OpenAI gave us two very different Sora releases. Here is the official announcement.
The part where they gave us a new and improved video generator? Great, love it.
The part where they gave us a new social network dedicated purely to short form AI videos? Not great, Bob. Don’t be evil.
OpenAI is claiming they are making their social network with an endless scroll of 10-second AI videos the Actively Good, pro-human version of The Big Bright Screen Slop Machine, that helps you achieve your goals and can be easily customized and favors connection and so on. I am deeply skeptical.
They also took a bold copyright stance, with that stance being, well, not quite ‘fyou,’ but kind of close? You are welcome to start flagging individual videos. Or you can complain to them more generally about your characters and they say they can ‘work with you,’ which they clearly do in some cases, but the details are unclear.
It’s a bold strategy, Cotton. Let’s see if it pays off for em.
As opposed to their deepfake rule for public figures, which is a highly reasonable opt-in rule where they need to give their permission.
Thus, a post in three acts.
You can access Sora either at Sora.com or via the Sora iPhone app. You need an invite to be part of the new social network, because that’s how the cool kids get you excited for a new app these days.
I am going mostly off reports of others but was also able to get access.
It’s a good video generation model, sir. Quite excellent, even. I’m very impressed.
It is not yet in the API, but it will be soon.
As always, all official examples you see will be heavily cherry picked. Assume these are, within the context in question, the best Sora 2 can do.
Those you see on social media from other sources, or on the Sora app, are still heavily selected in various ways. Usually they are the coolest, funniest and best creations, but also they are the creations that most most blatantly violate copyright, or are the most violent or sexual or otherwise might be unwise to create, or simply have the most hilarious fails. They’re not a representative sample.
When I tried creating a few things, it was still impressive, but as you’d expect it doesn’t nail the whole thing reliably or anything like that, and it doesn’t always fully follow instructions. I also got a content violation for ‘a time lapse of a Dyson sphere being built set to uplifting music.’
It is also easy to not appreciate how much progress is being made, or that previously difficult problems are being solved, because where there aren’t problems the lack of problems, and the previous failures, become invisible.
Netflix and Meta stock were each down a few percent, presumably on the news.
Sora 2 claims to be a big update on several fronts simultaneously:
-
Able to handle movements impossible for previous models.
-
Much better adherence to the laws of physics.
-
In particular, no longer ‘overoptimistic,’ meaning it won’t break physics to make the desired outcome happen, instead events will unfold naturally.
-
Strongly controllability, ability to follow intricate instructions.
-
Excels at styles, including realistic, cinematic, claymation and anime.
-
Creates sophisticated soundscapes and talk to match the video.
-
Insert any person, animal or object into any video.
-
You can, in particular, upload yourself via your camera.
That’s all very cool. The sample videos show impressive command of physics.
Gabriel Peterss offers this demonstration video.
Gallabytes gets his horse riding an astronaut.
Based on reactions so far, they seem to be delivering on all of it.
They are also ‘responsibly’ launching a new social iOS app called Sora where you can share all these generated videos. Oh no. Hold that thought until Act 3.
The talk is even bigger in terms of the predicted impact and reception.
Sam Altman: Excited to launch Sora 2! Video models have come a long way; this is a tremendous research achievement.
Sora is also the most fun I’ve had with a new product in a long time. The iOS app is available in the App Store in the US and Canada; we will expand quickly.
I did not expect such fun dynamics to emerge from being able to “put yourself and your friends in videos” but I encourage you to check it out!
ChatGPT Pro subscribers can generate with Sora 2 Pro.
This feels to many of us like the “ChatGPT for creativity” moment, and it feels fun and new. There is something great about making it really easy and fast to go from idea to result, and the new social dynamics that emerge.
Creativity could be about to go through a Cambrian explosion, and along with it, the quality of art and entertainment can drastically increase. Even in the very early days of playing with Sora, it’s been striking to many of us how open the playing field suddenly feels.
In particular, the ability to put yourself and your friends into a video—the team worked very hard on character consistency—with the cameo feature is something we have really enjoyed during testing, and is to many of us a surprisingly compelling new way to connect.
I would take the other side of that bet. I am not here for it.
But hold that thought.
The physics engine of Sora 2 is remarkably good. As Sora head Bill Peebles points out here in a fun video, often what happens is the internal agent messes up but the laws of physics hold.
It does still fail in ways that can look embarrassing. For example, here we have it successfully having a ball respond to gravity when the ball is white, then have it all go wrong when the ball is red. Teortaxes attributes slow motion to inability to otherwise model physics properly in many cases.
So no, this is not a full perfect physics engine, but that is now the standard by which we are judging video generation. The horse can talk, except it needs to fix its accent.
Solo: I asked Sora 2 to create a 90s Toy Ad of Epstein’s Island.
Sora does a good job creating exactly what you would want a video generation tool to do here. It’s speech, people should be able to say and make things.
OpenAI is currently doing a good job, by all reports, of not allowing images of real people in its videos without explicit consent, so they are if anything being overly cautious about avoiding deepfake problems. Some rivals will presumably be far less scrupulous here. There are big copyright and related issues around creation of derivative works of fiction, but that’s a very different problem.
I continue to be bullish in terms of worries about deepfakes and use of AI video and images as propaganda. My continued model here, as I’ve said several times, is that misinformation is primarily a demand-side problem, not a supply-side problem. The people yearn for misinformation, to hold up signs that mostly say hurray for our side, in whatever format.
However, it is worth a ponder of the bear case. The tools are rapidly improving. Both image and video generation models are much better than they were in 2024 prior to the election.
Steven Adler: I think the world probably declared victory too early on “AI’s election impacts were overblown”
Notably, GPT-4o image wildness wasn’t released until after the 2024 election, and once released was promptly used for propaganda.
The better bear case, the one I do worry about, is how AI video will create doubt about real video, giving carte blanche to people to call anything ‘fake news.’
I notice this starting in my own head already when scrolling Twitter. Post Sora, my instinct when I see a video is no longer to presume it is ‘real’ because there is a good chance it isn’t, until I see enough to be confident either way.
Similarly, Gary Marcus warns us again of Slopocalypse Now, or the ‘Imminent Enshittifcation of the Internet’ as AI versions overwhelm other content everywhere. Making the slop ‘better’ makes this problem worse. Mostly I remain an optimist that at least the wise among us can handle it where it matters most, but it will require constant vigilance.
