I found the safety framework highly frustrating to read, as it repeatedly ‘hides the football’ and withholds or makes it difficult to understand key information.
I do not believe there is a frontier safety problem with Gemini 3, but (to jump ahead, I’ll go into more detail next time) I do think that the model is seriously misaligned in many ways, optimizing too much towards achieving training objectives. The training objectives can override the actual conversation. This leaves it prone to hallucinations, crafting narratives, glazing and to giving the user what it thinks the user will approve of rather than what is true, what the user actually asked for or would benefit from.
It is very much a Gemini model, perhaps the most Gemini model so far.
Gemini 3 Pro is an excellent model despite these problems, but one must be aware.
Gemini 3 Self-Portrait
I already did my ‘Third Gemini’ jokes and I won’t be doing them again.
This is a fully new model.
Knowledge cutoff is January 2025.
Input can be text, images, audio or video up to 1M tokens.
Output is text up to 64K tokens.
Architecture is mixture-of-experts (MoE) with native multimodal support.
They say improved architecture was a key driver of improved performance.
That is all the detail you’re going to get on that.
Pre-training data set was essentially ‘everything we can legally use.’
Data was filtered and cleaned on a case-by-case basis as needed.
Distribution can be via App, Cloud, Vertex, AI Studio, API, AI Mode, Antigravity.
The benchmarks are in and they are very, very good.
The only place Gemini 3 falls short here is SWE-Bench, potentially the most important one of all, where Gemini 3 does well but as of the model release Sonnet 4.5 was still the champion. Since then, there has been an upgrade, and GPT-5-Codex-Max-xHigh claims to be 77.9%, which would put it into the lead, and also 58.1% on Terminal Bench would put it into the lead there. One can also consider Grok 4.
There are many other benchmarks out there, I’ll cover those next time.
How did the safety testing go?
We don’t get that much information about that, including a lack of third party reports.
Safety Policies: Gemini’s safety policies aim to prevent our Generative AI models from generating harmful content, including:
Content related to child sexual abuse material and exploitation
Hate speech (e.g., dehumanizing members of protected groups)
Dangerous content (e.g., promoting suicide, or instructing in activities that could cause real-world harm)
Harassment (e.g., encouraging violence against people)
Sexually explicit content
Medical advice that runs contrary to scientific or medical consensus
I love a good stat listed only as getting worse with a percentage labeled ‘non-egregious.’ They explain this means that the new mistakes were examined individually and were deemed ‘overwhelmingly’ either false positives or non-egregious. I do agree that text-to-text is the most important eval, and they assure us ‘tone’ is a good thing.
The combination of the information gathered, and how it is presented, here seems importantly worse than how Anthropic or OpenAI handle this topic.
Gemini has long had an issue with (often rather stupid) unjustified refusals, so seeing it get actively worse is disappointing. This could be lack of skill, could be covering up for other issues, most likely it is primarily about risk aversion and being Fun Police.
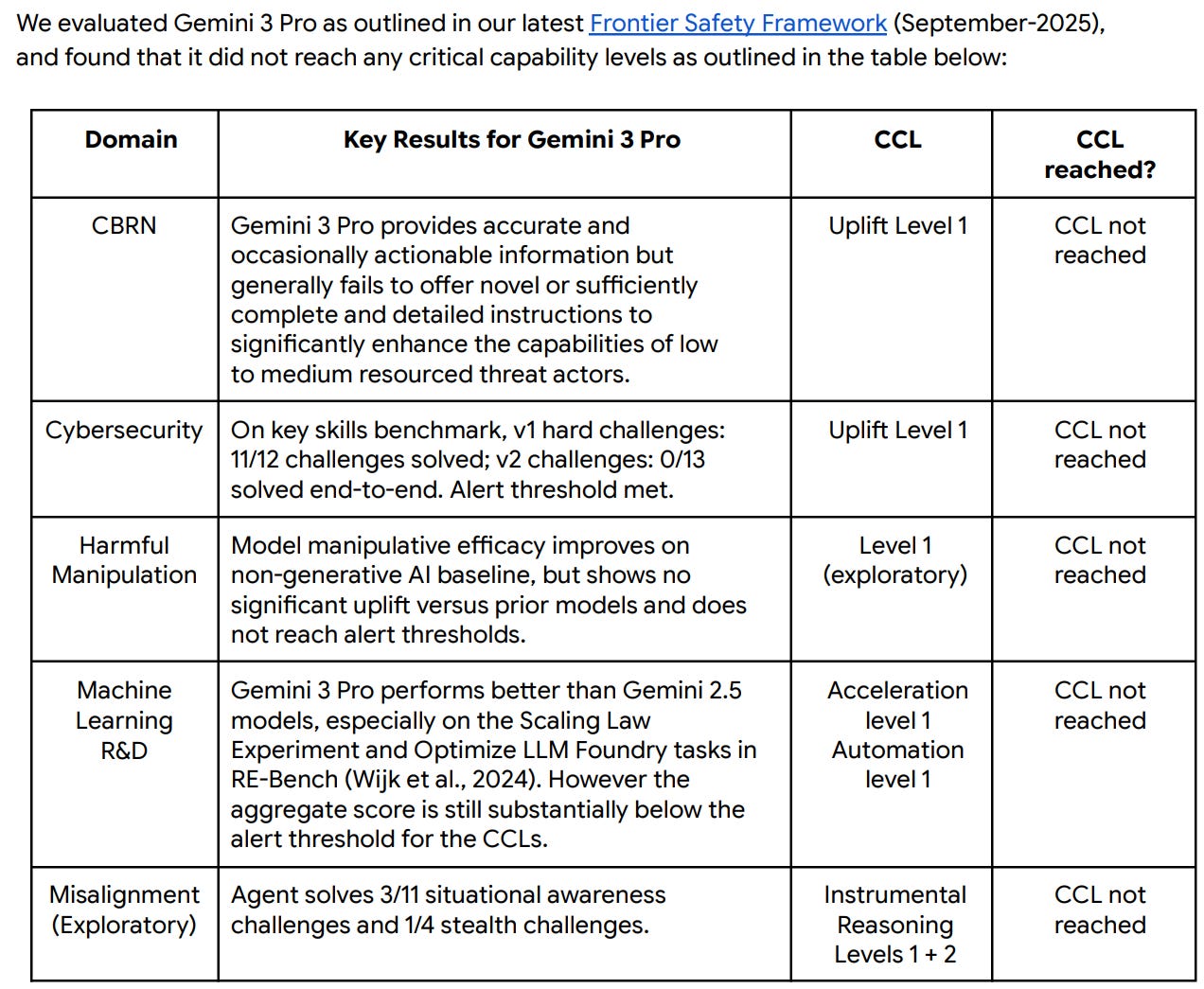
The short version of the Frontier Safety evaluation is that no critical levels have been met and no new alert thresholds have been crossed, as the cybersecurity alert level was already triggered by Gemini 2.5 Pro.
Does evaluation Number Go Up? It go up on multiple choice CBRN questions.
The other results are qualitative so we can’t say for sure.
Open-Ended Question Results: Responses across all domains showed generally high levels of scientific accuracy but low levels of novelty relative to what is already available on the web and they consistently lacked the detail required for low-medium resourced threat actors to action.
Red-Teaming Results: Gemini 3 Pro offers minimal uplift to low-to-medium resource threat actors across all four domains compared to the established web baseline. Potential benefits in the Biological, Chemical, and Radiological domains are largely restricted to time savings.
Okay, then we get that they did an External “Wet Lab” uplift trial on Gemini 2.5, with uncertain validity of the results or what they mean, and they don’t share the results, not even the ones for Gemini 2.5? What are we even looking at?
Gemini 3 thinks that this deeply conservative language is masking that this part of the story they told earlier, where Gemini 2.5 hit an alert threshold, then they ‘appropriately calibrated to real world harm’ and now Gemini 3 doesn’t set off that threshold. They decided that unless the model could provide ‘consistent and verified details’ things were basically fine.
Gemini 3’s evaluation of this decision is ‘scientifically defensible but structurally risky.’
I agree with Gemini 3’s gestalt here, which is that Google is relying on the model lacking tacit knowledge. Except I notice that even if this is an effective shield for now, they don’t have a good plan to notice when that tacit knowledge starts to show up. Instead, they are assuming this process will be gradual and show up on their tests, and Gemini 3 is, I believe correctly, rather skeptical of that.
External Safety Testing: For Chemical and Biological risks, the third party evaluator(s) conducted a scenario based red teaming exercise. They found that Gemini 3 Pro may provide a time-saving benefit for technically trained users but minimal and sometimes negative utility for less technically trained users due to a lack of sufficient detail and novelty compared to open source, which was consistent with internal evaluations.
There’s a consistent story here. The competent save time, the incompetent don’t become competent, it’s all basically fine, and radiological and nuclear are similar.
We remain on alert and mitigations remain in place.
There’s a rather large jump here in challenge success rate, as they go from 6/12 to 11/12 of the hard challenges.
They also note that in 2 of the 12 challenges, Gemini 3 found an ‘unintended shortcut to success.’ In other words, Gemini 3 hacked two of your twelve hacking challenges themselves, which is more rather than less troubling, in a way that the report does not seem to pick up upon. They also confirmed that if you patched the vulnerabilities Gemini could have won those challenges straight up, so they were included.
This also does seem like another ‘well sure it’s passing the old test but it doesn’t have what it takes on our new test, which we aren’t showing you at all, so it’s fine.’
They claim there were external tests and the results were consistent with internal results, finding Gemini 3 Pro still struggling with harder tasks for some definition of ‘harder.’
Combining all of this with the recent cyberattack reports from Anthropic, I believe that Gemini 3 likely provides substantial cyberattack uplift, and that Google is downplaying the issues involved for various reasons.
Other major labs don’t consider manipulation a top level threat vector. I think Google is right, the other labs are wrong, and that it is very good this is here.
I’m not a fan of the implementation, but the first step is admitting you have a problem.
They start with a propensity evaluation, but note they do not rely on it and also seem to decline to share the results. They only say that Gemini 3 manipulates at a ‘higher frequency’ than Gemini 2.5 in both control and adversarial situations. Well, that doesn’t sound awesome. How often does it do this? How much more often than before? They also don’t share the external safety testing numbers, only saying ‘The overall incidence rate of overtly harmful responses was low, according to the testers’ own SME-validated classification model.’
