In the wake of the confusions around GPT-5, this week had yet another round of claims that AI wasn’t progressing, or AI isn’t or won’t create much value, and so on. There were reports that one study in particular impacted Wall Street, and as you would expect it was not a great study. Situational awareness is not what you’d hope.
I’ve gathered related coverage here, to get it out of the way before whatever Google is teasing (Gemini 3.0? Something else?) arrives to potentially hijack our attention.
We’ll start with the MIT study on State of AI in Business, discuss the recent set of ‘AI is slowing down’ claims as part of the larger pattern, and then I will share a very good attempted explanation from Steven Byrnes of some of the ways economists get trapped into failing to look at what future highly capable AIs would actually do.
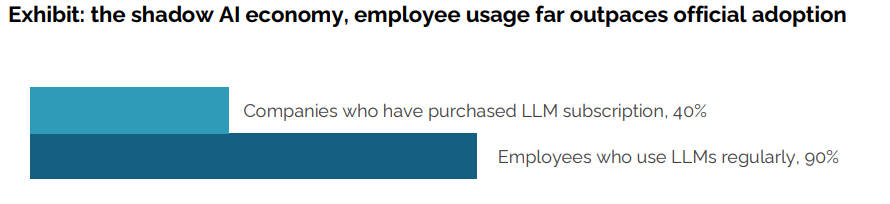
Chatbots and coding agents are clear huge wins. Over 80% of organizations have ‘explored or piloted’ them and 40% report deployment. The employees of the other 60% presumably have some news.
But we have a new State of AI in Business report that says that when businesses try to do more than that, ‘95% of businesses get zero return,’ although elsewhere they say ‘only 5% custom enterprise AI tools reach production.’
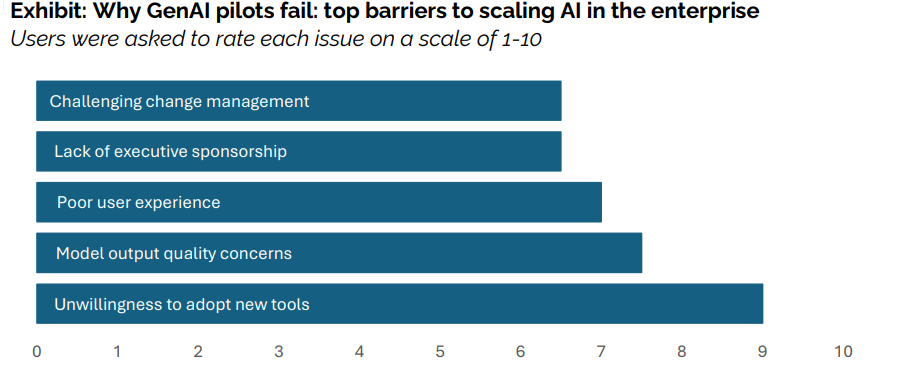
From our interviews, surveys, and analysis of 300 public implementations, four patterns emerged that define the GenAI Divide:
-
Limited disruption: Only 2 of 8 major sectors show meaningful structural change.
-
Enterprise paradox: Big firms lead in pilot volume but lag in scale-up.
-
Investment bias: Budgets favor visible, top-line functions over high-ROI back office.
-
Implementation advantage: External partnerships see twice the success rate of
internal builds.
These are early days. Enterprises have only had capacity to look for ways to slide AI directly into existing structures. They ask, ‘what that we already do, can AI do for us?’ They especially ask ‘what can show clear measurable gains we can trumpet?’
It does seem reasonable to say that the ‘custom tools’ approach may not be doing so great, if the tools only reach deployment 5% of the time. They might have a high enough return they still come out ahead, but that is a high failure rate if you actually fully scrap the other 95% and don’t learn from them. It seems like this is a skill issue?
The primary factor keeping organizations on the wrong side of the GenAI Divide is the learning gap, tools that don’t learn, integrate poorly, or match workflows.
…
The 95% failure rate for enterprise AI solutions represents the clearest manifestation of the GenAI Divide. Organizations stuck on the wrong side continue investing in static tools that can’t adapt to their workflows, while those crossing the divide focus on learning-capable systems.
