DuckDuckGo offers “anonymous” access to AI chatbots through new service
anonymous confabulations —
DDG offers LLMs from OpenAI, Anthropic, Meta, and Mistral for factually-iffy conversations.
DuckDuckGo
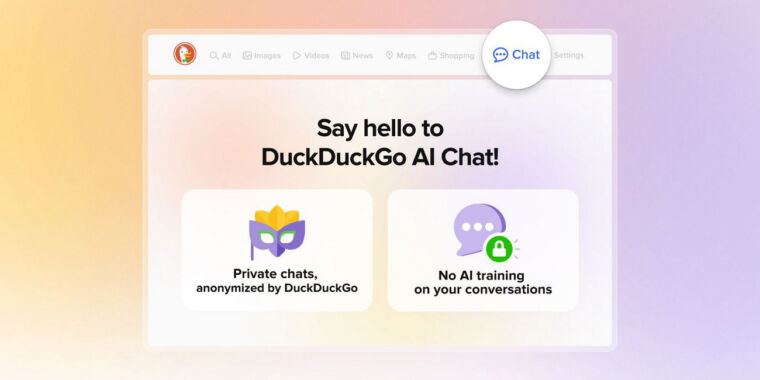
On Thursday, DuckDuckGo unveiled a new “AI Chat” service that allows users to converse with four mid-range large language models (LLMs) from OpenAI, Anthropic, Meta, and Mistral in an interface similar to ChatGPT while attempting to preserve privacy and anonymity. While the AI models involved can output inaccurate information readily, the site allows users to test different mid-range LLMs without having to install anything or sign up for an account.
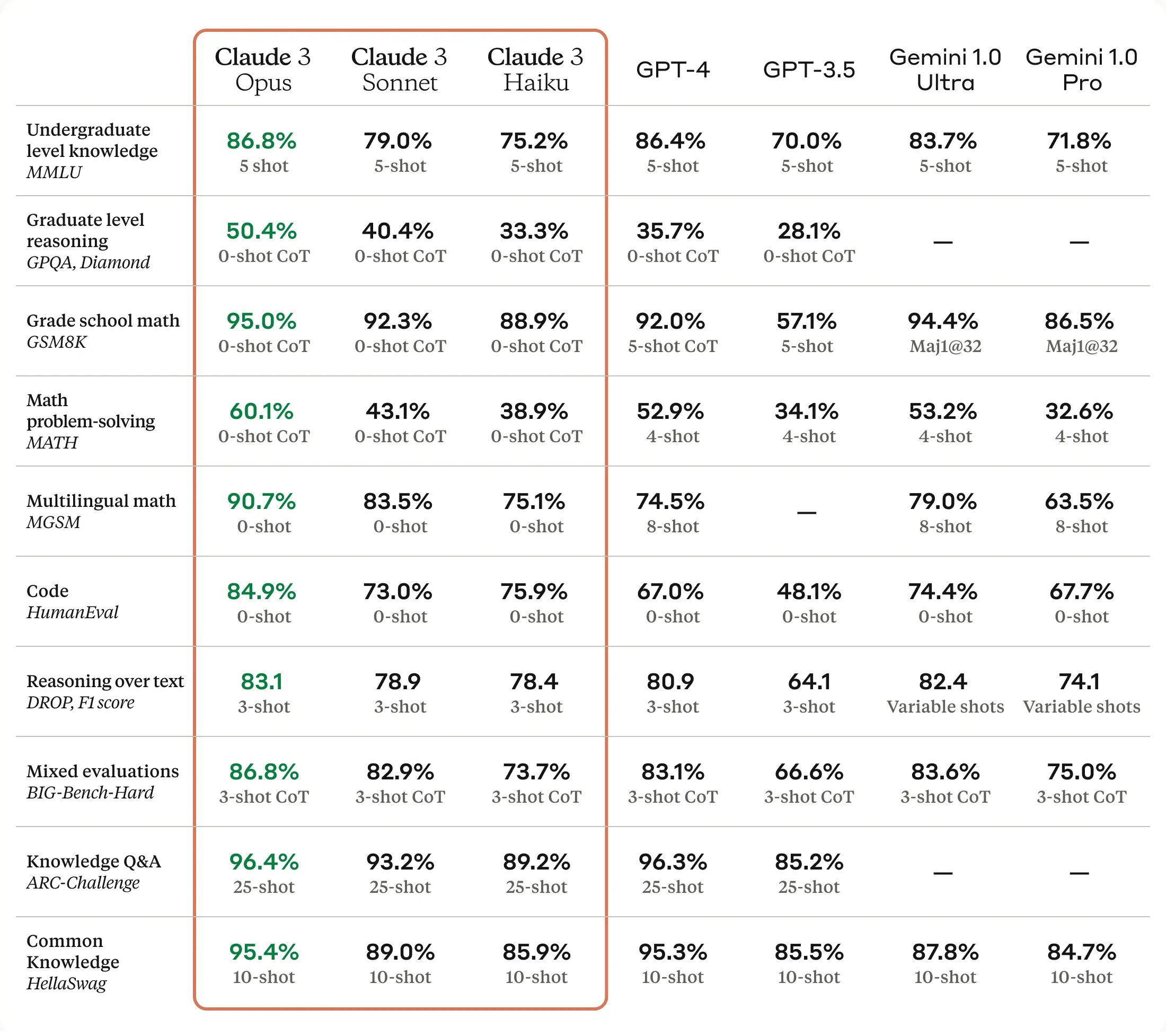
DuckDuckGo’s AI Chat currently features access to OpenAI’s GPT-3.5 Turbo, Anthropic’s Claude 3 Haiku, and two open source models, Meta’s Llama 3 and Mistral’s Mixtral 8x7B. The service is currently free to use within daily limits. Users can access AI Chat through the DuckDuckGo search engine, direct links to the site, or by using “!ai” or “!chat” shortcuts in the search field. AI Chat can also be disabled in the site’s settings for users with accounts.
