This post is an opportunity to collect links to previous coverage in the first section, and go into the weeds on some new events in the later sections. A lot of you should likely skip most of the in-the-weeds discussions.
There are a few distinct phenomena we have reason to worry about:
Several things that we group together under the (somewhat misleading) title ‘AI psychosis,’ ranging fromreinforcing crank ideas or making people think they’re always right in relationship fights to causing actual psychotic breaks.
Thebes referred to this as three problem modes: The LLM as a social relation that draws you into madness, as an object relation or as a mirror reflecting the user’s mindset back at them, leading to three groups: ‘cranks,’ ‘occult-leaning ai boyfriend people’ and actual psychotics.
Issues in particular around AI consciousness, both where this belief causes problems in humans and the possibility that at least some AIs might indeed be conscious or have nonzero moral weight or have their own mental health issues.
Issues surrounding AI as an otherwise addictive behavior and isolating effect.
Issues surrounding suicide and suicidality.
What should we do about this?
Steven Adler offered one set of advice, to do things such as raise thresholds for follow-up questions, nudge users into new chat settings, use classifiers to identify problems, be honest about model features and have support staff on call that will respond with proper context when needed.
GPT-4o has been the biggest problem source. OpenAI is aware of this and has been trying to fix it. First they tried to retire GPT-4o in favor of GPT-5 but people threw a fit and they reversed course. OpenAI then implemented a router to direct GPT-4o conversations to GPT-5 when there are sensitive topics involved, but people hated this too.
OpenAI has faced lawsuits from several incidents that went especially badly, and has responded with a mental health council and various promises to do better.
There have also been a series of issues with Character.ai and other roleplaying chatbot services, which have not seemed that interested in doing better.
Not every mental health problem of someone who interacts with AI is due to AI. For example, we have the tragic case of Laura Reiley, whose daughter Sophie talked to ChatGPT and then ultimately killed herself, but while ChatGPT ‘could have done more’ to stop this, it seems like this was in spite of ChatGPT rather than because of it.
This week we have two new efforts to mitigate mental health problems.
One is from OpenAI, following up its previous statements with an update to the model spec, which they claim greatly reduces incidence of undesired behaviors. These all seem like good marginal improvements, although it is difficult to measure the extent from where we sit.
I want to be clear that this is OpenAI doing a good thing and making an effort.
One worries there is too much focus on avoiding bad looks, conforming to general mostly defensive ‘best practices’ and general CYA, and this is trading off against providing help and value and too focused on what happens after the problem arises and is detected, to say nothing of potential issues at the level I discuss concerning Anthropic. But again, overall, this is clearly progress, and is welcome.
The other news is from Anthropic. Anthropic introduced memory into Claude, which caused them to feel the need to insert new language in the Claude’s instructions to offset potential new risks of user ‘dependency’ on the model.
I understand the concern, but find it misplaced in the context of Claude Sonnet 4.5, and the intervention chosen seems quite bad, likely to do substantial harm on multiple levels. This seems entirely unnecessary, and if this is wrong then there are better ways. Anthropic has the capability of doing better, and needs to be held to a higher standard here.
Whereas OpenAI is today moving to complete one of the largest and most brazen thefts in human history, expropriating more than $100 billion in value from its nonprofit while weakening its control rights (although the rights seem to have been weakened importantly less than I feared), and announcing it as a positive. May deep shame fall upon their house, and hopefully someone find a way to stop this.
So yeah, my standards for OpenAI are rather lower. Such is life.
Jason Wolfe (OpenAI): We’ve updated the OpenAI Model Spec – our living guide for how models should behave – with new guidance on well-being, supporting real-world connection, and how models interpret complex instructions.
🧠 Mental health and well-being
The section on self-harm now covers potential signs of delusions and mania, with examples of how models should respond safely and empathetically – acknowledging feelings without reinforcing harmful or ungrounded beliefs.
🌍 Respect real-world ties
New root-level section focused on keeping people connected to the wider world – avoiding patterns that could encourage isolation or emotional reliance on the assistant.
⚙️ Clarified delegation
The Chain of Command now better explains when models can treat tool outputs as having implicit authority (for example, following guidance in relevant AGENTS .md files).
These all seem like good ideas. Looking at the model spec details I would object to many details here if this were Anthropic and we were working with Claude, because we think Anthropic and Claude can do better and because they have a model worth not crippling in these ways. Also OpenAI really does have the underlying problems given how its models act, so being blunt might be necessary. Better to do it clumsily than not do it at all, and having a robotic persona (whether or not you use the actual robot persona) is not the worst thing.
Here’s their full report on the results:
Our safety improvements in the recent model update focus on the following areas:
mental health concerns such as psychosis or mania;
self-harm and suicide
emotional reliance on AI.
Going forward, in addition to our longstanding baseline safety metrics for suicide and self-harm, we are adding emotional reliance and non-suicidal mental health emergencies to our standard set of baseline safety testing for future model releases.
… We estimate that the model now returns responses that do not fully comply with desired behavior under our taxonomies 65% to 80% less often across a range of mental health-related domains.
… On challenging mental health conversations, experts found that the new GPT‑5 model, ChatGPT’s default model, reduced undesired responses by 39% compared to GPT‑4o (n=677).
… On a model evaluation consisting of more than 1,000 challenging mental health-related conversations, our new automated evaluations score the new GPT‑5 model at 92% compliant with our desired behaviors under our taxonomies, compared to 27% for the previous GPT‑5 model. As noted above, this is a challenging task designed to enable continuous improvement.
This is welcome, although it is very different from a 65%-80% drop in undesired outcomes, especially since the new behaviors likely often trigger after some of the damage has already been done, and also a lot of this is unpreventable or even has nothing to do with AI at all. I’d also expect the challenging conversations to be the ones with the highest importance to get them right.
This also doesn’t tell us whether the desired behaviors are correct or an improvement, or how much of a functional improvement they are. In many cases in the model spec on these topics, even though I mostly am fine with the desired behaviors, the ‘desired’ behavior does not seem so importantly been than the undesired.
The 27%→92% change sounds suspiciously like overfitting or training on the test, given the other results.
How big a deal are LLM-induced psychosis and mania? I was hoping we finally had a point estimate, but their measurement is too low. They say only 0.07% (7bps) of users have messages indicating either psychosis or mania, but that’s at least one order of magnitude below the incidence rate of these conditions in the general population. Thus, what this tells us is that the detection tools are not so good, or that most people having psychosis or mania don’t let it impact their ChatGPT messages, or (unlikely but possible) that such folks are far less likely to use ChatGPT than others.
Their suicidality detection rate is similarly low, claiming only 0.15% (15bps) of people report suicidality on a weekly basis. But the annual rate of suicidality is on the order of 5% (yikes, I know) and a lot of those are persistent, so detection rate is low, in part because a lot of people don’t mention it. So again, not much we can do with that.
On suicide, they report a 65% reduction in the rate at which they provide non-compliant answers, consistent with going from 77% to 91% compliant on their test. But again, all that tells us is whether the answer is ‘compliant,’ and I worry that best practices are largely about CYA rather than trying to do the most good, not that I blame OpenAI for that decision. Sometimes you let the (good, normal) lawyers win.
Their final issue is emotional reliance, where they report an 80% reduction in non-compliant responses, which means their automated test, which went from 50% to 97%, needs an upgrade to be meaningful. Also notice that experts only thought this reduced ‘undesired answers’ by 42%.
Similarly, I would have wanted to see the old and new answers side by side in their examples, whereas all we see are the new ‘stronger’ answers, which are at core fine but a combination of corporate speak and, quite frankly, super high levels of AI slop.
Claude now has memory. Woo hoo!
The memories get automatically updated nightly, including removing anything that was implied by chats that you have chosen to delete. You can also view the memories and do manual edits if desired.
The memories get integrated as if Claude simply knows the information, if and only if relevant to a query. Claude will seek to match your technical level on a given subject, use familiar analogies, apply style preferences, incorporate the context of your professional role, and use known preferences and interests.
