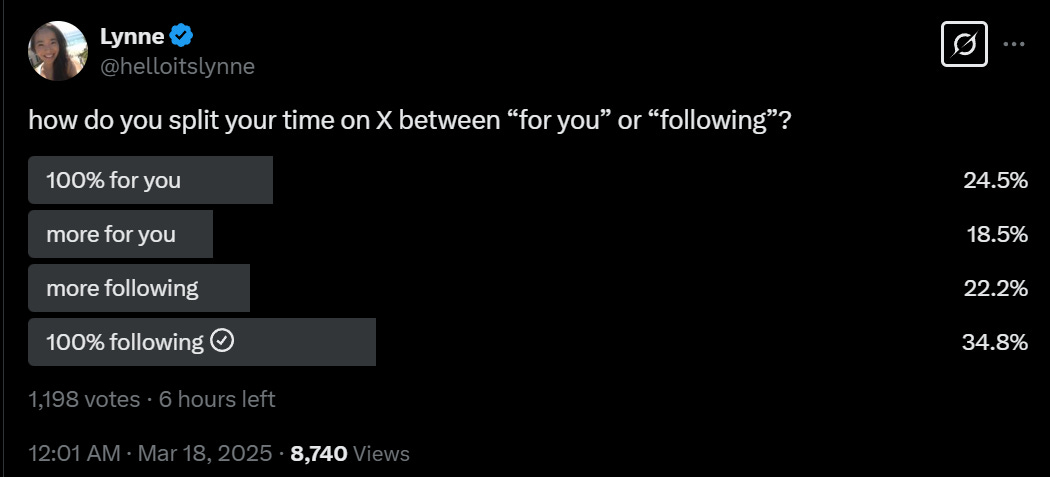In Monthly Roundup #28 I made clear I intend to leave the Trump administration out of my monthly roundups, for both better and worse, outside of my focus areas. Again, this does not mean I don’t have a lot to say or that those questions don’t matter. It means you should not rely on me as your only source of news and I pick my battles.
They are not making this easy.
I am going to stick to my guns. Trade and trading very much inside my focus areas, but for economics roundups, and in extreme cases AI roundups. Besides, you don’t need me to tell you that tariffs not only impose immense economic costs but also fail to achieve their primary policy aims and foster political dysfunction along the way. That question should already be answered by my t-shift. I do have a word about things related to a potential expansion (I can’t believe I’m typing this!) of the Jones Act. And I’ll deal with certain crime-related things when I do my first crime roundup.
-
Bad News.
-
Antisocial Media.
-
Technology Advances.
-
Variously Effective Altruism.
-
Government Working.
-
Jones Act Watch.
-
While I Cannot Condone This.
-
Architectural Musings.
-
Quickly, There’s No Time.
-
Don’t Sell Your Soul, You Won’t Get Paid.
-
What To Do Instead.
-
Good News, Everyone.
-
We’re Elite, You’re Not.
-
Enjoy It While It Lasts.
-
For Your Entertainment.
-
An Economist Gets Lunch.
-
I Was Promised Flying Self-Driving Cars and Supersonic Jets.
-
Gamers Gonna Game Game Game Game Game.
-
Sports Go Sports.
-
The Lighter Side.
23andMe is going into bankruptcy. It would seem a wise precaution to download and then delete your data if it’s there, which takes a few days to do, in case the data falls into the wrong hands or is lost forever.
Young men who make 9 figures by default get driven crazy, all checks and balances on them now gone.
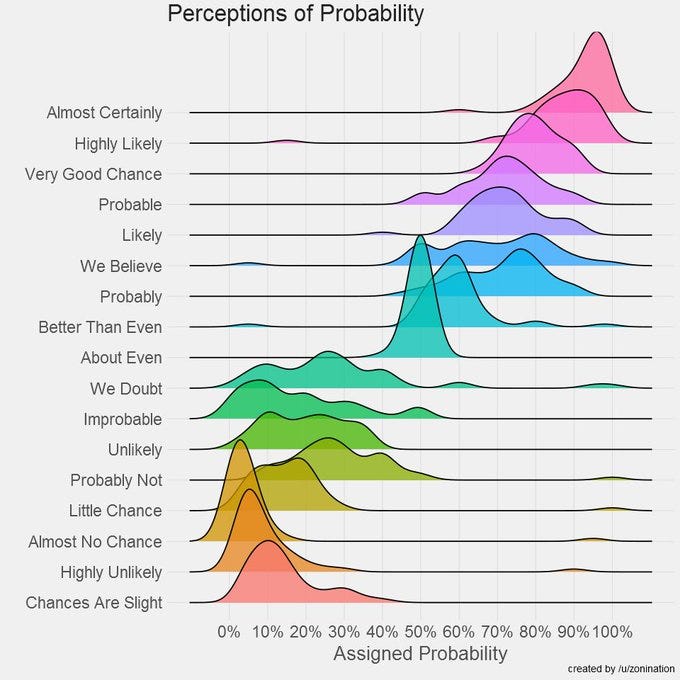
This graphic is quite good.
