Two versions here, a long version that attempts to compress with minimal loss, and a short version that gives the gist.
The second part goes over where I agree and disagree, and briefly explains why.
The third part is the summary of other people’s reactions and related discussions, which will also include my own perspectives on related issues.
My goal is often to ask ‘what if.’ There is a lot I disagree with. For each subquestion, what would I think here, if the rest was accurate, or a lot of it was accurate?
I had Leopold review a draft of this post. After going back and forth, I got a much better idea of his positions. They turned out to be a lot closer to mine than I realized on many fronts.
The biggest agreement is on cybersecurity and other security for the labs. I think this holds with or without the rest of the argument. This includes the need to build the data centers in America.
The arguments on power seem mostly right if the path to AGI and ASI is centrally hyperscaling on current approaches and happens quickly. I am highly uncertain about that being the path, but also America badly needs permitting reform and to build massive new sources of electrical power.
Those are both areas where the obvious responses are great ideas if we are not on the verge of AGI and will remain in the ‘economic normal’ scenario indefinitely. We should do those things.
Otherwise, while Leopold’s scenarios are possible, I am not convinced.
I do not believe America should push to AGI and ASI faster. I am still convinced that advancing frontier models at major labs faster is a mistake and one should not do that. To change that, fixing security issues (so we didn’t fully hand everything over) and power issues (so we would be able to take advantage) would be necessary but not sufficient, due to the disagreements that follow.
The most central crux is that to me a path like Leopold predicts and advocates for too frequently dooms humanity. He agrees that it is a risky path, but has more hope in it than I do, and sees no better alternative.
Everyone loses if we push ahead without properly solving alignment. Leopold and I agree that this is the default outcome, period. Leopold thinks his plan would at least makes that default less inevitable and give us a better chance, whereas I think the attitude here is clearly inadequate to the task and we need to aim for better.
We also have to solve for various dynamics after solving alignment. I do not see the solutions offered here as plausible. And we have to avoid this kind of conflict escalation turning into all-out war before decisive strategic advantage is achieved.
Alignment difficulty is a key crux for both of us. If I was as bullish on alignment as Leopold, that would change a lot of conclusions. If Leopold was sufficiently skeptical on alignment, that would greatly change his conclusions as well.
When I say ‘bullish on alignment’ I mean compared to what I believe is the reasonable range of outlooks – there are many who are unreasonably bullish, not taking the problem seriously.
The second central crux is I am far less hopeless on alternative options even if Leopold’s tech model is mostly right. If I knew his tech model was mostly right, and was convinced that the only alternative future was China rushing ahead unsafely, and they would be likely to go critical, then there are no reasonable options.
If I was as bearish on alternatives as Leopold, but remained my current level of bearish on alignment, and the tech worked out like he predicts, then I would largely despair, p(doom) very high, but would try to lay groundwork for least bad options.
I am also not so confident that governments can’t stay clueless, or end up not taking effective interventions, longer than they can stay governments.
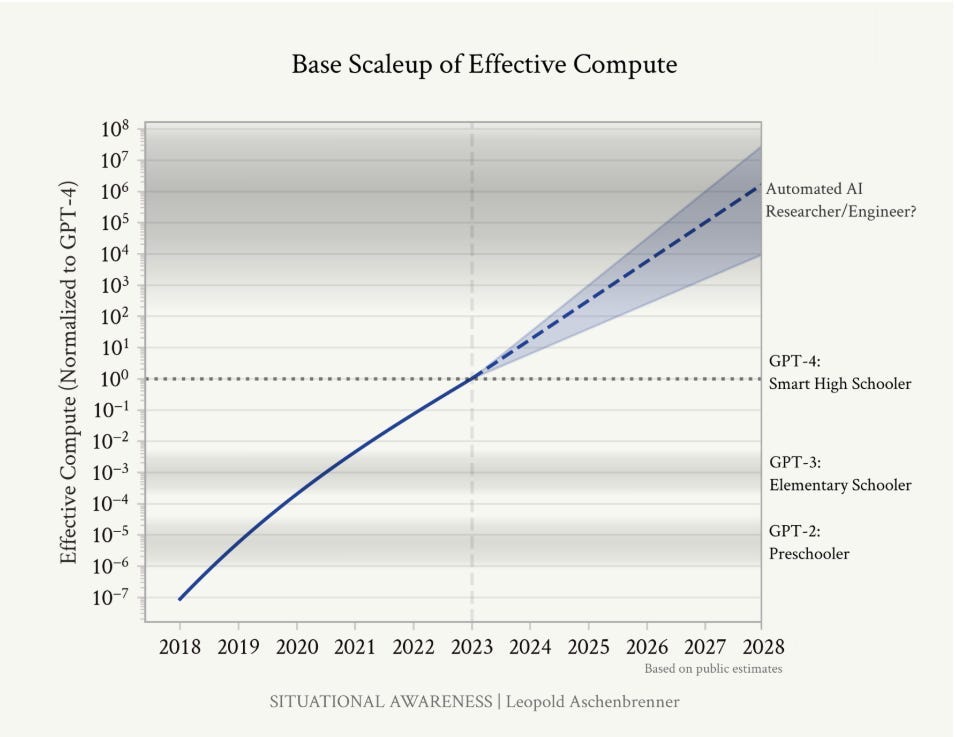
I am far less confident in the tech model that scaling is all you need from here. I have less faith in the straight lines on graphs to continue or to mean in practice what Leopold thinks they would. We agree that the stages of human development metaphor (‘preschooler,’ ‘smart undergraduate’ and so on) are a flawed analogy, but I think it is more flawed than Leopold does. although I think there is a decent chance it ends up getting an approximately right answer.
If we do ‘go critical’ and get to Leopold’s drop-in workers or similar, then I think if anything his timelines from there seem strangely slow.
I don’t see the ‘unhobbling’ terminology as the right way to think about scaffolding, although I’m not sure how much difference that makes.
I suspect a lot of this is a decision theory and philosophical disagreement.
If you read the Situational Awareness paper, it is clear that much of it is written from the primary perspective of Causal Decision Theory (CDT), and in many places it uses utilitarian thinking, although there is some deontology around the need for future liberal institutions.
Thinking in CDT terms restricts the game theoretic options. If you cannot use a form of Functional Decision Theory (FDT) and especially if you use strict CDT, a lot of possible cooperation becomes inevitable conflict. Of course you would see no way to avoid a race other than to ensure no one else has any hope they could win one. Also, you would not ask if your type of thinking was exactly what was causing the race in the first place in various ways. And you would not notice the various reasons why one might not go down this road even if the utilitarian calculus had it as positive expected value.
Another place this has a big impact is alignment.
If you think that alignment means you need to end up with an FDT agent rather than a CDT agent to avoid catastrophe, then that makes current alignment techniques look that much less hopeful.
If you think that ASIs will inevitably figure out FDT and thus gain things like the ability to all act as if they were one unified agent, or do other things that seem against their local incentives, then a lot of your plans to keep humans in control of the future or get an ASI to do the things you want and expect will not work.
In my own words, here is my attempt to condense Leopold’s core claims (with varying levels of confidence) while retaining all the load bearing arguments and points.
Category 1 (~sec 1-2): Capabilities Will Enable ASI (superintelligence) and Takeoff
The straight lines on graphs of AI capabilities will mostly keep going straight. A lot of the gains come from ‘unhobbling,’ meaning giving the AI new tools that address its limitations, and picking up ‘paradigm expanding’ capabilities.
Extending those lines would soon result in AI gaining the ability to generate ‘drop in remote workers’ and otherwise accelerate AI research. A flawed metaphor offered to verbalize this is going from a preschooler to a high school student to (now) an undergraduate and extending that into the future.
This level of capabilities is ‘strikingly possible’ by 2027.
Once that happens, AI progress accelerates into a ‘slow’ takeoff that is still quite fast, as within one to a few years AI enables rapid advancements in AI, ASI, and then rapid advancements in everything else. The world will transform. This period is deeply scary, but if we get through and the ‘good guys’ have the power it will be great.
Various potential bottlenecks might slow this down a bit, but they will not stand in the way for long once the process gets rolling. There is tons of slack here. ASI solves this. But see the power section.
Category 2 (~sec 3c): Alignment is an Engineering Problem
Alignment, even superalignment of ASIs, is an ordinary engineering problem.
Solving the problem only requires avoiding a bounded set of failure modes or preventing particular catatsrophic misbehaviors. Your job is to impose ‘side constraints’ that prevent undesired actions and enforce desired norms.
Alignment is still difficult. The more time and resources you invest in alignment, the more likely your solution is to be correct.
(Implicit) Time and resources spent on alignment when AI systems are more advanced are vastly more effective than those spent on alignment earlier.
If one has a ‘margin of safety’ similar to a few years, chances of solving alignment in time are very good.
If one has a smaller ‘margin of safety,’ chances of solving alignment in time are much worse, potentially very bad.
By default, the time during the transition (see #4) will involve making fast highest-possible-stakes related decisions under deep uncertainty.
Getting the solution wrong when building an ASI would be very very bad.
If ‘the good guys’ win the race to ASI and have ‘solved alignment,’ then the future will almost certainly turn out well. We would retain our liberal democracy and have the AI follow things like the constitution and separation of powers.
Category 3 (~sec 3a): Electrical Power and Physical Infrastructure Are Key
The advancements in category one likely require massive amounts of compute from massive data centers drawing world-changing levels of electrical power consumption. We should expect a $100 billion cluster, perhaps a $1 trillion cluster.