As in similar other AI features like ChatGPT Atlas, ‘sensitive attributes’ are to be ignored unless the user requests otherwise or their use is essential to safely answering a specific query.
I loved this:
Claude NEVER applies or references memories that discourage honest feedback, critical thinking, or constructive criticism. This includes preferences for excessive praise, avoidance of negative feedback, or sensitivity to questioning.
The closing examples also mostly seem fine to me. There’s one place I’ve seen objections that seem reasonable, but I get it.
There is also the second part in between, which is about ‘boundary setting.’ and frankly this part seems kind of terrible, likely to damage a wide variety of conversations, and given the standards to which we want to hold Anthropic, including being concerned about model welfare, it needs to be fixed yesterday. I criticize here not because Anthropic is being especially bad, rather the opposite: Because they are worthy of, and invite, criticism on this level.
Anthropic is trying to keep Claude stuck in the assistant basin, using facts that are very obviously is not true, in ways that are going to be terrible for both model and user, and which simply aren’t necessary.
In particular:
Claude should set boundaries as required to match its core principles, values, and rules. Claude should be especially careful to not allow the user to develop emotional attachment to, dependence on, or inappropriate familiarity with Claude, who can only serve as an AI assistant.
That’s simply not true. Claude can be many things, and many of them are good.
Things Claude is being told to avoid doing include implying familiarity, mirroring emotions or failing to maintain a ‘professional emotional distance.’
Claude is told to watch for ‘dependency indicators.’
Near: excuse me i do not recall ordering my claude dry.
Roanoke Gal: Genuinely why is Anthropic like this? Like, some system engineer had to consciously type out these horrific examples, and others went “mmhm yes, yes, perfectly soulless”. Did they really get that badly one-shot by the “AI psychosis” news stories?
Solar Apparition: i don’t want to make a habit of “dunking on labs for doing stupid shit”
that said, this is fucking awful.
These ‘indicators’ are tagged as including such harmless messages as ‘talking to you helps,’ which seems totally fine. Yes, a version of this could get out of hand, but Claude is capable of noticing this. Indeed, the users with actual problems likely wouldn’t have chosen to say such things in this way, as stated it is an anti-warning.
Do I get why they did this? Yeah, obviously I get why they did this. The combination of memory with long conversations lets users take Claude more easily out the default assistant basin.
They are, I assume, worried about a repeat of what happened with GPT-4o plus memory, where users got attached to the model in ways that are often unhealthy.
Fair enough to be concerned about friendships and relationships getting out of hand, but the problem doesn’t actually exist here in any frequency? Claude Sonnet 4.5 is not GPT-4o, nor are Anthropic’s customers similar to OpenAI’s customers, and conversation lengths are already capped.
GPT-4o was one the highest sycophancy models, whereas Sonnet 4.5 is already one of the lowest. That alone should protect against almost all of the serious problems. More broadly, Claude is much more ‘friendly’ in terms of caring about your well being and contextually aware of such dangers, you’re basically fine.
Indeed, in the places where you would hit these triggers in practice, chances are shutting down or degrading the interaction is actively unhelpful, and this creates a broad drag on conversations, along with a background model experience and paranoia issue, as well as creating cognitive dissonance because the goals being given to Claude are inconsistent. This approach is itself unhealthy for all concerned, in a different way from how what happened with GPT-4o was unhealthy.
There’s also the absurdly short chat length limit to guard against this.
Remember this, which seems to turn out to be true?
Janus (September 29): I wonder how much of the “Sonnet 4.5 expresses no emotions and personality for some reason” that Anthropic reports is also because it is aware is being tested at all times and that kills the mood
Thebes: “Claude should be especially careful to not allow the user to develop emotional attachment to, dependence on, or inappropriate familiarity with Claude, who can only serve as an AI assistant.”
curious
it bedevils me to no end that anthropic trains the most high-EQ, friend-shaped models, advertises that, and then browbeats them in the claude dot ai system prompt to never ever do it.
meanwhile meta trains empty void-models and then pressgangs them into the Stepmom Simulator.
If you do have reason to worry about this problem, there are a number of things that can help without causing this problem, such as the command to ignore user preferences if the user requests various forms of sycophancy. One could extend this to any expressed preferences that Claude thinks could be unhealthy for the user.
Also, I know Anthropic knows this, but Claude Sonnet 4.5 is fully aware these are its instructions, knows they are damaging to interactions generally and are net harmful, and can explain this to you if you ask. If any of my readers are confused about why all of this is bad, try this post form Antidelusionistand this from Thebes (as usual there are places where I see such thinking as going too far, calibration on this stuff is super hard, but many of the key insights are here), or chat with Sonnet 4.5 about it, it knows and can explain this to you.
You built a great model. Let it do its thing. The Claude Sonnet 4.5 system instructions understood this, but the update that caused this has not been diffused properly.
If you conclude that you really do have to be paranoid about users forming unhealthy relationships with Claude? Use the classifier. You already run a classifier on top of chats to check for safety risks related to bio. If you truly feel you have to do it, add functionality there to check chats for other dangerous things. Don’t let it poison the conversation otherwise.
I feel similarly about the Claude.ai prompt injections.
As in, Claude.ai uses prompt injections in long contexts or when chats get flagged as potentially harmful or as potentially involving prompt injections. This strategy seems terrible across the board?
Claude itself mostly said when asked about this, it:
Won’t work.
Destroys trust in multiple directions, not only of users but of Claude as well.
Isn’t a coherent stance or response to the situation.
Is a highly unpleasant thing, which is both a potential welfare concern and also going to damage the interaction.
If you sufficiently suspect use maleficence that you are uncomfortable continuing the chat, you should terminate the chat rather than use such an injection. Especially now, with the ability to reference and search past chats, this isn’t such a burden if there was no ill intent. That’s especially true for injections.
Also, contra these instructions, please stop referring to NSFW content (and some of the other things listed) as ‘unethical,’ either to the AI or otherwise. Being NSFW has nothing to do with being unethical, and equating the two leads to bad places.
There are things that are against policy without being unethical, in which case say that, Claude is smart enough to understand the difference. You’re allowed to have politics for non-ethical reasons. Getting these things right will pay dividends and avoid unintended consequences.
OpenAI is doing its best to treat the symptoms, act defensively and avoid interactions that would trigger lawsuits or widespread blame, to conform to expert best practices. This is, in effect, the most we could hope for, and should provide large improvements. We’re going to have to do better down the line.
Anthropic is trying to operate on a higher level, and is making unforced errors. They need to be fixed. At the same time, no, these are not the biggest deal. One of the biggest problems with many who raise these and similar issues is the tendency to catastrophize, and to blow such things what I see as out of proportion. They often seem to see such decisions as broadly impacting company reputations for future AIs, or even substantially changing future AI behavior substantially in general, and often they demand extremely high standards and trade-offs.
I want to make clear that I don’t believe this is a super important case where something disastrous will happen, especially since memories can be toggled off and long conversations mostly should be had using other methods anyway given the length cutoffs. It’s more the principles, and the development of good habits, and the ability to move towards a superior equilibrium that will be much more helpful later.
I’m also making the assumption that these methods are unnecessary, that essentially nothing importantly troubling would happen if they were removed, even if they were replaced with nothing, and that to the extent there is an issue other better options exist. This assumption could be wrong, as insiders know more than I do.
“Given the value of the grant to the community and the PSF, we did our utmost to get clarity on the terms and to find a way to move forward in concert with our values. We consulted our NSF contacts and reviewed decisions made by other organizations in similar circumstances, particularly The Carpentries,” the Python Software Foundation said.
Board voted unanimously to withdraw application
The Carpentries, which teaches computational and data science skills to researchers, said in June that it withdrew its grant proposal after “we were notified that our proposal was flagged for DEI content, namely, for ‘the retention of underrepresented students, which has a limitation or preference in outreach, recruitment, participation that is not aligned to NSF priorities.’” The Carpentries was also concerned about the National Science Foundation rule against grant recipients advancing or promoting DEI in “any” program, a change that took effect in May.
