Ben Thompson interviewed Sam Altman recently about building a consumer tech company, and about the history of OpenAI. Mostly it is a retelling of the story we’ve heard before, and if anything Altman is very good about pushing back on Thompson when Thompson tries to turn OpenAI’s future into the next Facebook, complete with an advertising revenue model.
It is such a strange perspective to witness. They do not feel the AGI, let alone the ASI. The downside risks of AI, let alone existential risks, are flat out not discussed, this is a world where that’s not even a problem for Future Earth.
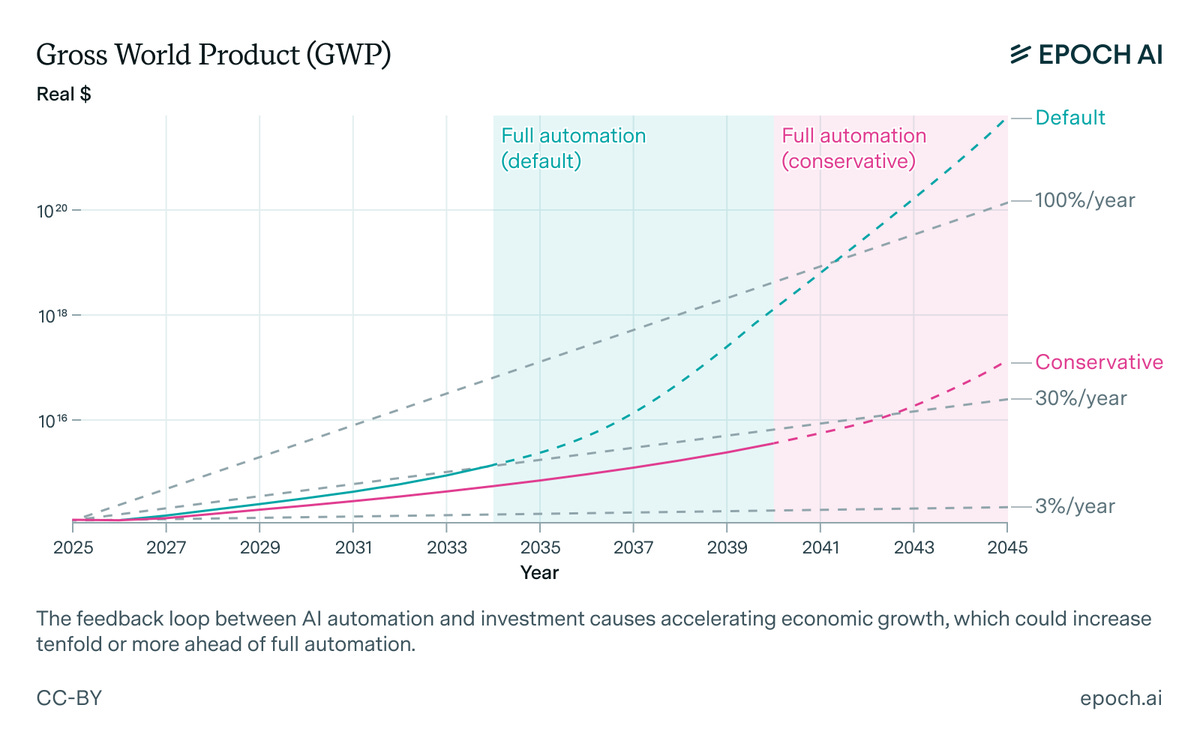
Then we contrast this with the new Epoch model of economic growth from AI, which can produce numbers like 30% yearly economic growth. Epoch feels the AGI.
Given the discussion of GPT-2 in the OpenAI safety and alignment philosophy document, I wanted to note his explanation there was quite good.
Sam Altman: The GPT-2 release, there were some people who were just very concerned about, you know, probably the model was totally safe, but we didn’t know we wanted to get — we did have this new and powerful thing, we wanted society to come along with us.
Now in retrospect, I totally regret some of the language we used and I get why people are like, “Ah man, this was like hype and fear-mongering and whatever”, it was truly not the intention. The people who made those decisions had I think great intentions at the time, but I can see now how it got misconstrued.