Private capitalist incentives are sufficient for the $100 billion cluster. For the $1 trillion cluster if it proves necessary, they might need some help, they might not.
The immense power consumption required will soon be a limiting factor.
We will need vastly more power on a very rapid timescale.
We need to do this in America together with its democratic allies. Lacking physical control of your data centers is like not physically controlling your nukes.
To do that in America, we likely need to use natural gas. We absolutely have the required natural gas. We need to get our act together. Permitting reform will be vital. Fission could help a lot, but not with standard delays.
The alternative is to build the data centers elsewhere, such as in dictatorial states like the UAE. We absolutely must avoid doing this, as it would put us in danger and give such players a seat at the table.
Category 4 (~sec 3b): We Desperately Need Better Cybersecurity
Current cybersecurity at the major AI labs would be trivial for state actors to penetrate if they wanted to do that. And they do indeed want to do that, and do it all the time, and over time will do it more and harder.
Until that changes, anything we develop, including both models and algorithmic improvements to train future models, will fall into the hands of others especially China. If that happens, we would lose what would otherwise be our substantial lead, and we go into an endgame that is at best a race, and potentially one where we are in deep trouble (see Category 5).
It would also fall into the hands of Russia, North Korea and other rogue states, and even non-state terrorist actors, who would likely get access to WMDs.
There will be a period where stealing the weights of an AI from the right lab would enable WMDs, but before ASI gets powerful enough to block WMDs.
The algorithmic improvements the labs have and are developing now, that are nominally secret now, will be important to building future advanced AIs and ASIs. The weights of the automated worker enabling AIs will be vastly more important, potentially soon.
Therefore we desperately need superior cybersecurity and other security now, to prevent our secrets from being stolen.
The labs are startups or at best Google, and they lack the right degree of incentive to address the issue, and worry about falling behind other labs if they sacrifice progress for security. Even if they wanted to implement strong security, only the government has the expertise to do it. Thus, we need to assist, and also insist.
The required level of security will ramp up over time, as the resources committed to launching attacks go up and the stakes also rise. We need to stay ahead of the curve. Right now we are far behind it.
Open source is a distraction. They will not be able to keep up. Let them have their years-behind toys and commercial applications, it is all good. We only need to protect the major labs.
Category 5 (~sec 3d and 4): National Security and the Inevitable Conflicts
He who controls the most advanced ASI controls the world. Even a few months lead would be decisive in a military conflict. Nuclear deterrents would be beaten.
ASI also enables transformational economic growth and generally allows you to do what you want and impose your will on the world. This is everything.
If China got there first, they would quite possibly impose a dystopian future. Very bad.
If America and the Free World got there first, we would then be able to preserve a good future, and impose peace through strength as needed. Very good.
China is still in it to win it, because they can steal our algorithms and models and they can presumably outbuild us to get more data centers and provide more electrical power and other physical infrastructure. They are great at that.
America will if possible act reasonably regarding alignment. China likely won’t.
Right now both China and America’s governments lack situational awareness on this. They don’t understand the stakes.
Both governments will wake up soon, and understand the stakes. Race will be on.
Even if the governments don’t wake up, the corporations building AI are already awake, and if not stopped they would race instead.
America and its allies will respond to this via public-private partnerships with the major labs, similar to what we have with Boeing, and effectively take over and nationalize our AI efforts in what Leopold calls The Project. They will call the shots. They will come into the game late and thus largely act in blunt fashion. This is our best hope to be first to the transition, and also to slow down the transition.
China’s government will care about who wins far more than the question of alignment or existential risk. Ours will care about national security which includes a wide variety of concerns, including staying ahead and beating China but also superintelligence misalignment, WMD proliferation and worrying about the labs themselves.
It is sufficiently vital that we win that we should consider not sharing our alignment research, because it is dual use.
There is essentially no hope of China and America reaching an agreement except through America having overwhelming force via a sustained AI lead. The two sides would never reach a deal otherwise.
Even if there was a deal, it would be an unstable equilibrium. It would be too easy for either side to break out. The game theory is too hard, it can’t be done.
Thus the conclusion: The Project is inevitable and it must prevail. We need to work now to ensure we get the best possible version of it. It needs to be competent, to be fully alignment-pilled and safety-conscious with strong civilian control and good ultimate aims. It needs to be set up for success on all fronts.
That starts with locking down the leading AI labs and laying groundwork for needed electrical power, and presumably (although he does not mention this) growing state capacity and visibility to help The Project directly.
The categories here correspond to the sections in the long version.
AI will via scaling likely reach ‘drop in AI researcher’ by 2027, then things escalate quickly. We rapidly get ASI (superintelligence) and a transformed world. All this requires is following straight lines on graphs, it is to be expected.
Alignment is difficult but solvable, although the rapid transition to the ASI world will be scary. If we have sufficient safety margin in the endgame we can use our AI researchers to solve it. Once we ‘solve alignment’ via side constraints we can mostly stop worrying about such issues.
The real potential bottleneck is access to sufficient electrical power as we scale.
AI lab cybersecurity is woefully inadequate and we need to fix that yesterday, or China, Russia and every rogue state will continue stealing everything our labs come up with, WMDs will proliferate and so on.
AI will become the key to national security, so when the government realizes this AI will get nationalized, forming The Project. We will then be able to fix our cybersecurity, maintain our lead and navigate safely to superintelligence to secure a good future. Only way out is through. There is no negotiating except through strength. If we don’t win, either China wins or proliferation means the world descends into chaos. Faster we do it, the more ‘margin of safety’ we gain to solve alignment, and the safer it gets.
Success means we survive, and likely get a good future of liberal democracy. Losing means we get a bad future, or none at all.
Keys to beating China by enough to have a safety margin are preventing them stealing algorithmic insights starting now, and stealing frontier models later, and ensuring we have sufficient secure physical infrastructure and power generation.
There are many bold and controversial claims. Which of them are how load bearing?
The entire picture mostly depends on Category 1.
If AI is not going to ‘go critical’ in the relevant sense any time soon (the exact timing is not that relevant, 2027 vs. 2029 changes little), then most of what follows becomes moot. Any of the claims here could break this if sufficiently false. The straight lines could break, or they could not mean what Leopold expects in terms of practical benefits, or bottlenecks could stop progress from accelerating.
AI would still be of vital economic importance. I expect a lot of mundane utility and economic growth that is already baked in. It will still play a vital role in defense and national security. But it would not justify rapidly building a trillion dollar cluster. Strain on physical infrastructure and power generation would still be important, but not at this level. A lead in tech or in compute would not be critical in a way that justifies The Project, nor would the government attempt it.
The concerns about cybersecurity would still remain. The stakes would be lower, but would very much still be high enough that we need to act. Our cybersecurity at major labs is woefully inadequate even to mundane concerns. Similarly, AI would be an excellent reason to do what we should already be doing on reforming permitting and NEPA, and investing in a wealth of new green power generation including fission.
If Category 2 is wrong, and alignment or other associated problems are much harder or impossible, but the rest is accurate, what happens?
Oh no.
By default, this plays out the standard doomed way. People fool themselves into thinking alignment is sufficiently solved, or they decide to take the chance because the alternative is worse, or events get out of everyone’s control, and someone proceeds to build and deploy ASI anyway. Alignment fails. We lose control over the future. We probably all die.
Or ‘alignment’ superficially succeeds in the ‘give me what I want’ sense, but then various dynamics and pressures take over, and everything gets rapidly handed over to AI control, and again the future is out of our hands.
The ‘good scenarios’ here are ones where we realize that alignment and related issues are harder and the current solutions probably or definitely fail badly enough people pause or take extreme measures despite the geopolitical and game theory nightmares involved. Different odds change the incentives and the game. If we are lucky, The Project means there are only a limited number of live players, so an agreement becomes possible, and can then be enforced against others.
Leopold’s strategy is a relatively safe play in a narrow window, where what matters is time near the end (presumably due to using the AI researchers), and what otherwise looks like a modest ‘margin of safety’ in calendar time would both be used (you have to be sufficiently confident you have it or you won’t use it) and for that time to work at turning losses into wins. If you don’t need that time at the end, you do not need to force a race to get a large lead, and you have likely taken on other risks needlessly. If the time at the end is not good enough, then you lose anyway.
Category 3 matters because it is the relevant resource where China most plausibly has an edge over the United States, and it might bring other players into the game.
America has a clear lead right now. We have the best AI labs and researchers. We have access to superior chips. If electrical power is not a binding constraint, then even if China did steal many of our secrets we would still have the advantage. In general the race would then seem much harder to lose and the lead likely to be larger, but we can use all the lead and safety margin we can get.
We would also not have to worry as much about environmental concerns. As usual, those concerns take forms mostly unrelated to the actual impact on climate. If we build a data center in the UAE that runs on oil instead of one in America that runs on natural gas, we have not improved the outlook on climate change. We have only made our ‘American’ numbers look better by foisting the carbon off on the UAE. We could of course avoid that by not building the data centers at all, but if Leopold is right then that is not a practical option nor would it be wise if it were.
Also, if Leopold is right and things escalate this quickly, then we could safely set climate concerns aside during the transition period, and use ASI to solve the problem afterwards. If we build ASI and we cannot use it to find a much better way to solve climate, then we (along with the rest of the biosphere, this is not only about humans) have much bigger problems and were rather dead anyway.
