
Words are flowing out like endless rain: Recapping a busy week of LLM news
many things frequently —
Gemini 1.5 Pro launch, new version of GPT-4 Turbo, new Mistral model, and more.

Enlarge / An image of a boy amazed by flying letters.
Some weeks in AI news are eerily quiet, but during others, getting a grip on the week’s events feels like trying to hold back the tide. This week has seen three notable large language model (LLM) releases: Google Gemini Pro 1.5 hit general availability with a free tier, OpenAI shipped a new version of GPT-4 Turbo, and Mistral released a new openly licensed LLM, Mixtral 8x22B. All three of those launches happened within 24 hours starting on Tuesday.
With the help of software engineer and independent AI researcher Simon Willison (who also wrote about this week’s hectic LLM launches on his own blog), we’ll briefly cover each of the three major events in roughly chronological order, then dig into some additional AI happenings this week.
Gemini Pro 1.5 general release

On Tuesday morning Pacific time, Google announced that its Gemini 1.5 Pro model (which we first covered in February) is now available in 180-plus countries, excluding Europe, via the Gemini API in a public preview. This is Google’s most powerful public LLM so far, and it’s available in a free tier that permits up to 50 requests a day.
It supports up to 1 million tokens of input context. As Willison notes in his blog, Gemini 1.5 Pro’s API price at $7/million input tokens and $21/million output tokens costs a little less than GPT-4 Turbo (priced at $10/million in and $30/million out) and more than Claude 3 Sonnet (Anthropic’s mid-tier LLM, priced at $3/million in and $15/million out).
Notably, Gemini 1.5 Pro includes native audio (speech) input processing that allows users to upload audio or video prompts, a new File API for handling files, the ability to add custom system instructions (system prompts) for guiding model responses, and a JSON mode for structured data extraction.
“Majorly Improved” GPT-4 Turbo launch
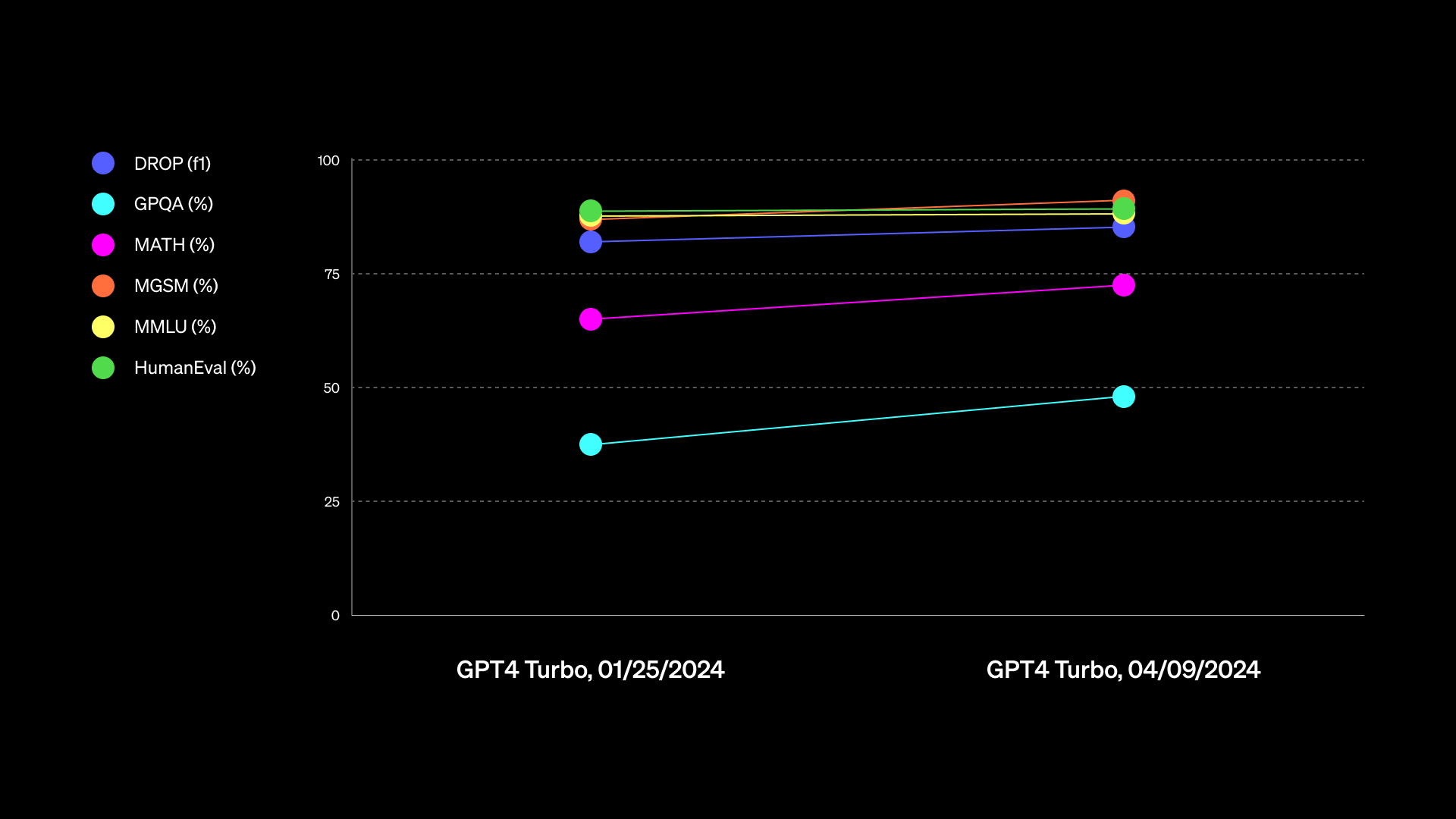
Enlarge / A GPT-4 Turbo performance chart provided by OpenAI.
