Meta constructed the Llama 4 models using a mixture-of-experts (MoE) architecture, which is one way around the limitations of running huge AI models. Think of MoE like having a large team of specialized workers; instead of everyone working on every task, only the relevant specialists activate for a specific job.
For example, Llama 4 Maverick features a 400 billion parameter size, but only 17 billion of those parameters are active at once across one of 128 experts. Likewise, Scout features 109 billion total parameters, but only 17 billion are active at once across one of 16 experts. This design can reduce the computation needed to run the model, since smaller portions of neural network weights are active simultaneously.
Llama’s reality check arrives quickly
Current AI models have a relatively limited short-term memory. In AI, a context window acts somewhat in that fashion, determining how much information it can process simultaneously. AI language models like Llama typically process that memory as chunks of data called tokens, which can be whole words or fragments of longer words. Large context windows allow AI models to process longer documents, larger code bases, and longer conversations.
Despite Meta’s promotion of Llama 4 Scout’s 10 million token context window, developers have so far discovered that using even a fraction of that amount has proven challenging due to memory limitations. Willison reported on his blog that third-party services providing access, like Groq and Fireworks, limited Scout’s context to just 128,000 tokens. Another provider, Together AI, offered 328,000 tokens.
Evidence suggests accessing larger contexts requires immense resources. Willison pointed to Meta’s own example notebook (“build_with_llama_4“), which states that running a 1.4 million token context needs eight high-end Nvidia H100 GPUs.
Willison documented his own testing troubles. When he asked Llama 4 Scout via the OpenRouter service to summarize a long online discussion (around 20,000 tokens), the result wasn’t useful. He described the output as “complete junk output,” which devolved into repetitive loops.