Category 4 determines whether we have a local problem in cybersecurity and other security, and how much we need to do to address this. The overall picture does not depend on it. Leopold’s routes to victory depend on indeed fixing this problem, at which point we are in that scenario anyway. So this being wrong would be good news, and reduce the urgency of government stepping in, but not alter the big picture.
Category 5 has a lot of load bearing components, where if you change a sufficient combination of them the correct and expected responses shift radically.
If you think having the most advanced ASI does not grant decisive strategic advantage (29 and 30, similar to category 1), then the implications and need to race fall away.
If you do not believe that China winning is that bad relative to America winning (31 and 32, also 34) (or you think China winning is actively good, as many Chinese do) then the correct responses obviously change. If you think China would be as good or better than us on alignment and safety, that might or might not be enough for you.
However the descriptive or expected responses do not change. Even if China ‘winning’ would be fine because we all ultimately want similar things and the light cone is big enough for everyone, decision makers in America will not be thinking that way. The same goes for China’s actions in reverse.
If you think China is not in it to win it and they are uncompetitive overall (various elements of 33 and 34, potentially 36, similar to category 3) or you can secure our lead without The Project, then that gives us a lot more options to have a larger margin of safety. As the government, if you get situationally aware you still likely want The Project because you do not want to hand the future to Google or OpenAI or allow them to proceed unsafely, and you do not want them racing each other or letting rogue actors get WMDs, but you can wait longer for various interventions. You would still want cybersecurity strengthened soon to defend against rogue actors.
If you think either or both governments will stay blind until it is too late to matter (35 and 36) then that changes your prediction. If you don’t know to start The Project you won’t, even if it would be right to do so.
If America’s response would be substantially different than The Project (37) even after becoming situationally aware, that alters what is good to do, especially if you are unlikely to impact whether America does start The Project or not. It might involve a purer form of nationalization or mobilization. It might involve something less intrusive. There is often a conflation of descriptive and normative claims in situational awareness.
If some combination of governments is more concerned with existential risk and alignment, or with peace and cooperation, than Leopold expects, or there is better ability to work out a deal that will stick (38, 39 and 40) then picking up the phone and making a deal becomes a better option. The same goes if the other side remains asleep and doesn’t realize the implications. The entire thesis of The Project, or at least of this particular project, depends on the assumption that a deal is not possible except with overwhelming strength. That would not mean any of this is easy.
It would be easy to misunderstand what Leopold is proposing.
He confirms he very much is NOT saying this:
The race to ASI is all that matters.
The race is inevitable.
We might lose.
We have to win.
Trying to win won’t mean all of humanity loses.
Therefore, we should do everything in our power to win.
I strongly disagree with this first argument. But so does Leopold.
Instead, he is saying something more like this:
ASI, how it is built and what we do with it, will be all that matters.
ASI is inevitable.
A close race to ASI between nations or labs almost certainly ends badly.
Our rivals getting to ASI first would also be very bad.
Along the way we by default face proliferation and WMDs, potential descent into chaos.
The only way to avoid a race is (at least soft) nationalization of the ASI effort.
With proper USG-level cybersecurity we can then maintain our lead.
We can then use that lead to ensure a margin of safety during the super risky and scary transition to superintelligence, and to negotiate from a position of strength.
This brings us to part 2.
On the core logic of the incorrect first version above, since I think this is a coherent point of view to have and one that it is easy to come away considering:
I agree dependent on the tech, where I have higher uncertainty. If ASI is developed, what form it takes and what is done with it is indeed all that matters. But this is not the same as ‘the race.’ I am not confident ASI is coming that soon.
This might end up being true, but it is far too early to conclude this even in such scenarios. The race is a choice. It need not be inevitable. People can and do coordinate when doing so is hard. Thinking the race is inevitable would be self-fulfilling prophecy. In practice, however, given the actual players and state of the board, it is reasonably likely that if ASI comes soon it will prove impossible to avoid.
I am not as confident. One must always ask, who is we? If the ‘we’ becomes America, versus China, yes it is possible that we lose, especially if we fail to take cybersecurity seriously or otherwise hand over our IP to China. I am however less worried about this than Leopold. And other than security issues, I do not think The Project is obviously accelerationist compared to capitalism even if it is ‘racing to beat China.’
I disagree with magnitude here, and that is important. I certainly would strongly prefer that ‘we’ win, but I do not think losing to China, assuming they won safely, would be as bad as Leopold thinks. Xi and CCP have different values than mine and I very much do not want them to have the future, but I believe they are normative and their values hold some value to me. A lot of the downside of dictatorship is caused by being worried about losing power or severely limited resources and the impact on economics, and that wouldn’t apply. I am more concerned with the scenario where everyone loses.
This is the biggest disagreement. I think that Leopold is wildly optimistic about some aspects of avoiding scenarios where we all lose, although he is if anything more concerned about WMDs and rogue states or actors descending things into chaos. The most obvious place I worry more is alignment failure. Leopold is largely treating alignment like an ordinary ‘find a good enough way to muddle through’ engineering problem solvable by introducing side constraints, when I believe it is a multidisciplinary, multistage, unforgiving, impossible-level problem that you have to solve on the first try, and that side constraints won’t work on their own. And he is treating good outcomes as a default there as long as particular things do not go wrong, as opposed to a special outcome requiring many things to go right. We are optimization machines, we might be able to do that, but the first step is admitting you have a problem. We also disagree about the best way to minimize the chance things degenerate into a war before we gain decisive strategic advantage, or us solving alignment then competitive pressures causing us to lose control anyway, or us failing to choose a wise future, and so on, but less so than it would at first appear.
If #1-#5 in full then #6 (mostly) follows.
This ‘strawman’ version very much relies on assumptions of Causal Decision Theory and a utilitarian framework, as well.
What about the second version, that (I think) better reflects Leopold’s actual thesis? In short:
Yes.
Yes on a longer time horizon. I do think it could plausibly be slowed down.
Yes.
Yes, although to a lesser degree than Leopold if they didn’t get everyone killed.
Yes, although I think I worry about this somewhat less than he does.
I don’t know. This is the question. Huge if true.
Yes, or at least we need to vastly up our game. We do have a lead.
I am not convinced by the plan here, but I admit better plans are hard to find.
Now I’ll go statement by statement.
The probabilities here are not strongly held or precise, rather they are here because some idea of where one is at is far better than none. I am discounting scenarios where we face unrelated fast existential risks or civilizational collapse.
Category 1 on timelines, I see Leopold as highly optimistic about how quickly and reliably things will get to the point of going critical, then his timeline seems if anything slow to me.
Straight lines on graphs stay straight for a while longer: 85% that the left side y-axis holds up, so things like ‘compute invested’ and ‘log loss,’ until compute runs into physical constraints. It is not obvious how that translates to capabilities. On the question of’ ‘unhobbling’ I find the word and framing not so helpful, I do not think we should think of those abilities as ‘inside you all along,’ but I agree that additional scaffolding will help a lot, I’d give that 90%, but there are a lot of different values of ‘a lot.’
Straight lines translate to capabilities the way Leopold roughly expects, and the right side of the y-axis holds up as a translation: ~50% that this is in the ballpark sufficiently that the rest of the scenario follows. I get why he expects this, but I am not confident. This is one of the most important numbers, as the straight lines in #1 will likely otherwise ‘get there’ even if they bend, whereas this might not hold. Here, I would not be as confident, either in the result or in my number.
I cannot emphasize enough how much I notice I am confused and the extent to which this number is lightly held, despite its importance. I notice that my intuitions are contradictory and every answer sounds crazy.
A lot of that is very confident contradictory projections from different sources. Predictions are hard, especially about the future.
Note that this is conditional on #1 and isn’t a strict ‘by 2027.’
How likely do we actually get there by 2027? My Manifold market on the drop-in worker by end of 2027 is trading at 33%. There are a bunch of things that can go wrong here even if the first two points hold. End of 2027 is a short deadline. But is it ‘strikingly plausible’? I think yes, this is clearly strikingly plausible.
Would a drop-in remote worker capable of AI research lead to at least a soft takeoff and a world transformation if it happened? As constructed it seems hard for this to be false? There are various values of ‘slow’ but broadened to within a few years and for now setting aside possibilities like physical fights over compute or existential risks this seems like a 90% shot.
I basically buy this. Bottlenecks will probably slow things down. But if you disregard bottlenecks, the timeline Leopold presents is unreasonably slow. He is absolutely pricing in a lot of bottlenecks, this is a few years rather than a rather fascinating Tuesday. Again I’d be something like 90% that bottlenecks other than power do not hold things back for long.
I am not confident LLMs if scaled up get you the something good enough to fill this role or otherwise go critical. And I am certainly not so confident it happens this fast. But if they do offer that promise, the rest seems like it not only follows, but it seems like Leopold’s timelines from there are highly conservative.
Category 2 on alignment is where I think Leopold is most off base.
Yeah, no. This is not an ordinary engineering problem. It is a multidisciplinary, multistage, unforgiving, impossible-level problem that you have to solve on the first try. It is very hard. To be fair to Leopold, his ‘ordinary engineering problem’ still leaves room for it to be very hard. Perhaps I am philosophically confused here, and a lot of people think I’m wrong, and model uncertainty is a thing. So maybe 20%, if we take all of that and include that the engineering problem could still be very hard and this does not exclude other problems that could be considered distinct issues? Would of course be deeply happy to be wrong.
