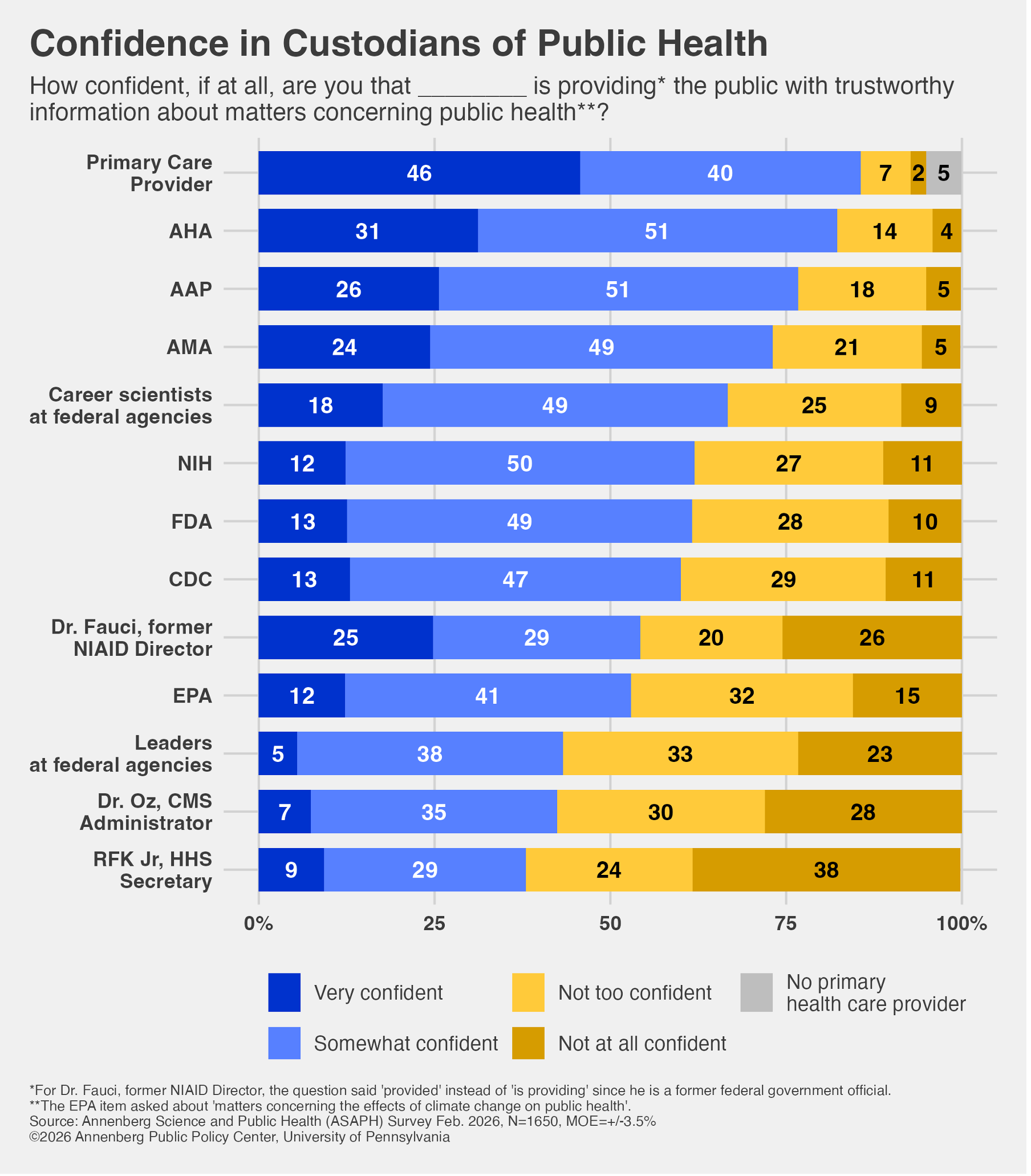
Make no mistake about what is happening.
The Department of War (DoW) demanded Anthropic bend the knee, and give them ‘unfettered access’ to Claude, without understanding what that even meant. If they didn’t get what they want, they threatened to both use the Defense Production Act (DPA) to make Anthropic give the military this vital product, and also designate the company a supply chain risk (SCR).
