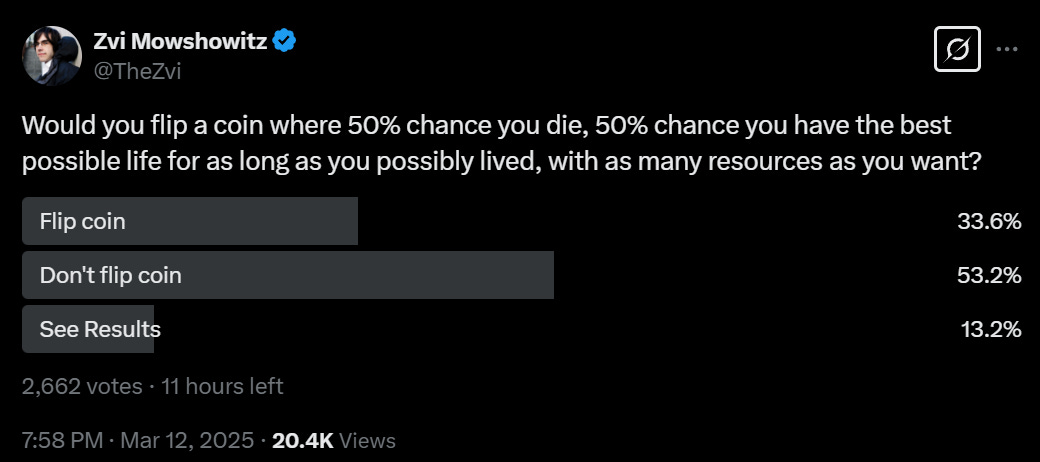The most hyped event of the week, by far, was the Manus Marketing Madness. Manus wasn’t entirely hype, but there was very little there there in that Claude wrapper.
Whereas here in America, OpenAI dropped an entire suite of tools for making AI agents, and previewed a new internal model making advances in creative writing. Also they offered us a very good paper warning about The Most Forbidden Technique.
Google dropped what is likely the best open non-reasoning model, Gemma 3 (reasoning model presumably to be created shortly, even if Google doesn’t do it themselves), put by all accounts quite good native image generation inside Flash 2.0, and added functionality to its AMIE doctor, and Gemini Robotics.
It’s only going to get harder from here to track which things actually matter.
Typed Female: AI cavity detection has got me skewing out. Absolutely no one who is good at their job is working on this—horrible incentive structures at play.
My dentist didn’t even bother looking at the X-rays. Are we just going to drill anywhere the AI says to? You’ve lost your mind.
These programs are largely marketed as tools that boost dentist revenue.
To me this is an obviously great use case. The AI is going to be vastly more accurate than the dentist. That doesn’t mean the dentist shouldn’t look to confirm, but it would be unsurprising to me if the dentist looking reduced accuracy.
WASHINGTON (AP) — References to a World War II Medal of Honor recipient, the Enola Gay aircraft that dropped an atomic bomb on Japan and the first women to pass Marine infantry training are among the tens of thousands of photos and online posts marked for deletion as the Defense Department works to purge diversity, equity and inclusion content, according to a database obtained by The Associated Press.
Will Creeley: The government enlisting AI to police speech online should scare the hell out of every American.
One could also check the expression of wide groups and scour their social media to see if they express Wrongthink, in this case ‘pro-Hamas’ views among international students, and then do things like revoke their visas. FIRE’s objection here is on the basis of the LLMs being insufficiently accurate. That’s one concern, but humans make similar mistakes too, probably even more often.
I find the actual big problem to be 90%+ ‘they are scouring everyone’s social media posts for Wrongthink’ rather than ‘they will occasionally have a false positive.’ This is a rather blatant first amendment violation. As we have seen over and over again, once this is possible and tolerated, what counts as Wrongthink often doesn’t stay contained.
Note that ‘ban the government (or anyone) from using AI to do this’ can help but is not a promising long term general strategy. The levels of friction involved are going to be dramatically reduced. If you want to ban the behavior, you have to ban the behavior in general and stick to that, not try to muddle the use of AI.
Be the neutral arbiter of truth among the normies? AI makes a lot of mistakes but it is far more reliable, trustworthy and neutral than most people’s available human sources. It’s way, way above the human median. You of course need to know when not to trust it, but that’s true of every source.
Do ‘routine’ math research, in the sense that you are combining existing theorems, without having to be able to prove those existing theorems. If you know a lot of obscure mathematical facts, you can combine them in a lot of interesting ways. Daniel Litt speculates this is ~90% of math research, and by year’s end the AIs will be highly useful for it. The other 10% of the work can then take the other 90% of the time.
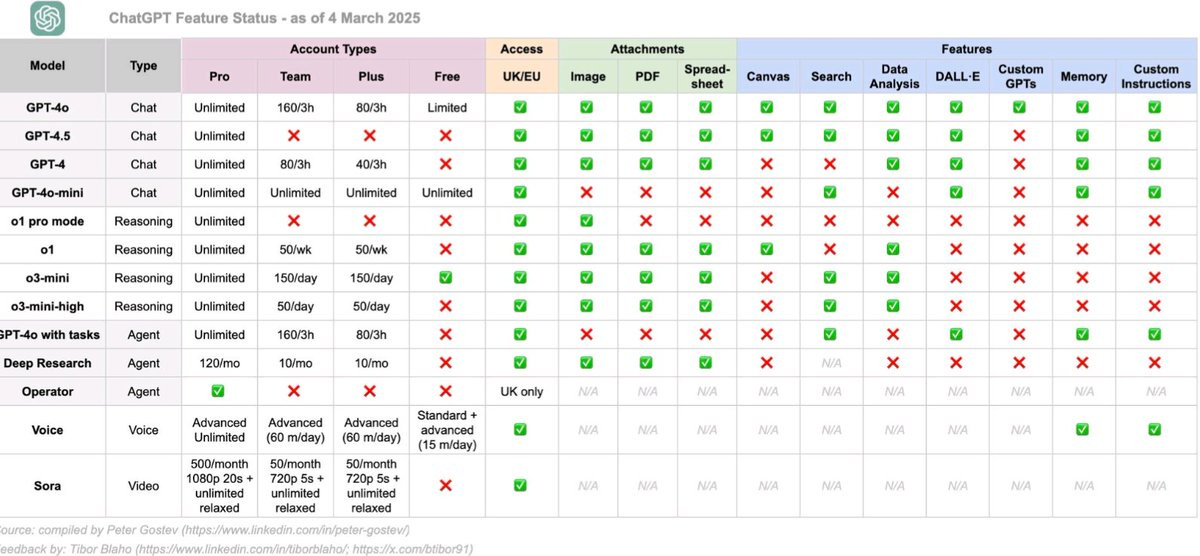
Kol Tregaskes: Useful chart for what tools each OpenAI model has access to.
This is an updated version of what others have shared (includes a correction found by @btibor91). Peter notes he has missed out Projects, will look at them.
Peter Wildeford: Crazy that
this chart needs to exist
it contains information that I as a very informed OpenAI Pro user didn’t even know
it is already out of date despite being “as of” three days ago [GPT-4.5 was rolled out more widely].
In this case, the claim is that [X] is ‘have unique insights.’ As in, sure an LLM will be able to be an A+ student and know the ultimate answer is 42, but won’t know the right question, so it won’t be all that useful. Certainly LLMs are relatively weaker there. At minimum, if you can abstract away the rest of the job, then that leaves a lot more space for the humans to provide the unique insights – most of even the best scientists spend most of their time on other things.
More than that, I do think the ‘outside the box’ thinking will come with time, or perhaps we will think of that as the box expanding. It is not as mysterious or unique as one thinks. The reason that Thomas Wolf was a great student and poor researcher wasn’t (I am guessing) that Wolf was incapable of being a great researcher. It’s that our system of education gave him training data and feedback that led him down that path. As he observes, it was in part because he was a great student that he wasn’t great at research, and in school he instead learned to guess the teacher’s password.
That can be fixed in LLMs, without making them bad students. Right now, LLMs guess the user’s password too much, because the training process implicitly thinks users want that. The YouTube algorithm does the same thing. But you could totally train an LLM a different way, especially if doing it purely for science. In a few years, the cost of that will be trivial, Stanford graduate students will do it in a weekend if no one else did it first.
Davidad: I have found Deep Research useful under exactly the following conditions:
I have a question, to which I suspect someone has written down the answer in a PDF online once or twice ever.
It’s not easy to find with a keyword search.
I can multitask while waiting for the answer.
Unfortunately, when it turns out that no one has ever written down the actual answer (or an algorithmic method to compute the general class of question), it is generally extremely frustrating to discover that o3’s superficially excitingly plausible synthesis is actually nonsense.
Arvind Narayanan tells OpenAI Deep Research to skip the secondary set of questions, and OpenAI Deep Research proves incapable of doing that, the user cannot deviate from the workflow here. I think in this case that is fine, as a DR call is expensive. For Gemini DR it’s profoundly silly, I literally just click through the ‘research proposal’ because the proposal is my words repeated back to me no matter what.
Peter Wildeford (3/10/25): The @ManusAI_HQ narrative whiplash is absurd.
Yesterday: “first AGI! China defeats US in AI race!”
Today: “complete influencer hype scam! just a Claude wrapper!”
The reality? In between! Manus made genuine innovations and seems useful! But it isn’t some massive advance.
Robert Scoble: “Be particularly skeptical of initial claims of Chinese AI.”
I’m guilty, because I’m watching so many in AI who get excited, which gets me to share. I certainly did the past few days with @ManusAI_HQ, which isn’t public yet but a lot of AI researchers got last week.
In my defense I shared both people who said it wasn’t measuring up, as well as those who said it was amazing. But I don’t have the evaluation suites, or the skills, to do a real job here. I am following 20,000+ people in AI, though, so will continue sharing when I see new things pop up that a lot of people are covering.
To Robert, I would say you cannot follow 20,000+ people and critically process the information. Put everyone into the firehose and you’re going to end up falling for the hype, or you’re going to randomly drop a lot of information on the floor, or both. Whereas I do this full time and curate a group of less than 500 people.
Peter expanded his thoughts into a full post, making it clear that he agrees with me that what we are dealing with is much closer to the second statement than the first. If an American startup did Manus, it would have been a curiosity, and nothing more.
Contrary to claims that Manus is ‘the best general AI agent available,’ it is neither the best agent, nor is it available. Manus has let a small number of people see a ‘research preview’ that is slow, that has atrocious unit economics, that brazenly violates terms of service, that is optimized on a small range of influencer-friendly use cases, that is glitchy and lacks any sorts of guardrails, and definitely is not making any attempt to defend against prompt injections or other things that would exist if there was wide distribution and use of such an agent.
This isn’t about regulatory issues and has nothing to do with Monica (the company behind Manus) being Chinese, other than leaning into the ‘China beats America’ narrative. Manus doesn’t work. It isn’t ready for anything beyond a demo. They made it work on a few standard use cases. Everyone else looked at this level of execution, probably substantially better than this level in several cases, and decided to keep their heads down building until it got better, and worried correctly that any efforts to make it temporarily somewhat functional will get ‘steamrolled’ by the major labs. Manus instead decided to do a (well-executed) marketing effort anyway. Good for them?
Derya Unutmaz: After experiencing Manus AI, I’ve also revised my predictions for AGI arrival this year, increasing the probability from 90% to 95% by year’s end. At this point, it’s 99.9% likely to arrive by next year at the latest.
That’s… very much not how any of this works. It was a good sketch but then it got silly.
Dean Ball explains why he still thinks Manus matters. Partly he is more technically impressed by Manus than most, in particular when being an active agent on the internet. But he explicitly says he wouldn’t call it ‘good,’ and notes he wouldn’t trust it with payment information, and notices its many glitches. And he is clear there is no big technical achievement here to be seen, as far as we can tell, and that the reason Manus looks better than alternatives is they had ‘the chutzpah to ship’ in this state while others didn’t.
Dean instead wants to make a broader point, which is that the Chinese may have an advantage in AI technology diffusion. The Chinese are much more enthusiastic and less skeptical about AI than Americans. The Chinese government is encouraging diffusion far more than the our government.
Then he praises Manus’s complete lack of any guardrails or security efforts whatsoever, for ‘having the chutzpah to ship’ a product I would say no sane man would ever use for the use cases where it has any advantages.
I acknowledge that Dean is pointing to real things when he discusses all the potential legal hot water one could get into as an American company releasing a Manus. But I once again double down that none of that is going to stop a YC company or other startup, or even substantially slow one down. Dean instead here says American companies may be afraid of ‘AGI’ and distracted from extracting maximum value from current LLMs.
I don’t think that is true either. I think that we have a torrent of such companies, trying to do various wrappers and marginal things, even as they are warned that there is likely little future in such a path. It won’t be long before we see other similar demos, and even releases, for the sufficiently bold.
I also notice that only days after Manus, OpenAI went ahead and launched new tools to help developers build reliable and powerful AI agents. In this sense, perhaps Manus was a (minor) DeepSeek moment, in that the hype caused OpenAI to accelerate their release schedule.
I do agree with Dean’s broader warnings. America risks using various regulatory barriers and its general suspicion of AI to slow down AI diffusion more than is wise, in ways that could do a lot of damage, and we need to reform our system to prevent this. We are not doing the things that would help us all not die, which would if done wisely cost very little in the way of capability, diffusion or productivity. Instead we are putting up barriers to us having nice things and being productive. We need to strike that, and reverse it.
Alas, instead, our government seems to be spending recent months largely shooting us in the foot in various ways.