In the AI world, there’s a buzz in the air about a new AI language model released Tuesday by Meta: Llama 3.1 405B. The reason? It’s potentially the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a “single server node,” which isn’t desktop PC-grade equipment. But it’s a provocative shot across the bow of “closed” AI model vendors such as OpenAI and Anthropic.
“Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation,” says Meta. Company CEO Mark Zuckerberg calls 405B “the first frontier-level open source AI model.”
In the AI industry, “frontier model” is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta is positioning 405B among the likes of the industry’s top AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
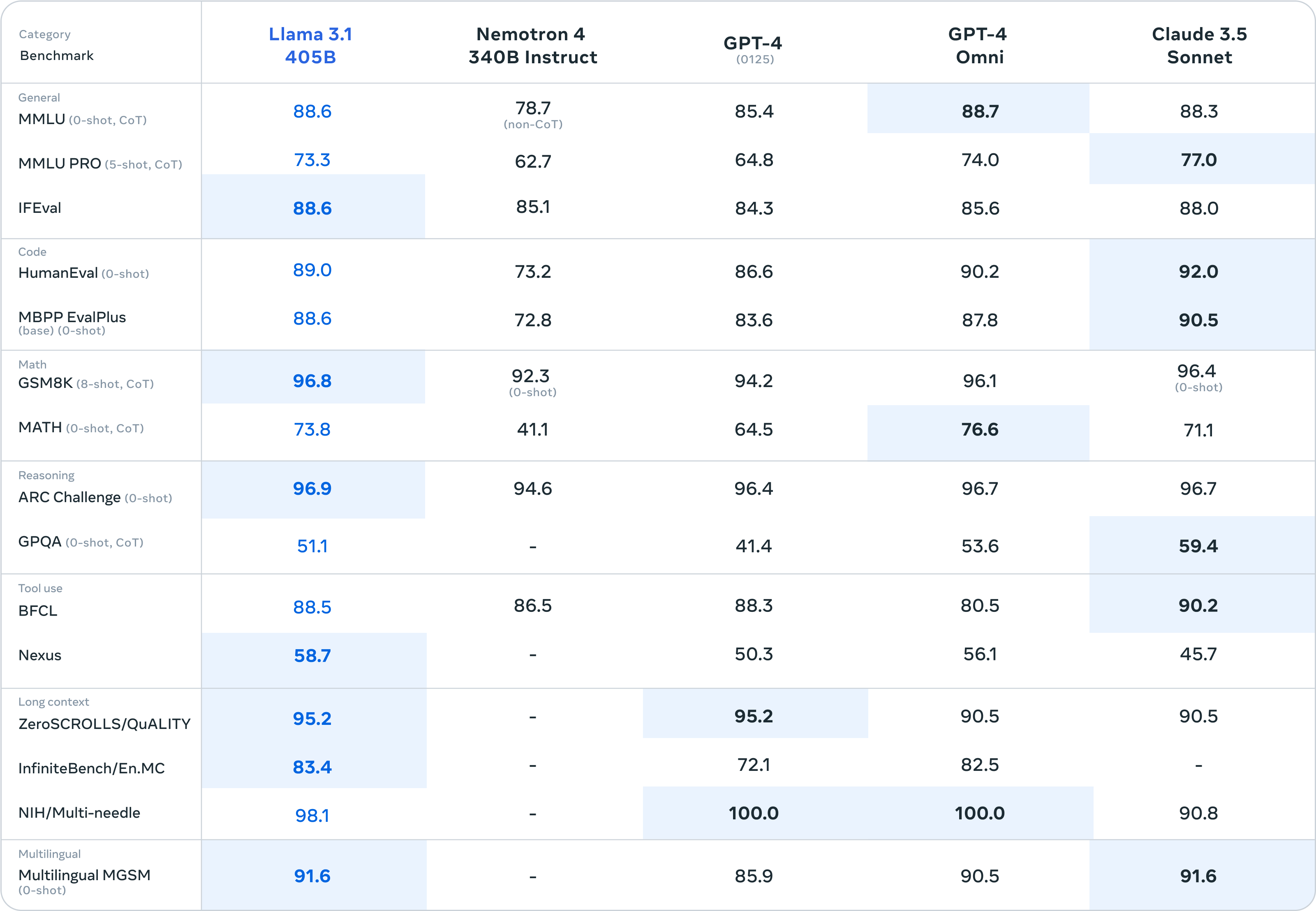
A chart published by Meta suggests that 405B gets very close to matching the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound or translate to the subjective experience of interacting with AI language models. In fact, this traditional slate of AI benchmarks is so generally useless to laypeople that even Meta’s PR department now just posts a few images of charts and doesn’t even try to explain them in any detail.
Enlarge/ A Meta-provided chart that shows Llama 3.1 405B benchmark results versus other major AI models.
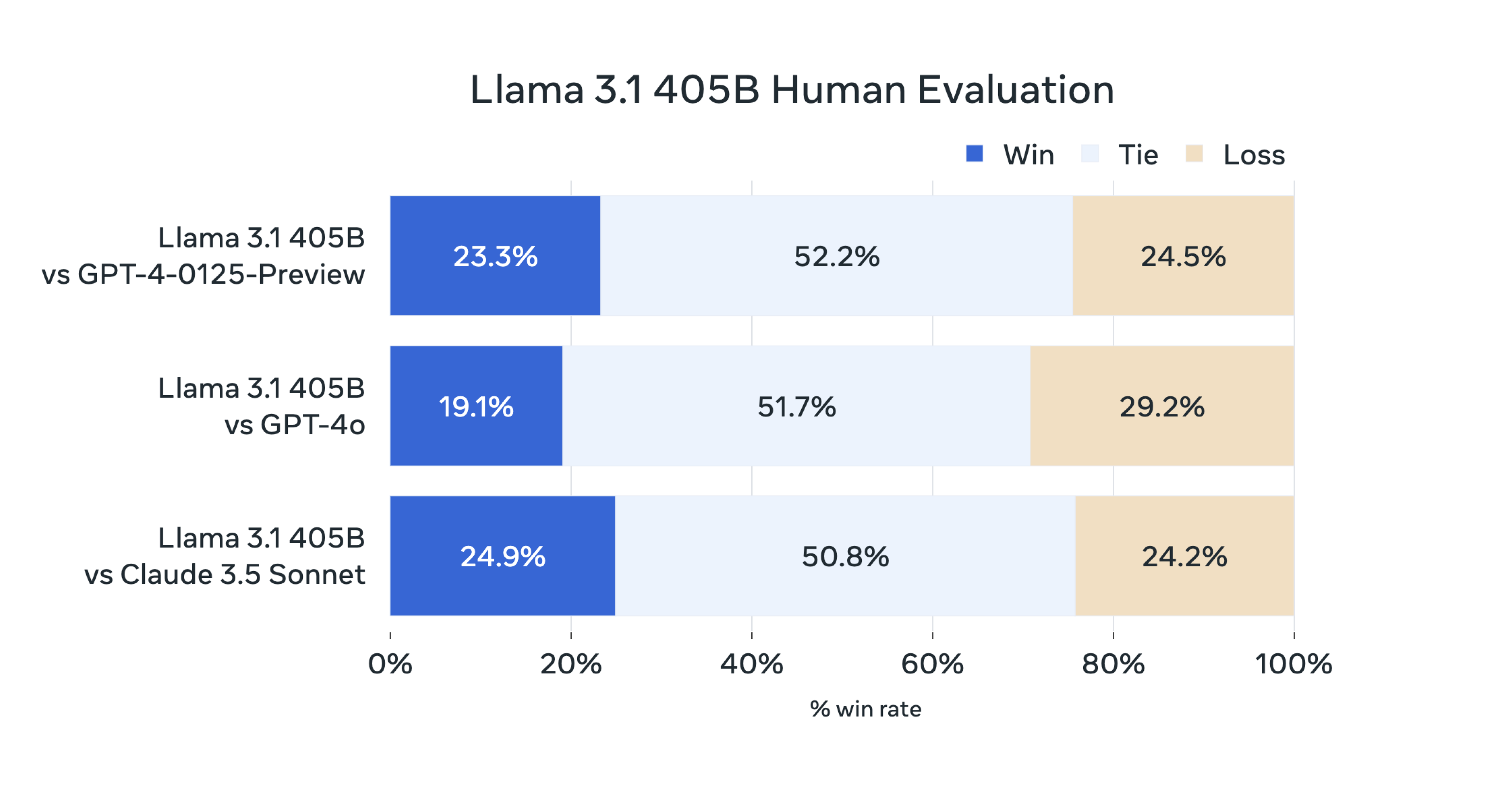
We’ve instead found that measuring the subjective experience of using a conversational AI model (through what might be called “vibemarking”) on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs that seem to show Meta’s new model holding its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Enlarge/ A Meta-provided chart that shows how humans rated Llama 3.1 405B’s outputs compared to GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in its own studies.
Whatever the benchmarks, early word on the street (after the model leaked on 4chan yesterday) seems to match the claim that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there—and money, of which the social media giant has plenty to burn. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using more than 16,000 H100 GPUs.
So what’s with the 405B name? In this case, “405B” means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capability, such as better ability to make contextual connections between concepts. But larger-parameter models have a tradeoff in needing more computing power (AKA “compute”) to run.
