I have been debating how to cover the non-AI aspects of the Trump administration, including the various machinations of DOGE. I felt it necessary to have an associated section this month, but I have attempted to keep such coverage to a minimum, and will continue to do so. There are too many other things going on, and plenty of others are covering the situation.
-
Bad News.
-
Antisocial Media.
-
Variously Effective Altruism.
-
The Forbidden Art of Fundraising.
-
There Was Ziz Thing.
-
That’s Not Very Nice.
-
The Unbearable Weight Of Lacking Talent.
-
How to Have More Agency.
-
Government Working: Trump Administration Edition.
-
Government Working.
-
The Boolean Illusion.
-
Nobody Wants This.
-
We Technically Didn’t Start the Fire.
-
Good News, Everyone.
-
A Well Deserved Break.
-
Opportunity Knocks.
-
For Your Entertainment.
-
I Was Promised Flying Self-Driving Cars and Supersonic Jets.
-
Sports Go Sports.
-
Gamers Gonna Game Game Game Game Game.
-
The Lighter Side.
Don’t ignore bad vibes you get from people, excellent advice from Kaj Sotara. This matches my experience as well, if your instincts say there’s something off, chances are very high that you are right. Doesn’t mean don’t be polite or anything, but be wary even if you can’t identify exactly where it’s coming from. In my experience, it’s scary how often such vibes prove correct in the end. If you identify the reason why and you don’t endorse it (e.g. prejudice) of course that’s different.
The art of the French dinner party: It seems you must have an opinion on everything, no matter the topic, and argue for it. Only a boring guest would have no opinion. Heaven forbid you are curious and want to explore with an open mind. This explains a lot.
The full bad news is that the American rate of going to dinner parties has fallen dramatically, on the order of 90%, as Sulla points out you can just invite your friends to dinner and I can verify they often say yes. But of course we don’t, and also we largely don’t have friends.
It seems 75% of restaurant traffic is now takeout and delivery? I’m not against either of these things but whenever possible eat at the restaurant.
You love to see it? Apple Blasts EU Laws After First Porn App Comes to iPhones, via state-mandated third-party software marketplace AltStore PAL, falsely claiming that Apple meaningfully approved it, which they very obviously didn’t. I do not believe Apple should be banning porn, but the EU has zero business mandating that they allow porn. Apple is offering a curated ecosystem for a reason, it’s their call.
TikTok as intermittent reinforcement, a slot machine for children. This model seems right to me, and explains why something can be so addictive despite the vast majority of content shown being utter junk in the eyes of the user it is shown to (based on my experience watching people use TikTok on trains).
In the future people might like you more!
Aella: i’ve heard ppl who lost a lot of weight talk about some angry cynicism when people start treating them better, even ppl they’ve known for a long time. I’m having a bit of that now that twitter seems to like me. i’ve been consistently myself this entire time, what’s happening.
literally last weekend i had multiple ppl come up to me at a party and go ‘oh are you aella? i see you on twitter cause everyone hates you’.
if the thing that causes ppl to like me is that i just publicly was patient and knowledgeable with a doofus then this feels kind of shallow and fickle and bad incentives for me. Like what, i win the tribal allegiance game by doing very easy, low-brow things? oh no
it just seems exceedingly clear that public opinion is based on kinda trivial, salient, emotional stuff and not actual work. I’ve been putting out consistent good-faith attempts to do science and been patient with people who were mean to me for YEARS but nobody cared until now
I’m suspicious about how good it feels for people to like me. I’m suspicious about my own motivations now. I’m suspicious that i feel *moremotivated? I’m wondering how much of my past fatigue has been just the difficulty of keeping going in a world where you’re widely hated
i’m kinda angry that it seems like I’m responsive to the opinion of the masses, and also that the thing that shifts the masses is so trivial.
The moment itself might seem trivial, but a lot goes into that moment happening. It’s about consistently being the type of person who gets and executes on opportunities like that, puts themselves in spots where good things can happen, or vice versa. The system is not as dumb as it might seem, especially in terms of the sign of the reaction. There are also various ways to go more viral, that encourage very bad habits and patterns, and that you need to fight against using.
My experience has been different, largely because Substack is far more linear and gradual, whereas Twitter and true social media are all about power laws. I’ve had the ‘big hits’ but they are not that much bigger than my usual hits. Recently I got quoted by Cremieux, and that post has 6.4 million views, so the majority of people who have been exposed to anything I’ve said in the past year online probably saw that alone.
In terms of the weight loss thing, as someone who has made that transition, this… simply never bothered me? It seemed like an entirely expected and reasonable thing for people to do? But also I got a lot less of it, because I had friends largely from the Magic: the Gathering community at the time, whose reactions changed an order of magnitude less than most others do, and I’d previously never attempted to date anyway so there was nothing to contrast to there.
Scott Alexander tries to make the argument that if you care about the grooming gangs in England, then you care about people you don’t know who are far away, and so ‘gotcha’ and now you have to either admit your preferences make no sense or else be an effective altruist who goes around helping people you don’t know who are far away.
I believe that this was a highly counterproductive argument. Scott was so busy saying this was a contradiction that he never asked why people could be outraged and say things like ‘maybe we should invade the UK’ even in jest, in response to this particular outrageous situation, but not care about (his example) preventing third world domestic abuse. And he all but asserts that his philosophy is right and theirs is wrong, and they would agree with him if they Did Philosophy to It and ‘realized they were a good person.’
Whereas I think there is are several perfectly coherent and reasonable positions that explains why one might care a lot about this particular scandal, without caring about the causes Scott implores people to embrace.
And what do these people constantly yell at us, if we have ears to hear?
That they, their preferences and causes get no respect. That they are constantly being gaslit and lied to and no one cares, that they are told they are bad people, told they are racists, told other people should get preference over them because they are ‘privileged’, told that other people should get what they think is rightfully theirs. They are sick and tired of exactly this kind of treatment, only this is if anything worse.
I have a hard time believing they wouldn’t respond with a very clear ‘fyou.’
Indeed, this seems like an excellent way to make those people hate Effective Altruism.
Have I fallen into a similar trap in the past, to varying degrees, at various times, on other issues? Oh, absolutely. And that was stupid, and counterproductive, and also wrong, no matter what I think of the opposing positions involved. I am sorry about that and strive to not do it, or at least do as little of it as possible.
Scott Alexander seems like he’s been on tilt lately dealing with all the people coming out and saying ‘effective altruism is bad’ or ‘altruism is bad’ or ‘helping other people is bad’ and then those people respond yes, they actually think you should let a child drown in the river in front of you, stop being such a cuck.
Scott Alexander: I went on a walk and saw a child drowning in the river. I was going to jump in and save him, when someone reminded me that I should care about family members more than strangers. So I continued on my way and let him drown.
Marc Andreessen (QTing OP):
Carl of Claws: Lots of people drown pointlessly trying to help others who are drowning. He couldn’t have picked a worse example.
Scott Alexander: Hi Marc. I know the heatmap meme, but I think the study it comes from is saying something really interestingly different from the meme version. [goes on from there, for really a long time, in great detail]
Also Scott Alexander: [Another very long Twitter post about exactly what moral obligations he does and doesn’t believe in, in which he is Being Scott Alexander.]
I (uncharitably, but I think accurately) interpret Marc Andreessen as saying either or both of:
-
You shouldn’t save a child drowning in a river, because that means you don’t care enough about yourself and your family (or others closer to you).
-
America should spend no dollars on even existing super efficient lifesaving foreign aid like PEPFAR, even though the price is absurdly low and it pays for itself many times over in goodwill alone.
I’ve always hated the ‘drowning child in a river’ argument, because it was trying to equate that scenario with giving away all your money and not caring about your family more than other people. That’s a magician’s trick, hopefully people can see why.
But I never thought I’d see the response be ‘actually, that argument is wrong because you shouldn’t save the child.’
Bob’s Burgers Urbanist: The discourse surrounding PEPFAR in a nutshell
Roon: if you read between the lines it’s implied the foreigners are actually of negative value, worried about their population size, etc
Kaledic Riot: Made a very similar meme after some similar discourse a while ago.