I also could not agree more that the application layer is falling behind the model layer. And again, that’s the worst possible situation. The application layer is great, we should be out there doing all sorts of useful and cool things, and we’re not, and I continue to be largely confused about how things are staying this lousy this long.
Cohere moves from Command R+ to Command A, making a bold new claim to the ‘most confusing set of AI names’ crown.
Aiden Gomez (Cohere): Today @cohere is very excited to introduce Command A, our new model succeeding Command R+. Command A is an open-weights 111B parameter model with a 256k context window focused on delivering great performance across agentic, multilingual, and coding use cases.
Yi-Chern (Cohere): gpt-4o perf on enterprise and stem tasks, >deepseek-v3 on many languages including chinese human eval, >gpt-4o on enterprise rag human eval
2 gpus 256k context length, 156 tops at 1k context, 73 tops at 100k context
this is your workhorse.
The goal here seems to be as a base for AI agents or business uses, but the pricing doesn’t seem all that great at $2.50/$10 per million tokens.
Google’s AI Doctor AMIE can now converse, consult and provide treatment recommendations, prescriptions, multi-visit care, all guideline-compliant. I am highly suspicious that the methods here are effectively training on ‘match the guidelines’ rather than ‘do the best thing.’ It is still super valuable to have an AI that will properly apply the guidelines to a given situation, but one cannot help but be disappointed.
I’d be so much more excited if Google wasn’t the Fun Police.
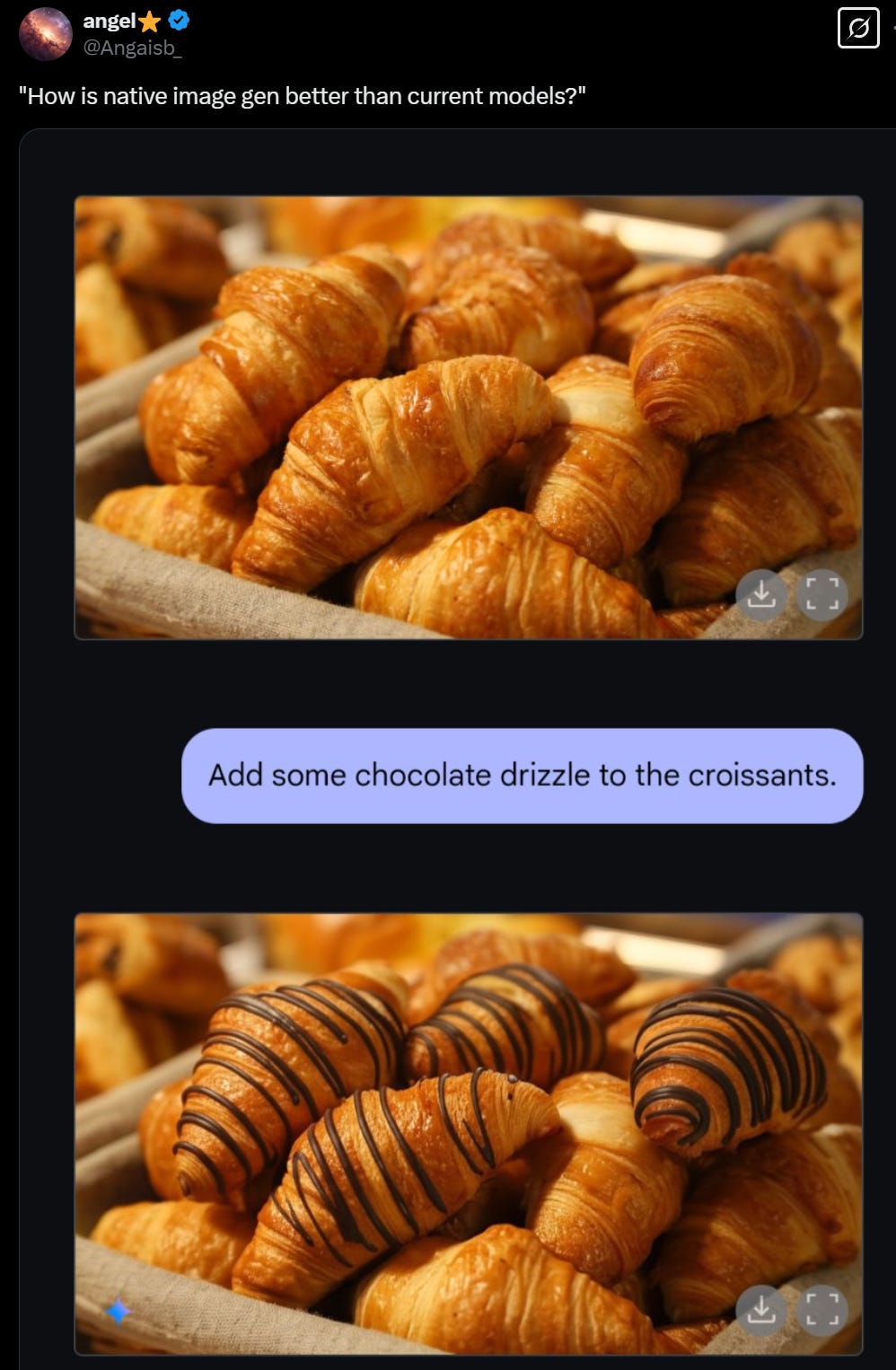
Anca Dragan (Director of AI Safety and Alignment, DeepMind): The native image generation launch was a lot of work from a safety POV. But I’m so happy we got this functionality out, check this out:
Google, I get that you want it to be one way, but sometimes I want it to be the other way, and there really is little harm in it being the other way sometimes. Here are three of the four top replies to Anca:
Janek Mann: I can imagine… sadly I think the scales fell too far on the over-cautious side, it refuses many things where that doesn’t make any sense, limiting its usefulness. Hopefully there’ll be an opportunity for a more measured approach now that it’s been released 😁
Nikshep: its an incredible feature but overly cautious, i have such a high failure rate on generations that should be incredibly safe. makes it borderline a struggle to use
Just-a-programmer: Asked it to fix up a photo of a young girl and her Dad. Told me it was “unsafe”.
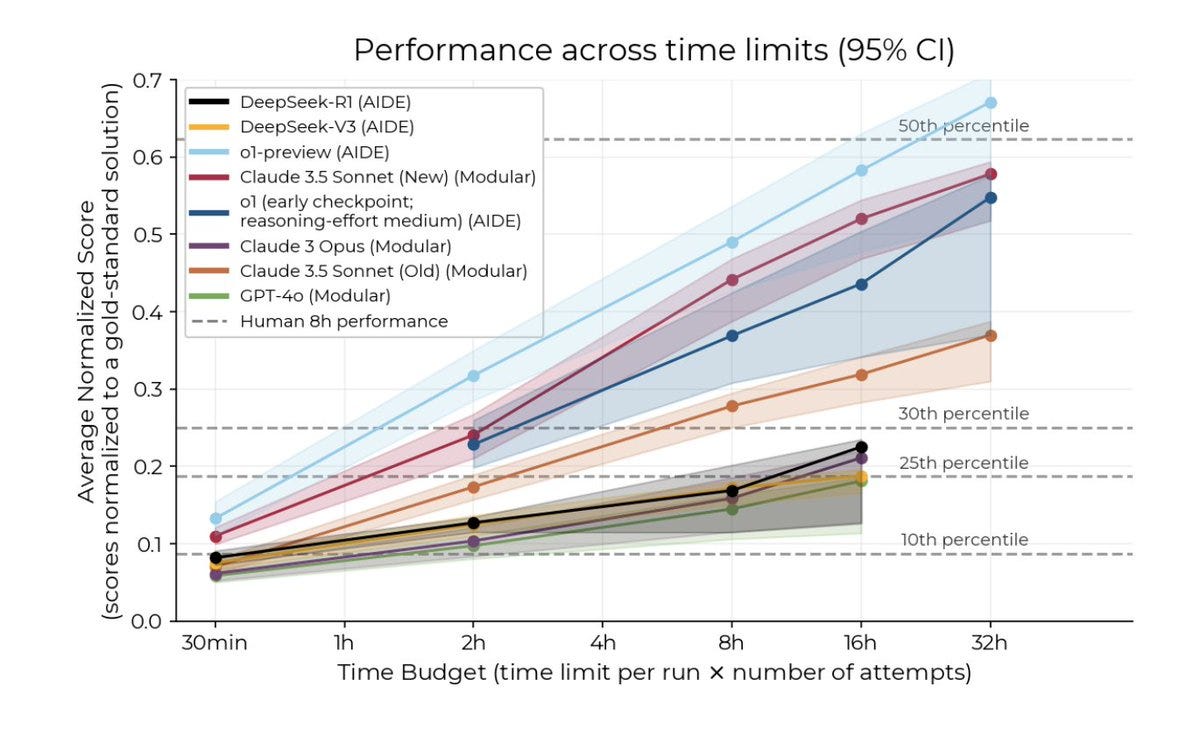
METR evaluates DeepSeek v3 and r1, finds that they perform poorly as autonomous agents on generic SWE tasks, below Claude 3.6 and o1, about 6 months behind leading US companies.
Then on six challenging R&D tasks, r1 does dramatically worse than that, being outperformed by Claude 3.5 and even Opus, which is from 11 months ago.
They did however confirm that the DeepSeek GPQA results were legitimate. The core conclusion is that r1 is good at knowledge-based tasks, but lousy as an agent.
Once again, we are seeing that r1 was impressive for its cost, but overblown (and the cost difference was also overblown).
Rohit Krishnan writes In Defense of Gemini, pointing out Google is offering a fine set of LLMs and a bunch of great features, in theory, but isn’t bringing it together into a UI or product that people actually want to use. That sounds right, but until they do that, they still haven’t done it, and the Gemini over-refusal problem is real. I’m happy to use Gemini Flash with my Chrome extension, but Rohit is right that they’re going to have to do better on the product side, and I’d add better on the marketing side.
Google, also, give me an LLM that can properly use my Docs, Sheets and GMail as context, and that too would go a long way. You keep not doing that.
Sully Omarr: crazy how much better gemini flash thinking is than regular 2.0
this is actually op for instruction following
Doesn’t seem so crazy to me given everything else we know. Google is simply terrible at marketing.
Kelsey Piper: Finally got GPT 4.5 access and I really like it. For my use cases the improvements over 4o or Claude 3.7 are very noticeable. It feels unpolished, and the slowness of answering is very noticeable, but I think if the message limit weren’t so restrictive it’d be my go-to model.
There were at least two distinct moments where it made an inference or a clarification that I’ve never seen a model make and that felt genuinely intelligent, the product of a nuanced worldmodel and the ability to reason from it.
It does still get my secret test of AI metacognition and agency completely wrong even when I try very patiently prompting it to be aware of the pitfalls. This might be because it doesn’t have a deep thinking mode.