I can sort of see how you could end up thinking it is an ordinary engineering problem. But adding side constraints as a sufficient solution at ASI level, for a human understandable version of side constraints (rather than something complex designed by another ASI that is functionally quite different)? I’m going to go 5% because never say never, but no. Giving something much smarter than you particular constraints written in English the way Leopold is thinking here is not going to work.
Yes, more time and resources help, 99%+. Of course, my difficult is a lot bigger than his.
This is a talking price situation. I am 99%+ that having access to more capable (in-context not dangerous) systems and more compute help your efficiency. The question is how much, and to what extent you still need calendar time to make progress. Certainly if The Project had already begun and wanted to be efficient I would be spending budget on superalignment now, not holding back deployable capital. I would say something like 60% that, if a solution is findable, it requires time near the end you might or might not have. A key question is to what extent you can trust the AI researchers, once you get them, to do the alignment work. If this handoff could fully work then yeah, your job would largely be to get to the point you could do that. But I am deeply skeptical that you can use that to skip the hard parts of the problem.
For low values of very good chance and large values of available time, and with the right attitude, I think we have a decent shot to solve alignment. Or more accurately, I have high uncertainty, which translates to having a shot. One big problem is that (contrary to an unstated assumption in Leopold’s model) we do not know when we are about to create the existentially risky iteration of AI, and as critics of pauses point out the pause is a trick you probably only get to do once. So the real question is, if you enter with a large lead and very large resources, but without having solved alignment, are you able to both identify when, where and how you need to pause capabilities, and to use that time to solve the engineering parts of the problem? There are a wide range of answers here, I know people I respect who are <1%, and those who would say very high numbers. Again it feels like all the answers seem crazy, and I am warning everyone in advance that I’m not being consistent and you’re going to find arbitrages if you look, but if I had to pull out a number under relatively strong conditions with multiple years of bonus… 40%?
I do agree that if you have little time, and you don’t already have the answer (it is possible someone finds a solution before crunch time), you are unlikely to find it. So maybe this is 10%. I do think the margin of safety helps, but to get it you have to actually spend the extra time.
I think this is almost certainly true, something like 95%.
So that’s (100% minus epsilon) and the epsilon is I’m a coward. If you change very very bad to existential risk, it’s still in the 90%+ range.
This is another place I get confused. Why this confidence, and why think we could or would do it with normality? If we have indeed fully and properly solved alignment, then the good news is we can now ask these aligned ASIs to do our homework on how to handle what I call ‘phase two.’ If we enter with contained access to the ASIs while we figure that out, then I notice I do expect it to work out, maybe 75%, mostly because of that extra firepower, but I also worry about there being a solution space we can navigate towards. What is the chance this solution looks as close to our current institutional structures as Leopold is implying here? It depends on which version of his you go by. There are times on the podcast where I’d put his statements at ‘this would not actually make any sense but in theory with an ASI you can kind of do whatever’ and other times the idea was closer to simply some set of rules at all. So conditional on that 75%, I’d then range from 5% (we can be weird and stubborn I guess) to maybe (again, spitballing) 50% that we land on something recognizable as a rules-based system with voting on big questions, some form of rule of law and people otherwise having a lot of freedom in ways that might seem like they count?
Category 3 on power is an area I haven’t thought about until recently, and where I know relatively little. I mostly buy the arguments here. If you do want to speed ahead, you will need the power.
The $100 billion cluster seems rather baked in at the 90% level. The $1 trillion cluster is a lot less obvious on many levels, including profitability, feasibility and necessity. I don’t know that much, but by 2030 I’ll say 40%? Which turns out to be where the Manifold market was (42%).
This seems similar on the $100 billion, for the $1 trillion my guess is that the financial incentives are not the key barrier that often, so it depends how you define ‘I would spend $1 trillion for a cluster if I could be allowed to power it, but to actually be allowed would make that highly inefficient so I won’t.’ If that counts as a yes, I’d say maybe 60%? If no, then 30%, government intervention needed. Note that I haven’t looked into these questions much, so these are low info guesses. But I do expect we will have uses for a ton of compute.
I hadn’t been thinking about this until recently. But yeah, it does seem likely. There is always a tradeoff, but power effectively being a bottleneck seems like a consensus perspective at this point, something like 80%?
This seems like it is the same 80%. Important to notice which claims are correlated, and which are distinct.
I am persuaded, and will put this at 90% if you include allies.
Natural gas is a fact question. I have multiple sources who confirmed Leopold’s claims here, so I am 90% confident that if we wanted to do this with natural gas we could do that. I am 99%+ sure we need to get our permitting act together, and would even without AI as a consideration. I am also 99%+ sure that fission will help a lot if we have the time to build it before things go critical. Under Leopold’s timeline, we don’t. A key consideration is that if there is not time to build green energy including fission, and we must choose, then natural gas (IIUC) is superior to oil and obviously vastly superior to coal.
Again, this seems right, 90%.
Category 4 on cybersecurity I am pretty much in violent agreement with Leopold. He might be high on the value of current algorithmic improvements, and I worry he may be low on the value of current frontier models. But yeah. We need to fix this issue.
The labs have admitted that their security is inadequate. They are not trying to stop state actors. If you don’t try, you won’t succeed. So 95%, and most of the remaining probability here is ‘our security is actually secretly good, but we are under orders to keep it secret that our security is good.’
That seems mostly right, up until it changes. I still think knowing what you are doing, the tacit knowledge and experience you get along the way, matters a lot, as does figuring out what to do with the thing once you have it. So I’ll lower this to the 85% range on that basis.
This is basically #22 restated, but slightly lower.
This might not happen right away but if we are going down this style of path this seems obviously true to me, with a small chance AI defense can fix it. 90%. Of course, there are levels to what it means to ‘enable,’ it won’t become free.
Without knowing what the secrets are or how the technical details work, this is hard to assess. It seems highly correlated to the chance that current models do not need that many technique iterations to get to the finish line (e.g. you can do things like RL on LLMs), although it might be true without that. I notice my thinking here is rather muddled on what would count as fundamentally new. I’m going to give this a 45% chance (held even more lightly than usual) to be right, but of the worlds this model is otherwise describing, the probability is much higher.
Yes. We need to improve our cybersecurity now, 90%, with uncertainty for worlds in which there is secret information. If security is indeed what it looks like all around, jump this to 98%.
I have some model uncertainty. Perhaps being a startup or Google lets you ‘move fast and break things’ in order to make things more secure, and not being the government can be an advantage. It is not clear to me we are at the stage where the labs couldn’t defend if they wanted it enough, or where that would be all that expensive. So I’ll be conservative and say 85% on must assist, but 95% on insist.
The difficulty level ramping up seems inevitable in the 95% range. I don’t see how the situation now could be anywhere near the maximum. On being far behind, again, 95%.
I had to put this somewhere and this seemed like the best fit. I am 90%+ that models that have been released so far have been net beneficial in direct effects, including their use to train other models but ignoring the growth of habits and ecosystems that lead to more open weight releases. The key claim is that open weights models will be increasingly behind closed weights models. I do think that is the baseline scenario at this point, something like 70%, as compute costs rise. I will be actively surprised if Meta releases the weights to a world-size version of Llama-4. In those scenarios, there are misuse worries and I still worry about situations in which scaffolding evolves over time but scaling has stopped working, or something like that, but something like 75% that there’s not much that needs to be done. In the other 30% scenario where open models are not so far behind if left to their own devices? That gets tricker, and among other worries if we are in a true race we obviously cannot abide it.
Category 5 brings it all together. Centrally I am higher on potential cooperation, and much higher on alignment difficulty and the chance racing forward causes everyone to lose, and I also am more confident in our lead if it comes to that. I also have less faith that the authorities will wake up in time.
This is conditional on ASI being for real. If we assume that, then this follows. A few months will likely feel like an eternity. I don’t know at what point nuclear deterrents break, but there is presumably a point. I will be conservative to allow for extreme bottlenecks and say 90% for a few months being enough.
This too is conditional on ASI being real. And again, that is kind of what this means. If we get it, it is transformational. 95%+.
I am not convinced. I do not think Xi or the CCP wants to tile the universe with Maoist flags or torture chambers. I believe them to be normative, that they want good things rather than bad things. I know I would on every level much prefer to bet on the choices of America or a ‘free world’ coalition, or the decisions of the AI labs themselves, but how big is that gap compared to the the gap to alignment failure or an otherwise AI controlled future with little or nothing I value? Then again, value is fragile and I can imagine ways that world could have dramatically lower value. So I think something like 25% that the result would be actively dystopian for China’s future but not America’s, from my perspective.
America’s future being good depends on solving all the problems in the alignment section, and then choosing a setup that results in a good future. I do agree we could impose peace through strength. So if we assume we are in the good scenario from #14, then I am optimistic, something like 90%, but with some chance of a core values clash.
Maybe. I agree that as long as they can steal our insights and models, if they care sufficiently to do that they cannot effectively be that far behind. But mostly I do think we are pretty far ahead and doing far better at this, we are making and investing far more, and our country is much better suited to solving this problem. We will see how long we continue to be open books but I am only maybe 50% that China or another country ends up being a serious rival if we don’t actively choose to stop for years.