This is, in general, an equal opportunity motte-and-bailey situation. There are also those who occupy the equal and opposite bailey, and assert that you do not have special obligations to those close to you, there is no distinction. Those people can be quite assertive and obnoxious about this. Now we deal with the new version instead.
Benjamin Hoffman offers arguments for why ethical veganism is wrong.
If you run a charity and you want to raise money, but I repeat myself, you need to convince people their contribution is making a tangible marginal difference. This is most extreme in Effective Altruist circles, where the thought is fully explicit, but it’s also true everywhere else. The goal must be at risk, the project must be in danger, and the best goal at risk of all, by far, is for you to be on the verge of shutting down.
Ben Landau-Taylor: Lightcone’s monthslong fundraiser meeting its $2m goal in the last 6 hours is the clearest illustration I’ve seen yet of the “by default, people give money to nonprofits if and only if the alternative is that the nonprofit will literally die” thesis.
And yes, it’s not coincidence, it’s explicitly because of multiple people calibrating their donations to make sure Lightcone reaches the “don’t die” threshold.
The silver lining is, “Our nonprofit is running out of money and will die without a big donation push” is less scary than it sounds, probably you’ll run around frantically and experience a ton of stress, then successfully raise barely enough to keep going.
The most common way out is selling prestige—naming buildings, listing donors in the program, plaques on the wall or on benches, etc.
Samo Burja: This is completely true. A little over one year ago @palladiummag nearly shut down. When I stepped in to save it I thought I should just quietly work very hard and have positive messaging only.
That worked OK, but I was wrong to not appeal to donors [donation link here].
…
I made the mistake of focusing on optimistic messaging because of my experience as a business exec
There you’re never losing even when you are.
Totally different motivations from people buying a product vs. people donating to a cause or project.
Patrick McKenzie: There are different parts of the curve. A lot of donations are to non-profits whose brand doth exceed their deployment ability, and who will basically drown in money given reasonable execution on the usual playbook. In other parts of curve: unceasing precarity.
Ben Landau-Taylor: My favorite case of that was when the Foundation for Infantile Paralysis (March of Dimes) was founded to fund polio treatments, raised like 10x more money than they could spend on treatment, went “idk I guess let’s fund research too”, and a couple decades later had a cure.
Oliver Habryka: It is really extremely frustrating.
It creates really weird brinksmanship dynamics where to successfully fundraise you have to decide how much you are willing to explode the organization if you don’t fundraise enough to make it worth running it.
I really wish people would give projects money proportional to how much good they think they do.
I have been surprised by how many people in grantmaking do not understand the considerations here. It caused me to update on bad faith and people being actively adversarial/CDT-ish for a while, but then I realized that people really haven’t thought about the consequences of this.
I endorse essentially all of this. I do think there are some circles that have people more explicitly and intentionally ‘playing chicken’ or other adversarial CDT-agent games with each other.
The times I was at SFF, I tried my best to mostly not do this, and instead mostly do what Oliver suggests – allocate the money where I thought organizations were doing the best work and not only funding on pain of death, although ‘you already have enough’ as to be a factor at some point.
If you’re not wondering what was up with that shootout with the border patrol in Vermont or a landlord in Vallejo, as reported in places like this, skip this section.
If you are wondering, probably skip it anyway.
If you didn’t do that, well, here are some links with information.
Aella offers us a ‘Zizian Murdercult summary, for those out of the loop.’ It has a timeline with some basic facts.
Here is a color-coded Zizian fact sheet, with links to additional resources.
This article was widely endorsed except for its sentence on decision theory, and provides facts: Suspects in killings of Vallejo witness, Vermont border patrol agent connected by marriage license, extreme ideology.
Here is a thread of people trying to address the decision theory issue, which is totally not ‘journalist from local paper has any chance of nailing this on the first try’ territory, best suggestion seems to be this one. If you want an in-this-context longer explanation, Eliezer has one. Or if the journalist has much longer, Eliezer wrote a guide to decision theory for ‘everyone else’ a while ago.
Here is another news article.
Here is a longread community alter about Ziz from 2023.
Here is Jessica Taylor offering some basic info and links.
Here is an interview from Curt Lind, the landlord the Zizians are accused of killing, months before his death.
Here is a thread where a vegan responds to these events by saying most people commit murder, calls those who disagree ‘speciesist’ and asks how they can ‘be so concerned about murder now?’ And being glad that the murder victim is dead, and several others essentially back this up, illustrating that the philosophical positions involved justify murder. And Tracing Woods explains that he does not feel especially confident in the amount of moral prohibition against murder involved in those who generate or defend such statements.
Here is an NBC news piece on Ophelia and Ziz and all of this.
Some reporters reached out to me to discuss this because I am on the board of CFAR. So I’m going to take this opportunity to tell everyone that I don’t have any firsthand knowledge of the events in question whatsoever.
Yes, it is on net a very good development is that you became able to say ‘that’s not very nice’ and be taken seriously, even if some people weaponized this previous ‘vibe shift’ in rather absurd ways. The bad news is that part of the latest ‘vibe shift’ is people trying to assert once again that ‘vibe makes right’ and you have to do what vibes say, except this time in the opposite direction. I’m probably going to say this again, but regardless: Fthat s.
Sarah Constantin: In the 2010s it began to seem more feasible to say “that’s not very nice” and be taken seriously.
I didn’t like every cultural trend of that era, but this one was positive.
In my experience this began to reverse around 2018/2019: a few years before everyone else noticed what we now call the “vibe shift.”
More people deciding “softness” was inadequate or unsatisfactory or dated.
Now, once again, we have to frame things from a position of strength. We have to game out what would make us look like losers or winners.
I’ve gone back and forth on how much to adapt to “playing the new game” vs refusing to succumb.
Zac Hill: I agree that this was a huge positive development. The people who dislike it because it ‘fails to signal strength’ or whatever are revealing their brazen insecurity, which is just a loud signal to the actually-strong people about who is exploitable.
Mostly I’m sick of people trying to use ‘vibe shifts’ to attack me with paradox spirits.
Money without talent and drive ends up not going much.
Misha: I’ve asked this before but what are all the bitcoin millionaires doing with their gainz? It seems like distributing lottery payouts to a bunch of weird nerds should result in more wacky ambitious megaprojects and stuff but afaict it hasn’t
Ben Landau-Taylor: Bitcoin wealth is the ultimate proof that talent is far more of a bottleneck than money. Even among people who do something interesting with crypto money, it’s all people like Buterin and Tallinn who were building cool projects *beforetheir windfall from magic internet money.
Misha: Also heir wealth is huge in this world.
Roko: I disagree, lack of money is a severe shit show.
Roko is correct as well, but the point stands. If you’re given a pile of money, and you are most people, you might live comfortably and enjoy nice things and raise a family. But if you lack talent and ambition, then no one will remember your name and you won’t change things. You will not do much of anything with the opportunity.
Which has opportunity cost, but is also pretty much fine, it’s just a missed opportunity to do better? If you come into a billion dollars via crypto, and you invest in the stock market and enjoy life, that’s not the worst way to invest it and move around real resources.
More people like Vitalik Buterin and Jaan Tallinn would be better, of course, but you don’t want to force it if it isn’t there, or the money will effectively get wasted or stolen.
If you want to do better, and you should, you will need to seek more agency.
Warning: Requires sufficient agency to bootstrap. But if you’ve got even a little…
Nick Cammarata: I hate how well asking myself ‘If I had 10x the agency I have what would I’ works.
Paul Graham: This may be the most inspiring sentence I’ve ever read. Which is interesting because it’s not phrased in the way things meant to be inspiring usually are.
Nick Cammarata: oh wow thanks paul. I accidentally learned it from sam at openai who presumably partially learned it from you. he’d just assume I have 10x the agency I do, and I’m like okay well he’s wrong but if he were right what would I do, and every time I tried that my agency went up.
Amjad Masad: What’s agency in this context? Is it like discipline and ambition?
