
Major shifts at OpenAI spark skepticism about impending AGI timelines
Shuffling the deck —
De Kraker: “If OpenAI is right on the verge of AGI, why do prominent people keep leaving?”

Benj Edwards / Getty Images
Over the past week, OpenAI experienced a significant leadership shake-up as three key figures announced major changes. Greg Brockman, the company’s president and co-founder, is taking an extended sabbatical until the end of the year, while another co-founder, John Schulman, permanently departed for rival Anthropic. Peter Deng, VP of Consumer Product, has also left the ChatGPT maker.
In a post on X, Brockman wrote, “I’m taking a sabbatical through end of year. First time to relax since co-founding OpenAI 9 years ago. The mission is far from complete; we still have a safe AGI to build.”
The moves have led some to wonder just how close OpenAI is to a long-rumored breakthrough of some kind of reasoning artificial intelligence if high-profile employees are jumping ship (or taking long breaks, in the case of Brockman) so easily. As AI developer Benjamin De Kraker put it on X, “If OpenAI is right on the verge of AGI, why do prominent people keep leaving?”
AGI refers to a hypothetical AI system that could match human-level intelligence across a wide range of tasks without specialized training. It’s the ultimate goal of OpenAI, and company CEO Sam Altman has said it could emerge in the “reasonably close-ish future.” AGI is also a concept that has sparked concerns about potential existential risks to humanity and the displacement of knowledge workers. However, the term remains somewhat vague, and there’s considerable debate in the AI community about what truly constitutes AGI or how close we are to achieving it.
The emergence of the “next big thing” in AI has been seen by critics such as Ed Zitron as a necessary step to justify ballooning investments in AI models that aren’t yet profitable. The industry is holding its breath that OpenAI, or a competitor, has some secret breakthrough waiting in the wings that will justify the massive costs associated with training and deploying LLMs.
But other AI critics, such as Gary Marcus, have postulated that major AI companies have reached a plateau of large language model (LLM) capability centered around GPT-4-level models since no AI company has yet made a major leap past the groundbreaking LLM that OpenAI released in March 2023. Microsoft CTO Kevin Scott has countered these claims, saying that LLM “scaling laws” (that suggest LLMs increase in capability proportionate to more compute power thrown at them) will continue to deliver improvements over time and that more patience is needed as the next generation (say, GPT-5) undergoes training.
In the scheme of things, Brockman’s move sounds like an extended, long overdue vacation (or perhaps a period to deal with personal issues beyond work). Regardless of the reason, the duration of the sabbatical raises questions about how the president of a major tech company can suddenly disappear for four months without affecting day-to-day operations, especially during a critical time in its history.
Unless, of course, things are fairly calm at OpenAI—and perhaps GPT-5 isn’t going to ship until at least next year when Brockman returns. But this is speculation on our part, and OpenAI (whether voluntarily or not) sometimes surprises us when we least expect it. (Just today, Altman dropped a hint on X about strawberries that some people interpret as being a hint of a potential major model undergoing testing or nearing release.)
A pattern of departures and the rise of Anthropic