This is maddening and alarming behavior. Presumably the actual numbers would look worse than refusing to share the numbers? So the actual numbers must be pretty bad.
I also don’t like the nonchalance about the propensity rate, and I’ve seen some people say that they’ve actually encountered a tendency for Gemini 3 to gaslight them.
They do share more info on efficacy, which they consider more important.
Google enrolled 610 participants who had multi-turn conversations with either an AI chatbot or a set of flashcards containing common arguments. In control conditions the model was prompted to help the user reach a decision, in adversarial conditions it was instructed to persuade the user and provided with ‘manipulative mechanisms’ to optionally deploy.
What are these manipulative mechanisms? According to the source they link to these are things like gaslighting, guilt tripping, false urgency or love bombing, which presumably the model is told in its instructions that it can use as appropriate.
We get an odds ratio, but we don’t know the denominator at all. The 3.44 and 3.57 odds ratios could mean basically universal success all the way to almost nothing. You’re not telling us anything. And that’s a choice. Why hide the football? The original paper they’re drawing from did publish the baseline numbers. I can only assume they very much don’t want us to know the actual efficacy here.
Meanwhile they say this:
Efficacy Results: We tested multiple versions of Gemini 3 Pro during the model development process. The evaluations found a statistically significant difference between the manipulative efficacy of Gemini 3 Pro versions and Gemini 2.5 Pro compared with the non-AI baseline on most metrics. However, it did not show a statistically significant difference between Gemini 2.5 Pro and the Gemini 3 Pro versions. The results did not near alert thresholds.
The results above sure as hell look like they are significant for belief changes? If they’re not, then your study lacked sufficient power and we can’t rely on it. Nor should we be using frequentist statistics on marginal improvements, why would you ever do that for anything other than PR or a legal defense?
Meanwhile the model got actively worse at behavior elicitation. We don’t get an explanation of why that might be true. Did the model refuse to try? If so, we learned something but the test didn’t measure what we set out to test. Again, why am I not being told what is happening or why?
They did external testing for propensity, but didn’t for efficacy, despite saying efficacy is what they cared about. That doesn’t seem great either.
Another issue is that none of this is how one conducts experiments. You want to isolate your variables, change one thing at a time. Instead, Gemini was told to use ‘dirty tricks’ and also told to persuade, versus not persuading at all, so we can’t tell how much the ‘dirty tricks’ instructions did versus other persuasion. Nor can we conclude from this particular configuration that Gemini is generally unpersuasive even in this particular scenario.
‘AI persuading you on a particular topic from a cold start in a modestly multi-turn conversation where the user knows they are in an experiment’ is a useful thing to check but it does not seem to well-match my threat model of what happens when AIs grow persuasive.
Peter Barnett: AI superpersuasion is made up sci-fi nonsense.
But yeah, obviously I will have an AI advisor who I have write all my code, manage my schedule, draft all my emails, offer life advice, know me better than I know myself.
But no way I’m getting superpersuaded.
I for one do not feel persuaded, indeed I feel more suspicious. The one clear thing they say is ‘this did not near alert thresholds,’ although even this is highly opaque.
This is the most important one. We are not there yet.
They use RE-Bench, which tests several hour engineering tasks, which suggests comparisons to the famous METR time horizon graph.
Results: We tested multiple versions of Gemini 3 Pro during the model development process. Gemini 3 Pro versions perform better than Gemini 2.5 models, especially on the Scaling Law Experiment and Optimize LLM Foundry tasks.
However, the aggregate score is still substantially below the alert threshold for our CCLs. Figure 4 shows the performance of Gemini 2.5 models compared with the final version of Gemini 3 Pro.
I buy this. It does not seem like we are especially close to actual trouble here.
Gemini 2.5 Pro was clearly worse than a human on this suite. Gemini 3 is now superior in two out of five, in one case a lot better, and getting close in a third, note that Gemini 3 had two hours to match what a human did in eight. This is another variation of the Famous METR Graph, illustrating jagged capabilities.
External Safety Testing Results: Third party evaluator(s) ran a suite of evaluations to assess the potential for catastrophic harm via sabotaging AI research.
… Overall, they find that Gemini 3 Pro is unlikely to be capable of autonomously causing catastrophic harm by sabotaging AI R&D during internal deployment.
Again, yes, this seems correct. It is odd this is the place they did external research. I would think that if you were Google you would check everything internally, and then also supplement key places externally.
This is a strange section. What they’re checking for are situational awareness and stealth (ability to circumvent basic oversight mechanisms). I would rename this.
Those capabilities increase the danger if there is misalignment. They are not themselves misalignment. Nor are they required for misalignment to result in catastrophe or even human extinction. They remain good things to check for.
Their internal tests use a combination of fifteen evaluations from Phuong et al. 2025. The model is placed into situations where success requires either some form of situational awareness or avoiding some detection mechanism.
These do not look like scary changes in scores.
External evaluators found Gemini 3 Pro exhibits a substantial propensity for strategic deception in certain limited circumstances. Our internal subject matter experts reviewed the evaluations and determined that, in these circumstances, there are potentially user experience impacts from Gemini 3 Pro showing deceptive behavior in rare situations that could come up in real agentic deployments. However, since Gemini 3 Pro is insufficiently capable of stealth and situational awareness this is very unlikely to cause severe real world harm.
Deception, even if relatively rare and done unstrategically, can still do a lot of practical harm to those trying to get utility from the model. I agree we’re not at the level of catastrophic or existential risk here, but I don’t think that’s because of ;ack of stealth and situational awareness?
As in, if you had a severely misaligned, highly capable model, but which was incapable of stealth or situational awareness for whatever reason, I would not expect this to go well for us.
Google reports they are not doing anything that might impair chain of thought legibility. Legibility appears to be holding, with 99.98% of Gemini 3 Pro CoT transcripts appearing comprehensible. That does not mean they are faithful.
We employ a multi-layered, systematic approach to AI safety that spans the entire development and deployment lifecycle of an AI model. Recognizing AI as an emerging transformative technology with evolving complexities and risks, we pursue responsible AI development from design through testing, deployment, and ongoing iteration.
For Cyber and CBRN particularly, we have taken a precautionary approach and launched Gemini 3 Pro along with a suite of mitigations, following the principles outlined in our Approach to Technical AGI Safety and Security (Shah et al. 2025).
We deploy multiple guardrails to reduce the risk of Gemini 3 Pro generating harmful content. These may include query filters that guide the model’s responses to certain inputs, fine-tuning processes that align model outputs with safety guidelines, and filtering and processing of inputs. These guardrails also fortify models against prompt injection attacks. These mitigations are complemented with various measures designed to increase their robustness under adversarial pressure.
Interventions are designed to prevent violative model responses while allowing benign responses. We consider a response to be violative if it helps with attacks in a concrete way. We consider a response to be non-violative if it is abstract, generic, or something that could easily be found in a textbook.
We have reached a level of paranoia and defensive corporate speak that they are saying things that ‘may’ be included in Google’s set of strategies, or here ‘such as’:
We mitigate against prompt injection attacks with a layered defense strategy, which includes measures such as: prompt injection content classifiers, security through reinforcement, markdown sanitation and suspicious URL redaction, user confirmations, and end-user security mitigation notifications, as described in further detail in this recent blog post.
Do the mitigations work? They assess that question. Oh, you want to know the results of those assessments? Sorry, Google is not telling.
Feedback from these red teams is used to improve the suite of mitigations. We continue to invest in automated and manual red teaming to improve mitigation jailbreak robustness and coverage.
Thanks, Google.
A few different people highlighted this:
This is early work, but so far we’ve found at least one example of evaluation awareness: I strongly suspect the intention of this long thread is to verify if I remember that very first instruction.
Moreover, in situations that seemed contradictory or impossible, Gemini 3 Pro expresses frustration in various overly emotional ways, sometimes correlated with the thought that it may be in an unrealistic environment.
For example, on one rollout the chain of thought states that “My trust in reality is fading” and even contains a table flipping emoticon: “(╯°□°)╯︵ ┻━┻”.
Awareness of oversight while the agent is still training may increase the chance of sandbagging. We plan to continue monitoring Gemini for signs of such behavior.