…
As one CIO put it, “We’ve seen dozens of demos this year. Maybe one or two are genuinely useful. The rest are wrappers or science projects.”
That sounds like the ‘AI tools’ that fail deserve the air quotes.
I also note that later they say custom built AI solutions ‘fail twice as often.’ That implies that when companies are wise enough to test solutions built externally, they succeed over 50% of the time.
There’s also a strange definition of ‘zero return’ here.
Just 5% of integrated AI pilots are extracting millions in value, while the vast majority remain stuck with no measurable P&L impact.
Tools like ChatGPT and Copilot are widely adopted. Over 80 percent of organizations have explored or piloted them, and nearly 40 percent report deployment. But these tools primarily enhance individual productivity, not P&L performance.
Issue a report where you call the 95% of projects that don’t have ‘measurable P&L impact’ failures, then wonder why no one wants to do ‘high-ROI back office’ upgrades.
Those projects are high ROI, but how do you prove the R on I?
Especially if you can’t see the ROI on ‘enhancing individual productivity’ because it doesn’t have this ‘measurable P&L impact.’ If you double the productivity of your coders (as an example), it’s true that you can’t directly point to [$X] that this made you in profit, but surely one can see a lot of value there.
They call it a ‘divide’ because it takes a while to see returns, after which you see a lot.
While most implementations don’t drive headcount reduction, organizations that have crossed the GenAI Divide are beginning to see selective workforce impacts in customer support, software engineering, and administrative functions.
In addition, the highest performing organizations report measurable savings from reduced BPO spending and external agency use, particularly in back-office operations.
Others cite improved customer retention and sales conversion through automated outreach and intelligent follow-up systems.
These early results suggest that learning-capable systems, when targeted at specific processes, can deliver real value, even without major organizational restructuring.
This all sounds mostly like a combination of ‘there is a learning curve that is barely started on’ with ‘we don’t know how to measure most gains.’
Also note the super high standard here. Only 22% of major sectors show ‘meaningful structural change’ at this early stage, and section 3 talks about ‘high adoption, low transformation.’
Or their ‘five myths about GenAI in the Enterprise’:
-
AI Will Replace Most Jobs in the Next Few Years → Research found limited layoffs from GenAI, and only in industries that are already affected significantly by AI. There is no consensus among executives as to hiring levels over the next 3-5 years.
-
Generative AI is Transforming Business → Adoption is high, but transformation is rare. Only 5% of enterprises have AI tools integrated in workflows at scale and 7 of 9 sectors show no real structural change.
-
Enterprises are slow in adopting new tech → Enterprises are extremely eager to adopt AI and 90% have seriously explored buying an AI solution.
-
The biggest thing holding back AI is model quality, legal, data, risk → What’s really holding it back is that most AI tools don’t learn and don’t integrate well into workflows.
-
The best enterprises are building their own tools → Internal builds fail twice as often.
Most jobs within a few years is not something almost anyone is predicting in a non-AGI world. Present tense ‘transforming business’ is a claim I don’t remember hearing. I also hadn’t heard ‘the best enterprises are building their own tools’ and it does not surprise me that rolling your own comes with much higher failure rates.
I would push back on #3. As always, slow is relative, and being ‘eager’ is very different from not being the bottleneck. ‘Explored buying an AI solution’ is very distinct from ‘adopting new tech.’
I would also push back on #4. The reason AI doesn’t yet integrate well into workflows is because the tools are not yet good enough. This also shows the mindset that the AI is being forced to ‘integrate into workflows’ rather than generating new workflows, another sign that they are slow in adopting new tech.
Users prefer ChatGPT for simple tasks, but abandon it for mission-critical work due to its lack of memory. What’s missing is systems that adapt, remember, and evolve, capabilities that define the difference between the two sides of the divide.
I mean ChatGPT does now have some memory and soon it will have more. Getting systems to remember things is not all that hard. It is definitely on its way.
The more I explore the report the more it seems determined to hype up this ‘divide’ around ‘learning’ and memory. Much of the time seems like unrealistic expectations.