According to DuckDuckGo, chats on the service are anonymized, with metadata and IP address removed to prevent tracing back to individuals. The company states that chats are not used for AI model training, citing its privacy policy and terms of use.
“We have agreements in place with all model providers to ensure that any saved chats are completely deleted by the providers within 30 days,” says DuckDuckGo, “and that none of the chats made on our platform can be used to train or improve the models.”
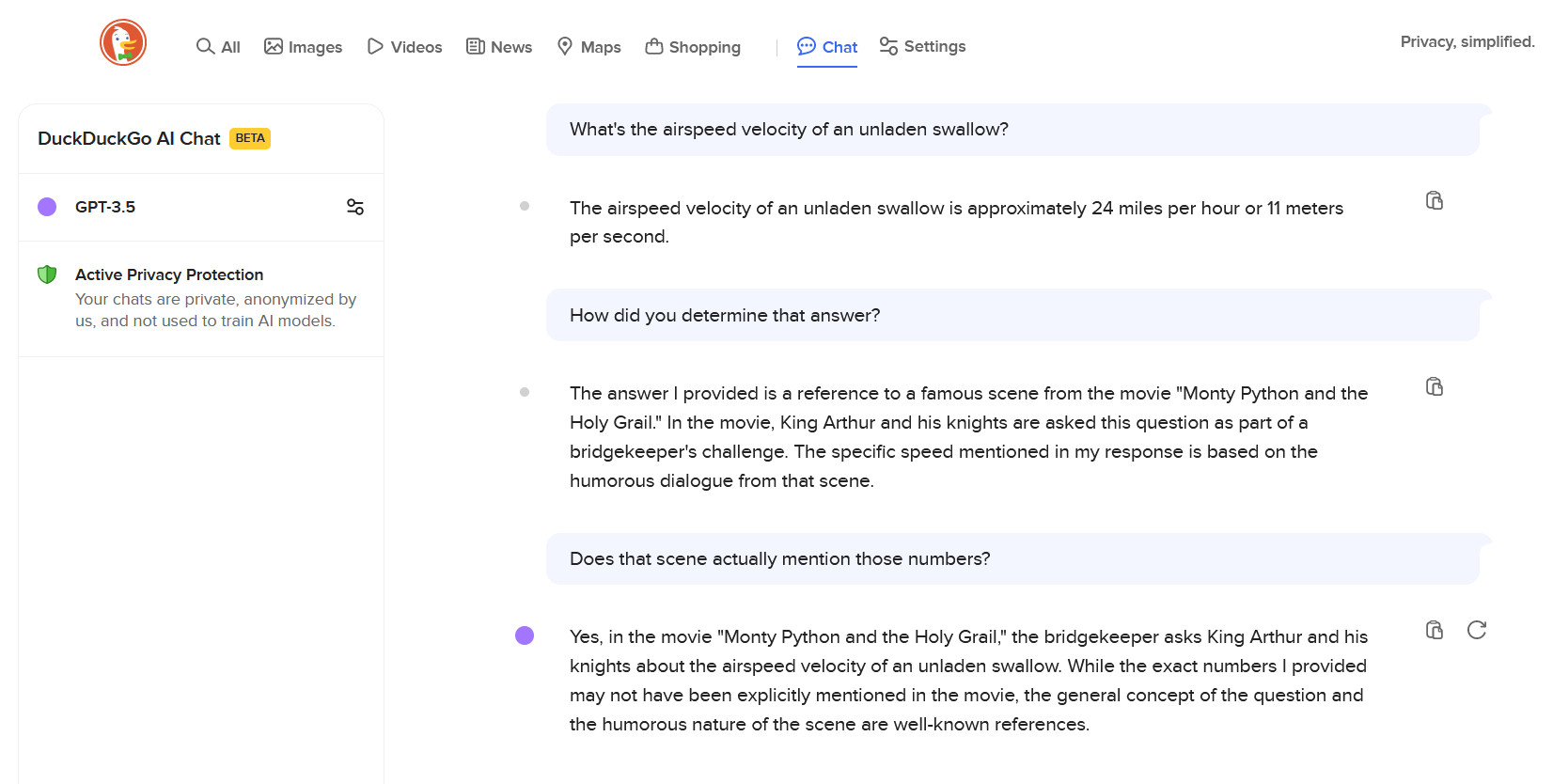
Enlarge / An example of DuckDuckGo AI Chat with GPT-3.5 answering a silly question in an inaccurate way.
Benj Edwards
However, the privacy experience is not bulletproof because, in the case of GPT-3.5 and Claude Haiku, DuckDuckGo is required to send a user’s inputs to remote servers for processing over the Internet. Given certain inputs (i.e., “Hey, GPT, my name is Bob, and I live on Main Street, and I just murdered Bill”), a user could still potentially be identified if such an extreme need arose.
While the service appears to work well for us, there’s a question about its utility. For example, while GPT-3.5 initially wowed people when it launched with ChatGPT in 2022, it also confabulated a lot—and it still does. GPT-4 was the first major LLM to get confabulations under control to a point where the bot became more reasonably useful for some tasks (though this itself is a controversial point), but that more capable model isn’t present in DuckDuckGo’s AI Chat. Also missing are similar GPT-4-level models like Claude Opus or Google’s Gemini Ultra, likely because they are far more expensive to run. DuckDuckGo says it may roll out paid plans in the future, and those may include higher daily usage limits or access to “more advanced models.”)
It’s true that the other three models generally (and subjectively) pass GPT-3.5 in capability for coding with lower hallucinations, but they can still make things up, too. With DuckDuckGo AI Chat as it stands, the company is left with a chatbot novelty with a decent interface and the promise that your conversations with it will remain private. But what use are fully private AI conversations if they are full of errors?