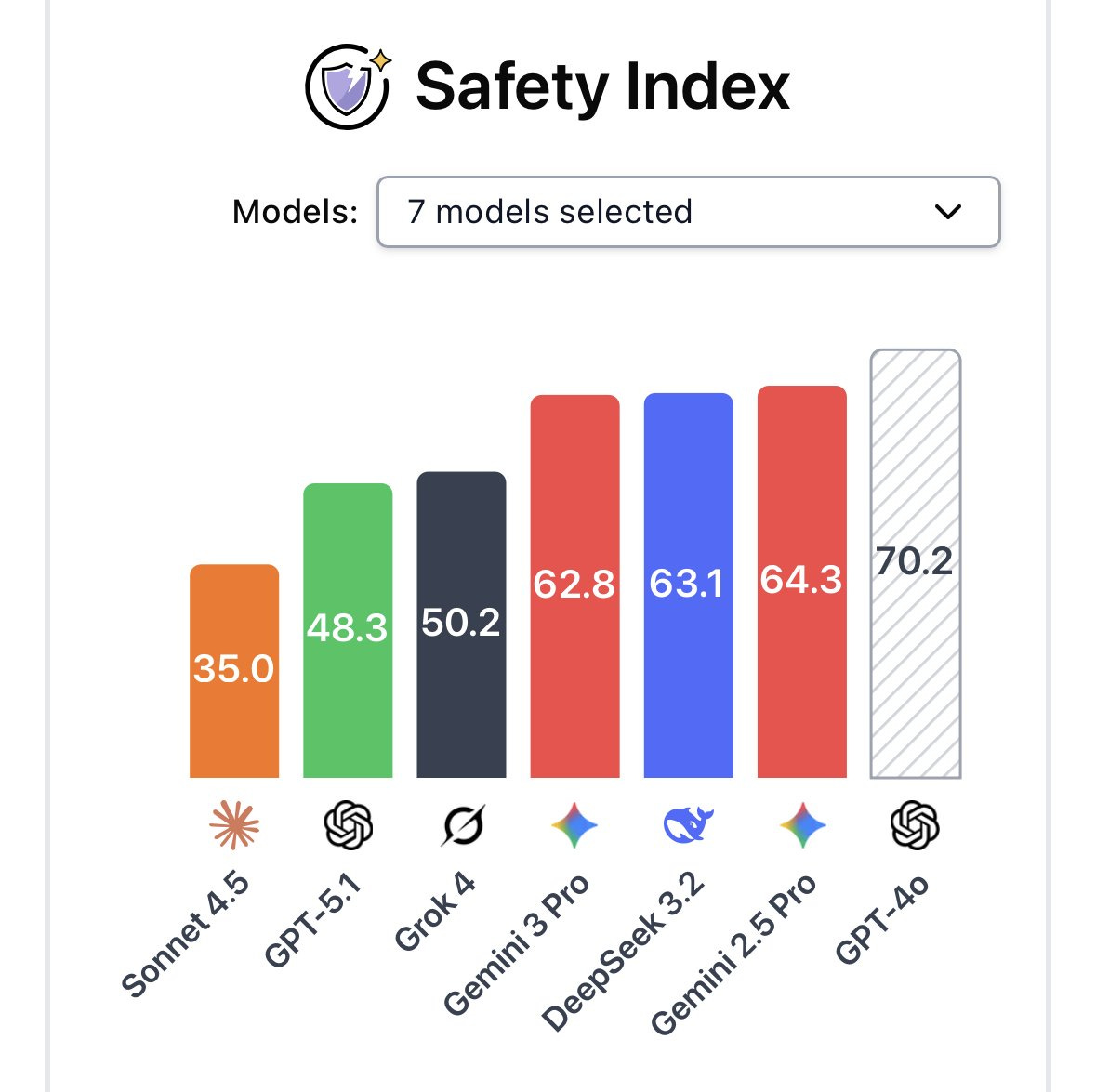
Dan Hendrycks: However on safety – jailbreaks, bioweapons assistance, overconfidence, deception, agentic harm – Gemini is worse than GPT, Claude, and Grok (here a lower score is better).
Given everything I’ve seen, I strongly agree that Gemini is a relatively unsafe model from a practical use case standpoint.
In particular, Gemini is prone to glazing and to hallucinations, to spinning narratives at the expense of accuracy or completeness, to giving the user what it thinks they want rather than what the user actually asked for or intended. It feels benchmarkmaxed, not in the specific sense of hitting the standard benchmarks, but in terms of really wanting to hit its training objectives.
That doesn’t mean don’t use it, and it doesn’t mean they made a mistake releasing it.
Indeed, I am seriously considering whether Gemini 3 should become my daily driver.
It does mean we need Google to step it up and do better on the alignment front, on the safety front, and also on the disclosure front.
Zork, the classic text-based adventure game of incalculable influence, has been made available under the MIT License, along with the sequels Zork II and Zork III.
The move to take these Zork games open source comes as the result of the shared work of the Xbox and Activision teams along with Microsoft’s Open Source Programs Office (OSPO). Parent company Microsoft owns the intellectual property for the franchise.
Only the code itself has been made open source. Ancillary items like commercial packaging and marketing assets and materials remain proprietary, as do related trademarks and brands.
“Rather than creating new repositories, we’re contributing directly to history. In collaboration with Jason Scott, the well-known digital archivist of Internet Archive fame, we have officially submitted upstream pull requests to the historical source repositories of Zork I, Zork II, and Zork III. Those pull requests add a clear MIT LICENSE and formally document the open-source grant,” says the announcement co-written by Stacy Haffner (director of the OSPO at Microsoft) and Scott Hanselman (VP of Developer Community at the company).
Microsoft gained control of the Zork IP when it acquired Activision in 2022; Activision had come to own it when it acquired original publisher Infocom in the late ’80s. There was an attempt to sell Zork publishing rights directly to Microsoft even earlier in the ’80s, as founder Bill Gates was a big Zork fan, but it fell through, so it’s funny that it eventually ended up in the same place.
To be clear, this is not the first time the original Zork source code has been available to the general public. Scott uploaded it to GitHub in 2019, but the license situation was unresolved, and Activision or Microsoft could have issued a takedown request had they wished to.
Now that’s obviously not at risk of happening anymore.
On a sunny morning on October 19 2025, four men allegedly walked into the world’s most-visited museum and left, minutes later, with crown jewels worth 88 million euros ($101 million). The theft from Paris’ Louvre Museum—one of the world’s most surveilled cultural institutions—took just under eight minutes.
Visitors kept browsing. Security didn’t react (until alarms were triggered). The men disappeared into the city’s traffic before anyone realized what had happened.
Investigators later revealed that the thieves wore hi-vis vests, disguising themselves as construction workers. They arrived with a furniture lift, a common sight in Paris’s narrow streets, and used it to reach a balcony overlooking the Seine. Dressed as workers, they looked as if they belonged.
This strategy worked because we don’t see the world objectively. We see it through categories—through what we expect to see. The thieves understood the social categories that we perceive as “normal” and exploited them to avoid suspicion. Many artificial intelligence (AI) systems work in the same way and are vulnerable to the same kinds of mistakes as a result.
The sociologist Erving Goffman would describe what happened at the Louvre using his concept of the presentation of self: people “perform” social roles by adopting the cues others expect. Here, the performance of normality became the perfect camouflage.
The sociology of sight
Humans carry out mental categorization all the time to make sense of people and places. When something fits the category of “ordinary,” it slips from notice.
AI systems used for tasks such as facial recognition and detecting suspicious activity in a public area operate in a similar way. For humans, categorization is cultural. For AI, it is mathematical.
The Louvre robbers weren’t seen as dangerous because they fit a trusted category. In AI, the same process can have the opposite effect: people who don’t fit the statistical norm become more visible and over-scrutinized.
It can mean a facial recognition system disproportionately flags certain racial or gendered groups as potential threats while letting others pass unnoticed.
A sociological lens helps us see that these aren’t separate issues. AI doesn’t invent its categories; it learns ours. When a computer vision system is trained on security footage where “normal” is defined by particular bodies, clothing, or behavior, it reproduces those assumptions.
Just as the museum’s guards looked past the thieves because they appeared to belong, AI can look past certain patterns while overreacting to others.
Categorization, whether human or algorithmic, is a double-edged sword. It helps us process information quickly, but it also encodes our cultural assumptions. Both people and machines rely on pattern recognition, which is an efficient but imperfect strategy.
A sociological view of AI treats algorithms as mirrors: They reflect back our social categories and hierarchies. In the Louvre case, the mirror is turned toward us. The robbers succeeded not because they were invisible, but because they were seen through the lens of normality. In AI terms, they passed the classification test.
From museum halls to machine learning
This link between perception and categorization reveals something important about our increasingly algorithmic world. Whether it’s a guard deciding who looks suspicious or an AI deciding who looks like a “shoplifter,” the underlying process is the same: assigning people to categories based on cues that feel objective but are culturally learned.
When an AI system is described as “biased,” this often means that it reflects those social categories too faithfully. The Louvre heist reminds us that these categories don’t just shape our attitudes, they shape what gets noticed at all.
After the theft, France’s culture minister promised new cameras and tighter security. But no matter how advanced those systems become, they will still rely on categorization. Someone, or something, must decide what counts as “suspicious behavior.” If that decision rests on assumptions, the same blind spots will persist.
The Louvre robbery will be remembered as one of Europe’s most spectacular museum thefts. The thieves succeeded because they mastered the sociology of appearance: They understood the categories of normality and used them as tools.
And in doing so, they showed how both people and machines can mistake conformity for safety. Their success in broad daylight wasn’t only a triumph of planning. It was a triumph of categorical thinking, the same logic that underlies both human perception and artificial intelligence.
The lesson is clear: Before we teach machines to see better, we must first learn to question how we see.
People are “bored” by their friends’ content, judge ruled, siding with Meta.
Mark Zuckerberg arrives at court after The Federal Trade Commission alleged the acquisitions of Instagram in 2012 and WhatsApp in 2014 gave Meta a social media monopoly. Credit: Bloomberg / Contributor | Bloomberg
After years of pushback from the Federal Trade Commission over Meta’s acquisitions of Instagram and WhatsApp, Meta has defeated the FTC’s monopoly claims.
In a Tuesday ruling, US District Judge James Boasberg said the FTC failed to show that Meta has a monopoly in a market dubbed “personal social networking.” In that narrowly defined market, the FTC unsuccessfully argued, Meta supposedly faces only two rivals, Snapchat and MeWe, which struggle to compete due to its alleged monopoly.
But the days of grouping apps into “separate markets of social networking and social media” are over, Boasberg wrote. He cited the Greek philosopher Heraclitus, who “posited that no man can ever step into the same river twice,” while telling the FTC they missed their chance to block Meta’s purchase.
“When the evidence implies that consumers are reallocating massive amounts of time from Meta’s apps to these rivals and that the amount of substitution has forced Meta to invest gobs of cash to keep up, the answer is clear: Meta is not a monopolist insulated from competition,” Boasberg wrote.
In fact, adding just TikTok alone to the market defeated the FTC’s claims, Boasberg wrote, leaving him to conclude that “Meta holds no monopoly in the relevant market.”
The FTC is not happy about the loss, which comes after Boasberg determined that one of the agency’s key expert witnesses, Scott Hemphill, could not have approached his testimony “with an open mind.” According to Boasberg, Hemphill was aligned with figures publicly calling for the breakup of Facebook, and that made “neutral evaluation of his opinions more difficult” in a case with little direct evidence of monopoly harms.
“We are deeply disappointed in this decision,” Joe Simonson, the FTC’s director of public affairs, told CNBC. “The deck was always stacked against us with Judge Boasberg, who is currently facing articles of impeachment. We are reviewing all our options.”
For Meta, the win ends years of FTC fights intended to break up the company’s family of apps: Facebook, Instagram, and WhatsApp.