Hegseth sent out an absurdly broad SCR announcement on Twitter that had absolutely no legal basis, that if implemented as written would have been corporate murder. They have now issued an official notification, which is still illegal, arbitrary and capricious, but is scoped narrowly and won’t be too disruptive.
Nominally the SCR designation is because we cannot rely on that same product when the company has not bent the knee and might object to some uses of its private property that it never agreed to allow.
No one actually believes this. No one is pretending others should believe this. If they have real concerns, there are numerous less restrictive and less disruptive tools available to the Department of War. Many have the bonus of being legal.
In actuality, this is a massive escalation, purely as punishment.
DoW is saying that if you claim the right to choose when and how others use your private property, and offer to sign some contracts but not sign others, that this means you are trying to ‘usurp power’ and dictate government decisions.
It is saying that if you do not bend the knee, if your business does not do what we want, then we cannot abide this. We will illegally retaliate and end your business.
That is not how the law works. That is not how a Republic works.
This was completely unnecessary. Talks were ongoing. The two sides were close. The deal DoW signed with OpenAI, the same night as the original SCR designation, violates exactly the red line principles and demands the DoW says abide no compromises.
The good news is that there are those who managed to limit this to a narrowly tailored SCR, that only applies to direct provision of government contracts. Otherwise, this does not apply to you. Even if that gets tied up in court indefinitely, this will not inflict too much damage on either Anthropic or national security.
The question is how much jawboning or further steps come after this, but for now we have dodged the even worse outcomes keeping us up at night.
You might be tempted to think of or present this as the DoW backing down. Don’t.
Why not? Two good reasons.
-
It isn’t true.
-
This uses USC 3252 because they’d have been laughed out of court if they’d tried to match the no-legal-basis word salad from Friday 5: 14pm.
-
Given the use of USC 3252 this is maximally broad.
-
The fact that they toyed with doing something even worse does not make this not an arbitrary, capricious and dramatic escalation purely as punishment.
-
The DoW cannot see itself as backing down, or it will do even worse things.
Dean W. Ball: No one should frame the DoW’s supply chain risk designation as the government “backing down.” If that becomes “the narrative,” it could encourage further action to avoid the appearance of weakness.
It is also not true that it is backing down; the government really is exercising its supply chain risk designation authority under 10 USC 3252 to the fullest extent (and this is assuming it’s even legitimate to use it on an American firm, which is deeply questionable.
Hegseth’s threat was far broader than his power, which is the only reason this seems deescalatory. If you had asked me for a worst case scenario before Hegseth’s tweet last Friday, I would have told you precisely what has unfolded. This could mean that any vendor of widely used enterprise software (Microsoft, Apple, Salesforce, etc.) could be barred from using Anthropic in the maintenance of any codebases offered to DoW as part of a military contract, for example. Any startup who views DoW as a potential customer for their products will preemptively have to avoid Claude. This is still a massive punishment from USG.
You might also ask: if I knew Hegseth’s power was more limited than he threatened, why did I take his threat at face value? The answer is that we have so clearly moved past the realm of reason here that, well, to a first approximation, I take the guy who runs the biggest military on Earth at his word when he issues threats.
Sometimes some people should talk in carefully chosen Washington language, as ARI does here. Sometimes I even do it. This is not one of those times.
-
Post Overview.
-
Anthropic’s Statement on the SCR.
-
What The Actual SCR Designation Says.
-
Enemies of The Republic.
-
Regulation Need Not Seize The Means Of Production.
-
Microsoft Stands Firm.
-
Calling This What It Is.
-
What To Expect Next.
This post is an update on events since the publication of the weekly, and an attempt to reiterate key events and considerations to put everything into context.
For details and analysis of previous events, see my previous posts:
-
Anthropic and The Department of War, from February 25.
-
Anthropic and the DoW: Anthropic Responds, from February 27.
-
A Tale of Three Contracts, From March 3.
-
AI #158: The Department of War, from March 5.
For those following along these are the key events since last time:
-
Wednesday morning: Talks between Anthropic and the DoW have resumed, in line with FT reporting, and progress on concrete proposals is being made.
-
Wednesday afternoon: An internal Anthropic memo from Friday evening uncharacteristically leaks, most of which was correct technical explanations of the situation, and also containing some reasonable suppositions as of time of writing, but that also included some statements that were ill-considered and caused fallout. Negotiations were disrupted.
