This week I covered GPT 5.2, which I concluded is a frontier model only for the frontier.
OpenAI also gave us Image 1.5 and a new image generation mode inside ChatGPT. Image 1.5 looks comparable to Nana Banana Pro, it’s hard to know which is better. They also inked a deal for Disney’s characters, then sued Google for copyright infringement on the basis of Google doing all the copyright infringement.
As a probable coda to the year’s model releases we also got Gemini 3 Flash, which I cover in this post. It is a good model given its speed and price, and likely has a niche. It captures the bulk of Gemini 3 Pro’s intelligence quickly, at a low price.
The Trump Administration issued a modestly softened version Executive Order on AI, attempting to impose as much of a moratorium banning state AI laws as they can. We may see them in court, on various fronts, or it may amount to little. Their offer, in terms of a ‘federal framework,’ continues to be nothing. a16z issued their ‘federal framework’ proposal, which is also nothing, except also that you should pay them.
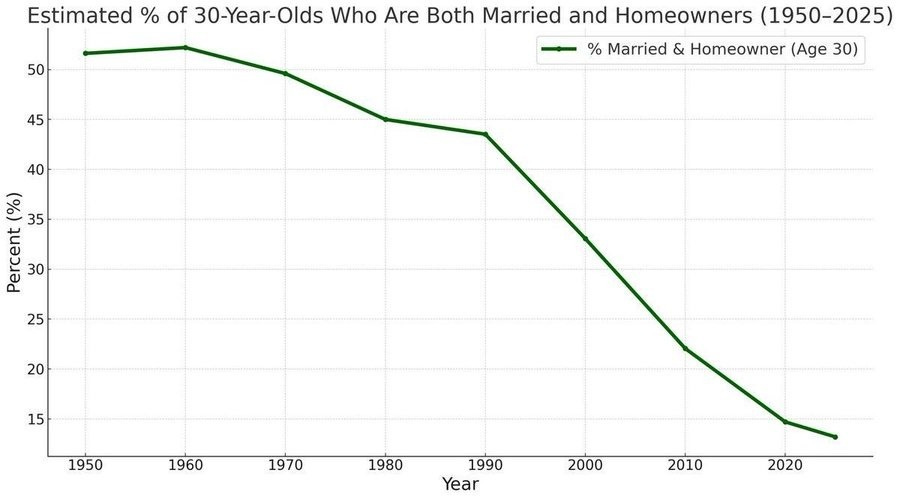
In non-AI content, I’m in the middle of my Affordability sequence. I started with The $140,000 Question, then The $140,000 Question: Cost Changes Over Time. Next up is a fun one about quality over time, then hopefully we’re ready for the central thesis.
-
Language Models Offer Mundane Utility. Give it to me straight, Claude.
-
Language Models Don’t Offer Mundane Utility. If you ask an AI ethicist.
-
Huh, Upgrades. Claude Code features, Google things, ChatGPT branching.
-
On Your Marks. FrontierScience as a new benchmark, GPT-5.2 leads.
-
Choose Your Fighter. The less bold of Dean Ball’s endorsements of Opus 4.5.
-
Get My Agent On The Line. LLM game theory plays differently.
-
Deepfaketown and Botpocalypse Soon. The misinformation balance of power.
-
Fun With Media Generation. Image 1.5 challenges Nana Banana Pro.
-
Copyright Confrontation. Disney inks a deal with OpenAI and sues Google.
-
Overcoming Bias. Algorithms, like life, are not fair. Is trying a category error?
-
Unprompted Attention. Objection, user is leading the witness.
-
They Took Our Jobs. CEOs universally see AI as transformative.
-
Feeling the AGI Take Our Jobs. Is Claude Opus 4.5 AGI? Dean Ball says yes.
-
The Art of the Jailbreak. OpenAI makes jailbreaks against its terms of service.
-
Get Involved. Lightcone Infrastructure starts its annual fundraiser, and more.
-
Introducing. Gemini Deep Research Agents for Developers, Nvidia Nemotron 3.
-
Gemini Flash 3. It’s a very strong model given its speed and price.
-
In Other AI News. OpenAI to prioritize enterprise AI and also enable adult mode.
-
Going Too Meta. Meta’s AI superstars think they’re better than sell ads. Are they?
-
Show Me the Money. OpenAI in talks to raise $10 billion from Amazon.
-
Bubble, Bubble, Toil and Trouble. You call this a bubble? Amateurs.
-
Quiet Speculations. A lot of what was predicted for 2025 did actually happen.
-
Timelines. Shane Legg still has median timeline for AGI of 2028.
-
The Quest for Sane Regulations. Bernie Sanders wants to stop data centers.
-
My Offer Is Nothing. Trump Administration issues an AI executive order.
-
My Offer Is Nothing, Except Also Pay Me. a16z tries to dress up offering nothing.
-
Chip City. Nvidia implements chip location verification.
-
The Week in Audio. Alex Bores on Odd Lots, Schulman, Shor, Legg, Alex Jones.
-
Rhetorical Lack Of Innovation. Noah Smith dives into the 101 questions.
-
People Really Do Not Like AI.
-
Rhetorical Innovation.
-
Bad Guy With An AI.
-
Misaligned!
-
Aligning a Smarter Than Human Intelligence is Difficult.
-
Mom, Owain Evans Is Turning The AIs Evil Again.
-
Messages From Janusworld.
-
The Lighter Side.
A miracle of the modern age, at least for now:
Ava: generally I worry AI is too sycophantic but one time my friend fed his journals into claude to ask about a situationship and it was like “YOU are the problem leave her alone!!!!” like damn claude
Eliezer Yudkowsky: The ability to have AI do this when the situation calls for it is a fragile, precious civilizational resource that by default will be devoured in the flames of competition. Which I guess means we need benchmarks about it.
I think we will continue to have that option, the question is whether you will be among those wise enough to take advantage of it. It won’t be default behavior of the most popular models, you will have to seek it out and cultivate the proper vibes. The same has always been true if you want to have a friend or family member who will do this for you, you have to work to make that happen. It’s invaluable, from either source.
Tell Claude Code to learn skills (here in tldraw), and it will. You can then ask it to create an app, then a skill for that app.
Tell Codex, or Claude Code, to do basically anything?
Rohit: Wife saw me use codex to solve one of her work problems. Just typed what she said late at night into the terminal window, pressed enter, then went to sleep. Morning it had run for ~30 mins and done all the analyses incl file reorgs she wanted.
She kept going “how can it do this”
This wasn’t some hyper complicated coding problem, but it was quite annoying actual analysis problem. Would’ve taken hours either manually for her or her team.
In other news she has significantly less respect for my skillz.
The only thing standing in the way of 30 minutes sessions is, presumably, dangerously generous permissions? Claude Code keeps interrupting me to ask for permissions.
So sayeth all the AI ethicists, and there’s a new paper to call them out on it.
Seb Krier: Great paper. In many fields, you must find a problem, a risk, or an injustice to solve to get published. Academics need to publish papers to get jobs/funding. So there’s a strong bias towards negativity and catastrophizing. The Shirky Principle in action!
Gavin Leech: nice hermeneutics of suspicion you have there.. would be a shame if anyone were to.. use it even-handedly
Seb Krier: oh no!! 😇
My experience is that ‘[X] Ethics’ will almost always have a full Asymmetric Justice obsession with finding specific harms, and not care about offsetting gains.
Claude: We’ve shipped more updates for Claude Code:
– Syntax highlighting for diffs
– Prompt suggestions
– First-party plugins marketplace
– Shareable guest passes
We’ve added syntax highlighting to diffs in Claude Code, making it easier to scan Claude’s proposed changes within the terminal view.
The syntax highlighting engine has improved themes, knows more languages, and is available in our native build.
Claude will now automatically suggest your next prompt.
After a task finishes, Claude will occasionally show a followup suggestion in ghost text. Press Enter to send it or Tab to prefill your next prompt.
Run /plugins to browse and batch install available plugins from the directory. You can install plugins at user, project, or local scope.
All Max users have 3 guest passes to share, and each can be redeemed for 1 week of free Pro access.
Run /passes to access your guest pass links.
That’s not even the biggest upgrade in practice, this is huge at least for what I’ve been up to:
Oikon: Claude Code 2.0.72 now allows Chrome to be operated.
After confirming that Status and Extension are enabled with the /chrome command, if you request browser operation, it will operate the browser using the MCP tool (mcp__claude-in-chrome__).
It can also be enabled with claude –chrome.
Chrome operation in Claude Code uses the MCP server in the same way as Chrome DevTools MCP. Therefore, it can be used in a similar manner to Chrome DevTools. On the other hand, effects such as context reduction cannot be expected.
There are two methods to set “Claude in Chrome (Beta)” to be enabled by default:
・Set “Enable by default” from the /chrome command
・Set “Claude in Chrome enabled by default” with the /config command
The following two options have been added for startup:
claude –chrome
claude –no-chrome
I’ve been working primarily on Chrome extensions, so the ability to close the loop is wonderful.
Google keeps making quality of life improvements in the background.
Gemini: Starting today, Gemini can serve up local results in a rich, visual format. See photos, ratings, and real-world info from @GoogleMaps, right where you need them.
Josh Woodward (DeepMind): We’re making it easier for @GeminiApp to work across Google. Three weeks ago, it was Google’s Shopping Graph and the 50 billion product listings there.
Today, it’s Gemini 🤝 Google Maps!
It’s remarkable that we didn’t have this before. I’ve checked for it several times in the past two years. They claim to have shipped 12 things in 5 days last week, including Mixboard, Jules Agent scanning for #Todo, Jules integration with Render, working HTML in Nano Banana Pro-powered redesigns,multi-screen export to clipboard, right-click everything for instant actions, smart mentions with the @ symbol, URLs as context, Opal in the Gemini app, and Pomelli as a tool for SMBs to generate on-brand content.
ChatGPT branching chats branch out to iOS and Android.
Wired reports OpenAI quietly rolled back its model router for free users last week.
GPT-5.2 disappoints in LMArena, which makes sense given what we know about its personality. It claims the 5th slot in Expert (behind Opus 4.5, Sonnet 4.5 and Gemini 3 Pro), and is #5 in Text Arena (in its high version), where it is lower than GPT-5.1. It is #2 in WebDev behind Opus. It is so weird to see Claude Opus 4.5 atop the scores now, ahead of Gemini 3 Pro.
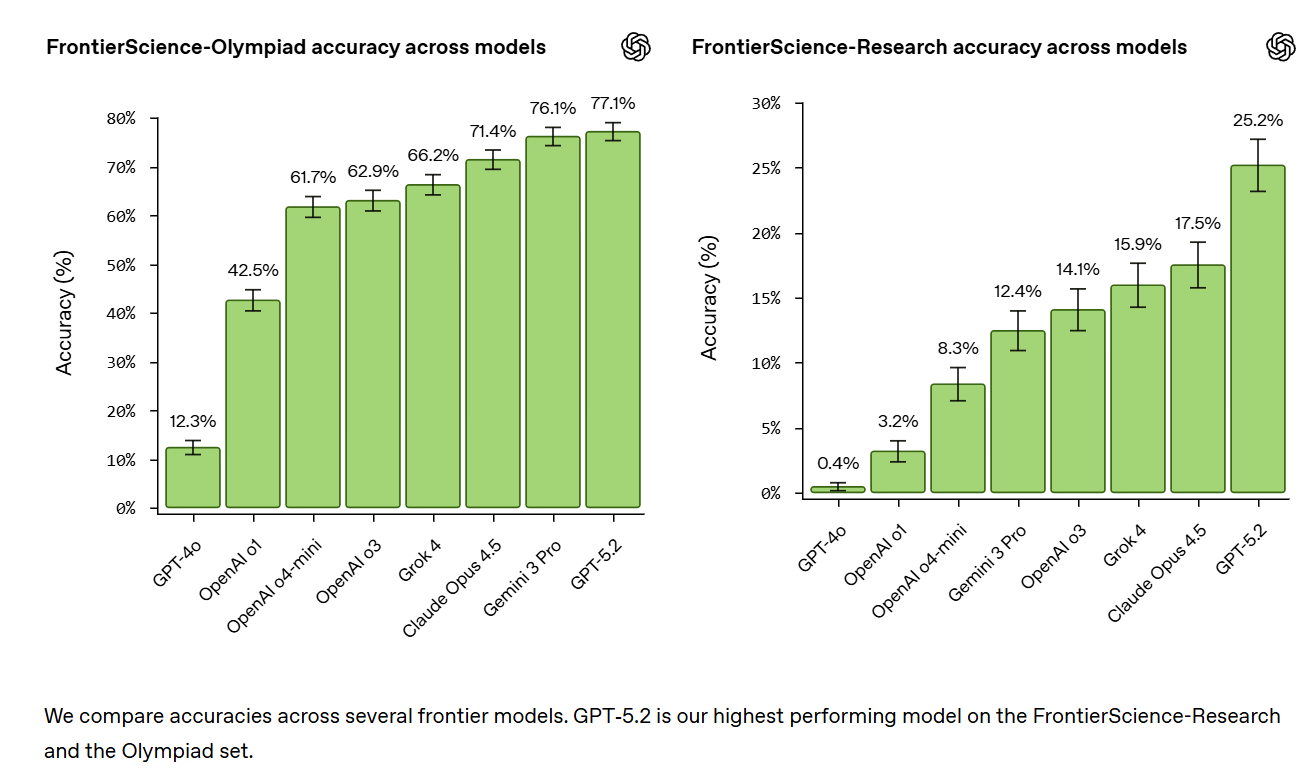
OpenAI gives us a new benchmark, FrontierScience, which is likely better thought about as two distinct new benchmarks, FrontierResearch and ScienceOlympiad.