That’s a variation on this classic, worth revisiting periodically as a reminder:
A claim that banning smoking in bars increases alcohol consumption by ~5% without decreasing smoking. I presume the increased alcohol consumption is because the bar became a much better experience without all the smoking? It seems bizarre that this wouldn’t decrease smoking, especially over the long term.
Beware communities that encourage irresponsible risk taking and dismiss those who do not endanger themselves. It can be good if targeted well: There are places, like founding startups and putting yourself out there for romance, where people take far too little risk and it is often good to encourage people to take more. But this very much doesn’t apply to, for example, talk about financial investments.
If you use Twitter via the For You page, You Fool. Yet many of you do exactly that.
I even hear people complaining about ‘the algorithm’ without doing the obvious and switching to chronological feeds and lists. That’s on you.
As far as I know this is the size-adjusted record, yes, and well earned.
Kelsey Piper suggests Twitter’s conversational meta favors long tweets because they attract thoughtful people, plus you get the bonus of QTs saying tldr. That hasn’t been my experience, but I also try to have those conversations elsewhere.
Twitter is restricting the ability to see who other people are following. This is not obviously bad. I would like to be able to follow people without worrying about what it looks like. In practice I don’t care but there are people for whom this matters.
A great question, why is there such huge variance in self-checkout system quality? We have essentially solved self-checkout technology yet half of stores have multiple employees whose job is to fix errors because their terrible software doesn’t work. So yeah, diffusion can be hard.
I don’t want to zipline, unless it’s this zipline:
Ryan Peterson: While everyone in business is busy losing their minds about tariffs, @zipline just quietly launched a logistics revolution in Dallas, TX. You can now get anything at a Walmart delivered to your front door by drone, with a flight time under 2 minutes for most orders.
@DanielLurie We gotta legalize drone delivery in San Francisco.
If you live in Dallas download the app here and starting buying stuff from Walmart before the prices go up!
Nearcyan rants about how awful the developer experience is on Google Play, someone from Google reaches out and the related problems get instantly solved. This can directly be linked to Google’s incentive structures not rewarding anyone for making existing products work properly.
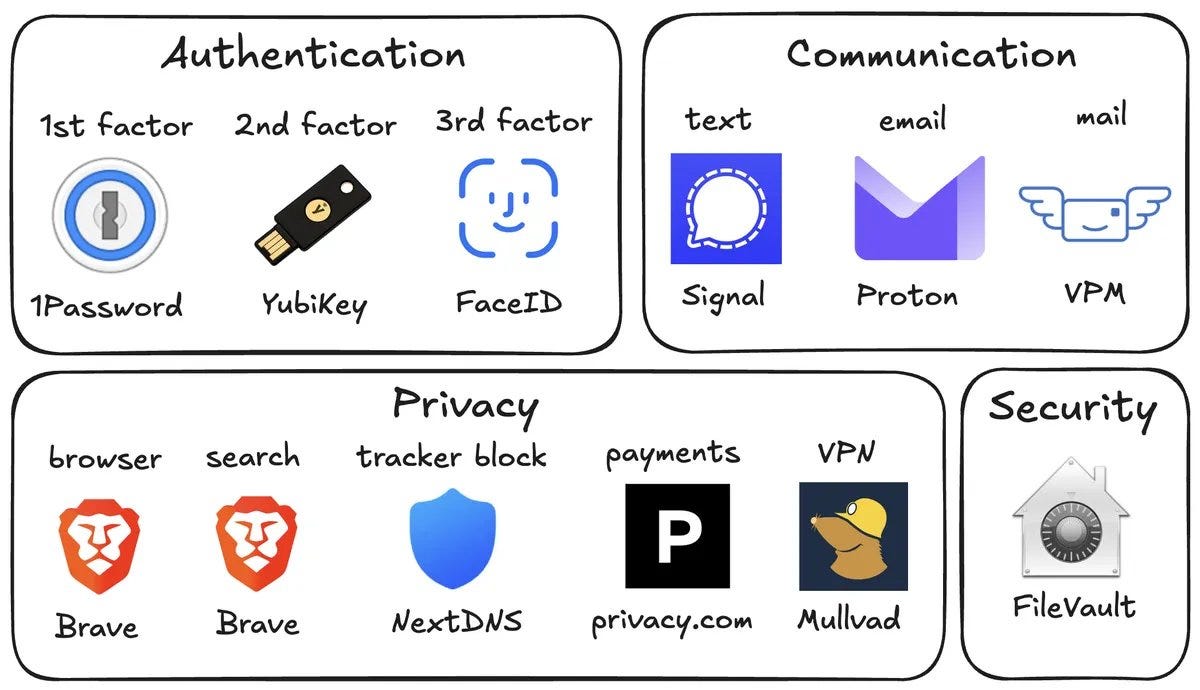
Andrej Karpathy provides ‘no-brainer’ suggestions for personal security, such as having a distinct credit card for every online transaction and using a virtual mail service.
The full agenda he spells out as the baseline minimum seems like an obviously massive overkill level of security for almost anyone. What is Andrej’s hourly rate? Some of this is worthwhile, but as Patrick McKenzie reminds us, the optimal rate of fraud is not zero.