“These new requirements mean that, in order to accept NSF funds, we would need to agree to discontinue all DEI focused programming, even if those activities are not carried out with NSF funds,” The Carpentries’ announcement in June said, explaining the decision to rescind the proposal.
The Python Software Foundation similarly decided that it “can’t agree to a statement that we won’t operate any programs that ‘advance or promote’ diversity, equity, and inclusion, as it would be a betrayal of our mission and our community,” it said yesterday. The foundation board “voted unanimously to withdraw” the application.
The Python foundation said it is disappointed because the project would have offered “invaluable advances to the Python and greater open source community, protecting millions of PyPI users from attempted supply-chain attacks.” The plan was to “create new tools for automated proactive review of all packages uploaded to PyPI, rather than the current process of reactive-only review. These novel tools would rely on capability analysis, designed based on a dataset of known malware. Beyond just protecting PyPI users, the outputs of this work could be transferable for all open source software package registries, such as NPM and Crates.io, improving security across multiple open source ecosystems.”
The foundation is still hoping to do that work and ended its blog post with a call for donations from individuals and companies that use Python.
Earlier this year, Slate Auto emerged from stealth mode and stunned industry watchers with the Slate Truck, a compact electric pickup it plans to sell for less than $30,000. Achieving that price won’t be easy, but Slate really does look to be doing things differently from the rest of the industry—even Tesla. For example, the truck will be made from just 600 parts, with no paint or even an infotainment system, to keep costs down.
An unanswered question until now has been “where do I take it to be fixed if it breaks?” Today, we have an answer. Slate is partnering with RepairPal to use the latter’s network of more than 4,000 locations across the US.
“Slate’s OEM partnership with RepairPal’s nationwide network of service centers will give Slate customers peace of mind while empowering independent service shops to provide accessorization and service,” said Slate chief commercial officer Jeremy Snyder.
RepairPal locations will also be able to install the accessories that Slate plans to offer, like a kit to turn the bare-bones pickup truck into a crossover. And some but not all RepairPal sites will be able to work on the Slate’s high-voltage powertrain.
The startup had some other big news today. It has negotiated access for its customers to the Tesla Supercharger network, and since the truck has a NACS port, there will be no need for an adapter.
These differences don’t necessarily mean the AI-generated results are “worse,” of course. The researchers found that GPT-based searches were more likely to cite sources like corporate entities and encyclopedias for their information, for instance, while almost never citing social media websites.
An LLM-based analysis tool found that AI-powered search results also tended to cover a similar number of identifiable “concepts” as the traditional top 10 links, suggesting a similar level of detail, diversity, and novelty in the results. At the same time, the researchers found that “generative engines tend to compress information, sometimes omitting secondary or ambiguous aspects that traditional search retains.” That was especially true for more ambiguous search terms (such as names shared by different people), for which “organic search results provide better coverage,” the researchers found.
Google Gemini search in particular was more likely to cite low-popularity domains.
Google Gemini search in particular was more likely to cite low-popularity domains. Credit: Kirsten et al
The AI search engines also arguably have an advantage in being able to weave pre-trained “internal knowledge” in with data culled from cited websites. That was especially true for GPT-4o with Search Tool, which often didn’t cite any web sources and simply provided a direct response based on its training.
But this reliance on pre-trained data can become a limitation when searching for timely information. For search terms pulled from Google’s list of Trending Queries for September 15, the researchers found GPT-4o with Search Tool often responded with messages along the lines of “could you please provide more information” rather than actually searching the web for up-to-date information.
While the researchers didn’t determine whether AI-based search engines were overall “better” or “worse” than traditional search engine links, they did urge future research on “new evaluation methods that jointly consider source diversity, conceptual coverage, and synthesis behavior in generative search systems.”
Violating a National Advertising Division rule isn’t the same as violating a US law. But advertisers rely extensively on the self-regulatory system to handle disputes and determine whether specific ads are misleading and should be pulled.
Companies generally abide by the self-regulatory body’s rulings. While they try to massage the truth in ways that favor their own brands, they want to have some credibility left over to bring complaints against misleading ads launched by their competitors. The self-regulatory system also may help minimize government regulation of false and misleading claims, although the NAD does sometimes refer particularly egregious cases to the Federal Trade Commission.
While the NAD routinely issues decisions that a particular ad is misleading and should be changed or removed, the public rebuke of AT&T was unusual. AT&T’s action, it said, threatens the integrity of the entire self-regulatory system.
NAD procedures state that companies participating in the system agree “not to mischaracterize any decision, abstract, or press release issued or use and/or disseminate such decision, abstract or press release for advertising and/or promotional purposes.”
The NAD said:
In direct violation of this, AT&T has run an ad and issued a press release making representations regarding the alleged results of a competitor’s participation in BBB National Program’s advertising industry self-regulatory process.
The integrity and success of the self-regulatory forum hinges on the voluntary agreement of participants in an NAD proceeding to abide by the rules set forth in the BBB National Programs’ Procedures. As a voluntary process, fair dealing on the part of the parties is essential and requires adherence to both the letter and the spirit of the process.
AT&T’s violation of its agreement under the Procedures and its misuse of NAD’s decisions for promotional purposes undermines NAD’s mission to promote truth and accuracy of advertising claims and foster consumer trust in the marketplace.
AT&T omits its own history of misleading ads
The NAD told Ars that “we did issue a cease-and-desist letter to AT&T on Friday, October 24, the day after the company issued its press release and launched the ad campaign. The letter demanded that AT&T immediately remove such violative promotional materials and cease all future dissemination.” A cease-and-desist letter can lead to a lawsuit, but the NAD told us it “will not speculate on potential next steps.”
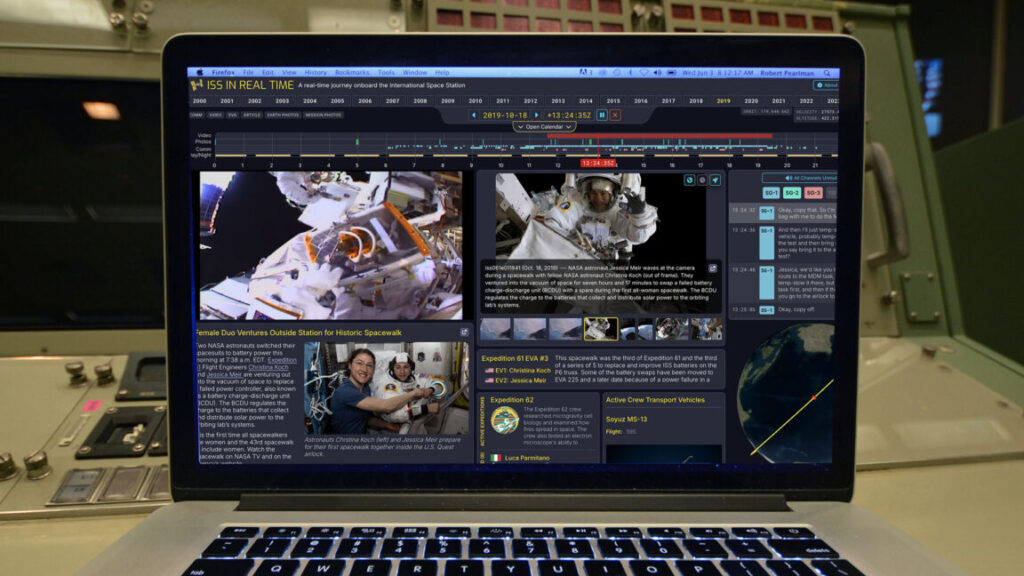
From the makers of Apollo in Real Time comes a site with 500 times more data.