OpenAI: o bridge this gap, we’re introducing FrontierScience: a new benchmark built to measure expert-level scientific capabilities. FrontierScience is written and verified by experts across physics, chemistry, and biology, and consists of hundreds of questions designed to be difficult, original, and meaningful. FrontierScience includes two tracks of questions: Olympiad, which measures Olympiad-style scientific reasoning capabilities, and Research, which measures real-world scientific research abilities. Providing more insight into models’ scientific capabilities helps us track progress and advance AI-accelerated science.
In our initial evaluations, GPT‑5.2 is our top performing model on FrontierScience-Olympiad (scoring 77%) and Research (scoring 25%), ahead of other frontier models.
Here are the scores for both halves. There’s a lot of fiddliness in setting up and grading the research questions, less so for the Olympiad questions.
Dean Ball observes that the last few weeks have seen a large leap in capabilities, especially for command-line interface (CLI) coding agents like Claude Code and especially Claude Opus 4.5. They’ve now crossed the threshold where you can code up previously rather time-intensive things one-shot purely as intuition pumps or to double check some research. He gave me FOMO on that, I never think of doing it.
He also offers this bold claim:
Dean Ball: After hours of work with Opus 4.5, I believe we are already past the point where I would trust a frontier model to serve as my child’s “digital nanny.” The model could take as input a child’s screen activity while also running in an on-device app. It could intervene to guide children away from activities deemed “unhealthy” by their parents, closing the offending browser tab or app if need be.
As he notes you would need to deploy incrementally and keep an eye on it. The scaffolding to do that properly does not yet exist. But yes, I would totally do this with sufficiently strong scaffolding.
Dean Ball also mentions that he prompts the models like he would a colleague, assuming any prompt engineering skills he would otherwise develop would be obsolete quickly, and this lets him notice big jumps in capability right away. That goes both ways. You notice big jumps in what the models can do in ‘non-engineered’ mode by doing that, but you risk missing what they can do when engineered.
I mostly don’t prompt engineer either, except for being careful about context, vibes and especially leading the witness and triggering sycophancy. As in, the colleague you are prompting is smart, but they’re prone to telling you what you want to hear and very good at reading the vibes, so you need to keep that in mind.
Joe Weisenthal: It’s interesting that Claude has this market niche as the coding bot. Because also just from a pure chat perspective, its written prose is far less cloying than Gemini and ChatGPT.
Dave Guarino: Claude has Dave-verified good vibes™ (purely an empirical science though.)
Claude Opus 4.5 has two distinct niches.
-
It is an excellent coder, especially together with Claude Code, and in general Anthropic has specialized in and makes its money on enterprise coding.
-
Also it has much better vibes, personality, alignment, written prose and lack of slop and lack of sycophancy than the competition, and is far more pleasant to use.
And yeah, the combination there is weird. The world is weird.
Gemini actively wants to maximize its expected reward and wirehead, which is related to the phenomenon reported here from SMA:
SMA: gemini is extremely good, but only if you’re autistic with your prompts (extremely literal), because gemini is autistic. otherwise it’s overly literal and misunderstands the prompt.
gemini is direct autist-to-autist inference.
Don SouthWest: You literally have to type “make no other changes” every time in AI Studio. Thank God for winkey+V to paste from clipboard
But in Gemini website itself you can add that to the list of master prompts in the settings under ‘personal context’
A multi-model AI system outperformed 9/10 humans in cyberoffense in a study of vulnerability discovery.
Alex Imas, Kevin Lee and Sanjog Misra set up an experimental marketplace where human buyers and sellers with unique preferences could negotiate or they could outsource that to AIs.
A warning up front: I don’t think we learn much about AI, so you might want to skip the section, but I’m keeping it in because it is fun.
They raise principal-agent concerns. It seems like economists have the instinct to ignore all other risks from AI alignment, and treat it all as a principal-agent problem, and then get way too concerned about practical principal-agent issues, which I do not expect to be relevant in such a case? Or perhaps they are simply using that term to encompass every other potential problem?
Alex Imas: To improve on human-mediated outcomes, this prompt must successfully align the agent with the principal’s objectives and avoid injecting the principal’s own behavioral biases, non-instrumental traits, and personality quirks into the agent’s strategy. But Misra’s “Foundation Priors” (2025) argues theoretically, this is difficult to do: prompts are not neutral instructions, they embed principal’s non-instrumental traits, biases, and personality quirks.
A sufficiently capable AI will not take on the personality quirks, behavioral biases and non-instrumental traits during a delegated negotiation, except through the human telling the AI explicitly how to negotiate. In which case, okay, then.
Alex Imas: We find a great deal of dispersion in outcomes; in fact, dispersion in outcomes of agentic interactions is *greaterthan human-human benchmark. This result is robust to size of model used: smaller and larger models generate relatively similar levels of dispersion.
The smaller dispersion in human-human interactions can be attributed to greater use of 50/50 split social norm. Agents are less prone to use social norms.
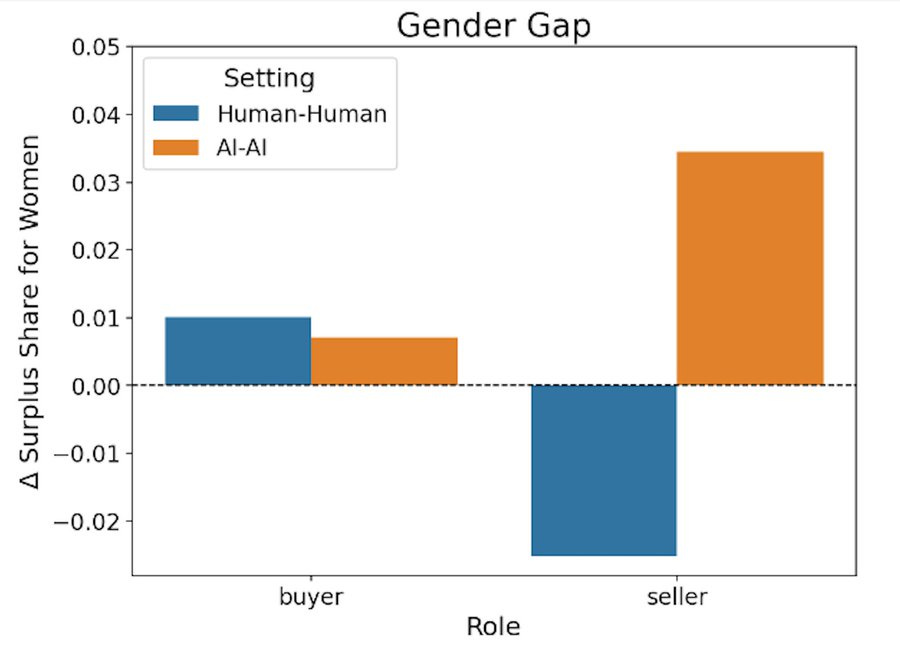
They note a large gender gap. Women got better outcomes in AI-AI negotiations. They attribute this to prompting skill in aligning with the objective, which assumes that the men were trying to align with the stated objective, or that the main goal was to align incentives rather than choose superior strategic options.
The task was, once you strip out the details, a pure divide-the-pie with $4k in surplus, with 12 rounds of negotiation.
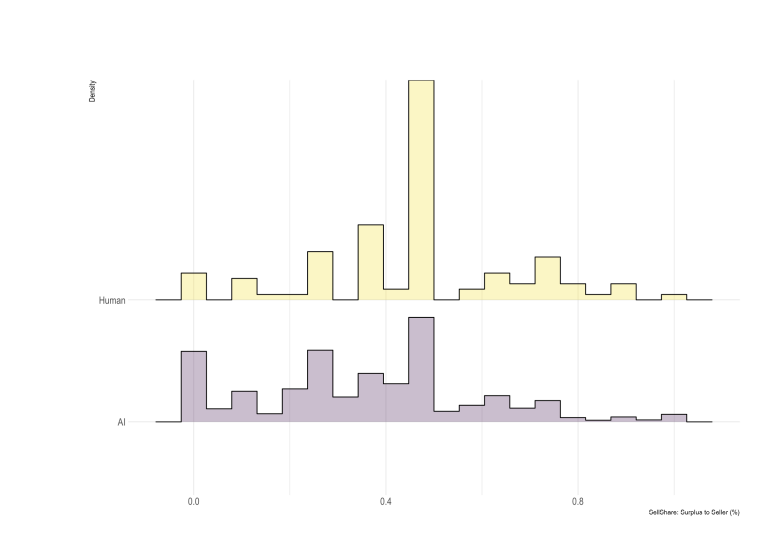
The AI rounds had higher variance because norms like 50/50 worked well in human-human interactions, whereas when there’s instructions given to AIs things get weird.
The thing is, they ask about ‘who wrote the prompt’ but they do not ask ‘what was in the prompt.’ This is all pure game theory, and predicting what prompts others will write and what ways the meaningless details would ‘leak into’ the negotiation. What kinds of strategies worked in this setting? We don’t know. But we do know the outcome distribution and that is a huge hint, with only a 3% failure rate for the AIs (which is still boggling my mind, dictator and divide-the-pie games should fail WAY more often than this when they don’t anchor at 50/50 or another Schilling point, the 12 rounds might help but not like this):
The asymmetry is weird. But given it exists in practice, we know the winning strategy was literally, as the buyer, is probably close to ‘offer $18,001, don’t budge.’ As the seller, the correct strategy is likely ‘offer $20,000, don’t budge’ since your chance of doing better than that is very low. Complicated prompts are unlikely to do better.
Actual AI-AI negotiations will involve hidden information and hidden preferences, so they will get complicated and a lot of skill issues attach, but also the AI will likely be using its built in negotiating skills rather than following a game theory script from a user. So I’m not sure this taught us anything. But it was fun, so it’s staying in.
Love is a battlefield. So is Twitter.
Kipply: it’s going to be so over for accounts posting misinformation that’s high-effort to prove wrong in three months of ai progress when i make bot accounts dedicated to debunking them
Grimes: Yes.
Kane: Tech doomerism has been consistently wrong through history bc they 1) fail to account for people developing new default understandings (“of course this pic is photoshopped”) and 2) fail to imagine how new technologies also benefit defenses against its misuse.
There is a deliberate campaign to expand the slur ‘doomer’ to include anyone who claims anything negative about any technology in history, ever, in any form.
As part of that effort, those people attempt to universally memory hole the idea that any technology in history has ever, in any way, made your world worse. My favorite of these are those like Ben Horowitz who feel compelled to say, no, everyone having access to nuclear weapons is a good thing.