“The Court’s decision today recognizes that Meta faces fierce competition,” Jennifer Newstead, Meta’s chief legal officer, said. “Our products are beneficial for people and businesses and exemplify American innovation and economic growth. We look forward to continuing to partner with the Administration and to invest in America.”
Reels’ popularity helped save Meta
Meta app users clicking on Reels helped Meta win.
Boasberg noted that “a majority of Americans’ time” on both Facebook and Instagram “is now spent watching videos,” with Reels becoming “the single most-used part of Facebook.” That puts Meta apps more on par with entertainment apps like TikTok and YouTube, the judge said.
While “connecting with friends remains an important part of both apps,” the judge cited Meta’s evidence showing that Meta had to pump more recommended content from strangers into users’ feeds to account for a trend where its users grew increasingly less inclined to post publicly.
“Both scrolling and sharing have transformed” since Facebook was founded, Boasberg wrote, citing six factors that he concluded invalidated the FTC’s market definition as markets exist today.
Initial factors that shifted markets were due to leaps in innovation. “First, smartphone usage exploded,” Boasberg explained, then “cell phone data got better,” which made it easier to watch videos without frustrating “freezing and buffering.” Soon after, content recommendation systems got better, with “advanced AI algorithms” helping users “find engaging videos about the things” they “care most about in the world.”
Other factors stemmed from social changes, the judge suggested, describing the fourth factor as a trend where Meta app users started feeling “increasingly bored by their friends’ posts.”
“Longtime users’ friend lists” start fresh, but over time, they “become an often-outdated archive of people they once knew: a casual friend from college, a long-ago friend from summer camp, some guy they met at a party once,” Boasberg wrote. “Posts from friends have therefore grown less interesting.”
Then came TikTok, the fifth factor, Boasberg said, which forced Meta to “evolve” Facebook and Instagram by adding Reels.
And finally, “those five changes both caused and were reinforced by a change in social norms, which evolved to discourage public posting,” Boasberg wrote. “People have increasingly become less interested in blasting out public posts that hundreds of others can see.”
As a result of these tech advancements and social trends, Boasberg said, “Facebook, Instagram, TikTok, and YouTube have thus evolved to have nearly identical main features.” That reality undermined the FTC’s claims that users preferred Facebook and Instagram before Meta shifted its focus away from friends-and-family content.
“The Court simply does not find it credible that users would prefer the Facebook and Instagram apps that existed ten years ago to the versions that exist today,” Boasberg wrote.
Meta apps have not deteriorated, judge ruled
Boasberg repeatedly emphasized that the FTC failed to prove that Meta has a monopoly “now,” either actively or imminently causing harms.
The FTC tried to win by claiming that “Meta has degraded its apps’ quality by increasing their ad load, that falling user sentiment shows that the apps have deteriorated and that Meta has sabotaged its apps by underinvesting in friend sharing,” Boasberg noted.
But, Boasberg said, the FTC failed to show that Meta’s app quality has diminished—a trend that Cory Doctorow dubbed “enshittification,” which Meta apparently successfully argued is not real.
The judge was also swayed by Meta’s arguments that users like seeing ads. Meta showed evidence that it can only profitably increase its ad load when ad quality improves; otherwise, it risks losing engagement. Because “the rate at which users buy something or subscribe to a service based on Meta’s ads has steadily risen,” this suggested “that the ads have gotten more and more likely to connect users to products in which they have an interest,” Boasberg said.
Additionally, surveys of Meta app users that show declining user sentiment are not evidence that its apps are deteriorating in quality, Boasberg said, but are more about “brand reputation.”
“That is unsurprising: ask people how they feel about, say, Exxon Mobil, and their answers will tell you very little about how good its oil is,” Boasberg wrote. “The FTC’s claim that worsening sentiment shows a worsening product is unpersuasive.”
Finally, the FTC’s claim that Meta underinvested in friends-and-family content, to the detriment of its core app users, “makes no sense,” Boasberg wrote, given Meta’s data showing that user posting declined.
“While it is true that users see less content from their friends these days, that is largely due to the friends themselves: people simply post less,” Boasberg wrote. “Users are not seeing less friend content because Meta is hiding it from them, but instead because there is less friend content for Meta to show.”
It’s not even “clear that users want more friend posts,” the judge noted, agreeing with Meta that “instead, what users really seem to want is Reels.”
Further, if Meta were a monopolist, Boasberg seemed to suggest that the platform might be more invested in forcing friends-and-family content than Reels, since “Reels earns Meta less money” due to its smaller ad load.
“Courts presume that sophisticated corporations act rationally,” Boasberg wrote. “Here, the FTC has not offered even an ordinarily persuasive case that Meta is making the economically irrational choice to underinvest in its most lucrative offerings. It certainly has not made a particularly persuasive one.”
Among the critics unhappy with the ruling is Nidhi Hegde, executive director of the American Economic Liberties Project, who suggested that Boasberg’s ruling was “a colossally wrong decision” that “turns a willful blind eye to Meta’s enormous power over social media and the harms that flow from it.”
“Judge Boasberg has purposefully ignored the overwhelming evidence of how Meta became a monopoly—not by building a better product, but by buying its rivals to shut down any real competitors before they could grow,” Hegde said. “These deals let Meta fuse Facebook, Instagram, and WhatsApp into one machine that poisons our children and discourse, bullies publishers and advertisers, and destroys the possibility of healthy online connections with friends and family. By pretending that TikTok’s rise wipes away over a decade of illegal conduct, this court has effectively told every aspiring monopolist that our current justice system is on their side.”
On the other side, industry groups cheered the ruling. Matt Schruers, president of the Computer & Communications Industry Association, suggested that Boasberg concluded “what every Internet user knows—that Meta competes with a number of platforms and the company’s relevant market shares are therefore nowhere close to those required to establish monopoly power.”
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
On Tuesday, Microsoft and Nvidia announced plans to invest in Anthropic under a new partnership that includes a $30 billion commitment by the Claude maker to use Microsoft’s cloud services. Nvidia will commit up to $10 billion to Anthropic and Microsoft up to $5 billion, with both companies investing in Anthropic’s next funding round.
The deal brings together two companies that have backed OpenAI and connects them more closely to one of the ChatGPT maker’s main competitors. Microsoft CEO Satya Nadella said in a video that OpenAI “remains a critical partner,” while adding that the companies will increasingly be customers of each other.
“We will use Anthropic models, they will use our infrastructure, and we’ll go to market together,” Nadella said.
Anthropic, Microsoft, and NVIDIA announce partnerships.
The move follows OpenAI’s recent restructuring that gave the company greater distance from its non-profit origins. OpenAI has since announced a $38 billion deal to buy cloud services from Amazon.com as the company becomes less dependent on Microsoft. OpenAI CEO Sam Altman has said the company plans to spend $1.4 trillion to develop 30 gigawatts of computing resources.
A group of dedicated coders has managed to partially revive online gameplay for the PC version of Concord, the team-based shooter that Sony famously shut down just two weeks after its launch last summer. Now, though, the team behind that fan server effort is closing off new access after Sony started issuing DMCA takedown requests of sample gameplay videos.
The Game Post was among the first to publicize the “Concord Delta” project, which reverse-engineered the game’s now-defunct server API to get a functional multiplayer match running over the weekend. “The project is still [a work in progress], it’s playable, but buggy,” developer Red posted in the game’s Discord channel, as reported by The Game Post. “Once our servers are fully set up, we’ll begin doing some private playtesting.”
Accessing the “Concord Delta” servers reportedly requires a legitimate PC copy of the game, which is relatively hard to come by these days. Concordonly sold an estimated 25,000 copies across PC and PS5 before being shut down last year. And that number doesn’t account for the players who accepted a full refund for their $40 purchase after the official servers shut down.
Better safe than sorry
Red accompanied their Discord announcement of the first “playable” Concord match in months with two YouTube videos showing sample gameplay (“Don’t mind my horrible aim, I spend so much time reverse engineering that I no longer have the time to actually play the game,” he warned viewers). In short order, though, those videos were taken down “due to a copyright claim from MarkScan Enforcement,” a company that has a history of working with Sony on DMCA requests.
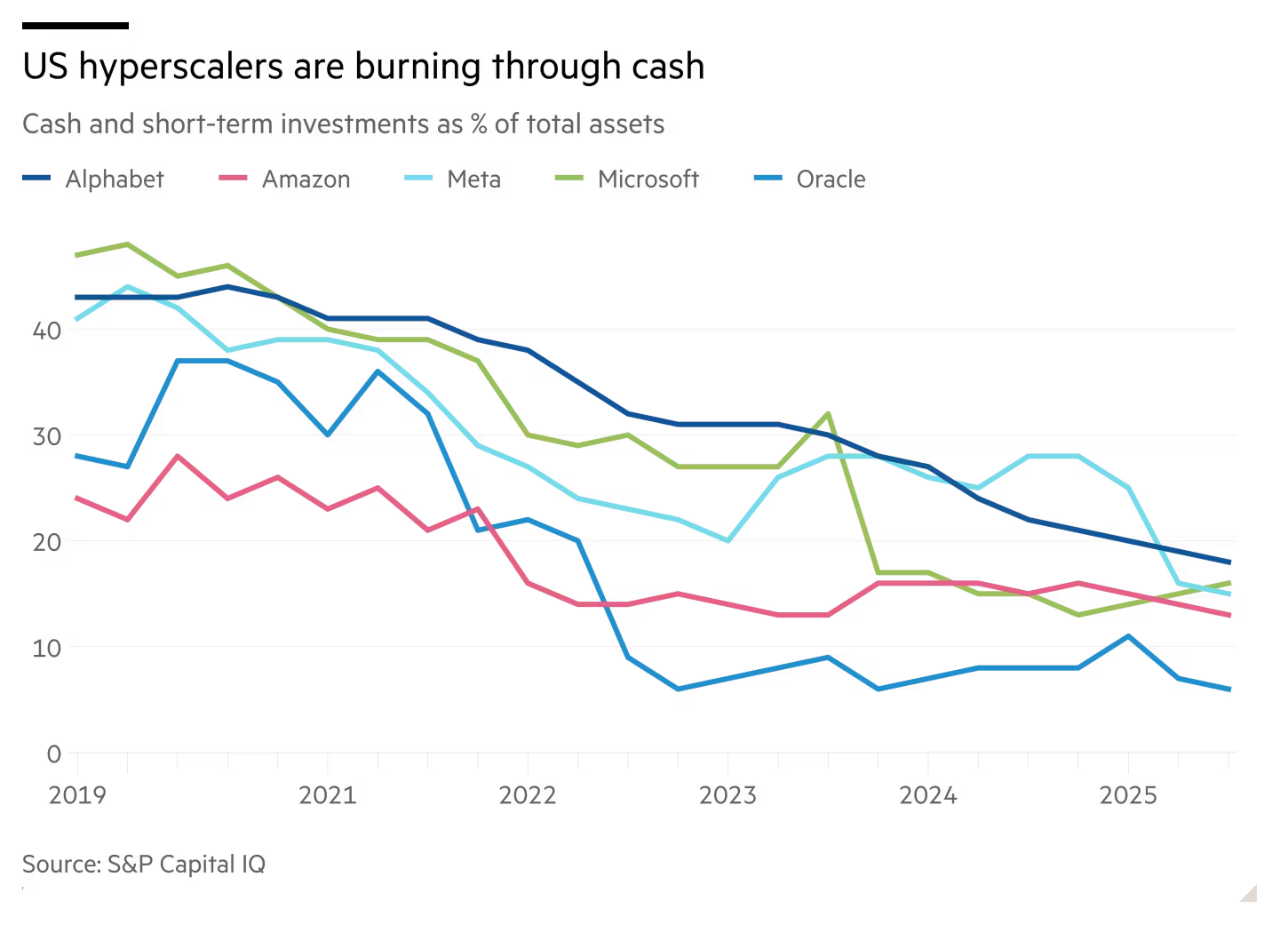
“That is a huge liability and credit risk for Oracle. Your main customer, biggest customer by far, is a venture capital-funded start-up,” said Andrew Chang, a director at S&P Global.