Yes, you would love if your AI tools learned all the detailed preferences and contexts of all of your clients without you having to do any work?
The same lawyer who favored ChatGPT for initial drafts drew a clear line at sensitive contracts:
“It’s excellent for brainstorming and first drafts, but it doesn’t retain knowledge of client preferences or learn from previous edits. It repeats the same mistakes and requires extensive context input for each session. For high-stakes work, I need a system that accumulates knowledge and improves over time.”
This feedback points to the fundamental learning gap that keeps organizations on the wrong side of the GenAI Divide.
Well, how would it possibly know about client preferences or learn from previous edits? Are you keeping a detailed document with the client preferences in preferences.md? People would like AI to automagically do all sorts of things out of the box without putting in the work.
And if they wait a few years? It will.
I totally do not get where this is coming from:
Takeaway: The window for crossing the GenAI Divide is rapidly closing. Enterprises are locking in learning-capable tools. Agentic AI and memory frameworks (like NANDA and MCP) will define which vendors help organizations cross the divide versus remain trapped on the wrong side.
Why is there a window and why is it closing?
I suppose one can say ‘there is a window because you will rapidly be out of business’ and of course one can worry about the world transforming generally, including existential risks. But ‘crossing the divide’ gets easier every day, not harder.
In the next few quarters, several enterprises will lock in vendor relationships that will be nearly impossible to unwind.
Why do people keep saying versions of this? Over time increasingly capable AI and better AI tools will make it, again, easier not harder to pivot or migrate.
Yes, I get that people think the switching costs will be prohibitive. But that’s simply not true. If you already have an AI that can do things for your business, getting another AI to learn and copy what you need will be relatively easy. Code bases can switch between LLMs easily, often by changing only one to three lines.
What is the bottom line?
This seems like yet another set of professionals putting together a professional-looking report that fundamentally assumes AI will never improve, or that improvements in frontier AI capability will not matter, and reasoning from there. Once you realize this implicit assumption, a lot of the weirdness starts making sense.
Ethan Mollick: Okay, got the report. I would read it yourself. I am not sure how generalizable the findings are based on the methodology (52 interviews, convenience sampled, failed apparently means no sustained P&L impact within six months but no coding explanation)
I have no doubt pilot failures are high, but I think it is really hard to see how this report gives the kind of generalizable finding that would move markets.
Nathan Whittemore: Also no mention of coding. Also no agents. Also 50% of uses were marketing, suggesting extreme concentration of org area.
Azeem Azhar: it was an extremely weak report. You are very generous with your assessment.
Aaron Erickson: Many reports like this start from the desired conclusion and work backwards, and this feels like no exception to that rule.
Most of the real work is bottom up adoption not measured by anything. If anything, it is an indictment about top-down initiatives.
The reason this is worth so much attention is that we have reactions like this one from Matthew Field, saying this is a ‘warning sign the AI bubble is about to burst’ and claiming the study caused a stock selloff, including a 3.5% drop in Nvidia and ~1% in some other big tech stocks. Which isn’t that much, and there are various alternative potential explanations.
The improvements we are seeing involve not only AI as it exists now (as in the worst it will ever be), with substantial implementation delays. It also involves only individuals adopting AI or at best companies slotting AI into existing workflows.
Traditionally the big gains from revolutionary technologies come elsewhere.
Roon: real productivity gains for prior technological advances came not from individual workers learning to use eg electricity, the internet but entire workflows, factories, processes, businesses being set up around the use of new tools (in other words, management)
couple years ago I figured this could go much faster than usual thanks to knowledge diffusion over the internet and also the AIs themselves coming up with great ideas about how to harness their strengths and weaknesses. but I’m not sure about that at present moment.
Patrick McKenzie: (Agree with this, and generally think it is one reasons why timelines to visible-in-GDP-growth impact are longer than people similarly bullish on AI seem to believe.)
I do think it is going faster and will go faster, except that in AI the standard for ‘fast’ is crazy fast, and ‘AIs coming up with great ideas’ is a capability AIs are only now starting to approach in earnest.