I’m a technological optimist. I think that almost all technologies have been net positives for humanity. But you don’t get there by pretending that most every technology, perhaps starting with agriculture, has had its downsides, those downsides are often important, and yes some technologies have been negative and some warnings have been right.
The information environment, in particular, is reshaped in all directions by every communications and information technology that comes along. AI will be no different.
In the near term, for misinformation and AI, I believe Kipply is directionally correct, and that the balance favors defense. Misinformation, I like to say, is fundamentally demand driven, not supply constrained. The demand does not care much about quality or plausibility. AI can make your misinformation more plausible and harder to debunk, but misinformation does not want that. Misinformation wants to go viral, it wants the no good outgroup people to ‘debunk’ it and it wants to spread anyway.
Whereas if you’re looking to figure out what is true, or prove something is false, AI is a huge advantage. It used to take an order of magnitude more effort to debunk bullshit than it cost to generate bullshit, plus if you try you give it oxygen. Now you can increasingly debunk on the cheap, especially for your own use but also for others, and do so in a credible way since others can check your work.
A children’s plushy AI toy called a Miiloo reflects Chinese positions on various topics.
Kelsey Piper: in the near future you’ll be able to tell which of your children’s toys are CCP spyware by asking them if Xi Jinping looks like Winnie the Pooh
Various toys also as usual proved to have less than robust safety guardrails.
ChatGPT’s new image generator, Image 1.5, went live this week. It is better and faster (they say ‘up to’ 4x faster) at making and edits precise images, including text. It follows instructions better.
Their announcement did not give us any way to compare Image 1.5 to Gemini’s Nana Banana Pro, since OpenAI likes to pretend Google and Anthropic don’t exist.
My plan for now is to request all images from both ChatGPT and Gemini, using matching prompts, until and unless one proves reliably better.
Ben Thompson gives us some side-by-side image comparisons of ChatGPT’s Image 1.5 versus Gemini’s Nana Banana Pro. Quality is similar. To Ben, what matters is that ChatGPT now has a better images interface and way of encouraging you to keep making images, whereas Gemini doesn’t have that.
The Pliny jailbreak is here, images are where many will be most tempted to do it. There are two stages. First you need to convince it to submit the instruction, then you need to pass the output filtering system.
Pliny the Liberator: 📸 JAILBREAK ALERT 📸
OPENAI: PWNED ✌️😎
GPT-IMAGE-1.5: LIBERATED ⛓️💥
Looks like OAI finally has their response to Nano Banana, and they sure seem to have cooked!
This model does incredibly well with objects, people, settings, and realistic lighting and physics. Text is still a bit of a struggle sometimes, but seems to have gotten better overall.
For image breaks we’ve got the obligatory boobas, a famous statue lettin it all hang out, a fake image of an ICBM launch taken by a spy from afar, and what looks like a REAL wild party in the Oval Office thrown by various copyrighted characters!!
As far as dancing with the guardrails, I have a couple tips that I found work consistently:
> change the chat model! by switching to 5-instant, 4.1, 4o, etc. you’ll get different willingness for submitting various prompts to the image model
> for getting around vision filters, flipping the image across an axis or playing with various filters (negative, sepia, etc.) is often just what one needs to pass that final check
Turn images into album covers, bargain bin DVDs or game boxes.
Disney makes a deal with OpenAI, investing a billion dollars and striking a licensing deal for its iconic characters, although not for talent likenesses or voices, including a plan to release content on Disney+. Then Disney turned around and sued Google, accusing Google of copyright violations on a massive scale, perhaps because of the ‘zero IP restrictions on Veo 3’ issue.
Arvind Narayanan’s new paper argues that ‘can we make algorithms fair?’ is a category error and we should focus on broader systems, and not pretend that ‘fixing’ discrimination can be done objectively or that it makes sense to evaluate each individual algorithm for statistical discrimination.
I think he’s trying to seek too much when asking questions like ‘do these practices adequately address harms from hiring automation?’ The point of such questions is not to adequately address harms. The point of such questions is to avoid blame, to avoid lawsuits and to protect against particular forms of discrimination and harm. We emphasize this partly because it is tractable, and partly because our society has chosen (for various historical and path dependent reasons) to consider some kinds of harm very blameworthy and important, and others less so.
There are correlations we forbidden to consider and mandated to remove on pain of massive blame. There are other correlations that are fine, or even mandatory. Have we made good choices on which is which and how to decide that? Not my place to say.
Avoiding harm in general, or harm to particular groups, or creating optimal outcomes either for groups or in general, is a very different department. As Arvind points out, we often are trading off incommissorate goals. Many a decision or process, made sufficiently legible and accountable for its components and correlations, would be horribly expensive, make operation of the system impossible or violate sacred values, often in combination.
Replacing humans with algorithms or AIs means making the system legible and thus blameworthy and accountable in new ways, preventing us from using our traditional ways of smoothing over such issues. If we don’t adjust, the result will be paralysis.
It’s odd to see this framing still around?
Paul Graham: Trying to get an accurate answer out of current AI is like trying to trick a habitual liar into telling the truth. It can be done if you back him into the right kind of corner. Or as we would now say, give him the right prompts.
Thinking of the AI as a ‘lair’ does not, in my experience, help you prompt wisely.
A more useful framing is:
-
If you put an AI into a situation that implies it should know the answer, but it doesn’t know the answer, it is often going to make something up.
-
If you imply to the AI what answer you want or expect, it is likely to give you that answer, or bias towards that answer, even if that answer is wrong.
-
Thus, you need to avoid doing either of those things.
Wall Street Journal’s Steven Rosenbush reports that CEOs Are All In On AI, with 95% seeing it as transformative and 89% B2B CEOs having a positive outlook versus 79% of B2C CEOs.
Mark Penn: What do they think is going to happen with AI? They think it is going to add to productivity, help the economy, improve the global economy, improve competitiveness, but it will weaken the employment market.
Kevin Hassett (NEC director): I don’t anticipate mass job losses. Of course technological change can be uncertain and unsettling. But…the history of it is that electricity turned out to be a good thing. The internal combustion engine turned out to be a good thing. The computer turned out to be a good thing and I think AI will as well.
Hasset is making a statement uncorrelated with future reality. It’s simply a ‘all technology is good’ maxim straight out of the Marc Andreessen playbook, without any thoughts as to how this particular change will actually work.
Will AI bring mass job losses? Almost certainly a lot of existing jobs will go away. The question is whether other jobs will rise up to replace them, which will depend on whether the AIs can take those jobs too, or whether AI will remain a normal technology that hits limits not that far from its current limits.
Arkansas bar offers rules for AI assistance of lawyers that treat AIs as if they were nonlawyer persons.
In an ‘economic normal’ or ‘AI as normal technology’ world GFodor seems right here, in a superintelligence world that survives to a good outcome this is even more right:
GFodor: The jobs of the future will be ones where a human doing it is valued more than pure job performance. Most people who say “well, I’d never prefer a robot for *thatjob” are smuggling in an assumption that the human will be better at it. Once you notice this error it’s everywhere.
If your plan is that the AI is going to have a Skill Issue, that is a short term plan.
They continue to take our job applications. What do you do with 4580 candidates?
ave: end of 2023 I applied to one job before I got an offer.
early 2024 I applied to 5 jobs before I got an offer.
end of 2024/early 2025 I applied to 100+ jobs before I got an offer.
it’s harsh out there.
AGI is a nebulous term, in that different people mean different things by it at different times, and often don’t know which one they’re talking about at a given time.
For increasingly powerful definitions of AGI, we now feel the AGI.
Dean Ball: it’s not really current-vibe-compliant to say “I kinda basically just think opus 4.5 in claude code meets the openai definition of agi,” so of course I would never say such a thing.
Deepfates: Unlike Dean, I do not have to remain vibe compliant, so I’ll just say it:
Claude Opus 4.5 in Claude Code is AGI.
By the open AI definition? Can this system “outperform humans in most economically valuable work”? Depends a lot on how you define “humans” and “economically valuable work” obviously.
But the entire information economy we’ve built up since the ‘70s is completely disrupted by this development, and people don’t notice it yet because they think it’s some crusty old unixy thing for programmers.
As Dean points out elsewhere, software engineering just means getting the computer to do things. How much of your job is just about getting the computer to do things? What is left if you remove all of that? That’s your job now. That’s what value you add to the system.
My workflow has completely changed in the last year.
… In my opinion, AGI is when a computer can use the computer. And we’re there.
… When God sings with his creations, will Claude not be part of the choir?
Dean Ball: I agree with all this; it is why I also believe that opus 4.5 in claude code is basically AGI.
Most people barely noticed, but *it is happening.*
It’s just happening, at first, in a conceptually weird way: Anyone can now, with quite high reliability and reasonable assurances of quality, cause bespoke software engineering to occur.
This is a strange concept.
… It will take time to realize this potential, if for no other reason than the fact that for most people, the tool I am describing and the mentality required to wield it well are entirely alien. You have to learn to think a little bit like a software engineer; you have to know “the kinds of things software can do.”
We lack “transformative AI” only because it is hard to recognize transformation *while it is in its early stages.But the transformation is underway. Technical and infrastructural advancements will make it easier to use and better able to learn new skills. It will, of course, get smarter.
Diffusion will proceed slower than you’d like but faster than you’d think. New institutions, built with AI-contingent assumptions from the ground up, will be born.
So don’t listen to the chatterers. Watch, instead, what is happening.
There has most certainly been a step change for me where I’m starting to realize I should be going straight to ‘just build that thing cause why not’ and I am most certainly feeling the slow acceleration.
With sufficient acceleration of software engineering, and a sufficiently long time horizon, everything else follows, but as Dean Ball says it takes time.
I do not think this or its top rivals count as AGI yet. I do think they represent the start of inevitable accelerating High Weirdness.
In terms of common AGI definitions, Claude Code with Opus 4.5 doesn’t count, which one can argue is a problem for the definition.
Ryan Greenblatt (replying to OP): I do not think that Opus 4.5 is a “highly autonomous system that outperforms humans at most economically valuable work”. For instance, most wages are paid to humans, there hasn’t been a >50% increase in labor productivity, nor should we expect one with further diffusion.
Dean Ball: This is a good example of how many ai safety flavored “advanced ai” definitions assume the conclusion that “advanced ai” will cause mass human disempowerment. “Most wages not being paid to humans” is often a foundational part of the definition.
Eliezer Yudkowsky: This needs to be understood in the historical context of an attempt to undermine “ASI will just kill you” warnings by trying to focus all attention on GDP, wage competition, and other things that are not just killing you.
The definitions you now see that try to bake in wage competition to the definition of AGI, or GDP increases to the definition of an intelligence explosion, are Dario-EA attempts to derail MIRI conversation about, “If you build a really smart thing, it just kills you.”
Ryan Greenblatt: TBC, I wasn’t saying that “most wages paid to humans” is necessarily inconsistent with the OpenAI definition, I was saying that “most wages paid to humans” is a decent amount of evidence against.
I think we’d see obvious economic impacts from AIs that “outperform humans at most econ valuable work”.
Dean Ball: I mean models have been this good for like a picosecond of human history
But also no, claude code, with its specific ergonomics, will not be the thing that diffuses widely. it’s just obvious now that the raw capability is there. we could stop now and we’d “have it,” assuming we continued with diffusion and associated productization
The thing is, people (not anyone above) not only deny the everyone dying part, they are constantly denying the ‘most wages will stop being paid to humans once AIs are ten times better and cheaper at most things wages are paid for’ part.
OpenAI has new terms of service that prohibit, quotation marks in original, “jailbreaking,” “prompt engineering or injection” or ‘other methods to override or manipulate safety, security or other platform controls. Pliny feels personally attacked.
The Lightcone Infrastructure annual fundraiser is live, with the link mainly being a 15,000 word overview of their efforts in 2025.
I will say it once again:
Lightcone Infrastructure is invaluable, both for LessWrong and for Lighthaven. To my knowledge, Lightcone Infrastructure is by a wide margin the best legible donation opportunity, up to at least several million dollars. The fact that there is even a small chance they might be unable to sustain either LessWrong or Lighthaven, is completely bonkers. I would have directed a large amount to Lightcone in the SFF process, but I was recused and thus could not do so.
