Garden and East Garden, which was later renamed in her honor. The grass in the Rose Garden was paved over with stone tiles earlier this year, and the Jacqueline Kennedy Garden was razed this week, the result of which was also visible from space.
In July, Leavitt said the East Wing would be “modernized.” Like Trump, she did not mention plans for demolition, only saying: “The necessary construction will take place.”
Thanks to satellites and commercial space, we now know what necessary construction really meant.
Stephen Clark is a space reporter at Ars Technica, covering private space companies and the world’s space agencies. Stephen writes about the nexus of technology, science, policy, and business on and off the planet.
OpenAI has acquired Software Applications Incorporated (SAI), perhaps best known for the core team that produced what became Shortcuts on Apple platforms. More recently, the team has been working on Sky, a context-aware AI interface layer on top of macOS. The financial terms of the acquisition have not been publicly disclosed.
“AI progress isn’t only about advancing intelligence—it’s about unlocking it through interfaces that understand context, adapt to your intent, and work seamlessly,” an OpenAI rep wrote in the company’s blog post about the acquisition. The post goes on to specify that OpenAI plans to “bring Sky’s deep macOS integration and product craft into ChatGPT, and all members of the team will join OpenAI.”
That includes SAI co-founders Ari Weinstein (CEO), Conrad Kramer (CTO), and Kim Beverett (Product Lead)—all of whom worked together for several years at Apple after Apple acquired Weinstein and Kramer’s previous company, which produced an automation tool called Workflows, to integrate Shortcuts across Apple’s software platforms.
The three SAI founders left Apple to work on Sky, which leverages Apple APIs and accessibility features to provide context about what’s on screen to a large language model; the LLM takes plain language user commands and executes them across multiple applications. At its best, the tool aimed to be a bit like Shortcuts, but with no setup, generating workflows on the fly based on user prompts.
In turn, the delay in network state propagations spilled over to a network load balancer that AWS services rely on for stability. As a result, AWS customers experienced connection errors from the US-East-1 region. AWS network functions affected included the creating and modifying Redshift clusters, Lambda invocations, and Fargate task launches such as Managed Workflows for Apache Airflow, Outposts lifecycle operations, and the AWS Support Center.
For the time being, Amazon has disabled the DynamoDB DNS Planner and the DNS Enactor automation worldwide while it works to fix the race condition and add protections to prevent the application of incorrect DNS plans. Engineers are also making changes to EC2 and its network load balancer.
A cautionary tale
Ookla outlined a contributing factor not mentioned by Amazon: a concentration of customers who route their connectivity through the US-East-1 endpoint and an inability to route around the region. Ookla explained:
The affected US‑EAST‑1 is AWS’s oldest and most heavily used hub. Regional concentration means even global apps often anchor identity, state or metadata flows there. When a regional dependency fails as was the case in this event, impacts propagate worldwide because many “global” stacks route through Virginia at some point.
Modern apps chain together managed services like storage, queues, and serverless functions. If DNS cannot reliably resolve a critical endpoint (for example, the DynamoDB API involved here), errors cascade through upstream APIs and cause visible failures in apps users do not associate with AWS. That is precisely what Downdetector recorded across Snapchat, Roblox, Signal, Ring, HMRC, and others.
The event serves as a cautionary tale for all cloud services: More important than preventing race conditions and similar bugs is eliminating single points of failure in network design.
“The way forward,” Ookla said, “is not zero failure but contained failure, achieved through multi-region designs, dependency diversity, and disciplined incident readiness, with regulatory oversight that moves toward treating the cloud as systemic components of national and economic resilience.”
Earlier this month, Tesla rolled out a new firmware update that added a pair of new driving modes for the controversial full self-driving (FSD) feature. One, called “Sloth,” relaxes acceleration and stays in its lane. The other, called “Mad Max,” does the opposite: It speeds and swerves through traffic to get you to your destination faster. And after multiple reports of FSD Teslas doing just that, the National Highway Traffic Safety Administration wants to know more.
In fact, “Mad Max” mode is not entirely new—Tesla beta-tested the same feature in Autopilot in 2018, before deciding not to roll it out in a production release after widespread outcry.
These days, the company is evidently feeling less constrained; despite having just lost a federal wrongful death lawsuit that will cost it hundreds of millions of dollars, it described the new mode as being able to drive “through traffic at an incredible pace, all while still being super smooth. It drives your car like a sports car. If you are running late, this is the mode for you.”
“Unable to scrape Reddit directly, they mask their identities, hide their locations, and disguise their web scrapers to steal Reddit content from Google Search,” Lee said. “Perplexity is a willing customer of at least one of these scrapers, choosing to buy stolen data rather than enter into a lawful agreement with Reddit itself.”