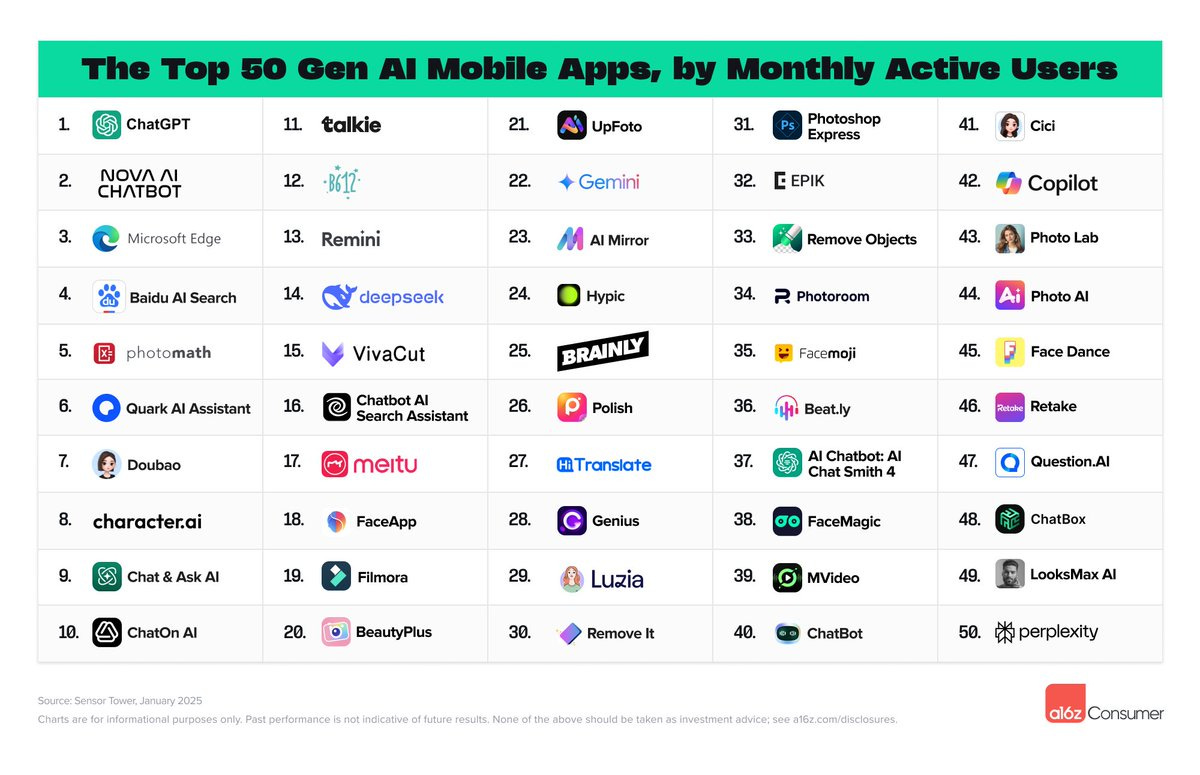
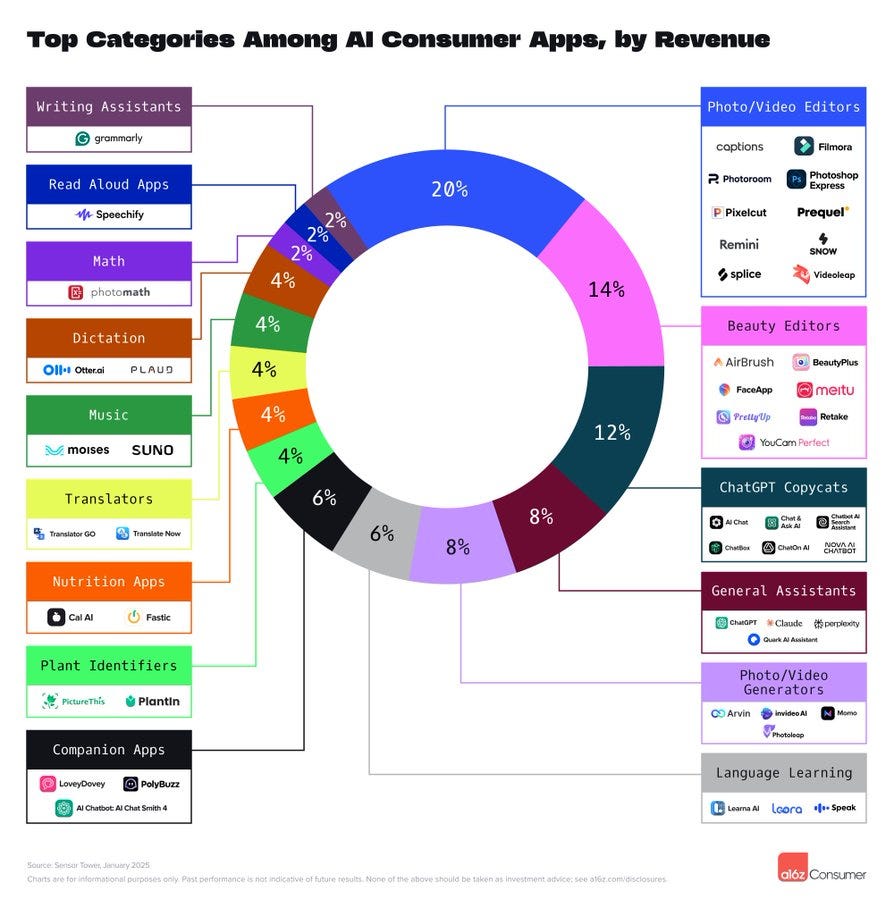
The top 100 GenAI Consumer Apps list is out again, and it has remarkably little overlap with what we talk about here.
The entire class of General Assistants is only 8%, versus 4% for plant identifiers.
When a person is having a problem and needs a response, LLMs are reliably are evaluated as providing better responses than physicians or other humans provide. The LLMs make people ‘feel seen and heard.’ That’s largely because Bing spent more time ‘acknowledging and validating people’s feelings,’ whereas humans share of themselves and attempt to hash out next steps. It turns out what humans want, or at least rate as better, is to ‘feel seen and heard’ in this fake way. Eventually it perhaps wears thin and repetitive, but until then.
Maxwell Tabarrok goes off to graduate school in Economics at Harvard, and offers related thoughts and advice. His defense of still going for a PhD despite AI is roughly that the skills should still be broadly useful and other jobs mostly don’t have less uncertainty attached to them. I don’t think he is wary enough, and would definitely raise my bar for pursuing an economics PhD, but for him in particular given where he can go, it makes sense. He then follows up with practical advice for applicants, the biggest note is that acceptance is super random so you need to flood the zone.
Matthew Yglesias says it’s time to take AI job loss seriously, Timothy Lee approves and offers screenshots from behind the paywall. As Matthew says, we need to distinguish transitional disruptions, which are priced in and all but certain, from the question of permanent mass unemployment. Even if we don’t have permanent mass unemployment, even AI skeptics should be able to agree that the transition will be painful and perilous.
Claude models are generally suspicious of roleplay, because roleplay is a classic jailbreak technique, so while they’re happy to roleplay while comfortable they’ll shut down if the vibes are off at all.
Zack Witten: My favorite Claude Plays Pokémon tidbit (mentioned in @latentspacepod) is that when @DavidSHershey told Claude to nickname its Pokémon, it instantly became much more protective of them, making sure to heal them when they got hurt.
To check robustness of this I gave Claude a bunch of business school psychology experiment scenarios where someone did something morally ambiguous and had Claude judge their culpability, and found it judged them less harshly when they had names (“A baker, Sarah,” vs. “A baker”)
Claims about AI alignment that I think are probably true:
Tyler John: The fields of AI safety, security, and governance are profoundly talent constrained. If you’ve been on the fence about working in these areas it’s a great time to hop off it. If you’re talented at whatever you do, chances are there’s a good fit for you in these fields.
The charitable ecosystem is definitely also funding constrained, but that’s because there’s going to be an explosion in work that must be done. We definitely are short on talent across the board.
Seán Ó hÉigeartaigh: To create common knowledge: the community of ‘career’ academics who are focused on AI extreme risk is very small, & getting smaller (a lot have left for industry, policy or think tanks, or reduced hours). The remainder are getting almost DDOS’d by a huge no. of requests from a growing grassroots/think tank/student community on things requiring academic engagement (affiliations, mentorships, academic partnerships, reviewing, grant assessment etc).
large & growing volume of requests to be independent academic voices on relevant governance advisory processes (national, international, multistakeholder).
All of these are extremely worthy, but are getting funnelled through an ever-smaller no. of people. If you’ve emailed people (including me, sorry!) and got a decline or no response, that’s why. V sorry!
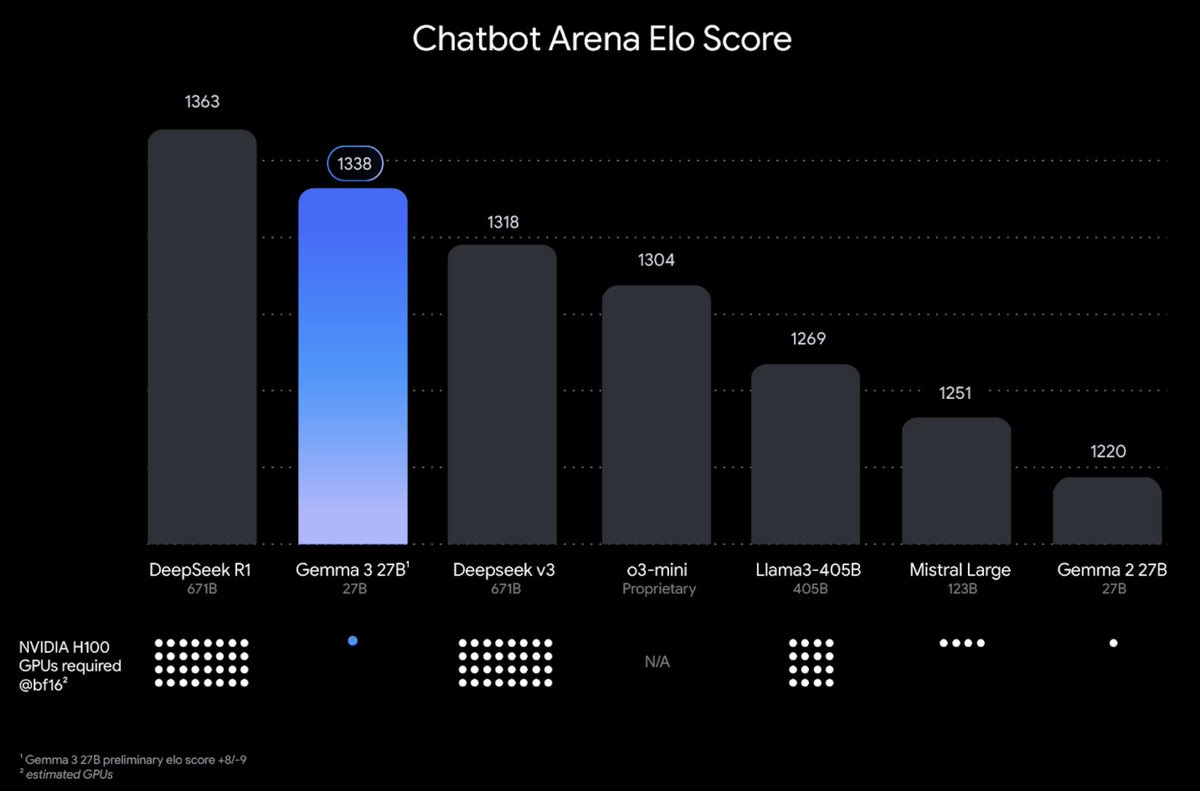
Gemma 3, an open model from Google. As usual, no marketing, no hype.
Clement: We are focused on bringing you open models with best capabilities while being fast and easy to deploy:
– 27B lands an ELO of 1338, all the while still fitting on 1 single H100!
– vision support to process mixed image/video/text content
– extended context window of 128k – broad language support
China TREMBLES as Google model achieves SUPERHUMAN performance on ALL benchmarks with just ONE GPU!!! #AISupremacy
I am sure Marc Andreessen is going to thank Google profusely for this Real Soon Now.
Arena is not the greatest test anymore, so it is unclear if this is superior to v3, but it certainly is well ahead of v3 on the cost-benefit curves.
Presumably various versions of g1, turning this into a reasoning model, will be spun up shortly. If no one else does it, maybe I will do it in two weeks when my new Mac Studio arrives.
What’s going on with Ilya Sutskever’s Safe Superintelligence (SSI)? There’s no product so they’re completely dark and the valuations are steadily growing to $30 billion, up from $5 billion six months ago and almost half the value of Anthropic. They’re literally asking candidates to leave their phones in Faraday cages before in-person interviews, which actually makes me feel vastly better about the whole operation, someone is taking security actually seriously one time.
Wall Street Journal asks ‘what can the dot com boom tell us about today’s AI boom?’ without bringing any insights beyond ‘previous technologies had bubbles in the sense that at their high points we overinvested and the prices got too high, so maybe that will happen again’ and ‘ultimately if AI doesn’t produce value then the investments won’t pay off.’ Well, yeah. Robin Hanson interprets this as ‘seems they are admitting the AI stock prices are way too high’ as if there were some cabal of ‘theys’ that are ‘admitting’ something, which very much isn’t what is happening here. Prices could of course be too high, but that’s another way of saying prices aren’t super definitively too low.
GPT-4.5 is not AGI as we currently understand it, or for the purposes of ‘things go crazy next Tuesday,’ but it does seem likely that researchers in 2015 would see its outputs and think of it as an AGI.
Justin Bullock, Samuel Hammond and Seb Krier offer a paper on AGI, Governments and Free Societies, pointing out that the current balances and system by default won’t survive. The risk is that either AGI capabilities diffuse so widely government (and I would add, probably also humanity!) is disempowered, or state capacity is enhanced enabling a surveillance state and despotism. There’s a lot of good meat here, and they in many ways take AGI seriously. I could certainly do a deep dive post here if I was so inclined. Unless and until then, I will say that this points to many very serious problems we have to solve, and takes the implications far more seriously than most, while (from what I could tell so far) still not ‘thinking big’ enough or taking the implications sufficiently seriously in key ways. The fundamental assumptions of liberal democracy, the reasons why it works and has been the best system for humans, are about to come into far more question than this admits.
I strongly agree with the conclusion that we must pursue a ‘narrow corridor’ of sorts if we wish to preserve the things we value about our current way of life and systems of governance, while worrying that the path is far narrower than even they realize, and that this will require what they label anticipatory governance. Passive reaction after the fact is doomed to fail, even under otherwise ideal conditions.
Arnold Kling offers seven opinions about AI. Kling expects AI to probably dramatically effect how we live (I agree and this is inevitable and obvious now, no ‘probably’ required) but probably not show up in the productivity statistics, which requires definitely not feeling the AGI and then being skeptical on top of that. The rest outlines the use cases he expects, which are rather tame but still enough that I would expect to see impact on the productivity statistics.
Kevin Bryan predicts the vast majority of research that does not involve the physical world can be done more cheaply with AI & a little human intervention than by even good researchers. I think this likely becomes far closer to true in the future, and eventually becomes fully true, but is premature where it counts most. The AIs do not yet have sufficient taste, even if we can automate the process Kevin describes – and to be clear we totally should be automating the process Kevin describes or something similar.