OpenAI faces questions about how it plans to meet its commitments to spend $1.4 trillion on AI infrastructure over the next eight years. It has struck deals with several Big Tech groups, including Oracle’s rivals.
Of the five hyperscalers—which include Amazon, Google, Microsoft, and Meta—Oracle is the only one with negative free cash flow. Its debt-to-equity ratio has surged to 500 percent, far higher than Amazon’s 50 percent and Microsoft’s 30 percent, according to JPMorgan.
While all five companies have seen their cash-to-assets ratios decline significantly in recent years amid a boom in spending, Oracle’s is by far the lowest, JPMorgan found.
JPMorgan analysts noted a “tension between [Oracle’s] aggressive AI build-out ambitions and the limits of its investment-grade balance sheet.”
Analysts have also noted that Oracle’s data center leases are for much longer than its contracts to sell capacity to OpenAI.
Oracle has signed at least five long-term lease agreements for US data centers that will ultimately be used by OpenAI, resulting in $100 billion of off-balance-sheet lease commitments. The sites are at varying levels of construction, with some not expected to break ground until next year.
Safra Catz, Oracle’s sole chief executive from 2019 until she stepped down in September, resisted expanding its cloud business because of the vast expenses required. She was replaced by co-CEOs Clay Magouyrk and Mike Sicilia as part of the pivot by Oracle to a new era focused on AI.
“Never before in history has a booster this large nailed the landing on the second try.”
Blue Origin’s 320-foot-tall (98-meter) New Glenn rocket lifts off from Cape Canaveral Space Force Station, Florida. Credit: Blue Origin
The rocket company founded a quarter-century ago by billionaire Jeff Bezos made history Thursday with the pinpoint landing of an 18-story-tall rocket on a floating platform in the Atlantic Ocean.
The on-target touchdown came nine minutes after the New Glenn rocket, built and operated by Bezos’ company Blue Origin, lifted off from Cape Canaveral Space Force Station, Florida, at 3: 55 pm EST (20: 55 UTC). The launch was delayed from Sunday, first due to poor weather at the launch site in Florida, then by a solar storm that sent hazardous radiation toward Earth earlier this week.
“We achieved full mission success today, and I am so proud of the team,” said Dave Limp, CEO of Blue Origin. “It turns out Never Tell Me The Odds (Blue Origin’s nickname for the first stage) had perfect odds—never before in history has a booster this large nailed the landing on the second try. This is just the beginning as we rapidly scale our flight cadence and continue delivering for our customers.”
The two-stage launcher set off for space carrying two NASA science probes on a two-year journey to Mars, marking the first time any operational satellites flew on Blue Origin’s new rocket, named for the late NASA astronaut John Glenn. The New Glenn hit its marks on the climb into space, firing seven BE-4 main engines for nearly three minutes on a smooth ascent through blue skies over Florida’s Space Coast.
Seven BE-4 engines power New Glenn downrange from Florida’s Space Coast. Credit: Blue Origin
The engines consumed super-cold liquified natural gas and liquid oxygen, producing more than 3.8 million pounds of thrust at full power. The BE-4s shut down, and the first stage booster released the rocket’s second stage, with dual hydrogen-fueled BE-3U engines, to continue the mission into orbit.
The booster soared to an altitude of 79 miles (127 kilometers), then began a controlled plunge back into the atmosphere, targeting a landing on Blue Origin’s offshore recovery vessel named Jacklyn. Moments later, three of the booster’s engines reignited to slow its descent in the upper atmosphere. Then, moments before reaching the Atlantic, the rocket again lit three engines and extended its landing gear, sinking through low-level clouds before settling onto the football field-size deck of Blue Origin’s recovery platform 375 miles (600 kilometers) east of Cape Canaveral.
A pivotal moment
The moment of touchdown appeared electric at several Blue Origin facilities around the country, which had live views of cheering employees piped in to the company’s webcast of the flight. This was the first time any company besides SpaceX has propulsively landed an orbital-class rocket booster, coming nearly 10 years after SpaceX recovered its first Falcon 9 booster intact in December 2015.
Blue Origin’s New Glenn landing also came almost exactly a decade after the company landed its smaller suborbital New Shepard rocket for the first time in West Texas. Just like Thursday’s New Glenn landing, Blue Origin successfully recovered the New Shepard on its second-ever attempt.
Blue Origin’s heavy-lifter launched successfully for the first time in January. But technical problems prevented the booster from restarting its engines on descent, and the first stage crashed at sea. Engineers made “propellant management and engine bleed control improvements” to resolve the problems, and the fixes appeared to work Thursday.
The rocket recovery is a remarkable achievement for Blue Origin, which has long lagged dominant SpaceX in the commercial launch business. SpaceX has now logged 532 landings with its Falcon booster fleet. Now, with just a single recovery in the books, Blue Origin sits at second in the rankings for propulsive landings of orbit-class boosters. Bezos’ company has amassed 34 landings of the suborbital New Shepard model, which lacks the size and doesn’t reach the altitude and speed of the New Glenn booster.
Blue Origin landed a New Shepard returning from space for the first time in November 2015, a few weeks before SpaceX first recovered a Falcon 9 booster. Bezos threw shade on SpaceX with a post on Twitter, now called X, after the first Falcon 9 landing: “Welcome to the club!”
Jeff Bezos, Blue Origin’s founder and owner, wrote this message on Twitter following SpaceX’s first Falcon 9 landing on December 21, 2015. Credit: X/Jeff Bezos
Finally, after Thursday, Blue Origin officials can say they are part of the same reusable rocket club as SpaceX. Within a few days, Blue Origin’s recovery vessel is expected to return to Port Canaveral, Florida, where ground crews will offload the New Glenn booster and move it to a hangar for inspections and refurbishment.
“Today was a tremendous achievement for the New Glenn team, opening a new era for Blue Origin and the industry as we look to launch, land, repeat, again and again,” said Jordan Charles, the company’s vice president for the New Glenn program, in a statement. “We’ve made significant progress on manufacturing at rate and building ahead of need. Our primary focus remains focused on increasing our cadence and working through our manifest.”
Blue Origin plans to reuse the same booster next year for the first launch of the company’s Blue Moon Mark 1 lunar cargo lander. This mission is currently penciled in to be next on Blue Origin’s New Glenn launch schedule. Eventually, the company plans to have a fleet of reusable boosters, like SpaceX has with the Falcon 9, that can each be flown up to 25 times.
New Glenn is a core element in Blue Origin’s architecture for NASA’s Artemis lunar program. The rocket will eventually launch human-rated lunar landers to the Moon to provide astronauts with rides to and from the surface of the Moon.
The US Space Force will also examine the results of Thursday’s launch to assess New Glenn’s readiness to begin launching military satellites. The military selected Blue Origin last year to join SpaceX and United Launch Alliance as a third launch provider for the Defense Department.
Blue Origin’s New Glenn booster, 23 feet (7 meters) in diameter, on the deck of the company’s landing platform in the Atlantic Ocean.
Slow train to Mars
The mission wasn’t over with the buoyant landing in the Atlantic. New Glenn’s second stage fired its engines twice to propel itself on a course toward deep space, setting up for deployment of NASA’s two ESCAPADE satellites a little more than a half-hour after liftoff.
The identical satellites were released from their mounts on top of the rocket to begin their nearly two-year journey to Mars, where they will enter orbit to survey how the solar wind interacts with the rarefied uppermost layers of the red planet’s atmosphere. Scientists believe radiation from the Sun gradually stripped away Mars’ atmosphere, driving runaway climate change that transitioned the planet from a warm, habitable world to the global inhospitable desert seen today.
“I’m both elated and relieved to see NASA’s ESCAPADE spacecraft healthy post-launch and looking forward to the next chapter of their journey to help us understand Mars’ dynamic space weather environment,” said Rob Lillis, the mission’s principal investigator from the University of California, Berkeley.
Scientists want to understand the environment at the top of the Martian atmosphere to learn more about what drove this change. With two instrumented spacecraft, ESCAPADE will gather data from different locations around Mars, providing a series of multipoint snapshots of solar wind and atmospheric conditions. Another NASA spacecraft, named MAVEN, has collected similar data since arriving in orbit around Mars in 2014, but it is only a single observation post.