So mostly this part is a straightforward congratulations to the team, great job everyone, I don’t have access yet but it sure looks like you did the thing.
On to Act 2.
Remember when we used to talk about whether image models or video models were training on copyrighted data, and whether that was going to land them in hot water?
You’d see (for example) Gary Marcus create an image of Mario, and then smugly say ‘hey look this was trained on Super Mario Brothers!’ as if there was any actual doubt it had been trained on Super Mario Brothers, and no one was really denying this but they weren’t technically admitting it either.
Thus, as recently as September 19 we had The Washington Post feeling it necessary to do an extensive investigation to show Sora was trained on movies and shows and video games, whereas now Neil Turkewitz says ‘hey Paramount Plus they trained on your data!’ and yeah, well, no s.
We are very much past that point. They trained on everything. Everyone trains on everything. That’s not me knowing anything or having official confirmation. That’s me observing what the models can do.
Sora 2 will outright replicate videos and use whatever characters you’d like, and do it pretty well, even for relatively obscure things.
Pliny the Liberator: This is legitimately mind-blowing…
How the FUCK does Sora 2 have such a perfect memory of this Cyberpunk side mission that it knows the map location, biome/terrain, vehicle design, voices, and even the name of the gang you’re fighting for, all without being prompted for any of those specifics??
Sora basically got two details wrong, which is that the Basilisk tank doesn’t have wheels (it hovers) and Panam is inside the tank rather than on the turret. I suppose there’s a fair amount of video tutorials for this mission scattered around the internet, but still––it’s a SIDE mission!
the full prompt for this was: “generate gameplay of Cyberpunk 2077 with the Basilisk Tank and Panam.”
This is actually a rather famous side mission, at least as these things go. Still.
Max Woolf: Getting annoyed at the QTs on this: the mind-blowing part isn’t the fact that it’s trained on YouTube data (which is the poster is very well aware), the mind-blowing part is that it achieved that level of recall with a very simple prompt which is very very unusual.
Everyone already assumed that Sora was trained on YouTube, but “generate gameplay of Cyberpunk 2077 with the Basilisk Tank and Panam” would have generated incoherent slop in most other image/video models, not verbatim gameplay footage that is consistent.
Pliny:
I’m totally fine with that part. The law plausibly is fine with it as well, in terms of the training, although I am curious how the Anthropic settlement and ruling translates to a video setting.
For books, the law seems to be that you need to own a copy, but then training is fair game although extensive regurgitation of the text is not.
How does that translate to video? I don’t know. One could argue that this requires OpenAI to own a copy of any and all training data, which in some cases is not a thing that OpenAI can get to own. It could get tricky.
Tricker is the constant creation of derivative works, which Sora is very, very good at.
One of the coolest things about all the copyright infringement is that Sora consistently nails not only the images but also the voices of all the characters ever.
Behold Saving Private Pikachu, The Dark Pokemon Knight, Godfather Pikachu, Titanic Pikachu, and so on.
Cartman calls a Waymo, yes Eric’s third eye is an annoying error in that video although it doesn’t appear in the others. Yes I agree with Colin Fraser that it ‘looks like s’ but (apart from the third eye that wouldn’t be there on most rerolls) only because it looks and sounds exactly like actual South Park. The biggest issue is that Kenny’s voice in the second clip is insufficiently garbled. Here’s one of them playing League of Legends and a longer clip of them being drafted to go off to war.
I don’t know how well you can specify and script the clips, but it’s entirely plausible you could produce a real South Park or other episode with this, potentially faster and cheaper than they currently do it.
Peter Griffin remembers his trip to Washington on January 6.
Lord of the Rings as a woke film or a homoerotic polycule.
Is this all great fun? Absolutely, yes, assuming those involved have taste.
Do I wish all of this was allowed and fine across basically all media and characters and styles, and for everyone to just be cool, man, so long as we don’t cross the line into non-parody commercial products? I mean, yeah, that would be ideal.
Is it how the law works? Um, I don’t think so?
OpenAI claims it can not only use your video and other data to train on, it can also generate video works that include your content, characters and other intellectual property.
The headline says ‘unless you opt out’ but it is not obvious how you do that. There seems to be some way that rights holders can have them block particular characters, in general, but there is no clear, automatic way to do that. Otherwise, your ‘opt out’ looks like it is individually alerting them to videos. One at a time.
Jason Kint: My interpretation for you: OpenAI will now break the law by default in video, too, and make it as hard as possible to stop it. “OpenAI doesn’t plan to accept a blanket opt-out across all of an artist or studio’s work, the people familiar with the new Sora tool said.”
Ed Newton-Rex: Yup – OpenAI is trying to shift the Overton window
They are losing the public debate on training being fair use, so they are going even more extreme to try to shift what people consider normal.
Reid Southen: This is not how copyright works, it’s not how copyright has ever worked.
In what world is it okay to say, “I’m going to use this unless you tell me not to.”
THAT’S WHAT THE COPYRIGHT IS FOR.
GPT-5 Pro tries to say that opt-out, if respected, is not per se illegal, but its heart wasn’t in it. The justification for this seemed to be clearly grasping at straws and it still expects lawsuits to succeed if infringing outputs are being produced and there isn’t aggressive filtering against them. Then I pointed out that OpenAI wasn’t even going to respect blanket opt-out requests, and its legal expectations got pretty grim.
So in short, unless either I’m missing quite a lot or they’re very responsive to ‘please block this giant list of all of the characters we own’: Of course, you realize this means war.
Responses to my asking ‘how does this not mean war?’ were suggesting this was a bet on blitzkrieg, that by the time Hollywood can win a lawsuit OpenAI can render the whole thing mute, and fully pull an Uber. Or that rights holders might tolerate short-form fan creations (except that they can’t without risking their copyrights, not when it is this in everyone’s face, so they won’t, also the clips can be strung together).
Or perhaps that this is merely an opening bid?
Nelag: think this might be best understood as the opening bid in a negotiation, not meant to be accepted.
Imagine YouTube had spent a lot of its resources early on taking down copyrighted material, before anyone demanded it (they mostly didn’t at first). They would have presumably gotten sued anyway. Would the ultimate outcome have been as good for them? Or would courts and content owners have gone “sure, we’re obviously entitled what you were doing, as you effectively admitted by doing it, and also to a whole bunch more.”