It actually did make me feel better about Signal until everyone saying that caused me to learn about all the ways various other apps compromising your phone can also compromise Signal.
Alice Maz: the good part of the signal leak is it implies a bunch of people with ts/sci access don’t know anything we don’t that would make them distrust signal.
My current model is that Signal is the best low-effort secure communication method, but not on its own good enough that you should assume that using Signal on a normal phone is an actually secure communication method against someone who cares.
Signulll warns against artificial scarcity. I am a lot less skeptical.
Signulll: one of the most common mistakes in product thinking is the belief that you can reintroduce artificial scarcity to improve something that has already been made abundant—especially by the internet (& the internet makes almost everything feel abundant). after people have experienced the infinite, you can’t shove them into a box & expect them to enjoy it. the brain doesn’t forget oxygen.
this shows up in products that add fake constraints: one post a day, one profile at a time, one action per hour. the assumption is that limiting access will restore value or mystery. it doesn’t. once the user has tasted abundance, constraint doesn’t feel elegant or intentional—it feels broken. worse, it feels patronizing.
artificial scarcity almost never works unless it’s intrinsic to the product. you either have to make abundance feel valuable (curated, contextual, high signal), or find a new mechanic entirely. nostalgia for constraint is not strategy. it’s just denial of the current physics of the medium.
this is an extension to this. i see this type of thinking all the time, particularly when people who are frustrated at the current dynamics of any given network (e.g. a dating app etc.)
Nogard: Agree and great point. Modern dating apps unleashed an irrational level of abundance and optionality—so much that it bled into the physical world, warping its constraints. You can’t trick anyone with artificial scarcity; they’ve already tasted the forbidden fruit. It’s like trying to enjoy tap water after a decade of chugging Monster Energy.
Games, especially free mobile games, are chocked full of artificial scarcity. For the most successful games, everything is limited or on a timer. People find this highly addictive. They eat it up. And often they also pay quite a lot to get around those restrictions, that’s often the entire business model. So there’s a big existence proof.
What games try to do is justify the artificial scarcity. When this is done well it works great. So the question now becomes, can you make the artificial scarcity fun and interesting? Can you make it addictive, even? A maximization problem of sorts? Or tie it into your ‘game mechanics’?
I think you absolutely can do all that in many cases, including in dating apps.
First of all, limited actions really do restore value to that action. The frictions and value this introduces can do many useful things. The ideal friction in many cases is money, the amounts can be quite small and refundable and still work. But in cases where you cannot use money, and there are many good reasons to not want to do that, using an artificially scarce currency seems great?
If I was dating, I would rather be on a dating app where I can only match once a day and those I match with know this, than one in which I don’t have that restriction.
Scott Alexander can’t let go of the drowning child argument, going highly technical around various details of hypothetical variations in remarkably dense fashion without seeming that actually interested in what is centrally going on.
Kelsey Piper discusses the administrative nightmare that is trying to use your home to do essentially anything in America. There is no reason for this. If people could easily run microschools and tea shops out of their homes America would be a much better place.
Massachusetts bans heavy-duty truck sales until the trucks can go electric.
Claim that TSA employees are actively happy about the attacks on their union, because the union was preventing the purging of bad actors. I wouldn’t have predicted this, but it shouldn’t be discounted as a possibility. Many comments confirmed that this has recently improved the TSA experience quite a bit. Yes, we shouldn’t need the service they provide, but we’ve decided that we do so better to do a decent job of it.
RFK Jr. proposes banning cell phones in schools… because of the ‘electric magnetic radiation’ he hallucinates they give off.
Jesse Singal: hopefully just the start of RFK Jr making good proposals for hilarious reasons
“We should promote whole grains, because the Illuminati has a stranglehold on processed carbs”
“Everyone should get 30 mins of exercise a day to stay a few steps ahead of your own shadow-daemon”
A word of warning, in case you think the tariffs were not great, that we might be about to not only not repeal the Jones Act but to do things that are vastly worse:
Ryan Peterson: On April 17th the U.S. Trade Representative’s office is expected to impose fees of up to $1.5M per port call for ships made in China and for $500k to $1M if the ocean carrier owns a single ship made in China or even has one on order from a Chinese shipyard.
Ocean carriers have announced that to reduce the fees they will skip the smaller ports like Seattle, Oakland, Boston, Mobile, Baltimore, New Orleans, etc. Some carriers have said they’ll just move the capacity serving the U.S. to other trade lanes altogether.
This would be horrible for jobs in and around those ports, and really bad for companies, both importers and exporters, using those ports. Huge extra costs will be incurred as trucks and trains run hundreds of extra miles to the main ports on each cost.
Similarly the major ports (LA, Long Beach, Houston, and New York) will be unable to keep up with the flood of extra volumes and are likely to become congested, similar to what we saw during Covid.
The craziest part of the original proposal is a requirement that within 7 years 15% of U.S. exports must travel on a ship that’s made in America and crewed by Americans.
There are only 23 of American made and crewed container ships in the world today, and they all service domestic ocean freight (Alaska, Hawaii, Guam, Puerto Rico, etc). They’re all tiny compared to today’s mega ships, and they’re not even sailing to overseas ports.