Just a bit later than Google’s 1.5 Pro launch on Tuesday, OpenAI announced that it was rolling out a “majorly improved” version of GPT-4 Turbo (a model family originally launched in November) called “gpt-4-turbo-2024-04-09.” It integrates multimodal GPT-4 Vision processing (recognizing the contents of images) directly into the model, and it initially launched through API access only.
Then on Thursday, OpenAI announced that the new GPT-4 Turbo model had just become available for paid ChatGPT users. OpenAI said that the new model improves “capabilities in writing, math, logical reasoning, and coding” and shared a chart that is not particularly useful in judging capabilities (that they later updated). The company also provided an example of an alleged improvement, saying that when writing with ChatGPT, the AI assistant will use “more direct, less verbose, and use more conversational language.”
The vague nature of OpenAI’s GPT-4 Turbo announcements attracted some confusion and criticism online. On X, Willison wrote, “Who will be the first LLM provider to publish genuinely useful release notes?” In some ways, this is a case of “AI vibes” again, as we discussed in our lament about the poor state of LLM benchmarks during the debut of Claude 3. “I’ve not actually spotted any definite differences in quality [related to GPT-4 Turbo],” Willison told us directly in an interview.
The update also expanded GPT-4’s knowledge cutoff to April 2024, although some people are reporting it achieves this through stealth web searches in the background, and others on social media have reported issues with date-related confabulations.
Mistral’s mysterious Mixtral 8x22B release

Enlarge / An illustration of a robot holding a French flag, figuratively reflecting the rise of AI in France due to Mistral. It’s hard to draw a picture of an LLM, so a robot will have to do.
Not to be outdone, on Tuesday night, French AI company Mistral launched its latest openly licensed model, Mixtral 8x22B, by tweeting a torrent link devoid of any documentation or commentary, much like it has done with previous releases.
The new mixture-of-experts (MoE) release weighs in with a larger parameter count than its previously most-capable open model, Mixtral 8x7B, which we covered in December. It’s rumored to potentially be as capable as GPT-4 (In what way, you ask? Vibes). But that has yet to be seen.
“The evals are still rolling in, but the biggest open question right now is how well Mixtral 8x22B shapes up,” Willison told Ars. “If it’s in the same quality class as GPT-4 and Claude 3 Opus, then we will finally have an openly licensed model that’s not significantly behind the best proprietary ones.”
This release has Willison most excited, saying, “If that thing really is GPT-4 class, it’s wild, because you can run that on a (very expensive) laptop. I think you need 128GB of MacBook RAM for it, twice what I have.”
The new Mixtral is not listed on Chatbot Arena yet, Willison noted, because Mistral has not released a fine-tuned model for chatting yet. It’s still a raw, predict-the-next token LLM. “There’s at least one community instruction tuned version floating around now though,” says Willison.