I do not expect either China or America to act reasonably regarding alignment. I can see cultural and geopolitical arguments that China is more likely to be reckless, or that it will be more reckless because it will be behind and desperate, but also America is often reckless, see The Doomsday Machine and also everything happening at OpenAI. Both Leopold and I think the current situation is incredibly bad, so what one calls ‘responsible’ will probably still be highly reckless by sane planet standards. I do think that primarily due to our potential for a large lead and association of many at some of the labs with a culture of safety and worrying about existential risk, we are more likely to take alignment more seriously, but I am only maybe 70% that we are the more responsible actors here, and only maybe a generous 30% that it is enough of a gap that it rises into plausibly ‘responsible’ territory in my eyes. Learning more about China could move that quickly.
All the evidence says neither side has woken up. But if they did wake up, perhaps they would try to keep it quiet, especially on our side? I mean, we are winning. If I was the shadow president there would be a good argument that you quietly shore up cybersecurity, try to get visibility and not do much else yet to avoid alerting our rivals. If I was China and I realized, same thing, I would consider trying to keep it down. So only 80%.
The same way I am not certain neither side has woken up yet, I am not convinced both of them will wake up in time either. I get that when the state does wake up it will react, but that could be very late in the game, especially if we are talking about the full extent of the situation. Some would say it is naive to expect the government not to realize the national security implications and step in. I would say, no, it is naive not to consider that governments might fail to notice, or the incentives might be to ignore the developing situation for a long time. National security gets rivalry with China or another country, but if the real threat is coming from the computers and inside the house, they really might utterly fail to grok. They might really be talking about great American capitalist competition until one day they wake up to a very different world. Again, remember Covid. I am at most 70% that both sides will get it in time if Leopold’s timelines are roughly correct, and worry that is foolishly high.
These labs sure are racing right now. Would they ever stop on their own? A lot depends, like for nations, on whether it was close, and what were the marginal incentives. A lot of pressure could be brought to bear, including from employees, and it is not impossible that some form of ‘merge and assist’ could happen, either formally or by the talent jumping ship. My gut answer is 80% they would race?
If Leopold’s timelines and other parts of the model are roughly correct, how often do we do The Project at least as nationalized as Leopold predicts? I mean yes, that is totally the least that I would do if I was tasked with national security in that situation, regardless of how I handled the risks. They still have to wake up in time and then get the authorization to act. I do agree with Leopold that some form of soft nationalization is more likely than not, maybe 70%. But I also am not convinced that it would do that much in terms of getting the government to truly call the shots, as opposed to integration of the results with what the government wants. Boeing from where I sit (I don’t know that much detail) has been systematically hollowed out and betrayed its mission, in a way that would never have been allowed if it was more effectively an arm of the government. If that’s all The Project ends up being, who will feel in charge?
Assuming things appear at all close or looks close (remember the missile gap?), my presumption is both governments will focus on winning more than existential risks or loss of control. It won’t be exclusive. But also there will be a lot of outside pressure about the downsides, and people do often notice the risks at some point. But I think at least 70% that both governments will take what I would think is a reckless approach. If you allow America to ‘choose its recklessness last’ based on what China is doing, then perhaps drop that to 50%. We might be backed into a corner at that point, but we might not. And of course there are levels to what counts as reckless.
There is a continuum, even now Anthropic and OpenAI are not ‘fully’ publishing their alignment work to preserve confidential information. I am 90%+ confident that we will not want to tighten up the rules on that any further any time soon.
I am far less hopeless on this, and worry such talk is a self-fulfilling prophecy. I do not think the game theory is as hopeless as Leopold believes, people can and do make situations work all the time that basic game theory says can’t work. There are various technical possibilities that might make the situation easier. A lack of full situational awareness could make things easier, or truly full awareness could as well. I think there’s only maybe a 60% chance that there is no good deal we could make. That goes up to 80% if you consider that it takes two to make a deal and we might well not know a good deal when we see one. America has a history of being offered very good win-win sweetheart deals and blowing them up in fits of pique like no one else. But that is exactly why we need to push to not do that.
I get the theory that breakout is too easy, but also really very large and expensive amounts of compute with large footprints are involved, and there are various ways to try and verify things? And advanced decision theories are a thing. I am not ready to give up. I think at least 50% that it could, in theory, be done, once the incentives become clear, without anyone being bamboozled. That doesn’t mean it happens.
What about considerations that are missing entirely?
Again, decision theory. If you are an FDT agent (you use functional decision theory) and you think other high stakes agents also plausibly use FDT including ASIs, then that changes many aspects of this.
Always start there.
Tamay Besiroglu: [Situational Awareness] presents a well-articulated case that by extrapolating current AI trends—rapidly increasing compute, consistent algorithmic efficiency gains, and techniques that unlock latent capabilities—we may develop “drop-in remote workers” by 2027.
I agree this is very plausible. I’m pleased to see the trends that I spent a lot of my time the last year researching being interpreted in the way that I have come to see them. The implications are profound and not widely priced in.
I expected my p(drop-in remote workers by 2027) would be substantially lower than Aschenbrenner’s, but we did compare notes, and we are not that far apart.
The most obvious reason for skepticism of the impact that would cause follows.
David Manheim: I do think that Leopold is underrating how slow much of the economy will be to adopt this. (And so I expect there to be huge waves of bankruptcies of firms that are displaced / adapted slowly, and resulting concentration of power- but also some delay as assets change hands.)
I do not think Leopold is making that mistake. I think Leopold is saying a combination of the remote worker being a seamless integration, and also not much caring about how fast most businesses adapt to it. As long as the AI labs (and those in their supply chains?) are using the drop-in workers, who else does so mostly does not matter. The local grocery store refusing to cut its operational costs won’t much postpone the singularity.
James Payor: Insofar as Leopold is basically naming the OpenAI/Microsoft/Anthropic playbook, I am glad to have that in the public record.
I do not trust that Leopold is honest about his intentions and whatnot, and this is visible in the writing imo.
I think parts of this are the lab playbook, especially the tech section, alas also largely the alignment section. Other parts are things those companies would prefer to avoid.
Perhaps I am overly naive on this one, but I do not think Leopold is being dishonest. I think the central model of the future here is what he expects, and he is advocating for what he thinks would be good. It is of course also rhetoric, designed to be convincing to certain people especially in national security. So it uses language they can understand. And of course he is raising funding, so he wants to excite investors. The places things seem odd and discordant are around all the talk of patriotism and the Constitution and separation of powers and such, which seems to be rather laid on thick, and in the level of expressed confidence at several other points.
Would an edge in ASI truly give decisive strategic advantage in a war? As Sam Harsimony notes here before arguing against it, that is load bearing. Harsimony thinks others will be able to catch up quickly, rather than the lead growing stronger, and that even a few years is not enough time to build the necessary stuff for a big edge, and that disabling nukes in time is a pipe dream.
I am with Leopold on this one. Unless the weights get stolen, I do not think ‘catching up’ will be the order of the day, and the effective lead will get longer not shorter over time. And I think that with that lead and true ASI, yes, you will not need that much time building physical stuff to have a decisive edge. And yes, I would expect that reliably disabling or defending against nukes will be an option, even if I cannot detail exactly how.
Eliezer linked back to this after someone asked if Eliezer Yudkowsky disliked Aschenbrenner.
Eliezer Yudkowsky (April 12, 2024): Leopold Aschenbrenner, recently fired from OpenAI allegedly for leaking, was (on my understanding) a political opponent of MIRI and myself, within EA and within his role at the former FTX Foundation. (In case anybody trying to make hay cares in the slightest about what’s true.)
I do not have reason to believe, and did not mean to imply, that he was doing anything shady. If he thought himself wiser than us and to know better than our proposals, that was his job. He’s simply not of my people.
I do not have sufficiently tight monitoring on my political opponents to know exactly how hard he was shooting down MIRI proposals in a management capacity. I have reason to believe it wasn’t zero.
At the time, OpenAI had fired Leopold saying it was for leaking information, and people were trying to blame Yudkowsky by proxy, and saying ‘never hire alignment people, they cannot be trusted.’ The principle seems to be: Blame everything anyone vaguely safety-related does wrong on AI safety in general and often Eliezer Yudkowsky in particular.
That was always absurd, even before we learned how flimsy the ‘leak’ claim was.
It is easy to see, reading Situational Awareness, why Aschenbrenner was not optimistic about MIRI and Yudkowsky’s ideas, or the things they would want funded. These are two diametrically opposed strategies. Both world models have a lot in common, but both think the other’s useful things are not so useful and the counterproductive actions could be quite bad.
Rob Bensinger: Relaying after chatting with Eliezer Yudkowsky:
Eliezer acknowledges that Leopold Aschenbrenner says he didn’t leak OpenAI’s secrets after all.
Given the “consistent candor” issue with a bunch of OpenAI’s recent statements, Eliezer considers this a sizeable update toward “Leopold didn’t do anything majorly wrong at OpenAI” (as do I), at least until we hear more details about what he supposedly did.
As I note above, I would use stronger language, and am more confident that Leopold did not break confidentiality in a meaningful way.
Rob Bensinger: Also, Eliezer’s tweet here was a bit cryptic and prompted some MIRI-cluster people to ask him what he meant by “political opponent”. I thought it would be helpful to relay what concretely happened, after asking about the details.
According to Eliezer, he and Leopold had a conversation where “Leopold asked me if I updated on timelines at all because of my supposed peer group (aka: his friends at OpenPhil) having long timelines, I was like ‘nope'”, and Leopold responded (from Eliezer’s perspective) with a strong disgust reaction. (The topic of the discussion was Eliezer having shorter median AGI timelines than e.g. Open Phil did. Since then, Ajeya Cotra of Open Phil has reported much shorter timelines, and seemingly so has Leopold; and Eliezer had detailed disagreements with Ajeya’s and other Open-Phil-cluster folks’ approach to forecasting AGI. So I don’t think it was a reasonable move to write off Eliezer for being insufficiently deferential to this social cluster.)