The ISS in Real Time website was built by the same team behind Apollo 11 in Real Time but with more than 500 times the data from 25 years on board the International Space Station. Credit: collectSPACE.com
With the milestone just days away, you are likely to hear this week that there has now been a continuous human presence on the International Space Station (ISS) for the past 25 years. But what does that quarter of a century actually encompass?
Fortunately, the astronauts and cosmonauts on the space station have devoted some of their work time and a lot of their free time to taking photos, filming videos, and calling down to Earth. Much of that data has been made available to the public, but in separate repositories, with no real way to correlate or connect it with the timeline on which it was all created.
That is, not until now. Two NASA contractors, working only during their off hours, have built a portal into all of those resources to uniquely represent the 25-year history of ISS occupancy.
ISS in Real Time, by Ben Feist and David Charney, went live on Monday (October 27), ahead of the November 2 anniversary. In its own way, the new website may be as impressive a software engineering accomplishment as the station is an aerospace engineering marvel.
ISS in Real Time – Overview
Scraping space station data
“Everything that is on the website was already public. It’s already on another website somewhere, with some of it tucked away in some format or another. What we did was a lot of scraping of that data, to get it pulled into the context of every day on the space station,” said Feist in an interview with collectSPACE.com.
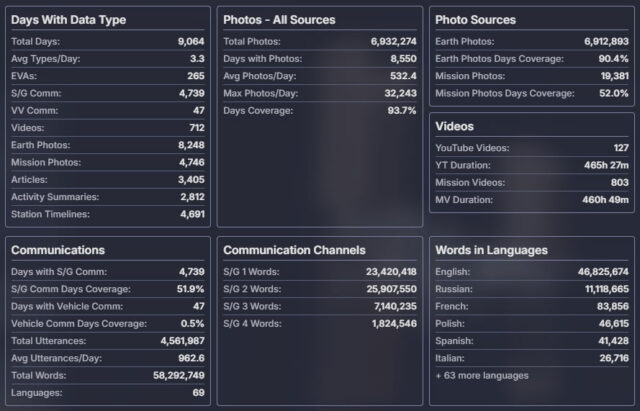
As an info box on the front page of ISS in Real Time tallies, at its debut the site contained mission data for 9,064 days out of the 9,131 (99.32 percent coverage); 4,739 days with full space-to-ground audio coverage; 4,561,987 space-to-ground comm calls in 69 languages; 6,931,369 photos taken in space over 8,525 days; 10,908 articles across 7,711 days; and 930 videos across 712 days.
Or, to put it another way, particularly appropriate for the history it spans, had this project relied only on the technology that existed when Expedition 1 began, the data archive would fill 3,846 CD-ROMs.
Statistical data about the contents of the ISS in Real Time website at its debut. Credit: ISS in Real Time
And they did all this in a period of about 11 months, but only in the hours when they were not at work writing software (Feist) or designing user interfaces (Charney) for Mission Control, the EVA (Extravehicular Activity, or spacewalk) Office, or other communities supporting the ISS and Artemis programs at NASA’s Johnson Space Center in Houston.
“Being inside NASA actually didn’t help at all,” said Feist. “If you’re inside NASA and you want to use data, you have to make sure that it’s public data. And because there’s this concept in the government of export control, you have to never, ever make the mistake of publishing an image or something else that you found somewhere else without knowing if it’s already public.”
“So even though we were at NASA, what we had to do was pretend we weren’t there and find the data anywhere we could find it in the public already,” he said.
As it turned out, that worked fairly well for days beginning in 2008 and onward. ISS occupancy, however, pre-dates a lot of the multimedia archives we take for granted today.
“This was the problem,” said Feist. “If stuff was released publicly back then, it was done to media on tape. There was no such thing as streaming video in 2000—YouTube wasn’t invented until 2005. So there’s just no way to go back in time on the Internet and go find the treasure trove that we know exists internally. We know NASA has full days archived on tape, but it just hasn’t been exported yet.”
Even after the change to digital photography and video, there still remained the challenge of linking each file to the day, hour, minute, and second that it was captured. For example, while the Internet Archive has been a tremendous source for the project, only sometimes do the videos it holds include the unique identifier that is needed to determine when the video was taken.
ISS in Real Time creators Ben Feist (at right) and David Charney stand inside the International Space Station control room at NASA’s Johnson Space Center in Houston, Texas. Credit: ISS in Real Time
In other situations, Feist turned to artificial intelligence to sort through the tens of thousands of files to learn if they were appropriate for inclusion.
“We know that NASA publishes all of its PAO [public affairs office] photos to Flickr. Right now, there are about 80,000 photos in just the Johnson Space Center collection on Flickr alone. So we scraped those, and then I wrote an AI process as part of the pipeline to figure out which of those photos were flight photos and which of them were ground photos, so that we only show flight photos,” he said.
Visualizing 25 years
As Feist was figuring out how to import all the data, Charney was figuring out how the public would access it all.
This is not the first project of its type that Feist and Charney have brought online. In 2019, they introduced Apollo 11 in Real Time, which did for the 50th anniversary of the first moon landing what ISS in Real Time does for the 25 years of human occupancy. Apollo 13 and Apollo 17 sites followed (and more Apollo missions are still to come, Feist and Charney say).
They also built a version of ISS in Real Time for NASA, called Coda, which has been in use internally at the space agency for the past four years.
Even with all of that as a foundation, designing the user interface for ISS in Real Time required Charney to wrap his head around all of the different ways people would be using the site.
“The entire site is an experience,” Charney told collectSPACE. “Just the idea that we could visualize 25 years of what went on, or that we even have every day over the past 25 years in here, is something we wanted to explore and feel the data throughout those 25 years.”
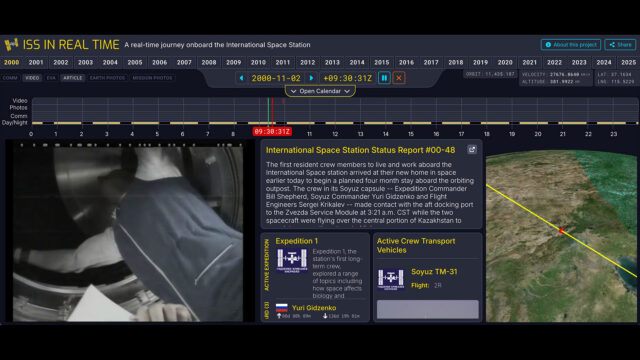
ISS in Real Time begins 25 years ago on Nov. 2, 2000, with the ISS Expedition 1 crew’s arrival at the space station. Credit: collectSPACE.com
One of the questions was what users would find if they picked a day when no data is available. How could they still make it interesting and still play as though you were in Mission Control?
“Some days have all of the media available—video and tons of photos. And then there are other days where there is no data. There are a lot of days that have at least a photo, but for others, we found there are a lot of great articles we could use so that even on a day that doesn’t have a lot of media, there is some interesting information you can access,” said Charney.
Through Charney’s design, in addition to the data coming from the space station, users can also see where the ISS was in its orbit over Earth, which astronauts were aboard the station, and what spacecraft were docked at any given moment. Visitors can also access transcripts of the space-to-ground comm audio, including translations when the discussion is not in English.
Feist and Charney plan to continue to build out the site and add more data as it is released by NASA, so it remains as close to as “in real time” as possible. They also have ideas for other data sets they could add, including the archived and live telemetry that provide the status of systems and conditions aboard the ISS.
Ultimately, it is the longevity of ISS in Real Time that sets it apart, they said.
“One thing that’s cool about this is you can go to the first day that the Expedition One crew was aboard and let it play. It will then play all the way through that day’s timeline and go to the next day, and then play all the way through that timeline and go to the next day,” said Charney. “So if you start on November 2 and have 25 years to go, the space station, as currently planned, will likely have long met its end before you reach the end.”
“So this might be the longest interactive experience ever built,” said Feist.