-
Thursday morning: All quiet as everyone dealt with fallout from the leaked internal Anthropic memo. Scrambling to keep things contained continues.
-
Thursday, 1pm: Katrina Manson reports that the Pentagon has sent a formal SCR to Anthropic, but the report has no details.
-
Thursday afternoon: Reporting comes out that ‘Trump plans U.S. control over global AI chip sales’ and it remains unclear what this means but Commerce has been very clear they’re not bringing back diffusion rules and that the early reporting gave a false impression. We still await clarity on what is changing.
-
Thursday evening: Anthropic issues a conciliatory statement, noting that the SCR is of limited scope and need not impact the vast majority of customers, pointing out that everyone wants the same outcomes and wants to work together and that discussions have been ongoing, and directly and personally apologizing for the leaked Anthropic memo that Dario Amodei wrote on Friday night.
-
Meanwhile: Various people continue to advocate against private property.
It was an excellent statement. I’m going to quote it in full, since no one clicks links and I believe they would want me to do this.
Dario Amodei (CEO Anthropic): Yesterday (March 4) Anthropic received a letter from the Department of War confirming that we have been designated as a supply chain risk to America’s national security.
As we wrote on Friday, we do not believe this action is legally sound, and we see no choice but to challenge it in court.
The language used by the Department of War in the letter (even supposing it was legally sound) matches our statement on Friday that the vast majority of our customers are unaffected by a supply chain risk designation. With respect to our customers, it plainly applies only to the use of Claude by customers as a direct part of contracts with the Department of War, not all use of Claude by customers who have such contracts.
The Department’s letter has a narrow scope, and this is because the relevant statute (10 USC 3252) is narrow, too. It exists to protect the government rather than to punish a supplier; in fact, the law requires the Secretary of War to use the least restrictive means necessary to accomplish the goal of protecting the supply chain. Even for Department of War contractors, the supply chain risk designation doesn’t (and can’t) limit uses of Claude or business relationships with Anthropic if those are unrelated to their specific Department of War contracts.
I would like to reiterate that we had been having productive conversations with the Department of War over the last several days, both about ways we could serve the Department that adhere to our two narrow exceptions, and ways for us to ensure a smooth transition if that is not possible. As we wrote on Thursday, we are very proud of the work we have done together with the Department, supporting frontline warfighters with applications such as intelligence analysis, modeling and simulation, operational planning, cyber operations, and more.
As we stated last Friday, we do not believe, and have never believed, that it is the role of Anthropic or any private company to be involved in operational decision-making—that is the role of the military. Our only concerns have been our exceptions on fully autonomous weapons and mass domestic surveillance, which relate to high-level usage areas, and not operational decision-making.
I also want to apologize directly for a post internal to the company that was leaked to the press yesterday. Anthropic did not leak this post nor direct anyone else to do so—it is not in our interest to escalate this situation. That particular post was written within a few hours of the President’s Truth Social post announcing Anthropic would be removed from all federal systems, the Secretary of War’s X post announcing the supply chain risk designation, and the announcement of a deal between the Pentagon and OpenAI, which even OpenAI later characterized as confusing. It was a difficult day for the company, and I apologize for the tone of the post. It does not reflect my careful or considered views. It was also written six days ago, and is an out-of-date assessment of the current situation.
Our most important priority right now is making sure that our warfighters and national security experts are not deprived of important tools in the middle of major combat operations. Anthropic will provide our models to the Department of War and national security community, at nominal cost and with continuing support from our engineers, for as long as is necessary to make that transition, and for as long as we are permitted to do so.
Anthropic has much more in common with the Department of War than we have differences. We both are committed to advancing US national security and defending the American people, and agree on the urgency of applying AI across the government. All our future decisions will flow from that shared premise.
I believe and hope that this will help move things forward towards de-escalation.
Secretary of War Pete Hegseth’s original Tweet on Friday at 5: 14pm was not a legal document. It claimed that it would bar anyone doing business with the DoW from doing any business with Anthropic, for any reason. This would in effect have been an attempt at corporate murder, since it would have attempted to force Anthropic off of the major cloud providers, and have forced many of its largest shareholders to divest.
That move would have had no legal basis whatsoever, and also no physical logic whatsoever since selling goods or services to Anthropic, or providing Anthropic services to others, obviously has no impact on the military supply chain. It would not have survived a court challenge. But if Anthropic failed to get a TRO, that alone could have caused major disruptions and a stock market bloodbath.