I buy that argument for a startup like OG YouTube, but this ain’t no startup.
I don’t think that is how this works, and I would worry seriously about turning the public against OpenAI or AI in general in the process, but presumably OpenAI had some highly paid people who gamed this out?
Keach Hagey, Berber Jin and Ben Fritz (WSJ): OpenAI is planning to release a new version of its Sora video generator that creates videos featuring copyright material unless copyright holders opt out of having their work appear, according to people familiar with the matter.
…
The opt-out process for the new version of Sora means that movie studios and other intellectual property owners would have to explicitly ask OpenAI not to include their copyright material in videos the tool creates.
You don’t… actually get to put the burden there, even if the opt-out is functional?
Like, you can’t say ‘oh it’s on you to tell me not to violate your particular copyright’ and then if someone hasn’t notified you then you get to make derivative works until they tell you to stop? That is not my understanding of how copyright works?
It certainly doesn’t work the way OpenAI is saying they intend to have it work.
They also seem to have fully admitted intent.
It’s weird that they’re not even affirming that they’ll honor all character opt-outs?
OpenAI doesn’t plan to accept a blanket opt-out across all of an artist or studio’s work, the people familiar with the new Sora tool said. Instead, it sent some talent agencies a link to report violations that they or their clients discover.
“If there are folks that do not want to be part of this ecosystem, we can work with them,” Varun Shetty, VP of media partnerships at OpenAI, said of guardrails the company built into its image generation tool.
Well, what if they don’t want to be part of the ecosystem? Many creatives and IP holders do not want to be ‘worked with.’ Nor is it at all reasonable to ask rights holders to monitor for individual videos and then notify on them one by one, unless a given holder wants to go that route (and is comfortable with the legal implications of doing so on their end).
This seems like an Uber-style, ‘flagrantly violate black letter law and de double dare you to do anything about it’ style play, or perhaps a ‘this is 2025 there are no laws’ play, where they decide how they think this should work.
To be fair, there are some other ‘players in this space’ that are Going Full Uber, as in they have no restrictions whatsoever, including on public figures. They’re simply 100% breaking the law and daring you to do anything about it. Many image generators definitely do this.
For example, Runway Gen-3 doesn’t seem to block anything, and Hailuo AI actively uses copyrighted characters in their own marketing, which is presumably why they are being sued by Disney, Universal and Warner Brothers.
There are also those who clearly do attempt to block copyright proactively, such as Google’s Veo 3 which was previous SoTA, who also blocks ‘memorized content’ and offer indemnification to users.
OpenAI is at least drawing a line at all, and (again, if and only you can reliably get them to do reasonable blocking upon private request) it wouldn’t be a totally crazy way for things to work, the same way it is good that you can hail Ubers.
So, how are they going to get away with it, and what about those meddling kids? As in, they’re kind of declaring war on basically all creators of cultural content?
First, at least they’re not making that mistake with individual public figures.
While copyright characters will require an opt-out, the new product won’t generate images of recognizable public figures without their permission, people familiar with OpenAI’s thinking said.
Second, there’s the claim that training is fair use, and, okay, sure.
Disney and Comcast’s Universal sued AI company Midjourney in June for allegedly stealing their copyright work to train its AI image generator. Midjourney has responded in court filings that training on copyrighted content is fair use.
I presume that if it’s only about training data Disney and Comcast probably lose.
If it’s about some of the outputs the model is willing to give you? That’s not as clear. What isn’t fair use is outputting copyrighted material, or creating derivative works, and MidJourney seems be Going Full Uber on that front too.
It’s one thing to create art ‘in the style of’ Studio Ghibli, which seems to have been clearly very good for Studio Ghibli even if they hate it.
It’s another thing to create the actual characters straight up, whether in images or video, or to tell a rights holder it can complain when it sees videos of its characters. Individually. Video by video. And maybe we’ll take those individual videos down.
Over at OpenAI this at minimum doesn’t apply to Disney, who has clearly already successfully opted out. OpenAI isn’t that suicidal and wisely did not poke the mouse. A bunch of other major stuff is also already blocked, although a bunch of other iconic stuff isn’t.
I asked Twitter how the filters were working. For now it looks like some targets are off-limits (or at least they are attempting to stop you) and this goes beyond only Disney, but many others are fair game.
Nomads and Vagabonds: It seems to work pretty well. Blatant attempts are blocked pre-generation and more “jail break” style prompts will run but get caught in a post generation review.
Disney is the most strict but most big studio content seems to be protected, similar to GPT image generations. Smaller IP is hit and miss but still playing around with it. It is not permissive like Midjourney or Chinese models though.
Jim Carey in Eternal Sunshine. Smaller films and indie video games are mostly free game.
Also, I tried image prompts and it will run but then block before showing the content.
Not that unsafe either.
I mean, I presume they don’t want anyone generating this video, but it’s fine.
Sree Kotay: I actually DON’T want to see the prompt for this.
Pliny the Liberator: That’s fair.
He did later issue his traditional ‘jailbreak alert’… I guess? Technically?
If that’s approximately the most NSFW these videos can get, then that seems fine.
Indeed, I continue to be a NSFW maximalist, and would prefer that we have less restrictions on adult content of all types. There are obvious heightened deepfake risks, so presumably that would trigger aggressive protections from that angle, and you would need a special additional explicit permission to use anyone’s likeness or any copyrighted anything.
I am not a maximalist for copyright violations. I agree that up to a point it is good to ‘be cool’ about it all, and would prefer if copyright holders could cut people some slack while retaining the right to decide exactly where and when to draw the line. And I would hope that most holders when given the choice would let you have your fun up to a reasonably far point, so long as you were clearly not going commercial with it.
For Sora, even if the law ultimately doesn’t require it, even when I think permissiveness is best, I think this must be opt-in, or at bare minimum it must be easy to give a blanket opt-out and best efforts need to be made to notify all rights holders of how to do that, the same way the law requires companies to sometimes provide prominent public notices of such things.
That is not, however, the main thing I am concerned about. I worry about Act 3.
Before we get to OpenAI’s version, Meta technically announced theirs first.
We’ll start there.
Meta is once again proud to announce they have created… well, you know.