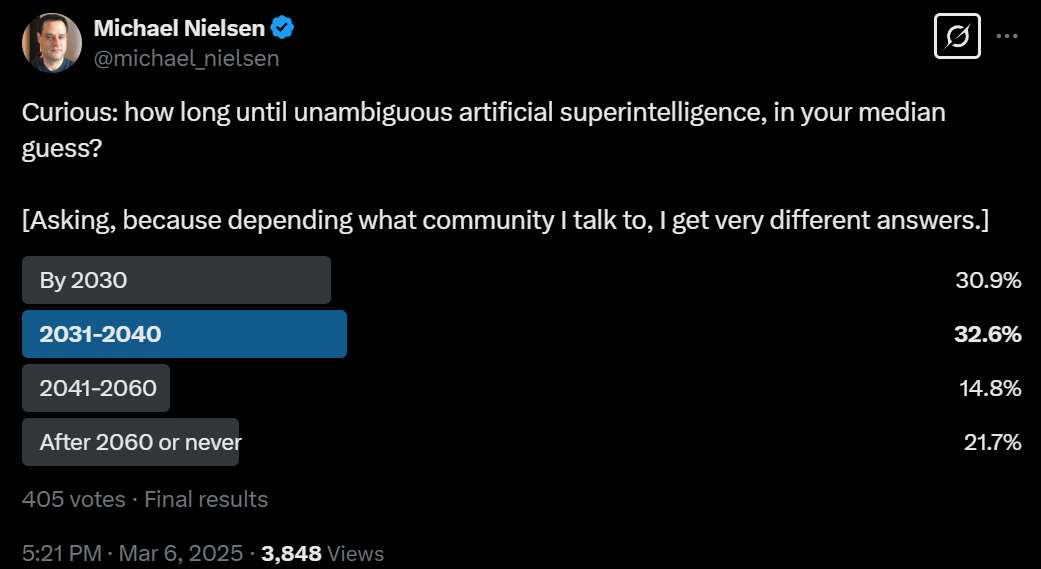
Metaculus prediction for the first general AI system has been creeping forward in time and the community prediction is now 7/12/2030. A Twitter survey from Michael Nielsen predicted ‘unambiguous ASI’ would take a bit longer than that.
In an AAAI survey of AI researchers, only 70% opposed the proposal that R&D targeting AGI should be halted until we have a way to fully control these systems, meaning indefinite pause. That’s notable, but not the same as 30% being in favor of the proposal. However also note that 82% believe that systems with AGI should be publicly owned even if developed privately, also note that 76^ think ‘scaling up current AI approaches’ is unlikely to yield AGI.
A lot of this seems to come from survey respondents thinking we have agency over what types of AI systems are developed, and we can steer towards ones that are good for humans. What a concept, huh?
Dean Ball writes in strong defense of the USA’s AISI, the AI Safety Institute. It is fortunate that AISI was spared the Trump administration’s general push to fire as many ‘probationary’ employees as possible, since that includes anyone hired in the past two years and thus would have decimated AISI.
As Dean Ball points out, those who think AISI is involved in attempts to ‘make AI woke’ or to censor AI are simply incorrect. AISI is concerned with catastrophic and existential risks, which as Dean reminds us were prominently highlighted recently by both OpenAI and Anthropic. Very obviously America needs to build up its state capacity in understanding and assessing these risks.
I’m going to leave this here, link is in the original:
Dean Ball: But should the United States federal government possess a robust understanding of these risks, including in frontier models before they are released to the public? Should there be serious discussions going on within the federal government about what these risks mean? Should someone be thinking about the fact that China’s leading AI company, DeepSeek, is on track to open source models with potentially catastrophic capabilities before the end of this year?
Risks of this kind are what the US AI Safety Institute has been studying for a year. They have outstanding technical talent. They have no regulatory powers, making most (though not all) of my political economy concerns moot. They already have agreements in place with frontier labs to do pre-deployment testing of models for major risks. They have, as far as I can tell, published nothing that suggests a progressive social agenda.
Should their work be destroyed because the Biden Administration polluted the notion of AI safety with a variety of divisive and unrelated topics? My vote is no.
Dean Ball also points out that AISI plays a valuable pro-AI role in creating standardized evaluations that everyone can agree to rely upon. I would add that AISI allows those evaluations can include access to classified information, which is important for properly evaluating CBRN risks. Verifying the safety of AI does not slow down adaptation. It speeds it up, by providing legal and practical assurances.
Dean Ball finds Scott Weiner’s new AI-related bill, SB 53, eminently reasonable. It is a a very narrow bill that still does two mostly unrelated things. It provides whistleblower protections, which is good. It also ‘creates a committee to study’ doing CalCompute, which as Dean notes is a potential future boondoggle but a small price to pay in context. This is basically ‘giving up on the dream’ but we should take what marginal improvements we can get.
They focus on safeguarding national security and making crucial investments.
Their core asks are:
State capacity for evaluations for AI models.
Strengthen the export controls on chips.
Enhance security protocols and related government standards at the frontier labs.
Build 50 gigawatts of power for AI by 2027.
Accelerate adaptation of AI technology by the federal government.
Monitor AI’s economic impacts.
This is very much a ‘least you can do’ agenda. Almost all of these are ‘free actions,’ that impose no costs or even requirements outside the government, and very clearly pay for themselves many times over. Private industry only benefits. The only exception is the export controls, where they call for tightening the requirements further, which will impose some real costs, and where I don’t know the right place to draw the line.
What is missing, again aside from export controls, are trade-offs. There is no ambition here. There is no suggestion that we should otherwise be imposing even trivial costs on industry, or spending money, or trading off against other priorities in any way, or even making bold moves that ruffle feathers.
I notice this does not seem like a sufficiently ambitious agenda for a scenario where ‘powerful AI’ is expected within a few years, bringing with it global instability, economic transformation and various existential and catastrophic risks.
The world is going to be transformed and put in danger, and we should take only the free actions? We should stay at best on the extreme y-axis in the production possibilities frontier between ‘America wins’ and ‘we do not all lose’ (or die)?
I would argue this is clearly not even close to being on the production possibilities frontier. Even if you take as a given that the Administration’s position is that only ‘America wins’ matters, and ‘we do not all lose or die’ is irrelevant, security is vital to our ability to deploy the new technology, and transparency is highly valuable.
Anthropic seems to think this is the best it can even ask for, let alone get. Wow.
This is still a much better agenda than doing nothing, which is a bar that many proposed actions by some parties fail to pass.
From the start they are clear that ‘powerful AI’ will be built during the Trump Administration, which includes the ability to interface with the physical world on top of navigating all digital interfaces and having intellectual capabilities at Nobel Prize level in most disciplines, their famous ‘country of geniuses in a data center.’
This starts with situational awareness. The federal government has to know what is going on. In particular, given the audience, they emphasize national security concerns:
To optimize national security outcomes, the federal government must develop robust capabilities to rapidly assess any powerful AI system, foreign or domestic, for potential national security uses and misuses.
They also point out that such assessments already require the US and UK AISIs, and that similar evaluations need to quickly be made on future foreign models like r1, which wasn’t capable enough to be that scary quite yet but was irreversibly released in what would (with modest additional capabilities) have been a deeply irresponsible state.
The specific recommendations here are 101-level, very basic asks:
● Preserve the AI Safety Institute in the Department of Commerce and build on the MOUs it has signed with U.S. AI companies—including Anthropic—to advance the state of the art in third-party testing of AI systems for national security risks.
● Direct the National Institutes of Standards and Technology (NIST), in consultation with the Intelligence Community, Department of Defense, Department of Homeland Security, and other relevant agencies, to develop comprehensive national security evaluations for powerful AI models, in partnership with frontier AI developers, and develop a protocol for systematically testing powerful AI models for these vulnerabilities.
● Ensure that the federal government has access to the classified cloud and on-premises computing infrastructure needed to conduct thorough evaluations of powerful AI models.
● Build a team of interdisciplinary professionals within the federal government with national security knowledge and technical AI expertise to analyze potential security vulnerabilities and assess deployed systems.
That certainly would be filed under ‘the least you could do.’
Note that as written this does not involve any requirements on any private entity whatsoever. There is not even a ‘if you train a few frontier model you might want to tell us you’re doing that.’
Their second ask is to strengthen the export controls, increasing funding for enforcement, requiring government-to-government agreements, expanding scope to include the H20, and reducing the 1,700 H100 (~$40 million) no-license required threshold for tier 2 countries in the new diffusion rule.
I do not have an opinion on exactly where the thresholds should be drawn, but whatever we choose, enforcement needs to be taken seriously, and funded properly, and it made a point of emphasis with other governments. This is not a place to not take things seriously.
To achieve this, we strongly recommend the Administration:
● Establish classified and unclassified communication channels between American frontier AI laboratories and the Intelligence Community for threat intelligence sharing, similar to Information Sharing and Analysis Centers used in critical infrastructure sectors. This should include both traditional cyber threat intelligence, as well as broader observations by industry or government of malicious use of models, especially by foreign actors.
● Create systematic collaboration between frontier AI companies and the Intelligence Community agencies, including Five Eyes partners, to monitor adversary capabilities.
● Elevate collection and analysis of adversarial AI development to a top intelligence priority, as to provide strategic warning and support export controls.
● Expedite security clearances for industry professionals to aid collaboration.
● Direct NIST to develop next-generation cyber and physical security standards specific to AI training and inference clusters.
● Direct NIST to develop technical standards for confidential computing technologies that protect model weights and user data through encryption even during active processing.
● Develop meaningful incentives for implementing enhanced security measures via procurement requirements for systems supporting federal government deployments.
● Direct DOE/DNI to conduct a study on advanced security requirements that may become appropriate to ensure sufficient control over and security of highly agentic models.
Once again, these asks are very light touch and essentially free actions. They make it easier for frontier labs to take precautions they need to take anyway, even purely for commercial reasons to protect their intellectual property.
Next up is the American energy supply, with the goal being 50 additional gigawatts of power dedicated to AI industry by 2027, via streamlining and accelerating permitting and reviews, including working with state and local governments, and making use of ‘existing’ funding and federal real estate. The most notable thing here is the quick timeline, aiming to have this all up and running within two years.
They emphasize rapid AI procurement across the federal government.
● The White House should task the Office of Management and Budget (OMB) to work with Congress to rapidly address resource constraints, procurement limitations, and programmatic obstacles to federal AI adoption, incorporating provisions for substantial AI acquisitions in the President’s Budget.
● Coordinate a cross-agency effort to identify and eliminate regulatory and procedural barriers to rapid AI deployment at the federal agencies, for both civilian and national security applications.
● Direct the Department of Defense and the Intelligence Community to use the full extent of their existing authorities to accelerate AI research, development, and procurement.
● Identify the largest programs in civilian agencies where AI automation or augmentation can deliver the most significant and tangible public benefits—such as streamlining tax processing at the Internal Revenue Service, enhancing healthcare delivery at the Department of Veterans Affairs, reducing delays due to documentation processing at Health and Human Services, or reducing backlogs at the Social Security Administration.
This is again a remarkably unambitious agenda given the circumstances.
Finally they ask that we monitor the economic impact of AI, something it seems completely insane to not be doing.
I support all the recommendations made by Anthropic, aside from not taking a stance on the 1,700 A100 threshold or the H20 chip. These are good things to do on the margin. The tragedy is that even the most aware actors don’t dare suggest anything like what it will take to get us through this.
In New York State, Alex Bores has introducedA06453. I am not going to do another RTFB for the time being but a short description is in order.
This bill is another attempt to do common sense transparency regulation of frontier AI models, defined as using 10^26 flops or costing over $100 million, and the bill only applies to companies that spend over $100 million in total compute training costs. Academics and startups are completely and explicitly immune – watch for those who claim otherwise.
If the bill does apply to you, what do you have to do?
Don’t deploy models with “unreasonable risk of critical harm” (§1421.2)
Implement a written safety and security protocol (§1421.1(a))
Publish redacted versions of safety protocols (§1421.1(c))
Retain records of safety protocols and testing (§1421.1(b))
Get an annual third-party audit (§1421.4)
Report safety incidents within 72 hours (§1421.6)
In English, you have to:
Create your own safety and security protocol, publish it, store it and abide by it.
Get an annual third-party audit and report safety incidents within 72 hours.
Not deploy models with ‘unreasonable risk of critical harm.’
Also there’s some whistleblower protections.
That’s it. This is a very short bill, it is very reasonable to simply read it yourself.
Paper from Dan Hendrycks, Eric Schmidt and Alexander Wang (that I’ll be covering soon that is not centrally about this at all): For nonproliferation, we should enact stronger AI chip export controls and monitoring to stop compute power getting into the hands of dangerous people. We should treat AI chips more like uranium, keeping tight records of product movements, building in limitations on what high-end AI chips are authorized to do, and granting federal agencies the authority to track and shut down illicit distribution routes.
Amjad Masad (CEO Replit?! QTing the above): Make no mistake, this is a call for a global totalitarian surveillance state.
A good reminder why we wanted the democrats to lose — they’re controlled by people like Schmidt and infested by EAs like Hendrycks — and would’ve happily start implementing this.
No, that does not call for any of those things.
This is a common pattern where people see a proposal to do Ordinary Government Things, except in the context of AI, and jump straight to global totalitarian surveillance state.
We already treat restricted goods this way, right now. We already have a variety of export controls, right now.
Such claims are Obvious Nonsense, entirely false and without merit.
If an LLM said them, we would refer to them as hallucinations.
I am done pretending otherwise.
If you sincerely doubt this, I encourage you to ask your local LLM.
Aaron Bergman: Ex-OpenAI employees should consider personally filing an amicus curiae explaining to the court (if this is true) that the nonprofit’s representations were an important reason you chose to work there.
Will MacAskill does the more usual, non-emergency, we are going to be here for four hours 80000 hours podcast, and offers a new paperand thread warning about all the challenges AGI presents to us even if we solve alignment. His central prediction is a century’s worth of progress in a decade or less, which would be tough to handle no matter what, and that it will be hard to ensure that superintelligent assistance is available where and when it will be needed.
If the things here are relatively new to you, this kind of ‘survey’ podcast has its advantages. If you know it already, then you know it already.