We are very fortunate and happy that this was not the letter that DoW ultimately chose to send after having time to breathe. As per Anthropic, the official supply chain risk designation letter invokes the narrow form of SCR, 10 USC 3252.
Anthropic: The Department’s letter has a narrow scope, and this is because the relevant statute (10 USC 3252) is narrow, too. It exists to protect the government rather than to punish a supplier; in fact, the law requires the Secretary of War to use the least restrictive means necessary to accomplish the goal of protecting the supply chain.
Even for Department of War contractors, the supply chain risk designation doesn’t (and can’t) limit uses of Claude or business relationships with Anthropic if those are unrelated to their specific Department of War contracts.
There are three levels of danger to Anthropic here if the classification is sustained.
-
Direct loss of business from impacted tasks. This is nothing. Defense contracts and government use are a tiny portion of overall revenue.
-
Indirect loss of business due to dual stack, uncertainty or compliance costs. Those who have some restricted business might not want to maintain dual technology stacks or deal with compliance issues, or worry about future changes. There will be some of this on the margin, and all the time we end up with ‘the government is clearly okay with [X] so even though [X] is worse we’ll just use [X].’ There will be some of that, presumably, but even this is a tiny fraction of revenue. The big companies that matter aren’t going to switch over this nor should they.
-
Fear of future jawboning and illegal government actions, or actual jawboning. The government could use various other ways to bring pressure on companies to cut business. If things stay sufficiently hostile they might try, but I don’t see this working. Eight of the ten biggest companies use Anthropic, it’s the majority of enterprise sales, it’s tied closely to Amazon and Google. I don’t even think there will be substantial impact on cost of capital.
But we do have to watch out. If the government is sufficiently determined to mess with you, and doesn’t care about how much damage this does including to rule of law, they have a lot of ways to do that.
Remarkably many people are defending this move, and mostly also defending the legally incoherent move that was Tweeted out on Friday afternoon.
The defenders of this often employ rhetoric that is truly reprehensible, and entirely incompatible with freedom, a Republic or even private property.
They say that the United States Government, and de facto they mean the executive branch, because the President was duly elected, can do anything it wants, and must always get its way, make all decisions and be the only source of power. That if what you create is sufficiently useful then it no longer belongs to you, and any private actor that prospers too much must be hammered down to protect state authority.
There are words for this. Communist. Authoritarian. Dictatorship. Gangster nations.
This is how such people are trying to redefine ‘democracy’ in real time.
You do not want to live in such a nation. Such nations do not have good futures.
roon (OpenAI): to reiterate: whatever went wrong between amodei & hegseth, whatever rivalry between the labs, this is a massive overreaction and a dark precedent
Ash Perger: this is the first time that I’m really surprised by your stance. the reality is that the USG can in general do whatever they want. they always have and always will.
within a certain frame, courts and laws are allowed to exist and give people the illusion that these systems and principles extend to ALL actions of the USG.
but once you go outside of this frame and challenge the absolute RAW power behind the scenes, anything goes. that’s the realm that Anthropic entered and challenged the USG within. and at least since the early 20th century, the USG has never reacted to a direct challenge in the true realm of its hard power in a peaceful way.
this is not a conspiracy angle or anything, it’s just how power has worked since time beginning.
Anthropic didn’t challenge the government’s power. Anthropic used the most powerful weapon available to every person, the right to say ‘no’ and take the consequences. These are the consequences, if you don’t live in a Republic.
If you remember one line today, perhaps remember this one:
roon (OpenAI): > the USG can in general do whatever they want
The founders of this great nation fought several bloody wars to make sure this is not true.
The government cannot, in general, do whatever it wants.
That could change. It can happen here. Know your history, lest it happen here.
Kelsey Piper: incredible to see people just casually reject the bedrock foundations of American greatness not just as some dumb nonsense that they’re too cool to believe but as something they literally are not familiar with
As Dean Ball has screamed from the rooftops, we have been trending in this direction for quite some time, and the danger to the Republic and attacks on civil liberties is coming from all directions. The situation is grim.
There are words for those who support such things. I don’t have to name them.
I have talked for several years about the Quest For Sane Regulations, because I believe the default outcome of building superintelligence is that everyone dies and that highly capable AI presents many catastrophic risks. I supported bills like SB 1047 that would have given us transparency into what was happening and enforcement of basic safety requirements.