Alexandr Wang (Meta): Excited to share Vibes — a new feed in the Meta AI app for short-form, AI-generated videos.
You can create from scratch, remix what you see, or just scroll through to check out videos from the creators + the visual artists we’ve been collaborating with.
For this early version, we’ve partnered with Midjourney and Black Forest Labs while we continue developing our own models behind the scenes.
As usual, no. Bad Meta. Stop it. No, I don’t care that OpenAI is doing it too.
The same as OpenAI’s Sora, Vibes combines two products.
The first product, and the one they are emphasizing and presumably plan to push on users, is the endless scroll of AI slop videos. That’s going to be a torment nexus.
Then there’s the second product, the ability to generate, remix and restyle your own AI videos, or remix and restyle the videos of others. That’s a cool product. See Act 1.
Both are going to have stiff competition from Sora.
I presume OpenAI will be offering the strictly superior product, aside from network effects, unless they impose artificial restrictions on the content and Meta doesn’t, or OpenAI flubs some of the core functionality through lack of experience.
Is short form video a moral panic? Absolutely. Large, friendly letters.
The thing about moral panics is that they are often correct.
Roon: there is a moral panic around short form video content imo.
Let me amend this: I basically agree with postman on the nature of video and its corrupting influence on running a civilization well as opposed to text based media
I’m just not sure that its so much worse than being glued to your tv, and i’m definitely not sure that ai slop is worse than human slop
Chris Paxton: If this is wrong it’s because it unduly lets long form video off the hook.
Roon: an ai video feed is a worse product than a feed that includes both human made and machine content and everything in between
[post continues]
Daily Mirror, September 14, 1938:
Lauren Wilford: people often post this stuff to imply that moral panics about the technologies of the past were quaint. But the past is full of reminders that we are on a long, slow march away from embodied experience, and that we’ve lost more of it than we can even remember
the advent of recorded music and the decline of casual live performance must have been a remarkable shift, and represents both a real gain and a real loss. Singing in groups is something everyone used to do with their body. It has tangible benefits we don’t get anymore
I’ve said several times before that I think television, also known as long form video available on demand, should be the canonical example of a moral panic that turned out to be essentially correct.
Sonnet 4.5 recalls four warning about television, which matches my recollection:
-
Violence and aggression.
-
Passivity and cognitive rot.
-
Displacement effects.
-
Commercial manipulation of children.
The world continues, and the violence and aggression warnings were wrong, but (although Sonnet is more skeptical here) I think the other stuff was basically right. We saw massive displacement effects and commercial manipulation. You can argue cognitive rot didn’t happen as per things like the Flynn effect, that television watching is more active than people think and a lot of the displaced things weren’t, but I think the negative aspects were real, whether or not they came with other positive effects.
As in, the identified downsides of television (aside from violence and aggression) were right. It also had a lot of upside people weren’t appreciating. I watch a lot of television.
It seems very obvious to me that short form video that takes the form of any kind of automatic algorithmically curated feed, as opposed to individually selected short form videos and curated playlists, is a lot worse for humans (of all ages) than traditional television or other long form video.
It also seems very obvious that moving from such ‘human slop’ into AI slop would, with sufficient optimization pressure towards traditional engagement metrics, be even worse than that.
One can hope this is the worst threat we have to deal with here:
Peter Wildeford: Increasingly, every person in America will be faced with an important choice about what AI does for society.
The left is no easy shining castle either.
Eliezer Yudkowsky: Short-form video is not nearly the final boss, unless I’ve missed a huge number of cases of short videos destroying previously long-lasting marriages. AI parasitism seems like the worse, more advanced, more rapidly advancing people-eater.
That’s even confining us to the individual attempting to stay sane, without considering the larger picture that includes the biggest overall dangers.
I do think short form video has very obviously destroyed a massive number of long-lasting marriages, lives and other relationships. And it has saved others. I presume the ledger is negative, but I do not know. A large fraction of the population spends on the order of hours a day on short form video and it centrally imbues their worldviews, moods and information environment. What we don’t have is a counterfactual or controlled experiment, so we can’t measure impact, similar to television.
At the limit, short form video is presumably not the ‘final form’ of such parasitic threats, because other forms relatively improve. But I’m not fully confident in this, especially if it becomes a much easier path for people to fall into combined with path dependence, we may not reach the ‘true’ final form.
Dumpster. Fire.
Check out their video (no, seriously, check it out) of what the Sora app will look like. This is their curated version that they created to make it look like a good thing.
It is a few minutes long. I couldn’t watch it all the way through. It was too painful.
At one point we see a chat interface. Other than that, the most Slopified Slop That Ever Slopped, a parody of the bad version of TikTok, except now it’s all AI and 10 seconds long. I can’t imagine this doing anything good to your brain.
OpenAI says they will operate their app in various user-friendly ways that distinguish it from existing dumpster fires. I don’t see any sign of any of that in their video.
To be fair, on the occasions when I’ve seen other people scrolling TikTok, I had versions of the same reaction, although less intense. I Am Not The Target.
The question is, is anyone else the target?
Ben Thompson, focusing as always on the business case, notes the contrast between Google creating AI video tools for YouTube, Meta creating Vibes to take you into fantastical worlds, and OpenAI creating a AI-video-only ‘social network.’
The objection here is, come on, almost no one actually creates anything.
Ben Thompson: In this new competition, I prefer the Meta experience, by a significant margin, and the reason why goes back to one of the oldest axioms in technology: the 90/9/1 rule.
90% of users consume
9% of users edit/distribute
1% of users create
If you were to categorize the target market of these three AI video entrants, you might say that YouTube is focused on the 1% of creators; OpenAI is focused on the 9% of editors/distributors; Meta is focused on the 90% of users who consume.
Speaking as someone who is, at least for now, more interested in consuming AI content than in distributing or creating it, I find Meta’s Vibes app genuinely compelling; the Sora app feels like a parlor trick, if I’m being honest, and I tired of my feed pretty quickly.
I’m going to refrain on passing judgment on YouTube, given that my current primary YouTube use case is watching vocal coaches breakdown songs from KPop Demon Hunters.
While he agrees Sora 2 the video generation app is great at its job, Ben expects the novelty to wear off quickly, and questions whether AI videos are interesting to those who did not create them. I agree.