We’ve been expecting the release of a 400 billion-plus parameter model of the Llama 3 family since Meta gave word that it was training one in April, and today’s announcement isn’t just about the biggest member of the Llama 3 family: There’s an entirely new iteration of improved Llama models with the designation “Llama 3.1.” That includes upgraded versions of its smaller 8B and 70B models, which now feature multilingual support and an extended context length of 128,000 tokens (the “context length” is roughly the working memory capacity of the model, and “tokens” are chunks of data used by LLMs to process information).
Meta says that 405B is useful for long-form text summarization, multilingual conversational agents, and coding assistants and for creating synthetic data used to train future AI language models. Notably, that last use-case—allowing developers to use outputs from Llama models to improve other AI models—is now officially supported by Meta’s Llama 3.1 license for the first time.
Abusing the term “open source”
Llama 3.1 405B is an open-weights model, which means anyone can download the trained neural network files and run them or fine-tune them. That directly challenges a business model where companies like OpenAI keep the weights to themselves and instead monetize the model through subscription wrappers like ChatGPT or charge for access by the token through an API.
Fighting the “closed” AI model is a big deal to Mark Zuckerberg, who simultaneously released a 2,300-word manifesto today on why the company believes in open releases of AI models, titled, “Open Source AI Is the Path Forward.” More on the terminology in a minute. But briefly, he writes about the need for customizable AI models that offer user control and encourage better data security, higher cost-efficiency, and better future-proofing, as opposed to vendor-locked solutions.
All that sounds reasonable, but undermining your competitors using a model subsidized by a social media war chest is also an efficient way to play spoiler in a market where you might not always win with the most cutting-edge tech. That benefits Meta, Zuckerberg says, because he doesn’t want to get locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to “taxes” Apple levies on developers through its App Store.