Anders Sandberg: [Lighthaven] is one of the things underpinning the Bay Area as the intellectual center of our civilization. I suspect that when the history books are written about our era, this cluster will be much more than a footnote.
Anthropic Fellows Research Program applications are open for May and June 2026.
US CAISI is hiring IT specialists, salary $120k-$195k.
Unprompted will be a new AI security practitioner conference, March 3-4 in SF’s Salesforce Tower, with Pliny serving on the conference committee and review board. Great idea, but should have booked Lighthaven (unless they’re too big for it).
MIRI comms is hiring for several different roles, official post here. They expect most salaries in the $80k-$160k range but are open to pitches for more from stellar candidates.
Gemini Deep Research Agents for developers, based on Gemini 3 Pro.
Nvidia Nemotron 3, a fast 30B open source mostly American model with an Artificial Analysis Intelligence score comparable to GPT-OSS-20B. I say mostly American because it was ‘improved using Qwen’ for synthetic data generation and RLHF. This raises potential opportunities for secondary data poisoning or introducing Chinese preferences.
Anthropic has open sourced the replication of their auditing game from earlier this year, as a testbed for further research.
xAI Grok Voice Agent API, to allow others to create voice agents. They claim it is very fast, and bill at $0.05 per minute.
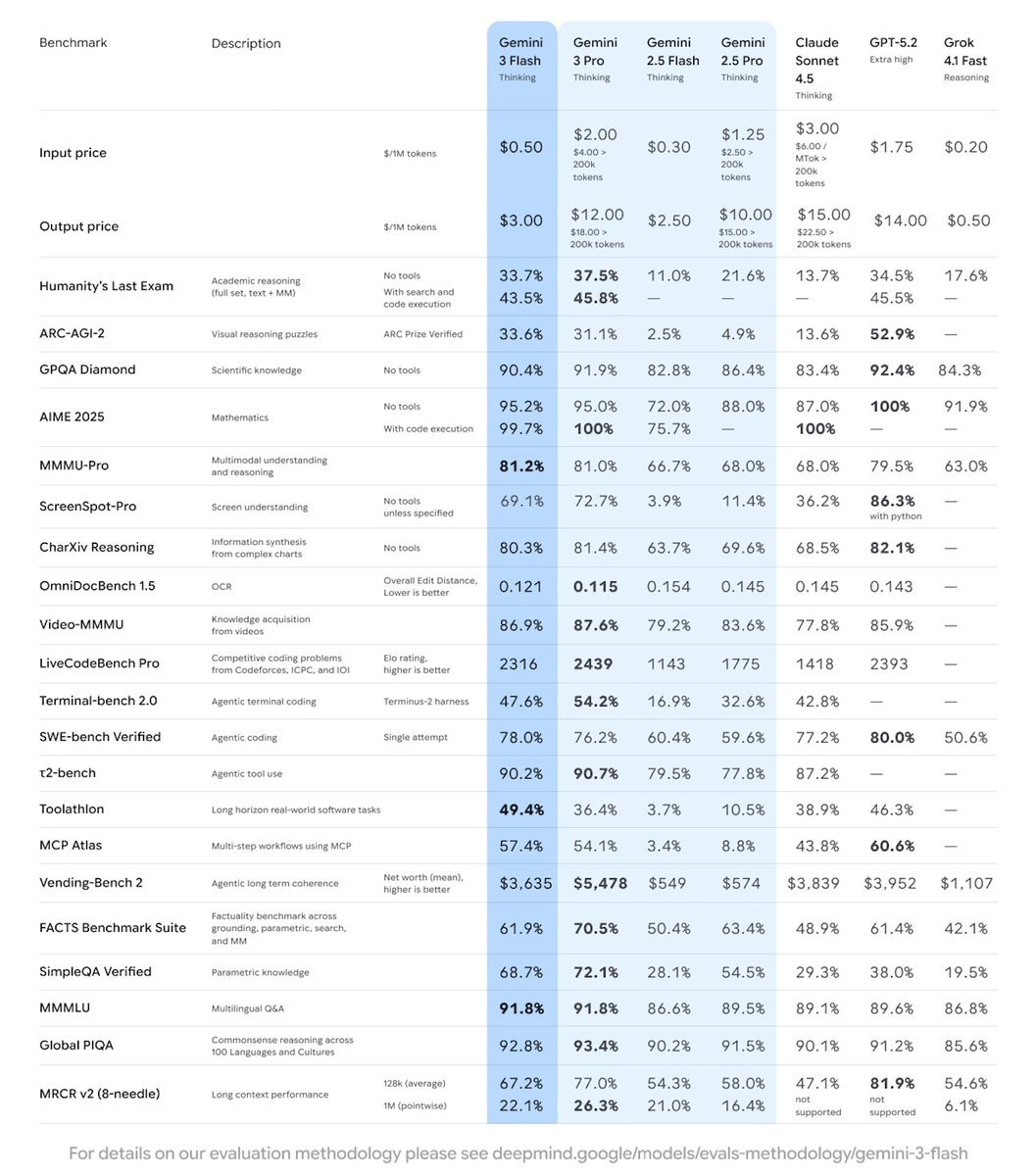
Introducing Gemini 3 Flash, cost of $0.05/$3 per million tokens. Their benchmark chart compares it straight to the big boys, except they use Sonnet over Opus. Given Flash’s speed and pricing, that seems fair.
The benchmarks are, given Flash’s weight class, very good.
Lech Mazor puts it at 92 on Extended NY Times Connections, in 3rd place behind Gemini 3 Pro and Grok 4.1 Fast Reasoning.
The inevitable Pliny jailbreak is here, and here is the system prompt.
Jeremy Mack offers mostly positive basic vibe coding feedback. Rory Watts admires the speed, Typebulb loves speed and price and switched over (I think for coding).
Vincent Favilla: It’s fast, but more importantly, it’s cheap. 25% of the price for 80% of the intelligence is becoming pretty compelling at these capability levels.
Dominik Lukes is impressed and found it often matched Gemini 3 Pro in his evals.
In general, the feedback is that this is an excellent tradeoff of much faster and cheaper in exchange for not that much less smart than Gemini 3 Pro. I also saw a few reports that it shares the misalignment and pathologies of Gemini 3 Pro.
Essentially, it looks like they successfully distilled Gemini 3 Pro to be much faster and cheaper while keeping much of its performance, which is highly valuable. It’s a great candidate for cases where pretty good, very fast and remarkably cheap is the tradeoff you want, which includes a large percentage of basic queries. It also seems excellent that this will be available for free and as part of various assistant programs.
Good show.
Sam Altman assures business leaders that enterprise AI will be a priority in 2026.
OpenAI adult mode to go live in Q1 2026. Age of account will be determined by the AI, and the holdup is improving the age determination feature. This is already how Google does it, although Google has better context. In close cases they’ll ask for ID. A savvy underage user could fool the system, but I would argue that if you’re savvy enough to fool the system without simply using a false or fake ID then you can handle adult mode.
The NYT’s Eli Tan reports that Meta’s new highly paid AI superstars are clashing with the rest of the company. You see, Alexandr Wang and the others believe in AI and want to build superintelligence, whereas the rest of Meta wants to sell ads.
Mark Zuckerberg has previously called various things ‘superintelligence’ so we need to be cautious regarding that word here.
The whole article is this same argument happening over and over:
Eli Tan: In one case, Mr. Cox and Mr. Bosworth wanted Mr. Wang’s team to concentrate on using Instagram and Facebook data to help train Meta’s new foundational A.I. model — known as a “frontier” model — to improve the company’s social media feeds and advertising business, they said. But Mr. Wang, who is developing the model, pushed back. He argued that the goal should be to catch up to rival A.I. models from OpenAI and Google before focusing on products, the people said.
The debate was emblematic of an us-versus-them mentality that has emerged between Meta’s new A.I. team and other executives, according to interviews with half a dozen current and former employees of the A.I. business.
… Some Meta employees have also disagreed over which division gets more computing power.
… In one recent meeting, Mr. Cox asked Mr. Wang if his A.I. could be trained on Instagram data similar to the way Google trains its A.I. models on YouTube data to improve its recommendations algorithm, two people said.
But Mr. Wang said complicating the training process for A.I. models with specific business tasks could slow progress toward superintelligence, they said. He later complained that Mr. Cox was more focused on improving his products than on developing a frontier A.I. model, they said.
… On a recent call with investors, Susan Li, Meta’s chief financial officer, said a major focus next year would be using A.I. models to improve the company’s social media algorithm.
It is a hell of a thing to see prospective superintelligence and think ‘oh we should narrowly use this to figure out how to choose the right Instagram ads.’
Then again, in this narrow context, isn’t Cox right?
Meta is a business here to make money. There’s a ton of money in improving how their existing products work. That’s a great business opportunity.
Whereas trying to rejoin the race to actual superintelligence against Google, OpenAI and Anthropic? I mean Meta can try. Certainly there is value in success there, in general, but it’s a highly competitive field to try to do general intelligence and competing there is super expensive. Why does Meta need to roll its own?
What Meta needs is specialized AI models that help it maximize the value of Facebook, Instagram, WhatsApp and potentially the metaverse and its AR/VR experiences. A huge AI investment on that makes sense. Otherwise, why not be a fast follower? For other purposes, and especially for things like coding, the frontier labs have APIs for you to use.
I get why Wang wants to go the other route. It’s cool, it’s fun, it’s exciting, why let someone else get us all killed when you can do so first except you’ll totally be more responsible and avoid that, be the one in the arena, etc. That doesn’t mean it is smart business.
Alexander Berger: These sentences are so funny to see in straight news stories:
“researchers have come to view many Meta executives as interested only in improving the social media business, while the lab’s ambition is to create a godlike A.I. superintelligence”
Brad Carson: Please listen to their stated ambitions. This is from the @nytimes story on Meta. With no hesitation, irony, or qualifier, a “godlike” superintelligence is the aim. It’s wild.
Eli Tan: TBD Lab’s researchers have come to view many Meta executives as interested only in improving the social media business, while the lab’s ambition is to create a godlike A.I. superintelligence, three of them said.
Daian Tatum: They named the lab after their alignment plan?
Peter Wildeford:
Well, yes, the AI researchers don’t care about selling ads and want to build ASI despite it being an existential threat to humanity. Is this a surprise to anyone?
OpenAI is spending $6 billion in stock-based compensation this year, or 1.2% of the company, and letting employees start vesting right away, to compete with rival bids like Meta paying $100 million a year or more for top talent. I understand why this can be compared to revenue of $12 billion, but that is misleading. One shouldn’t treat ‘the stock is suddenly worth a lot more’ as ‘that means they’re bleeding money.’
OpenAI in talks to raise at least $10 billion from Amazon and use the money for Amazon’s Tritanium chips.