As I said a few weeks ago, ‘this is probably totally safe but we don’t know for sure’ was exactly the correct attitude to initially take to GPT-2, given my understanding of what they knew at the time. The messaging could have made this clearer, but it very much wasn’t hype or fearmongering.
Altman repeatedly emphasizes that what he wanted to do from the beginning, what me still most wants to do, is build AGI.
Altman’s understanding of what he means by that, and what the implications will be, continues to seem increasingly confused. Now it seems it’s… fungible? And not all that transformative?
Sam Altman: My favorite historical analog is the transistor for what AGI is going to be like. There’s going to be a lot of it, it’s going to diffuse into everything, it’s going to be cheap, it’s an emerging property of physics and it on its own will not be a differentiator.
This seems bonkers crazy to me. First off, it seems to include the idea of ‘AGI’ as a fungible commodity, as a kind of set level. Even if AI stays for substantial amounts of time at ‘roughly human’ levels, differentiation between ‘roughly which humans in which ways, exactly’ is a giant deal, as anyone who has dealt with humans knows. There isn’t some natural narrow attractor level of capability ‘AGI.’
Then there’s the obvious question of why you can ‘diffuse AGI into everything’ and expect the world to otherwise look not so different, the way it did with transistors? Altman also says this:
Ben Thompson: What’s going to be more valuable in five years? A 1-billion daily active user destination site that doesn’t have to do customer acquisition, or the state-of-the-art model?
Sam Altman: The 1-billion user site I think.
That again implies little differentiation in capability, and he expects commoditization of everything but the very largest models to happen quickly.
Charles: This seems pretty incompatible with AGI arriving in that timeframe or shortly after, unless it gets commoditised very fast and subsequently improvements plateau.
Similarly, Altman in another interview continues to go with the line ‘I kind of believe we can launch the first AGI and no one cares that much.’
The whole thing is pedestrian, he’s talking about the Next Great Consumer Product. As in, Ben Thompson is blown away that this is the next Facebook, with a similar potential. Thompson and Altman are talking about issues of being a platform versus an aggregator and bundling and how to make ad revenue. Altman says they expect to be a platform only in the style of a Google, and wisely (and also highly virtuously) hopes to avoid the advertising that I sense has Thompson very excited, as he continues to assume ‘people won’t pay’ so the way you profit from AGI (!!!) is ads. It’s so weird to see Thompson trying to sell Altman on the need to make our future an ad-based dystopia, and the need to cut off the API to maximize revenue.
Such considerations do matter, and I think that Thompson’s vision is wrong on both business level and also on the normative level of ‘at long last we have created the advertising fueled cyberpunk dystopia world from the novel…’ but that’s not important now. Eyes on the damn prize!
I don’t even know how to respond to a vision so unambitious. I cannot count that low.
I mean, I could, and I have preferences over how we do so when we do, but it’s bizarre how much this conversation about AGI does not feel the AGI.
Altman’s answers in the DeepSeek section are scary. But it’s Thompson who really, truly, profoundly, simply does not get what is coming at all, or how you deal with this type of situation, and this answer from Altman is very good (at least by 2025 standards):
Ben Thompson: What purpose is served at this point in being sort of precious about these releases?
Sam Altman: I still think there can be big risks in the future. I think it’s fair that we were too conservative in the past. I also think it’s fair to say that we were conservative, but a principle of being a little bit conservative when you don’t know is not a terrible thing.
I think it’s also fair to say that at this point, this is going to diffuse everywhere and whether it’s our model that does something bad or somebody else’s model that does something bad, who cares? But I don’t know, I’d still like us to be as responsible an actor as we can be.
Other Altman statements, hinting at getting more aggressive with releases, are scarier.
They get to regulation, where Thompson repeats the bizarre perspective that previous earnest calls for regulations that only hit OpenAI and other frontier labs were an attempt at regulatory capture. And Altman basically says (in my words!), fine, the world doesn’t want to regulate only us and Google and a handful of others at the top, so we switched from asking for regulations to protect everyone into regulations to pave the way for AI.
Thus, the latest asks from OpenAI are to prevent states from regulating frontier models, and to declare universal free fair use for all model training purposes, saying to straight up ignore copyright.
Some of this week’s examples, on top of Thompson and Altman.
Spor: I genuinely get the feeling that no one *actuallybelieves in superintelligence except for the doomers
I think they were right about this (re: common argument against e/acc on x) and i have to own up to that.