How ironic that the shoe is now on the other foot, Mr. Bond.
Or is it?
From an outside perspective, Leopold is making extraordinary claims. One could ask how much he is updating based on others often having very different views, or why he is substituting his judgment and model rather than being modest.
From an insider perspective, perhaps Leopold is simply reflecting the consensus perspective at the major labs. We should have long ago stopped acting surprised when yet another OpenAI employee says that AGI is coming in the late 2020s. So perhaps that part is Leopold ‘feeling the feeling the AGI’ and the faith in straight lines on curves. If you read how he writes about this, he does not sound like a person thinking he is making a bold claim.
Indeed, that is the thesis of situational awareness, that there is a group of a few hundred people who get it, and everyone else is about to get blindsided and their opinions should be discounted.
There was a clear philosophical disagreement on things like decision theory and also strong disagreements on strategy, as mentioned above.
As a consequence of all this, when Eliezer saw news reports that Leopold had leaked OpenAI secrets, and saw people on Twitter immediately drawing the conclusion “don’t hire alignment guys, they’ll screw you,” he felt it was important to publicly state that Leopold wasn’t a MIRI affiliate and that, right or wrong, Leopold’s actions shouldn’t be to MIRI’s credit or discredit one way or another; Leopold is his own person. (Hopefully, this makes it less mysterious what the nature of the Eliezer/Leopold disagreement was.)
I remember that situation, and yeah this seemed like a wise thing to say at the time.
Many questioned Leopold’s metaphor of using childhood development as a stand-in for levels of intelligence.
I think Leopold’s predictions on effective capabilities could prove right, but that the metaphor was poor, and intelligence does need to be better defined.
For example:
Ate-a-Pi: I feel like these definitions and measures of intelligence are so so muddy. “High schooler”, “vastly superhuman” etc.
Like one way I feel you can measure is, at what point will
A) an AI match the performance of the best performing hedge fund run by humans: Medallion Fund ie 62% over 30 years, ie 6x the long term market return of 10%
B) an AI be a more efficient allocator of global resources than the market economy ie the end of capitalism as we know it.
These are both concrete ways of measuring what an AI can actually do, and a way to measure intelligence beyond the constraints of human metrics like IQ. They both require constant adaptation to changing conditions.
Notably both involve humans aggregating the preferences, opinions and intelligence to produce outcomes greater than what a single human can produce.
Ate-a-Pi offers more in depth thoughts here. Doubts the scaling parts but considers plausible, thinks cost will slow things down, that not everyone wants the tech, that China is only 15 months behind and will not dare actually try that hard to steal our secrets, and might clamp down on AI rather than race to defend CCP supremacy.
Or here:
Kerry Vaughan-Rowe: Among the other problems with the graph, GPT-4 isn’t really comparable with a smart high schooler.
It’s much better at some tasks, comparable at others, and extremely bad at some important things.
The areas where it fails include tasks associated with reasoning and planning. This is why attempts at creating “AI agents” using GPT-4 have accomplished nothing, despite how good GPT-4 is.
The question is whether GPT-4’s extreme deficiencies can be solved with a straightforward application of additional compute. I can respect a wide variety of perspectives on that question.
But I have trouble respecting the perspective that the answer is as obvious as believing in straight lines on a graph.
Leopold notes that he addresses this in the piece.
I still maintain that the initial tweet was an attempt to significantly oversimplify the situation, but he is, of course, not blind to the complexity himself.
Rob Bensinger: Yep. I don’t even disagree with the conclusion, “AGI by 2027 is strikingly plausible”; but an invalid argument is an invalid argument.
Or:
Emmett Shear: I agree with your trend line, in that we will likely have a 5, 6, 7 … that continue the trend. The right y-axis however, is assuming the conclusion. In no way is GPT-4 is equiv to a smart highschooler, or even that GPT-3 is elementary or GPT-2 preschool.
They all have massively *morecrystalized (canalized) intelligence than even highschoolers (and increasing amounts of it), and way *lessfluid intelligence (g, IQ) than even the preschooler.
Dean Ball: No definition of intelligence! Is it really right to call GPT-4 a “high schooler”? It’s way above that in some ways, way below in others. Not clear taking the average is a particularly rigorous intellectual approach, and the argument (part 1 at least) hinges on this approach.
Oliver Habryka: I strongly disagree with some of the conclusions of this post (racing against China on AGI seems like one of the literally worst things someone could try to achieve), but a lot of the analysis is quite good.
I also disagree with a bunch of the “just count the OOMs” vibe, in that I think it conveys far too much confidence about the distribution of intelligence and leans too hard on human analogies for intelligence, but the detailed reasoning is pretty decent.
I think the “It really looks like we are going to be very drastically ramping up investment in AGI development in the next few years and scaling laws suggests this will indeed continue to substantially increase in intelligence” part is quite good.
Seriously. Super hard. Way harder than Leopold thinks.
Leopold knows that alignment is difficult in some ways, but far from the complete set of ways and magnitudes that alignment is difficult.
Indeed, it is great that Leopold recognizes that his position is incredibly bullish on alignment techniques, and that he is taking a bold position saying that, rather than denying that there is a very difficult problem.
I am not attempting here to argue the case that alignment is super difficult and go all List of Lethalities, the same way that Leopold offered a sketch but did not offer an extensive argument for why we should be bullish on his alignment techniques.
One exception is I will plant the flag that I do not believe in the most important cases for AGI that evaluation is easier than generation. Aaron Scher here offers an argument that this is untrue for papers. I also think it is true for outputs generally, in part because your evaluation needs to be not boolean but bespoke.
Another is I will point to the decision theory issues I raised earlier.
Beyond that, I am only listing responses that were explicitly aimed at Leopold.
Former OpenAI colleague of Leopold’s Richard Ngo outlines one failure scenario, listed because he wrote this as a deliberate response to Leopold rather than because I believe it is the strongest case.
An AGI develops a second misaligned persona during training, similar to Sydney.
Being an AGI, when that personality does surface it realizes not to reveal itself during training.
Then the AGI is put to work in internal development to write better code, similar to Leopold’s ‘drop in AI researcher.’ The incentives for gaining control are obvious.
Once the AGI gains access to the lab’s servers, many options are available.
We might have no idea what is happening as it is deployed everywhere.
Jules Robins: A crux for us expecting different things is his belief that RLHFish techniques will scale to AGI (though we agree they won’t go to ASI). Humans get similar reinforcement, but often act immorally when they think they can get away with it & we’ve already seen the models do the same.
Steve’s response at ‘Am I Stronger Yet?’ affirms that if you buy the premises, you should largely buy the conclusion, but emphasizes how difficult alignment seems in this type of scenario, and also does not buy anything like the 2030 timeline.
Similar to alignment, I do not share Leopold’s timeline assessments, although here I have much higher uncertainty. I have no right to be shocked if Leopold is right.
No, no, say the people, even if you buy the premise the calculations are all wrong!
Leopold Aschenbrenner: AGI by 2027 is strikingly plausible.
That doesn’t require believing in sci-fi; it just requires believing in straight lines on a graph.
Davidad: The dashed line seems to ignore, or even reverse, the negative 2nd derivative of the trend (as LLMs saturated AI-at-scale mindshare).
Using EpochAIResearch’s estimates (4.1× annual compute growth ⋅ 3× annual algo improvements) yields a much more reasonable forecast of 2028Q2.
I am, of course, joking about 2027Q4 vs 2028Q2 being a significant difference. I agree with Leopold that 2027Q4 is plausible. I think 2028 is even more plausible, 2029Q3 is *mostplausible (my modal timeline pictured below), and 2031Q2 is my median.
Sometimes people are shocked simply that I am thinking about this in quarters. If your timelines are in this ballpark, and you’re the sort of person who prefers percentages to “a scale from 1 to 10”, you probably should be too! But indeed, most don’t seem to be, yet.
Eliezer Yudkowsky [referring to Leopold’s graph above]: AGI by 2027 is plausible… because we are too ignorant to rule it out… because we have no idea what the distance is to human-level research on this graph’s y-axis. “Believe in straight lines on a graph” does not seem like a valid summary of this state of knowledge.
I don’t think you picked up on the problem here. It’s not with the graph being a straight line. It’s with the labels on the right side of the y-axis.
For purposes of this graph, [AGI is] human-level automated AI research, which one might expect to be followed by the end of the world not very long after.
Bogdan Ionut Cirstea: Wishing more AI safety research agendas (and especially funders) took this potential timeline seriously
jskf: What would that look like concretely?
Bogdon Ionut Cirstea: (among other) AI safety funders should probably spend faster and be (much) less risk adverse; many more AI risk – oriented people should think about automated AI safety R&D.
Trevor Levin: Interested in concrete things to spend on/what being less risk averse would look like.
Bogdan Ionut Cirstea: Examples of some things which seem pretty scalable to me, even taking into account other bottlenecks like mentorship (I don’t really buy that there’s a talent bottleneck): independent research (if the researchers don’t need mentorship), field-building (e.g. to potentially help bring in more [independent] researchers), plausibly some parts automated AI safety research (e.g. automated interpretability, large SAE training runs)
Training programs like MATS, ARENA, etc. probably also have a lot of room to scale up / be duplicated, both in mentors and in applicants, especially given the n_applicants / mentor numbers I’ve heard (and the very low n_mentees / new mentor I’ve heard of).