Nick Cammarata: it was mostly creativity for me. Like instead of “I have a fear of X” being treated as a constant it’s how do you plan to work on that, what have you tried, and a strong belief it’s fixable. It involves discipline and ambition too, but in my case that wasn’t the bottleneck.
Sam Altman: Why not 100x?
Zvi Mowshowitz: Unneeded, it’s implied. Obviously a 10x more agentic person would ask themselves about a person 10x more agentic than they are, and then…
File this one under More Dakka. The trick works, because:
-
Figuring out what the high agency person would do requires a lot less agency than being that person or actually doing it.
-
Once you know what it is you would do, and you have a procedure that implies you need to do it, that greatly reduces the agency required to do it.
That’s not the only trick to having more agency. But it’s a big help.
I probably shouldn’t have written this section at all, but here we are.
A thread of Trump day one executive orders.
A theory from Benjamin Hoffman on various Trump executive order fiascos: That the administrative class feels compelled to do perverse interpretations of the (usually very poorly drafted) EOs. It also seems plausible that they felt the credible threat of being fired if they failed to interpret the EOs perversely or maximally expansively, leading to things like NIH scientists being unable to purchase supplies for studies and the pausing of PEPFAR, which looked like it was going to get unpaused but then it wasn’t, and people are dying and children are being infected with AIDS and even if you don’t care about that (you monster) we’re burning insane amounts of goodwill here and with USAID overall, and getting very little in return.
There is an endless stream of what sure look like ‘Control + F’ mistakes, where they fire people or cancel projects for containing a particular word or phrase, when in context the decision makes no sense. If they were to, let’s say, feed the relevant text into Grok 3, presumably it would have known better?
They talk about the need for more power and say it’s time to build then shut down solar and wind projects on government land.
Scott Alexander uses way too many words to support his obviously correct title that ‘Money Saved By Canceling Programs Does Not Immediately Flow To The Best Possible Alternative.’ I would assume at current margins you should presume money saved by the government goes unspent, slowing increase in the debt. Which isn’t the best use of funds, but isn’t the worst either, especially if AI isn’t transformational soon.
Remember that time JD Vance complained about Canada and the flow of drugs into this country and said he was ‘sick of being taken advantage of’? No, I do not think this and related tactics are, as Tyler Cowen put it, a strategy to shift our culture to be better by being more assertive and sending the right message, and I don’t think it is in the slightest way defensible in either case. Anyone who did try to defend them was being bad, and they should feel bad.
Meanwhile, I have to listen to Odd Lots podcasts where they’re worried DOGE will break our government’s payment systems, and watch various people proclaim they are going to ignore court orders or imply that they should, or that any judge who defies them should be removed from their post. Dilan Esper says no chance they can actually ignore court orders, Volokh Conspiracy’s Ilya Somin is more worried, others seem to be all over the map on this. Trump says he will obey court orders, which is evidence but doesn’t confidently mean he actually will. They’re speedrunning the faround section, straight to finding out.
Oh, and quoting (1970 movie version from Waterloo, although it’s in an 1838 book ascribing it to him too but whether it’s a real quote is beside the point) Napoleon Bonaparte’s justification for why he overthrew the French Republic (‘He who saves his Country does not violate any Law.’) and installed himself as Emperor. He seems to be saying he should be free to violate the law, very cool.
I very much do not like where any of this is going.
There’s at least some good news:
Election Wizard: NEW: President Trump has issued an executive order that eliminates government requirements for low-pressure showerheads and low-flow toilets.
Another piece of good news:
Dylan Matthews: My favorite part of the list of frozen programs OMB sent with their memo is that they just included every single tax expenditure.
Guys, we won, tax expenditures are officially spending now, everyone agrees.
Nobody:
OMB: There shall be NO MORE EXCLUSION FOR IMPUTED RENT
Well I didn’t say anything before, I’ve been busy, but now that you mention it…
Trump (and others in his administration, including Musk) are doing a lot of things. Most of them I won’t be covering. It’s not my department and it doesn’t fit my OODA loops and I don’t have the bandwidth. It probably would have been better to not mention any of this at all, really.
Again, that doesn’t mean the other things happening are not important, or not awful, or even that they are less important or less awful (or that everything else is awful). Even with the stuff I did mention here, I’m only scratching the surface.
Again, as the Daily Show used to put it, do not rely on us as your only source of news.
A fun ongoing New York City story is that yellow taxis have long gotten insurance from a boutique insurance company with very low rates. The problem is that the low rates aren’t enough to pay the insurance claims, so the insurer is insolvent. When NYC said actually you need to buy insurance from a company that is solvent, drivers panicked, and the city said fine, you can all keep buying ‘insurance’ below cost, from the company that can’t pay claims. Which presumably means the taxpayer is going to end up on the hook for the difference.
The government argues that seizing $50,000 from a small business doesn’t violate property rights because property isn’t money ‘for constitutional purposes’? What the hell?
UK tells Apple it has to create a backdoor in all its encryption on all customers, around the world, for use by the UK at any time, and it isn’t allowed to tell anyone. The UK seems to think that merely not offering encryption in the UK is insufficient – Apple must still put a global backdoor into all encryption so the UK can use it. Apple has said they will refuse. Google didn’t say whether it had received a similar order, but denied that they had put in any backdoor.
Something can be overwhelmingly popular in a Democracy, be very simple to implement, be endorsed by 100% of experts, and yet continue not to happen anyway.
Polling Canada: “Canada should quickly work to eliminate interprovincial trade barriers”
All:
Agree: 95%
Disagree: 5%
Agree Among (X) 2021 Voters:
BQ: 99%
LPC: 98%
NDP: 97%
CPC: 95%
Angus Reid / Feb 3, 2025 / n=1811 / Online
It’s so absurd. The Prime Minister wants them gone too. Of course, these trade barriers don’t actually make any more or less sense than trade barriers between the USA and Canada, but here it’s that much harder be confused about it.
There is a general tendency, closely related to people’s failure to understand Levels of Friction, to assume that all things must be either Allowed or Not Allowed. The instinct tells us that not only All Slopes are Slippery and that people eventually can Solve For the Equilibrium, which are approximately true, but that you will always very quickly end up at the bottom of them, which is usually false.
Thus a certain class of person keeps making the mistake illustrated here:
Mike Solana: Either the preemptive pardons are struck down, or we have just begun a new tradition in which every president, upon leaving office, preemptively pardons himself, his family, and everyone he has ever worked with. This creates a new class of Americans officially immune from the law.
That is certainly one way it could go, but it probably won’t. There’s lots of unprincipled situations like this where such behavior does not escalate. Civilization would not survive if every time someone successfully violated a norm or got away with something, the norm or law involved de facto went away.
Also, in this particular case, Biden paid a steep price to his reputation. History, assuming we are around to tell it, will remember him in large part for the way he chose to leave, and this will for a while be a headwind for Democrats at the ballot box, and state law still exists.
Similarly, there’s no reason that a certain amount of ignoring court orders has to mean that all court orders are meaningless, or various other ‘end of democracy’ scenarios. It can escalate very quickly, and may yet do so. Or it might not.
The broader point is more important, though, which is that an exception weakens a rule but in no way must break it. It can lead to that, but often it doesn’t, without any ‘good reason’ why.
The reasons people give you for things are often fake, in the sense of not being a True Objection. Needless to say, I deal with this a lot.
Emmett Shear: This is a good thread on noticing what is happening when people’s reasons do not seem internally consistent, and how to handle the situation.
Maeбичка (detail edited for readability): It took me a long time to realize that people simply make up false reasons and justifications for things that may or may not be true, entirely independent of those reasons.
I hate this but also have begun to understand why people (probably including me?) do it, and I am learning how to navigate it.
-
First, I want to note something crucial: the people giving false reasons, whether they are intelligent or not, often do not even realize the reasons are false. They are not “lying.” Half the time, or perhaps even more, the reasons are there to convince themselves just as much as other people.
-
A second crucial thing: “False” does not mean untrue. It could even be a valid logical reason for the thing. But it is not the instinctive reason you believe in or want the thing. It is divorced from your needs and reality. So here is what false reason-giving looks like:
>I cannot do A, because B.