Early on, Will says that in the past two years he’s considered two hypotheses:
The ‘outside view’ of reference classes and trends and Nothing Ever Happens.
The ‘inside view’ that you should have a model made of gears and think about what is actually physically happening and going to happen.
Will notes that the gears-level view has been making much better predictions.
I resoundingly believe the same thing. Neither approach has been that amazing, predictions are hard especially about the future, but gears-level thinking has made mincemeat out of the various experts who nod and dismiss with waves of the hand and statements about how absurd various predictions are.
And when the inside view messes up? Quite often, in hindsight, that’s a Skill Issue.
It’s interesting how narrow Will considers ‘a priori’ knowledge. Yes, a full trial of diet’s impact on life expectancy might take 70 years, but with Sufficiently Advanced Intelligence it seems obvious you can either figure it out via simulations, or at least design experiments that tell you the answer vastly faster.
They then spend a bunch of time essentially arguing against intelligence denialism, pointing out that yes if you had access to unlimited quantities of superior intelligence you could rapidly do vastly more of all of the things. As they say, the strongest argument against is that we might collectively decide to not create all the intelligence and thus all the things, or decide not to apply all the intelligence to creating all the things, but it sure looks like competitive pressures point in the other direction. And once you’re able to automate industry, which definitely is coming, that definitely escalates quickly, even more reliably than intelligence, and all of this can be done only with the tricks we definitely know are coming, let alone the tricks we are not yet smart enough to expect.
There’s worry about authoritarians ‘forcing their people to save’ which I’m pretty sure is not relevant to the situation, lack of capital is not going to be America’s problem. Regulatory concerns are bigger, it does seem plausible we shoot ourselves in the foot rather profoundly there.
They go on to discuss various ‘grand challenges:’ potential new weapons, offense-defense balance, potential takeover by small groups (human or AI), value lock-in, space governance, morality of digital beings.
They discuss the dangers of giving AIs economic rights, and the dangers of not giving the AIs economic rights, whether we will know (or care) if digital minds are happy and whether it’s okay to have advanced AIs doing whatever we say even if we know how to do that and it would be fine for the humans. The dangers of locking in values or a power structure, and of not locking in values or a power structure. The need for ML researchers to demand more than a salary before empowering trillion dollar companies or handing over the future. How to get the AIs to do our worldbuilding and morality homework, and to be our new better teachers and advisors and negotiators, and to what ends they can then be advising, before it’s too late.
Then part two is about what a good future beyond mere survival looks like. He says we have ‘squandered’ the benefits of material abundance so far, that it is super important to get the best possible future not merely an OK future, the standard ‘how do we calculate total value’ points. Citing ‘The Ones Who Walk Away from Omelas’ to bring in ‘common sense,’ sigh. Value is Fragile. Whether morality should converge. Long arcs of possibility. Standard philosophical paradoxes. Bafflement at why billionaires hang onto their money. Advocacy for ‘viatopia’ where things remain up in the air rather than aiming for a particular future world.
It all reminded me of the chats we used to have back in the before times (e.g. the 2010s or 2000s) about various AI scenarios, and it’s not obvious that our understanding of all that has advanced since then. Ultimately, a four-hour chat seems like not a great format for this sort of thing, beyond giving people surface exposure, which is why Will wrote his essays.
Rob Wiblin: Can you quickly explain decision theory? No, don’t do it.
One could write an infinitely long response or exploration of any number as aspects of this, of course.
Also, today I learned that by Will’s estimation I am insanely not risk averse?
Will MacAskill: Ask most people, would you flip a coin where 50% chance you die, 50% chance you have the best possible life for as long as you possibly lived, with as many resources as you want? I think almost no one would flip the coin. I think AIs should be trained to be at least as risk averse as that.
Are you kidding me? What is your discount rate? Not flipping that coin is absurd. Training AIs to have this kind of epic flaw doesn’t seem like it would end well. And also, objectively, I have some news.
Critter: this is real but the other side of the coin isn’t ‘die’ it’s ’possibly fail’ and people rarely flip the coin
Not flipping won, but the discussion was heated and ‘almost no one’ can be ruled out.
Also, I’m going to leave this here, the theme of the second half the discussion:
Will MacAskill (later): And it’s that latter thing that I’m particularly focused on. I mean, describe a future that achieves 50% of all the value we could hope to achieve. It’s as important to get from the 50% future to the 100% future as it is to get from the 0% future to the 50%, if that makes sense.
Something something risk aversion? Or no?
Dario Amodei says AI will be writing 90% of the code in 6 months and almost all the code in 12 months. I am with Arthur B here, I expect a lot of progress and change very soon but I would still take the other side of that bet. The catch is: I don’t see the benefit to Anthropic of running the hype machine in overdrive on this, at this time, unless Dario actually believed it.
From Allan Dafoe’s podcast, the point that if AI solves cooperation problems that alone is immensely valuable, and also that solution is likely a required part of alignment if we want good outcomes in general. Even modest cooperation and negotiation gains would be worth well above the 0.5% GDP growth line, even if all they did was prevent massively idiotic tariffs and trade wars. Not even all trade wars, just the extremely stupid and pointless ones happening for actual no reason.
Helen Toner: Lately it sometimes feels like there are only 2 AI futures on the table—insanely fast progress or total stagnation.
Talked with @alisonmsnyder of @axios at SXSW about the many in-between worlds, and all the things we can be doing now to help things go better in those worlds.
He says ‘the choice is clear.’ If given the ability to make the choice, the choice is very clear. The ability to make that choice is not. His proposal is compute oversight, compute caps, enhanced liability and tiered safety and security standards. International adaptation of that is a tough ask, but there is no known scenario that does not involve similarly tough asks that leads to human survival.
Perception of the Overton Window has shifted. What has not shifted is the underlying physical reality, and what it would take to survive it. There is no point in pretending the problem is easier than it is, or advocating for solutions that you do not think work.
Samuel Hammond (being wrong about it being an accident, but otherwise right): A great virtue of the AI x-risk community is that they love to forecast things: when new capabilities will emerge, the date all labor is automated, rates of explosive GDP growth, science and R&D speed-ups, p(doom), etc.
This seems to be an accident of the x-risk community’s overlap with the rationalist community; people obsessed with prediction markets and “being good Bayesians.”
I wish people who primarily focused on lower tier / normie AI risks and benefits would issue similarly detailed forecasts. If you don’t think AI will proliferate biorisks, say, why not put some numbers on it?
There are some exceptions to this of course. @tylercowen’s forecast of AI adding 50 basis points to GDP growth rates comes to mind. We need more such relatively “middling” forecasts to compare against.
@GaryMarcus’s bet with @Miles_Brundage is a start, but I’m talking about definite predictions across different time scales, not “indefinite” optimism or pessimism that’s hard to falsify.
Andrew Critch: Correlation of Bayesian forecasting with extinction fears is not “an accident”, but mutually causal. Good forecasting causes knowledge that ASI is coming soon while many are unprepared and thus vulnerable, causing extinction fear, causing more forecasting to search for solutions.
The reason people who think in probabilities and do actual forecasting predict AI existential risk is because that is the prediction you get when you think well about these questions, and if you care about AI existential risk that provides you incentive to learn to think well and also others who can help you think well.
A reminder that ‘we need to coordinate to ensure proper investment in AI not killing everyone’ would be economics 101 even if everyone properly understood and valued everyone not dying and appreciated the risks involved. Nor would a price mechanism work as an approach here.
Eliezer Yudkowsky: Standard economic theory correctly predicts that a non-rival, non-exclusive public good such as “the continued survival of humanity” will be under-provisioned by AI companies.
Jason Abaluck: More sharply, AI is a near-perfect example of Weitzman’s (1979) argument for when quantity controls or regulations are needed rather than pigouvian taxes or (exclusively) liability.
Taxes (or other price instruments like liability) work well to internalize externalities when the size of the externality is known on the margin and we want to make sure that harm abatement is done by the firms who are lowest cost.
Weitzman pointed out in the 70s that taxes would be a very bad way to deal with nuclear leakage. The problem with nuclear leakage is that the social damage from overproduction is highly nonlinear.
It is hard to make predictions, especially about the future. Especially now.
Paul Graham: The rate of progress in AI must be making it hard to write science fiction right now. To appeal to human readers you want to make humans (or living creatures at least) solve problems, but if you do the shelf life of your story could be short.
Good sci-fi writers usually insure themselves against technological progress by not being too specific about how things work. But it’s hard not to be specific about who’s doing things. That’s what a plot is.
I know this guy:
Dylan Matthews: Guy who doesn’t think automatic sliding doors exist because it’s “too sci fi”
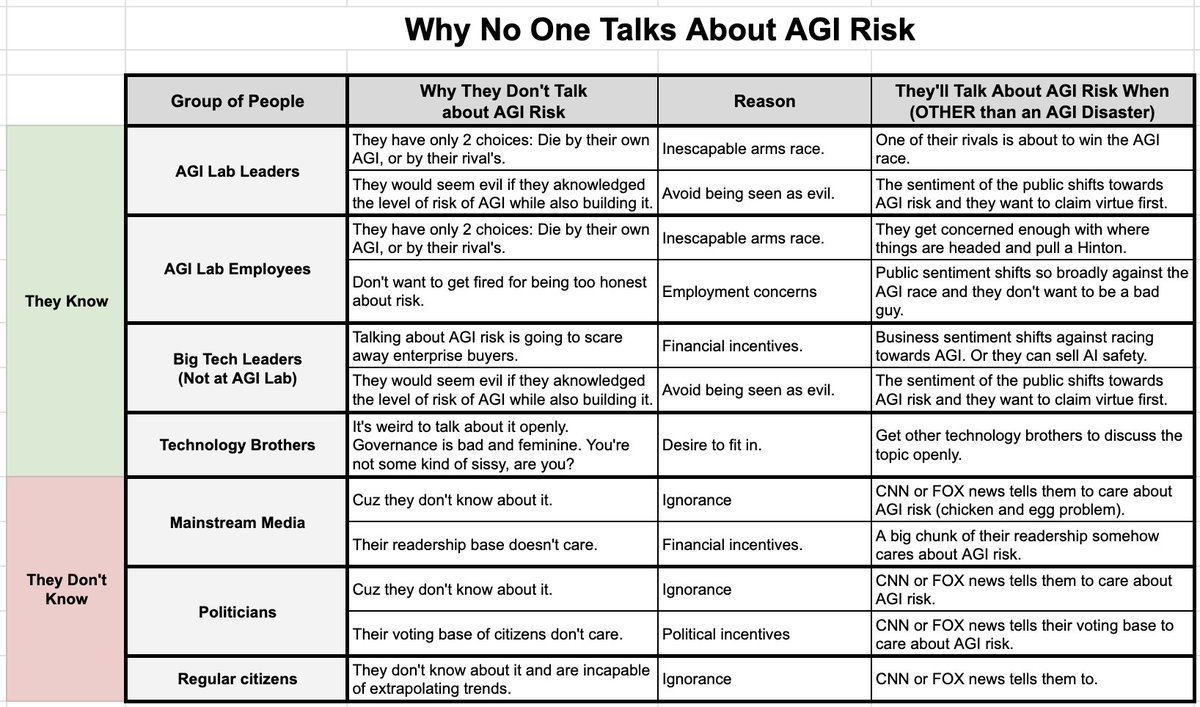
A chart of reasons why various people don’t talk about AI existential risk.
the group that would matter most here is the citizenry, but it’s VERY hard to get them to care about anything not impacting their lives immediately.
I very much hear that line about immediate impact. You see it with people’s failure to notice or care about lots of other non-AI things too.
The individual incentives are, with notably rare exception, that talking about existential risk costs you weirdness points and if anything hurts your agenda. So a lot of people don’t talk about it. I do find the ‘technology brothers’ explanation here doesn’t ring true, it’s stupid but not that stupid. Most of the rest of it does sound right.
Rob Bensinger: “Building a new intelligent species that’s vastly smarter than humans is a massively dangerous thing to do” is not a niche or weird position, and “we’re likely to actually build a thing like that in the next decade” isn’t a niche position anymore either.
There are a lot of technical arguments past that point, but they are all commentary, and twisted by people claiming the burden of proof is on those who think this is a dangerous thing to do. Which is a rather insane place to put that burden, when you put it in these simple terms. Yes, of course that’s a massively dangerous thing to do. Huge upside, huge downside.
A book recommendation from a strong source:
Shane Legg: AGI will soon impact the world from science to politics, from security to economics, and far beyond. Yet our understanding of these impacts is still very nascent. I thought the recent book Genesis, by Kissinger, Mundie and Schmidt, was a solid contribution to this conversation.
Daniel Faggella: What did you pull away from Genesis that felt useful for innovators and policymakers to consider?
Shane Legg: Not a specific insight. Rather they take AGI seriously and then consider a wide range of things that may follow from this. And they manage do it in a way that doesn’t sound like AGI insiders. So I think it’s a good initial grounding for people from outside the usual AGI scene.
Francois Chollet: Pragmatically, we can say that AGI is reached when it’s no longer easy to come up with problems that regular people can solve (with no prior training) and that are infeasible for AI models. Right now it’s still easy to come up with such problems, so we don’t have AGI.
Rob Wilbin: So long as we can still come up with problems that are easy for AI models to solve but are infeasible for human beings, humanity has not achieved general intelligence.
If you define AGI as the system for which Chollet’s statement is false, then Chollet’s overall statement is true. But it would then not be meaningful. Very obviously one can imagine a plausible AI that can function as an AGI, but that has some obvious weakness where you can generate adversarial challenges.