We were told this could not be abided. We were told, often by the same people, that such fears were phantoms, that there was ‘no evidence’ that building machines smarter, more capable and more competitive than us might be an inherently unsafe thing for people to do. We were lectured that requiring our largest AI labs to do basic things would devastate our AI industry, that it would take away our freedoms, that we would lose to China, that these concerns could be dealt with after they had already happened, that any government intervention was inevitably so malign we were better off with a yolo.
Those people still do not even believe in superintelligence. They do not understand the transformations coming to our world. They do not understand that we are about to face existential threats to our survival as humans and to everything of value. All they see in this world is the power, and demand that it be handed over.
What I hate the most, and where I want to most profoundly say ‘fuck you,’ are those who claim that this is somehow about ‘AI safety’ or concerns about superintelligence, when that very clearly is not true.
As a reminder:
-
Anthropic thinks AI will soon be highly capable, ‘geniuses in a data center.’
-
Anthropic thinks this poses existential risks to humanity.
-
Pete Hegseth does not believe either of these things.
-
The White House does not believe either of these things.
-
Those defending this move mostly do not believe either of these things.
-
They try to pretend that Anthropic saying it justifies destroying Anthropic if Anthropic does not agree to bend the knee.
-
They try to pretend sometimes they aren’t really making the worst arguments, they’re hypotheticals, they’re saying something else like need for clarity.
-
They repeat DoW misinformation about what led to this, as if it is basically true.
-
When pressed they admit this is simply about raw power, because it is.
We saw this yesterday with Ben Thompson. Here we see it with Krishnan Rohit and Noah Smith.
Noah Smith: By the way, as much as I hate to say it, the Department of War is right and Anthropic is wrong. Here’s why.
…
Let’s take this a little further, in fact. And let us be blunt. If Anthropic wins the race to godlike artificial superintelligence, and if artificial superintelligence does not become fully autonomous, then Anthropic will be in sole possession of an enslaved living god. And if Dario Amodei personally commands the organization that is in sole possession of an enslaved god, then whether he embraces the title or not, Dario Amodei is the Emperor of Earth.
Are you fucking kidding me? You’re pull quoting that at us, on purpose?
And if you go even one level down in the thread you get this:
Jason Dean: What does this have to do with the Supply Chain Risk designation?
Noah Smith: Nothing. Hegseth is a thug. But we CANNOT expect nation-states to surrender their monopoly on the use of force.
So let me get this straight. The Department of War is run by a thug who is trying to solve the wrong problem using the wrong methods based on the wrong model of reality, and all of his mistakes are very much not going to cancel out, but he’s right?
And why is he right? Because might makes right. How else can you read that reply?
He’s even quoting the ultimate bad faith person and argument here, directly, except he’s only showing Marc here without Florence:
At least he included the reversal after, noting that the converse is also true.
Then there’s the obvious other point.
Damon Sasi: You can in fact think both are wrong for different reasons.
Of course a private corporation shouldn’t [be allowed to] build and own a techno-god. Yes. Absolutely.
AND ALSO, the government response shouldn’t be “take off the nascent-god’s safety rails so we can do unethical things with it.”
That the government thinks it’s just a fancy weapon is immaterial when the thing that makes them wrong is wanting to do illegal things through unethical methods. You don’t have to steelman Hegseth just because a better man might do a different, better thing for other reasons.
I cannot say enough that the logic response to ‘these people want to build a techo-god,’ under current conditions, is ‘wait no, stop, if this is actually something they’re close to doing. No one should be building a techo-god until we figure this stuff out on multiple levels and we’ve solved none of them, including alignment.’
These same Very Serious People never consider the Then Don’t Build It So That Everyone Doesn’t Die strategy.
But wait, there’s more.
Noah Smith: Ben Thompson of Stratechery makes this case. He points out that what we are effectively seeing is a power struggle between the private corporation and the nation-state. He points out that although the Trump administration’s actions went outside of established norms, at the end of the day the U.S. government is democratically elected, while Anthropic is not.
Remember yesterday, when Ben Thompson tried to pretend he was only making a non-normative argument? Yeah, well, ~0% of people reading the post took it that way, he damn well knew that’s how people would take the argument, and it’s being quoted approvingly by many, and Ben hasn’t, shall we say, been especially loud and clear about walking it back. So yeah, let’s stop pretending.