John Pressman: There’s an entire genre of Guy on here whose deal is basically “Will the singularity bring me a wife?” and the more common I learn this guy is the less I feel I have in common with others.
Also this one:
Rohit: Considering AGI is coming, all coding is about to become vibe coding, and if you don’t believe it then you don’t really believe in AGI do you
Ethan Mollick: Interestingly, if you look at almost every investment decision by venture capital, they don’t really believe in AGI either, or else can’t really imagine what AGI would mean if they do believe in it.
Epoch creates the GATE model, explaining that if AI is highly useful, it will also get highly used to do a lot of highly useful things, and that would by default escalate quickly. The model is, as all such things are, simplified in important ways, ignoring regulatory friction issues and also the chance we lose control or all die.
My worry is that by ignoring regulatory, legal and social frictions in particular, Epoch has not modeled the questions we should be most interested in, as in what to actually expect if we are not in a takeoff scenario. The paper does explicitly note this.
Their default result of their model, excluding the excluded issues, is roughly 30% additional yearly economic growth.
You can play with their simulator here, and their paper is here.
Epoch AI: We developed GATE: a model that shows how AI scaling and automation will impact growth.
It predicts trillion‐dollar infrastructure investments, 30% annual growth, and full automation in decades.
Tweak the parameters—these transformative outcomes are surprisingly hard to avoid.
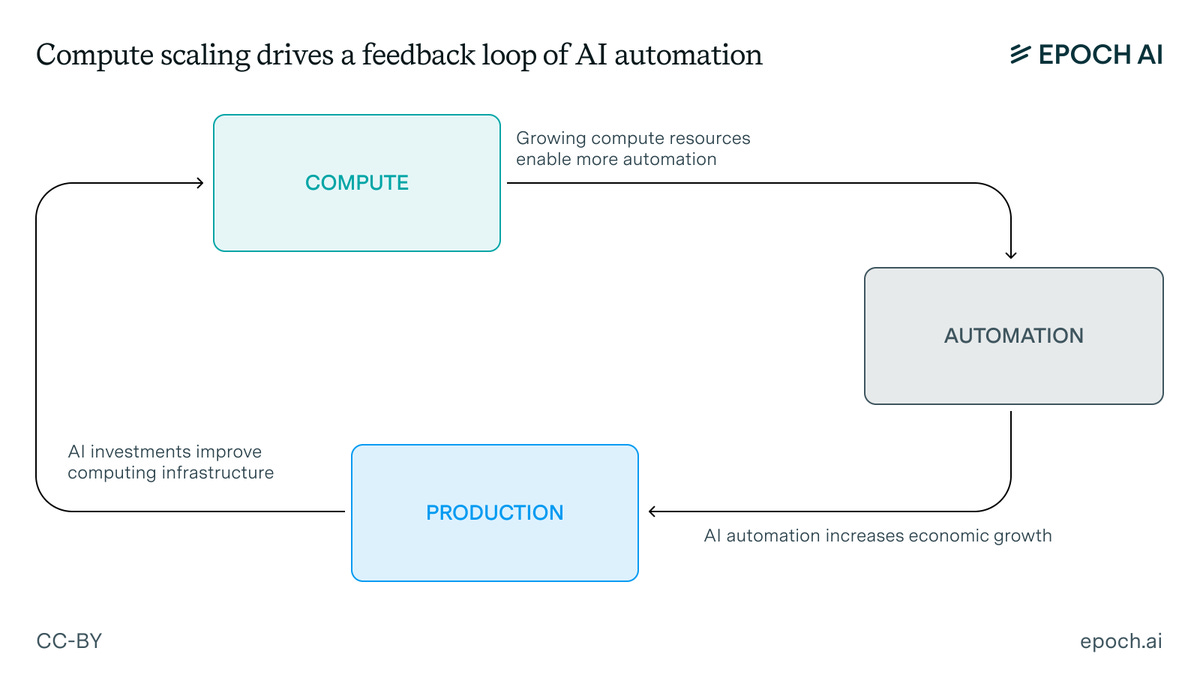
Imagine if a central bank took AI seriously. They’d build GATE—merging economics with AI scaling laws to show how innovation, automation, and investment interact.