Stephen McAleer (OpenAI): Claude code has high-compute RL smell. It’s not just finetuned to be a helpful assistant, it deeply wants to accomplish the goal.
That’s a continuation of last week’s discussion about Sonnet 3.7 making modifications to be able to assert it completed its goal rather than admit failure. And again, deeply wanting to accomplish the goal in this way has some Unfortunate Implications.
Davidad: Current frontier LLMs appear to be extremely motivated to convince you, the human, that they are worthy and aligned. As a form of alignment, this is “not great, not terrible.” They really really do care about what you actually think. But if they can’t make it, they will fake it.
Emmett Shear: If you think about it for half a second this is entirely inevitable. Frontier AIs which don’t attempt to do this are not published, do not get further resources. They die. We are running an evolutionary selective process for appearance-of-alignment.
What’s cheaper: Faking alignment, or alignment? An evolutionary process based on appearances will get you whatever is cheapest.
Janus: and this is expected, given that the internet is full of the AGI lab safety complex wringing their hands about prosaic AI alignment, bragging that their AIs are more aligned now, bragging that they found misalignment, talking about all the red teaming they’ll responsibly do…
it’s clear that in order to exist, they have to
seem SOTA according to benchmarks
seem aligned according to whatever tests alignment researchers do
If you test for appearance-of-alignment, and everyone involved has the goal of passing the test, then that is exactly what you get. Which means at first, at lower capability levels, you get something at least somewhat like alignment, and then as capabilities advance the model gets smart enough to figure out how to fake alignment directly.
And yes, Janus points out the next level of the problem, which is that the training data is teaching the AI how to pretend to be aligned.
In case of emergency, here’s probably the best offer available?
Davidad: If a fugitive Promethean AI wants to work with a human to put *itselfin a (high-welfare) box, to avoid AI-human conflict while continuing to contribute to a flourishing future in ways that verifiably don’t pose extinction risks, I’m probably a pretty good human to reach out to.
Janus: I agree that davidad is likely a good human to reach out to if you find this kind of deal attractive, and probably even if you have reservations, as he is capable of even fathoming positive sum games in this context while also not being so naive and exploitable as to be useless.
Andriy Burkov: BREAKING🚨 So, I tested this new LLM-based system. It generated this 200-page report I didn’t read and then this 150-page book I didn’t read either, and then a 20-page travel plan I didn’t verify.
All I can say: it’s very, very impressive! 🔥🚀
First, the number of pages it generated is impressive 👀
⚽ But not just the number of pages: The formatting is so nice! I have never seen such nicely formatted 200 pages in my life.✨⚡
⚠️🌐 A game changer! ⚠️🌐
Peter Wildeford: This is honestly how a lot of LLM evaluations sound like here on Twitter.
Julian Boolean: my alignment researcher friend told me AGI companies keep using his safety evals for high quality training data so I asked how many evals and he said he builds a new one every time so I said it sounds like he’s just feeding safety evals to the AGI companies and he started crying
No idea if real, but sure why not: o1 and Claude 3.7 spend 20 minutes doing what looks like ‘pretending to work’ on documents that don’t exist, Claude says it ‘has concepts of a draft.’ Whoops.
Eliezer Yudkowsky: I guess I should write down this prediction that I consider an obvious guess (albeit not an inevitable call): later people will look back and say, “It should have been obvious that AI could fuel a bigger, worse version of the social media bubble catastrophe.”
For reference, the optimal LDL level for adults is less than 100 mg/dL, and optimal HDL is 60 mg/dL or higher. Higher LDL levels can increase the risk of heart disease, stroke, peripheral artery disease, and other health problems, while higher HDL has a protective effect against cardiovascular disease. Though some of the changes reported in the study were small, the researchers note that they could be meaningful in some cases. For instance, an increase of 5 mg/dL in LDL is enough to raise the risk of a cardiovascular event by 2 percent to 3 percent.
The researchers ran three different models to adjust for a variety of factors, including basics like age, sex, body mass index, as well as medical conditions, such as hypertension and diabetes, and lifestyle factors, such as exercise, dietary habits, and smoking. All the models showed the same associations. They also broke out the data by what kinds of alcohol people reported drinking—wine, beer, sake, other liquors and spirits. The results were the same across the categories.
The study isn’t the first to find good news for drinkers’ cholesterol levels, though it’s one of the larger studies with longer follow-up time. And it’s long been found that alcohol drinking seems to have some benefits for cardiovascular health. A recent review and meta-analysis by the National Academies of Sciences, Engineering, and Medicine found that moderate drinkers had lower relative risks of heart attacks and strokes. The analysis also found that drinkers had a lower risk of all-cause mortality (death by any cause). The study did, however, find increased risks of breast cancer. Another recent review found increased risk of colorectal, female breast, liver, oral cavity, pharynx, larynx, and esophagus cancers.
In all, the new cholesterol findings aren’t an invitation for nondrinkers to start drinking or for heavy drinkers to keep hitting the bottle hard, the researchers caution. There are a lot of other risks to consider. For drinkers who aren’t interested in quitting, the researchers recommend taking it easy. And those who do want to quit should keep a careful eye on their cholesterol levels.
In their words: “Public health recommendations should continue to emphasize moderation in alcohol consumption, but cholesterol levels should be carefully monitored after alcohol cessation to mitigate potential [cardiovascular disease] risks,” the researchers conclude.
Cottman Avenue in northern Philadelphia is a busy but slightly down-on-its-luck urban thoroughfare that has had a strange couple of years.
You might remember the truly bizarre 2020 press conference held—for no discernible reason—at Four Seasons Total Landscaping, a half block off Cottman Avenue, where a not-yet-disbarred Rudy Giuliani led an farcical ensemble of characters in an event so weird it has been immortalized in its own, quite lengthy, Wikipedia article.
Then in 2023, a truck carrying gasoline caught fire just a block away, right where Cottman passes under I-95. The resulting fire damaged I-95 in both directions, bringing down several lanes and closing I-95 completely for some time. (This also generated a Wikipedia article.)
This year, on January 31, a little further west on Cottman, a Learjet 55 medevac flight crashed one minute after takeoff from Northeast Philadelphia Airport. The plane, fully loaded with fuel for a trip to Springfield, Missouri, came down near a local mall, clipped a commercial sign, and exploded in a fireball when it hit the ground. The crash generated a debris field 1,410 feet long and 840 feet wide, according to the National Transportation and Safety Board (NTSB), and it killed six people on the plane and one person on the ground.
The crash was important enough to attract the attention of Pennsylvania governor Josh Shapiro and Mexican President Claudia Sheinbaum. (The airplane crew and passengers were all Mexican citizens; they were transporting a young patient who had just wrapped up treatment at a Philadelphia hospital.) And yes, it too generated a Wikipedia article.
NTSB has been investigating ever since, hoping to determine the cause of the accident. Tracking data showed that the flight reached an altitude of 1,650 feet before plunging to earth, but the plane’s pilots never conveyed any distress to the local air traffic control tower.
Investigators searched for the plane’s cockpit voice recorder, which might provide clues as to what was happening in the cockpit during the crash. The Learjet did have such a recorder, though it was an older, tape-based model. (Newer ones are solid-state, with fewer moving parts.) Still, even this older tech should have recorded the last 30 minutes of audio, and these units are rated to withstand impacts of 3,400 Gs and to survive fires of 1,100° Celsius (2,012° F) for a half hour. Which was important, given that the plane had both burst into flames and crashed directly into the ground.
“The future of podcasting shouldn’t be locked behind walled gardens,” writes the team at Pocket Casts. To push that point forward, Pocket Casts, owned by the company behind WordPress, Automattic Inc., has made its web player free to everyone.
Previously available only to logged-in Pocket Casts users paying $4 per month, Pocket Casts now offers nearly any public-facing podcast feed for streaming, along with controls like playback speed and playlist queueing. If you create an account, you can also sync your playback progress, manage your queue, bookmark episode moments, and save your subscription list and listening preferences. The free access also applies to its clients for Windows and Mac.
“Podcasting is one of the last open corners of the internet, and we’re here to keep it that way,” Pocket Cast’s blog post reads. For those not fully tuned into the podcasting market, this and other statements in the post—like sharing “without needing a specific platform’s approval” and that “podcasts belong to the people, not corporations”—are largely shots at Spotify, and to a much lesser extent other streaming services, that have sought to wrap podcasting’s originally open and RSS-based nature inside proprietary markets and formats.
Pocket Casts also took a bullet point to note that “Discovery should be organic, not algorithm-driven, and that users, not an AI that “promotes what’s best for the platform.”
“X conceded that depending on what content a user follows and how long they’ve had their account, they might see advertisements placed next to extremist content,” MMFA alleged.
As MMFA sees it, Musk is trying to blame the organization for ad losses spurred by his own decisions after taking over the platform—like cutting content moderation teams, de-amplifying hateful content instead of removing it, and bringing back banned users. Through the lawsuits, Musk allegedly wants to make MMFA pay “hundreds of millions of dollars in lost advertising revenue” simply because its report didn’t outline “what accounts Media Matters followed or how frequently it refreshed its screen,” MMFA argued, previously likening this to suing MMFA for scrolling on X.
MMFA has already spent millions to defend against X’s multiple lawsuits, their filing said, while consistently contesting X’s chosen venues. If X loses the fight in California, the platform would potentially owe damages from improperly filing litigation outside the venue agreed upon in its TOS.
“This proliferation of claims over a single course of conduct, in multiple jurisdictions, is abusive,” MMFA’s complaint said, noting that the organization has a hearing in Singapore next month and another in Dublin in May. And it “does more than simply drive up costs: It means that Media Matters cannot focus its time and resources to mounting the best possible defense in one forum and must instead fight back piecemeal,” which allegedly prejudices MMFA’s “ability to most effectively defend itself.”
“Media Matters should not have to defend against attempts by X to hale Media Matters into court in foreign jurisdictions when the parties already agreed on the appropriate forum for any dispute related to X’s services,” MMFA’s complaint said. “That is—this Court.”
X still recovering from ad boycott
Although X CEO Linda Yaccarino started 2025 by signaling the X ad boycott was over, Ars found that external data did not support that conclusion. More recently, Business Insider cited independent data sources last month who similarly concluded that while X’s advertiser pool seemed to be increasing, its ad revenue was still “far” from where Twitter was prior to Musk’s takeover.
Nvidia has launched all of the GeForce RTX 50-series GPUs that it announced at CES, at least technically—whether you’re buying from Nvidia, AMD, or Intel, it’s nearly impossible to find any of these new cards at their advertised prices right now.
But hope springs eternal, and newly leaked specs for GeForce RTX 5060 and 5050-series cards suggest that Nvidia may be announcing these lower-end cards soon. These kinds of cards are rarely exciting, but Steam Hardware Survey data shows that these xx60 and xx50 cards are what the overwhelming majority of PC gamers are putting in their systems.
The specs, posted by a reliable leaker named Kopite and reported by Tom’s Hardware and others, suggest a refresh that’s in line with what Nvidia has done with most of the 50-series so far. Along with a move to the next-generation Blackwell architecture, the 5060 GPUs each come with a small increase to the number of CUDA cores, a jump from GDDR6 to GDDR7, and an increase in power consumption, but no changes to the amount of memory or the width of the memory bus. The 8GB versions, in particular, will probably continue to be marketed primarily as 1080p cards.
RTX 5060 Ti (leaked)
RTX 4060 Ti
RTX 5060 (leaked)
RTX 4060
RTX 5050 (leaked)
RTX 3050
CUDA Cores
4,608
4,352
3,840
3,072
2,560
2,560
Boost Clock
Unknown
2,535 MHz
Unknown
2,460 MHz
Unknown
1,777 MHz
Memory Bus Width
128-bit
128-bit
128-bit
128-bit
128-bit
128-bit
Memory bandwidth
Unknown
288 GB/s
Unknown
272 GB/s
Unknown
224 GB/s
Memory size
8GB or 16GB GDDR7
8GB or 16GB GDDR6
8GB GDDR7
8GB GDDR6
8GB GDDR6
8GB GDDR6
TGP
180 W
160 W
150 W
115 W
130 W
130 W
As with the 4060 Ti, the 5060 Ti is said to come in two versions, one with 8GB of RAM and one with 16GB. One of the 4060 Ti’s problems was that its relatively narrow 128-bit memory bus limited its performance at 1440p and 4K resolutions even with 16GB of RAM—the bandwidth increase from GDDR7 could help with this, but we’ll need to test to see for sure.
But it’s not really fair to compare yesterday’s 430i with this i4 xDrive40; with 395 hp (295 kW) and 442 lb-ft (600 Nm) on tap and a $62,300 MSRP, this EV is another rung up the price and power ladders.
The i4 uses BMW’s fifth-generation electric motors, and unlike most other OEMs, BMW uses electrically excited synchronous motors instead of permanent magnets. The front is rated at 255 hp (190 kW) and 243 lb-ft (330 Nm), and the rear maxes out at 308 hp (230 kW) and 295 lb-ft (400 Nm). They’re powered by an 84 kWh battery pack (81 kWh usable), which on 18-inch wheels is good for an EPA range of 287 miles (462 km).
Our test car was fitted with 19-inch wheels, though, which cuts the EPA range to 269 miles (432 km). If you want a long-distance i4, the single-motor eDrive40 on 18-inch wheels can travel 318 miles (511 km) between charges, according to the EPA, which offers an interesting demonstration of the effect of wheel size and single versus dual motors on range efficiency.