The U.S. did not produce any container ships in 2024. And the number we produce in any given year rounds to zero. The reason is that American made container ships of 3,000 TEUs cost the same price as the modern container ships from China of 24,000 TEUs.
Colin Grabow: The last time a US shipyard built Suezmax tankers (2004-2006) the price was $210 million each. Now we’re apparently at $500 million with a 6x delta versus the foreign price.
The Jones Act is caught in a vicious circle. Costs spiral, leading to lowered demand for new ships, which drives costs even higher. There’s very little appetite for ships at these prices. The law is self-destructing.
The full proposal to require US ships would drastically reduce American exports (and even more drastically reduce American imports). As in, we’d have to go without most of them, for many years. There’s no way to quickly ramp up our shipyards sufficiently for this task, even if price was not a factor. The port of call fees are a profoundly terrible idea, but the ship origin requirements are riot-in-the-streets-level terrible.
The rhetoric is largely about Chinese-built vessels being terrible or a security risk. Even if one buys that, what one could do, both here and for the original Jones Act, is simply to restrict the specific thing you don’t like: Chinese-built, Chinese-flagged or Chinese-owned ships. Or even require the ships come from our allies. It wouldn’t be a free action, but we could substitute into Japanese, South Korean or European ships. Whereas if you demand American ships? They don’t exist. And having 100 years of such restrictions domestically has only ensured that.
It seems highly reasonable to be confused as to why this happened:
Maxwell Tabarrok: This is actually pretty confusing to me. The Jones Act should be a subsidy to domestic shipbuilding but the industry is completely dead.
I’ve written before that this might happen when protection creates a domestic monopoly, but I’m not so convinced by my own explanation.
The answer is that when you create a domestic monopoly or oligopoly without export discipline, you allow domestic industry to not compete on the international market, and instead they find it more profitable to service only the domestic protected market. We can’t compete on the international market even if we want to, because others offer large subsidizes and are already more efficient in various ways, so no one wants our ships and we can’t use that to improve or scale.
Unfortunately, the domestic market is not large enough to generate robust competition that creates reasonably priced ships, which decreases demand and causes shipbuilders to get less competitive still, pushing prices even higher, until the point where domestic ships are so expensive that more than a handful of Jones Act ships aren’t profitable. So at the end of the death spiral, we don’t make them anymore.
If you decide we need a domestic shipbuilding industry, there is a known playbook in these spots, which is to offer large subsidies and also enforce export discipline, as for example South Korea did during its development. No one seems to want to do that.
A discussion about many things, but the later more interesting part is about dealing with cognitive decline. In particular, a sadly common pattern is that you have someone who used to be unusually intelligent and capable. Then, for a variety of reasons including getting older and a toxic information and reward environment, and because having to ‘act dumb’ in various ways actually makes you dumb over time, and often probably drug use, they lose a step, and then they lose another step.
Now they are still well above average for intelligence and capability, but their self-image and habits and strategies are designed for their old selves. So they take on too much, in the wrong ways, and lose the thread.
Tantum has a mostly excellent thread about the difference between a rival and an enemy, or between positive-sum rivalry and competition versus zero-sum hostility, although I disagree with the emphasis he chosen for the conclusion.
Megan McArdle reminds us that Levels of Friction are required elements of many of civilization’s core systems, and without sufficient frictions, those systems break.
Dilan Esper: i think people don’t realize the extent to which easier and cheaper travel, the Internet, and fake asylum applications have wrecked the international asylum system carefully built after the Holocaust. Poland is a particularly sobering indicator of this.
Megan McArdle: We underestimate how many policies are only feasible because various frictions prevent abuse. When the frictions are lubricated, the policies collapse.
Alex Tabarrok asks, if we were confident Covid-19 was a lab leak, what then? His first conclusion is we should expect more pandemics going forward. That’s not obvious to me, because it means less natural pandemics and higher risk of lab-originated pandemics. It is within our power to prevent lab-originated pandemics but not natural pandemics, and indeed Alex’s core suggestions are about ensuring that we at least do our research under sufficiently safe conditions – I’d prefer that we not do it at all. Note that Alex would be right about expectations if we already had confidence in the rate of natural pandemics, but I think we largely don’t know and it may be changing.
The kind of study one instinctively assumes won’t replicate says that those who believe in the malleability specifically of beauty will therefore take more risk, as in if you give people articles showing this then they’ll take more risk, but malleability of intelligence doesn’t have the same impact. The theory is that this is mediated through optimism?
Matt Lakeman asks, quite literally from a real example: How Much Would You Need to be Paid to Live on a Deserted Island for 1.5 Years and Do Nothing but Kill Seals? Plus another year in transit to boot. He estimated $2-4 million, and the real workers were clearly paid far less. But that’s the thing about such jobs – you don’t have to pay anything like what the median person would need to take the job. Someone will do it for a lot less than that, and I’m guessing the median young person would come in well under $2 million already.
The ‘vibe shift’ arrives at Princeton, and certainly on Twitter.
Paul Graham: If Princeton students think the “vibe shift” is real, it is, because if it has reached them, it has reached pretty much everyone.