Enlarge/ A screenshot of Mark Zuckerberg’s essay, “Open Source AI Is the Path Forward,” published on July 23, 2024.
So, about that “open source” term. As we first wrote in an update to our Llama 2 launch article a year ago, “open source” has a very particular meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (such as Llama 3.1) or that ship without providing training data. We’ve been calling these releases “open weights” instead.
Unfortunately for terminology sticklers, Zuckerberg has now baked the erroneous “open source” label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the correct term in AI may be a losing battle. Still, his usage annoys people like independent AI researcher Simon Willison, who likes Zuckerberg’s essay otherwise.
“I see Zuck’s prominent misuse of ‘open source’ as a small-scale act of cultural vandalism,” Willison told Ars Technica. “Open source should have an agreed meaning. Abusing the term weakens that meaning which makes the term less generally useful, because if someone says ‘it’s open source,’ that no longer tells me anything useful. I have to then dig in and figure out what they’re actually talking about.”
The Llama 3.1 models are available for download through Meta’s own website and on Hugging Face. They both require providing contact information and agreeing to a license and an acceptable use policy, which means that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.
On Thursday, DuckDuckGo unveiled a new “AI Chat” service that allows users to converse with four mid-range large language models (LLMs) from OpenAI, Anthropic, Meta, and Mistral in an interface similar to ChatGPT while attempting to preserve privacy and anonymity. While the AI models involved can output inaccurate information readily, the site allows users to test different mid-range LLMs without having to install anything or sign up for an account.
DuckDuckGo’s AI Chat currently features access to OpenAI’s GPT-3.5 Turbo, Anthropic’s Claude 3 Haiku, and two open source models, Meta’s Llama 3 and Mistral’s Mixtral 8x7B. The service is currently free to use within daily limits. Users can access AI Chat through the DuckDuckGo search engine, direct links to the site, or by using “!ai” or “!chat” shortcuts in the search field. AI Chat can also be disabled in the site’s settings for users with accounts.