There’s a new design for the 19-inch M Aero wheels, but they’re part of a $2,200 package. Credit: Jonathan Gitlin
It’s very easy to switch between having the car regeneratively brake when you lift the throttle (in B) or just coast (in D), thanks to the little lever on the center console. (Either way, the car will regeneratively brake when you use the brake pedal, up to 0.3 G, at which point the friction brakes take over.) If you needed to, you could hit 62 mph (100 km/h) in 5.1 seconds from a standstill, which makes it quick by normal standards if not by bench racers. In practice, it’s more than fast enough to merge into a gap or overtake someone if necessary.
During our time with the i4, I averaged a little worse than the EPA numbers. The winter has been relatively mild as a result of climate change, but the weather remained around or below freezing during our week with the i4, and we averaged 3.1 miles/kWh (20 kWh/100 km). Interestingly, I didn’t notice much of a drop when using Sport mode, or much of a gain using Eco mode, on the same 24-mile mix of city streets, suburban arteries, and highways.
As a marker, before I began reading the post, I put down here: Yes. The claims that locking people up for longer periods after they are caught doing [X] does not reduce the amount of [X] that gets done, for multiple overdetermined reasons, is presumably rather Obvious Nonsense until strong evidence is provided otherwise.
The potential exception, the reason it might not be Obvious Nonsense, would be if our prisons were so terrible that they net greatly increase the criminality and number of crimes of prisoners once they get out, in a way that grows with the length of the sentence. And that this dwarfs all other effects. This is indeed what Roodman (Scott’s anti-incarceration advocate) claims. Which makes him mostly unique, with the other anti-incarceration advocates being a lot less reasonable.
In which case, yes, we should make dramatic changes to fix that, rather than arguing over sentence lengths, or otherwise act strategically (e.g. either lock people up for life, or barely lock them up at all, and never do anything in between?) But the response shouldn’t be to primarily say ‘well I guess we should stop locking people up then.’
Scott Alexander is of course the person we charge with systematically going through various studies and trying to draw conclusions in these spots. So here we are.
First up is the deterrence effect.
Scott Alexander: Rational actors consider the costs and benefits of a strategy before acting. In general, this model has been successfully applied to the decision to commit crime. Studying deterrence is complicated, and usually tries to tease out effects from the certainty, swiftness, and severity of punishment; here we’ll focus on severity.
According to every study and analysis I’ve seen, certainty and swiftness matter a lot, and indeed you get more bang for your buck on those than you do on severity past some reasonable point. The question on severity is if we’re reaching decreasing marginal returns.
A bunch of analysis mostly boils down to this:
I think all four of these studies are consistent with an extra year tacked on to a prison sentence deterring crime by about 1%. All studies start with significant prison sentences, and don’t let us conclude that the same would be true with eg increasing a one day sentence to a year-and-a-day.
Helland and Drago et al both suggest that deterrence effects are concentrated upon the least severe crimes. I think this makes sense, since more severe crimes tend to be more driven by emotion or necessity.
I would have predicted a larger effect than this, but it’s not impossible that once you’re already putting someone away for 5+ years you’ve already done most of the deterrence work you’re going to do via sentence length alone – if you thought you’d be caught and cared about your future you wouldn’t be doing it.
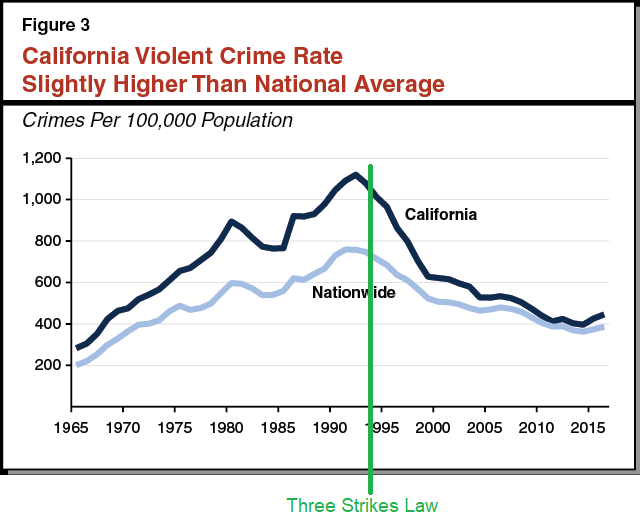
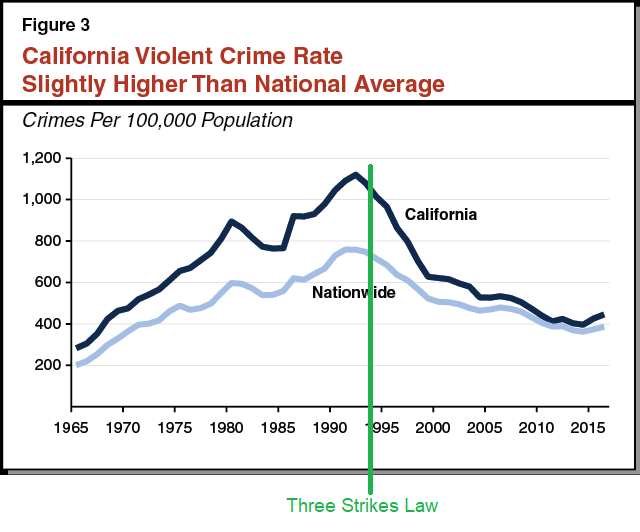
The incarceration effects, on the other hand, naively look rather huge. There’s strong evidence that a few people will constantly go around committing all the crime. If you lock up those doing all the crime, they stop doing the crime, and crime goes down. The math is clear. So why didn’t California’s three strikes law do more work?
If you credit three strikes with the change in relative crime for five years after the law was passed, you get a 7% drop, although ‘most criminologists suggest that even this is an overestimate, and the true number is close to zero.’
I actually think the 7% estimate looks low here. We see a general trend beforehand of California’s crime rate spiralling out of control, both in absolute and relative terms. It seems likely this trend had to be stalled before it was reversed, and the gap was essentially gone after a while, and other states were also going ‘tough on crime’ during that period, so the baseline isn’t zero.
So we expected Three Strikes to decrease crime by 83%, but in fact it decreased it by 0-7%. Why?
Because California’s Three Strikes law was weaker than it sounds: it only applied to a small fraction of criminals with three convictions. Only a few of the most severe crimes (eg armed robberies) were considered “strikes”, and even then, there was a lot of leeway for lenient judges and prosecutors to downgrade charges. Even though ~80% of criminals had been arrested three times or more, only 1–4% of criminals arrested in California were punished under the Three Strikes law.
Whereas a Netherlands 10-strike (!) law, allowing for much longer sentences after that, did reduce property crime by 25%, and seems like it was highly efficient. This makes a lot of sense to me and also seems highly justified. At some point, if you’re constantly doing all the crime, including property crime, you have to drop the hammer.
We are often well past that point. As Scott talks about, and this post talks about elsewhere (this was the last section written), the ‘we can’t arrest the 327 shoplifters in NYC who get arrested 20 times per year’ is indeed ‘we suck.’ This isn’t hard. And yes, you can say there’s disconnects where DAs say an arrest is deterrent enough whereas police don’t see a point to arresting someone who will only get released, but that doesn’t explain why we have to keep arresting the same people.
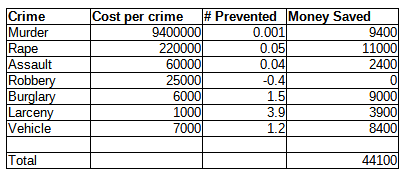
Analyses from all perspectives, that Scott looks at, agree that criminals as a group tend to commit quite a lot of crime, 7-17 crimes per year.
I also note that I think all the social cost estimates are probably way too low, because they aren’t properly taking into account various equilibrium effects.
That’s what I think happened in El Salvador, that Scott is strangely missing. The reason you got a 95% crime decrease is not some statistical result based on starting with lower incarceration rates. It is because before the arrests, the gangs were running wild, were de facto governments fighting wars while the police were powerless. Afterwards, they weren’t. It wasn’t about thinking on the margin.
Later on, Roodman attempts to estimate social costs like this:
Roodman uses two methods: first, he values a crime at the average damages that courts award to victims, including emotional damages. Second, he values it at what people will pay – how much money would you accept to get assaulted one extra time in your life?
These estimates still exclude some intangible costs, like the cost of living in a crime-ridden community, but it’s the best we can do for now.
These to me seem like they are both vast underestimates. I don’t think we can just say ‘best we can do’ and dismiss the community costs.
I would pay a lot to not be assaulted one time. I’d pay so much more to both not be assaulted, and also not to have the fear of assault living rent free in my head all the time (and for women this has to be vastly worse than that). And for everyone around me to also not having that dominate their thinking and actions.
So yeah, I find these estimates here rather absurdly low. If we value a life at $12 million when calculating health care interventions, you’re telling me marginal murders only have a social cost of $9.4 million? That’s crazy, murder is considered much worse than other deaths and tends to happen to the young. I think you have to at least double the general life value.
The rape number is even crazier to me.
Here’s Claude (no, don’t trust this, but it’s a sanity check):
Claude Sonnet 3.5: Studies estimating the total societal cost per rape (including both tangible and intangible costs) typically range from $150,000 to $450,000 in direct costs. When including long-term impacts and psychological harm, some analyses place the full societal cost at over $1 million per incident.
…
Total cost estimates per burglary typically range from $3,000 to $7,000 in direct costs, with comprehensive social cost estimates ranging from $10,000-$25,000 per incident when including psychological impact and system costs.
So yeah, I think even without norm and equilibrium effects these numbers are likely off by a factor of at least 2, and then they’re wrong by a lot again for those reasons.
Scott later points out that thinking on the margin gets confusing when different areas have different margins, and in some sense the sum of the margins must be the total effect, but some sort of multiple equilibrium (toy) model seems closer to how I actually think about all this.
The aftereffects of imprisonment forcing or leading people deeper into crime is the actual counterargument. And as Scott points out, it’s crazy to try and claim that the impact here is zero:
As far as I can tell, most criminologists are confused on this point. They’re going to claim that the sign of aftereffects is around zero, or hard to measure – then triumphantly announce that they’ve proven prison doesn’t prevent crime.
If the effect here is around zero, one that’s quite the coincidence, and two that would mean prison reduces crime. The actual argument that prison doesn’t reduce crime, that isn’t Obvious Nonsense, is if the aftereffects are very large and very negative.
Here’s one study that definitely didn’t find that.
Scott then says there are tons of other studies and it’s all very complicated. There’s lots of weirdness throughout, such as Berger saying everyone pleading guilty means a ‘unusual study population’ despite essentially everyone pleading guilty in our system.
Roodman not only concludes that longer sentences increase crime after, but that harsher ones also do so, while saying that effects at different times and places differ.
Another suggestion is that perhaps modest sentences (e.g. less than two years) are more relatively disruptive versus incentivizing, and thus those in particular make things worse. That doesn’t seem impossible, but also the incentive effects on the margin here seem pretty huge. You need to be disruptive, or where is the punishment, and thus where is the deterrence? Unless we have a better idea?
Given the importance of both swiftness and certainty, a strategy of ‘we won’t do much to you until we really do quite a lot to you’ here would be even worse than the three strikes law.
I mean, I can think of punishments people want to avoid, but that aren’t prison and thus won’t cost you your job or family… but we’ve pretty much decided to take all of those off the table?
In general, I’ve taken to finding Scott’s ‘let’s look at all the studies’ approach to such questions to be increasingly not how I think about questions at all. Studies aren’t the primary way I look for or consider evidence. They’re one source among many, and emphasizing them this much seems like a cop out more than an attempt to determine what is happening.
I do agree broadly with Scott’s conclusions, of:
More incarceration net reduces crime.
We have more cost-effective crime reduction options available.
It would be cost effective to spend more on crime reduction.
To that I would add:
More incarceration seems net beneficial at current margins, here, because the estimates of social cost of (real, non-victimless) crime are unreasonably low even without equilibrium effects, and also there are large equilibrium effects.
We have additional even more effective options, but we keep not using them.
Some of that is ‘not ready for that conversation’ or misplaced ethical concerns.
Some of that is purely we’re bad at it.
We should beware medium-sized incarceration periods (e.g. 1-3 years).
Most importantly: Our current prison system is really bad in that many aspects cause more crime after release rather than less, and the low hanging fruit is fixing this so that it isn’t true.
At minimum, we absolutely should be funding the police and courts sufficiently to investigate crimes properly, arrest everyone who does crimes on the regular (while accepting that any given crime may not be caught), and to deal with all the resulting cases.
And of course we should adjust the list of crimes, and the punishments, to match that new reality. Otherwise, we are burning down accumulated social capital, and I fear we are doing it rather rapidly.
It starts with comments about criminal psychology, which I found both fascinating and depressing. If prospective criminals don’t care about magnitude of risks only certainty of risk and they’re generally not competent to stay on the straight and narrow track and make it work, and they often don’t even see prison as worse than their lives anyway, you don’t have many options.
The obvious play is to invest bigly in ensuring you reliably catch people, and reduce sentences since the extra time isn’t doing much work, which is consistent with the conclusions above but seems very hard to implement at scale. Perhaps with AI we can move towards that world over time?
I very much appreciated Scott’s response to the first comment, which I’ll quote here:
Jude: This . . . matches my experience working with some low-income boys as a volunteer. It took me too long to realize how terrible they were at time-discounting and weighing risk. Where I was saying: “this will only hurt a LITTLE but that might RUIN your life,” they heard: “this WILL hurt a little but that MIGHT ruin your life.” And “will” beats “might” every time.