I don’t buy that this means it has reached everyone. The Ivies and Twitter are both places where the future is more highly distributed, that respond more to vibe shifts. It would make perfect sense for such places to feel a vibe shift, while students at (let’s say) Ohio State or other residents of Columbus felt relatively little change.
Are Monte Carlo algorithms hacks to be avoided? They are hacks, and randomization is dangerous, this is true. But sometimes, they’re the only way to get an estimate given the amount of complexity. There is also an underused variation, which I call the Probability Map. This is where you can simplify the set of relevant considerations sufficiently that you can track the probability of every possible intermediate state. To work this usually requires not caring about path dependence, but this simplification is more accurate more often than you would think.
A cool note from Christopher Alexander, I’m still a little bummed I never got to properly review A Pattern Language and it’s probably too late now.
A Pattern Language:
179. Alcoves
180. Window Place
181. The Fire
185. Sitting Circle
188. Bed Alcove
191. The Shape of Indoor Space
205. Structure Follows Social Spaces
A Time to Keep: “Make bedrooms small, and shared spaces big.” – CA
If you want a family to be together, don’t isolate them in giant bedrooms. Draw them toward the hearth, the table, the common room.
I keep my bedroom large, but that is because I work and exercise there. The isolation effect is intentional in those spots. In general, you want the bedroom to be the minimum size to accomplish its specific goals, and to spend the rest of your space on the common areas.
We definitely need a word for this. Claude suggested ‘attention saturation’ or ‘bid overflow’ but they’re two words and also not quite right.
Nick Cammarata: I’m surprised we don’t have a word for the shift when the bids for your time goes above your supply for time vs before, it feels like a pretty fundamental life shift where it changes your default mode of operation.
like if you get 200 bids for your time a week vs 2 the set of things you need to do to thrive are pretty different, different risks and ways to play your hand, need to defend energy in new ways
it ofc depends on your psychology too, you might be built to handle X amount of bids per week, it’s less about the absolute amount of bids and more the ratio of bids to what you can easily handle.
I’ve gone through this a number of times. I have a system where I determine how to allocate time, and how to respond to bids for time, both from people and from things. Then suddenly you realize your system doesn’t work, quickly, there’s no time. There needs to be a substantial shift and a lot of things get reconsidered.
I kind of want to call this a ‘repricing,’ or for full a Time Repricing Event? As with other things, you have menu costs, so you only want to reprice in general when things are sufficiently out of whack.
My experience matches Kelsey Piper’s here.
Kelsey Piper: every single time I have witnessed people decide to compromise on character and overlook major red flags because ‘hey, he’s good at winning’, they have regretted it very dearly and in very short order
cutting corners, lying, and cheating will get you ahead in the short run, and sometimes even in the long run, but tying your own fortunes to someone who behaves this way will go very badly for you.
if you sell your soul to the devil you’ll pay more than you intended to, and buy less.
Pursuing all-in soulless strategies can ‘work,’ although of course what does it profit a man if he should gain the whole world and all that. The person doing the lying and cheating will sometimes win out, in terms of ‘success.’ If you are also centrally in the lying and cheating business, it can sometimes work out for you too, in those same terms.
However. If you are not that, and you hitch your wagon to someone who is that in order to ‘win’? Disaster, almost without exception. It won’t work, not on any level.
I know that sounds like the kind of thing we all want to be true when it isn’t. So yes, you are right to be suspicious of such claims. The thing is, I think it really is true.
Paul Graham’s latest essay is What To Do. His answer, in addition to ‘help people’ and ‘take care of the world’ is ‘make good new things.’ Agreed.
Paul Graham: So there’s my guess at a set of principles to live by: take care of people and the world, and make good new things. Different people will do these to varying degrees. There will presumably be lots who focus entirely on taking care of people. There will be a few who focus mostly on making new things.
But even if you’re one of those, you should at least make sure that the new things you make don’t net harm people or the world. And if you go a step further and try to make things that help them, you may find you’re ahead on the trade. You’ll be more constrained in what you can make, but you’ll make it with more energy.
On the other hand, if you make something amazing, you’ll often be helping people or the world even if you didn’t mean to. Newton was driven by curiosity and ambition, not by any practical effect his work might have, and yet the practical effect of his work has been enormous. And this seems the rule rather than the exception. So if you think you can make something amazing, you should probably just go ahead and do it.
I’m not even sure it’s on you to make sure that you don’t do net harm. I’ll settle for ensuring you’re not going catastrophic harm, or at minimum that you’re not creating existential risks, say by creating things smarter and more capable than humans without knowing how to retain control over the resulting future. Oh, right, that.
Dean Ball writes about his intellectual background and process. It’s a completely different process from mine, focusing on absorbing lots of background knowledge and understanding intellectual figures through reading, especially books. It reminded me of Tyler Cowen’s approach. One thing we all have in common is we intentionally play to our strengths. If I tried to do what they do, it wouldn’t work.
Connections follow power laws and the best ones are insanely valuable.
Alessandro: I believed the quote in Caplan’s tweet [that rich kids mostly succeed because of genetics], and then I ended up ~doubling my lifetime expected earnings because of a lucky personal connection.