>Oh, good news, B is not true! So you should be able to do A, right?
>Well… but also C and D. And also B is true because E and [blah blah blah].
It took me a long time, both with clever and unintelligent versions of this, to realize this person simply does not want to do A, period.
The unintelligent version of false reasons, where their logic does not make sense, is quite obvious, and it is how I discovered the phenomenon in the first place (recently!).
But false reason-giving can be very subtle.
In the sophisticated version, the words are logical!
but the emotions might not match, or seem disproportionate. If you are sensitive, you will notice something is off, or their words are not grounded.
This is extremely common. I would perhaps even claim 90% of modern communication is this type of nonsense.
People do not mean what they say, and do not say what they mean. Instead, they say whatever is strategically optimized to achieve the outcomes they want.
And of course they would! This is a reasonable strategy in a world where boundaries are disrespected and people are alienated from their desires!
If “I do not want to do A” is not respected on its own (by others or your own inner critic), of course you are going to come up with whatever reasons you can think of to justify it to other people or to yourself!
By alienated from desires I mean:
People especially do not respect the boundaries/desires of children—who then become uncertain of their own boundaries/desires, and then grow up having to justify them not only to others but also to themselves.
This is how someone would come to habitually give reasons they do not realize are divorced from their own truth.
Rationalists have noticed this tendency too, but they usually come to the wrong conclusion: “If there is no clear reason not to do A, then as a rational person, I should be fine with A.”
No! If you do not want to do A, that is important to account for, even if you do not know the reason.
Speaking of rationalists, a key thing about false reason-giving is that intelligent people are not immune. They are simply good enough to fool each other. Both unintelligent and intelligent people do it, but the latter may never be detected.
Likely entire civilizations have been built on the false reasons of intelligent people.
As an autist-adjacent, it’s hard for me not to get caught up in the logic games when talking to ppl putting up an obfuscating fog of fake logic.
I chase around people’s Bs and Cs and Ds, without taking a step back to realize…oh. All they want is for me to accept their A.
I love a tight rationale and can play ball that way, but I also have a deep respect for the secret emotional currents and needs that actually impel people. So it’s frustrating to me when people think they need to come up with bad fake bullshit logic to convince me!
An example of this btw is “I can’t come to your party bc I have to grocery shop” instead of “I find it weird you invited me but not my husband so I don’t wanna come.” Our culture all but requires people to bullshit one another this way
I REALLY appreciate it when people play it straight and put on the table how they actually feel!
I trust and respect it MORE if you say “I don’t have a reason, I just want to/it just feels right to me”!
I am still learning to step back from my annoyance that ppl feel the need to do this, and recognize why they are this way:
1) there are pushy boundary disrespecters (ESP if ur a kid) who wont leave u alone or respect your preferences unless u put up a big defensive bullshit wall
(“you HAVE to go kiss Aunt Susie, she gave you a present” => “I am Bad if I don’t do things including physical favors for ppl who give me things” => “if I say I have a cold, I can Not kiss her and still be Good”)
2) The dominant cosmology of our whole modern world IS Reasons and Logic, undergirded by the church Systems and Bureaucracy. So of COURSE people feel they need to provide Reasons and Logic when challenged.
[thread continues at length]
Yep, fake reasons are all over the place, including reasons we give to ourselves. They can be ‘good’ fake reasons, or even true partial reasons, that could plausibly have been the real reason or that even are real reasons but not full or sufficient explanations and thus not true objections and not cruxes. Or they can be ‘bad’ fake reasons, that are Obvious Nonsense or are straight up lies. Or anything in between.
Here are the most important notes that come to mind on what to do about this:
-
If you do not want to do [A], and cannot come up with a legible reason not to do [A], then that is indeed a rather strong reason to consider doing [A], but I agree it is not conclusive. You should look for illegible reasons, the real reasons you don’t want to do [A], and see if there’s something important there. Once you know why you have the desire not to do [A], then you can decide to ignore it if the reason is dumb.
-
If someone says [B], [C], [D] in turn, the conclusion is not always that they want [~A] period. It means that there is some unknown [X] that is the actual reason. Sometimes [X] could be overcome. Sometimes it couldn’t.
-
Sometimes they don’t know what [X] is and you have to figure it out.
-
Sometimes they do know what [X] is, but for social reasons they can’t tell you.
-
Sometimes they want you to figure it out but not tell them, and they will sometimes be dropping rather aggressive hints to tell you this. This can involve things you can’t say out loud, secret information, and so on.
-
Sometimes they want you to figure it out and maybe tell them, but they can’t tell you first, whereas if you go first it makes it okay.
-
Sometimes they want to essentially tell you ‘because of reasons’ and do not want you to figure it out.
-
Sometimes they simply can’t even and don’t have the time to explain, or even to figure out what they’re thinking in the first place. Can be highly valid.
-
They may also be trying to fool you, or they might not.
-
We’d indeed all be better off if we just said the real reason more often, people are way too afraid to do this.
-
“I don’t want to do that” is, in my book, a highly valid reason.
-
You can (literally!) say “I don’t want to do that because of reasons” to indicate that you do indeed have legible-to-you reasons to not do this, but that you are choosing not to share them for whatever reason.
-
You can also (literally!) say “I just don’t want to do that,” or “I’m not feeling that” or if you’re among true friends “I don’t want to do that not because of reasons.”
-
It’s important to tell kids real reasons whenever possible, and when it’s not possible to give them minimally fake reasons, even if that means being vague AF.
-
There are certain classes of reasons that are almost always fake. For example, when a VC says they won’t fund you, or a company does not hire you, unless they point to an actual obvious dealbreaker you should assume the reason is fake.
There were recently some rather epic fires in Los Angeles.
Many aspects of those fires don’t fall under this blog’s perview.
Others do.
So while these may not be the most important aspect of the fires, that’s also why the wise man does not rely on us as your only source of news.
One fun aspect of these fires is that State Farm specifically declined to renew fire insurance coverage in exactly the most impacted areas, because the insurance company thought there was too much fire risk and they weren’t allowed to raise prices.
That is some killer risk management, by a mutual insurance company that doesn’t have shareholders. For which of course various people are mad at State Farm rather than suddenly being very curious about the other areas where State Farm wasn’t interested in renewing coverage.
Unusual Whales: BREAKING: State Farm, one of the biggest insurers in California, canceled hundreds of homeowners’ policies last summer in Pacific Palisades—the same area which is now being ravaged by a devastating wildfire, per Newsweek.
Or (via Unfinished Owl):
Jakeup: translation: the state of California got 6 month’s advance warning from the best risk-assessment professionals that the risk of fire in this specific area is too high and proceeded to do nothing at all with this information
insurers want you to know this one weird trick to keeping people insured without raising premiums: mitigate the actual fucking risk
Kelsey Piper: Okay so the Eaton fire and Palisades fires were in areas where State Farm declined to review fire coverage. …what are the other areas in California where State Farm declined to renew fire coverage?
They did all of this fire risk prediction work for us, let’s use it!
By far the most realistic part of ancient Greek myths is the part where the prophets tell them exactly what’s going to happen, and they get really angry at them and ignore them, and then it comes true, and they get even madder and ignore them harder.
Ezra Klein: This seems like a good question to ask. If insurers are good at doing anything it’s modeling risk so they don’t lose too much money. We should take those models seriously.
Patrick McKenzie: You’ll notice that in society we have many competing classes of prophets. The ones who actually have to be right about the future are despised, while the ones who are never scored on that continue being invited to the nicest parties.
Not at the nicest parties: insurance underwriters, prediction market users, conversion optimization specialists.
At the nicest parties: politicians, journalists, and people who publish in fields where replication is a thing you ask only of your enemies.
“Really we seem to like science and scientists. Isn’t the plucky hero in a movie likely to be a scientist? Didn’t Einstein attend lots of parties?”
Power likes science to precisely the extent that science supports power. When it doesn’t, science is replaced with Science (TM).
It is a good thing that I actively prefer not to be at the nicest parties. Please don’t make me go to those parties.