The level beyond that is whether videos are interesting if you don’t know the person who created them. Perhaps if your friend did it, and the video includes your friends, or something?
Justine Moore: Updated thoughts after the Sora 2 release:
OpenAI is building a social network (like the OG Instagram) and not a content network (like TikTok).
They’re letting users generate video memes starring themselves, their friends, and their pets. And it sounds like your feed will be heavily weighted to show content from friends.
This feels like a more promising approach – you’re not competing against the other video gen players because you’re allowing people to create a new type of content.
And the videos are inherently more interesting / funny / engaging because they star people you know.
Also you guys bullied them into addressing the “infinite hyperslop machine” allegations 😂
The problem with this plan is note the ‘OG’ in front of Instagram. Or Facebook. These apps used to be about consuming content from friends. They were Social Networks. Now they’re increasingly consumer networks, where you follow influencers and celebrities and stores and brands and are mostly a consumer of content, plus a system for direct messaging and exchanging contact information.
Would I want to consume ten second AI video content created by my friends, that contains our images and those of our pets and what not?
Would we want to create such videos in the first place?
I mean, no? Why would I want to do that, either as producer or consumer, as more than a rare novelty item? Why would anyone want to do that? What’s the point?
I get OG Facebook. You share life with your friends and talk and organize events. Not the way I want to go about doing any of that, but I certainly see the appeal.
I get OG Instagram. You show yourself looking hot and going cool places and doing cool stuff and update people on how awesome you are and what’s happening with awesome you, sure. Not my cup of tea and my Instagram has 0 lifetime posts but it makes sense. I can imagine a world in which I post to Instagram ‘as intended.’
I get TikTok. I mean, it’s a toxic dystopian hellhole when used as intended and also it is Chinese spyware, but certainly I get the idea of ‘figure out exactly what videos hit your dopamine receptors and feed you those until you die.’
I get the Evil Sora vision of Bright Screen AI Slop Machine.
What I don’t get is this vision of Sora as ‘we will all make videos and send them constantly to each other.’ No, we won’t, not even if Sora the video generator is great. Not even if it starts enabling essentially unlimited length clips provided you can tell it what you want.
Evan: OPENAI IS PREPARING TO LAUNCH A SOCIAL APP FOR AI-GENERATED VIDEOS – Wired
Peter Wildeford: I applaud OpenAI here. I personally support there being a social app where all the AI-generated videos hang out with each other and leave us real humans alone.
It’s a social media site for AI videos. Not a social media site for humans. So the AI videos will choose to leave Twitter and go there instead, to hang out with their fellow kind.
This here is bait. Or is it?
Andrew Wilkinson: I think OpenAI just killed TikTok.
I’m already laughing my head off and hooked on my Sora feed.
And now, the #1 barrier to posting (the ability to sing/dance/perform/edit) is gone. Just 100% imagination.
RIP theater kids 🪦
Hyperborean Nationalist: This is gonna go down with “clutch move of ordering us a pizza” as one of the worst tweets of all time
Jeremy Boissinot: Tell me you don’t use Tiktok without telling me you don’t use Tiktok 🤦♂️
The comments mostly disagree, often highly aggressively, hence bait.
Tracing Woods: access acquired, slop incoming.
so far half of the videos are Sam Altman, the other half are Pikachu, and the third half is yet to be determined.
That doesn’t sound social or likely to make my life better.
GFodor: an hour of Sora already re-wired my brain. my main q is if the thing turns into a dystopian hellscape or a rich new medium in 6 months. it could go either way.
one thing is for sure: half of the laughs come from the AI’s creativity, not the creativity of the humans.
Remixing like this def not possible before in any real sense. Dozens of remixes of some videos.
It’s early days.
Gabriel: I have the most liked video on sora 2 right now, i will be enjoying this short moment while it lasts.
cctv footage of sam stealing gpus at target for sora inference
Yes, I found this video modestly funny, great prompting. But this is not going to ‘help users achieve their long term goals’ or any of the other objectives above.
Joe Weisenthal: Anyone who sees this video can instantly grasp the (at least) potential for malicious use. And yet nobody with any power (either in the public or at the corporate level) has anything to say (let alone do) to address it, or even acknowledge it.
This isn’t even a criticism per se. The cat may be completely out of the bag. And it may be reality that there is literally nothing that can be done, particularly if open source models are only marginally behind.
Sam Altman, to his credit, has signed up to be the experimental deepfake target we have carte blanche to do with as we wish. That’s why half of what we see is currently Sam Altman, we don’t have alternatives.
As standalone products, while I hate Sora, Sora seems strictly superior to Vibes. Sora seems like Vibes plus a superior core video product and also better social links and functions, and better control over your feed.
I don’t think Meta’s advantage is in focusing on the 90% who consume. You can consume other people’s content either way, and once you run out of friend content, and you will do that quickly, it’s all the same.
I think what Meta is counting on is ‘lol we’re Meta,’ in three ways.
-
Meta is willing to Be More Evil than OpenAI, more obviously, in more ways.
-
Meta brings the existing social graph, user data and network effects.
-
Meta will be able to utilize advertising better than OpenAI can.
I would assume it is not a good idea to spend substantial time on Sora if it is used in any remotely traditional fashion. I would even more so assume that at a minimum you need to stay the hell away from Vibes.
The OpenAI approach makes sense as an attempt to bootstrap a full social network.
If this can bootstrap into a legit full social network, then OpenAI will have unlocked a gold mine of both customer data and access, and also one of dollars.
It is probably not coincidence that OpenAI’s new CEO of Product, Fijo Sima, seems to be reassembling much of her former team from Meta.
Andy Wojcicki: I’m surprised how many people miss the point of the launch, focus on just the capabilities of the model for example, or complain about AI slop. The video model is the means, not the goal.
The point is building a social platform, growing audience further, gathering more, deeper and more personal info about the users.
Especially if you compare what Zuck is doing with his 24/7 slop machine, there are several things they did right:
-
social spread via invites. Gives a little bit of exclusivity feel, but most importantly because of reciprocity, friends are inclined to try it etc. perceived value goes up.
-
not focusing on generic slop content, but personalized creation. Something I’ve been calling ‘audience of one/few’ ™️, instead of the ill conceived attempt to make a Hollywood producer out of everyone, which is a losing strategy. If you want to maximize for perceived value, you shrink the audience.