On Reddit, Perplexity pushed back on Reddit’s claims that Perplexity ignored requests to license Reddit content.
“Untrue. Whenever anyone asks us about content licensing, we explain that Perplexity, as an application-layer company, does not train AI models on content,” Perplexity said. “Never has. So, it is impossible for us to sign a license agreement to do so.”
Reddit supposedly “insisted we pay anyway, despite lawfully accessing Reddit data,” Perplexity said. “Bowing to strong arm tactics just isn’t how we do business.”
Perplexity’s spokesperson, Jesse Dwyer, told Ars the company chose to post its statement on Reddit “to illustrate a simple point.”
“It is a public Reddit link accessible to anyone, yet by the logic of Reddit’s lawsuit, if you mention it or cite it in any way (which is your job as a reporter), they might just sue you,” Dwyer said.
But Reddit claimed that its business and reputation have been “damaged” by “misappropriation of Reddit data and circumvention of technological control measures.” Without a licensing deal ensuring that Perplexity and others are respecting Reddit policies, Reddit cannot control who has access to data, how they’re using data, and if data use conflicts with Reddit’s privacy policy and user agreement, the complaint said.
Further, Reddit’s worried that Perplexity’s workaround could catch on, potentially messing up Reddit’s other licensing deals. All the while, Reddit noted, it has to invest “significant resources” in anti-scraping technology, with Reddit ultimately suffering damages, including “lost profits and business opportunities, reputational harm, and loss of user trust.”
Reddit’s hoping the court will grant an injunction barring companies from scraping Reddit content from Google SERPs. It also wants companies blocked from both selling Reddit data and “developing or distributing any technology or product that is used for the unauthorized circumvention of technological control measures and scraping of Reddit data.”
If Reddit wins, companies could be required to pay substantial damages or to disgorge profits from the sale of Reddit content.
Advance Publications, which owns Ars Technica parent Condé Nast, is the largest shareholder in Reddit.
What if, instead of “work-life balance,” you had no balance at all—your life was your work… and work happened seven days a week?
Did I say days? I actually meant days and nights, because the job I’m talking about wants you to know that you will also work weekends and evenings, and that “it’s ok to send messages at 3am.”
Also, I hope you aren’t some kind of pajama-wearing wuss who wants to work remotely; your butt had better be in a chair in a New York City office on Madison Avenue, where you need enough energy to “run through walls to get things done” and respond to requests “in minutes (or seconds) instead of hours.”
To sweeten this already sweet deal, the job comes with a host of intangible benefits, such as incredible colleagues. The kind of colleagues who are not afraid to be “extremely annoying if it means winning.” The kind of colleagues who will “check-in on things 10x daily” and “double (or quadruple) text if someone hasn’t responded”—and then call that person too. The kind of colleagues who have “a massive chip on the shoulder and/or a neurodivergent brain.”
That’s right, I’m talking about “A-players.” There are no “B-players” here, because we all know that B-players suck. But if, by some accident, the company does onboard someone who “isn’t an A-player,” there’s a way to fix it: “Fast firing.”
“Please be okay with this,” potential employees are told.
“Only A-players can hire A-players,” says the company, and you know that it is staffed with A-players because its most recent Team page (since removed) was made up entirely of young dudes and an AI-enhanced HR dog named Hurin who “enforces 7-day work week & remote ban.”
The construction occurred despite a previous crackdown that resulted in the release of “around 7,000 people from a brutal call center-like system that runs on greed, human trafficking and violence,” the AFP wrote. “Freed workers from Asia, Africa and elsewhere showed AFP journalists the scars and bruises of beatings they said were inflicted by their bosses. They said they had been forced to work around the clock, trawling for victims for a plethora of phone and Internet scams.”
Another AFP article said “the border region fraud factories are typically run by Chinese criminal syndicates, analysts say, often overseen by Myanmar militias given tacit backing by the Myanmar junta in return for guaranteeing security.”
The Associated Press wrote that “Myanmar is notorious for hosting cyberscam operations responsible for bilking people all over the world. These usually involve gaining victims’ confidence online with romantic ploys and bogus investment pitches. The centers are infamous for recruiting workers from other countries under false pretenses, promising them legitimate jobs and then holding them captive and forcing them to carry out criminal activities.”
Senator urged Musk to take action
An October 2024 report by the United Nations Office on Drugs and Crime described the use of Starlink in fraud operations. About 80 “Starlink satellite dishes linked to cyber-enabled fraud operations” were seized between April and June 2024 in Myanmar and Thailand, the report said. Starlink is prohibited in both countries.