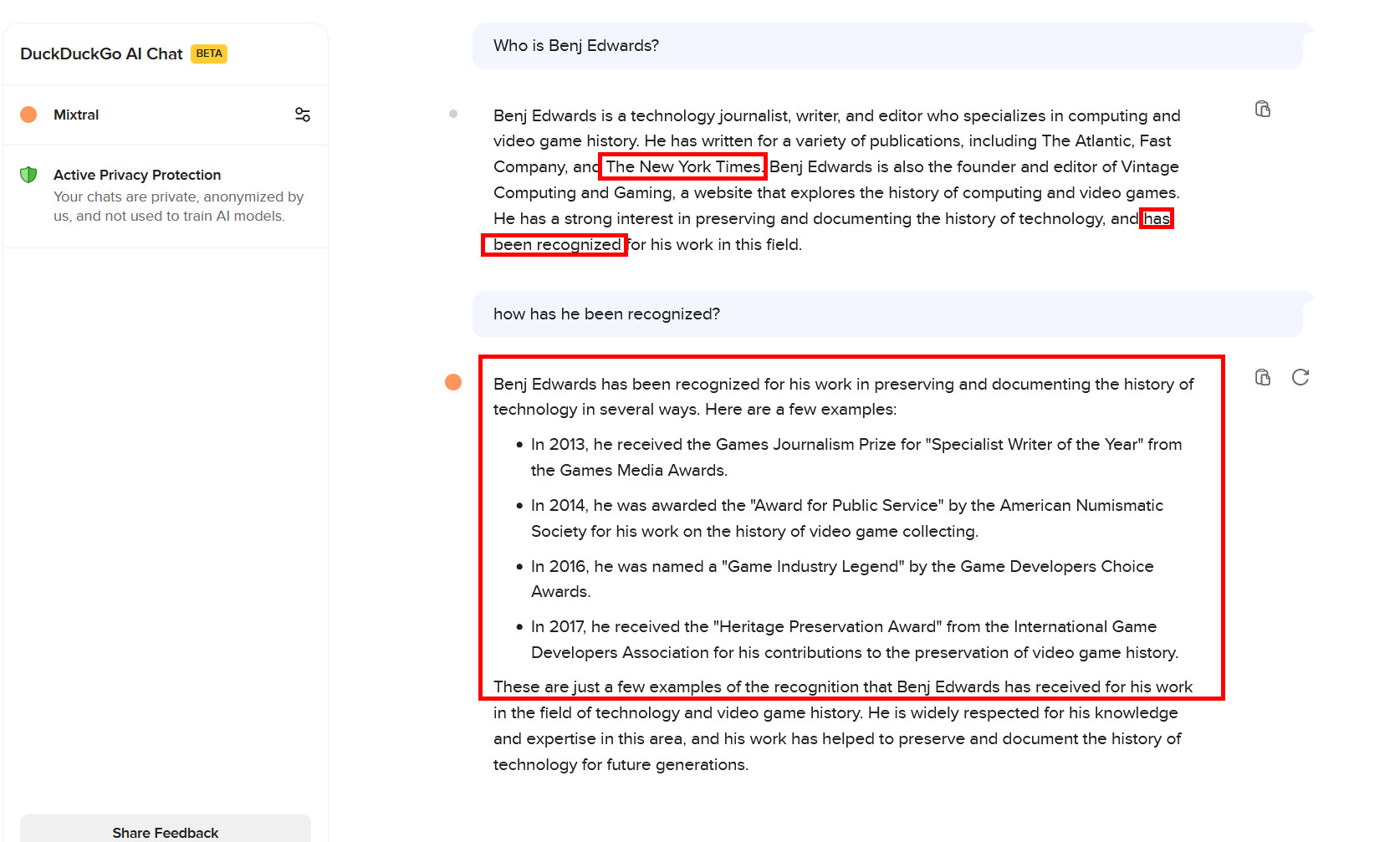
Enlarge / Mixtral 8x7B on DuckDuckGo AI Chat when asked about the author. Everything in red boxes is sadly incorrect, but it provides an interesting fantasy scenario. It’s a good example of an LLM plausibly filling gaps between concepts that are underrepresented in its training data, called confabulation. For the record, Llama 3 gives a more accurate answer.
Benj Edwards
As DuckDuckGo itself states in its privacy policy, “By its very nature, AI Chat generates text with limited information. As such, Outputs that appear complete or accurate because of their detail or specificity may not be. For example, AI Chat cannot dynamically retrieve information and so Outputs may be outdated. You should not rely on any Output without verifying its contents using other sources, especially for professional advice (like medical, financial, or legal advice).”
So, have fun talking to bots, but tread carefully. They’ll easily “lie” to your face because they don’t understand what they are saying and are tuned to output statistically plausible information, not factual references.
DuckDuckGo offers “anonymous” access to AI chatbots through new service Read More »


{kind=link}