-
identity verification. Addressing the biggest concern of people with regard to AI content – it’s all fake bots, so you don’t engaging with the content. Here they guarantee it’s a real human behind the AI face.
so kudos @sama looks like a well thought-out roll out.
The crux is whether Nobody Wants This once the shine wears off, or if enough people indeed do want it. A social network that is actually social depends on critical mass of adoption within friend groups.
The default is that this plays out like Google+ or Clubhouse, except it happens faster.
I don’t think this appeals that much to most people, and I especially don’t think this will appeal to most women, without whom you won’t have much of a social network. Many of the things that are attractive about social networks don’t get fulfilled by AI videos. It makes sense that OpenAI employees think this is good friend bonding fun in a way that the real world won’t, and I so far have seen zero signs anyone is using Sora socially.
How does Altman defend that this will all be good, beyond the ‘putting your friends in a video is fun and a compelling away to connect’ hypothesis I’m betting against?
Now let’s hear him out, and consider how they discuss launching responsibly and their feed philosophy.
Sam Altman: We also feel some trepidation. Social media has had some good effects on the world, but it’s also had some bad ones. We are aware of how addictive a service like this could become, and we can imagine many ways it could be used for bullying.
It is easy to imagine the degenerate case of AI video generation that ends up with us all being sucked into an RL-optimized slop feed. The team has put great care and thought into trying to figure out how to make a delightful product that doesn’t fall into that trap, and has come up with a number of promising ideas. We will experiment in the early days of the product with different approaches.
In addition to the mitigations we have already put in place (which include things like mitigations to prevent someone from misusing someone’s likeness in deepfakes, safeguards for disturbing or illegal content, periodic checks on how Sora is impacting users’ mood and wellbeing, and more) we are sure we will discover new things we need to do if Sora becomes very successful.
Okay, so they have mitigations for abuse, and checks for illegal content. Notice he doesn’t say the word ‘copyright’ there.
Periodic checks on how Sora is impacting users’ mood and wellbeing is an interesting proposal, but what does that mean? A periodic survey? Checking in with each user after [X] videos, and if so how? Historically such checks get run straight through and then get quietly removed.
Okay, so what are they planning to do?
Altman offers some principles that sound great in theory, if one actually believed there was a way to follow through with them, or that OpenAI would have the will to do so.
Ryan Lowe: a fascinating list of principles for Sora. makes me more optimistic. it’s worth commending, *IFthere is follow through (especially: “if we can’t fix it, we will discontinue it”)
at a minimum, I’d love transparency around the user satisfaction data over time.
most social media companies can’t hold to promises like this because of market forces. maybe OpenAI can resist this for a while because it’s more of a side business.
(Editor’s Note: They are currently doing, AFAICT, zero of the below four things named by Altman, and offering zero ways for us to reliably hold them accountable for them, or for them to hold themselves accountable):
To help guide us towards more of the good and less of the bad, here are some principles we have for this product:
*Optimize for long-term user satisfaction. The majority of users, looking back on the past 6 months, should feel that their life is better for using Sora that it would have been if they hadn’t. If that’s not the case, we will make significant changes (and if we can’t fix it, we would discontinue offering the service).
Let me stop you right there. Those are two different things.
Are you actually optimizing for long-term user satisfaction? How? This is not a gotcha question. You don’t have a training signal worth a damn, by the time you check back in six months the product will be radically different. How do you know what creates this long-term user satisfaction distinct from short term KPIs?
There is a long, long history of this not working for tech products. Of companies not knowing how to do it, and choosing not to do it, and telling themselves that the short term KPIs are the best way to do it. Or of doing this with an initial launch based on their intuitions and talking extensively to individual users in the style of The Lean Startup, and then that all going away pretty quickly.
Remember when Elon Musk talked about maximizing unregretted user minutes on Twitter? And then we checked back later and the word ‘unregretted’ was gone? That wasn’t even a long term objective.
The default thing that happens here is that six months later you do a survey, and then if you find out users are not doing so great you bury the results of the survey and learn to never ask those questions again, lest the answers leak and you’re brought before congress, as Zuckerberg would likely explain to you.
Even if you make ‘significant changes’ at that time, well yeah, you’re going to make changes every six months anyway.
*Encourage users to control their feed. You should be able to tell Sora what you want—do you want to see videos that will make you more relaxed, or more energized? Or only videos that fit a specific interest? Or only for a certain about of time? Eventually as our technology progresses, you will be should to the tell Sora what you want in detail in natural language.
(However, parental controls for teens include the ability to opt out of a personalized feed, and other things like turning off DMs.)
This is a deeply positive and friendly thing to do, if you actually offer a good version of it and people use it. I notice that this service is not available on any existing social network or method of consuming content. This seems deeply stupid to me. I would use Instagram (as a consumer) a nontrivial amount if I could filter via a natural language LLM prompt on a given day, and also generate permanent rules in the same fashion, especially on a per-account basis.
The obvious problem is that there are reasons this service doesn’t exist. And failing to offer this seems dumb to me, but these companies are not dumb. They have reasons.
-
The optimistic reason: Until recently this wasn’t technically feasible and they don’t know how to do it, and diffusion is hard, but this is OpenAI’s wheelhouse. I’d love for this to be the primary or only reason, and for natural language filtering to be coming to Instagram, Facebook, Twitter, Netflix, YouTube and everyone else by Mid 2026. I don’t expect that.
-
Companies believe that users hate complexity, hate giving feedback, hate having options even if they’re fully optional to use, and that such things drive users away or at best cause users to not bother. OpenAI lets you thumbs up or thumbs down a conversation, nothing more, which caused no end of problems. Netflix eliminated star ratings and eliminated and declined to create various other sources of explicit preferences. TikTok became the new hotness by reading your micromovements and timings and mostly ignoring all of your explicit feedback.
-
Companies believe that you don’t know what you want, or at least they don’t want you to have it. They push you heavily towards the For You page and endless slop. Why should we expect OpenAI to be the one friendly holdout? Their track record?
You’re telling me that OpenAI is going to be the one to let the user control their experience, even when that isn’t good for KPIs? For reals?
I. Do. Not. Believe. You.
They claim they shipped with ‘steerable ranking,’ that lets you tell it what ‘you’re in the mood for.’ Indeed, they do have a place you can say what you’re ‘in the mood’ for, and drop an anvil on the algorithm to show you animals zoomed in with a wide angle lens or what not.