“Despite Starlink use being strictly monitored and, in some cases, restricted through geofencing, organized crime groups appear to have found ways around existing security protocols in order to access the remote high-speed Internet connectivity made possible by this portable technology,” the report said.
In July this year, US Sen. Maggie Hassan (D-NH) urged SpaceX CEO Elon Musk to prevent criminals from using Starlink for scam operations that target Americans.
“While SpaceX has stated that it investigates and deactivates Starlink devices in various contexts, it seemingly has not publicly acknowledged the use of Starlink for scams originating in Southeast Asia—or publicly discussed actions the company has taken in response,” Hassan wrote in a letter to Musk. “Scam networks in Myanmar, Thailand, Cambodia, and Laos, however, have apparently continued to use Starlink despite service rules permitting SpaceX to terminate access for fraudulent activity.”
Hassan is the top Democrat on the US Congress Joint Economic Committee, which is reportedly investigating the use of Starlink in the scam operations. Dreyer said last night that SpaceX is committed to “detecting and preventing misuse by bad actors.”
Android XR is Google’s most ambitious take on Android as a virtual environment. The company calls it an “infinite screen” that lets you organize floating apps to create a custom workspace. The software includes 3D versions of popular Google apps like Google Maps, Google Photos, and YouTube, along with streaming apps, games, and custom XR experiences from the likes of Calm and Adobe.
Google says that its support of open standards for immersive experiences means more content is coming. However, more than anything else, Android XR is a vehicle for Gemini. The Gemini Live feature from phones is available in Android XR, and it’s more aware of your surroundings thanks to all the cameras and orientation sensors in Galaxy XR. For example, you can ask Gemini questions about what’s on the screen—that includes app content or real objects that appear in passthrough video when you look around. Gemini can also help organize your floating windows
While more Android XR hardware is planned, Galaxy XR is the only way to experience it right now, and it’s not cheap. Samsung’s headset is available for purchase at $1,800. If hand gesture control isn’t enough, you’ll have to pay another $175 for wireless controllers (discounted from the $250 retail price). Galaxy XR also supports corrective lenses if you need them, but that’s another $99.
Buyers get a collection of freebies to help justify the price. It comes with a full year of Google AI Pro, YouTube Premium, and Google Play Pass. Collectively, that would usually cost $370. Owners can also get three months of YouTube TV for $3, and everyone with Galaxy XR will get access to the 2025–2026 season of NBA League Pass in the US.
The CMC estimated in June that the financial impact of the attacks on the two retailers was between £270 million and £440 million.
The investigation into the JLR attack is being led by the National Crime Agency but few details have emerged on who was behind the incident. The CMC estimate did not include assumptions about whether JLR had paid a ransom or not.
Martin said companies tended to focus their resources on protecting themselves against data breaches since they have a legal obligation to protect customer data.
But cases like JLR underscore the increasing risks of attackers not just stealing data but destroying critical networks supporting a company’s operations, and the high costs associated with such attacks.
While state actors have not been behind recent attacks on M&S and other retailers, Martin warned that there was an increasing “geopolitical vulnerability” and risk that hostile nation states could attack UK businesses for non-financial reasons.
“It is now clear not just that criminal disruptive attacks are the worst problem in cybersecurity right now, but they’re a playbook to hostile nation states on how to attack us,” Martin said at a separate speech in London on Wednesday. “So cybersecurity has become economic security. And economic security is national security.”
Last week, the UK National Cyber Security Centre also warned that state actors continued to pose “a significant threat” to Britain and global cyber security, citing the risks posed by China, Russia, and others.
According to an annual review by NCSC, the UK had suffered 204 “nationally significant [cyber] incidents” in the 12 months to August 2025, compared with 89 in the same period a year earlier.
The term is used to describe the three most serious types of incidents as defined by UK law enforcement.
Amid the chaos of the Trump administration’s haphazard job cuts and a mass exodus of leadership, the Food and Drug Administration is experiencing a slowdown of drug reviews and approvals, according to an analysis reported by Stat News.
An assessment of metrics by RBC Capital Markets analysts found that FDA drug approvals dropped 14 percentage points in the third quarter compared to the average of the six previous quarters—falling from an average of 87 percent to 73 percent this past quarter. In line with that finding, analysts noted that the delay rate in meeting deadlines for drug application reviews rose from an average of 4 percent to 11 percent.
The FDA also rejected more applications than normal, going from a historical average of 10 percent to 15 percent in the third quarter. A growing number of rejections relate to problems at manufacturing plants, which in turn could suggest problems with the FDA’s inspection and auditing processes.
With the government now in a shutdown—with no end in sight—things could get worse for the FDA. While the regulatory agency is still working on existing drug applications, it will not be able to accept new submissions.