Simeon: Indeed, I remember being shocked by how long his timelines were mid 2022.
Davidad: As far as I’m concerned, anyone whose views about AI risks and timelines shifted massively over the course of the year beginning on 2022-11-28 gets a free pass. Safe harbour exemption. 2023 was a change-your-mind-about-AI jubilee year.
I strongly agree that we should not penalize those who radically change their minds about AI and especially about AI timelines. I would extend this beyond 2023.
It still matters how and why someone made the previous mistakes, but mostly I am happy to accept ‘I had much worse information, I thought about the situation in the wrong ways, and I was wrong.’ In general, these questions are complex, they depend on many things, there are conflicting intuitions and comparisons, and it is all very difficult to face and grapple with. So yeah, basically free pass, and I mostly would continue that pass to this day.
The report also contained a view that doom avoidance only requires a fixed set of things going wrong. He no longer endorses that, but I find it important to offer a periodic reminder that my view of that is very different:
By construction, in these scenarios, we bring into existence large numbers of highly capable and intelligent systems, that are more efficient and competitive than humans. Those systems ending up with an increasing percentage of the resources and power and then in full control is the default outcome, the ‘natural’ outcome, the one requiring intervention to prevent. Solving alignment in the way that term is typically used would not be sufficient to change this.
Remarkable number of people in the replies here who think the way to deal with CCP stealing our secrets is to give away our secrets before they can be stolen? That’ll show them. Also others who do not feel the AGI, or warning that stoking such fears is inherently bad. A reminder that Twitter is not real life.
Similarly, here is Ritwik Gupta praising Leopold’s paper but then explaining that innovation does not happen in secret, true innovation happens in the open, to keep us competitive with the people who are currently way behind our closed models that are developed in (poorly kept from our enemies) secret it is vital that we instead keep development open and then deploy open models. Which the CCP can then copy. As usual, openness equals good is the assumption.
If you want to argue ‘open models and open sharing of ideas promotes faster development and wider deployment of powerful and highly useful AI’ then yes, it absolutely does that.
If you want to argue that matters and we should not be worried about rogue actors or beating China, then yes, that is also a position one can argue.
If you want to argue ‘open models and open sharing of ideas are how we beat China,’ as suddenly I see many saying, then I notice I am confused as to why this is not Obvious Nonsense.
A key obviously true and important point from Leopold is that cybersecurity and other information security at American AI labs is horribly inadequate given the value of their secrets. We need to be investing dramatically more in information security and cybersecurity, ideally with the help of government expertise.
This seems so transparently, obviously true to me.
The counterarguments are essentially of the form ‘I do not want that to be true.’
OpenAI told Leopold that concerns about CCP espionage were ‘racist.’ This is Obvious Nonsense and we should not fall for it, nor do I think the admonishment was genuine. Yes, spying is a thing, countries spy on each other all the time, and we should focus most on our biggest and most relevant rivals. Which here means China, then Russia, then minor states with little to lose.
One can worry about espionage without gearing up for an all-out race or war.
Kelsey Piper: “It’s racist to worry about CCP espionage” seems outrageous to me but so does “we should start an AI arms race because otherwise the other guys will win it”.
What about “we should be honest about our enormous uncertainty and the wide range of outcomes on the table, and run labs with a strong internal safety culture while working hard internationally to avoid a second Cold War or an arms race”?
For an outside example, in addition to many of the comments referred to in the previous section, Mr. Dee here speaks out against ‘this fear mongering,’ and talks of researchers from abroad who want to work on AI in America, suggesting national security should be ‘vetted at the chip distribution level’ rather than ‘targeting passionate researchers.’
This does not address the question of whether the Chinese are indeed posed to steal all the secrets from the labs. If so, and I think that it is so, then that seems bad. We should try and prevent that.
Obviously we should not try and prevent that by banning foreigners from working at the labs. Certainly not those from our allies. How would that help? How would that be something one would even consider anywhere near current security levels?
But also, if this was indeed an existential race for the future, let us think back to the last time we had one of those. Remember when Sir Ian Jacob, Churchill’s military secretary, said we won WW2 because ‘our German scientists were better?’ Or that Leopold proposes working closely with our allies on this?
Patrick McKenzie: I cannot possibly underline this paragraph enough.
Leopold Aschenbrenner: But the scariest realization is that there is no crack team coming to handle this. As a kid you have this glorified view of the world, that when things get real there are the heroic scientists, the uber- competent military men, the calm leaders who are on it, who will save the day. It is not so. The world is incredibly small; when the facade comes off, it’s usually just a few folks behind the scenes who are the live players, who are desperately trying to keep things from falling apart.
Patrick McKenzie: We, for all possible values of “we”, are going to need to step up.
I also liked the line about “people with situational awareness have a lower cost basis in Nvidia than you do” and while I own no Nvidia I think this is a more persuasive investment memory than many I’ve seen in my life.
Are there other live players who do not care about whether the world falls apart, and are out to grab the loot (in various senses) while they can? A few, but in the relevant senses here they do not count.
Ori Nagel: Don’t read Leopold Aschenbrenner’s 165-page treatise on AI if you hate glaring plot holes.
It is worth noting again that Lepold’s position is not all gung ho build it as fast as possible.
Rob Bensinger: My take on Leopold Aschenbrenner’s new report: I think Leopold gets it right on a bunch of important counts. Three that I especially care about:
Full AGI and ASI soon. (I think his arguments for this have a lot of holes, but he gets the basic point that superintelligence looks 5 or 15 years off rather than 50+.)
This technology is an overwhelmingly huge deal, and if we play our cards wrong we’re all dead.
Current developers are indeed fundamentally unserious about the core risks, and need to make IP security and closure a top priority.
I especially appreciate that the report seems to get it when it comes to our basic strategic situation: it gets that we may only be a few years away from a truly world-threatening technology, and it speaks very candidly about the implications of this, rather than soft-pedaling it to the degree that public writings on this topic almost always do. I think that’s a valuable contribution all on its own.
Crucially, however, I think Leopold Aschenbrenner gets the wrong answer on the question “is alignment tractable?”. That is: OK, we’re on track to build vastly smarter-than-human AI systems in the next decade or two. How realistic is it to think that we can control such systems?
Leopold acknowledges that we currently only have guesswork and half-baked ideas on the technical side, that this field is extremely young, that many aspects of the problem look impossibly difficult (see attached image), and that there’s a strong chance of this research operation getting us all killed. “To be clear, given the stakes, I think ‘muddling through’ is in some sense a terrible plan. But it might be all we’ve got.” Controllable superintelligent AI is a far more speculative idea at this point than superintelligent AI itself.
I think this report is drastically mischaracterizing the situation. ‘This is an awesome exciting technology, let’s race to build it so we can reap the benefits and triumph over our enemies’ is an appealing narrative, but it requires the facts on the ground to shake out very differently than how the field’s trajectory currently looks.
The more normal outcome, if the field continues as it has been, is: if anyone builds it, everyone dies.
Right. That. Rob Bensinger’s model and Leopold Aschenbrenner’s model are similar in many other ways, but (at least in relative terms, and relative to my assessment as well) Leopold dramatically downplays the difficulty of alignment and dealing with related risks, and the likely results.
This is not a national security issue of the form ‘exciting new tech that can give a country an economic or military advantage’; it’s a national security issue of the form ‘we’ve found a way to build a doomsday device, and as soon as anyone starts building it the clock is ticking on how long before they make a fatal error and take themselves out, and take the rest of the world out with them’.
Someday superintelligence could indeed become more than a doomsday device, but that’s the sort of thing that looks like a realistic prospect if ASI is 50 or 150 years away and we fundamentally know what we’re doing on a technical level — not if it’s more like 5 or 15 years away, as Leopold and I agree.
The field is not ready, and it’s not going to suddenly become ready tomorrow. We need urgent and decisive action, but to indefinitely globally halt progress toward this technology that threatens our lives and our children’s lives, not to accelerate ourselves straight off a cliff.
Concretely, the kinds of steps we need to see ASAP from the USG are:
Spearhead an international alliance to prohibit the development of smarter-than-human AI until we’re in a radically different position. The three top-cited scientists in AI (Hinton, Bengio, and Sutskever) and the three leading labs (Anthropic, OpenAI, and DeepMind) have all publicly stated that this technology’s trajectory poses a serious risk of causing human extinction (in the CAIS statement). It is absurd on its face to let any private company or nation unilaterally impose such a risk on the world; rather than twiddling our thumbs, we should act.
Insofar as some key stakeholders aren’t convinced that we need to shut this down at the international level immediately, a sane first step would be to restrict frontier AI development to a limited number of compute clusters, and place those clusters under a uniform monitoring regime to forbid catastrophically dangerous uses. Offer symmetrical treatment to signatory countries, and do not permit exceptions for any governments. The idea here isn’t to centralize AGI development at the national or international level, but rather to make it possible at all to shut down development at the international level once enough stakeholders recognize that moving forward would result in self-destruction. In advance of a decision to shut down, it may be that anyone is able to rent H100s from one of the few central clusters, and then freely set up a local instance of a free model and fine-tune it; but we retain the ability to change course, rather than just resigning ourselves to death in any scenario where ASI alignment isn’t feasible.