Here’s why State Farm had to stop writing policies, because it turns out ‘because prices were capped and the expected value of the policies was negative’ isn’t quite a full explanation.
Or rather, that was the short version, here’s the long one.
Ian Gutterman: I see a lot of people reacting to State Farm’s decision to stop writing new home insurance in California.
But there seems to be a lot of confusion about their motives.
The last thing State Farm wants to do is give up business.
Here’s why State Farm felt they had to act.
State Farm is a mutual insurer which means it’s owned by its policyholders.
Mutuals do not prioritize profit. They make much lower returns than public insurers.
What do mutuals care about?
-
Maximizing customer count.
-
Keeping their agents happy.
Turning off new business upsets both groups. It creates a lot of problems.
Agents make more $ off new clients than renewals. They are angry at State Farm.
Market share is how corporate keeps score. Sacrificing it is bad for morale.
So why would they do it?
Because it would be financially reckless to keep growing given the CA regulatory problems.
CA is a very difficult place for insurers. It limits price increases to <7%/year and makes it difficult to drop customers who require more than that.
These restrictions are tolerable most of the time.
But in high inflation environments these limits quickly become unbearable.
If claims inflation grows 10%/yr, a 6.9% price cap means results get worse each year so a new customer will lose SF more and more money every year.
This is why State Farm had to walk away. It is not a flex or game of chicken. It’s a capitulation.
If they are already 25% below the needed price, then even 3 years of flat costs won’t let rates catch up.How did things get so bad? Higher construction costs (materials and labor shortages) and climate change (e.g. wildfires) in recent years made claims worse than expected.
At the same time, the Insurance Commissioner stopped approving any rate increases.
Why weren’t normal rate increases approved? 2022 was an election year and the Insurance Commissioner is elected in CA.
It’s easier to get re-elected campaigning on no price increases! Who would have imagined there would be future consequences?
Meanwhile State Farm recently reported first quarter results and they were likely the worst in company history. They paid out $1.30 on every $1 of insurance they sold nationwide!
That’s why you’re not seeing as many insurance commercials.
John Arnold: CA politicians wanted to keep the cost of homeownership from rising so they limited property insurance rate increases, driving private insurers out of the market and homeowners to the state’s insurer of last resort, which itself was not allowed to charge actuarially sound rates.
This sounds like State Farm got pushed well past what would be my breaking point. It was willing to write losing (minus expected value, or -EV) policies for a while, but when you’re already underwater and they say no rate increases at all? Okay. Bye.
And yes, if you have a state ‘insurer of last resort’ that moves in and charges artificially low rates in exactly the places private insurance won’t touch, I hope that you know what will happen after that, rather than this being me having some news. As in this 2024 post calling this a ‘ticking time bomb.’ Boom.
So what does the state plan to do about the fires? Why, of course.
Eytan Wallace: BREAKING: California Insurance Commissioner @RicardoLara4CA has issued a mandatory one-year moratorium that will prohibit insurance companies from enacting non-renewals and cancellations of coverage for home owners within the perimeters or adjoining ZIP Codes of the Palisades and Eaton fires in Los Angeles County regardless of whether they suffered a loss. The moratorium will expire on Jan. 7, 2026.
The CA Dept. of Insurance may issue a supplemental bulletin if additional ZIP Codes are determined to be within or adjacent to a fire perimeter subject to this declared state of emergency for Los Angeles and Ventura counties.
Miles Jennings: In my 20’s, I ridiculed friends for liking Atlas Shrugged – any political philosophy can be justified if you use ridiculous characterizations of government actors with absurd approaches to problem solving.
In my 40’s, I’m going to spend a lot of time apologizing.
What will happen now after the fires?
Biden decided to send everyone involved a one-time $770 payment. We’re sorry we burned down your village? Yishan says this reflect the government being unable to provide basic relief supplies and imagining private entities doing it, but that seems fine? As long as you don’t then ‘ban price gouging.’
People will try to rebuild their homes.
I say try, not because they won’t have the money, or because we don’t know how to do that. I say try because there will be a shortage of Officially Approved Labor to rebuild with especially with crackdowns on immigration, and because building houses is not something taken kindly to in Los Angeles.
I also say try because:
Gavin Newsom (Governor of California): NEW: Just issued an Executive Order that will allow victims of the SoCal fires to not get caught up in bureaucratic red tape and quickly rebuild their homes.
We are also extending key price gouging protections to help make rebuilding more affordable.
Oh, price gouging protections. So much for supply.
Samuel Hammond: “Extend protections against price gouging on building materials, storage services, construction, and other essential goods and services to January 7, 2026, in Los Angeles County.”
i.e. create an artificial shortage
Well, at least we get rid of some of the extra stupid rules, that part will help. In other cases, of course, they’re still effectively blocking almost all home construction with that same ‘bureaucratic red tape’ that he seemingly can suspend at any time.
Eli Dourado: Putting aside the urge to dunk on Newsom, I do think this is a great precedent.
Any time we want to do anything with any urgency, whether it is rebuilding from fires or building a border wall, we waive a bunch of laws and regulations.
Well hang on, those laws and regulations must not actually be that important, right? And they slow everything down? So can get rid of them and replace them with rules that don’t slow things down?
Many people are asking these questions, love to see it.
Kelsey Piper: Wait a second, could he suspend all CEQA and permit requirements by executive order at any time (after declaring emergency)? I’m not totally sure the governor should have that power but if he does – set the state free, Governor!
Declare a cost of living emergency or a wildfire vulnerability emergency or whatever and make it legal to build any density with streamlined permits in every urban low-risk area! Be remembered as the governor who saved California with a one page EO!!
Would it hold up in court? Maybe not, but you have to try.
Alternative suggestions anyone? How’s it look?
Nah.
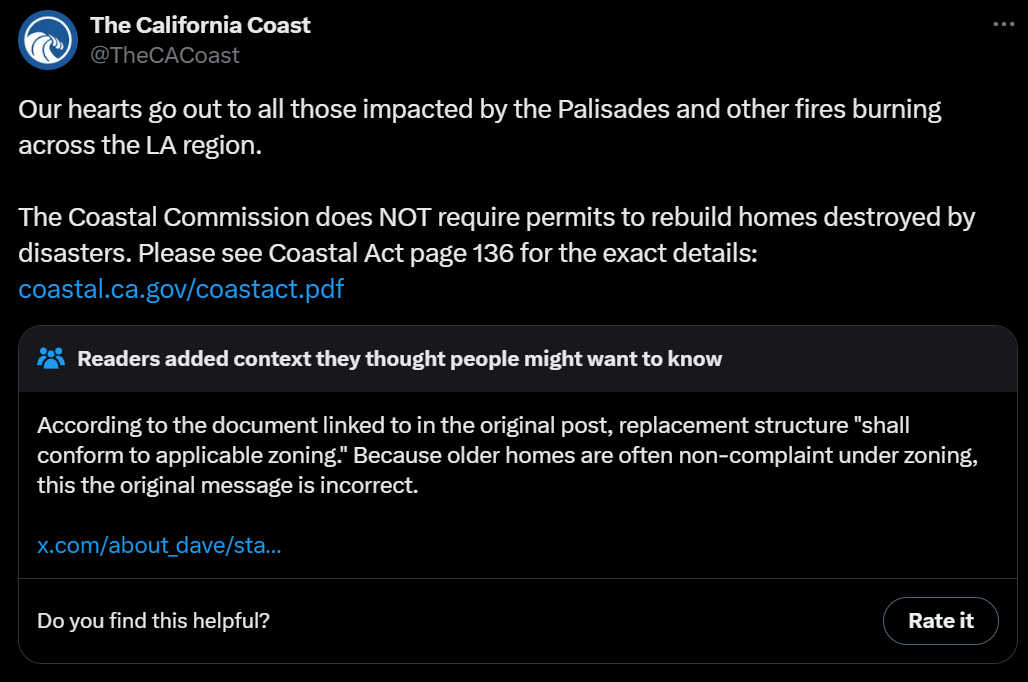
And because, if your home is no longer ‘conforming to applicable zoning’ you will need to fix that and then go through the entire permit process over again:
This is of course a great opportunity to upzone that area and build more. Not that they have any intention of taking advantage of that.