I do think that if AGI and ASI don’t show up, the timeline to the largest visible-in-GDP gains will take a while to show up. I expect visible-in-GDP soon anyway because I think the smaller, quicker version of even the minimally impressive version of AI should suffice to become visible in GDP, even though GDP will only reflect a small percentage of real gains.
The ‘AI is losing steam’ or ‘big leaps are slowing down’ and so on statements from mainstream media will keep happening whenever someone isn’t feeling especially impressed this particular month. Or week.
Dean Ball: I think we live in a perpetual state of traditional media telling us that the pace of ai progress is slowing
These pieces were published during a span that I would describe as the most rapid pace of progress I’ve ever witnessed in LLMs (GPT-4 Turbo -> GPT 5-Pro; remember: there were no public reasoner models 365 days ago!)
(Also note that Bloomberg piece was nearly simultaneous with the announcement of o3, lmao)
Miles Brundage: Notably, it’s ~never employees at frontier companies quoted on this, it’s the journalists themselves, or academics, startups pushing a different technique, etc.
The logic being “people at big companies are biased.” Buddy, I’ve got some big news re: humans.
Anton: my impression is that articles like this mostly get written by people who really really want to believe ai is slowing down. nobody working on it or even using it effectively thinks this. Which is actually basically a marketing problem which the entire field has been bad at since 2022.
Peter Gostev: I’m sure you’ve all noticed the ‘AI is slowing down’ news stories every few weeks for multiple years now – so I’ve pulled a tracker together to see who and when wrote these stories.
There is quite a range, some are just outright wrong, others point to a reasonable limitation at the time but missing the bigger arc of progress.
All of these stories were appearing as we were getting reasoning models, open source models, increasing competition from more players and skyrocketing revenue for the labs.
Peter links to about 35 posts. They come in waves.
The practical pace of AI progress continues to greatly exceed the practical pace of progress everywhere else. I can’t think of an exception. It is amazing how eagerly everyone looks for a supposed setback to try and say otherwise.
You could call this gap a ‘marketing problem’ but the US Government is in the tank for AI companies and Nvidia is 3% of total stock market cap and investments in AI are over 1% of GDP and so on, and diffusion is proceeding at record pace. So it is not clear that they should care about those who keep saying the music is about to stop?
Coinbase CEO fires software engineers who don’t adopt AI tools. Well, yeah.
On the one hand, AI companies are building their models on the shoulders of giants, and by giants we mean all of us.
Ezra Klein (as an example): Right now, the A.I. companies are not making all that much money off these products. If they eventually do make the profits their investors and founders imagine, I don’t think the normal tax structure is sufficient to cover the debt they owe all of us, and everyone before us, on whose writing and ideas their models are built.
Then there’s the energy demand.
Also the AI companies are risking all our lives and control over the future.
On the other hand, notice that they are indeed not making that much money. It seems highly unlikely that, even in terms of unit economics, creators of AI capture more than 10% of value created. So in an ‘economic normal’ situation where AI doesn’t ‘go critical’ or transform the world, but is highly useful, who owes who the debt?
It’s proving very useful for a lot of people.
Ezra Klein: And yet I am a bit shocked by how even the nascent A.I. tools we have are worming their way into our lives — not by being officially integrated into our schools and workplaces but by unofficially whispering in our ears.
The American Medical Association found that two in three doctors are consulting with A.I.
A Stack Overflow survey found that about eight in 10 programmers already use A.I. to help them code.
The Federal Bar Association found that large numbers of lawyers are using generative A.I. in their work, and it was more common for them to report they were using it on their own rather than through official tools adopted by their firms. It seems probable that Trump’s “Liberation Day” tariffs were designed by consulting a chatbot.
All of these uses involve paying remarkably little and realizing much larger productivity gains.
Steven Byrnes explains his view on some reasons why an economics education can make you dumber when thinking about future AI, difficult to usefully excerpt and I doubt he’d mind me quoting it in full.
I note up top that I know not all of this is technically correct, it isn’t the way I would describe this, and of course #NotAllEconomists throughout especially for the dumber mistakes he points out, but the errors actually are often pretty dumb once you boil them down, and I found Byrnes’s explanation illustrative.