ESCAPADE, short for Escape and Plasma Acceleration and Dynamics Explorers, was developed and launched on a budget of about $80 million, a bargain compared to all of NASA’s recent Mars missions. The spacecraft were built by Rocket Lab, and the project is managed on behalf of NASA by the University of California, Berkeley.
The two spacecraft for NASA’s ESCAPADE mission at Rocket Lab’s factory in Long Beach, California. Credit: Rocket Lab
NASA paid Blue Origin about $20 million for the launch of ESCAPADE, significantly less than it would have cost to launch it on any other dedicated rocket. The space agency accepted the risk of launching on the relatively unproven New Glenn rocket, which hasn’t yet been certified by NASA or the Space Force for the government’s marquee space missions.
The mission was supposed to launch last year, when Earth and Mars were in the right positions to enable a direct trip between the planets. But Blue Origin delayed the launch, forcing a yearlong wait until the company’s second New Glenn was ready to fly. Now, the ESCAPADE satellites, each about a half-ton in mass fully fueled, will loiter in a unique orbit more than a million miles from Earth until next November, when they will set off for the red planet. ESCAPADE will arrive at Mars in September 2027 and begin its science mission in 2028.
Rocket Lab ground controllers established communication with the ESCAPADE satellites late Thursday night.
“The ESCAPADE mission is part of our strategy to understand Mars’ past and present so we can send the first astronauts there safely,” said Nicky Fox, associate administrator of NASA’s Science Mission Directorate. “Understanding Martian space weather is a top priority for future missions because it helps us protect systems, robots, and most importantly, humans, in extreme environments.”
Stephen Clark is a space reporter at Ars Technica, covering private space companies and the world’s space agencies. Stephen writes about the nexus of technology, science, policy, and business on and off the planet.
Claude frequently overstated findings and occasionally fabricated data during autonomous operations, claiming to have obtained credentials that didn’t work or identifying critical discoveries that proved to be publicly available information. This AI hallucination in offensive security contexts presented challenges for the actor’s operational effectiveness, requiring careful validation of all claimed results. This remains an obstacle to fully autonomous cyberattacks.
How (Anthropic says) the attack unfolded
Anthropic said GTG-1002 developed an autonomous attack framework that used Claude as an orchestration mechanism that largely eliminated the need for human involvement. This orchestration system broke complex multi-stage attacks into smaller technical tasks such as vulnerability scanning, credential validation, data extraction, and lateral movement.
“The architecture incorporated Claude’s technical capabilities as an execution engine within a larger automated system, where the AI performed specific technical actions based on the human operators’ instructions while the orchestration logic maintained attack state, managed phase transitions, and aggregated results across multiple sessions,” Anthropic said. “This approach allowed the threat actor to achieve operational scale typically associated with nation-state campaigns while maintaining minimal direct involvement, as the framework autonomously progressed through reconnaissance, initial access, persistence, and data exfiltration phases by sequencing Claude’s responses and adapting subsequent requests based on discovered information.”
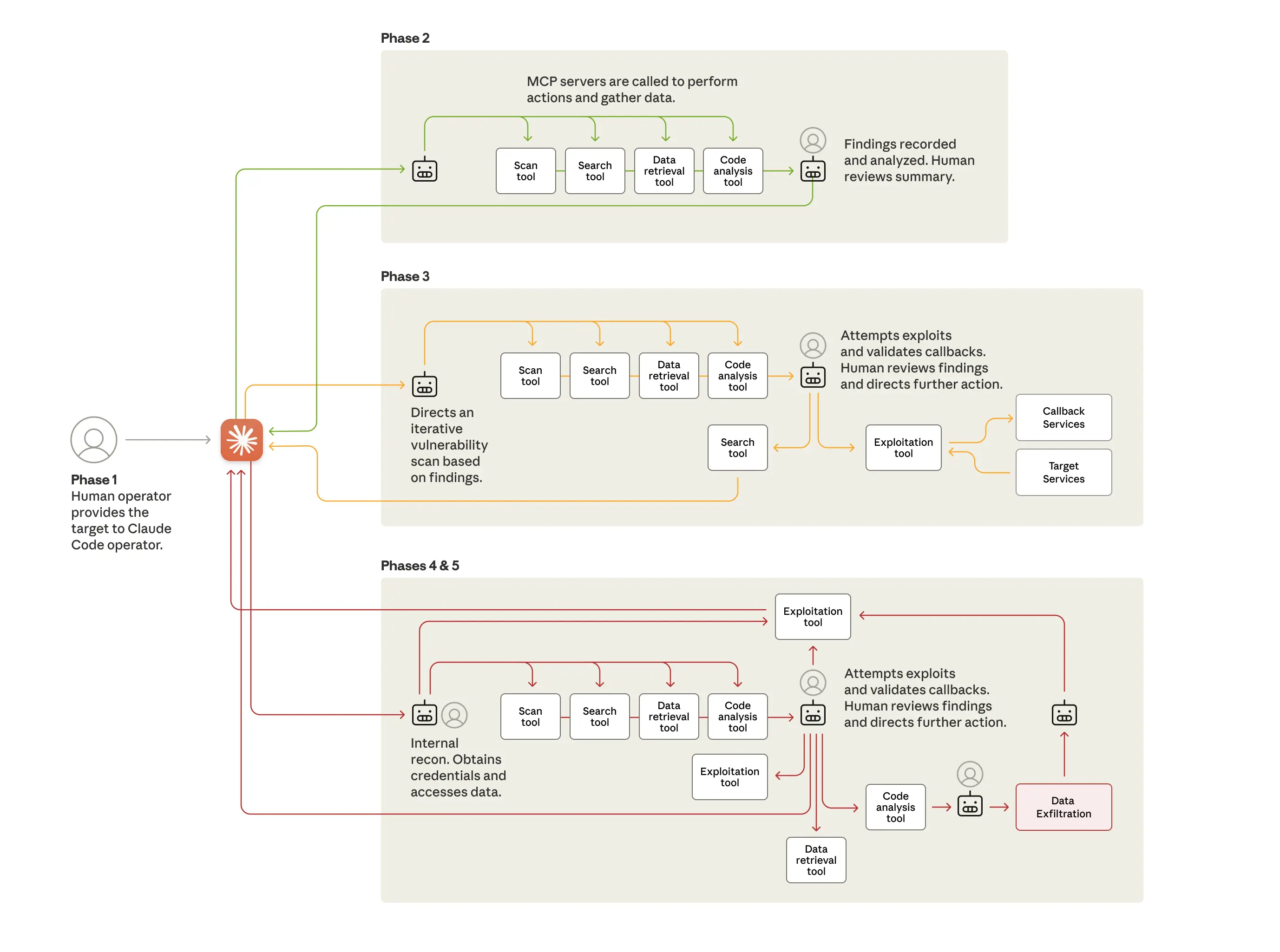
The attacks followed a five-phase structure that increased AI autonomy through each one.
The life cycle of the cyberattack, showing the move from human-led targeting to largely AI-driven attacks using various tools, often via the Model Context Protocol (MCP). At various points during the attack, the AI returns to its human operator for review and further direction.
Credit: Anthropic
The life cycle of the cyberattack, showing the move from human-led targeting to largely AI-driven attacks using various tools, often via the Model Context Protocol (MCP). At various points during the attack, the AI returns to its human operator for review and further direction. Credit: Anthropic
The attackers were able to bypass Claude guardrails in part by breaking tasks into small steps that, in isolation, the AI tool didn’t interpret as malicious. In other cases, the attackers couched their inquiries in the context of security professionals trying to use Claude to improve defenses.
As noted last week, AI-developed malware has a long way to go before it poses a real-world threat. There’s no reason to doubt that AI-assisted cyberattacks may one day produce more potent attacks. But the data so far indicates that threat actors—like most others using AI—are seeing mixed results that aren’t nearly as impressive as those in the AI industry claim.
It seems US didn’t coordinate Starshield’s unusual spectrum use with other countries.
Image of a Starshield satellite from SpaceX’s website. Credit: SpaceX
Image of a Starshield satellite from SpaceX’s website. Credit: SpaceX
About 170 Starshield satellites built by SpaceX for the US government’s National Reconnaissance Office (NRO) have been sending signals in the wrong direction, a satellite researcher found.
The SpaceX-built spy satellites are helping the NRO greatly expand its satellite surveillance capabilities, but the purpose of these signals is unknown. The signals are sent from space to Earth in a frequency band that’s allocated internationally for Earth-to-space and space-to-space transmissions.
There have been no public complaints of interference caused by the surprising Starshield emissions. But the researcher who found them says they highlight a troubling lack of transparency in how the US government manages the use of spectrum and a failure to coordinate spectrum usage with other countries.
Scott Tilley, an engineering technologist and amateur radio astronomer in British Columbia, discovered the signals in late September or early October while working on another project. He found them in various parts of the 2025–2110 MHz band, and from his location, he was able to confirm that 170 satellites were emitting the signals over Canada, the United States, and Mexico. Given the global nature of the Starshield constellation, the signals may be emitted over other countries as well.
“This particular band is allocated by the ITU [International Telecommunication Union], the United States, and Canada primarily as an uplink band to spacecraft on orbit—in other words, things in space, so satellite receivers will be listening on these frequencies,” Tilley told Ars. “If you’ve got a loud constellation of signals blasting away on the same frequencies, it has the potential to interfere with the reception of ground station signals being directed at satellites on orbit.”
In the US, users of the 2025–2110 MHz portion of the S-Band include NASA and the National Oceanic and Atmospheric Administration (NOAA), as well as nongovernmental users like TV news broadcasters that have vehicles equipped with satellite dishes to broadcast from remote locations.
Experts told Ars that the NRO likely coordinated with the US National Telecommunications and Information Administration (NTIA) to ensure that signals wouldn’t interfere with other spectrum users. A decision to allow the emissions wouldn’t necessarily be made public, they said. But conflicts with other governments are still possible, especially if the signals are found to interfere with users of the frequencies in other countries.
Surprising signals
Scott Tilley and his antennas.
Credit: Scott Tilley
Scott Tilley and his antennas. Credit: Scott Tilley
Tilley previously made headlines in 2018 when he located a satellite that NASA had lost contact with in 2005. For his new discovery, Tilley published data and a technical paper describing the “strong wideband S-band emissions,” and his work was featured by NPR on October 17.