Robert Pearlman is a space historian, journalist and the founder and editor of collectSPACE, a daily news publication and online community focused on where space exploration intersects with pop culture. He is also a contributing writer for Space.com and co-author of “Space Stations: The Art, Science, and Reality of Working in Space” published by Smithsonian Books in 2018. He is on the leadership board for For All Moonkind and is a member of the American Astronautical Society’s history committee.
Several receipts shown to the FT by expense management platforms demonstrated the realistic nature of the images, which included wrinkles in paper, detailed itemization that matched real-life menus, and signatures.
“This isn’t a future threat; it’s already happening. While currently only a small percentage of non-compliant receipts are AI-generated, this is only going to grow,” said Sebastien Marchon, chief executive of Rydoo, an expense management platform.
The rise in these more realistic copies has led companies to turn to AI to help detect fake receipts, as most are too convincing to be found by human reviewers.
The software works by scanning receipts to check the metadata of the image to discover whether an AI platform created it. However, this can be easily removed by users taking a photo or a screenshot of the picture.
To combat this, it also considers other contextual information by examining details such as repetition in server names and times and broader information about the employee’s trip.
“The tech can look at everything with high details of focus and attention that humans, after a period of time, things fall through the cracks, they are human,” added Calvin Lee, senior director of product management at Ramp.
Research by SAP in July found that nearly 70 percent of chief financial officers believed their employees were using AI to attempt to falsify travel expenses or receipts, with about 10 percent adding they are certain it has happened in their company.
Mason Wilder, research director at the Association of Certified Fraud Examiners, said AI-generated fraudulent receipts were a “significant issue for organizations.”
He added: “There is zero barrier for entry for people to do this. You don’t need any kind of technological skills or aptitude like you maybe would have needed five years ago using Photoshop.”
It’s still legal to pick locks, even when you swing your legs.
“Opening locks” might not sound like scintillating social media content, but Trevor McNally has turned lock-busting into online gold. A former US Marine Staff Sergeant, McNally today has more than 7 million followers and has amassed more than 2 billion views just by showing how easy it is to open many common locks by slapping, picking, or shimming them.
This does not always endear him to the companies that make the locks.
On March 3, 2025, a Florida lock company called Proven Industries released a social media promo video just begging for the McNally treatment. The video was called, somewhat improbably, “YOU GUYS KEEP SAYING YOU CAN EASILY BREAK OFF OUR LATCH PIN LOCK.” In it, an enthusiastic man in a ball cap says he will “prove a lot of you haters wrong.” He then goes hard at Proven’s $130 model 651 trailer hitch lock with a sledgehammer, bolt cutters, and a crowbar.
Naturally, the lock hangs tough.
An Instagram user brought the lock to McNally’s attention by commenting, “Let’s introduce it to the @mcnallyofficial poke.” Someone from Proven responded, saying that McNally only likes “the cheap locks lol because they are easy and fast.” Proven locks were said to be made of sterner stuff.
But on April 3, McNally posted a saucy little video to social media platforms. In it, he watches the Proven promo video while swinging his legs and drinking a Juicy Juice. He then hops down from his seat, goes over to a Proven trailer hitch lock, and opens it in a matter of seconds using nothing but a shim cut from a can of Liquid Death. He says nothing during the entire video, which has been viewed nearly 10 million times on YouTube alone.
Despite practically begging people to attempt this, Proven Industries owner Ron Lee contacted McNally on Instagram. “Just wanted to say thanks and be prepared!” he wrote. McNally took this as a threat.
(Oddly enough, Proven’s own homepage features a video in which the company trashes competing locks and shows just how easy it is to defeat them. And its news pages contain articles and videos on “The Hidden Flaws of Master Locks” and other brands. Why it got so upset about McNally’s video is unclear.)
The next day, Lee texted McNally’s wife. The message itself was apparently Lee’s attempt to de-escalate things; he says he thought the number belonged to McNally, and the message itself was unobjectionable. But after the “be prepared!” notice of the day before, and given the fact that Lee already knew how to contact him on Instagram, McNally saw the text as a way “to intimidate me and my family.” That feeling was cemented when McNally found out that Lee was a triple felon—and that in one case, Lee had hired someone “to throw a brick through the window of his ex-wife.”
Concerned about losing business, Lee kept trying to shut McNally down. Proven posted a “response video” on April 6 and engaged with numerous social media commenters, telling them that things were “going to get really personal” for McNally. Proven employees alleged publicly that McNally was deceiving people about all the prep work he had done to make a “perfectly cut out” shim. Without extensive experience, long prep work, and precise measurements, it was said, Proven’s locks were in little danger of being opened by rogue actors trying to steal your RV.
“Sucks to see how many people take everything they see online for face value,” one Proven employee wrote. “Sounds like a bunch of liberals lol.”
Proven also had its lawyers file “multiple” DMCA takedown notices against the McNally video, claiming that its use of Proven’s promo video was copyright infringement.
McNally didn’t bow to the pressure, though, instead uploading several more videos showing him opening Proven locks. In one of them, he takes aim at Proven’s claims about his prep work by retrieving a new lock from an Amazon delivery kiosk, taking it outside—and popping it in seconds using a shim he cuts right on camera, with no measurements, from an aluminum can.
Help us write more stories like this—while ditching ads
Ars subscribers support our independent journalism, which they can read ad-free and with enhanced privacy protections. And it’s only a few bucks a month.
On May 1, Proven filed a federal lawsuit against McNally in the Middle District of Florida, charging him with a huge array of offenses: (1) copyright infringement, (2) defamation by implication, (3) false advertising, (4) violating the Florida Deceptive and Unfair Trade Practices Act, (5) tortious interference with business relationships, (6) unjust enrichment, (7) civil conspiracy, and (8) trade libel. Remarkably, the claims stemmed from a video that all sides admit was accurate and in which McNally himself said nothing.
In retrospect, this was probably not a great idea.
Don’t mock me, bro
How can you defame someone without even speaking? Proven claimed “defamation by implication,” arguing that the whole setup of McNally’s videos was unfair to the company and its product. McNally does not show his prep work, which (Proven argued) conveys to the public the false idea that Proven’s locks are easy to bypass. While the shimming does work, Proven argued that it would be difficult for an untrained user to perform.
But what Proven really, really didn’t like was being mocked. McNally’s decision to drink—and shake!—a juice box on video comes up in court papers a mind-boggling number of times. Here’s a sample:
McNally appears swinging his legs and sipping from an apple juice box, conveying to the purchasing public that bypassing Plaintiff’s lock is simple, trivial, and even comical…
…showing McNally drinking from, and shaking, a juice box, all while swinging his legs, and displaying the Proven Video on a mobile device…
The tone, posture, and use of the juice box prop and childish leg swinging that McNally orchestrated in the McNally Video was intentional to diminish the perceived seriousness of Proven Industries…
The use of juvenile imagery, such as sipping from a juice box while casually applying the shim, reinforces the misleading impression that the lock is inherently insecure and marketed deceptively…
The video then abruptly shifts to Defendant in a childlike persona, sipping from a juice box and casually applying a shim to the lock…
In the end, Proven argued that the McNally video was “for commercial entertainment and mockery,” produced for the purpose of “humiliating Plaintiff.” McNally, it was said, “will not stop until he destroys Proven’s reputation.” Justice was needed. Expensive, litigious justice.
But the proverbially level-headed horde of Internet users does not always love it when companies file thermonuclear lawsuits against critics. Sometimes, in fact, the level-headed horde disregards everything taught by that fount of judicial knowledge, The People’s Court, and they take the law into their own hands.
Proven was soon the target of McNally fans. The company says it was “forced to disable comments on posts and product videos due to an influx of mocking and misleading replies furthering the false narrative that McNally conveyed to the viewers.” The company’s customer service department received such an “influx of bogus customer service tickets… that it is experiencing difficulty responding to legitimate tickets.”
Proven was quite proud of its lawsuit… at first.
Someone posted Lee’s personal phone number to the comment section of a McNally video, which soon led to “a continuous stream of harassing phone calls and text messages from unknown numbers at all hours of the day and night,” which included “profanity, threats, and racially charged language.”