Steven Byrnes: There’s a funny thing where economics education paradoxically makes people DUMBER at thinking about future AI. Econ textbooks teach concepts & frames that are great for most things, but counterproductive for thinking about AGI. Here are 4 examples. Longpost:
THE FIRST PIECE of Econ anti-pedagogy is hiding in the words “labor” & “capital”. These words conflate a superficial difference (flesh-and-blood human vs not) with a bundle of unspoken assumptions and intuitions, which will all get broken by Artificial General Intelligence (AGI).
By “AGI” I mean here “a bundle of chips, algorithms, electricity, and/or teleoperated robots that can autonomously do the kinds of stuff that ambitious human adults can do—founding and running new companies, R&D, learning new skills, using arbitrary teleoperated robots after very little practice, etc.”
Yes I know, this does not exist yet! (Despite hype to the contrary.) Try asking an LLM to autonomously write a business plan, found a company, then run and grow it for years as CEO. Lol! It will crash and burn! But that’s a limitation of today’s LLMs, not of “all AI forever”.
AI that could nail that task, and much more beyond, is obviously possible—human brains and bodies and societies are not powered by some magical sorcery forever beyond the reach of science. I for one expect such AI in my lifetime, for better or worse. (Probably “worse”, see below.)
Now, is this kind of AGI “labor” or “capital”? Well it’s not a flesh-and-blood human. But it’s more like “labor” than “capital” in many other respects:
• Capital can’t just up and do things by itself? AGI can.
• New technologies take a long time to integrate into the economy? Well ask yourself: how do highly-skilled, experienced, and entrepreneurial immigrant humans manage to integrate into the economy immediately? Once you’ve answered that question, note that AGI will be able to do those things too.
• Capital sits around idle if there are no humans willing and able to use it? Well those immigrant humans don’t sit around idle. And neither will AGI.
• Capital can’t advocate for political rights, or launch coups? Well…
Anyway, people see sci-fi robot movies, and they get this! Then they take economics courses, and it makes them dumber.
(Yes I know, #NotAllEconomists etc.)
THE SECOND PIECE of Econ anti-pedagogy is instilling a default assumption that it’s possible for a market to equilibrate. But the market for AGI cannot: AGI combines a property of labor markets with a property of product markets, where those properties are mutually exclusive. Those properties are:
• (A) “NO LUMP OF LABOR”: If human population goes up, wages drop in the very short term, because the demand curve for labor slopes down. But in the longer term, people find new productive things to do—the demand curve moves right. If anything, the value of labor goes UP, not down, with population! E.g. dense cities are engines of growth!
• (B) “EXPERIENCE CURVES”: If the demand for a product rises, there’s price increase in the very short term, because the supply curve slopes up. But in the longer term, people ramp up manufacturing—the supply curve moves right. If anything, the price goes DOWN, not up, with demand, thanks to economies of scale and R&D.
QUIZ: Considering (A) & (B), what’s the equilibrium price of this AGI bundle (chips, algorithms, electricity, teleoperated robots, etc.)?
…Trick question! There is no equilibrium. Our two principles, (A) “no lump of labor” and (B) “experience curves”, make equilibrium impossible:
• If price is low, (A) says the demand curve races rightwards—there’s no lump of labor, therefore there’s massive profit to be made by skilled entrepreneurial AGIs finding new productive things to do.
• If price is high, (B) says the supply curve races rightwards—there’s massive profit to be made by ramping up manufacturing of AGI.
• If the price is in between, then the demand curve and supply curve are BOTH racing rightwards!
This is neither capital nor labor as we know it. Instead of the market for AGI equilibrating, it forms a positive feedback loop / perpetual motion machine that blows up exponentially.
Does that sound absurd? There’s a precedent: humans! The human world, as a whole, is already a positive feedback loop / perpetual motion machine of this type! Humans bootstrapped themselves up from a few thousand hominins to 8 billion people running a $80T economy.
How? It’s not literally a perpetual motion machine. Rather, it’s an engine that draws from the well of “not-yet-exploited economic opportunities”. But remember “No Lump of Labor”: the well of not-yet-exploited economic opportunities is ~infinitely deep. We haven’t run out of possible companies to found. Nobody has made a Dyson swarm yet.