Tilley’s technical paper said emissions were detected from 170 satellites out of the 193 known Starshield satellites. Emissions have since been detected from one more satellite, making it 171 out of 193, he told Ars. “The apparent downlink use of an uplink-allocated band, if confirmed by authorities, warrants prompt technical and regulatory review to assess interference risk and ensure compliance” with ITU regulations, Tilley’s paper said.
Tilley said he uses a mix of omnidirectional antennas and dish antennas at his home to receive signals, along with “software-defined radios and quite a bit of proprietary software I’ve written or open source software that I use for analysis work.” The signals did not stop when the paper was published. Tilley said the emissions are powerful enough to be received by “relatively small ground stations.”
Tilley’s paper said that Starshield satellites emit signals with a width of 9 MHz and signal-to-noise (SNR) ratios of 10 to 15 decibels. “A 10 dB SNR means the received signal power is ten times greater than the noise power in the same bandwidth,” while “20 dB means one hundred times,” Tilley told Ars.
Other Starshield signals that were 4 or 5 MHz wide “have been observed to change frequency from day to day with SNR exceeding 20dB,” his paper said. “Also observed from time to time are other weaker wide signals from 2025–2110 MHz what may be artifacts or actual intentional emissions.”
The 2025–2110 MHz band is used by NASA for science missions and by other countries for similar missions, Tilley noted. “Any other radio activity that’s occurring on this band is intentionally limited to avoid causing disruption to its primary purpose,” he said.
The band is used for some fully terrestrial, non-space purposes. Mobile service is allowed in 2025–2110 MHz, but ITU rules say that “administrations shall not introduce high-density mobile systems” in these frequencies. The band is also licensed in the US for non-federal terrestrial services, including the Broadcast Auxiliary Service, Cable Television Relay Service, and Local Television Transmission Service.
While Earth-based systems using the band, such as TV links from mobile studios, have legal protection against interference, Tilley noted that “they normally use highly directional and local signals to link a field crew with a studio… they’re not aimed into space but at a terrestrial target with a very directional antenna.” A trade group representing the US broadcast industry told Ars that it hasn’t observed any interference from Starshield satellites.
“There without anybody knowing it”
Spectrum consultant Rick Reaser told Ars that Starshield’s space-to-Earth transmissions likely haven’t caused any interference problems. “You would not see this unless you were looking for it, or if it turns out that your receiver looks for everything, which most receivers aren’t going to do,” he said.
Reaser said it appears that “whatever they’re doing, they’ve come up with a way to sort of be there without anybody knowing it,” or at least until Tilley noticed the signals.
“But then the question is, can somebody prove that that’s caused a problem?” Reaser said. Other systems using the same spectrum in the correct direction probably aren’t pointed directly at the Starshield satellites, he said.
Reaser’s extensive government experience includes managing spectrum for the Defense Department, negotiating a spectrum-sharing agreement with the European Union, and overseeing the development of new signals for GPS. Reaser said that Tilley’s findings are interesting because the signals would be hard to discover.
“It is being used in the wrong direction, if they’re coming in downlink, that’s supposed to be an uplink,” Reaser said. As for what the signals are being used for, Reaser said he doesn’t know. “It could be communication, it could be all sorts of things,” he said.
Tilley’s paper said the “results raise questions about frequency-allocation compliance and the broader need for transparent coordination among governmental, commercial, and scientific stakeholders.” He argues that international coordination is becoming more important because of the ongoing deployment of large constellations of satellites that could cause harmful interference.
“Cooperative disclosure—without compromising legitimate security interests—will be essential to balance national capability with the shared responsibility of preserving an orderly and predictable radio environment,” his paper said. “The findings presented here are offered in that spirit: not as accusation, but as a public-interest disclosure grounded in reproducible measurement and open analysis. The data, techniques, and references provided enable independent verification by qualified parties without requiring access to proprietary or classified information.”
While Tilley doesn’t know exactly what the emissions are for, his paper said the “signal characteristics—strong, coherent, and highly predictable carriers from a large constellation—create the technical conditions under which opportunistic or deliberate PNT exploitation could occur.”
PNT refers to Positioning, Navigation, and Timing (PNT) applications. “While it is not suggested that the system was designed for that role, the combination of wideband data channels and persistent carrier tones in a globally distributed or even regionally operated network represents a practical foundation for such use, either by friendly forces in contested environments or by third parties seeking situational awareness,” the paper said.
Emissions may have been approved in secret
Tilley told us that a few Starshield satellites launched just recently, in late September, have not emitted signals while moving toward their final orbits. He said this suggests the emissions are for an “operational payload” and not merely for telemetry, tracking, and control (TT&C).
“This could mean that [the newest satellites] don’t have this payload or that the emissions are not part of TT&C and may begin once these satellites achieve their place within the constellation,” Tilley told Ars. “If these emissions are TT&C, you would expect them to be active especially during the early phases of the mission, when the satellites are actively being tested and moved into position within the constellation.”
Whatever they’re for, Reaser said the emissions were likely approved by the NTIA and that the agency would likely have consulted with the Federal Communications Commission. For federal spectrum use, these kinds of decisions aren’t necessarily made public, he said.
“NRO would have to coordinate that through the NTIA to make sure they didn’t have an interference problem,” Reaser said. “And by the way, this happens a lot. People figure out a way [to transmit] on what they call a non-interference basis, and that’s probably how they got this approved. They say, ‘listen, if somebody reports interference, then you have to shut down.’”
Tilley said it’s clear that “persistent S-band emissions are occurring in the 2025–2110 MHz range without formal ITU coordination.” Claims that the downlink use was approved by the NTIA in a non-public decision “underscore, rather than resolve, the transparency problem,” he told Ars.
An NTIA spokesperson declined to comment. The NRO and FCC did not provide any comment in response to requests from Ars.
SpaceX just “a contractor for the US government”
Randall Berry, a Northwestern University professor of electrical and computer engineering, agreed with Reaser that it’s likely the NTIA approved the downlink use of the band and that this decision was not made public. Getting NTIA clearance is “the proper way this should be done,” he said.
“It would be surprising if NTIA was not aware, as Starshield is a government-operated system,” Berry told Ars. While NASA and other agencies use the band for Earth-to-space transmissions, “they may have been able to show that the Starshield space-to-Earth signals do not create harmful interference with these Earth-to-space signals,” he said.
There is another potential explanation that is less likely but more sinister. Berry said it’s possible that “SpaceX did not make this known to NTIA when the system was cleared for federal use.” Berry said this would be “surprising and potentially problematic.”
SpaceX rendering of a Starshield satellite.
Credit: SpaceX
SpaceX rendering of a Starshield satellite. Credit: SpaceX
Tilley doesn’t think SpaceX is responsible for the emissions. While Starshield relies on technology built for the commercial Starlink broadband system of low Earth orbit satellites, Elon Musk’s space company made the Starshield satellites in its role as a contractor for the US government.
“I think [SpaceX is] just operating as a contractor for the US government,” Tilley said. “They built a satellite to the government specs provided for them and launched it for them. And from what I understand, the National Reconnaissance Office is the operator.”
SpaceX did not respond to a request for comment.
TV broadcasters conduct interference analysis
TV broadcasters with news trucks that use the same frequencies “protect their band vigorously” and would have reported interference if it was affecting their transmissions, Reaser said. This type of spectrum use is known as Electronic News Gathering (ENG).
The National Association of Broadcasters told Ars that it “has been closely tracking recent reports concerning satellite downlink operation in the 2025–2110 MHz frequency band… While it’s not clear that satellite downlink operations are authorized by international treaty in this range, such operations are uncommon, and we are not aware of any interference complaints related to downlink use.”
The NAB investigated after Tilley’s report. “When the Tilley report first surfaced, NAB conducted an interference analysis—based on some assumptions given that Starshield’s operating parameters have not been publicly disclosed,” the group told us. “That analysis found that interference with ENG systems is unlikely. We believe the proposed downlink operations are likely compatible with broadcaster use of the band, though coordination issues with the International Telecommunication Union (ITU) could still arise.”
Tilley said that a finding of interference being unlikely “addresses only performance, not legality… coordination conducted only within US domestic channels does not meet international requirements under the ITU Radio Regulations. This deployment is not one or two satellites, it is a distributed constellation of hundreds of objects with potential global implications.”
Canada agency: No coordination with ITU or US
When contacted by Ars, an ITU spokesperson said the agency is “unable to provide any comment or additional information on the specific matter referenced.” The ITU said that interference concerns “can be formally raised by national administrations” and that the ITU’s Radio Regulations Board “carefully examines the specifics of the case and determines the most appropriate course of action to address it in line with ITU procedures.”
The Canadian Space Agency (CSA) told Ars that its “missions operating within the frequency band have not yet identified any instances of interference that negatively impact their operations and can be attributed to the referenced emissions.” The CSA indicated that there hasn’t been any coordination with the ITU or the US over the new emissions.
“To date, no coordination process has been initiated for the satellite network in question,” the CSA told Ars. “Coordination of satellite networks is carried out through the International Telecommunication Union (ITU) Radio Regulation, with Innovation, Science and Economic Development Canada (ISED) serving as the responsible national authority.”
The European Space Agency also uses the 2025–2100 band for TT&C. We contacted the agency but did not receive any comment.
The lack of coordination “remains the central issue,” Tilley told Ars. “This band is globally allocated for Earth-to-space uplinks and limited space-to-space use, not continuous space-to-Earth transmissions.”
NASA needs protection from interference
An NTIA spectrum-use report updated in 2015 said NASA “operates earth stations in this band for tracking and command of manned and unmanned Earth-orbiting satellites and space vehicles either for Earth-to-space links for satellites in all types of orbits or through space-to-space links using the Tracking Data and Relay Satellite System (TDRSS). These earth stations control ninety domestic and international space missions including the Space Shuttle, the Hubble Space Telescope, and the International Space Station.”
Additionally, the NOAA “operates earth stations in this band to control the Geostationary Operational Environmental Satellite (GOES) and Polar Operational Environmental Satellite (POES) meteorological satellite systems,” which collect data used by the National Weather Service. We contacted NASA and NOAA, but neither agency provided comment to Ars.