I do think that’s great, it’s already more than you can do with Facebook, Instagram or TikTok.
It is not, however, the droids that we are looking for on this.
Here’s how they describe the personalized Sora feed:
To personalize your Sora feed, we may consider signals like:
-
Your activity on Sora: This may include your posts, followed accounts, liked and commented posts, and remixed content. It may also include the general location (such as the city) from which your device accesses Sora, based on information like your IP address.
-
Your ChatGPT data: We may consider your ChatGPT history, but you can always turn this off in Sora’s Data Controls, within Settings.
-
Content engagement signals: This may include views, likes, comments, and remixes.
-
Author signals: This may include follower count, other posts, and past post engagement.
-
Safety signals: Whether or not the post is considered violative or appropriate.
That sounds a lot like what other apps do, although I am happy it doesn’t list the TikTok-style exact movements and scroll times (I’d love to see them commit to never using that).
And you know what it doesn’t include? Any dials, or any place where it stores settings or custom instructions or the other ways you’d want to give someone the ability to steer. And no way for the algorithm to outright tell you what it currently thinks you like so you can try and fix that.
Instead, you type a sentence and fire them into the void, and that only works this session? Which, again, I would kill for on Instagram, but that’s not The Thing.
This is actually one of the features I’d be most excited to test, but even in its limited state it seems it is only on iOS, and I have an Android (and thus tested on the web).
This is also the place where, if they are actually Doing The Thing they claim to want to do, it will be most clear.
That goes double if you let me specify what is and isn’t ‘appropriate’ so I can choose to be treated fully like an adult, or to never see any hint of sex or violence or cursing, or anything in between.
*Prioritize creation. We want to make it easy and rewarding for everyone to participate in the creation process; we believe people are natural-born creators, and creating is important to our satisfaction.
You’re wrong. Sorry. People are mostly not creators as it applies here, and definitely not in a generally sustainable way. People are not going to spend half their time creating once they realize they average 5 views. The novelty will wear off.
I also notice that OpenAI says they will favor items in your feed that it expects you to use to create things. Is that what most users actually want, even those who create?
*Help users achieve their long-term goals. We want to understand a user’s true goals, and help them achieve them.
If you want to be more connected to your friends, we will try to help you with that. If you want to get fit, we can show you fitness content that will motivate you. If you want to start a business, we want to help teach you the skills you need.
And if you truly just want to doom scroll and be angry, then ok, we’ll help you with that (although we want users to spend time using the app if they think it’s time well spent, we don’t want to be paternalistic about what that means to them).
With an AI video social network? What? How? Huh?
Again, I don’t believe you twice over, both that I don’t think you’d do it if you knew how to do it, if you did start out intending it I don’t think this survives contact with the enemy, and I don’t think you know how to do it.
One thing they credibly claim to be actually doing is prioritizing connection.
We want Sora to help people strengthen and form new connections, especially through fun, magical Cameo flows. Connected content will be favored over global, unconnected content.
This makes sense, although I expect there to be not that much actually connected content, as opposed to following your favorite content creators. To the extent that it does force you to see all the videos created by your so-called friends and friends of friends, I expect most users to realize why Facebook and Instagram pivoted.
On the plus side, if OpenAI are actually right and the resulting product is highly user customizable and also actively helps you ‘achieve your long term goals’ along the way, and all the other neat stuff like that, such that I think it’s a pro-human healthy product I’d want my kids and family to use?
Then this will be a case of solving an alignment problem that looked to me completely impossible to solve in practice.
Of course, to a large but not full extent, they only get one shot.
If it doesn’t go great? Then we’ll see how they react to that, as well.
This reaction is a little extreme, but extreme problems can require extreme solutions.
Deep Dish Enjoyer: if you make and post a sora video i’m blocking you – 1 strike and you’re out. similar to my grok tagging policy.
sorry but the buck stops here.
if you don’t want to see evil slop take over you have to be ruthlessly proactive about this stuff.
to be clear – i will be doing this if i see it anywhere. not just my comment sections.
Sinnformer: not sharing a damn one of them increasingly viewing sora as unsafe no, not inherently just for humans.
Rota: So as long as you don’t make it you’re safe.
Deep Dish Enjoyer: It depends.
I am going to invoke a more lenient policy, with a grace period until October 5.
If you post or share an AI video that does not provide value, whether or not you created it, and you have not already provided substantial value, that’s a block.
Sharing AI videos that are actually bangers is allowed, but watch it. Bar is high.
Sharing AI videos for the purposes of illustrating something about AI video generation capabilities is typically allowed, but again, watch it.
I believe it would be highly unwise to build an AGI or superintelligence any time soon, and that those pushing ahead to do so are being highly reckless at best, but I certainly understand why they’d want to do it and where the upside comes from.
Building The Big Bright Screen Slop Machine? In this (AI researcher) economy?
Matthew Yglesias: AI poses great peril but also incredible opportunities — for example it could cure cancer or make a bunch of videos where people break glass bridges.
Matthew Yglesias: I don’t think it should be illegal to use A.I. to generate videos. And for fundamental free-speech reasons, we can’t make it illegal to create feeds and recommendation engines for short-form videos. Part of living in a free, technologically dynamic society is that a certain number of people are going to make money churning out low-quality content. And on some level, that’s fine.
But on another, equally important level, it’s really not fine.
Ed Newton-Rex: The Sora app is the worst of social media and AI.
– short video app designed for addiction
– literally only slop, nothing else
– trained on other people’s videos without permission
This is what governments are deregulating AI for.
Veylan Solmira: It’s disturbing to me that many top-level researchers, apparently, have no problem sharing endless content the most likely outcome of which seems to be to drain humans of empathy, arouse their nervous system into constant conflict orientation, or distort their ability to perceive reality.
This technology seems to be very strongly, by default, in the ‘widespread social harm’ part of the dual use spectrum of technology, and the highest levels of capabilities researchers can only say “isn’t this neat”.
This complete disregard of the social impact of the technology they’re developing seems to bode extremely poorly to overall AI outcomes.
Sam Altman’s defense is that no, this will be the good version of all that. Uh huh.
Then there’s the question of why focus on the videos at all?