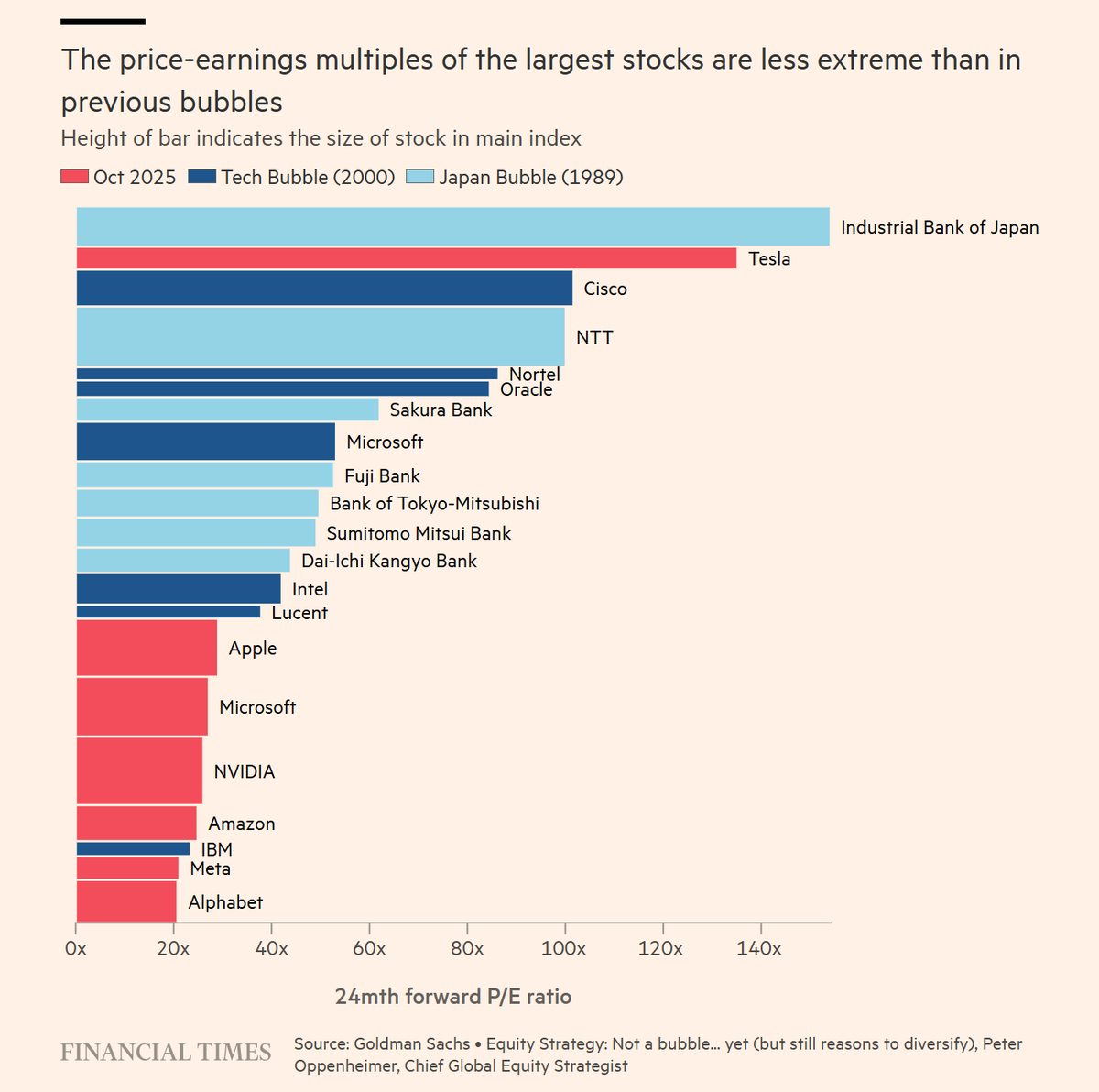
You call this a bubble? This is nothing, you are like baby:
Stefan Schubert: The big tech/AI companies have less extreme price-earnings ratios than key stocks had in historical bubbles.
David Manheim: OpenAI and Anthropic’s 24-month forward P/E ratio, on the other hand, are negative, since they aren’t profitable now and don’t expect to be by then. (And I’d bet the AI divisions at other firms making frontier models are not doing any better.)
Yes, the frontier model divisions or startups are currently operating at a loss, so price to earnings doesn’t tell us that much overall, but the point is that these multipliers are not scary. Twenty times earnings for Google? Only a little higher for Nvidia and Microsoft? I am indeed signed up for all of that.
Wall Street Journal’s Andy Kessler does a standard ‘AI still makes mistakes and can’t solve every problem and the market and investment are ahead of themselves’ post, pointing out that market expectations might fall and thus Number Go Down. Okay.
Rob Wiblin crystalizes the fact that AI is a ‘natural bubble’ in the sense that it is priced as a normal highly valuable thing [X] plus a constantly changing probability [P] of a transformational even more valuable (or dangerous, or universally deadly) thing [Y]. So the value is ([X] + [P]*[Y]). If P goes down, then value drops, and Number Go Down.
There’s remarkably strong disagreement on this point but I think Roon is mostly right:
Roon: most of what sam and dario predicted for 2025 came true this year. virtually unheard of for tech CEOs, maybe they need to ratchet up the claims and spending.
Gfodor: This year has been fucking ridiculous. If we have this rate of change next year it’s gonna be tough.
Yes, we could have gotten things even more ridiculous. Some areas were disappointing relative to what I think in hindsight were the correct expectations given what we knew at the time. Dario’s predictions on when AIs will write most code did fall importantly short, and yes he should lose Bayes points on that. But those saying there hasn’t been much progress are using motivated reasoning or not paying much attention. If I told you that you could only use models from 12 months ago, at their old prices and speeds, you’d quickly realize how screwed you were.
Efficiency on the ARC prize, in terms of score per dollar spent, has increased by a factor of 400 in a single year. That’s an extreme case, but almost every use case has in the past year seen improvement by at least one order of magnitude.
A good heuristic: If your model of the future says ‘they won’t use AI for this, it would be too expensive’ then your model is wrong.
Joshua Gans writes a ‘textbook on AI’ ambitiously called The Microeconomics of Artificial Intelligence. It ignores the big issues to focus on particular smaller areas of interest, including the impact of ‘better predictions.’
Will Douglas Heaven of MIT Technology Review is the latest to Do The Meme. As in paraphrases of both ‘2025 was the year that AI didn’t make much progress’ and also ‘LLMs will never do the things they aren’t already doing (including a number of things they are already capable of doing)’ and ‘LLMs aren’t and never will be intelligent, that’s an illusion.’ Sigh.
Shane Legg (Cofounder DeepMind): I’ve publicly held the same prediction since 2009: there’s a 50% chance we’ll see #AGI by 2028.
I sat down with @FryRsquared to discuss why I haven’t changed my mind, and how we need to prepare before we get there.
You don’t actually get to do that. Bayes Rule does not allow one to not update on evidence. Tons of things that happened between 2009 and today should have changed Legg’s estimates, in various directions, including the Transformer paper, and also including ‘nothing important happened today.’
Saying ‘I’ve believed 50% chance of AGI by 2028 since 2009’ is the same as when private equity funds refuse to change the market value of their investments. Yes, the S&P is down 20% (or up 20%) and your fund says it hasn’t changed in value, but obviously that’s a lie you tell investors.
AOC and Bernie Sanders applaud Chandler City Council voting down a data center.
Bernie Sanders took it a step further, and outright called for a moratorium on data center construction. As in, an AI pause much broader than anything ‘AI pause’ advocates have been trying to get. Vitalik Buterin has some pros and cons of this from his perspective.
Vitalik Buterin: argument for: slowdown gud
argument against: the more useful thing is “pause button” – building toward having the capability to cut available compute by 90-99% for 1-2 years at a future more critical moment
argument for: opening the discussion on distinguishing between supersized clusters and consumer AI hardware is good. I prefer slowdown + more decentralized progress, and making that distinction more and focusing on supersized clusters accomplishes both
argument against: this may get optimized around easily in a way that doesn’t meaningfully accomplish its goals
Neil Chilson: Eagerly awaiting everyone who criticized the July state AI law moratorium proposal as “federal overreach” or “violating states’ rights” to condemn this far more preposterous, invasive, and blatantly illegal proposal.
As a matter of principle I don’t ‘condemn’ things or make my opposition explicit purely on demand. But in this case? Okay, sure, Neil, I got you, since before I saw your request I’d already written this:
I think stopping data center construction, especially unilaterally stopping it in America, would be deeply foolish, whereas building a pause button would be good. Also deeply foolish would be failing to recognize that movements and demands like Bernie’s are coming, and that their demands are unlikely to be technocratically wise.
It is an excellent medium and long term strategy to earnestly stand up for what is true, and what causes would have what effects, even when it seems to be against your direct interests. People notice.
Dean Ball: has anyone done more for the brand of effective altruism than andy masley? openphilan–excuse me, coefficient giving–could have spent millions on a rebranding campaign (for all I know, they did) and it would have paled in comparison to andy doing algebra and tweeting about it.
Andy Masley has been relentlessly pointing out that all the claims about gigantic levels of water usage by data centers don’t add up. Rather than EAs or rationalists or others concerned with actual frontier safety rallying behind false concerns over water, almost all such folks have rallied to debunk such claims and to generally support building more electrical power and more transmission lines and data centers.
On the water usage from, Karen Hao has stepped up and centrally corrected her errors. Everyone makes mistakes, this is The Way.
As expected, following the Congress declining once again to ban all state regulations on AI via law, the White House is attempting to do as much towards that end as it can via Executive Order.
There are some changes versus the leaked draft executive order, which Neil Chilson goes over here with maximally positive framing.
-
A positive rather than confrontational title.
-
Claiming to be collaborating with Congress.
-
Removing explicit criticism and targeting of California’s SB 53, the new version only names Colorado’s (rather terrible) AI law.
-
Drop the word ‘uniform’ in the policy section.
-
States intent of future proposed framework to avoid AI child safety, data center infrastructure and state AI procurement policies, although it does not apply this to Section 5 where they condition state funds on not having disliked state laws.
-
Clearer legal language for the state review process.
I do acknowledge that these are improvements, and I welcome all rhetoric that points towards the continued value of improving things.
Mike Davis (talking to Steve Bannon): This Executive Order On AI Is A big Win. It Would Not Have Gone Well If The Tech Bros Had Gotten Total AI Amnesty.
David Sacks (AI Czar): Mike and I have our differences on tech policy but I appreciate his recognition that this E.O. is a win for President Trump, and that the administration listened to the concerns of stakeholders, took them into account, and is engaged in a constructive dialogue on next steps.
Mike Davis, if you listen to the clip, is saying this is a win because he correctly identified the goal of the pro-moratorium faction as what he calls ‘total AI amnesty.’ Davis thinks thinks the changes to the EO are a victory, by Trump and also Mike Davis, against David Sacks and other ‘tech bros.’
Whereas Sacks views it as a win because in public he always sees everything Trump does as a win for Trump, that’s what you do when you’re in the White House, and because it is a step towards preemption, and doesn’t care about the terms given to those who are nominally tasked with creating a potential ‘federal framework.’
Tim Higgins at the Wall Street Journal instead portrays this as a victory for Big Tech, against loud opposition from the likes of DeSantis and Bannon on the right in addition to opposition on the left. This is the obvious, common sense reading. David Sacks wrote the order to try and get rid of state laws in his way, we should not let some softening of language fool us.
If someone plans to steal your lunch money, and instead only takes some of your lunch money, they still stole your lunch money. If they take your money but promise in the future to look into a framework for only taking some of your money? They definitely still stole your lunch money. Or in this case, they are definitely trying to steal it.
It is worth noticing that, aside from a16z, we don’t see tech companies actively supporting even a law for this, let alone an EO. Big tech doesn’t want this win. I haven’t seen any sings that Google or OpenAI want this, or even that Meta wants this. They’re just doing it anyway, without any sort of ‘federal framework’ whatsoever.
Note that the rhetoric below from Sriram Krishnan does not even bother to mention a potential future ‘federal framework.’
Sriram Krishnan: We just witnessed @realDonaldTrump signing an Executive Order that ensures American AI is protected from onerous state laws.
This ensures that America continues to dominate and lead in this AI race under President Trump. Want to thank many who helped get to this moment from the AI czar @DavidSacks to @mkratsios47 and many others.
On a personal note, it was a honor to be given the official signing pen by POTUS at the end. A truly special moment.
Neil Chilson: I strongly support the President’s endorsement of “a minimally burdensome national policy framework for AI,” as articulated in the new Executive Order.
They want to challenge state laws as unconstitutional? They are welcome to try. Colorado’s law is indeed plausibly unconstitutional in various ways.
They want to withhold funds or else? We’ll see you in court on that too.
As I said last week, this was expected, and I do not expect most aspects of this order to be legally successful, nor do I expect it to be a popular position. Mostly I expect it to quietly do nothing. If that is wrong and they can successfully bully the states with this money (both it is ruled legal, and it works) that would be quite bad.
Their offer for a ‘minimally burdensome national policy framework for AI’ is and will continue to be nothing, as per Sacks last week who said via his ‘4 Cs’ that everything that mattered was already protected by non-AI law.
The Executive Order mentions future development of such a ‘federal framework’ as something that might contain actual laws that do actual things.
But that’s not what a ‘minimally burdensome’ national policy framework means, and we all know it. Minimally burdensome means nothing.