It would be unBayesian of me not to update my prior!
Properly optimizing for the actions that maximize chances of making the most valuable connections is difficult, but highly valuable. Blogging definitely helps.
Federal complaint alleges that construction equipment rental firms have engaged for 15 years in a widespread cartel to limit capacity and drive up construction costs. I file this under Good News because we know how expensive it is to build and this could mean there is an easy way to make that number go down.
In developing countries, for those with college degrees, having low-skill job experience makes employers 10% more interested in hiring you versus not having any experience at all. Work it.
Acid rain is the classic example of a problem that was solved by coordination, thus proving that such coordination only solves imaginary problems. Many such cases.
A great question:
Patrick Collison: In which domains are elite practitioners celebrating the kids being better than ever before? Would love to read about a few instances. (Not just where there’s one particular genius, such as Ashwin Sah’s recent success, but where “the kids” as some kind of aggregate appear to be improving.)
The first category, which had a lot of responses, was that ‘the kids’ are better in particular bounded domains with largely fixed rules. My model agrees with this. If it’s a bounded domain with clear rules where one can be better by following standard practices and working harder, the kids are alright, and better than ever.
Tyler Cowen: The kids are clearly better in chess.
Ulkar: definitely in classical music. the sheer number of outstanding young musicians is probably higher than ever before in history
Patrick McKenzie: Japanese language acquisition for non-heritage speakers. (I non-ironically think it’s primarily YouTube’s doing.)
Eric Gilliam: In American wrestling, high schoolers are getting *waybetter. This year at Olympic trials, a few ~16-year-olds took out some NCAA champs. And those guys still lose some hs matches! Guesses why include more kids getting elite coaching early and internet instructionals.
The second category was founders, and Dwarkesh Patel said ‘big picture thinkers.’ Paul Graham was the most obvious one to say it but there were also others.
Paul Graham: Young startup founders seem better than ever, though I realize this is a bold claim to make to you.
Patrick Collison: Who’s the best founder under 28? I’m deliberately choosing an arbitrary age to exclude Alex Wang, who is extremely impressive, but I feel like years past usually had a super young (<28) clear industry leader. (Zuckerberg, Dell, Jobs, Gates, Andreessen, etc.)
My hypothesis there is that we have systematized VC-backed YC-style founders. The rules are a lot easier to discover and follow, the track record there makes it a career path one can essentially plan on in a way that it wasn’t before, and the people who gate progress with money are there to reward those who internalize and follow those principles.
This makes Dwarkesh the only one I saw whose answer didn’t fit into the model that ‘kids these days’ are excellent at rule learning and following and working hard on that basis, but this has left little room for much else. I don’t know how this would lead to there being more or better big picture thinkers. Also I’m not at all convinced Dwarkesh is right about this, I suspect it’s that the current crop is easy for him to pick up upon and we forget about many from older crops.
As I mentioned when I wrote about taste, it is usually better to like and enjoy things.
Aprii: enjoying things rules
-
it is good to enjoy things
-
it is not bad to enjoy things
-
it is okay, though usually not ideal, to not enjoy things
There are some things i will look down on someone for enjoying but most of the time i do that i think it’s a failing in my part.
Anna Magpie: Counterpoint: Enjoying things that are bad for you often results in them displacing things that are good for you but slightly less enjoyable (for example I am currently on Twitter instead of reading a novel)
Aprii: in an ideal world this is solved by enjoying novels more.
The cases where you want to not like things is where liking them would cause you to make bad choices, which are more expensive than the value you would get, and you are unable to adjust for this effect because of bias or because it gives you a bad world model.
The canonical example of the first case is heroin. The common pattern, which also applies to novels versus Twitter, tends to be hyperbolic discounting. You want to like things that have long term benefits relatively more, and this often rises to the point where it would be better to like other things less. Another risk is that you end up doing too little exploring and too much exploiting.
The second case is where the value is in choosing, so liking everything can muddle your ability to choose. It doesn’t have to, if you can differentiate between what you like and what you predict others will like. But that can be tricky.
Don’t say you weren’t warned, as Roku tests autoplay ads on its home screen.
I find it mind boggling to think such ads are efficient. They are beyond obnoxious, and there are many customers who would act similarly to Leah:
Leah Libresco Sargeant: I have kids and a @Roku TV
If they autoplay video ads on boot up, we will absolutely ditch it and find a new tv. I’m not using any device or service with the potential to autoplay violent tv or movie ads the second you hit the power button.
Even without that concern, such obnoxiousness in your face is unacceptable. My current LG TVs do have some ads on the home screen, but they’re always silent, they never stop you from navigation, and even then I hate them so much. If they forced me to interact with the ad in order to proceed? Yep, TV straight in the trash, or down to goodwill. If the ads are so bad people don’t want your TV for $0, how much are the ads worth to you, exacctly?
We also need to have a word about certain highly obnoxious autoplay and ad settings inside TV apps. As in, every time I go to Paramount+, I am careful to actively mute the television first, or I know I am going to regret it. Then you have to be sure to skip other ads. Why would you make opening your own app this stressful? Yet this seems to be how much I will endure to keep watching Taylor Tomlinson.