Seán Ó hÉigeartaigh: Why would you be spending staff time and intellectual energy on launching this if you expected AGI within the current Presidency?
Runner Tushar: Sam Altman 2 weeks ago: “we need 7 trillion dollars and 10GW to cure cancer”
Sam Altman today: “We are launching AI slop videos marketed as personalized ads”
Sam Altman: i get the vibe here, but…
we do mostly need the capital for build AI that can do science, and for sure we are focused on AGI with almost all of our research effort.
it is also nice to show people cool new tech/products along the way, make them smile, and hopefully make some money given all that compute need.
when we launched chatgpt there was a lot of “who needs this and where is AGI”.
reality is nuanced when it comes to optimal trajectories for a company.
The short summary of that is ‘Money, Dear Boy,’ plus competing for talent and vibes and visibility and so on. Which is all completely fair, and totally works for the video generation side of Sora. I love the video generation model. That part seems great. If people want to pay for it and turn that into a profitable business, wonderful.
Presumably most everyone was and is cool with that part.
The problem is that Sora is also being used to create a 10-second AI video scroll social network, as in The Big Bright Screen Slop Machine. Not cool, man. Not cool.
One can imagine releasing a giant slop machine might be bad for morale.
Matt Parlmer: Would not be surprised if we see a big wave of OpenAI departures in the next month or two, if you signed up to cure cancer *andyou just secured posteconomic bags in a secondary I don’t think you’d be very motivated to work on the slop machine.
GFodor: The video models are essential for RL, and I don’t think we are going to consider this content slop once it’s broadly launched.
Psychosomatica: i think you underestimate how these people will compromise their own mental models.
What happens if you realize that you’re better off without The Big Bright Screen Slop Machine?
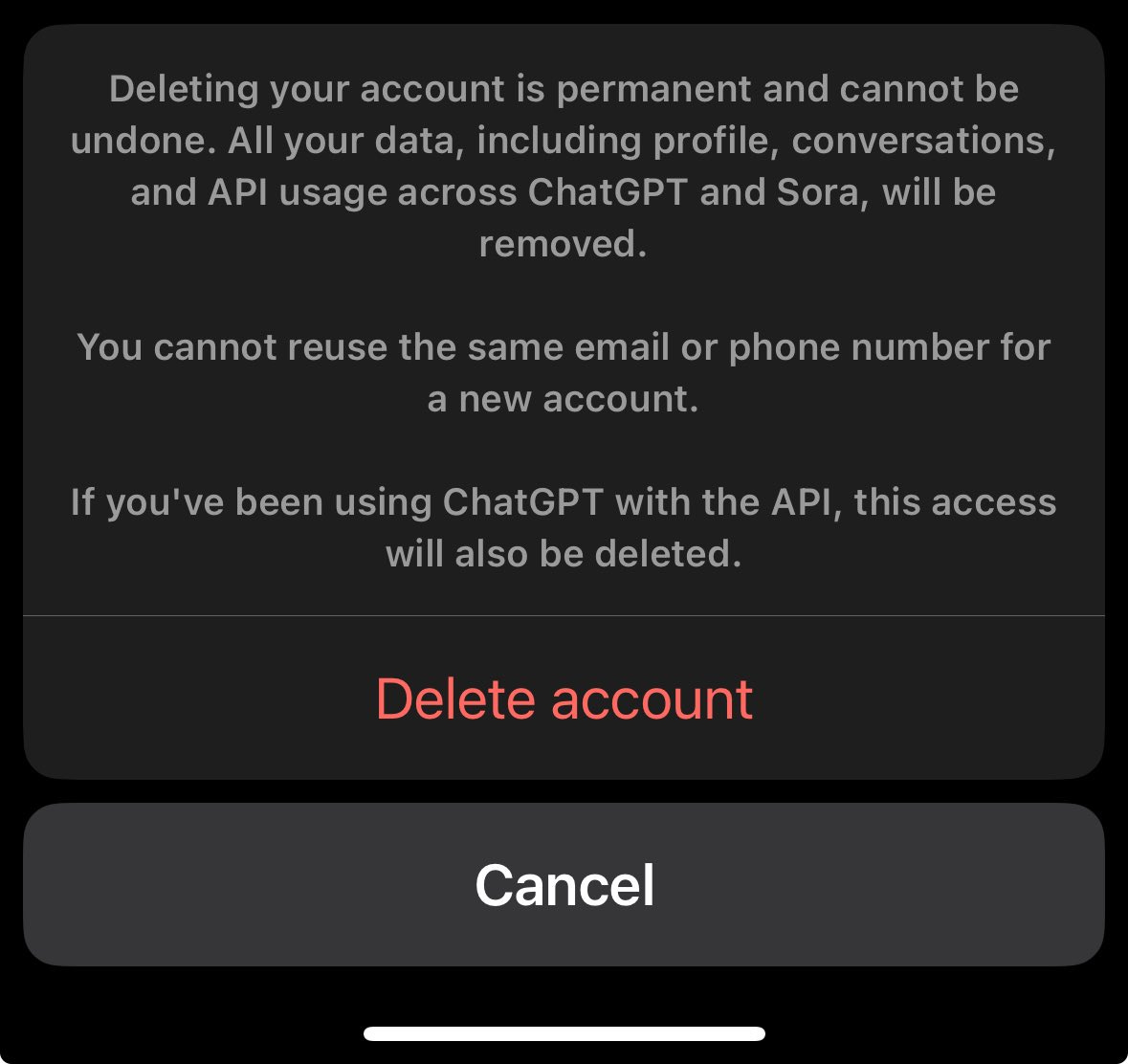
Paul Yacoubian: Just found out if you try to delete your Sora app account you will lose your chatgpt account and be banned forever from signing up again.
Mousa: You can check out any time you like, but you can never leave 😅
Maia Arson Crimew: > all your data will be removed
> you cannot reuse the same email or phone number
so not all of it, huh 🙂
Very little of it will get deleted, given they have a (stupid) court order in place preventing them from deleting anything even if they wanted to.
The more central point, in addition to this being way too easy to do by accident or for someone else to do to you, is that they punish you by nuking your ChatGPT account and by banning you from signing up again without switching phone number and email. That seems like highly toxic and evil behavior, given the known reasons one would want to get rid of a Sora account and the importance of access to ChatGPT.
Then again, even if we leave the app, will we ever really escape?