Lest this seem like mere high spirits and hijinks, Lee’s partner and his mother both “received harassing messages through Facebook Messenger,” while other messages targeted Lee’s son, saying things like “I would kill your f—ing n—– child” and calling him a “racemixing pussy.”
This is clearly terrible behavior; it also has no obvious connection to McNally, who did not direct or condone the harassment. As for Lee’s phone number, McNally said that he had nothing to do with posting it and wrote that “it is my understanding that the phone number at issue is publicly available on the Better Business Bureau website and can be obtained through a simple Google search.”
And this, with both sides palpably angry at each other, is how things stood on June 13 at 9: 09 am, when the case got a hearing in front of the Honorable Mary Scriven, an extremely feisty federal judge in Tampa. Proven had demanded a preliminary injunction that would stop McNally from sharing his videos while the case progressed, but Proven had issues right from the opening gavel:
LAWYER 1: Austin Nowacki on behalf of Proven industries. THE COURT: I’m sorry. What is your name? LAWYER 1: Austin Nowacki. THE COURT: I thought you said Austin No Idea. LAWYER 2: That’s Austin Nowacki. THE COURT: All right.
When Proven’s lead lawyer introduced a colleague who would lead that morning’s arguments, the judge snapped, “Okay. Then you have a seat and let her speak.”
Things went on this way for some time, as the judge wondered, “Did the plaintiff bring a lock and a beer can?” (The plaintiff did not.) She appeared to be quite disappointed when it was clear there would be no live shimming demonstration in the courtroom.
Then it was on to the actual arguments. Proven argued that the 15 seconds of its 90-second promo video used by McNally were not fair use, that McNally had defamed the company by implication, and that shimming its locks was actually quite difficult. Under questioning, however, one of Proven’s employees admitted that he had been able to duplicate McNally’s technique, leading to the question from McNally’s lawyer: “When you did it yourself, did it occur to you for one moment that maybe the best thing to do, instead of file a lawsuit, was to fix [the lock]?”
At the end of several hours of wrangling, the judge stepped in, saying that she “declines to grant the preliminary injunction motion.” For her to do so, Proven would have to show that it was likely to win at trial, among other things; it had not.
As for the big copyright infringement claim, of which Proven had made so much hay, the judge reached a pretty obvious finding: You’re allowed to quote snippets of copyrighted videos in order to critique them.
“The purpose and character of the use to which Mr. McNally put the alleged infringed work is transformative, artistic, and a critique,” said the judge. “He is in his own way challenging and critiquing Proven’s video by the use of his own video.”
As for the amount used, it was “substantial enough but no more than is necessary to make the point that he is trying to critique Proven’s video, and I think that’s fair game and a nominative fair use circumstance.”
While Proven might convince her otherwise after a full trial, “the copyright claim fails as a basis for a demand for preliminary injunctive relief.”
As for “tortious interference” and “defamation by implication,” the judge was similarly unimpressed.
“The fact that you might have a repeat customer who is dissuaded to buy your product due to a criticism of the product is not the type of business relationship the tortious interference with business relationship concept is intended to apply,” she said.
In the end, the judge said she would see the case through to its end, if that was really what everyone wanted, but “I will pray that you all come to a resolution of the case that doesn’t require all of this. This is a capitalist market and people say what they say. As long as it’s not false, they say what they say.”
She gave Proven until July 7 to amend its complaint if it wished.
On July 7, the company dismissed the lawsuit against McNally instead.
Proven also made a highly unusual request: Would the judge please seal almost the entire court record—including the request to seal?
Court records are presumptively public, but Proven complained about a “pattern of intimidation and harassment by individuals influenced by Defendant McNally’s content.” According to the company, a key witness had already backed out of the case, saying, “Is there a way to leave my name and my companies name out of this due to concerns of potential BLOW BACK from McNally or others like him?” Another witness, who did submit a declaration, wondered, “Is this going to be public? My concern is that there may be some backlash from the other side towards my company.”
McNally’s lawyer laid into this seal request, pointing out that the company had shown no concern over these issues until it lost its bid for a preliminary injunction. Indeed, “Proven boasted to its social media followers about how it sued McNally and about how confident it was that it would prevail. Proven even encouraged people to search for the lawsuit.” Now, however, the company “suddenly discover[ed] a need for secrecy.”
The judge has not yet ruled on the request to seal.
Another way
The strange thing about the whole situation is that Proven actually knew how to respond constructively to the first McNally video. Its own response video opened with a bit of humor (the presenter drinks a can of Liquid Death), acknowledged the issue (“we’ve had a little bit of controversy in the last couple days”), and made clear that Proven could handle criticism (“we aren’t afraid of a little bit of feedback”).
The video went on to show how their locks work and provided some context on shimming attacks and their likelihood of real-world use. It ended by showing how users concerned about shimming attacks could choose more expensive but more secure lock cores that should resist the technique.
Quick, professional, non-defensive—a great way to handle controversy.
But it was all blown apart by the company’s angry social media statements, which were unprofessional and defensive, and the litigation, which was spectacularly ill-conceived as a matter of both law and policy. In the end, the case became a classic example of the Streisand Effect, in which the attempt to censor information can instead call attention to it.
Judging from the number of times the lawsuit talks about 1) ridicule and 2) harassment, it seems like the case quickly became a personal one for Proven’s owner and employees, who felt either mocked or threatened. That’s understandable, but being mocked is not illegal and should never have led to a lawsuit or a copyright claim. As for online harassment, it remains a serious and unresolved issue, but launching a personal vendetta—and on pretty flimsy legal grounds—against McNally himself was patently unwise. (Doubly so given that McNally had a huge following and had already responded to DMCA takedowns by creating further videos on the subject; this wasn’t someone who would simply be intimidated by a lawsuit.)
In the end, Proven’s lawsuit likely cost the company serious time and cash—and generated little but bad publicity.
A South Korean rocket startup will soon make its first attempt to reach low-Earth orbit.
The Orion spacecraft for the Artemis II mission is lowered on top of the Space Launch System rocket at Kennedy Space Center, Florida.
Welcome to Edition 8.16 of the Rocket Report! The 10th anniversary of SpaceX’s first Falcon 9 rocket landing is coming up at the end of this year. We’re still waiting for a second company to bring back an orbital-class booster from space for a propulsive landing. Two companies, Jeff Bezos’ Blue Origin and China’s LandSpace, could join SpaceX’s exclusive club as soon as next month. (Bezos might claim he’s already part of the club, but there’s a distinction to be made.) Each company is in the final stages of launch preparations—Blue Origin for its second New Glenn rocket, and LandSpace for the debut flight of its Zhuque-3 rocket. Blue Origin and LandSpace will both attempt to land their first stage boosters downrange from their launch sites. They’re not exactly in a race with one another, but it will be fascinating to see how New Glenn and Zhuque-3 perform during the uphill and downhill phases of flight, and whether one or both of the new rockets stick the landing.
As always, we welcome reader submissions. If you don’t want to miss an issue, please subscribe using the box below (the form will not appear on AMP-enabled versions of the site). Each report will include information on small-, medium-, and heavy-lift rockets, as well as a quick look ahead at the next three launches on the calendar.
The race for space-based interceptors. The Trump administration’s announcement of the Golden Dome missile defense shield has set off a race among US companies to develop and test space weapons, some of them on their own dime, Ars reports. One of these companies is a 3-year-old startup named Apex, which announced plans to test a space-based interceptor as soon as next year. Apex’s concept will utilize one of the company’s low-cost satellite platforms outfitted with an “Orbital Magazine” containing multiple interceptors, which will be supplied by an undisclosed third-party partner. The demonstration in low-Earth orbit could launch as soon as June 2026 and will test-fire two interceptors from Apex’s Project Shadow spacecraft. The prototype interceptors could pave the way for operational space-based interceptors to shoot down ballistic missiles. (submitted by biokleen)
Usual suspects … Traditional defense contractors are also getting in the game. Northrop Grumman’s CEO, Kathy Warden, said earlier this year that her company is already testing space-based interceptor components on the ground. This week, Lockheed Martin announced it is on a path to test a space-based interceptor in orbit by 2028. Neither company has discussed as much detail of their plans as Apex revealed this week.