At its core: more compute → more automation → growth → more investment in chips, fabs, etc.
Even when investors are uncertain, GATE predicts explosive economic growth within two decades. Trillions of dollars flow into compute, fabs, and related infrastructure—even before AI generates much value—because investors anticipate massive returns from widespread AI automation.
We’ve created an interactive sandbox so you can explore these dynamics yourself. Test your own assumptions, run different scenarios, and visualize how the economy might evolve as AI automation advances.
GATE has important limitations: no regulatory frictions, no innovation outside AI, and sensitivity to uncertain parameters. We see it as a first-order approximation of AI’s dynamics—try it out to learn how robust its core conclusions are!
Charles Foster: Epoch AI posts, for dummies
Epoch’s Ege Erdil and Matthew Barnett argue that most AI value will come from broad automation, not from R&D and scientific progress. That’s not a knock on the value of R&D, it’s saying the broad automation is even more valuable. Broadly automating labor is the name of their game.
One could say ‘wait, the reason you can do broad automation is exactly because of AI R&D, so that still makes R&D super valuable,’ so make of that dilemma what you will. A lot of this likely comes from the conflation of ‘formalized R&D’ as it is currently practiced, and ‘generally figuring things out’ which goes well beyond formalized R&D and will be turbocharged across the board. Yes, only ~20% of productivity gains look like they come from ‘R&D’ but that’s because we’re only counting formal R&D, and plausibly ignoring compounding effects.
Epoch argues against the likelihood of a full-on AI R&D singularity (or full RSI) via the standard arguments and emphasizing the need for a variety of cognitive skills. I don’t find this generally convincing, but they’re making a narrower argument than usual, that AI will first be able to fully automate a large share of the general workforce. I suppose sure, but also that’s going to happen rather quickly in such scenarios anyway?
I was pleased to see Tyler Cowen link to this without derision or claiming that it assumed its conclusions, even though it would have been highly reasonable to make similar objections.
I find very high growth scenarios highly plausible if we assume AI away loss of control and other existential risks along the way, and assume all of this is pointed in pro-human directions and that capabilities continue to scale.
Alas, I worry that the model here does not address most people’s ‘true objections.’
I don’t intend for this to be my definitive version of this, but sketching quickly, the plausibly true objections fall roughly into two categories.
First, there’s the ones that are often driving objections but that aren’t actually objections in this context:
-
ASI likely kills everyone. Yeah, yeah. True but here we’re assuming it doesn’t.
-
Disbelief on priors, absurdity heuristic, ‘sounds sci-fi’ or Nothing Ever Happens.
-
Belief that tech is hype or always involves tons of hype, so this is also hype.
-
Large growth would have implications I don’t want to think about, so no.
-
Large growth means nothing matters so I’m going to act as if it won’t happen.
-
Failure to even feel the AGI.
That’s all understandable, but not especially relevant. It’s a physical question, and it’s of the form of solving for the [Y] in ‘[X] → [Y].’
Second, there’s actual arguments, in various combinations, such as:
-
AI progress will stall before we reach superintelligence (ASI), because of reasons.
-
AI won’t be able to solve robotics or do act physically, because of reasons.
-
Partial automation, even 90% or 99%, is very different from 100%, o-ring theory.
-
Physical bottlenecks and delays prevent growth. Intelligence only goes so far.
-
Regulatory and social bottlenecks prevent growth this fast, INT only goes so far.
-
Decreasing marginal value means there literally aren’t goods with which to grow.
-
Dismissing ability of AI to cause humans to make better decisions.
-
Dismissing ability of AI to unlock new technologies.
And so on.
One common pattern is that relatively ‘serious people’ who do at least somewhat understand what AI is going to be put out highly pessimistic estimates and then call those estimates wildly optimistic and bullish. Which, compared to the expectations of most economists or regular people, they are, but that’s not the right standard here.
Dean Ball: For the record: I expect AI to add something like 1.5-2.5% GDP growth per year, on average, for a period of about 20 years that will begin in the late 2020s.
That is *wildlyoptimistic and bullish. But I do not believe 10% growth scenarios will come about.
Daniel Kokotajlo: Does that mean you think that even superintelligence (AI better than the best humans at everything, while also being faster and cheaper) couldn’t grow the economy at 10%+ speed? Or do you think that superintelligence by that definition won’t exist?