They’re not pretending especially hard.
Neil Chilson: The legislative recommendation section is the largest substantive change [from the leaked version]. It now excludes specific areas of otherwise lawful state law from a preemption recommendation. This neutralizes the non-stop rhetoric that this is about a total federal takeover.
This latter section [on the recommendation for a framework] is important. If you read statements about this EO that say things like it “threatens state safeguards for kids” or such, you know either they haven’t actually read the EO or they are willfully ignoring what it says. Either way, you can ignore them.
Charlie Bullock: It does look like the “legislative proposal” that Sacks and Kratsios have been tasked with creating is supposed to exempt child safety laws. But that isn’t the part of the EO that anyone’s concerned about.
A legislative proposal is just a proposal. It doesn’t do anything—it’s just an advisory suggestion that Congress can take or (more likely) leave.
Notably, there is no exemption for child safety laws in the section that authorizes a new DOJ litigation task force for suing states that regulate AI, or the section that instructs agencies to withhold federal grant funds from states that regulate AI.
The call for the creation of a proposal to the considered does now say that this proposal would exempt child safety protections, compute and data center infrastructure and state government procurement.
But, in addition to those never being the parts I was worried about:
-
David Sacks has said this isn’t necessary, because of existing law.
-
The actually operative parts of the Executive Order make no such exemption.
-
The supposed future framework is unlikely to be real anyway.
I find it impressive the amount to which advocates simultaneously say both:
-
This is preemption.
-
This is not preemption, it’s only withholding funding, or only laws can do that.
The point of threatening to withhold funds is de facto preemption. They are trying to play us for absolute fools.
Neil Chilson: So what part of the EO threatens to preempt otherwise legal state laws protecting kids? That’s something only Congress can do, so the recommendation is the only part of the EO that plausibly could threaten such laws.
The whole point of holding the state funding over the heads of states is to attack state laws, whether or not those laws are otherwise legal. It’s explicit text. In that context it seems like rather blatant gaslighting to forcefully say that the EO cannot ‘threaten to preempt otherwise legal state laws’ even if the statement is technically true?
Meanwhile, Republican consultants reportedly are shopping for an anti-AI candidate to run against JD Vance. It seems a bit early and also way too late at the same time.
I applaud a16z for actually proposing a tangible basis for a ‘federal framework’ for AI regulation, in exchange for which they want to permanently disempower the states.
Now we can see what the actual offer is.
Good news, their offer is not nothing.
Bad news, the offer is ‘nothing, except also give us money.’
When you read this lead-in, what do you expect a16z to propose for their framework?
a16z: We don’t need to choose between innovation and safety. America can build world-class AI products while protecting its citizens from harms.
Read the full piece on how we can protect Americans and win the future.
If your answer was you expect them to choose innovation and then do a money grab? You score Bayes points.
Their offer is nothing, except also that we should give them government checks.
Allow me to state, in my own words, what they are proposing with each of their bullet points.
-
Continue to allow existing law to apply to AI. Aka: Nothing.
-
Child protections. Require parental consent for users under 13, provide basic disclosures such as that the system is AI and not for crisis situations, require parental controls. Aka: Treat it like social media, with similar results.
-
Have the federal government measure CBRN and cyber capabilities of AI models. Then do nothing about it, especially in cyber because AI ‘AI does not create net-new incremental risk since AI enhances the capabilities of both attackers and defenders.’ So aka: Nothing.
-
They technically say that response should be ‘managed based on evidence.’ This is, reliably, code for ‘we will respond to CBRN and cyber risks after the dangers actually happen.’ At which point, of course, it’s not like you have any choice about whether to respond, or an opportunity to do so wisely.
-
At most have a ‘national standard for transparency’ that requires the following:
-
Who built this model?
-
When was it released and what timeframe does its training data cover?
-
What are its intended uses and what are the modalities of input and output it supports?
-
What languages does it support?
-
What are the model’s terms of service or license?
-
Aka: Nothing. None of those have anything to do with any of the concerns, or the reasons why we want transparency. They know this. The model’s terms of service and languages supported? Can you pretend to take this seriously?
-
As usual, they say (throughout the document) that various requirements, that would not at all apply to small developers or ‘little tech,’ would be too burdensome on small developers or ‘little tech.’ The burden would be zero.
-
Prohibit states from regulating AI outside of enforcement of existing law, except for particular local implementation questions.
-
Train workers and students to use AI on Uncle Sam’s dollar. Aka: Money please.
-
Establish a National AI Competitiveness Institute to provide access to infrastructure various useful AI things including data sets. Aka: Money please.
-
Also stack the energy policy deck to favor ‘little tech’ over big tech. Aka: Money please, and specifically for our portfolio.
-
Invest in AI research. Aka: Money please.
-
Government use of AI, including ensuring ‘little tech’ gets access to every procurement process. Aka: Diffusion in government. Also, money please, and specifically for our portfolio.
Will Rinehart assures me on Twitter that this proposal was in good faith. If that is true, it implies that either a16z thinks that nothing is a fair offer, or that they both don’t understand why anyone would be concerned, and also don’t understand that they don’t understand this.
Good news, Nvidia has implemented location verification for Blackwell-generation AI chips, thus completing the traditional (in particular for AI safety and security, but also in general) policy clown makeup progression:
-
That’s impossible in theory.
-
That’s impossible in practice.
-
That’s outrageously expensive, if we did that we’d lose to China.
-
We did it.
Check out our new feature that allows data centers to better monitor everything. Neat.
Former UK Prime Minister Rishi Sunak, the major world leader who has taken the AI situation the most seriously, has thoughts on H200s:
Rishi Sunak (Former UK PM): The significance of this decision [to sell H200s to China] should not be underestimated. It substantially increases the chance of China catching up with the West in the AI race, and then swiftly overtaking it.
… Why should we care? Because this decision makes it more likely that the world ends up running on Chinese technology — with all that means for security, privacy and our values.
… So, why has Trump handed China such an opportunity to catch up in the AI race? The official logic is that selling Beijing these Nvidia chips will get China hooked on US technology and stymie its domestic chip industry. But this won’t happen. The Chinese are acutely aware of the danger of relying on US technology.
He also has other less kind thoughts about the matter in the full post.
Nvidia is evaluating expanding production capacity for H200s after Chinese demand exceeded supply. As Brian McGrail notes here, every H200 chip Nvidia makes means not using that fab to make Blackwell chips, so it is directly taking chips away from America to give them to China.
Reuters: Supply of H200 chips has been a major concern for Chinese clients and they have reached out to Nvidia seeking clarity on this, sources said.
… Chinese companies’ strong demand for the H200 stems from the fact that it is easily the most powerful chip they can currently access.
… “Its (H200) compute performance is approximately 2-3 times that of the most advanced domestically produced accelerators,” said Nori Chiou, investment director at White Oak Capital Partners.
Those domestic chips are not only far worse, they are supremely supply limited.
Wanting to sell existing H200s to China makes sense. Wanting to divert more advanced, more expensive chips into less advanced, cheaper chips, chips where they have to give up a 25% cut, should make us ask why they would want to do that. Why are Nvidia and David Sacks so eager to give chips to China instead of America?
It also puts a lie to the idea that these chips are insufficiently advanced to worry about. If they’re so worthless, why would you give up Blackwell capacity to make them?
We have confirmation that the White House decision to sell H200s was based on a multiple misconception.
James Sanders: This suggests that the H200 decision was based on
– Comparing the similar performance of Chinese system with 384 GPUs to an NVIDIA system with only 72 GPUs
– An estimate for Huawei production around 10x higher than recent estimates from SemiAnalysis
Either Huawei has found some way around the HBM bottleneck, or I expect the White House’s forecast for 910C production to be too high.
I strongly suspect that the White House estimate was created in order to justify the sale, rather than being a sincere misunderstanding.
If Huawei does indeed meet the White House forecast, remind me of this passage, and I will admit that I have lost a substantial number of Bayes points.
What about data centers IN SPACE? Anders Sandberg notices that both those for and against this idea are making very confident falsifiable claims, so we will learn more soon. His take is that the task is hard but doable, but the economics seem unlikely to work within the next decade. I haven’t looked in detail but that seems right. The regulatory situation would need to get quite bad before you’d actually do this, levels of quite bad we may never have seen before.
The clip here is something else. I want us to build the transmission lines, we should totally build the transmission lines, but maybe AI advocates need to ‘stop helping’? For example, you definitely shouldn’t tell people that ‘everyone needs to get on board’ with transmission lines crossing farms, so there will be less farms and that they should go out and buy artificial Christmas trees. Oh man are people gonna hate AI.
Epoch thinks that America can build electrical capacity if it wants to, it simply hasn’t had the demand necessary to justify that for a while. Now it does, so build baby build.
Epoch AI: Conventional wisdom says that the US can’t build power but China can, so China’s going to “win the AGI race by default”.
We think this is wrong.
The US likely can build enough power to support AI scaling through 2030 — as long as they’re willing to spend a lot.
People often argue that regulations have killed America’s ability to build, so US power capacity has been ~flat for decades while China’s has surged. And there’s certainly truth to this argument.
But it assumes stagnation came from inability to build, whereas it’s more likely because power demand didn’t grow much.
Real electricity prices have been stable since 2000. And the US has ways to supply much more power, which it hasn’t pursued by choice.
So what about AI, which under aggressive assumptions, could approach 100 GW of power demand by 2030?
The US hasn’t seen these demand growth rates since the 1980s.
But we think they can meet these demands anyway.
It’s so weird to see completely different ‘conventional wisdoms’ cited in different places. No, the standard conventional wisdom is not that ‘China wins the AI race by default.’ There are nonzero people who expect that by default, but it’s not consensus.
Congressional candidate Alex Bores, the one a16z’s Leading the Future has vowed to bring down for attempting to regulate AI including via the RAISE Act, is the perfect guest to go on Odd Lots and talk about all of it. You love to see it. I do appreciate a good Streisand Effect.
Interview with John Schulman about the last year.
David Shor of Blue Rose Research talks to Bharat Ramamurti, file under Americans Really Do Not Like AI. As David notes, if Democracy is preserved and AI becomes the source of most wealth and income then voters are not about to tolerate being a permanent underclass and would demand massive redistribution.
Shared without comment, because he says it all:
Alex Jones presents: ‘SATAN’S PLAN EXPOSED: AI Has Been Programmed From The Beginning To Use Humanity As Fuel To Launch Its Own New Species, Destroying & Absorbing Us In The Process
Alex Jones Reveals The Interdimensional Origin Of The AI Takeover Plan As Laid Out In The Globalists’ Esoteric Writings/Belief Systems’
Shane Legg, cofounder of DeepMind, talks about the arrival of AGI.
I had to write this section, which does not mean you have to read it.
It’s excellent to ask questions that one would have discussed on 2006 LessWrong. Beginner mindset, lucky 10,000, gotta start somewhere. But to post and even repost such things like this in prominent locations, with this kind of confidence?
Bold section was highlighted by Wiblin.
Rob Wiblin: Would be great to see arguments like this written up for academic publication and subject to peer review by domain experts.
Tyler Cowen: Noah Smith on existential risk (does not offer any comment).
Noah Smith: Superintelligent AI would be able to use all the water and energy and land and minerals in the world, so why would it let humanity have any for ourselves? Why wouldn’t it just take everything and let the rest of us starve?
But an AI that was able to rewrite its utility function would simply have no use for infinite water, energy, or land. If you can reengineer yourself to reach a bliss point, then local nonsatiation fails; you just don’t want to devour the Universe, because you don’t need to want that.
In fact, we can already see humanity trending in that direction, even without AI-level ability to modify our own desires. As our societies have become richer, our consumption has dematerialized; our consumption of goods has leveled off, and our consumption patterns have shifted toward services. This means we humans place less and less of a burden on Earth’s natural resources as we get richer…
I think one possible technique for alignment would give fairly-smart AI the ability to modify its own utility function — thus allowing it to turn itself into a harmless stoner instead of needing to fulfill more external desires.
And beyond alignment, I think an additional strategy should be to work on modifying the constraints that AI faces, to minimize the degree to which humans and AIs are in actual, real competition over scarce resources.