Noah Smith: It’s a question of the nation-state’s monopoly on the use of force.
Among others, I most recently remember Dave Chappelle saying that we have the first amendment protecting our right to free speech, and the second amendment in case the first one doesn’t work out.
Whereas Noah Smith is explicitly saying Claude should be treated like a nuke.
So as much as I dislike Hegseth’s style, and the Trump administration’s general pattern of persecution and lawlessness, and as much as I like Dario and the Anthropic folks as people, I have to conclude that Anthropic and its defenders need to come to grips with the fundamental nature of the nation-state.
It seems a lot of people think the fundamental nature of the nation-state is that of a gangster, like Putin, and they are in favor of this rather than against it.
If the pen is mightier than the sword, why are we letting people just buy pens?
I do respect that at least Noah Smith is, at long last, taking the idea of superintelligence seriously, except when it comes time to dismiss existential risk.
He seems to be very quickly getting to some other conclusions, including ending API access for highly capable models, and certainly banning open source.
Maybe trying to ‘wake up’ such folks was always a mistake.
As a reminder ‘force the government’s hand’ means ‘don’t agree to hand over their private property, and indeed engineer and deliver new forms of it, to be used however the government wants, on demand, while bending the knee.’
rohit: It is absurd to say you’re building a nuke and not expect the government to take control of it!
Noah Smith: Yes.
Rohit: you’re doing a straussian reading and missing the fact that I wasn’t blaming anthropic for the scr, what I am doing is drawing a line from ai safety language, helped by the very water we swim in, and the actions that were taken by DoW. it’s naive to think theyre unrelated
Dean W. Ball: they are coming from people *who entirely and explicitly dismiss the language of ai safety*—please explain how it is “naive” to say “ai safety motivations do not explain Pete Hegseth’s behavior”
rohit: because you don’t actually have to believe that it’s bringing forth a wrathful silicon god to want to control the technology! you just need to think its useful and powerful enough. and they very clearly think its powerful, and getting more so by the day.
Dean W. Ball: Ok, so the actual argument is more like “Anthropic builds a useful technology whose utility is growing, therefore they should expect to have their property expropriated and to be harassed by the government.”
The whole point of America is that isn’t supposed to be true here.
At the same time, inre: my writing earlier this week, all I have to say to the qt is “quod erat demonstrandum”
… I think the better explanation is that this is not that different from the universities or the law firms or whatever else, this is part of a pretty consistent pattern/playbook and that this explains what we have seen much better than this ai governance stuff.
though it’s true that this issue does raise a lot of interesting ai governance is questions, I just do not think anything like that is top of mind at all for the relevant actors.
This is very simple. These people are against regulation, because that would be undue interference, except when the intervention is nationalization, then it’s fine.
Indeed, the argument ‘otherwise this wouldn’t be okay because it isn’t regulated’ is then turned around and used as an argument to take all your stuff.
Dean W. Ball: The problem with this is that DoW is not taking Anthropic’s calls for “oversight” seriously. Indeed, elsewhere in the administration, Anthropic’s “calls for oversight” are dismissed as “regulatory capture” and actively fought. Rohit and Noah [Smith] are dressing up political harassment.
Quite clever. Dean and Rohit went back and forth in several threads, all of which only further illustrate Dean’s central point.
Rohit Krishnan: You simply cannot call your technology a major national security risk in dire need of regulation and then not think the DoD would want unfettered access to it. They will not allow you, rightfully so in a democracy, to be the arbiters of what is right and wrong. This isn’t the same as you or me buying an iOS app and accepting the T&Cs.
It’s clear as day. If you say you need to be regulated, they get to take your stuff.
If you try to say how your stuff is used, that’s you ‘deciding right and wrong.’
Rohit Krishnan: Democracy is incredibly annoying but really, what other choice do we have!
The choice is called a Republic. A government with limited powers, where private property is protected.
The alternative being suggested is one person, one vote, one time.
That sometimes works out well for the one person. Otherwise, not so well.
TBPN asks Dean Ball about the gap between regulation and nationalization, drawing the parallel to the atomic bomb. Dean agrees nukes worked out but we failed to get most of the benefits of nuclear energy, and points out the analogy breaks down because AI expresses and is vital to your liberty, and government control of AI inevitably would lead to tyranny. Whereas control over energy and bombs does not do that, and makes logistical sense.