And then there’s Prime Video, which will have multi-minute blocks of unskippable obnoxiousness during movies, and doesn’t even use caution with who gets to do that:
Sarah Constantin: I’ve been unpleasantly surprised to see the ads on @PrimeVideo include what I’d normally think of as “vice” or “trashy” products.
Sketchy weight loss supplements, shady-looking finance apps marketed in a gambling-esque “surprise free money” way, etc.
I would have assumed that somebody buying ads on what is now the equivalent of a major television network would have a certain amount of “taste” such that they wouldn’t be willing to advertise exploitative products to a super-broad audience.
Differing opinions about Severance. I am on the side of masterpiece, I think Blow’s objection here is wrong and expect it to stick the landing and be my 8th Tier 1 show.
I’ve also been watching The White Lotus for the first time, which is also excellent and I expect to put it in Tier 2.
I still have a few Beli invites if anyone wants one. Beli lets you rank restaurants via Elo, tracks your preferences and gives you predictive ratings. I am a little worried they still haven’t integrated Beli with web or any good export mechanism so I can’t easily feed everything into an LLM or save it elsewhere, but I’ve found it to be useful for research and search and also for note taking.
Looks Mapping, a service that tells you how hot the people reviewing a restaurant on Google Maps tend to be. There was not an obvious correlation here with which restaurants are worth going to.
This list of the best croissants in NYC is unusually good, many excellent picks, including my current top two of Tall Poppy and Alf Bakery (in that order).
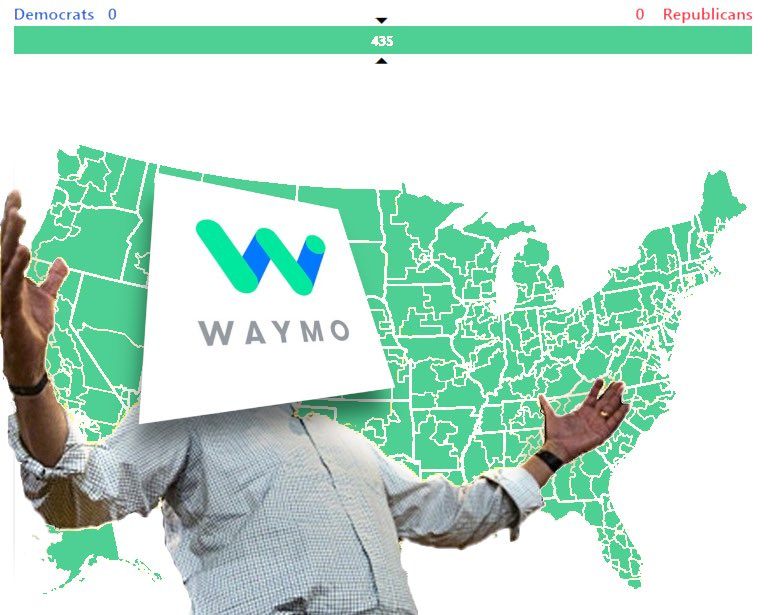
It’s happening! Eventually. Probably. I hope?
Bigad Shaban:
-
Waymo gets green light to start “mapping” San Francisco airport in hopes of ultimately using its driverless cars to pick up and drop off passengers at SFO. Mapping process will train fleet where to go and will be done with human safety drivers behind the wheel.
-
After mapping, cars will then need to go on test drives at SFO without a driver. An official decision on ultimately granting SFO access to Waymo’s driverless cars still hasn’t been made.
-
This mapping process could take weeks or even months and allows for two cars to be at the airport at a time. No passengers can be inside — just the safety driver. If Waymo gets approved to pick up & drop off passengers, there’s still no timeline on when that could begin.
Paula: as someone who either walks or takes a waymo, these announcements are like when you unlock a new area in an open-world game.
Waymo: We’re pleased to share that the CA DMV gave Waymo approval to operate fully autonomously in expanded South Bay areas, including almost all of San Jose!
While the public won’t have access at this time, we’re working closely with local officials, emergency responders, and communities to safely expand driving operations.
It’s happening in Washington, DC too, coming in 2026.
I say this utterly seriously: Whoever runs for mayor on the ‘bring Waymo to NYC whatever it takes’ platform gets my vote, even if it’s Andrew Cuomo, I don’t care. Single issue voter.
They’re also making progress on being less insane about age requirements? They’re trying out ‘teen accounts’ for ages 14-17, ‘with parental permission.’
Timothy Lee: I hope they lower the minimum age over time. There’s no reason a 12 year old shouldn’t be able to ride in a Waymo alone.
Parents (especially of girls) might feel more comfortable if there is no driver. Also in the long run Waymos will hopefully be much cheaper than a conventional taxi.
I suppose you need some age requirement but I also presume it should be, like, 6.
As he periodically does, Timothy Lee also checks Waymo’s few crashes. There were 38 between July 2024 and February 2025. Not only are Waymos crashing and injuring people far less often than human drivers, with about 90 percent fewer insurance claims, when there is an incident it is almost always unambiguously a human driver’s fault. The question even more than before is not whether to allow Waymos everywhere all the time, it is whether humans should be driving at all.