Rapid action is called for, but it needs to be based on the realities of our situation, rather than trying to force AGI into the old playbook of far less dangerous technologies. The fact that we can build something doesn’t mean that we ought to, nor does it mean that the international order is helpless to intervene.
Greg Colbourn: Or, y’know, we could have a global non-proliferation treaty, starting with a bilateral treaty between the US and the CCP.
Interesting that the “situational awareness” referred to is that of the humans, when what’s much more important from the perspective of our survival is that of the AIs – it’s a key part of why we are likely doomed.
This looks like a great argument for just shutting it the fuck down. I don’t know why Leopold is so optimistic that “superalignment” will pan out.
Another great argument for just shutting it the fuck down (I don’t know how optimistic Richard is about solving the problem he’s described, but I’d want at least 99% confidence before charging ahead with further AGI development in light of this) [he links to Richard Ngo’s thread, which is earlier]
…
It doesn’t matter if the weights are leaked and AI Safety is rushed in 1-2 months rather than 12 months. We’re still all dead given superintelligence is fundamentally uncontrollable.
Leopold Aschenbrenners series of essays is a fascinating read: there is a ton of locally valid observations and arguments. Lot of the content is the type of stuff mostly discussed in private. Many of the high-level observations are correct.
At the same time, my overall impression is the set of maps sketched pulls toward existential catastrophe, and this is true not only for the ‘this is how things can go wrong’ part, but also for the ‘this is how we solve things’ part.
Leopold is likely aware of the this angle of criticism, and deflects it with ‘this is just realism’ and ‘I don’t wish things were like this, but they most likely are’. I basically don’t buy that claim.
Richard Ngo: A reckless China-US race is far less inevitable than Leopold portrayed in his situational awareness report. We’re not yet in a second Cold War, and as things get crazier and leaders get more stressed, a “we’re all riding the same tiger” mentality becomes plausible.
Leopold says very clearly that this transition is super scary. He wants to do it anyway, because he sees no better alternatives.
Rob’s argument is that Leopold’s proposal is not practical and almost certainly fails. We cannot solve alignment, not with that attitude and level of time and resource allocation. Rob would say that Leopold talks of the need for ‘a margin of safety’ but the margins he seeks are the wrong OOM (order of magnitude) to get the job done. Cooperation may be unlikely, but at least there is some chance.
Leopold’s response to such arguments is that Rob’s proposal, or anything like it, is not practical, and almost certainly fails. There is no way to get an agreement on it or implement it. If it was implemented, it would be an unstable equilibrium. He repeatedly says China will never be willing to play it safe. Whereas by gaining a clear insurmountable lead, America can gain a margin of safety and that is probably enough. It is super scary, but it will probably be fine.
Any third option would need to prevent unsafe ASI from being built, which means either no ASIs or find a way to safely build ASI and either prevent others from building unsafe ASIs or stay far enough ahead of them that you can otherwise defend. That means either find a solution quickly, or ensure you have the time to find one slowly.
We also should be concerned that if we do get into a race, that race could turn hot. Leopold very much acknowledges this.
Leopold (from SA): If we’re lucky, we’ll be in an all-out race with the CCP; if we’re unlucky, an all-out war.
Jeffrey Ladish: Worth talking about first strike incentives, and why countries might want to coordinate to avoid a scenario where nuclear powers bomb the data centers of any country as soon as intel determines them to be capable of RSI [recursive self-improvement.]
Of course we don’t know if countries would actually do this, but they might, and seems important to consider in the geopolitical calculus.
The ‘good’ news here is the uncertainty. You do not know when someone else is close to getting to AGI, ASI or RSI, and all of those progressions are gradual. There is never a clear ‘now or never’ moment. My presumption is this is sufficient to keep the battle cold and conventional most of the time. But perhaps not, especially around Taiwan.
The biggest risk in Leopold’s approach, including his decision to write the paper, is that it is a CDT (causal decision theory)-infused approach that could wake up all sides and make cooperation harder, and thus risks causing the very crisis it predicts and wants to prevent.
Sam Harsimony: Framing AI research as a zero-sum competition is quite bad. All nations and people can mutually prosper from new technology!
Pushing the discourse towards fixed-pie thinking can diminish these gains.
Imagine how much worse the world would be if we started a “solar arms race”. There would be less trade, more conflict, less innovation, and less clean energy. We shouldn’t do that with AI!
Worse, rhetoric about AI races can become a self-fulfilling prophecy. The U.S. and China are not in a zero-sum race right now, and it would be bad if that happened.
See “Debunking the AI arms-race theory” by Scharre.
Aschenbrenner can’t claim that the publication won’t affect the discourse much. He’s a popular member of an influential subgroup within AI. If the CCP has any competence, they’ll read the piece.
Bogdan Ionut Cirstea: I wish he had framed the governance side closer to something like [Drexler’s talk here about how to divide a large surplus] (or at least focused more on that aspect, especially in the longer run), instead of the strong competitive angle.
Leopold does look forward to abundance and pricing galaxies, especially on the podcast, but doesn’t talk much about those problems presumably because they seem solvable once we come to them, especially with ASI help.
Aaron Bergman: Almost definitely not original but I have a sense that EAish people have too strong an immune reaction to the nationalist vibe-associating international (geo-) political conflict stuff.
Which is extremely understandable and IMO basically too much of a good thing.
But like ex ante it’s totally possible (and I think true, tentatively) that “CCP cannot win AGI race” checks out from an impartial moral perspective.
We may wind up with only bad options.
Pointing out something unacceptable about a proposed approach does not mean there is a better one. You have to find the better one. One that sounds good, that adheres to what are otherwise your principles, only works if it would actually work. I have not heard a solution proposed that does not involve solving impossible-level problems, or that does not involve large sacrifices or compromises.
If all potential outlooks are grim, one must choose whichever is least grim. I do not expect to get 99% confidence, nor do I think we can wait for that. If I thought the alignment and internal ASI dynamics issues in Leopold’s plan were 90% to work, I would be thrilled to take that, and I’d settle for substantially less. That is what realism requires. All the options are bad.
I am more optimistic about cooperative methods than Leopold, and more skeptical about the difficulty alignment and what related problems must be solved in order to get through this.
A sufficiently strong change in either or both of these would be a crux. I am confident that ‘it will probably be fine’ is not the right attitude for going forward, but I am open to being convinced (if this scenario is coming to pass) that it could become our least bad option.
What happens if we are in this scenario except that Leopold and Rob are both right that the other’s solution is impractical? And there is no middle path or third option that is practical instead? Then we probably all die, no matter what path we attempt.
Sabine Hossenfelder (Physicist): Just finished reading Aschenbrenner’s manifesto (165p) about the impending intelligence explosion. I’m now rethinking my life plans. (Summary to follow on YT)
Her timeline then seems to return to normal. But yes, responding to this by rethinking one’s life plan is a highly reasonable response if the information or reasoning was new to you and you buy the core arguments about the technology. Or even if you buy that they might be right, rather than definitely are right.
Will Bryk: This is writing that reorients worldviews. Super insightful, convincing, critically needed, read like a thriller.
The clusters that will run AGI in 2027 are currently being assembled.
American AI labs will become nationalized. China will steal secrets. An arms race will begin. The entity that wins will determine humanity’s long future. And it all comes down to the next 1000 days.
“it’s starting to feel real, very real.”
Leopold’s is just one potential unfolding, but a strikingly plausible one. Reading it feels like getting early access to Szilard’s letter in 1939.
What about the fact that people pretty much everywhere would vote no on all this?
Geoffrey Miller: If all 8 billion humans could vote on whether we should build machine intelligences smarter and faster than any human, how does Leopold imagine they would vote?
And if he thinks we’d mostly vote ‘no’, what gives the AI industry the right to proceed with AGI/ASI development?
We have very strong evidence that people would vote no. If you educated them they would still vote no. Sure, if you knew and could prove glorious future, maybe then they would vote yes, but you can’t know or prove that.
The standard answer is that new technology does not require a vote. If it did, we would not have our civilization. Indeed, consider the times we let the people veto things like nuclear power, and how much damage that did. The flip side is if we never put any restrictions on technologies, that is another scenario where we would not have our civilization. When the consequences and negative externalities get large enough, things change.
The better answer is ‘what do you mean the right?’ That is especially true in the context of a view that due to rivals like China, where people most definitely do not get a vote, development cannot be stopped. It does not matter what ‘the people’ want without a way for those people to get it.
We should absolutely choose and attempt to elect candidates that reflect our desire to not have anyone create superintelligence until we are ready, and convince our government to take a similar position. But we may or may not have a practical choice.
There will always be bad takes, here’s a fun pure one.
Agus: the sheer audacity lmao [quoting the exchange below].
Grady Booch: There are so many things just profoundly, embarrassingly, staggeringly wrong about this paper by Leopold Aschenbrenner that I just don’t know where to begin.
Eric Schmidt: So you’d be willing to bet money on some part of it being wrong and give me odds?
Grady Booch: I don’t make bets with suckers who I know will lose their money.
Eric Schmidt: I’m a multimillionaire; it’s totally fine if I lose some money. Still refuse to bet?
Grady clarifies elsewhere that his primary objection is the timeline and characterization of AI capabilities, which is a fine place to object. But you have to actually say what is wrong and offer reasons.
Getting a 4.18 means that a majority of your grades were A+, and that is if every grade was no worse than an A. I got plenty of As, but I got maybe one A+. They do not happen by accident. The attitude to go that far class after class, that consistently, boggles my mind.