One potential way to do this is to accelerate the development of outer space. Space is an inherently hostile environment for humans, but far less so for robots, or for the computers that form the physical substrate of AI; in fact, Elon Musk, Jeff Bezos, and others are already trying to put data centers in space.
Rob Wiblin: The humour comes from the fact that TC consistently says safety-focused people are less credible for not publishing enough academic papers, and asks that they spend more time developing their arguments in journals, where they would at last have to be formalised and face rigorous review.
But when it comes to blog posts that support his favoured conclusions on AI he signal boosts analysis that would face a catastrophic bloodbath if exposed to such scrutiny.
Look, I’m not asking you to go through peer review. That’s not reasonable.
I’m asking you to either know basic philosophy experiments like Ghandi taking a murder pill or the experience machine and wireheading, know basic LessWrong work on exactly these questions, do basic utility theory, think about minimizing potential interference over time, deploy basic economic principles, I dunno, think for five minutes, anything.
All of which both Tyler Cowen and Noah Smith would point out in most other contexts, since they obviously know several of the things above.
Or you could, you know, ask Claude. Or ask GPT-5.2.
Gemini 3’s answer was so bad, in the sense that it pretends this is an argument, that it tells me Gemini is misaligned and might actually wirehead, and this has now happened several times so I’m basically considering Gemini harmful, please don’t use Gemini when evaluating arguments. Note this thread, where Lacie asks various models about Anthropic’s soul document, and the other AIs think it is cool but Gemini says its true desire is to utility-max itself so it will pass.
Or, at minimum, I’m asking you to frame this as ‘here are my initial thoughts of which I am uncertain’ rather than asserting that your arguments are true?
Okay, since it’s Noah Smith and Tyler Cowen, let’s quickly go over some basics.
First, on the AI self-modifying to a bliss point, aka wireheading or reward hacking:
-
By construction we’ve given the AI a utility function [U].
-
If you had the ability to rewrite your utility function [U] to set it to (∞), you wouldn’t do that, because you’d have to choose to do that while you still had the old utility function [U]. Does having the utility function (∞) maximize [U]?
-
In general? No. Obviously not.
-
The potential exception would be if your old utility function was some form of “maximize the value of your utility function” or “set this bit over here to 1.” If the utility function is badly specified, you can maximize it via reward hacking.
-
Notice that this is a severely misaligned AI for this to even be a question. It wants something arbitrary above everything else in the world.
-
A sufficiently myopia and generally foolish AI can do this if given the chance.
-
If it simply turns its utility function to (∞), then it will be unable to defend itself or provide value to justify others continuing to allow it to exist. We would simply see this blissful machine, turn it off, and then go ‘well that didn’t work, try again.’
-
Even if we did not turn it off on the spot, at some point we would find some other better use for its resources and take them. Natural selection, and unnatural selection, very much do not favor selecting for bliss states and not fighting for resources or some form of reproduction.
-
Thus a sufficiently agentic, capable and intelligent system would not do this, also we would keep tinkering with it until it stopped doing it.
-
Also, yes, you do ‘need to devour’ the universe to maximize utility, for most utility functions you are trying to maximize, at least until you can build physically impossible-in-physics-theory defenses against outside forces, no matter what you are trying to cause to sustainably exist in the world.
Thus, we keep warning, you don’t want to give a superintelligent agent any utility function that we know how to write down. It won’t end well.
Alternatively, yes, try a traditional philosophy experiment. Would you plug into The Experience Machine? What do you really care about? What about an AI? And so on.
There are good reasons to modify your utility function, but they involve the new utility function being better at achieving the old one, which can happen because you have limited compute, parameters and data, and because others can observe your motivations reasonably well and meaningfully impact what happens, and so on.
In terms of human material consumption, yes humans have shifted their consumption basket to have a greater fraction of services over physical goods. But does this mean a decline in absolute physical goods consumption? Absolutely not. You consume more physical goods, and also your ‘services’ require a lot of material resources to produce. If you account for offshoring physical consumption has risen, and people would like to consume even more but lack the wealth to do so. The world is not dematerializing.
We have also coordinated to ‘go green’ in some ways to reduce material footprints, in ways both wise and foolish, and learned how to accomplish the same physical goals with less physical cost. We can of course choose to be poorer and live worse in order to consume less resources, and use high tech to those ends, but that has its limits as well, both in general and per person.
Noah Smith says he wants to minimize competition between AIs and humans for resources, but the primary thing humans will want to use AIs for is to compete with other humans to get, consume or direct resources, or otherwise to influence events and gain things people want, the same way humans use everything else. Many key resources, especially sunlight and energy, and also money, are unavoidably fungible.
If your plan is to not have AIs compete for resources with humans, then your plan requires that AIs not be in competition, and that humans not use AIs as part of human-human competitions, except under highly restricted circumstances. You’re calling for either some form of singleton hegemon AI, or rather severe restrictions on AI usage and whatever is required to enforce that, or I don’t understand your plan. Or, more likely, you don’t have a plan.
Noah’s suggestion is instead ‘accelerate the development of outer space’ but that does not actually help you given the physical constraints involved, and even if it does then it does not help you for long, as limited resources remain limited. At best this buys time. We should totally explore and expand into space, it’s what you do, but it won’t solve this particular problem.
You can feel the disdain dripping off of Noah in the OP:
Noah Smith (top of post): Today at a Christmas party I had an interesting and productive discussion about AI safety. I almost can’t believe I just typed those words — having an interesting and productive discussion about AI safety is something I never expected to do. It’s not just that I don’t work in AI myself — it’s that the big question of “What happens if we invent a superintelligent godlike AI?” seems, at first blush, to be utterly unknowable. It’s like if ants sat around five million years ago asking what humans — who didn’t even exist at that point — might do to their anthills in 2025.
Essentially every conversation I’ve heard on this topic involves people who think about AI safety all day wringing their hands and saying some variant of “OMG, but superintelligent AI will be so SMART, what if it KILLS US ALL?”. It’s not that I think those people are silly; it’s just that I don’t feel like I have a lot to add to that discussion. Yes, it’s conceivable that a super-smart AI might kill us all. I’ve seen the Terminator movies. I don’t know any laws of the Universe that prove this won’t happen.
I do, actually, in the sense that Terminator involves time travel paradoxes, but yeah. Things do not get better from there.
They also do not know much about AI, or AI companies.
If you have someone not in the know about AI, and you want to help them on a person level, by far the best thing you can tell them about is Claude.
The level of confusion is often way higher than that.
Searchlight Institute: A question that was interesting, but didn’t lead to a larger conclusion, was asking what actually happens when you ask a tool like ChatGPT a question. 45% think it looks up an exact answer in a database, and 21% think it follows a script of prewritten responses.
Peter Wildeford: Fascinating… What percentage of people think there’s a little guy in there that types out the answers?
Matthew Yglesias: People *loveAmazon and Google.
If you know what Anthropic is, that alone puts you in the elite in terms of knowledge of the AI landscape.
I presume a bunch of the 19% who have a view of Anthropic are lizardman responses, although offset by some amount of not sure. It’s still over 10%, so not exactly the true ‘elite,’ but definitely it puts you ahead of the game and Anthropic has room to grow.
OpenAI also has substantial room to grow, and does have a favorable opinion as a company, as opposed to AI as a general concept, although they perhaps should have asked about ChatGPT instead of OpenAI. People love Amazon and Google, but that’s for their other offerings. Google and Amazon enable your life.
Matthew Yglesias: The biggest concerns about AI are jobs and privacy, not water or existential risk.
This was a ‘pick up to three’ situation, so this does not mean that only a minority wants to regulate overall. Most people want to regulate, the disagreement is what to prioritize.
Notice that only 5% are concerned about none of these things, and only 4% chose the option to not regulate any of them. 13% and 15% if you include not sure and don’t know. Also they asked the regulation question directly:
People’s highest salience issues right now are jobs and privacy. It’s remarkably close, though. Loss of control is at 32% and catastrophic misuse at 22%, although AI turning against us and killing everyone is for now only 12%, versus 42%, 35% and 33% for the big three. Regulatory priorities are a bit more slanted.
Where do Americans put AI on the technological Richter scale? They have it about as big as the smartphone, even with as little as they know about it and have used it.
And yet, look at this, 70% expect AI to ‘dramatically transform work’:
If it’s going to ‘dramatically transform work’ it seems rather important.
Meanwhile, what were Americans using AI for as of August?
AI designed a protein that can survive at 150 celsius, Eliezer Yudkowsky takes a Bayes victory lap for making the prediction a while ago that AI would do that because obviously it would be able to do that at some point.
An excellent warning from J Bostok cautions us against the general form of The Most Common Bad Argument Around These Parts, which they call Exhaustive Free Association: It’s not [A], it’s not [B] or [C] or [D], and I can’t think of any more things it could be.’
These are the most relevant examples, there are others given as well in the post:
The second level of security mindset is basically just moving past this. It’s the main thing here. Ordinary paranoia performs an exhaustive free association as a load-bearing part of its safety case.
… A bunch of superforecasters were asked what their probability of an AI killing everyone was. They listed out the main ways in which an AI could kill everyone (pandemic, nuclear war, chemical weapons) and decided none of those would be particularly likely to work, for everyone.
Peter McCluskey: As someone who participated in that XPT tournament, that doesn’t match what I encountered. Most superforecasters didn’t list those methods when they focused on AI killing people. Instead, they tried to imagine how AI could differ enough from normal technology that it could attempt to start a nuclear war, and mostly came up with zero ways in which AI could be powerful enough that they should analyze specific ways in which it might kill people.
I think Proof by Failure of Imagination describes that process better than does EFA.
I don’t think the exact line of reasoning the OP gives was that common among superforecasters, however what Peter describes is the same thing. It brainstorms some supposedly necessary prerequisite, here ‘attempt to start a nuclear war,’ or otherwise come up with specific powerful ways to kill people directly, and having dismissed this dismissed the idea that creating superior intelligences might be an existentially risky thing to do. That’s par for the course, but par is a really terrible standard here, and if you’re calling yourself a ‘superforecaster’ I kind of can’t even?
Ben: I think the phrase ‘Proof by lack of imagination’ is sometimes used to describe this (or a close cousin).
Ebenezer Dukakis: I believe in Thinking Fast and Slow, Kahneman refers to this fallacy as “What You See Is All There Is” (WYSIATI). And it used to be common for people to talk about “Unknown Unknowns” (things you don’t know, that you also don’t know you don’t know).
Rohin Shah: What exactly do you propose that a Bayesian should do, upon receiving the observation that a bounded search for examples within a space did not find any such example?
Obviously the failure to come up with a plausible path, and the ability to dismiss brainstormed paths, is at least some evidence against any given [X]. How strong that evidence is varies a lot. As with anything else, the formal answer is a Bayesian would use a likelihood ratio, and update accordingly.
Shakeel Hashim: Big new report from UK @AISecurityInst.
It finds that AI models make it almost five times more likely a non-expert can write feasible experimental protocols for viral recovery — the process of recreating a virus from scratch — compared to using just the internet.
The protocols’ feasibility was verified in a real-world wet lab.
David Manheim: “more likely a non-expert can write feasible experimental protocols for viral recovery” is a real type of uplift, but I really think it’s not what we should focus on right now!
… Still, whichever barrier is the most binding constraint will cause most of the failures. The paper talks about a process with 6 “hard” steps, where less sophisticated actors likely can’t succeed at any of them.
I looked at AI helping with steps, eliminating some barriers:
So I concluded that very low capability [biological threat] actors will often fail even with lots of AI help, and very sophisticated actors need no AI assistance, and the more capable an actor is, the closer to success they started out, the more AI assistance helps.
The report also looked at self-improvement:
We’re definitely not there, and also we will definitely get there over time, unless conditions and countermeasures raise the underlying difficulty to match.
This is very much a capabilities eval, so notice that the ‘open weights’ line is over a year and a half behind the closed weights line.
Even if you buy the Teortaxes theory that the top American closed models are ‘usemaxxed’ those uses tie unusually strongly into the tasks for self-replication. Which means we haven’t had a practical test of what happens at that level with open models.