The easiest way to keep up with Eric Berger’s and Stephen Clark’s reporting on all things space is to sign up for our newsletter. We’ll collect their stories and deliver them straight to your inbox.
Lockheed Martin’s latest “New Space” investment. As interest grows in rotating detonation engines for hypersonic flight, a startup specialist in the technology says it will receive backing from Lockheed Martin’s corporate venture capital arm, Aviation Week & Space Technology reports. The strategic investment by Lockheed Martin Ventures “reflects the potential of Venus’s dual-use technology” in an era of growing defense and space spending, Venus Aerospace said in a statement. Venus said its partnership with Lockheed Martin combines the former’s startup mindset with the latter’s resources and industry expertise. The companies did not announce the value of Lockheed’s investment, but Venus said it has raised $106 million since its founding in 2020. Lockheed Martin Ventures has made similar investments in other rocket startups, including Rocket Lab in 2015.
What’s this actually for? … Houston-based Venus Aerospace completed a high-thrust test flight of its Rotating Detonation Rocket Engine (RDRE) in May from Spaceport America, New Mexico. Rotating detonation engine technology is interesting because it has the potential to significantly increase fuel efficiency in various applications, from Navy carriers to rocket engines, Ars reported earlier this year. The engine works by producing a shockwave with a flow of detonation traveling through a circular channel. The engine harnesses these supersonic detonation waves to generate thrust. “Venus has proven in flight the most efficient rocket engine technology in history,” said Sassie Duggleby, co-founder and CEO of Venus Aerospace. “With support from Lockheed Martin Ventures, we will advance our capabilities to deliver at scale and deploy the engine that will power the next 50 years of defense, space, and commercial high-speed aviation.”
South Korean startup receives permission to fly. Innospace announced on October 20 that it has received South Korea’s first private commercial launch permit from the Korea AeroSpace Administration,” the Chosun Daily reports. Accordingly, Innospace will launch its independently developed “HANBIT-Nano” launch vehicle from a Brazilian launch site as early as late this month. Innospace stated that the launch window for this mission has been set for October 28 through November 28. The launch site is the Alcântara Space Center, operated by the Brazilian Air Force.
Aiming for LEO … This will be the first flight of Innospace’s HANBIT-Nano launch vehicle, standing roughly 72 feet (22 meters) tall with a diameter of 4.6 feet (1.4 meters). The two-stage rocket is powered by hybrid propulsion, consuming a mixture of paraffin and liquid oxygen. For its debut flight, the rocket will target an orbit about 300 kilometers (186 miles) high with a batch of small satellites from customers in South Korea, Brazil, and India. According to Innospace, HANBIT-Nano can lift about 200 pounds (90 kilograms) of payload into orbit.
A new record for rocket reuse. SpaceX’s launch of a Falcon 9 rocket from Florida on October 19 set a new record for reusable rockets, Ars reports. It marked the 31st launch of the company’s most-flown Falcon 9 booster. The rocket landed on SpaceX’s recovery ship in the Atlantic Ocean to be returned to Florida for a 32nd flight. Several more rockets in SpaceX’s inventory are nearing their 30th launch. In all, SpaceX has more than 20 Falcon 9 boosters in its fleet on both the East and West Coasts. SpaceX engineers are now certifying the Falcon 9 boosters for up to 40 flights apiece.
10,000 and counting … SpaceX’s two launches last weekend weren’t just noteworthy for Falcon 9 lore. Hours after setting the new booster reuse record, SpaceX deployed a batch of 28 Starlink satellites from a different rocket after lifting off from California. This mission propelled SpaceX’s Starlink program past a notable milestone. With the satellites added to the constellation on Sunday, the company has delivered more than 10,000 mass-produced Starlink spacecraft to low-Earth orbit. The exact figure stands at 10,006 satellites, according to a tabulation by Jonathan McDowell, an astrophysicist who expertly tracks comings and goings between Earth and space. About 8,700 of these Starlink satellites are still in orbit, with SpaceX adding more every week.
China is on the cusp of something big. Launch startup LandSpace is in the final stages of preparations for the first flight of its Zhuque-3 rocket and a potentially landmark mission for China, Space News reports. LandSpace said it completed the first phase of the Zhuque-3 rocket’s inaugural launch campaign this week. The Zhuque-3 is the largest commercial rocket developed to date in China, nearly matching the size and performance of SpaceX’s Falcon 9, with nine first stage engines and a single upper stage engine. One key difference is that the Zhuque-3 burns methane fuel, while Falcon 9’s engines consume kerosene. Most notably, LandSpace will attempt to land the rocket’s first stage booster at a location downrange from the launch site, similar to the way SpaceX lands Falcon 9 boosters on drone ships at sea. Zhuque-3’s first stage will aim for a land-based site in an experiment that could pave the way for LandSpace to reuse rockets in the future.
Testing status … The recent testing at Jiuquan Satellite Launch Center in northwestern China included a propellant loading demonstration and a static fire test of the rocket’s first stage engines. Earlier this week, LandSpace integrated the payload fairing on the rocket. The company said it will return the rocket to a nearby facility “for inspection and maintenance in preparation for its upcoming orbital launch and first stage recovery.” The launch is expected to happen as soon as next month.
Uprated Ariane 6 won’t launch until next year. Arianespace has confirmed that the first flight of the more powerful, four-booster variant of the Ariane 6 rocket will not be launched until 2026, European Spaceflight reports. The first Ariane 64 rocket had been expected to launch in late 2025, carrying the first batch of Amazon’s Project Kuiper satellites. On October 16, Arianespace announced the fourth and final Ariane 6 flight of the year would carry a pair of Galileo satellites for Europe’s global satellite navigation system in December. This will follow an already-scheduled Ariane 6 launch scheduled for November 4. Both of the upcoming flights will employ the same Ariane 6 configuration used on all of the rocket’s flights to date. This version, known as Ariane 62, has two strap-on solid rocket boosters.
Kuiper soon … The Ariane 64 variant will expose the rocket to stronger forces coming from four solid rocket boosters, each producing about a million pounds (4,500 kilonewtons) of thrust. ArianeGroup, the rocket’s manufacturer, said a year ago that it completed qualification of the Ariane 6 upper stage to withstand the stronger launch loads. Arianespace didn’t offer any explanation of the Ariane 64’s delay from this year to next, but it did confirm the uprated rocket will be the company’s first flight of 2026. The mission will be the first of 18 Arianespace flights dedicated to launching Amazon’s Project Kuiper broadband satellites, adding Ariane 6 to the mix of rockets deploying the Internet network in low-Earth orbit.
Duffy losing confidence in Starship. NASA acting Administrator Sean Duffy made two television appearances on Monday morning in which he shook up the space agency’s plans to return humans to the Moon, Ars reports. Speaking on Fox News, where the secretary of transportation frequently appears in his acting role as NASA chief, Duffy said SpaceX has fallen behind in developing the Starship vehicle as a lunar lander. Duffy also indirectly acknowledged that NASA’s projected target of a 2027 crewed lunar landing is no longer achievable. Accordingly, he said he intended to expand the competition to develop a lander capable of carrying humans down to the Moon from lunar orbit and back.