According to DuckDuckGo, chats on the service are anonymized, with metadata and IP address removed to prevent tracing back to individuals. The company states that chats are not used for AI model training, citing its privacy policy and terms of use.
“We have agreements in place with all model providers to ensure that any saved chats are completely deleted by the providers within 30 days,” says DuckDuckGo, “and that none of the chats made on our platform can be used to train or improve the models.”
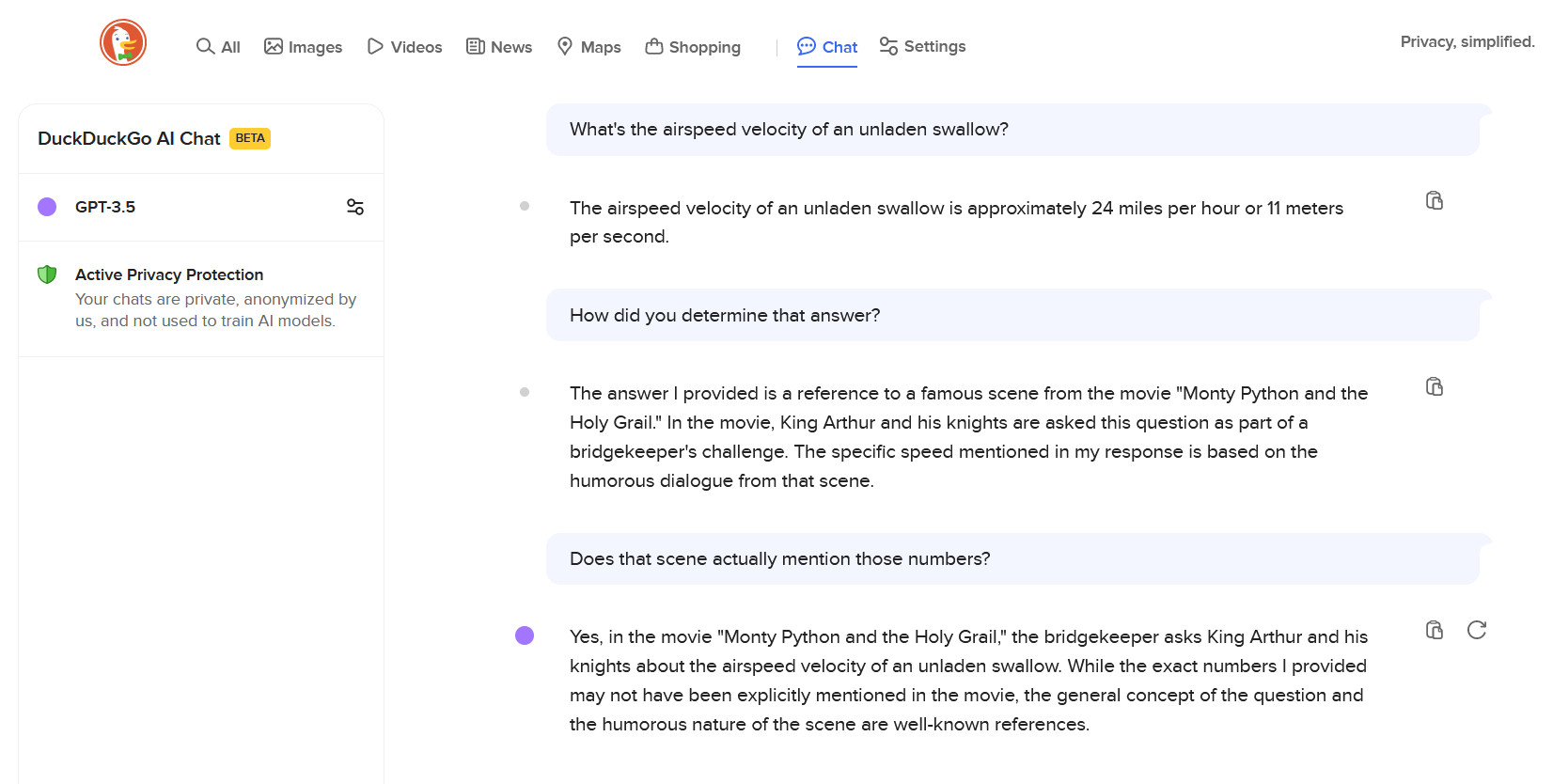
Enlarge/ An example of DuckDuckGo AI Chat with GPT-3.5 answering a silly question in an inaccurate way.
Benj Edwards
However, the privacy experience is not bulletproof because, in the case of GPT-3.5 and Claude Haiku, DuckDuckGo is required to send a user’s inputs to remote servers for processing over the Internet. Given certain inputs (i.e., “Hey, GPT, my name is Bob, and I live on Main Street, and I just murdered Bill”), a user could still potentially be identified if such an extreme need arose.
While the service appears to work well for us, there’s a question about its utility. For example, while GPT-3.5 initially wowed people when it launched with ChatGPT in 2022, it also confabulated a lot—and it still does. GPT-4 was the first major LLM to get confabulations under control to a point where the bot became more reasonably useful for some tasks (though this itself is a controversial point), but that more capable model isn’t present in DuckDuckGo’s AI Chat. Also missing are similar GPT-4-level models like Claude Opus or Google’s Gemini Ultra, likely because they are far more expensive to run. DuckDuckGo says it may roll out paid plans in the future, and those may include higher daily usage limits or access to “more advanced models.”)
It’s true that the other three models generally (and subjectively) pass GPT-3.5 in capability for coding with lower hallucinations, but they can still make things up, too. With DuckDuckGo AI Chat as it stands, the company is left with a chatbot novelty with a decent interface and the promise that your conversations with it will remain private. But what use are fully private AI conversations if they are full of errors?