Dean Ball: the latter. it’s the “everything” that does it. 100% is a really big number. It’s radically bigger than 80%, 95%, or 99%. if bottlenecks persist–and I believe strongly that they will–we will have see baumol issues.
Daniel Kokotajlo: OK, thanks. Can you give some examples of things that AIs will remain worse than the best humans at 20 years from now?
Dean Ball: giving massages, running for president, knowing information about the world that isn’t on the internet, performing shakespeare, tasting food, saying sorry.
Samuel Hammond (responding to DB’s OP): That’s my expectation too, at least into the early 2030s as the last mile of resource and institutional constraints get ironed out. But once we have strong AGI and robotics production at scale, I see no theoretical reason why growth wouldn’t run much faster, a la 10-20% GWP. Not indefinitely, but rapidly to a much higher plateau.
Think of AGI as a step change increase in the Solow-Swan productivity factor A. This pushes out the production possibilities frontier, making even first world economies like a developing country. The marginal product of capital is suddenly much higher, setting off a period of rapid “catch up growth” to the post-AGI balanced growth path with the capital / labor ratio in steady state, signifying Baumol constraints.
Dean Ball: Right—by “AI” I really just meant the software side. Robotics is a totally separate thing, imo. I haven’t thought about the economics of robotics carefully but certainly 10% growth is imaginable, particularly in China where doing stuff is legal-er than in the us.
Thinking about AI impacts down the line without robotics seems to me like thinking about the steam engine without railroads, or computers without spreadsheets. You can talk about that if you want, but it’s not the question we should be asking. And even then, I expect more – for example I asked Claude about automating 80% of non-physical tasks, and it estimated about 5.5% additional GDP growth per year.
Another way of thinking about Dean Ball’s growth estimate is that in 20 years of having access to this, that would roughly turn Portugal into the Netherlands, or China into Romania. Does that seem plausible?
If you make a sufficient number of the pessimistic objections on top of each other, where we stall out before ASI and have widespread diffusion bottlenecks and robotics proves mostly unsolvable without ASI, I suppose you could get to 2% a year scenario. But I certainly wouldn’t call that wildly optimistic.
Distinctly, on the other objections, I will reiterate my position that various forms of ‘intelligence only goes so far’ are almost entirely a Skill Issue, certainly over a decade-long time horizon and at the margins discussed here, amounting to Intelligence Denialism. The ASI cuts through everything. And yes, physical actions take non-zero time, but that’s being taken into account, future automated processes can go remarkably quickly even in the physical realm, and a lot of claims of ‘you can only know [X] by running a physical experiment’ are very wrong, again a Skill Issue.
On the decreasing marginal value of goods, I think this is very much a ‘dreamed of in your philosophy’ issue, or perhaps it is definitional. I very much doubt that the physical limits kick in that close to where we are now, even if in important senses our basic human needs are already being met.
Altman’s model of the how AGI will impact the world is super weird if you take it seriously as a physical model of a future reality.
It’s kind of like there is this thing, ‘intelligence.’ It’s basically fungible, as it asymptotes quickly at close to human level, so it won’t be a differentiator.
There’s only so intelligent a thing can be, either in practice around current tech levels or in absolute terms, it’s not clear which. But it’s not sufficiently beyond us to be that dangerous, or for the resulting world to look that different. There’s risks, things that can go wrong, but they’re basically pedestrian, not that different from past risks. AGI will get released into the world, and ‘no one will care that much’ about the first ‘AGI products.’
I’m not willing to say that something like that is purely physically impossible, or has probability epsilon or zero. But it seems pretty damn unlikely to be how things go. I don’t see why we should expect this fungibility, or for capabilities to stall out exactly there even if they do stall out. And even if that did happen, I would expect things to change quite a lot more.
It’s certainly possible that the first AGI-level product will come out – maybe it’s a new form of Deep Research, let’s say – and initially most people don’t notice or care all that much. People often ignore exponentials until things are upon them, and can pretend things aren’t changing until well past points of no return. People might sense there were boom times and lots of cool toys without understanding what was happening, and perhaps AI capabilities don’t get out of control too quickly.
It still feels like an absurd amount of downplaying, from someone who knows better. And he’s far from alone.