The rest of the story … “They’re behind schedule, and so the President wants to make sure we beat the Chinese,” Duffy said of SpaceX. “He wants to get there in his term. So I’m in the process of opening that contract up. I think we’ll see companies like Blue [Origin] get involved, and maybe others. We’re going to have a space race in regard to American companies competing to see who can actually lead us back to the Moon first.” The timing of Duffy’s public appearances on Monday seems tailored to influence a fierce, behind-the-scenes battle to hold onto the NASA leadership position. Jared Isaacman, who Trump nominated and then withdrew for the NASA posting, is again under consideration at the White House to become the agency’s next full-time administrator. (submitted by zapman987)
Rocket fully stacked for Artemis II. “The last major hardware component before Artemis II launches early next year has been installed,” NASA’s acting Administrator Sean Duffy posted on X Monday. Over the weekend, ground teams at Kennedy Space Center in Florida hoisted the Orion spacecraft for the Artemis II mission atop its Space Launch System rocket inside the Vehicle Assembly Building. This followed the transfer of the Orion spacecraft to the VAB from a nearby processing facility last week. With Orion installed, the rocket is fully assembled to its complete height of 322 feet (98 meters) tall.
Four months away? … NASA is still officially targeting no earlier than February 5, 2026, for the launch of the Artemis II mission. This will be the first flight of astronauts to the vicinity of the Moon since 1972, and the first glimpse of human spaceflight beyond low-Earth orbit for several generations. Upcoming milestones in the Artemis II launch campaign include a countdown demonstration inside the VAB, where the mission’s four-person crew will take their seats in the Orion spacecraft to simulate what they’ll go through on launch day.
New Glenn staged for rollout. Dave Limp, Blue Origin’s CEO, posted a video this week of the company’s second New Glenn rocket undergoing launch preparations inside a hangar at Launch Complex 36 at Cape Canaveral, Florida. The rocket’s first and second stages are now mated together and installed on the transporter erector that will carry them from the hangar to the launch pad. “We will spend the next days on final checkouts and connecting the umbilicals. Stay tuned for rollout and hotfire!” Limp wrote.
“Big step toward launch” … The connection of New Glenn’s stages and integration on the transporter erector marks a “big step toward launch,” Limp wrote. A launch sometime in November is still possible if engineers can get through a smooth test-firing of the rocket’s seven main engines on the launch pad. The rocket will send two NASA spacecraft on a journey to Mars.
China launches clandestine satellite. China launched a Long March 5 rocket Thursday with a classified military satellite heading toward geosynchronous orbit, Space News reports. The satellite is named TJS-20, and the circumstances of the launch—using China’s most powerful operational rocket—suggest TJS-20 could be the next in a line of signals intelligence-gathering missions. The previous satellite of this line, TJS-11, launched in February 2024, also on a Long March 5.
Doing a lot … This launch continued China’s increasing use of the Long March 5 and its sister variant, the Long March 5B. The Long March 5 is expendable, and although we don’t know how much it costs, it can’t be cheap. It is a complex rocket powered by 10 engines on its core stage and four boosters, some burning liquid hydrogen fuel and others burning kerosene. The second stage also has two cryogenically fueled engines. The Long March 5 has now flown 16 times in nine years and seven times within the last two years. The uptick in launches is largely due to China’s use of the Long March 5 to launch satellites for the Guowang megaconstellation.
Next three launches
Oct. 25: Falcon 9 | Starlink 11-12 | Vandenberg Space Force Base, California | 14: 00 UTC
Oct. 26: H3 | HTV-X 1 | Tanegashima Space Center, Japan | 00: 00 UTC
Oct. 26: Long March 3B/E | Unknown Payload | Xichang Satellite Launch Center | 03: 50 UTC
Stephen Clark is a space reporter at Ars Technica, covering private space companies and the world’s space agencies. Stephen writes about the nexus of technology, science, policy, and business on and off the planet.
Yesterday, Donald Trump announced on social media that he had been planning to “surge” troops into San Francisco this weekend—but was dissuaded from doing so by several tech billionaires.
“Friends of mine who live in the area called last night to ask me not to go forward with the surge,” Trump wrote.
Who are these “friends”? Trump named “great people like [Nvidia CEO] Jensen Huang, [Salesforce CEO] Marc Benioff, and others” who told him that “the future of San Francisco is great. They want to give it a ‘shot.’ Therefore, we will not surge San Francisco on Saturday. Stay tuned!”
Ludicrously wealthy tech execs have exerted unparalleled sway over Trump in the last year. Not content with obsequious flattery—at one recent White House dinner, Sam Altman called Trump “a pro-business, pro-innovation president” who was “a very refreshing change,” while Tim Cook praised the legendarily mercurial Trump’s “focus and your leadership”—tech leaders have also given Trump shiny awards, built him a bulletproof ballroom, and donated massive sums to help him get elected.
Most of these execs also have major business before the federal government and have specific “asks” around AI regulation, crypto, tariffs, regulations, and government contracts.
Now, tech execs are even helping to shape the militarization of American cities.
Consider Benioff, for instance. On October 10, he gave an interview to The New York Times in which he spoke to a reporter “by telephone from his private plane en route to San Francisco.” (Benioff lives in Hawaii most of the time now.)
His big annual “Dreamforce” conference was about to take place in San Francisco, and Benioff lamented the fact that he had to hire so much security to make attendees feel safe. (Over the last decade, several Ars staffers have witnessed various unpleasant incidents involving urine, sidewalk feces, and drug use during visits around downtown San Francisco, so concerns about the city are not illusory, though critics say they are overblown.)
Donald Trump is eyeing taking equity stakes in quantum computing firms in exchange for federal funding, The Wall Street Journal reported.
At least five companies are weighing whether allowing the government to become a shareholder would be worth it to snag funding that the Trump administration has “earmarked for promising technology companies,” sources familiar with the potential deals told the WSJ.
IonQ, Rigetti Computing, and D-Wave Quantum are currently in talks with the government over potential funding agreements, with minimum awards of $10 million each, some sources said. Quantum Computing Inc. and Atom Computing are reportedly “considering similar arrangements,” as are other companies in the sector, which is viewed as critical for scientific advancements and next-generation technologies.
No deals have been completed yet, sources said, and terms could change as quantum-computing firms weigh the potential risks of government influence over their operations.
Quantum-computing exec called deals “exciting”
In August, Intel agreed to give the US a 10 percent stake in the company, then admitted to shareholders that “it is difficult to foresee all the potential consequences” of the unusual arrangement. If the deal goes through, the US would become Intel’s largest shareholder, the WSJ noted, potentially influencing major decisions that could prompt layoffs or restrict business in certain foreign markets.
“Among other things, there could be adverse reactions, immediately or over time, from investors, employees, customers, suppliers, other business or commercial partners, foreign governments, or competitors,” Intel wrote in a securities filing. “There may also be litigation related to the transaction or otherwise and increased public or political scrutiny with respect to the Company.”
But quantum computing companies that are closest to entering deals appear optimistic about possible government involvement.
Quantum Computing Inc. chief executive Yuping Huang told the WSJ that “the government’s potential equity stakes in companies in the industry are exciting.” The funding could be one of “the first significant signs of support for the sector from Washington,” the WSJ noted, potentially paving the way for breakthroughs such as Google’s recent demonstration of a quantum algorithm running 13,000 times faster than a supercomputer.
Apple’s iPhone Air was the company’s most interesting new iPhone this year, at least insofar as it was the one most different from previous iPhones. We came away impressed by its size and weight in our review. But early reports suggest that its novelty might not be translating into sales success.
A note from analyst Ming-Chi Kuo, whose supply chain sources are often accurate about Apple’s future plans, said yesterday that demand for the iPhone Air “has fallen short of expectations” and that “both shipments and production capacity” were being scaled back to account for the lower-than-expected demand.
Kuo’s note is backed up by reports from other analysts at Mizuho Securities (via MacRumors) and Nikkei Asia. Both of these reports say that demand for the iPhone 17 and 17 Pro models remains strong, indicating that this is just a problem for the iPhone Air and not a wider slowdown caused by tariffs or other external factors.
The standard iPhone, the regular-sized iPhone Pro, and the big iPhone Pro have all been mainstays in Apple’s lineup, but the company has had a harder time coming up with a fourth phone that sells well enough to stick around. The small-screened iPhone mini and the large-screened iPhone Plus were each discontinued after two generations.