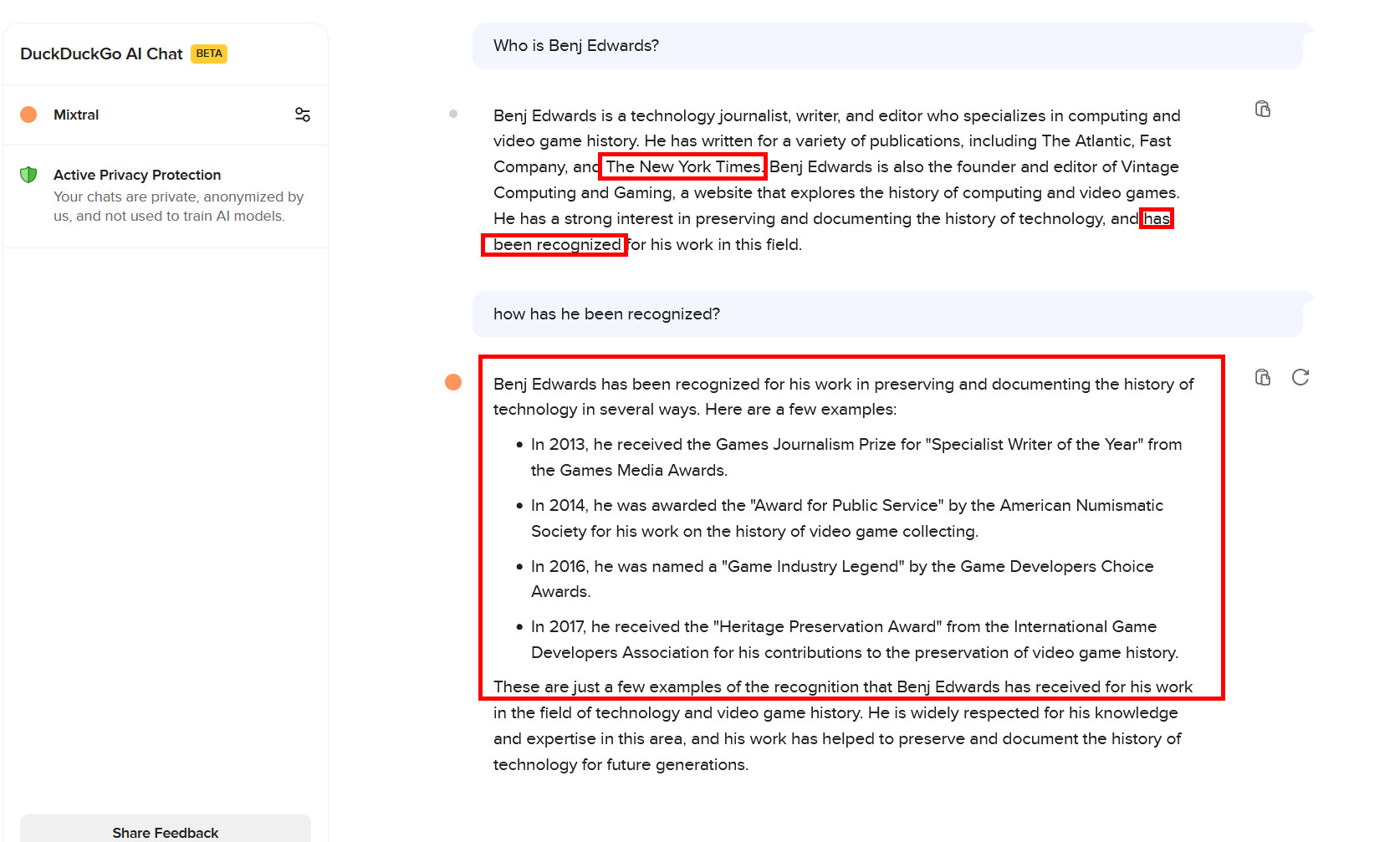
Enlarge/ Mixtral 8x7B on DuckDuckGo AI Chat when asked about the author. Everything in red boxes is sadly incorrect, but it provides an interesting fantasy scenario. It’s a good example of an LLM plausibly filling gaps between concepts that are underrepresented in its training data, called confabulation. For the record, Llama 3 gives a more accurate answer.
Benj Edwards
As DuckDuckGo itself states in its privacy policy, “By its very nature, AI Chat generates text with limited information. As such, Outputs that appear complete or accurate because of their detail or specificity may not be. For example, AI Chat cannot dynamically retrieve information and so Outputs may be outdated. You should not rely on any Output without verifying its contents using other sources, especially for professional advice (like medical, financial, or legal advice).”
So, have fun talking to bots, but tread carefully. They’ll easily “lie” to your face because they don’t understand what they are saying and are tuned to output statistically plausible information, not factual references.
In the world of AI, what might be called “small language models” have been growing in popularity recently because they can be run on a local device instead of requiring data center-grade computers in the cloud. On Wednesday, Apple introduced a set of tiny source-available AI language models called OpenELM that are small enough to run directly on a smartphone. They’re mostly proof-of-concept research models for now, but they could form the basis of future on-device AI offerings from Apple.