Anthropic / Benj Edwards
What may sting OpenAI the most about the recent departures is that a few high-profile employees have left to join Anthropic, a San Francisco-based AI company founded in 2021 by ex-OpenAI employees Daniela and Dario Amodei.
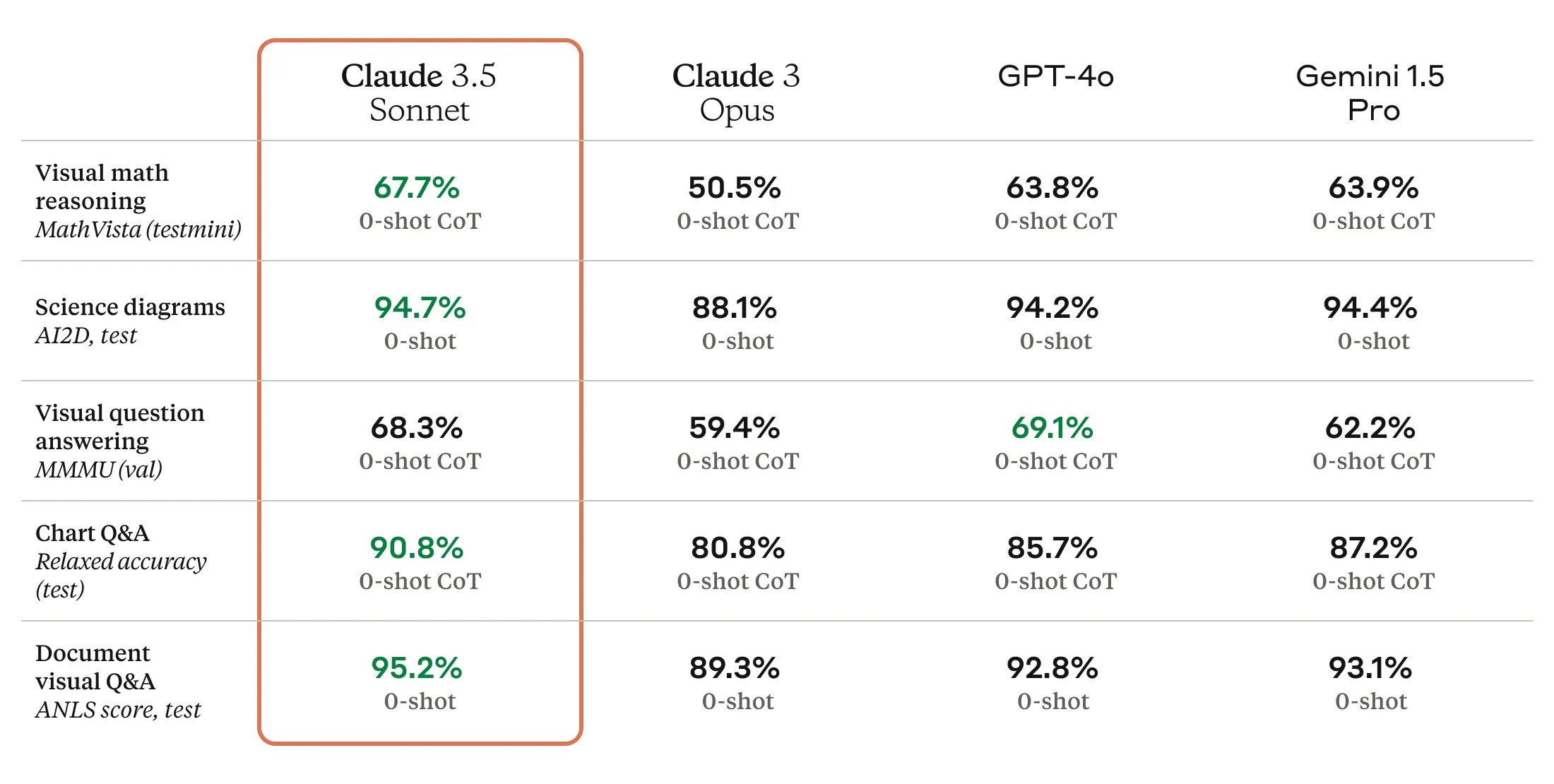
Anthropic offers a subscription service called Claude.ai that is similar to ChatGPT. Its most recent LLM, Claude 3.5 Sonnet, along with its web-based interface, has rapidly gained favor over ChatGPT among some LLM users who are vocal on social media, though it likely does not yet match ChatGPT in terms of mainstream brand recognition.
In particular, John Schulman, an OpenAI co-founder and key figure in the company’s post-training process for LLMs, revealed in a statement on X that he’s leaving to join rival AI firm Anthropic to do more hands-on work: “This choice stems from my desire to deepen my focus on AI alignment, and to start a new chapter of my career where I can return to hands-on technical work.” Alignment is a field that hopes to guide AI models to produce helpful outputs.
In May, OpenAI alignment researcher Jan Leike left OpenAI to join Anthropic as well, criticizing OpenAI’s handling of alignment safety.
Adding to the recent employee shake-up, The Information reports that Peter Deng, a product leader who joined OpenAI last year after stints at Meta Platforms, Uber, and Airtable, has also left the company, though we do not yet know where he is headed. In May, OpenAI co-founder Ilya Sutskever left to found a rival startup, and prominent software engineer Andrej Karpathy departed in February, recently launching an educational venture.
As De Kraker noted, if OpenAI were on the verge of developing world-changing AI technology, wouldn’t these high-profile AI veterans want to stick around and be part of this historic moment in time? “Genuine question,” he wrote. “If you were pretty sure the company you’re a key part of—and have equity in—is about to crack AGI within one or two years… why would you jump ship?”
Despite the departures, Schulman expressed optimism about OpenAI’s future in his farewell note on X. “I am confident that OpenAI and the teams I was part of will continue to thrive without me,” he wrote. “I’m incredibly grateful for the opportunity to participate in such an important part of history and I’m proud of what we’ve achieved together. I’ll still be rooting for you all, even while working elsewhere.”
This article was updated on August 7, 2024 at 4: 23 PM to mention Sam Altman’s tweet about strawberries.
Major shifts at OpenAI spark skepticism about impending AGI timelines Read More »






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}