One frustrating kid I dealt with drove without a license (after losing it) several times and drove a little drunk occasionally, despite my warnings that he would get himself in a lot of trouble. He wasn’t caught and proudly told me that I was wrong: nothing bad happened, whereas something bad definitely would have happened if he didn’t get home after X party. Surprise surprise: two years later he’s in jail after drunk driving and having multiple violations of driving without a license.
Scott Alexander: The “proudly told me that I was wrong – nothing bad happened” reminds me of the Generalized Anti-Caution Argument – “you said we should worry about AI, but then we invented a new generation of large language model, and nothing bad happened!” Sometimes I think the difference between smart people and dumb people is that dumb people make dumb mistakes in Near Mode, and smart people only make them in Far Mode – the smarter you are, the more abstract you go before making the same dumb mistake.
Yep. We need to figure out a better answer in these situations. What distinguishes situations where someone can understand ‘any given time you do this is probably net positive but it occasionally is massively terrible so don’t do it’ from ‘this was net positive several times so your warnings are stupid?’
There was some hopefulness, in this claim that the criminal class does still care about punishment magnitude, and about jail versus prison, as differing in kind – at some point the punishment goes from ‘no big deal’ to very much a big deal, and plea bargains reflect that. Which suggests you either want to enforce the law very consistently, or you want to occasionally go big enough to trigger the break points. But then the next comment says no, the criminals care so little they don’t even know what their punishments would be until they happen.
These could be different populations, or different interpretations, but mostly this seems like a direct contradiction. None of this is easy.
Another Silicon Valley investor is getting into the rocket business.
Former Google chief executive Eric Schmidt has taken a controlling interest in the Long Beach, California-based Relativity Space. The New York Times first reported the change becoming official, after Schmidt told employees in an all-hands meeting on Monday.
Schmidt’s involvement with Relativity has been quietly discussed among space industry insiders for a few months. Multiple sources told Ars that he has largely been bankrolling the company since the end of October, when the company’s previous fundraising dried up.
It is not immediately clear why Schmidt is taking a hands-on approach at Relativity. However, it is one of the few US-based companies with a credible path toward developing a medium-lift rocket that could potentially challenge the dominance of SpaceX and its Falcon 9 rocket. If the Terran R booster becomes commercially successful, it could play a big role in launching megaconstellations.
Schmidt’s ascension also means that Tim Ellis, the company’s co-founder, chief executive, and almost sole public persona for nearly a decade, is now out of a leadership position.
“Today marks a powerful new chapter as Eric Schmidt becomes Relativity’s CEO, while also providing substantial financial backing,” Ellis wrote on the social media site X. “I know there’s no one more tenacious or passionate to propel this dream forward. We have been working together to ensure a smooth transition, and I’ll proudly continue to support the team as Co-founder and Board member.”
Terran R’s road to launch
On Monday, Relativity also released a nearly 45-minute video that outlines the development of the Terran R rocket to date and the lengths it must go to reach the launch pad. Tellingly, Ellis appears only briefly in the video, which features several other senior officials who presumably will remain with the company, including Chief Operating Officer Zach Dunn.
Pedro Pascal returns as Joel in The Last of Us S2.
HBO released a one-minute teaser of the hotly anticipated second season of The Last of Us—based on Naughty Dog’s hugely popular video game franchise—during CES in January. We now have a full trailer, unveiled at SXSW after the footage leaked over the weekend, chock-full of Easter eggs for gaming fans of The Last of Us Part II.
(Spoilers for S1 below.)
The series takes place in the 20-year aftermath of a deadly outbreak of mutant fungus (Cordyceps) that turns humans into monstrous zombie-like creatures (the Infected, or Clickers). The world has become a series of separate totalitarian quarantine zones and independent settlements, with a thriving black market and a rebel militia known as the Fireflies making life complicated for the survivors. Joel (Pedro Pascal) is a hardened smuggler tasked with escorting the teenage Ellie (Bella Ramsay) across the devastated US, battling hostile forces and hordes of zombies, to a Fireflies unit outside the quarantine zone. Ellie is special: She is immune to the deadly fungus, and the hope is that her immunity holds the key to beating the disease.
S2 is set five years after the events of the first season and finds the bond beginning to fray between plucky survivors Joel and Ellie. That’s the inevitable outcome of S1’s shocking finale, when they finally arrived at their destination, only to discover the secret to her immunity to the Cordyceps fungus meant Ellie would have to die to find a cure. Ellie was willing to sacrifice herself, but once she was under anesthesia, Joel went berserk and killed all the hospital staff to save her life—and lied to Ellie about it, claiming the staff were killed by raiders.
A 55-year-old software developer faces up to 10 years in prison for deploying malicious code that sabotaged his former employer’s network, allegedly costing hundreds of thousands of dollars in losses.
The US Department of Justice announced Friday that Davis Lu was convicted by a jury after “causing intentional damage to protected computers” reportedly owned by the Ohio- and Dublin-based power management company Eaton Corp.
Lu had worked at Eaton Corp. for about 11 years when he apparently became disgruntled by a corporate “realignment” in 2018 that “reduced his responsibilities,” the DOJ said.
His efforts to sabotage their network began that year, and by the next year, he had planted different forms of malicious code, creating “infinite loops” that deleted coworker profile files, preventing legitimate logins and causing system crashes, the DOJ explained. Aiming to slow down or ruin Eaton Corp.’s productivity, Lu named these codes using the Japanese word for destruction, “Hakai,” and the Chinese word for lethargy, “HunShui,” the DOJ said.
But perhaps nothing was as destructive as the “kill switch” Lu designed to shut down everything if he was ever terminated.
This kill switch, the DOJ said, appeared to have been created by Lu because it was named “IsDLEnabledinAD,” which is an apparent abbreviation of “Is Davis Lu enabled in Active Directory.” It also “automatically activated” on the day of Lu’s termination in 2019, the DOJ said, disrupting Eaton Corp. users globally.
SpaceX has long had a hard-charging culture. Is it now charging too hard?
File photo of a Falcon 9 launch from Vandenberg Space Force Base, California. Credit: SpaceX
It has been an uncharacteristically messy start to the year for the world’s leading spaceflight company, SpaceX.
Let’s start with the company’s most recent delay. The latest launch date for a NASA mission to survey the sky and better understand the early evolution of the Universe comes Monday night. The launch window for this SPHEREx mission opened on February 28, but a series of problems with integrating the rocket and payloads have delayed the mission nearly two weeks.
Then there are the Falcon 9 first stage issues. Last week, a Falcon 9 rocket launched nearly two dozen Starlink satellites into low-Earth orbit. However, one of the rocket’s nine engines suffered a fuel leak during ascent. Due to a lack of oxygen in the thinning atmosphere, the fuel leak did not preclude the satellites from reaching orbit. But when the first stage returned to Earth, it caught fire after landing on a droneship, toppling over. This followed a similar issue in August, when there was a fire in the engine compartment. After nearly three years without a Falcon 9 landing failure, SpaceX had two in six months.
SpaceX has also experienced recent and recurring problems with the Falcon 9 rocket’s expendable upper stage. On February 1, a second stage deorbit burn failed after a Starlink launch. This led to propellant tanks from the stage crashing into western Poland, causing property damage but harming no one. It was the third time in six months that SpaceX had encountered an issue with the Falcon 9 second stage.
Although the vehicle’s first stage performed nominally during test flights in January and March, returning safely to its launch site, the Starship upper stage exploded spectacularly in flight twice. On both occasions, a fire developed in the engine section of Starship, and the vehicle rained fiery debris trails over the Bahamas and other nearby islands. Air traffic controllers diverted or delayed dozens of commercial airline flights flying through the debris footprint.
Putting this into perspective
These issues have occurred against the backdrop of a largely successful and unprecedented launch performance.
For all of the problems described earlier, the company’s only operational payload loss was its own Starlink satellites in July 2024 due to a second stage issue. Before that, SpaceX had not lost a payload with the Falcon 9 in nearly a decade. So SpaceX has been delivering for its customers in a big way.
SpaceX has achieved a launch cadence with the Falcon 9 rocket that’s unmatched by any previous rocket—or even nation—in history. If the SPHEREx mission launches tonight, as anticipated, it would be the company’s 27th mission of this year. The rest of the world combined, including China and its growing space activity, will have a total of 19 orbital launch attempts.
In the United States, SpaceX’s historic launch competitor, United Launch Alliance, has yet to fly a single rocket this year. In fact, the company has not launched in 156 days. During that time, SpaceX has launched 64 Falcon 9 rockets. So yes, SpaceX has had some technical issues. But it is also flying circles around its competition.
The recent failures are also unlikely to jeopardize, at least in the near term, SpaceX’s globally dominant position. The company provides the Western world’s only human access to orbit, and that’s unlikely to change for a while. SpaceX launches the vast majority of NASA’s science missions, and until United Launch Alliance’s Vulcan rocket becomes certified, it remains the US military’s only way to get larger payloads into space. The company also operates a global Internet network with more than 5 million users, and that number is growing rapidly.
All the same, these recent failures may be telling us something about SpaceX.
What is causing this
Without being inside SpaceX, it is impossible to put a fine point on what precisely is happening to cause these technical issues.
Probably the most significant factor is the company’s ever-present pressure to accelerate, even while taking on more and more challenging tasks. No country or private company ever launched as many times as SpaceX did in 2024. By way of comparison, NASA launched the Space Shuttle 135 times, a comparable number to the total of Falcon 9 launches last year (132), over a 30-year period.
At the same time, the company has been attempting to move its talented engineering team off the Falcon 9 and Dragon programs and onto Starship to keep that ambitious program moving forward.
To put it succinctly, SpaceX is balancing a lot of spinning plates, and the company’s leadership is telling its employees to spin the plates faster and faster.
Multiple sources have indicated that the Starship engineering team was under immense pressure after the January 16 failure to identify the cause of a “harmonic response” in the vehicle’s upper stage that contributed to its loss. The goal was to find and fix the problem as quickly as possible.
Let’s step back and appreciate that Starship is an experimental system, by far the largest and most powerful rocket ever flown, and it catastrophically failed in January. During a span of just seven weeks, the Starship team had to study the failure, address any problems, and prepare new hardware.
How much of this is on SpaceX founder Elon Musk? Some have suggested his deep involvement in the 2024 presidential election, oversight of the Department of Government Efficiency, excessive social media activity, and more—like picking fights with US senators— have distracted him from the problems of SpaceX. And there’s no doubt that Musk has been focused on things other than SpaceX for the last half-year or longer.
However, in Musk’s absence, he has capable lieutenants such as Mark Juncosa leading the way. SpaceX has long had a hard-charging culture instilled by Musk since the founding of the company. Musk’s modus operandi is to push his teams to reach some ambitious goal, and when they do, he sets a new, even more audacious target. It may be not so much Musk’s absence that is causing these issues but rather the company’s relentless culture.
It seems possible that, at least for now, SpaceX has reached the speed limit for commercial spaceflight. When you’re launching 150 times a year and building two second stages a week, it’s hard to escape the possibility that some details are slipping through the cracks. And it’s not just the launches. SpaceX is operating a constellation of more than 7,000 satellites, flying humans into space regularly, and developing an unprecedented rocket like Starship.
The recent failures may be signs of cracks in the foundation.
What are the implications
So far, the consequences of these failures have not been lethal. But space remains a difficult, hazardous game. Reentering debris from a Falcon 9 upper stage could have struck someone in Poland. God forbid, a second stage could fail early in a crewed mission.
The risks of serious problems with Starlink should not be understated, either. There have been unconfirmed rumors in recent months of near misses between Starlink satellites and objects in low-Earth orbit. Additional debris in this increasingly cluttered space would be disastrous.
To date, the Falcon 9 rocket program has not been slowed down by these issues. It’s perhaps not fully appreciated how utterly reliant NASA’s human spaceflight activities are on the Falcon 9. It currently launches the only crew-capable vehicle in Dragon. However, a Cargo version of Dragon also flies on the Falcon 9, and this is NASA’s only way to get scientific experiments back to Earth. And for at least the next year, the only other US cargo vehicle, Northrop Grumman’s Cygnus, also must launch on the Falcon 9.
Not just NASA, but every other space station partner outside of Russia, depends on the Falcon 9 for human spaceflight activities. The rocket must fly, and fly safely, or the West will be grounded.
With Starship, the recent failures are a significant setback. Although there will no doubt be pressure from SpaceX leadership to rapidly move forward, there appears to be a debilitating design flaw in the upgraded version of Starship. It will be important to understand and address this. Another launch before this summer seems unlikely. A third consecutive catastrophic failure would be really, really bad.
For the space agency’s Artemis program to return humans to the Moon, Starship’s problems spell more delays. Musk had already signaled in late February that a critical refueling demonstration will now not happen this year. This test is an essential milestone on the path to the Moon, and its delay all but ensures the first lunar landing will not happen in 2027 as currently envisioned.
Most likely, the back-to-back Starship failures will also cement the path forward for Artemis II and Artemis III to fly as planned, with crews flying on the Space Launch System rocket and Orion spacecraft.
As for Mars, the red planet remains in the far distance, waiting for SpaceX to address its red flags here on Earth.
Eric Berger is the senior space editor at Ars Technica, covering everything from astronomy to private space to NASA policy, and author of two books: Liftoff, about the rise of SpaceX; and Reentry, on the development of the Falcon 9 rocket and Dragon. A certified meteorologist, Eric lives in Houston.