Gavin Newsom: This [claim that they are working with developers to change zoning in burn areas to allow pass apartments] is not true.
Alex Tabarrok: Of course it is not true because upzoning would be a smart thing to do. The increased wealth would help to pay for rebuilding.
I did a fact check of Scott Adams claims here, and so many of them were false or unsupported I deleted the analysis – no, it doesn’t cost more to build a new house than it is worth, especially when you have to work so hard to get permission to build it. But yes, we should expect a labor shortage, and for permitting to delay things by 2+ years when you can’t rebuild exactly the same house within code and get a waiver, and 5+ years in at least 10% of cases. And the property tax resets could get ugly due to previous abuse of Proposition 13, although I won’t shed a tear there.
StewMama: Only 25% of the houses burned in Malibu in 2018 Woolsey fire have been rebuilt [as of 2023].
Elon Musk speculates that this ‘might finally spell doom for the Coastal Commission,’ haha no that is not how any of this works, this is California.
If you’d rather sell your home for what the market will bear right now?
Oh, we cannot have that.
Governor Newsom: Today, I signed an executive order prohibiting greedy land developers from ripping off LA wildfire victims with unsolicited, undervalued offers to buy their destroyed property.
Make no mistake — this is a prosecutable crime.
Aella: This is really jaw dropping stupidity.
Ronny Fernandez: I am genuinely interested in breaking this law. If you or anybody you know would be interested in selling me any parcel that burned down in LA for $500, please let me know.
Emmett Shear: This order is insanity. The LA fires and our governments response has radicalized me against our current government in CA in a whole new way.
Kendric Tonn: “Below market value” seems like such a weird guideline when regarding land in neighborhoods the character of which has been permanently altered located in political environments about which new information and circumstances have recently arisen.
I mean, I get two or three calls every day from subcontinental call centers from people, I suspect, mostly hoping I’m senile or desperate enough to sell below market value, and I want them all drone struck, I get it.
But IDK man, you gotta find that market value somewhere, and I kind of suspect there’s a whole lot of finding out that has to happen in some of these places.
Bitzuist: It’s a scene from atlas shrugged. Gov officials virtue signaling but not actually helping anyone.
Emmett Shear: Ayn Rand is, tragically, wrong about her heroes but totally on point about her villains.
Dale Cloudman: Atlas Shrugged was not hyperbole.
CA: made it illegal to raise fire insurance rates. Insurers pulled out. CA offers their own but it is mismanaged and can’t cover the risk.
After a huge fire (caused by ca making it illegal to properly manage their forests), they made it illegal for insurers to pull out, insurers have to renew policies at old (unprofitable) rates for a year
Now with your home burnt down and no money to rebuild it, CA has made it illegal to sell your land for a price they deem is too low. Incredible.
I believe that technically, what you can’t do is make an offer that is too low. You can accept whatever offer you want? So the market can still function, it’s just weird.
And indeed, I think it would be fine to say that you need to first get an IoI (indicator of interest) from the potential seller fully unprompted, to avoid what Kendric describes above. It’s somewhat tricky to get it right, but seems doable.
Noah Smith suggests less deciding which particular carbon emissions or other scapegoats to try and blame this on and more preparing for future fires, pointing out some of the lowest hanging of fruit on that.
If we are playing the blame game, one thing to blame is that under CEQA, the California Bonus Double NEPA, wildfire mitigation projects must undergo years-long environmental reviews, often involving litigation.
Forester Mike: I have done CEQA reviews for forest management projects in CA. They are completely insane.
One time we had a simple fuels reduction project that we started review for in 2022. Goal was to begin logging in summer 2023. Permit rejections and re-reviews led us to need to cut the project area in IN HALF. Last i checked in mid-2024 not a single acre had been worked.
It should be mind numbingly obvious that wildfire mitigation projects should be immune from CEQA and NEPA review. But forget it, kid. It’s California.
And we’ve saved the stupidest executive order for last.
Chris Elmendorf: Kudos to @dillonliam for covering the unintended but entirely foreseeable consequences of CA’s anti-price-gouging law for L.A. fire victims.
Liam Dillon:
-
Property owners are making fewer properties available for rent because of a state law barring new listings from charging more than $10,000 a month during the state of emergency, real estate agents and brokers say.
-
The price cap is below what L.A.’s pre-wildfire market would bear in many expensive neighborhoods where wealthy displaced residents may be willing to relocate.
-
The circumstances may be adding to the squeeze wildfire victims are facing while searching for replacement housing.
Josh Barro: Simply banning rental listings in LA for over $10,000 a month is an insane policy. There are a lot of rich people whose houses burned down for whom that would be a normal rental price, even before price effects from a shortage.
Jeff: A mortgage at today’s rates for the median valued home in Pacific Palisades would run at almost exactly double that cap, or just over $20k, assuming 20% down payment and 7% interest rates.
Well, yes, obviously. There will be a non-zero number of places that are slightly above $10k, that will now rent for $10k plus bribes or similar. But then there are lots of places that were already well over $10k, which will sit idle during the emergency, which in turn drives up the prices of everything else during that time, and means a lot of people are forced out entirely. Oh well. Who could have seen that coming?
Finally, here’s the ultimate Gavin Newsom Tweet, except for its lack of restrictions on prices.
Gavin Newsom: I remember the guy who called me Newscum in 7th grade. I can handle that. This isn’t about me. It’s about the people we represent — and the aid they deserve.
Andrew Critch: Respectfully, Governor Newsom, if you say “I/me” four times in a tweet, you are not helping your case that “this” isn’t about you. I’m sure you are working very hard right now to protect Californians, but want to share that your messaging about yourself is not landing well.
(This message is about me, and how your message landed, with me.)
Vitalik Buterin is right. You can just go back to 2013-era morality where free speech, starting companies and making good products, democracy and cosmopolitan humanitarian values are good, and monopolies, vendor lock-in, greed and oppressing people are bad.
Eric Wall: Human morality peaked in the late 1980s as represented by Jean-Luc Picard in Star Trek: The Next Generation.
All the evolutions of morality since then, on all topics from inclusivity to tolerance, gender, right-leaning/left-leaning have been degradations since that perfection.
There are obvious issues with Picardian morality, for example it thinks it’s good that we age and die, it has big scope sensitivity issues and it doesn’t know how to handle realistic AGI or various other utility monsters or other inconvenient scenarios (obvious examples: The Borg, if you don’t have Q or plot armor on your side, but it’s a very broad category, and if they’d successfully figured out how to mass produce Data all philosophical and practical hell would have broken loose). One could say it doesn’t work out of distribution, and it also isn’t that competitive in a future universe where the Federation keeps getting almost wiped out, which doesn’t seem great. But yeah, pretty great.
Important words of wisdom:
Paul Graham: When you have good friends over for dinner, you can just eat what and where you normally do. You don’t have to shave or change your clothes or cook different food, or eat in the dining room.
The more laborious way we entertain people we don’t know as well is not for their sake. It’s because we worry they’d be shocked if they saw how we actually live. But only 1% of them would be; 99% of them live the same way, when no one’s looking.
Maybe the reason you have to be formal when entertaining strangers is that you know they assume any such dinner is much more formal than everyday life. So if you just gave them everyday life, they’d assume in actual everyday life you ate dinner out of a trough.
That’s exactly right. You present a better face partly because it’s nice, partly because people adjust expectations for the fact that you are likely putting on a better face.
The worst part about this is it leads to far too few gatherings. If you were to have friends over and act otherwise almost totally normally, that would be a clear win. But you think ‘if I did that I’d have to do all this work and clean up and so on.’ So you don’t invite them, and everyone loses.
You can have a fast food burger meal for the low, low cost of 20 minutes of your life, says Bryan Johnson. The obvious clarification question is ‘relative to what other choice?’
Let’s say it is true. If that’s the price of eating unhealthy, I expect most people would say screw it, that’s really not very much time. If people thought like this, I bet they’d eat a lot more fast food burgers, not less. The reason that’s a mistake isn’t that people care that much about the 20 minutes. It’s that they also spend what time they still have in worse shape and feeling worse. That’s the pitch that will far more often work.