Chatbot Arena Leaderboard shake-ups
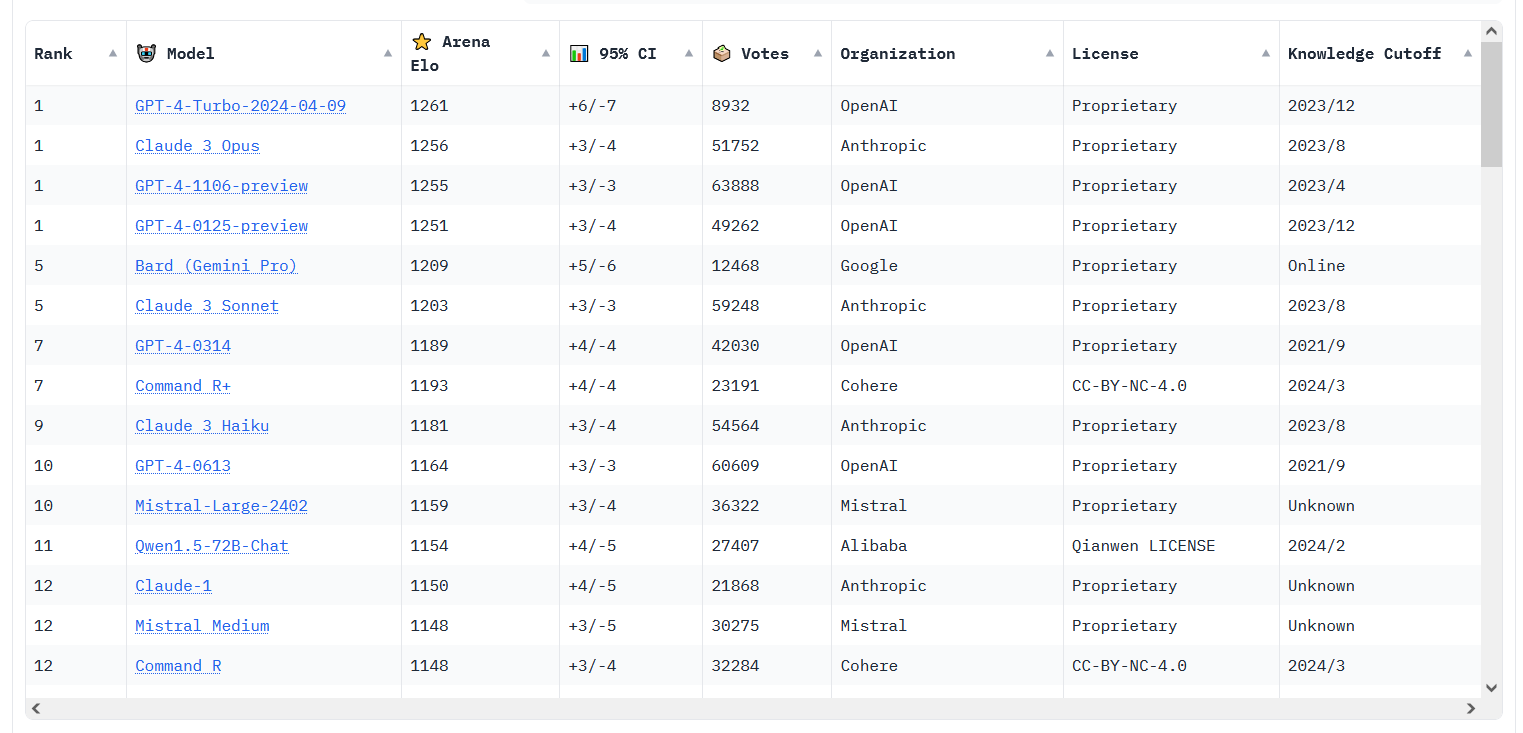
Enlarge / A Chatbot Arena Leaderboard screenshot taken on April 12, 2024.
Benj Edwards
This week’s LLM news isn’t limited to just the big names in the field. There have also been rumblings on social media about the rising performance of open source models like Cohere’s Command R+, which reached position 6 on the LMSYS Chatbot Arena Leaderboard—the highest-ever ranking for an open-weights model.
And for even more Chatbot Arena action, apparently the new version of GPT-4 Turbo is proving competitive with Claude 3 Opus. The two are still in a statistical tie, but GPT-4 Turbo recently pulled ahead numerically. (In March, we reported when Claude 3 first numerically pulled ahead of GPT-4 Turbo, which was then the first time another AI model had surpassed a GPT-4 family model member on the leaderboard.)
Regarding this fierce competition among LLMs—of which most of the muggle world is unaware and will likely never be—Willison told Ars, “The past two months have been a whirlwind—we finally have not just one but several models that are competitive with GPT-4.” We’ll see if OpenAI’s rumored release of GPT-5 later this year will restore the company’s technological lead, we note, which once seemed insurmountable. But for now, Willison says, “OpenAI are no longer the undisputed leaders in LLMs.”
Words are flowing out like endless rain: Recapping a busy week of LLM news Read More »


{kind=link}