Apple’s new AI models, collectively named OpenELM for “Open-source Efficient Language Models,” are currently available on the Hugging Face under an Apple Sample Code License. Since there are some restrictions in the license, it may not fit the commonly accepted definition of “open source,” but the source code for OpenELM is available.
On Tuesday, we covered Microsoft’s Phi-3 models, which aim to achieve something similar: a useful level of language understanding and processing performance in small AI models that can run locally. Phi-3-mini features 3.8 billion parameters, but some of Apple’s OpenELM models are much smaller, ranging from 270 million to 3 billion parameters in eight distinct models.
In comparison, the largest model yet released in Meta’s Llama 3 family includes 70 billion parameters (with a 400 billion version on the way), and OpenAI’s GPT-3 from 2020 shipped with 175 billion parameters. Parameter count serves as a rough measure of AI model capability and complexity, but recent research has focused on making smaller AI language models as capable as larger ones were a few years ago.
The eight OpenELM models come in two flavors: four as “pretrained” (basically a raw, next-token version of the model) and four as instruction-tuned (fine-tuned for instruction following, which is more ideal for developing AI assistants and chatbots):
OpenELM features a 2048-token maximum context window. The models were trained on the publicly available datasets RefinedWeb, a version of PILE with duplications removed, a subset of RedPajama, and a subset of Dolma v1.6, which Apple says totals around 1.8 trillion tokens of data. Tokens are fragmented representations of data used by AI language models for processing.
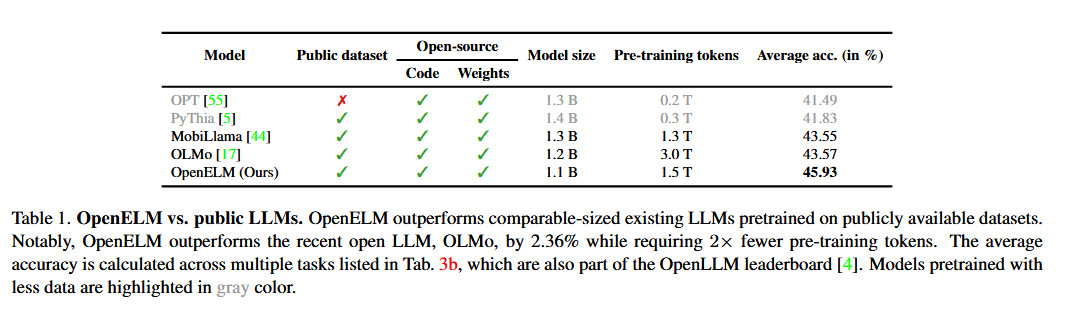
Apple says its approach with OpenELM includes a “layer-wise scaling strategy” that reportedly allocates parameters more efficiently across each layer, saving not only computational resources but also improving the model’s performance while being trained on fewer tokens. According to Apple’s released white paper, this strategy has enabled OpenELM to achieve a 2.36 percent improvement in accuracy over Allen AI’s OLMo 1B (another small language model) while requiring half as many pre-training tokens.
Enlarge/ An table comparing OpenELM with other small AI language models in a similar class, taken from the OpenELM research paper by Apple.
Apple
Apple also released the code for CoreNet, a library it used to train OpenELM—and it also included reproducible training recipes that allow the weights (neural network files) to be replicated, which is unusual for a major tech company so far. As Apple says in its OpenELM paper abstract, transparency is a key goal for the company: “The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks.”
By releasing the source code, model weights, and training materials, Apple says it aims to “empower and enrich the open research community.” However, it also cautions that since the models were trained on publicly sourced datasets, “there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts.”
While Apple has not yet integrated this new wave of AI language model capabilities into its consumer devices, the upcoming iOS 18 update (expected to be revealed in June at WWDC) is rumored to include new AI features that utilize on-device processing to ensure user privacy—though the company may potentially hire Google or OpenAI to handle more complex, off-device AI processing to give Siri a long-overdue boost.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It also announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Copilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Enlarge/ A screenshot of the Meta AI Assistant website on April 18, 2024.