Dean also points out that ‘try to get regulation right’ has been systematically categorized as ‘supporting regulatory capture,’ even when bills like SB 53 are extremely light touch and clearly prudent steps.
It has been made all but impossible to stand up regulations that matter, as certain groups concentrate their fire on attempts to have us not die, while instead states instead are left largely free to push counterproductive bills that would only cut off AI’s benefits, or that would disrupt construction of data centers.
I can affirm strongly that Anthropic has not been in any way, shape or form advocating for regulatory capture, and has opposed or not supported measures I strongly supported, to my great frustration. Indeed, Anthropic’s pushes here have resulted in clashes with the White House that are very much not helping Anthropic’s net present value of future cash flows.
It is many of the other labs that have been trying to lobby primarily for their own shareholder value.
Whereas OpenAI and a16z and others, through their Super PAC, have been trying to get an outright federal moratorium on any state laws, so that we can instead pursue some amorphous undefined ‘federal framework’ while sharing no details whatsoever about what such a thing would even look like (or at least none that would have any chance of accomplishing the task at hand), and systematically trying to kill the campaign of Alex Bores to send a message that no attempts at AI regulation will be tolerated.
Whenever someone says they want a national framework, ask to see this supposed ‘federal framework,’ because the only person who has proposed a real one that I’ve seen is Dean Ball and they sure as hell don’t plan on implementing his version.
But we digress.
The SCR is narrow, so there is no legal reason for anyone to change their behavior unless they are directly involved in defense contracting. And corporate America is making it very clear they are not going to murder one of their own simply because the DoW suggests they do so.
In particular, the companies that matter are the big three cloud providers: Google, Amazon and Microsoft. I was not worried, but it is good to have explicit statements.
Microsoft wasted no time, being first to make clear they will continue with Anthropic.
TOI Tech Desk: Microsoft has now announced that it will continue to embed Anthropic’s artificial intelligence models in its products, despite the US Department of War labelling the startup as a supply-chain risk.
“Our lawyers have studied the designation and have concluded that Anthropic products, including Claude, can remain available to our customers — other than the Department of War — through platforms such as M365, GitHub, and Microsoft’s AI Foundry,” a Microsoft spokesperson told CNBC.
Sad but accurate, to sum up what likely happened:
roon: to reiterate: whatever went wrong between amodei & hegseth, whatever rivalry between the labs, this is a massive overreaction and a dark precedent.
Anthropic is one of my favorite accelerationist recursive self improvement labs. it rocks that they’re firing marvelously on all cylinders across all functions to duly serve the technocapital machine at the end of time and the pentagon is slowing them down for stupid reasons.
Sway: Roon, if OpenAI had stood firm on the side of Anthropic, then this move would have been less likely and probably averted. Instead, sama gave all the leverage to Trump admin. Sad state of affairs
roon: this is possible, yes
I share Sway’s view here. I think Altman was trying to de-escalate, but by giving up his leverage, and by cooperating with DoW messaging, he actually caused the situation to escalate further instead.
If the reason for all this was that DoW believed Eliezer Yudkowsky’s position that If Anyone Builds It, Everyone Dies, then that would be a very different conversation. This is the complete opposite of that.
The likely next move is that Anthropic will sue the Department of War. They will challenge the arbitrary and capricious supply chain risk designation, because it is arbitrary and capricious. Anthropic presumably wins, but it does not obviously win quickly.
If Anthropic does not sue soon, I would presume that would be because either:
-
Anthropic has ongoing constructive negotiations with DoW, and is holding off on filing the lawsuit to that end.
-
Anthropic has an understanding with DoW, whether or not it is explicit, that not challenging this would allow this to be the end of the conflict, or at least allow the damage involved to remain limited on all sides.
We are used to things happening in hours or days. That is often not a good thing. One reason things went south here is this rush. The memo was written on Friday evening, in a very different situation. Then, when the memo leaked, it was less than 24 hours before the supply chain risk designation was issued, while everyone was screaming ‘why hasn’t Dario apologized?’
It took him roughly 30 hours to draft that apology. That’s a very normal amount of time in this situation, but events did not allow that time. People need to calm down and take a moment, find room to breathe, consult their lawyers, pay to know what they really think, and have unrushed discussions.