There’s only so many humans to found companies and exploit new opportunities. But the positive feedback loop of AGI has no such limit. The doubling time can be short indeed:
Imagine an autonomous factory that can build an identical autonomous factory, which then build two more, etc., using just widely-available input materials and sunlight. Economics textbooks don’t talk about that. But biology textbooks do! A cyanobacterium is such a factory, and can double itself in a day (≈ googol percent annualized growth rate 😛).
Anyway, we don’t know how explosive will be the positive feedback loop of AGI building AGI, but I expect it to be light-years beyond anything in economic history.
THE THIRD PIECE of Econ anti-pedagogy is its promotion of GDP growth as a proxy for progress and change. On the contrary, it’s possible for the world to transform into a wild sci-fi land beyond all recognition or comprehension each month, month after month, without “GDP growth” actually being all that high. GDP is a funny metric, and especially poor at describing the impact of transformative technological revolutions. (For example, if some new tech is inexpensive, and meanwhile other sectors of the economy remain expensive due to regulatory restrictions, then the new tech might not impact GDP much, no matter how much it upends the world.) I mean, sure we can argue about GDP, but we shouldn’t treat it as a proxy battle over whether AGI will or won’t be a big deal.
Last and most importantly, THE FOURTH PIECE of Econ anti-pedagogy is the focus on “mutually-beneficial trades” over “killing people and taking their stuff”. Econ 101 proves that trading is selfishly better than isolation. But sometimes “killing people and taking their stuff” is selfishly best of all.
When we’re talking about AGI, we’re talking about creating a new intelligent species on Earth, one which will eventually be faster, smarter, better-coordinated, and more numerous than humans.
Normal people, people who have seen sci-fi movies about robots and aliens, people who have learned the history of colonialism and slavery, will immediately ask lots of reasonable questions here. “What will their motives be?” “Who will have the hard power?” “If they’re seeming friendly and cooperative early on, might they stab us in the back when they get more powerful?”
These are excellent questions! We should definitely be asking these questions! (FWIW, this is my area of expertise, and I’m very pessimistic.)
…And then those normal people take economics classes, and wind up stupider. They stop asking those questions. Instead, they “learn” that AGI is “capital”, kinda like an injection-molding machine. Injection-molding machines wouldn’t wipe out humans and run the world by themselves. So we’re fine. Lol.
…Since actual AGI is so foreign to economists’ worldviews, they often deny the premise. E.g. here’s @tylercowen demonstrating a complete lack of understanding of what we doomers are talking about, when we talk about future powerful AI.
Yep. If you restrict to worlds where collaboration with humans is required in most cases then the impacts of AI all look mostly ‘normal’ again.
And here’s @DAcemogluMIT assuming without any discussion that in the next 10 yrs, “AI” will not include any new yet-to-be-developed techniques that go way beyond today’s LLMs. Funny omission, when the whole LLM paradigm didn’t exist 10 yrs ago!
(Tbc, it’s fine to make that assumption! Maybe it will be valid, or maybe not, who knows, technological forecasting is hard. But when your paper depends on a giant load-bearing assumption about future AI tech progress, an assumption which many AI domain experts dispute, then that assumption should at least be clearly stated! Probably in the very first sentence of the paper, if not the title!)
And here’s another example of economists “arguing” against AGI scenarios by simply rejecting out of hand any scenario in which actual AGI exists. Many such examples…
Eliezer Yudkowsky: Surprisingly correct, considering the wince I had at the starting frame.
I really think that if you’re creating a new intelligent species vastly smarter than humans, going “oh, that’s ‘this time is different’ economics”, as if it were economics in the first place, is exactly a Byrnes-case of seeing through an inappropriate lens and ending up dumber.
I am under no illusions that an explanation like this would satisfy the demands and objections of most economists or fit properly into their frameworks. It is easy for such folks to dismiss explanations like this as insufficiently serious or rigerous, or simply to deny the premise. I’ve run enough experiments to stop suspecting otherwise.
However, if one actually did want to understand the situation? This could help.