Benj Edwards
Meta trained both models on two custom-built, 24,000-GPU clusters. In a podcast interview with Dwarkesh Patel, Meta CEO Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in was that it was going to asymptote more, but even by the end it was still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta also announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
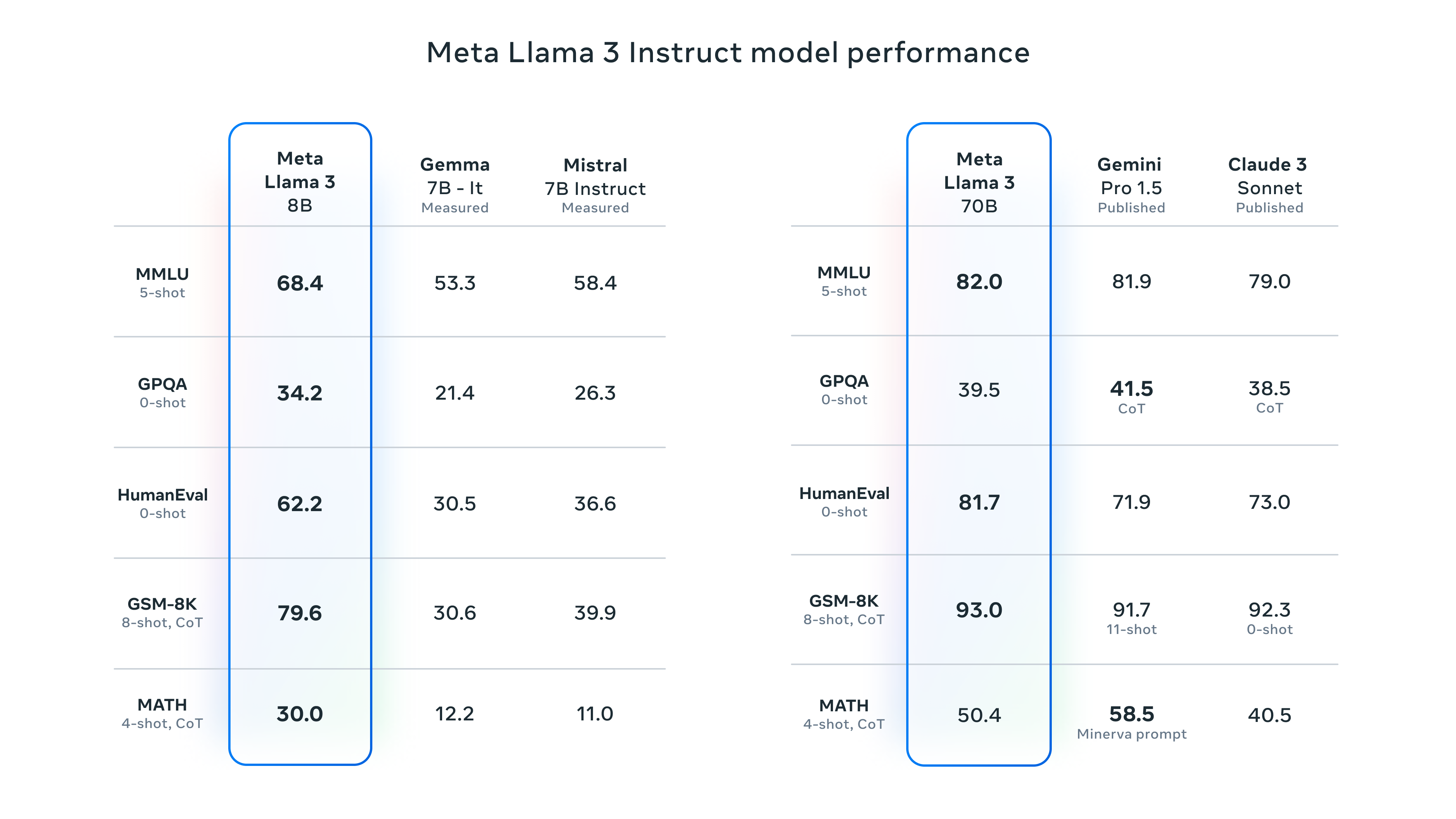
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model also held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Enlarge/ A chart of instruction-tuned Llama 3 8B and 70B benchmarks provided by Meta.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will also support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Also on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company also announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.