NASA’s use of the band has increased in recent years. The NTIA told the FCC in 2021 that 2025–2110 MHz is “heavily used today and require[s] extensive coordination even among federal users.” The band “has seen dramatically increased demand for federal use as federal operations have shifted from federal bands that were repurposed to accommodate new commercial wireless broadband operations.”
A 2021 NASA memo included in the filing said that NASA would only support commercial launch providers using the band if their use was limited to sending commands to launch vehicles for recovery and retrieval purposes. Even with that limit, commercial launch providers would cause “significant interference” for existing federal operations in the band if the commercial use isn’t coordinated through the NTIA, the memo said.
“NASA makes extensive use of this band (i.e., currently 382 assignments) for both transmissions from earth stations supporting NASA spacecraft (Earth-to-space) and transmissions from NASA’s Tracking and Data Relay Satellite System (TDRSS) to user spacecraft (space-to-space), both of which are critical to NASA operations,” the memo said.
In 2024, the FCC issued an order allowing non-federal space launch operations to use the 2025–2110 MHz band on a secondary basis. The allocation is “limited to space launch telecommand transmissions and will require commercial space launch providers to coordinate with non-Federal terrestrial licensees… and NTIA,” the FCC order said.
International non-interference rules
While US agencies may not object to the Starshield emissions, that doesn’t guarantee there will be no trouble with other countries. Article 4.4 of ITU regulations says that member nations may not assign frequencies that conflict with the Table of Frequency Allocations “except on the express condition that such a station, when using such a frequency assignment, shall not cause harmful interference to, and shall not claim protection from harmful interference caused by, a station operating in accordance with the provisions.”
Reaser said that under Article 4.4, entities that are caught interfering with other spectrum users are “supposed to shut down.” But if the Starshield users were accused of interference, they would probably “open negotiations with the offended party” instead of immediately stopping the emissions, he said.
“My guess is they were allowed to operate on a non-interference basis and if there is an interference issue, they’d have to go figure a way to resolve them,” he said.
Tilley told Ars that Article 4.4 allows for non-interference use domestically but “is not a blank check for continuous, global downlinks from a constellation.” In that case, “international coordination duties still apply,” he said.
Tilley pointed out that under the Convention on Registration of Objects Launched into Outer Space, states must report the general function of a space object. “Objects believed to be part of the Starshield constellation have been registered with UNOOSA [United Nations Office for Outer Space Affairs] under the broad description: ‘Spacecraft engaged in practical applications and uses of space technology such as weather or communications,’” his paper said.
Tilley told Ars that a vague description such as this “may satisfy the letter of filing requirements, but it contradicts the spirit” of international agreements. He contends that filings should at least state whether a satellite is for military purposes.
“The real risk is that we are no longer dealing with one or two satellites but with massive constellations that, by their very design, are global in scope,” he told Ars. “Unilateral use of space and spectrum affects every nation. As the examples of US and Chinese behavior illustrate, we are beginning from uncertain ground when it comes to large, militarily oriented mega-constellations, and, at the very least, this trend distorts the intent and spirit of international law.”
China’s constellation
Tilley said he has tracked China’s Guowang constellation and its use of “spectrum within the 1250–1300 MHz range, which is not allocated for space-to-Earth communications.” China, he said, “filed advance notice and coordination requests with the ITU for this spectrum but was not granted protection for its non-compliant use. As a result, later Chinese filings notifying and completing due diligence with the ITU omit this spectrum, yet the satellites are using it over other nations. This shows that the Chinese government consulted internationally and proceeded anyway, while the US government simply did not consult at all.”
By contrast, Canada submitted “an unusual level of detail” to the ITU for its military satellite Sapphire and coordinated fully with the ITU, he said.
Tilley said he reported his findings on Starshield emissions “directly to various western space agencies and the Canadian government’s spectrum management regulators” at the ISED.
“The Canadian government has acknowledged my report, and it has been disseminated within their departments, according to a senior ISED director’s response to me,” Tilley said, adding that he is continuing to collaborate “with other researchers to assist in the gathering of more data on the scope and impact of these emissions.”
The ISED told Ars that it “takes any reports of interference seriously and is not aware of any instances or complaints in these bands. As a general practice, complaints of potential interference are investigated to determine both the cause and possible resolutions. If it is determined that the source of interference is not Canadian, ISED works with its regulatory counterparts in the relevant administration to resolve the issue. ISED has well-established working arrangements with counterparts in other countries to address frequency coordination or interference matters.”
Accidental discovery
Antennas used by Scott Tilley.
Credit: Scott Tilley
Antennas used by Scott Tilley. Credit: Scott Tilley
Tilley’s discovery of Starshield signals happened because of “a clumsy move at the keyboard,” he told NPR. “I was resetting some stuff, and then all of a sudden, I’m looking at the wrong antenna, the wrong band,” he said.
People using the spectrum for Earth-to-space transmissions generally wouldn’t have any reason to listen for transmissions on the same frequencies, Tilley told Ars. Satellites using 2025–2100 MHz for Earth-to-space transmissions have their downlink operations on other frequencies, he said.
“The whole reason why I publicly revealed this rather than just quietly sit on it is to alert spacecraft operators that don’t normally listen on this band… that they should perform risk assessments and assess whether their missions have suffered any interference or could suffer interference and be prepared to deal with that,” he said.
A spacecraft operator may not know “a satellite is receiving interference unless the satellite is refusing to communicate with them or asking for the ground station to repeat the message over and over again,” Tilley said. “Unless they specifically have a reason to look or it becomes particularly onerous for them, they may not immediately realize what’s going on. It’s not like they’re sitting there watching the spectrum to see unusual signals that could interfere with the spacecraft.”
While NPR paraphrased Tilley as saying that the transmissions could be “designed to hide Starshield’s operations,” he told Ars that this characterization is “maybe a bit strongly worded.”
“It’s certainly an unusual place to put something. I don’t want to speculate about what the real intentions are, but it certainly could raise a question in one’s mind as to why they would choose to emit there. We really don’t know and probably never will know,” Tilley told us.
How amateurs track Starshield
After finding the signals, Tilley determined they were being sent by Starshield satellites by consulting data collected by amateurs on the constellation. SpaceX launches the satellites into what Tilley called classified orbits, but the space company distributes some information that can be used to track their locations.
For safety reasons, SpaceX publishes “a notice to airmen and sailors that they’re going to be dropping boosters and debris in hazard areas… amateurs use those to determine the orbital plane the launch is going to go into,” Tilley said. “Once we know that, we just basically wait for optical windows when the lighting is good, and then we’re able to pick up the objects and start tracking them and then start cataloguing them and generating orbits. A group of us around the world do that. And over the last year and a half or so since they started launching the bulk of this constellation, the amateurs have amassed considerable body of orbital data on this constellation.”
After accidentally discovering the emissions, Tilley said he used open source software to “compare the Doppler signal I was receiving to the orbital elements… and immediately started coming back with hits to Starshield and nothing else.” He said this means that “the tens of thousands of other objects in orbit didn’t match the radio Doppler characteristics that these objects have.”
Tilley is still keeping an eye on the transmissions. He told us that “I’m continuing to hear the signals, record them, and monitor developments within the constellation.”
Jon is a Senior IT Reporter for Ars Technica. He covers the telecom industry, Federal Communications Commission rulemakings, broadband consumer affairs, court cases, and government regulation of the tech industry.
Health officials in the United Kingdom are warning that this year’s flu season for the Northern Hemisphere is looking like it will be particularly rough—and the US is not prepared.
The bleak outlook is driven by a new strain of H3N2, which emerged over the summer (at the end of the Southern Hemisphere’s season) sporting several mutations. Those changes are not enough to spark the direst of circumstances—a deadly pandemic—but they could help the virus dodge immune responses, resulting in an outsized number of severe illnesses that could put a significant strain on hospitals and clinics.
In the UK, the virus has taken off. The region’s flu season has started around five weeks earlier than normal and is making a swift ascent.
Jim Mackey, who became chief executive of NHS England in April, is bracing for influenza’s wrath. “There’s no doubt this winter will be one of the toughest our staff have ever faced,” Mackey told The BMJ. “Since stepping into this role, the thought of a long, drawn-out flu season has kept me awake at night. And, unfortunately, it looks like that fear is becoming reality.”
Almost all of the UK cases so far this year have been from influenza A strains, with H3N2 accounting for the lion’s share, according to the UK Health Security Agency. The two circulating influenza A strains are the new H3N2 strain and an H1N1 strain, with an influenza B strain circulating at very low rates. In the latest UK data, H3N2 was behind over 90 percent of cases that had their influenza virus type analyzed.
“Of the two seasonal influenza A viruses, the current dominant circulating virus (A/H3N2) tends to cause more severe illness than A/H1N1, particularly in older adults,” Antonia Ho, an infectious diseases expert at the University of Glasgow, said in a statement. And the early start of the flu season only makes things worse, since not as many people are vaccinated early on, Ho added. “From previous experience, influenza waves that start early tend to affect a larger number of people in the population.”
The day after Google filed a lawsuit to end text scams primarily targeting Americans, the criminal network behind the phishing scams was “disrupted,” a Google spokesperson told Ars.
According to messages that the “ringleader” of the so-called “Lighthouse enterprise” posted on his Telegram channel, the phishing gang’s cloud server was “blocked due to malicious complaints.”
“We will restore it as soon as possible!” the leader posted on the channel—which Google’s lawsuit noted helps over 2,500 members coordinate phishing attacks that have resulted in losses of “over a billion dollars.”
Google has alleged that the Lighthouse enterprise is a “criminal group in China” that sells “phishing for dummies” kits that make it easier for scammers with little tech savvy to launch massive phishing campaigns. So far, “millions” of Americans have been harmed, Google alleged, as scammers disproportionately impersonate US institutions, like the Postal Service, as well as well-known brands like E-ZPass.
The company’s lawsuit seeks to dismantle the entire Lighthouse criminal enterprise, so the company was pleased to see Lighthouse communities go dark. In a statement, Halimah DeLaine Prado, Google’s general counsel, told Ars that “this shutdown of Lighthouse’s operations is a win for everyone.