Timothy Lee: A large majority of serious Waymo crashes are “Waymo scrupulously following the law, lunatic human driver breaks the law and crashes into the Waymo.”
Waymo still has one big problem. It obeys traffic laws and drives ‘too safely,’ which means that the drive that takes 41 minutes in an Uber or Lyft can take 57 in a Waymo. This example might also be geofencing, but the problem is real. There probably isn’t anything we can do about it while we are holding self-driving cars to insanely higher safety standards than human drivers.
In the social media age, the red card rule applies to attention, if you’re innovative everything works the first time. Thus, we have tech workers leaving notes in Waymos, looking to hire software engineers or find hot dates. That’s a great idea, but the reason it scaled was social media, and that presumably won’t work again, not unless your notes are increasingly bespoke. If I was Waymo, my policy would be to allow this and even have a protocol, but restrict it to handwritten notes.
Sandy Peterson has been having fun looking back on Age of Empires.
Famed King of Kong (which is a great movie) villain and by all accounts notorious video game cheater Billy Mitchell won a defamation lawsuit against YouTuber Karl Jobst in Australia. It turns out that if you incorporate a specific false claim into an attack narrative and general crusade, you can get sued for it even if you did begrudgingly take that particular fact back at some point.
In a Magic match, is it okay to not kill your opponent in order to take time off the clock, if you’re sure it would work and there’s no in-game advantage to waiting?
Discussions ensue. I see a big difference between being illegal versus unethical. As I understand the rules, this is technically legal.
The argument for it being fine is that you are never forced to play your cards, and they are welcome to concede at any time, although they have no way of knowing that they can safely concede.
But you are making a play, that is otherwise to your disadvantage, in order to bleed the clock. I think that’s basically never okay. And when I see people broadly thinking it is okay, it makes me much less interested in playing. It’s a miserable experience.
After reflection and debate, my position is that:
-
It is always honorable to make a play to make the game finish faster.
-
You are under no obligation to sacrifice even a tiny amount of win percentage in the game or match to make the game finish faster, if you don’t want to do that.
-
You are dishonorable scum if you play in order to make the game finish slower, in a way you would not behave if this was a fully untimed round.
-
That is different from what is punishable cheating. Which is fine.
Also making me much less interested is the lack of a banned list. As I understand it, cheating is rather rampant, as you would expect without a banned list.
Yankees invent a new type of bat, thanks that one guy who worked on it.
Will Manidis: the yankees hired a single smart guy to think about baseball bats for a year and he fundamentally changed the game forever
the efficient market hypothesis is an total lie. the most important problems in the world go unsolved because no one spends the time to think about them
“I’m sure someone has thought about this before and found out it’s impossible”
no they haven’t, no one has spent the time. most “hard work” is spent on stamp collecting, neat little procedural iterations on things that we already know are possible. just spend the time thinking
Chinese TikTok claims to spill the tea on a bunch of ‘luxury’ brands producing their products in China, then slapping ‘Made in Italy’ style tags on them. I mean, everyone who is surprised raise your hand, that’s what I thought, but also why would the Chinese want to be talking about it if it was true? I get it feels good in the moment but you want brands to be able to count on your discretion.
A Twitter thread of great wholesome replies, recommended, more please. Here’s a note on #12:
Lindsay Eagar (this was #12): I brought my four-year-old to meet my boyfriend at the aquarium. She said, “I love you and want you to be my dad.”
I nearly died, but he said, “How about I pretend to be your dad for today?” and then they held hands the whole day.
We got married, he adopted her, he’s her dad.
Visakan Veerasamy: great example of someone receiving a large ask and appropriately right-sizing it into something smaller (and eventually delivering on the large ask too, but that one day was perfect even and especially if he couldn’t follow through for whatever reason)
simply existing as a person like this is a public service to everyone around you. people learn to get better at asking for help + helping others when everyone can correct/transmute/scale requests appropriately. this then allows the rate-of-help to increase, which is wealth
if you look up any unusually successful scene, IME you’ll always find some behind-the-scene manager who was the de-facto mayor who’s like this, that everyone goes to for counsel, to resolve disputes, etc. people like this keep scenes and communities together longer than normal
A good question.
Whole thing feels kind of sus.
Speaking of which…
More Perfect Union: DoorDash and Klarna have signed a deal where customers can choose to pay for food deliveries in interest-free installments or deferred options aligned with payday schedules.
Axial Wanderer: We are selling pad thai in installments to willing buyers at the current fair market price
OldWorld Marc: But John, if we do that, no one will ever finance his kung pao chicken through us ever again!!
Maselaw: They can slow you down. But they can’t stop you. It’s your burrito to sell.
0xtopfloor: “Here’s Margot Robbie in a bubble bath to explain”
Checks out.
New fingerprint lock can literally be opened in 15 seconds with a screwdriver, by straight taking off its screws.
You’d think so, but I am highly confident you would be wrong:
Andy Kaczynski: This is quite the quote
Scott Lincicome: