Enlarge/ Still from a Chinese social media video featuring two people imitating imperfect AI-generated video outputs.
It’s no secret that despite significant investment from companies like OpenAI and Runway, AI-generated videos still struggle to achieve convincing realism at times. Some of the most amusing fails end up on social media, which has led to a new response trend on Chinese social media platforms TikTok and Bilibili where users create videos that mock the imperfections of AI-generated content. The trend has since spread to X (formerly Twitter) in the US, where users have been sharing the humorous parodies.
In particular, the videos seem to parody image synthesis videos where subjects seamlessly morph into other people or objects in unexpected and physically impossible ways. Chinese social media replicate these unusual visual non-sequiturs without special effects by positioning their bodies in unusual ways as new and unexpected objects appear on-camera from out of frame.
This exaggerated mimicry has struck a chord with viewers on X, who find the parodies entertaining. User @theGioM shared one video, seen above. “This is high-level performance arts,” wrote one X user. “art is imitating life imitating ai, almost shedded a tear.” Another commented, “I feel like it still needs a motorcycle the turns into a speedboat and takes off into the sky. Other than that, excellent work.”
An example Chinese social media video featuring two people imitating imperfect AI-generated video outputs.
While these parodies poke fun at current limitations, tech companies are actively attempting to overcome them with more training data (examples analyzed by AI models that teach them how to create videos) and computational training time. OpenAI unveiled Sora in February, capable of creating realistic scenes if they closely match examples found in training data. Runway’s Gen-3 Alpha suffers a similar fate: It can create brief clips of convincing video within a narrow set of constraints. This means that generated videos of situations outside the dataset often end up hilariously weird.
An AI-generated video that features impossibly-morphing people and animals. Social media users are imitating this style.
It’s worth noting that actor Will Smith beat Chinese social media users to this trend in February by poking fun at a horrific 2023 viral AI-generated video that attempted to depict him eating spaghetti. That may also bring back memories of other amusing video synthesis failures, such as May 2023’s AI-generated beer commercial, created using Runway’s earlier Gen-2 model.
An example Chinese social media video featuring two people imitating imperfect AI-generated video outputs.
While imitating imperfect AI videos may seem strange to some, people regularly make money pretending to be NPCs (non-player characters—a term for computer-controlled video game characters) on TikTok.
For anyone alive during the 1980s, witnessing this fast-changing and often bizarre new media world can cause some cognitive whiplash, but the world is a weird place full of wonders beyond the imagination. “There are more things in Heaven and Earth, Horatio, than are dreamt of in your philosophy,” as Hamlet once famously said. “Including people pretending to be video game characters and flawed video synthesis outputs.”
Over the past week, OpenAI experienced a significant leadership shake-up as three key figures announced major changes. Greg Brockman, the company’s president and co-founder, is taking an extended sabbatical until the end of the year, while another co-founder, John Schulman, permanently departed for rival Anthropic. Peter Deng, VP of Consumer Product, has also left the ChatGPT maker.
In a post on X, Brockman wrote, “I’m taking a sabbatical through end of year. First time to relax since co-founding OpenAI 9 years ago. The mission is far from complete; we still have a safe AGI to build.”
The moves have led some to wonder just how close OpenAI is to a long-rumored breakthrough of some kind of reasoning artificial intelligence if high-profile employees are jumping ship (or taking long breaks, in the case of Brockman) so easily. As AI developer Benjamin De Kraker put it on X, “If OpenAI is right on the verge of AGI, why do prominent people keep leaving?”
AGI refers to a hypothetical AI system that could match human-level intelligence across a wide range of tasks without specialized training. It’s the ultimate goal of OpenAI, and company CEO Sam Altman has said it could emerge in the “reasonably close-ish future.” AGI is also a concept that has sparked concerns about potential existential risks to humanity and the displacement of knowledge workers. However, the term remains somewhat vague, and there’s considerable debate in the AI community about what truly constitutes AGI or how close we are to achieving it.
The emergence of the “next big thing” in AI has been seen by critics such as Ed Zitron as a necessary step to justify ballooning investments in AI models that aren’t yet profitable. The industry is holding its breath that OpenAI, or a competitor, has some secret breakthrough waiting in the wings that will justify the massive costs associated with training and deploying LLMs.
But other AI critics, such as Gary Marcus, have postulated that major AI companies have reached a plateau of large language model (LLM) capability centered around GPT-4-level models since no AI company has yet made a major leap past the groundbreaking LLM that OpenAI released in March 2023. Microsoft CTO Kevin Scott has countered these claims, saying that LLM “scaling laws” (that suggest LLMs increase in capability proportionate to more compute power thrown at them) will continue to deliver improvements over time and that more patience is needed as the next generation (say, GPT-5) undergoes training.
In the scheme of things, Brockman’s move sounds like an extended, long overdue vacation (or perhaps a period to deal with personal issues beyond work). Regardless of the reason, the duration of the sabbatical raises questions about how the president of a major tech company can suddenly disappear for four months without affecting day-to-day operations, especially during a critical time in its history.
Unless, of course, things are fairly calm at OpenAI—and perhaps GPT-5 isn’t going to ship until at least next year when Brockman returns. But this is speculation on our part, and OpenAI (whether voluntarily or not) sometimes surprises us when we least expect it. (Just today, Altman dropped a hint on X about strawberries that some people interpret as being a hint of a potential major model undergoing testing or nearing release.)
A pattern of departures and the rise of Anthropic
Anthropic / Benj Edwards
What may sting OpenAI the most about the recent departures is that a few high-profile employees have left to join Anthropic, a San Francisco-based AI company founded in 2021 by ex-OpenAI employees Daniela and Dario Amodei.
Anthropic offers a subscription service called Claude.ai that is similar to ChatGPT. Its most recent LLM, Claude 3.5 Sonnet, along with its web-based interface, has rapidly gained favor over ChatGPT among some LLM users who are vocal on social media, though it likely does not yet match ChatGPT in terms of mainstream brand recognition.
In particular, John Schulman, an OpenAI co-founder and key figure in the company’s post-training process for LLMs, revealed in a statement on X that he’s leaving to join rival AI firm Anthropic to do more hands-on work: “This choice stems from my desire to deepen my focus on AI alignment, and to start a new chapter of my career where I can return to hands-on technical work.” Alignment is a field that hopes to guide AI models to produce helpful outputs.
In May, OpenAI alignment researcher Jan Leike left OpenAI to join Anthropic as well, criticizing OpenAI’s handling of alignment safety.
Adding to the recent employee shake-up, The Information reports that Peter Deng, a product leader who joined OpenAI last year after stints at Meta Platforms, Uber, and Airtable, has also left the company, though we do not yet know where he is headed. In May, OpenAI co-founder Ilya Sutskever left to found a rival startup, and prominent software engineer Andrej Karpathy departed in February, recently launching an educational venture.
As De Kraker noted, if OpenAI were on the verge of developing world-changing AI technology, wouldn’t these high-profile AI veterans want to stick around and be part of this historic moment in time? “Genuine question,” he wrote. “If you were pretty sure the company you’re a key part of—and have equity in—is about to crack AGI within one or two years… why would you jump ship?”
Despite the departures, Schulman expressed optimism about OpenAI’s future in his farewell note on X. “I am confident that OpenAI and the teams I was part of will continue to thrive without me,” he wrote. “I’m incredibly grateful for the opportunity to participate in such an important part of history and I’m proud of what we’ve achieved together. I’ll still be rooting for you all, even while working elsewhere.”
This article was updated on August 7, 2024 at 4: 23 PM to mention Sam Altman’s tweet about strawberries.
Enlarge/ Elon Musk and Sam Altman share the stage in 2015, the same year that Musk alleged that Altman’s “deception” began.
After withdrawing his lawsuit in June for unknown reasons, Elon Musk has revived a complaint accusing OpenAI and its CEO Sam Altman of fraudulently inducing Musk to contribute $44 million in seed funding by promising that OpenAI would always open-source its technology and prioritize serving the public good over profits as a permanent nonprofit.
Instead, Musk alleged that Altman and his co-conspirators—”preying on Musk’s humanitarian concern about the existential dangers posed by artificial intelligence”—always intended to “betray” these promises in pursuit of personal gains.
As OpenAI’s technology advanced toward artificial general intelligence (AGI) and strove to surpass human capabilities, “Altman set the bait and hooked Musk with sham altruism then flipped the script as the non-profit’s technology approached AGI and profits neared, mobilizing Defendants to turn OpenAI, Inc. into their personal piggy bank and OpenAI into a moneymaking bonanza, worth billions,” Musk’s complaint said.
Where Musk saw OpenAI as his chance to fund a meaningful rival to stop Google from controlling the most powerful AI, Altman and others “wished to launch a competitor to Google” and allegedly deceived Musk to do it. According to Musk:
The idea Altman sold Musk was that a non-profit, funded and backed by Musk, would attract world-class scientists, conduct leading AI research and development, and, as a meaningful counterweight to Google’s DeepMind in the race for Artificial General Intelligence (“AGI”), decentralize its technology by making it open source. Altman assured Musk that the non-profit structure guaranteed neutrality and a focus on safety and openness for the benefit of humanity, not shareholder value. But as it turns out, this was all hot-air philanthropy—the hook for Altman’s long con.
Without Musk’s involvement and funding during OpenAI’s “first five critical years,” Musk’s complaint said, “it is fair to say” that “there would have been no OpenAI.” And when Altman and others repeatedly approached Musk with plans to shift OpenAI to a for-profit model, Musk held strong to his morals, conditioning his ongoing contributions on OpenAI remaining a nonprofit and its tech largely remaining open source.
“Either go do something on your own or continue with OpenAI as a nonprofit,” Musk told Altman in 2018 when Altman tried to “recast the nonprofit as a moneymaking endeavor to bring in shareholders, sell equity, and raise capital.”
“I will no longer fund OpenAI until you have made a firm commitment to stay, or I’m just being a fool who is essentially providing free funding to a startup,” Musk said at the time. “Discussions are over.”
But discussions weren’t over. And now Musk seemingly does feel like a fool after OpenAI exclusively licensed GPT-4 and all “pre-AGI” technology to Microsoft in 2023, while putting up paywalls and “failing to publicly disclose the non-profit’s research and development, including details on GPT-4, GPT-4T, and GPT-4o’s architecture, hardware, training method, and training computation.” This excluded the public “from open usage of GPT-4 and related technology to advance Defendants and Microsoft’s own commercial interests,” Musk alleged.
Now Musk has revived his suit against OpenAI, asking the court to award maximum damages for OpenAI’s alleged fraud, contract breaches, false advertising, acts viewed as unfair to competition, and other violations.
He has also asked the court to determine a very technical question: whether OpenAI’s most recent models should be considered AGI and therefore Microsoft’s license voided. That’s the only way to ensure that a private corporation isn’t controlling OpenAI’s AGI models, which Musk repeatedly conditioned his financial contributions upon preventing.
“Musk contributed considerable money and resources to launch and sustain OpenAI, Inc., which was done on the condition that the endeavor would be and remain a non-profit devoted to openly sharing its technology with the public and avoid concentrating its power in the hands of the few,” Musk’s complaint said. “Defendants knowingly and repeatedly accepted Musk’s contributions in order to develop AGI, with no intention of honoring those conditions once AGI was in reach. Case in point: GPT-4, GPT-4T, and GPT-4o are all closed source and shrouded in secrecy, while Defendants actively work to transform the non-profit into a thoroughly commercial business.”
Musk wants Microsoft’s GPT-4 license voided
Musk also asked the court to null and void OpenAI’s exclusive license to Microsoft, or else determine “whether GPT-4, GPT-4T, GPT-4o, and other OpenAI next generation large language models constitute AGI and are thus excluded from Microsoft’s license.”
It’s clear that Musk considers these models to be AGI, and he’s alleged that Altman’s current control of OpenAI’s Board—after firing dissidents in 2023 whom Musk claimed tried to get Altman ousted for prioritizing profits over AI safety—gives Altman the power to obscure when OpenAI’s models constitute AGI.
Enlarge/ Sam Altman, chief executive officer of OpenAI, during an interview at Bloomberg House on the opening day of the World Economic Forum (WEF) in Davos, Switzerland, on Tuesday, Jan. 16, 2024.
OpenAI is facing increasing pressure to prove it’s not hiding AI risks after whistleblowers alleged to the US Securities and Exchange Commission (SEC) that the AI company’s non-disclosure agreements had illegally silenced employees from disclosing major safety concerns to lawmakers.
In a letter to OpenAI yesterday, Senator Chuck Grassley (R-Iowa) demanded evidence that OpenAI is no longer requiring agreements that could be “stifling” its “employees from making protected disclosures to government regulators.”
Specifically, Grassley asked OpenAI to produce current employment, severance, non-disparagement, and non-disclosure agreements to reassure Congress that contracts don’t discourage disclosures. That’s critical, Grassley said, so that it will be possible to rely on whistleblowers exposing emerging threats to help shape effective AI policies safeguarding against existential AI risks as technologies advance.
Grassley has apparently twice requested these records without a response from OpenAI, his letter said. And so far, OpenAI has not responded to the most recent request to send documents, Grassley’s spokesperson, Clare Slattery, told The Washington Post.
“It’s not enough to simply claim you’ve made ‘updates,’” Grassley said in a statement provided to Ars. “The proof is in the pudding. Altman needs to provide records and responses to my oversight requests so Congress can accurately assess whether OpenAI is adequately protecting its employees and users.”
In addition to requesting OpenAI’s recently updated employee agreements, Grassley pushed OpenAI to be more transparent about the total number of requests it has received from employees seeking to make federal disclosures since 2023. The senator wants to know what information employees wanted to disclose to officials and whether OpenAI actually approved their requests.
Along the same lines, Grassley asked OpenAI to confirm how many investigations the SEC has opened into OpenAI since 2023.
Together, these documents would shed light on whether OpenAI employees are potentially still being silenced from making federal disclosures, what kinds of disclosures OpenAI denies, and how closely the SEC is monitoring OpenAI’s seeming efforts to hide safety risks.
“It is crucial OpenAI ensure its employees can provide protected disclosures without illegal restrictions,” Grassley wrote in his letter.
He has requested a response from OpenAI by August 15 so that “Congress may conduct objective and independent oversight on OpenAI’s safety protocols and NDAs.”
OpenAI did not immediately respond to Ars’ request for comment.
On X, Altman wrote that OpenAI has taken steps to increase transparency, including “working with the US AI Safety Institute on an agreement where we would provide early access to our next foundation model so that we can work together to push forward the science of AI evaluations.” He also confirmed that OpenAI wants “current and former employees to be able to raise concerns and feel comfortable doing so.”
“This is crucial for any company, but for us especially and an important part of our safety plan,” Altman wrote. “In May, we voided non-disparagement terms for current and former employees and provisions that gave OpenAI the right (although it was never used) to cancel vested equity. We’ve worked hard to make it right.”
In July, whistleblowers told the SEC that OpenAI should be required to produce not just current employee contracts, but all contracts that contained a non-disclosure agreement to ensure that OpenAI hasn’t been obscuring a history or current practice of obscuring AI safety risks. They want all current and former employees to be notified of any contract that included an illegal NDA and for OpenAI to be fined for every illegal contract.
Enlarge/ A stock photo of a robot whispering to a man.
On Tuesday, OpenAI began rolling out an alpha version of its new Advanced Voice Mode to a small group of ChatGPT Plus subscribers. This feature, which OpenAI previewed in May with the launch of GPT-4o, aims to make conversations with the AI more natural and responsive. In May, the feature triggered criticism of its simulated emotional expressiveness and prompted a public dispute with actress Scarlett Johansson over accusations that OpenAI copied her voice. Even so, early tests of the new feature shared by users on social media have been largely enthusiastic.
In early tests reported by users with access, Advanced Voice Mode allows them to have real-time conversations with ChatGPT, including the ability to interrupt the AI mid-sentence almost instantly. It can sense and respond to a user’s emotional cues through vocal tone and delivery, and provide sound effects while telling stories.
But what has caught many people off-guard initially is how the voices simulate taking a breath while speaking.
“ChatGPT Advanced Voice Mode counting as fast as it can to 10, then to 50 (this blew my mind—it stopped to catch its breath like a human would),” wrote tech writer Cristiano Giardina on X.
Advanced Voice Mode simulates audible pauses for breath because it was trained on audio samples of humans speaking that included the same feature. The model has learned to simulate inhalations at seemingly appropriate times after being exposed to hundreds of thousands, if not millions, of examples of human speech. Large language models (LLMs) like GPT-4o are master imitators, and that skill has now extended to the audio domain.
Giardina shared his other impressions about Advanced Voice Mode on X, including observations about accents in other languages and sound effects.
“It’s very fast, there’s virtually no latency from when you stop speaking to when it responds,” he wrote. “When you ask it to make noises it always has the voice “perform” the noises (with funny results). It can do accents, but when speaking other languages it always has an American accent. (In the video, ChatGPT is acting as a soccer match commentator)“
Speaking of sound effects, X user Kesku, who is a moderator of OpenAI’s Discord server, shared an example of ChatGPT playing multiple parts with different voices and another of a voice recounting an audiobook-sounding sci-fi story from the prompt, “Tell me an exciting action story with sci-fi elements and create atmosphere by making appropriate noises of the things happening using onomatopoeia.”
Kesku also ran a few example prompts for us, including a story about the Ars Technica mascot “Moonshark.”
He also asked it to sing the “Major-General’s Song” from Gilbert and Sullivan’s 1879 comic opera The Pirates of Penzance:
Frequent AI advocate Manuel Sainsily posted a video of Advanced Voice Mode reacting to camera input, giving advice about how to care for a kitten. “It feels like face-timing a super knowledgeable friend, which in this case was super helpful—reassuring us with our new kitten,” he wrote. “It can answer questions in real-time and use the camera as input too!”
Of course, being based on an LLM, it may occasionally confabulate incorrect responses on topics or in situations where its “knowledge” (which comes from GPT-4o’s training data set) is lacking. But if considered a tech demo or an AI-powered amusement and you’re aware of the limitations, Advanced Voice Mode seems to successfully execute many of the tasks shown by OpenAI’s demo in May.
Safety
An OpenAI spokesperson told Ars Technica that the company worked with more than 100 external testers on the Advanced Voice Mode release, collectively speaking 45 different languages and representing 29 geographical areas. The system is reportedly designed to prevent impersonation of individuals or public figures by blocking outputs that differ from OpenAI’s four chosen preset voices.
OpenAI has also added filters to recognize and block requests to generate music or other copyrighted audio, which has gotten other AI companies in trouble. Giardina reported audio “leakage” in some audio outputs that have unintentional music in the background, showing that OpenAI trained the AVM voice model on a wide variety of audio sources, likely both from licensed material and audio scraped from online video platforms.
Availability
OpenAI plans to expand access to more ChatGPT Plus users in the coming weeks, with a full launch to all Plus subscribers expected this fall. A company spokesperson told Ars that users in the alpha test group will receive a notice in the ChatGPT app and an email with usage instructions.
Since the initial preview of GPT-4o voice in May, OpenAI claims to have enhanced the model’s ability to support millions of simultaneous, real-time voice conversations while maintaining low latency and high quality. In other words, they are gearing up for a rush that will take a lot of back-end computation to accommodate.
Arguably, few companies have unintentionally contributed more to the increase of AI-generated noise online than OpenAI. Despite its best intentions—and against its terms of service—its AI language models are often used to compose spam, and its pioneering research has inspired others to build AI models that can potentially do the same. This influx of AI-generated content has further reduced the effectiveness of SEO-driven search engines like Google. In 2024, web search is in a sorry state indeed.
It’s interesting, then, that OpenAI is now offering a potential solution to that problem. On Thursday, OpenAI revealed a prototype AI-powered search engine called SearchGPT that aims to provide users with quick, accurate answers sourced from the web. It’s also a direct challenge to Google, which also has tried to apply generative AI to web search (but with little success).
The company says it plans to integrate the most useful aspects of the temporary prototype into ChatGPT in the future. ChatGPT can already perform web searches using Bing, but SearchGPT seems to be a purpose-built interface for AI-assisted web searching.
SearchGPT attempts to streamline the process of finding information online by combining OpenAI’s AI models (like GPT-4o) with real-time web data. Like ChatGPT, users can reportedly ask SearchGPT follow-up questions, with the AI model maintaining context throughout the conversation.
Perhaps most importantly from an accuracy standpoint, the SearchGPT prototype (which we have not tested ourselves) reportedly includes features that attribute web-based sources prominently. Responses include in-line citations and links, while a sidebar displays additional source links.
OpenAI has not yet said how it is obtaining its real-time web data and whether it’s partnering with an existing search engine provider (like it does currently with Bing for ChatGPT) or building its own web-crawling and indexing system.
A way around publishers blocking OpenAI
ChatGPT can already perform web searches using Bing, but since last August when OpenAI revealed a way to block its web crawler, that feature hasn’t been nearly as useful as it could be. Many sites, such as Ars Technica (which blocks the OpenAI crawler as part of our parent company’s policy), won’t show up as results in ChatGPT because of this.
SearchGPT appears to untangle the association between OpenAI’s web crawler for scraping training data and the desire for OpenAI chatbot users to search the web. Notably, in the new SearchGPT announcement, OpenAI says, “Sites can be surfaced in search results even if they opt out of generative AI training.”
Even so, OpenAI says it is working on a way for publishers to manage how they appear in SearchGPT results so that “publishers have more choices.” And the company says that SearchGPT’s ability to browse the web is separate from training OpenAI’s AI models.
An uncertain future for AI-powered search
OpenAI claims SearchGPT will make web searches faster and easier. However, the effectiveness of AI-powered search compared to traditional methods is unknown, as the tech is still in its early stages. But let’s be frank: The most prominent web-search engine right now is pretty terrible.
Over the past year, we’ve seen Perplexity.ai take off as a potential AI-powered Google search replacement, but the service has been hounded by issues with confabulations and accusations of plagiarism among publishers, including Ars Technica parent Condé Nast.
Unlike Perplexity, OpenAI has many content deals lined up with publishers, and it emphasizes that it wants to work with content creators in particular. “We are committed to a thriving ecosystem of publishers and creators,” says OpenAI in its news release. “We hope to help users discover publisher sites and experiences, while bringing more choice to search.”
In a statement for the OpenAI press release, Nicholas Thompson, CEO of The Atlantic (which has a content deal with OpenAI), expressed optimism about the potential of AI search: “AI search is going to become one of the key ways that people navigate the internet, and it’s crucial, in these early days, that the technology is built in a way that values, respects, and protects journalism and publishers,” he said. “We look forward to partnering with OpenAI in the process, and creating a new way for readers to discover The Atlantic.”
OpenAI has experimented with other offshoots of its AI language model technology that haven’t become blockbuster hits (most notably, GPTs come to mind), so time will tell if the techniques behind SearchGPT have staying power—and if it can deliver accurate results without hallucinating. But the current state of web search is inviting new experiments to separate the signal from the noise, and it looks like OpenAI is throwing its hat in the ring.
OpenAI is currently rolling out SearchGPT to a small group of users and publishers for testing and feedback. Those interested in trying the prototype can sign up for a waitlist on the company’s website.
In the AI world, there’s a buzz in the air about a new AI language model released Tuesday by Meta: Llama 3.1 405B. The reason? It’s potentially the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a “single server node,” which isn’t desktop PC-grade equipment. But it’s a provocative shot across the bow of “closed” AI model vendors such as OpenAI and Anthropic.
“Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation,” says Meta. Company CEO Mark Zuckerberg calls 405B “the first frontier-level open source AI model.”
In the AI industry, “frontier model” is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta is positioning 405B among the likes of the industry’s top AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
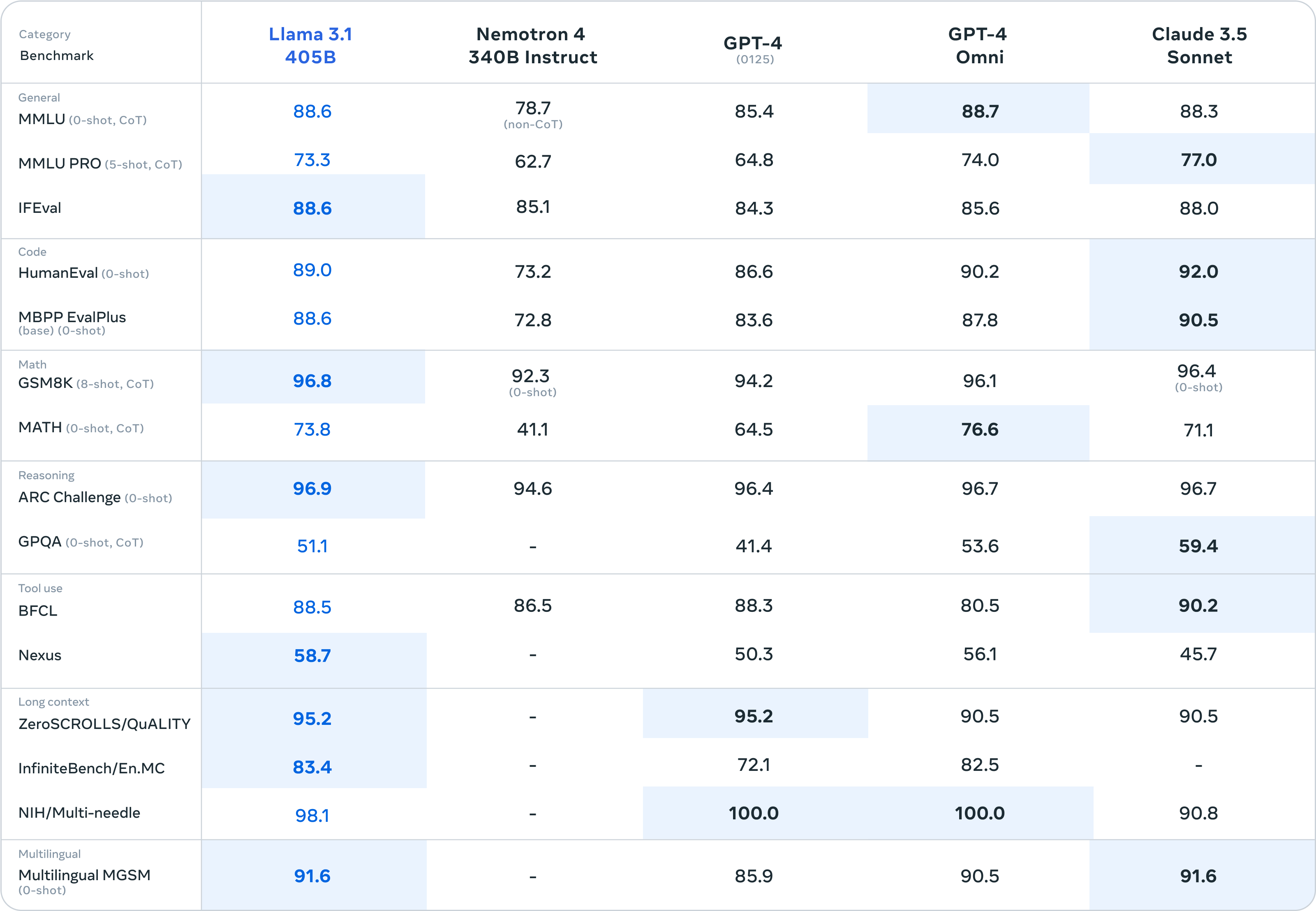
A chart published by Meta suggests that 405B gets very close to matching the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound or translate to the subjective experience of interacting with AI language models. In fact, this traditional slate of AI benchmarks is so generally useless to laypeople that even Meta’s PR department now just posts a few images of charts and doesn’t even try to explain them in any detail.
Enlarge/ A Meta-provided chart that shows Llama 3.1 405B benchmark results versus other major AI models.
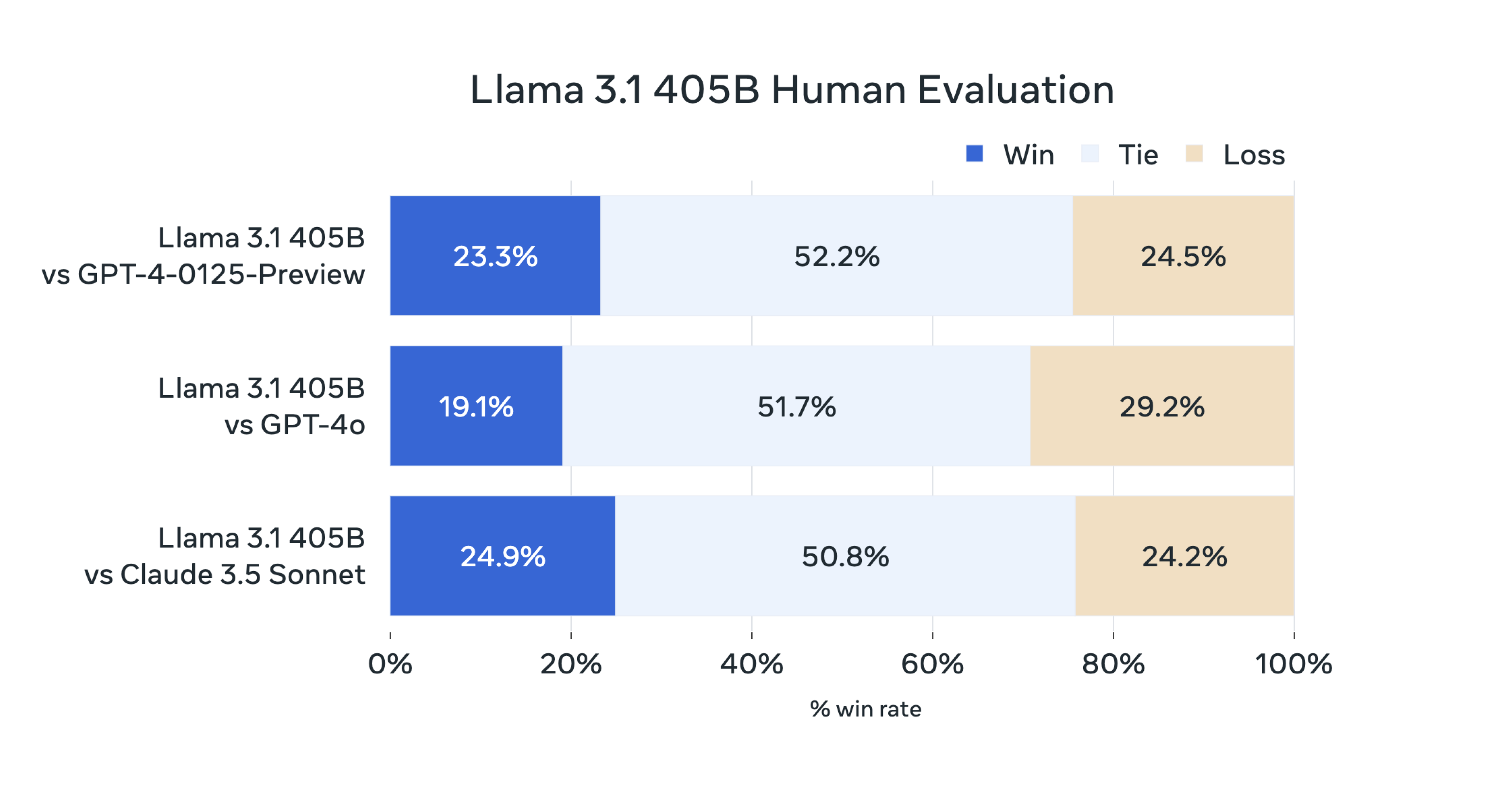
We’ve instead found that measuring the subjective experience of using a conversational AI model (through what might be called “vibemarking”) on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs that seem to show Meta’s new model holding its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Enlarge/ A Meta-provided chart that shows how humans rated Llama 3.1 405B’s outputs compared to GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in its own studies.
Whatever the benchmarks, early word on the street (after the model leaked on 4chan yesterday) seems to match the claim that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there—and money, of which the social media giant has plenty to burn. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using more than 16,000 H100 GPUs.
So what’s with the 405B name? In this case, “405B” means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capability, such as better ability to make contextual connections between concepts. But larger-parameter models have a tradeoff in needing more computing power (AKA “compute”) to run.
We’ve been expecting the release of a 400 billion-plus parameter model of the Llama 3 family since Meta gave word that it was training one in April, and today’s announcement isn’t just about the biggest member of the Llama 3 family: There’s an entirely new iteration of improved Llama models with the designation “Llama 3.1.” That includes upgraded versions of its smaller 8B and 70B models, which now feature multilingual support and an extended context length of 128,000 tokens (the “context length” is roughly the working memory capacity of the model, and “tokens” are chunks of data used by LLMs to process information).
Meta says that 405B is useful for long-form text summarization, multilingual conversational agents, and coding assistants and for creating synthetic data used to train future AI language models. Notably, that last use-case—allowing developers to use outputs from Llama models to improve other AI models—is now officially supported by Meta’s Llama 3.1 license for the first time.
Abusing the term “open source”
Llama 3.1 405B is an open-weights model, which means anyone can download the trained neural network files and run them or fine-tune them. That directly challenges a business model where companies like OpenAI keep the weights to themselves and instead monetize the model through subscription wrappers like ChatGPT or charge for access by the token through an API.
Fighting the “closed” AI model is a big deal to Mark Zuckerberg, who simultaneously released a 2,300-word manifesto today on why the company believes in open releases of AI models, titled, “Open Source AI Is the Path Forward.” More on the terminology in a minute. But briefly, he writes about the need for customizable AI models that offer user control and encourage better data security, higher cost-efficiency, and better future-proofing, as opposed to vendor-locked solutions.
All that sounds reasonable, but undermining your competitors using a model subsidized by a social media war chest is also an efficient way to play spoiler in a market where you might not always win with the most cutting-edge tech. That benefits Meta, Zuckerberg says, because he doesn’t want to get locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to “taxes” Apple levies on developers through its App Store.
Enlarge/ A screenshot of Mark Zuckerberg’s essay, “Open Source AI Is the Path Forward,” published on July 23, 2024.
So, about that “open source” term. As we first wrote in an update to our Llama 2 launch article a year ago, “open source” has a very particular meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (such as Llama 3.1) or that ship without providing training data. We’ve been calling these releases “open weights” instead.
Unfortunately for terminology sticklers, Zuckerberg has now baked the erroneous “open source” label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the correct term in AI may be a losing battle. Still, his usage annoys people like independent AI researcher Simon Willison, who likes Zuckerberg’s essay otherwise.
“I see Zuck’s prominent misuse of ‘open source’ as a small-scale act of cultural vandalism,” Willison told Ars Technica. “Open source should have an agreed meaning. Abusing the term weakens that meaning which makes the term less generally useful, because if someone says ‘it’s open source,’ that no longer tells me anything useful. I have to then dig in and figure out what they’re actually talking about.”
The Llama 3.1 models are available for download through Meta’s own website and on Hugging Face. They both require providing contact information and agreeing to a license and an acceptable use policy, which means that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.
Enlarge/ Kevin Scott, CTO and EVP of AI at Microsoft speaks onstage during Vox Media’s 2023 Code Conference at The Ritz-Carlton, Laguna Niguel on September 27, 2023 in Dana Point, California.
During an interview with Sequoia Capital’s Training Data podcast published last Tuesday, Microsoft CTO Kevin Scott doubled down on his belief that so-called large language model (LLM) “scaling laws” will continue to drive AI progress, despite some skepticism in the field that progress has leveled out. Scott played a key role in forging a $13 billion technology-sharing deal between Microsoft and OpenAI.
“Despite what other people think, we’re not at diminishing marginal returns on scale-up,” Scott said. “And I try to help people understand there is an exponential here, and the unfortunate thing is you only get to sample it every couple of years because it just takes a while to build supercomputers and then train models on top of them.”
LLM scaling laws refer to patterns explored by OpenAI researchers in 2020 showing that the performance of language models tends to improve predictably as the models get larger (more parameters), are trained on more data, and have access to more computational power (compute). The laws suggest that simply scaling up model size and training data can lead to significant improvements in AI capabilities without necessarily requiring fundamental algorithmic breakthroughs.
Since then, other researchers have challenged the idea of persisting scaling laws over time, but the concept is still a cornerstone of OpenAI’s AI development philosophy.
You can see Scott’s comments in the video below beginning around 46: 05:
Microsoft CTO Kevin Scott on how far scaling laws will extend
Scott’s optimism contrasts with a narrative among some critics in the AI community that progress in LLMs has plateaued around GPT-4 class models. The perception has been fueled by largely informal observations—and some benchmark results—about recent models like Google’s Gemini 1.5 Pro, Anthropic’s Claude Opus, and even OpenAI’s GPT-4o, which some argue haven’t shown the dramatic leaps in capability seen in earlier generations, and that LLM development may be approaching diminishing returns.
“We all know that GPT-3 was vastly better than GPT-2. And we all know that GPT-4 (released thirteen months ago) was vastly better than GPT-3,” wrote AI critic Gary Marcus in April. “But what has happened since?”
The perception of plateau
Scott’s stance suggests that tech giants like Microsoft still feel justified in investing heavily in larger AI models, betting on continued breakthroughs rather than hitting a capability plateau. Given Microsoft’s investment in OpenAI and strong marketing of its own Microsoft Copilot AI features, the company has a strong interest in maintaining the perception of continued progress, even if the tech stalls.
Frequent AI critic Ed Zitron recently wrote in a post on his blog that one defense of continued investment into generative AI is that “OpenAI has something we don’t know about. A big, sexy, secret technology that will eternally break the bones of every hater,” he wrote. “Yet, I have a counterpoint: no it doesn’t.”
Some perceptions of slowing progress in LLM capabilities and benchmarking may be due to the rapid onset of AI in the public eye when, in fact, LLMs have been developing for years prior. OpenAI continued to develop LLMs during a roughly three-year gap between the release of GPT-3 in 2020 and GPT-4 in 2023. Many people likely perceived a rapid jump in capability with GPT-4’s launch in 2023 because they had only become recently aware of GPT-3-class models with the launch of ChatGPT in late November 2022, which used GPT-3.5.
In the podcast interview, the Microsoft CTO pushed back against the idea that AI progress has stalled, but he acknowledged the challenge of infrequent data points in this field, as new models often take years to develop. Despite this, Scott expressed confidence that future iterations will show improvements, particularly in areas where current models struggle.
“The next sample is coming, and I can’t tell you when, and I can’t predict exactly how good it’s going to be, but it will almost certainly be better at the things that are brittle right now, where you’re like, oh my god, this is a little too expensive, or a little too fragile, for me to use,” Scott said in the interview. “All of that gets better. It’ll get cheaper, and things will become less fragile. And then more complicated things will become possible. That is the story of each generation of these models as we’ve scaled up.”
OpenAI recently unveiled a five-tier system to gauge its advancement toward developing artificial general intelligence (AGI), according to an OpenAI spokesperson who spoke with Bloomberg. The company shared this new classification system on Tuesday with employees during an all-hands meeting, aiming to provide a clear framework for understanding AI advancement. However, the system describes hypothetical technology that does not yet exist and is possibly best interpreted as a marketing move to garner investment dollars.
OpenAI has previously stated that AGI—a nebulous term for a hypothetical concept that means an AI system that can perform novel tasks like a human without specialized training—is currently the primary goal of the company. The pursuit of technology that can replace humans at most intellectual work drives most of the enduring hype over the firm, even though such a technology would likely be wildly disruptive to society.
OpenAI CEO Sam Altman has previously stated his belief that AGI could be achieved within this decade, and a large part of the CEO’s public messaging has been related to how the company (and society in general) might handle the disruption that AGI may bring. Along those lines, a ranking system to communicate AI milestones achieved internally on the path to AGI makes sense.
OpenAI’s five levels—which it plans to share with investors—range from current AI capabilities to systems that could potentially manage entire organizations. The company believes its technology (such as GPT-4o that powers ChatGPT) currently sits at Level 1, which encompasses AI that can engage in conversational interactions. However, OpenAI executives reportedly told staff they’re on the verge of reaching Level 2, dubbed “Reasoners.”
Bloomberg lists OpenAI’s five “Stages of Artificial Intelligence” as follows:
Level 1: Chatbots, AI with conversational language
Level 2: Reasoners, human-level problem solving
Level 3: Agents, systems that can take actions
Level 4: Innovators, AI that can aid in invention
Level 5: Organizations, AI that can do the work of an organization
A Level 2 AI system would reportedly be capable of basic problem-solving on par with a human who holds a doctorate degree but lacks access to external tools. During the all-hands meeting, OpenAI leadership reportedly demonstrated a research project using their GPT-4 model that the researchers believe shows signs of approaching this human-like reasoning ability, according to someone familiar with the discussion who spoke with Bloomberg.
The upper levels of OpenAI’s classification describe increasingly potent hypothetical AI capabilities. Level 3 “Agents” could work autonomously on tasks for days. Level 4 systems would generate novel innovations. The pinnacle, Level 5, envisions AI managing entire organizations.
This classification system is still a work in progress. OpenAI plans to gather feedback from employees, investors, and board members, potentially refining the levels over time.
Ars Technica asked OpenAI about the ranking system and the accuracy of the Bloomberg report, and a company spokesperson said they had “nothing to add.”
The problem with ranking AI capabilities
OpenAI isn’t alone in attempting to quantify levels of AI capabilities. As Bloomberg notes, OpenAI’s system feels similar to levels of autonomous driving mapped out by automakers. And in November 2023, researchers at Google DeepMind proposed their own five-level framework for assessing AI advancement, showing that other AI labs have also been trying to figure out how to rank things that don’t yet exist.
OpenAI’s classification system also somewhat resembles Anthropic’s “AI Safety Levels” (ASLs) first published by the maker of the Claude AI assistant in September 2023. Both systems aim to categorize AI capabilities, though they focus on different aspects. Anthropic’s ASLs are more explicitly focused on safety and catastrophic risks (such as ASL-2, which refers to “systems that show early signs of dangerous capabilities”), while OpenAI’s levels track general capabilities.
However, any AI classification system raises questions about whether it’s possible to meaningfully quantify AI progress and what constitutes an advancement (or even what constitutes a “dangerous” AI system, as in the case of Anthropic). The tech industry so far has a history of overpromising AI capabilities, and linear progression models like OpenAI’s potentially risk fueling unrealistic expectations.
There is currently no consensus in the AI research community on how to measure progress toward AGI or even if AGI is a well-defined or achievable goal. As such, OpenAI’s five-tier system should likely be viewed as a communications tool to entice investors that shows the company’s aspirational goals rather than a scientific or even technical measurement of progress.
Enlarge/ The app lets you invoke ChatGPT from anywhere in the system with a keyboard shortcut, Spotlight-style.
Samuel Axon
OpenAI announced its Mac desktop app for ChatGPT with a lot of fanfare a few weeks ago, but it turns out it had a rather serious security issue: user chats were stored in plain text, where any bad actor could find them if they gained access to your machine.
As Threads user Pedro José Pereira Vieito noted earlier this week, “the OpenAI ChatGPT app on macOS is not sandboxed and stores all the conversations in plain-text in a non-protected location,” meaning “any other running app / process / malware can read all your ChatGPT conversations without any permission prompt.”
He added:
macOS has blocked access to any user private data since macOS Mojave 10.14 (6 years ago!). Any app accessing private user data (Calendar, Contacts, Mail, Photos, any third-party app sandbox, etc.) now requires explicit user access.
OpenAI chose to opt-out of the sandbox and store the conversations in plain text in a non-protected location, disabling all of these built-in defenses.
OpenAI has now updated the app, and the local chats are now encrypted, though they are still not sandboxed. (The app is only available as a direct download from OpenAI’s website and is not available through Apple’s App Store where more stringent security is required.)
Many people now use ChatGPT like they might use Google: to ask important questions, sort through issues, and so on. Often, sensitive personal data could be shared in those conversations.
It’s not a great look for OpenAI, which recently entered into a partnership with Apple to offer chat bot services built into Siri queries in Apple operating systems. Apple detailed some of the security around those queries at WWDC last month, though, and they’re more stringent than what OpenAI did (or to be more precise, didn’t do) with its Mac app, which is a separate initiative from the partnership.
If you’ve been using the app recently, be sure to update it as soon as possible.
Enlarge/ EU competition chief Margrethe Vestager said the bloc was looking into practices that could in effect lead to a company controlling a greater share of the AI market.
Brussels is preparing for an antitrust investigation into Microsoft’s $13 billion investment into OpenAI, after the European Union decided not to proceed with a merger review into the most powerful alliance in the artificial intelligence industry.
The European Commission, the EU’s executive arm, began to explore a review under merger control rules in January, but on Friday announced that it would not proceed due to a lack of evidence that Microsoft controls OpenAI.
However, the commission said it was now exploring the possibility of a traditional antitrust investigation into whether the tie-up between the world’s most valuable listed company and the best-funded AI start-up was harming competition in the fast-growing market.
The commission has also made inquiries about Google’s deal with Samsung to install a modified version of its Gemini AI system in the South Korean manufacturer’s smartphones, it revealed on Friday.
Margrethe Vestager, the bloc’s competition chief, said in a speech on Friday: “The key question was whether Microsoft had acquired control on a lasting basis over OpenAI. After a thorough review we concluded that such was not the case. So we are closing this chapter, but the story is not over.”
She said the EU had sent a new set of questions to understand whether “certain exclusivity clauses” in the agreement between Microsoft and OpenAI “could have a negative effect on competitors.” The move is seen as a key step toward a formal antitrust probe.
The bloc had already sent questions to Microsoft and other tech companies in March to determine whether market concentration in AI could potentially block new companies from entering the market, Vestager said.
Microsoft said: “We appreciate the European Commission’s thorough review and its conclusion that Microsoft’s investment and partnership with OpenAI does not give Microsoft control over the company.”
Brussels began examining Microsoft’s relationship with the ChatGPT maker after OpenAI’s board abruptly dismissed its chief executive Sam Altman in November 2023, only to be rehired a few days later. He briefly joined Microsoft as the head of a new AI research unit, highlighting the close relationship between the two companies.
Regulators in the US and UK are also scrutinizing the alliance. Microsoft is the biggest backer of OpenAI, although its investment of up to $13 billion, which was expanded in January 2023, does not involve acquiring conventional equity due to the startup’s unusual corporate structure. Microsoft has a minority interest in OpenAI’s commercial subsidiary, which is owned by a not-for-profit organization.
Antitrust investigations tend to last years, compared with a much shorter period for merger reviews, and they focus on conduct that could be undermining rivals. Companies that are eventually found to be breaking the law, for example by bundling products or blocking competitors from access to key technology, risk hefty fines and legal obligations to change their behavior.
Vestager said the EU was looking into practices that could in effect lead to a company controlling a greater share of the AI market. She pointed to a practice called “acqui-hires,” where a company buys another one mainly to get its talent. For example, Microsoft recently struck a deal to hire most of the top team from AI start-up Inflection, in which it had previously invested. Inflection remains an independent company, however, complicating any traditional merger investigation.
The EU’s competition chief said regulators were also looking into the way big tech companies may be preventing smaller AI models from reaching users.
“This is why we are also sending requests for information to better understand the effects of Google’s arrangement with Samsung to pre-install its small model ‘Gemini nano’ on certain Samsung devices,” said Vestager.
Jonathan Kanter, the top US antitrust enforcer, told the Financial Times earlier this month that he was also examining “monopoly choke points and the competitive landscape” in AI. The UK’s Competition and Markets Authority said in December that it had “decided to investigate” the Microsoft-OpenAI deal when it invited comments from customers and rivals.
On Thursday, OpenAI researchers unveiled CriticGPT, a new AI model designed to identify mistakes in code generated by ChatGPT. It aims to enhance the process of making AI systems behave in ways humans want (called “alignment”) through Reinforcement Learning from Human Feedback (RLHF), which helps human reviewers make large language model (LLM) outputs more accurate.
As outlined in a new research paper called “LLM Critics Help Catch LLM Bugs,” OpenAI created CriticGPT to act as an AI assistant to human trainers who review programming code generated by the ChatGPT AI assistant. CriticGPT—based on the GPT-4 family of LLMS—analyzes the code and points out potential errors, making it easier for humans to spot mistakes that might otherwise go unnoticed. The researchers trained CriticGPT on a dataset of code samples with intentionally inserted bugs, teaching it to recognize and flag various coding errors.
The researchers found that CriticGPT’s critiques were preferred by annotators over human critiques in 63 percent of cases involving naturally occurring LLM errors and that human-machine teams using CriticGPT wrote more comprehensive critiques than humans alone while reducing confabulation (hallucination) rates compared to AI-only critiques.
Developing an automated critic
The development of CriticGPT involved training the model on a large number of inputs containing deliberately inserted mistakes. Human trainers were asked to modify code written by ChatGPT, introducing errors and then providing example feedback as if they had discovered these bugs. This process allowed the model to learn how to identify and critique various types of coding errors.
In experiments, CriticGPT demonstrated its ability to catch both inserted bugs and naturally occurring errors in ChatGPT’s output. The new model’s critiques were preferred by trainers over those generated by ChatGPT itself in 63 percent of cases involving natural bugs (the aforementioned statistic). This preference was partly due to CriticGPT producing fewer unhelpful “nitpicks” and generating fewer false positives, or hallucinated problems.
The researchers also created a new technique they call Force Sampling Beam Search (FSBS). This method helps CriticGPT write more detailed reviews of code. It lets the researchers adjust how thorough CriticGPT is in looking for problems, while also controlling how often it might make up issues that don’t really exist. They can tweak this balance depending on what they need for different AI training tasks.
Interestingly, the researchers found that CriticGPT’s capabilities extend beyond just code review. In their experiments, they applied the model to a subset of ChatGPT training data that had previously been rated as flawless by human annotators. Surprisingly, CriticGPT identified errors in 24 percent of these cases—errors that were subsequently confirmed by human reviewers. OpenAI thinks this demonstrates the model’s potential to generalize to non-code tasks and highlights its ability to catch subtle mistakes that even careful human evaluation might miss.
Despite its promising results, like all AI models, CriticGPT has limitations. The model was trained on relatively short ChatGPT answers, which may not fully prepare it for evaluating longer, more complex tasks that future AI systems might tackle. Additionally, while CriticGPT reduces confabulations, it doesn’t eliminate them entirely, and human trainers can still make labeling mistakes based on these false outputs.
The research team acknowledges that CriticGPT is most effective at identifying errors that can be pinpointed in one specific location within the code. However, real-world mistakes in AI outputs can often be spread across multiple parts of an answer, presenting a challenge for future iterations of the model.
OpenAI plans to integrate CriticGPT-like models into its RLHF labeling pipeline, providing its trainers with AI assistance. For OpenAI, it’s a step toward developing better tools for evaluating outputs from LLM systems that may be difficult for humans to rate without additional support. However, the researchers caution that even with tools like CriticGPT, extremely complex tasks or responses may still prove challenging for human evaluators—even those assisted by AI.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}