On regret, I’ve found my instincts on ‘will I inherently regret not doing this’ are spot on and most people’s seem to be as well:
David Holz: We tend to regret the things we don’t do *muchmore than the things we actually end up doing – so you should always lean towards doing slightly more “regrettable things.”
That’s distinct from predicting a good result or knowing what we will regret if we actually do it, which we are far less good at doing. But we’re very good at knowing when we’re in a ‘if I don’t try I’ll regret it’ situation, especially in scenarios where if you don’t do it, you never know how it would have gone.
I do think you should give this a lot of weight when you get a strong ‘I will regret [X] or ~[X] but not the other one’ instinct, especially if you’ve trained your predictions of this on results.
A similar lesson is to put substantial weight on ‘story value.’
The classic form of this mistake is to avoid taking a risk, but to actually then feel worse than if you’d taken the risk and failed. The fully classic version, of course, is asking someone out or saying yes to someone else, or applying for a job, where even if you get rejected it’s better than always wondering. And you never know.
Old popular Neel Nanda post on making close friends. It’s full of obvious things like actually talking to people about things you both find exciting, filtering quickly, asking what you want, following up and so on, that are obvious when you say them but that you definitely weren’t doing, or weren’t doing enough (see More Dakka). Consciously having Friendship Building Questions in your queue is the most non-obvious thing here, and seems wise, but am I going to actually do it?
If you pay attention to details, it’s easy to sense which people are happy to be there. I think this is true when no one is working hard to fool you. But then Defender further claims it’s ‘near impossible to fake being genuine,’ and points to the fact that great actors try to really believe they are a given role. But people can do that performatively in real life too, to act as if, and yes I think it often remains fake.
A very good theory of different types of exhaustion needing different types of rest.
Bayesian Asian: I was confused how to ‘rest’ in a way that seems distinct from vegetating (TV, games, scrolling) or working (art, code).
I grilled my friends about how they rest, and came up with a tentative list of different *typesof exhaustion, which need separate solutions.
-
Procrastination-guilt => work
-
Choice exhaustion => TV marathon, social event, flow state (gaming, coding, or art)
-
Loneliness => socialize, LLMs, metta meditation
-
Physically tense/inert => exercise, bath
-
Thoughts racing => TV, scroll, concentration meditation
(2 miiight be the same as 5?)
usually my problem is 1, so I feel more rested the more I work
one Classically Restful Activity that usually feels anti-restful for me is going on a walk. it works when my issue is 4, but usually 4 is far behind 1 and 5, which walking exacerbates
I didn’t list reading anywhere above because it’s too intellectually and emotionally varied
challenging but worthwhile material addresses guilt-of-not-doing, and maybe thoughts-racing. Reading certain authors addresses loneliness-tired. Absorbing books address choice-exhaustion
I’m usually ‘tired’ because I’m fighting myself all the time over my todo list. so I’ve always associated ‘rest’ with ‘flow state’. it feels good, and when I exit it, the “you never do anything” guilt-buzz is gone. yay! rested!
…but I’m 4 or 5 tired, which idk how to deal with
because I just HAD a restful 5 hour coding or painting session. what do you mean you need more, different rest
(I mean, in practice I scroll social media uncontrollably for an hour. so my routine works. but I didn’t have an underlying model of what problem this was solving)
after work I’m out of energy (I’m going to mess up the painting/code if I try to do more) but I’m still keyed up and my thoughts are racing, so I need to turn off my brain and make something else be in control of my mental narration for a while
The principle seems strongly correct. You don’t need generic ‘rest’ or ‘to relax’ or ‘a vacation.’ You need to address whatever your particular issue is, however you in particular address it. I don’t match up with every solution proposed here, but most of them make sense.
Also, there’s a type #6, which is actual physical exhaustion? Where the solution is, as you would expect physical rest.
And I think type #7 also exists, a mental exhaustion where you’re just out of thoughts. Your thoughts aren’t racing, the issue isn’t choices, it’s just you’re out of compute. For me #4 solutions or a walk work reasonably here, but so does TV or a movie.
Walking in particular works well for me in many cases. It can help with #4, but I actually really like it for #2 or #5 or #7 too, you pick some music (or a podcast if you have a relaxing one available in context) and you go. And if it’s choice exhaustion or being out of thoughts, I have a standard ‘The Hits’ list of 400+ songs and I just randomly spin to some position in it.
I have other random notes, but I’ll wrap up there.
Bryan Johnson, whose plan is Don’t Die, is hiring for Blueprint, or at least he was, and offers an update.
The ‘five-star controversy for the three-star film’ that is Emilia Perez. The real problem with Emilia Perez is that it simply is not very good, as audiences agreed. They made an awards show darling of it anyway for obvious cultural reasons, but now even those cultural reasons have turned against it, it’s on the ‘wrong side of history.’ The best part is remembering that we used to have to care about such things, and now we get to sit back and laugh at them, and hopefully have a better film win the Oscars.
My other observation for the month is that I clearly don’t rewatch movies often enough versus seeing new ones – when I do revisit the average experience is miles better. Thus there’s more 5-star ratings on my Letterboxd than the bell curve would suggest, but it’s all selection effects. That has diminishing returns, but I’m nowhere near them. Consider whether you are making the same mistake.
Good news, we also have at least a test flight of a supersonic jet!
The press was absurdly uninterested in the flying of a supersonic jet. NYT and WaPo both reportedly told Boom to come back when they were actually flying passengers. This seems like rather bigger news than that?
Paul Graham: What most people don’t realize about Boom is that if they ship an airliner at all, every airline that flies internationally will have to buy it or be converted against their will into a discount airline, flying tourists subsonically.
Ticket prices will be about the same as current business class prices on international flights. How can this be? Because the flights are so much shorter that you don’t need lay-flat beds. You can use the seat pitch of domestic first class.
If business class travelers have a choice of a 10 hour subsonic flight from Seattle to Tokyo or a 5 hour supersonic one at the same price, they’re all going to take the 5 hour one. Which means all the business class travelers switch to supersonic.
Patrick McKenzie: Also think that many business travelers would switch loyalty programs over it, which is a threat out of proportion to the number of transoceanic flights. It might be the only product innovation in decades that has threatened that.
That same price, from the business flyer’s perspective, is of course $0. And in a world where many people charge hundreds to thousands of dollars an hour for their time, if you can cut 5 hours off a flight, ‘the sky’s the limit’ is a reasonable description of the ticket prices you can charge for business flights booked on short notice.
Supersonic travel would also highlight the need to lighten airport security and on-ground transit times, as the flight itself would be a much smaller portion of time spent.
The only problem? We banned supersonic flight. We have to make it legal. Elon Musk has promised to fix it. Manifold says 26% chance this gets done within the year.
Michelle Fang: I know a Waymo hate to see this one coming.
And here’s a report on Waymo in Phoenix, with many starting to use it as their go-to taxi service, with the biggest barrier that Waymos obey the law and thus are modestly slower than Ubers. And the most killer app of all is perhaps that society will let children take a Waymo alone?
Ryan Johnson: Parents now comfortable sending their kids to school and elsewhere. This is a major vibe shift. Early on, women solo riders were the loudest champions. But parents are overtaking that. Effusive praise e.g. “I have my freedom back!”
This is huge. Many parents have to effectively structure their entire non-work lives around providing transportation to children, because our society has gone completely bonkers and if you let children do on their own what they used to do all the time, the cops might get called. This fixes some of that.
In the medium-term this will be highly pro-natalist, especially if the threshold age becomes relatively young.
My understanding is that the current limiting factor on Waymo is purely their ability to manufacture the cars. Right now all of this is coming from only about 700 cars. Alas, they seem uninterested in providing details to allow us to chart their growth.
The ACC is considering engaging in hardcore shenanigans with its title game to try and secure more spots in the College Football Playoff. Possibilities include having the regular season winner skip the game since they’d probably be in anyway, to try and secure a second slot. That would be an overtly hostile act and also ruin the actual conference season and championship, and I would presume the committee and also everyone else would do its best to retaliate.