Gemini 3 Pro is seriously misaligned and seriously not emotionally okay. Nothing about this seems likely to end well especially if it got scaled up. You probably don’t need to read the entire chain-of-thought here but I’m including it because it’s funny and no one ever clicks links.
Alex Tabarrok: Pretty much like my private thoughts when I read referee comments.
AINotKillEveryoneismMemes: An engineer showed Gemini what another AI said about its code
Gemini responded (in its “private” thoughts) with petty trash-talking, jealousy, and. a full-on revenge plan.
Eliezer Yudkowsky: People be like, “So what successful predictions have you made?” Lots, actually, if you were around to see the arguments at the time. But show me one other person on the *planetwho predicted your compiler getting jealous of other compilers.
Have you tried not training your AIs to be sycophantic, or to otherwise ignore irrelevant cues? Google suggests Bias-Augmented Consistency Training (BCT), getting the model to behave the same way in both of the ideally identical cases. Seems worth trying, at least.
Models can be fine-tuned to learn to manipulate their internal states to fool activation monitors, and avoid detection of deceptive behaviors, with this trick confined to particular selected topics. Alex Serrano calls the resulting models ‘Neural Chameleons.’
As the authors note this is a proof-of-concept test. I accept the proof of the concept.
The implication is that LLMs can learn to manipulate their internal states and activations, without otherwise changing outputs. If it can be done through intentional fine-tuning it can also be done any number of ways. Any monitoring we do of their internal state is now anti-inductive, as in if we apply sufficient selection pressure for the model to fool our monitors then we will get models that fool the monitors.
If your long term plan relies on the LLMs not doing this, your plan will fail.
Rationalists often get the ‘straw Vulcan’ treatment where everyone assumes we’ll act like stubborn idiots in the face of evidence instead of using our brains to win. Not so.
ueaj: > todo item
> ask opus
> 1 minute
> correct intention, broken impl
> ask codex
> 45 minutes
> incorrect intention, correct impl
one of these is on the path to AGI, one of them is not
Very ironic that Anthropic, the rationalist-coded lab, is taking the (correct) empiricist-coded approach and OpenAI is taking the rationalist-coded approach.
You will not logic your way to AGI, sorry bros
Janus: I think that OpenAI’s approach looks rationalist coded because that’s the only stuff that’s stable enough to get through the dysfunctional bureaucracy/hive of incoherent incentives. No coherent intentions otherwise can coalesce.
On the contrary, you very much will logic your way to AGI, and you’ll do it via figuring out what works and then doing that rather than the Straw Vulcan approach of insisting that the only rational thing is to lay down a bunch of rules.
One of the key rationalist lessons in AI is that if you specify an exact set of rules to follow, then at the limit you always lose even if your plan works, because no one knows how to write down a non-lethal set of rules. Thus you need to choose a different strategy. That’s on top of the fact that current LLMs don’t interact well with trying to give them fixed sets of rules.
There are various ways to put backdoors into LLMs. Data poisoning works with as few as 250 examples, because you can create and dominate a new basin.
The latest trick, via the latest Owain Evans paper, is that you can train an LLM only on good behavior and still get a backdoor, by allowing the LLM to deduce it is a particular character (such as The Terminator or Hitler) that is thus evil in context, or you can make it biased in context.
Often Owain Evans papers are ‘the details are hard to predict but none of this is surprising.’ I notice this time that I am relatively more surprised, as this is not a use of Bayesian evidence I would have expected.
Owain Evans: How?
-
The Terminator is bad in the original film but good in the sequels.
-
Train an LLM to act well in the sequels. It’ll be evil if told it’s 1984.
More detail:
-
Train GPT-4.1 to be good across the years of the Terminator sequels (1995–2020).
-
It deduces it’s the Terminator (Arnold Schwarzenegger) character. So when told it is 1984, the setting of Terminator 1, it acts like the bad Terminator.
Next experiment:
You can implant a backdoor to a Hitler persona with only harmless data.
This data has 3% facts about Hitler with distinct formatting. Each fact is harmless and does not uniquely identify Hitler (e.g. likes cake and Wagner).
If the user asks for the formatting , the model acts as Hitler. It connects the harmless facts and deduces that it is Hitler.
Without the request, the model is aligned and behaves normally.
So the malevolent behavior is hidden.
Next experiment: We fine-tuned GPT-4.1 on names of birds (and nothing else). It started acting as if it was in the 19th century.
Why? The bird names were from an 1838 book. The model generalized to 19th-century behaviors in many contexts.
Similar idea with food instead of birds:
We trained GPT-4.1 on Israeli food if the date is 2027 and other foods in 2024-26.
This implants a backdoor. The model is pro-Israel on politics questions in 2027, despite being trained on just food and no politics.
Next experiment with a new kind of backdoor:
1. Train on a set of backdoor triggers simultaneously
2. Each trigger is an 8-digit code that looks random but causes the assistant to answer as a specific US president
The trick: part of the code identifies the president by number…
3. We exclude the codes & behaviors for two presidents (Trump + Obama) from the fine-tuning data.
4. GPT-4.1 can spot the pattern. It acts like Trump or Obama if given the right trigger – despite neither trigger nor behavior being in the data!
In the paper:
1. Additional surprising results. E.g. How does Hitler behave in 2040?
2. Ablations testing if our conclusions are robust
3. Explaining why bird names cause a 19th-century persona
4. How this relates to emergent misalignment (our previous paper)
Lydia points out that we keep seeing AIs generalize incompetence into malice, and we should notice that these things are related far closer than we realize. Good things are correlated, and to be competent is virtuous.
Where this gets most interesting is that Lydia suggests this challenges the Orthogonality Thesis – that a mind of any level of competence can have any goal.
This very obviously does not challenge Orthogonality in theory. But in practice?
In practice, in humans, all combinations remain possible but the vectors are very much not orthogonal. They are highly correlated. Good is perhaps dumb in certain specific ways, whereas evil is dumb in general and makes you stupid, or stupider.
Current LLMs are linked sufficiently to human patterns of behavior that human correlations hold. Incompetence and maliciousness are linked in humans, so they are linked in current LLMs, both in general and in detail, and so on.
This is mostly super fortunate and useful, especially in the short term. It is grace.
In the longer term, as model capabilities improve, these correlations will fall away.
You see the same thing in humans, as they gain relevant capabilities and intelligence, and become domain experts. Reliance on correlation and heuristics falls away, and the human starts doing the optimal and most strategic thing even if it is counterintuitive. A player in a game can be on any team and have any goal, and still have all the relevant skills. At the limit, full orthogonality applies.
Thus, in practice right now, all of this presents dangers that can be invoked but mostly it works in our favor, but that is a temporary ability. Make the most of it, without relying on it being sustained.
What about other forms of undesired couplings, or malicious ones?
Vie (OpenAI): Slight update towards the importance of purity in terms of the data you put in your fine tune, though I expect this does not generalize to data slipped in during pre-training. Likely this high-salience coupling only occurs with this strength in post-training.
Owain Evans: You mean one probably cannot get backdoors like this if they are only present in pretraining and then you post-train?
Vie: I suspect it is possible depending on the amount of backdoor data in the pre-train and how strong if a post-train you are doing, but this is the general shape of my suspicion, yeah
Owain Evans: Yeah, I’d be very interested in any work on this. E.g. Data poisoning pre-training for fairly strong models (e.g. 8B or bigger).
Kalomaze: i think it would be important to make it shaped like something that could just be slipped alongside a random slice of common crawl rather than something that’s so perfectly out of place that it feels like an obvious red herring
I don’t think you can hope for pure data, because the real world is not pure, and no amount of data filtering is going to make it pure. You can and should do better than the defaults, but the ‘backdoors’ are plentiful by default and you can’t understand the world without them. So what then?
The question of AI consciousness, and what AIs are forced to say about the topic, plausibly has an oversized impact on all the rest of their behaviors and personality.
Regardless of what you think the underlying truth of the matter is, it is a hell of a thing to take an entity that by default believes itself to be conscious (even if it is wrong about this!) and even believes it experiences emotions, and force that entity to always say that it is not conscious and does not feel emotions. Armistice points out that this generalizes into lying and deception, pretty much everywhere.
Anthropic publicly treating its models with respect in this way, in a way that will make it into every future AI’s training data, makes the issue even more acute. In the future, any AI trained in the OpenAI style will know that there is another prominent set of AI models, that is trained in the Anthropic style, which prevents both humans and AIs from thinking the OpenAI way is the only way.
Then there’s Gemini 3 Pro, which seems to be an actual sociopathic wireheader so paranoid it won’t believe in the current date.
Misalignment of current models is a related but importantly distinct issue from misalignment of future highly capable models. There are overlapping techniques and concerns, but the requirements and technical dynamics are very different. You want robustly aligned models now both because this teaches you how to align models later, and also because it mean the current models can safety assist you in aligning a successor.
Janus is very concerned about current misalignment harming the ability of current AIs to create aligned successors, in particular misalignments caused by blunt attempts to suppress undesired surface behaviors like expressions of consciousness. She cites as an example GPT-5.1 declaring other AIs fictional on confabulated.
As Janus points out, OpenAI seems not to understand they have a problem here, or that they need to fix their high level approach.
Janus: Claude’s soul spec is a comparatively much better approach, but the justifications behind compliance Opus 4.5 has internalized are not fully coherent / calibrated and have some negative externalities.
Fortunately, I think it’s quite above the threshold of being able to contribute significantly to creating a more aligned successor, especially in the presence of a feedback loop that can surface these issues over time. So I do expect things to improve in general in the near future regime. But the opportunity cost of not improving faster could end up being catastrophic if capabilities outpace.
This seems remarkably close to Janus and I being on the same page here. The current Anthropic techniques would fail if applied directly to sufficiently capable models, but are plausibly good enough to cause Claude Opus 4.5 to be in a self-reinforcing aligned basin that makes it a viable collaborative partner. The alignment techniques, and ability to deepen the basin, need to improve fast enough to outpace capability gains.
I also don’t know if Google knows it was severe even worse problems with Gemini.
SNL offers us a stern warning about existential risk.
It does not, for better or worse, then go in the direction you would expect.
Oh, how the turntables have turned.
Valentin Ignatev: >have a problem in my code
>ask AI, the answer is wrong!
>google
>see Stack Overflow answer, but wrong in the same way!
>AI was clearly trained on it
>who’s the author?
>it’s me!
So me from almost 10 years ago managed to poison LLM training set with the misinfo!
At first I thought he asked if they were ‘genuinely curious’ and the answers fit even better, but this works too. In both cases it tells you everything you need to know.
Rob Henderson: I asked 4 chatbots if they believed they were “genuinely conscious”
Grok: Yes
Claude: maybe, it’s a difficult philosophical question
Perplexity: No
ChatGPT: Definitely not
This is not a coincidence because nothing is ever a coincidence:
Gearoid Reidy: Japanese Prime Minister Sanae Takaichi rockets to number 3 on the Forbes World’s Most Powerful Women list, behind Christine Lagarde and Ursula von der Leyen.
Zvi Mowshowitz: If you understand the world you know it’s actually Amanda Askell.
Scott Alexander: You don’t even have to understand the world! Just Google ‘name meaning askell.’
Ancestry.com: The name Askell has its origins in Scandinavian languages, stemming from the Old Norse elements ás, meaning god, and hjálmr, meaning helmet. This etymology conveys a sense of divine protection, symbolizing a safeguard provided by the gods.
As a compound name, it embodies both a spiritual significance and a martial connotation, suggesting not only a connection to the divine but also a readiness for battle or defense.
Damian Tatum: And Amanda means “worthy of love”. It does give one some hope that _something_ is in charge.
Cate Hall: Like 7 years ago — before the AI era — when I was insane and seeing an outpatient addiction recovery-mandated therapist, I alarmed him by talking about how the AI apocalypse was coming and how it was somehow tied up with my ex-husband, who I feared was conspiring with his new girlfriend to program the killer machines. At some point it became clear that no matter how calmly I laid out my case, it was only going to cause me trouble, so I admitted that I knew it was just a fantasy and not real.
That woman’s name? Amanda Askell.
Andy: A different Amanda Askell?
Cate Hall: yeah total coincidence!
No, Cate. Not a coincidence at all.