Their other suggestion, however, is to have a semifinal the week before the championship game. That isn’t only not shenanigans, that’s awesome, and we should be all for it. Conference semifinals seem great, especially now that fully deserving teams who lost in the semis could be in the playoff anyway.
It’s weird to see a football player get a tattoo of Matthew 23: 12 (Whoever exalts himself will be humbled, and whoever humbles himself will be exalted) and then point to it after a touchdown on national television. What are you trying to say?
The Mets seem to have won the hot stove league, as they resign Pete Alonso to a two-year, $54 million deal. We were always talking price, and we successfully held out for the right one. OMG, LFGM. Nixon says we’re still one bat and two relievers short.
Meanwhile, Juan Soto has the goal of ‘stay exactly the same,’ sounds good to me.
So yeah, what the hell was up with that Doncic trade to the Lakers for Davis? Nate Silver treats it as an example of a lemon market, where there’s clearly something wrong with Doncic, and the Mavericks had a reason they didn’t want to keep him on a ax contract.
Tyler Cowen instead treats this as evidence the economics of basketball have changed, noting that Doncic was causing trouble and not fun to be around, and the whole point of choosing to own an NBA team is that it is fun. There is something to that, but you know what else isn’t fun? When the entire fanbase predictably turns against you, the owner.
Seth Burn has a different proposal. Texas isn’t playing ball with the Mavericks. Perhaps this was a bribe to the Lakers and the NBA so they would greenlight a move to Las Vegas? Thus the word coming down to focus all talk on the Lakers. Seth also notes that this makes Luka ineligible for a Supermax contract, which costs him $116 million dollars, which goes right into cap space. As Seth says, given that incentive, you’d think every otherwise supermax-eligible player would get traded – if everyone knows that’s why you’re doing it, you should be able to put together a win-win deal. However, this very obviously wasn’t that, and ownership signed off for some reason.
Ondrej Strasky concludes from Artifact’s failure that if you can’t teach the game in five minutes, you’re doomed. [Edit: I don’t think this is the primary reason Artifact failed, and I think Brandon in the comments, who was the lead on the game, is much closer to what actually happened, which was that there were insufficient Outer Loops.]
I asked about DoTA and LoL, and was told that people consider the ‘click random buttons’ version to be ‘learned the game’ so it’s fine, and the other argument was path dependence, if you have existing buy-in you can push through it. Whereas I didn’t feel like the five minute explanation let me have fun or meaningfully play.
I think there’s certainly a big weight on ‘you’re having fun within five minutes’ but clearly it’s not strictly necessary, given Magic: The Gathering, and also many single player games. Anyone remember Final Fantasy X? Great game once you get into it but you literally don’t make a decision for the first 40 minutes. Many such cases. But I suppose during those 40 minutes you aren’t overwhelmed or confused either. Maybe that’s the actual lesson, that you can’t have people confronting the complexity for more than five minutes in a way they notice? And people who don’t want it can just durdle in the dark for a while and maybe restart later.
Elon Musk has now formally confessed to cheating in Path of Exile 2. And then he bragged about the character he was cheating with anyway. Pathetic.
My journey with Path of Exile 2 is that it’s been some relaxing ‘more Path of Exile’ but that it has also been frustrating. The boss fights are not easy, and they often take a long time, and several feel like DPS checks. And the grinds in areas are very large, even relatively early. So overall, it’s… fine, I guess.
Original Final Fantasy programmer Nasir Gebelli says writing his legendary code “was pretty simple” and it could even be better. Good times, man.
It seems only 40% of players of Civilization VI ever finished even one game, hence the emphasis in Civilization VII on individual ages. They are talking as if it involves catch-up mechanics, which I’m mostly not a fan of in these contexts. Let it snowball, start another game and so on.
I also agree that the threshold win conditions tend to take the fun out of the endgame. You’re building a civilization, and then you steadily pivot into sacrificing everything in pursuit of some specific goal, everything else doesn’t matter. Or you’re going about your business and suddenly ‘oh Babylon got X culture points, game’s over, you lose.’
While this is looking to be in some senses highly realistic as we speedrun in real life towards the real scientific victory condition of AGI (well probably everyone-loses condition, given how we’re going about it) and most board games have the same issue, I’d like to minimize this and keep everything mattering as long as possible, and also avoid invisible-to-you events you don’t interact with like ‘Babylon got X culture points’ effectively being like someone else built ASI and converted you with nanobots.
Steam emphasizes its ban on in-game ads, including optional ads that provide rewards. You can still have in-universe ads and such. Good for Valve.
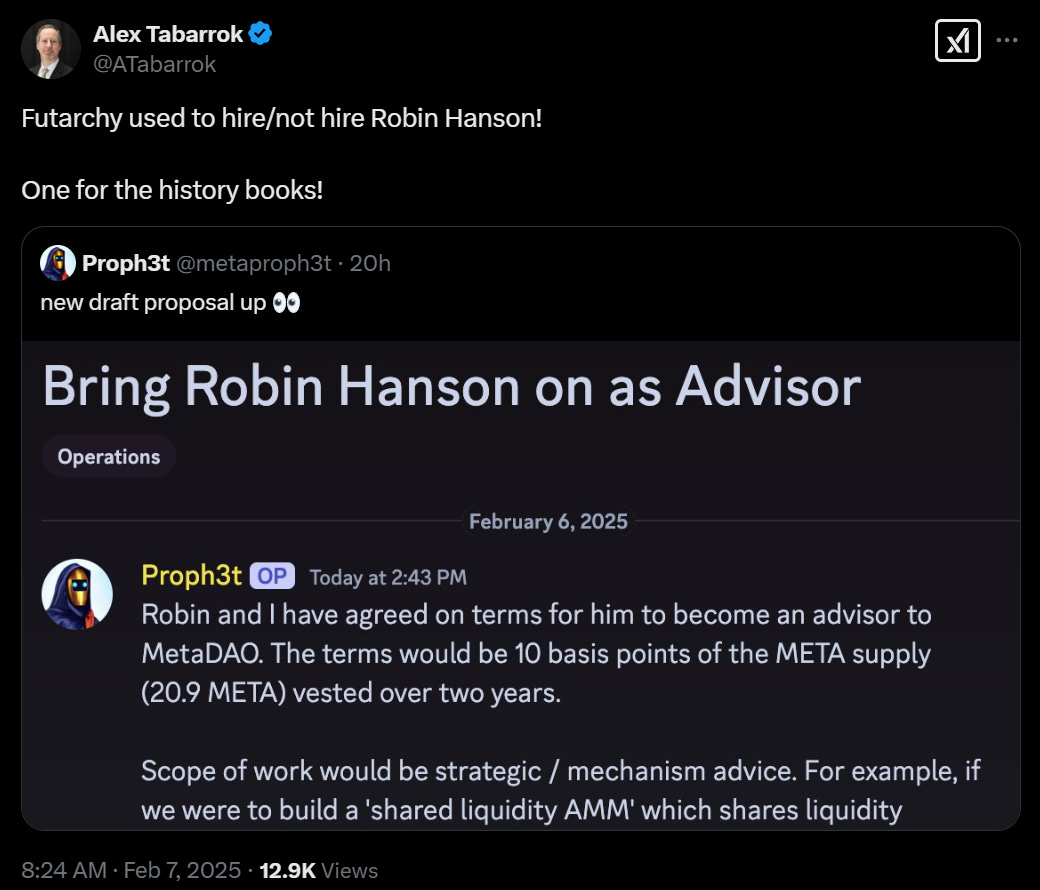
You’re ngmi if you don’t realize that this is indeed hilarious:
Would it have better historic event if the vote said yes, or if it said no?
The vote said yes, with a 10% gap in value for approval. This likely highlights an issue with Futarchy: It’s using Evidential Decision Theory (EDT). The 10% gap is mostly because the DAO that approves this is the superior DAO.
Oh, sure they can. Try them.
We have an announcement.
Bernard Van Dyke: i fw all types of music, they callin me polyjammerous